深度优先搜索
深度优先搜索和广度优先搜索

二、 重排九宫问题游戏
在一个 3 乘 3 的九宫中有 1-8 的 8 个数及一个空格随机摆放在其中的格子里。如下面 左图所示。现在要求实现这样的问题:将该九宫调整为如下图右图所示的形式。调整规则是: 每次只能将与空格(上,下或左,右)相临的一个数字平移到空格中。试编程实现。
|2|8 |3|
|1|2|3|
from = f; to = t; distance = d; skip = false; } } class Depth { final int MAX = 100; // This array holds the flight information. FlightInfo flights[] = new FlightInfo[MAX]; int numFlights = 0; // number of entries in flight array Stack btStack = new Stack(); // backtrack stack public static void main(String args[]) {
下面是用深度优先搜索求解的程序:
// Find connections using a depth-first search. import java.util.*; import java.io.*; // Flight information. class FlightInfo {
String from; String to; int distance; boolean skip; // used in backtracking FlightInfo(String f, String t, int d) {
int dist; FlightInfo f; // See if at destination. dist = match(from, to); if(dist != 0) {
深度优先搜索和广度优先搜索

深度优先搜索和广度优先搜索一、深度优先搜索和广度优先搜索的深入讨论(一)深度优先搜索的特点是无论问题的内容和性质以及求解要求如何不同,它们的程序结构都是相同的,即都是深度优先算法(一)和深度优先算法(二)中描述的算法结构,不相同的仅仅是存储结点数据结构和产生规则以及输出要求。
(2)深度优先搜索法有递归以及非递归两种设计方法。
一般的,当搜索深度较小、问题递归方式比较明显时,用递归方法设计好,它可以使得程序结构更简捷易懂。
当搜索深度较大时,当数据量较大时,由于系统堆栈容量的限制,递归容易产生溢出,用非递归方法设计比较好。
(3)深度优先搜索方法有广义和狭义两种理解。
广义的理解是,只要最新产生的结点(即深度最大的结点)先进行扩展的方法,就称为深度优先搜索方法。
在这种理解情况下,深度优先搜索算法有全部保留和不全部保留产生的结点的两种情况。
而狭义的理解是,仅仅只保留全部产生结点的算法。
本书取前一种广义的理解。
不保留全部结点的算法属于一般的回溯算法范畴。
保留全部结点的算法,实际上是在数据库中产生一个结点之间的搜索树,因此也属于图搜索算法的范畴。
(4)不保留全部结点的深度优先搜索法,由于把扩展望的结点从数据库中弹出删除,这样,一般在数据库中存储的结点数就是深度值,因此它占用的空间较少,所以,当搜索树的结点较多,用其他方法易产生内存溢出时,深度优先搜索不失为一种有效的算法。
(5)从输出结果可看出,深度优先搜索找到的第一个解并不一定是最优解.如果要求出最优解的话,一种方法将是后面要介绍的动态规划法,另一种方法是修改原算法:把原输出过程的地方改为记录过程,即记录达到当前目标的路径和相应的路程值,并与前面已记录的值进行比较,保留其中最优的,等全部搜索完成后,才把保留的最优解输出。
二、广度优先搜索法的显著特点是:(1)在产生新的子结点时,深度越小的结点越先得到扩展,即先产生它的子结点。
为使算法便于实现,存放结点的数据库一般用队列的结构。
dfs通用步骤-概述说明以及解释

dfs通用步骤-概述说明以及解释1.引言1.1 概述DFS(深度优先搜索)是一种常用的图遍历算法,它通过深度优先的策略来遍历图中的所有节点。
在DFS中,从起始节点开始,一直向下访问直到无法继续为止,然后返回到上一个未完成的节点,继续访问它的下一个未被访问的邻居节点。
这个过程不断重复,直到图中所有的节点都被访问为止。
DFS算法的核心思想是沿着一条路径尽可能深入地搜索,直到无法继续为止。
在搜索过程中,DFS会使用一个栈来保存待访问的节点,以及记录已经访问过的节点。
当访问一个节点时,将其标记为已访问,并将其所有未访问的邻居节点加入到栈中。
然后从栈中取出下一个节点进行访问,重复这个过程直到栈为空。
优点是DFS算法实现起来比较简单,而且在解决一些问题时具有较好的效果。
同时,DFS算法可以用来解决一些经典的问题,比如寻找图中的连通分量、判断图中是否存在环、图的拓扑排序等。
然而,DFS算法也存在一些缺点。
首先,DFS算法不保证找到最优解,有可能陷入局部最优解而无法找到全局最优解。
另外,如果图非常庞大且存在大量的无效节点,DFS可能会陷入无限循环或者无法找到解。
综上所述,DFS是一种常用的图遍历算法,可以用来解决一些问题,但需要注意其局限性和缺点。
在实际应用中,我们需要根据具体问题的特点来选择合适的搜索策略。
在下一部分中,我们将详细介绍DFS算法的通用步骤和要点,以便读者更好地理解和应用该算法。
1.2 文章结构文章结构部分的内容如下所示:文章结构:在本文中,将按照以下顺序介绍DFS(深度优先搜索)通用步骤。
首先,引言部分将概述DFS的基本概念和应用场景。
其次,正文部分将详细解释DFS通用步骤的两个要点。
最后,结论部分将总结本文的主要内容并展望未来DFS的发展趋势。
通过这样的结构安排,读者可以清晰地了解到DFS算法的基本原理和它在实际问题中的应用。
接下来,让我们开始正文的介绍。
1.3 目的目的部分的内容可以包括对DFS(Depth First Search,深度优先搜索)的应用和重要性进行介绍。
深度优先搜索和广度优先搜索

深度优先搜索和⼴度优先搜索 深度优先搜索和⼴度优先搜索都是图的遍历算法。
⼀、深度优先搜索(Depth First Search) 1、介绍 深度优先搜索(DFS),顾名思义,在进⾏遍历或者说搜索的时候,选择⼀个没有被搜过的结点(⼀般选择顶点),按照深度优先,⼀直往该结点的后续路径结点进⾏访问,直到该路径的最后⼀个结点,然后再从未被访问的邻结点进⾏深度优先搜索,重复以上过程,直⾄所有点都被访问,遍历结束。
⼀般步骤:(1)访问顶点v;(2)依次从v的未被访问的邻接点出发,对图进⾏深度优先遍历;直⾄图中和v有路径相通的顶点都被访问;(3)若此时图中尚有顶点未被访问,则从⼀个未被访问的顶点出发,重新进⾏深度优先遍历,直到图中所有顶点均被访问过为⽌。
可以看出,深度优先算法使⽤递归即可实现。
2、⽆向图的深度优先搜索 下⾯以⽆向图为例,进⾏深度优先搜索遍历: 遍历过程: 所以遍历结果是:A→C→B→D→F→G→E。
3、有向图的深度优先搜索 下⾯以有向图为例,进⾏深度优先遍历: 遍历过程: 所以遍历结果为:A→B→C→E→D→F→G。
⼆、⼴度优先搜索(Breadth First Search) 1、介绍 ⼴度优先搜索(BFS)是图的另⼀种遍历⽅式,与DFS相对,是以⼴度优先进⾏搜索。
简⾔之就是先访问图的顶点,然后⼴度优先访问其邻接点,然后再依次进⾏被访问点的邻接点,⼀层⼀层访问,直⾄访问完所有点,遍历结束。
2、⽆向图的⼴度优先搜索 下⾯是⽆向图的⼴度优先搜索过程: 所以遍历结果为:A→C→D→F→B→G→E。
3、有向图的⼴度优先搜索 下⾯是有向图的⼴度优先搜索过程: 所以遍历结果为:A→B→C→E→F→D→G。
三、两者实现⽅式对⽐ 深度优先搜索⽤栈(stack)来实现,整个过程可以想象成⼀个倒⽴的树形:把根节点压⼊栈中。
每次从栈中弹出⼀个元素,搜索所有在它下⼀级的元素,把这些元素压⼊栈中。
并把这个元素记为它下⼀级元素的前驱。
深度优先搜索算法详解及代码实现

深度优先搜索算法详解及代码实现深度优先搜索(Depth-First Search,DFS)是一种常见的图遍历算法,用于遍历或搜索图或树的所有节点。
它的核心思想是从起始节点开始,沿着一条路径尽可能深入地访问其他节点,直到无法继续深入为止,然后回退到上一个节点,继续搜索未访问过的节点,直到所有节点都被访问为止。
一、算法原理深度优先搜索算法是通过递归或使用栈(Stack)的数据结构来实现的。
下面是深度优先搜索算法的详细步骤:1. 选择起始节点,并标记该节点为已访问。
2. 从起始节点出发,依次访问与当前节点相邻且未被访问的节点。
3. 若当前节点有未被访问的邻居节点,则选择其中一个节点,将其标记为已访问,并将当前节点入栈。
4. 重复步骤2和3,直到当前节点没有未被访问的邻居节点。
5. 若当前节点没有未被访问的邻居节点,则从栈中弹出一个节点作为当前节点。
6. 重复步骤2至5,直到栈为空。
深度优先搜索算法会不断地深入到图或树的某一分支直到底部,然后再回退到上层节点继续搜索其他分支。
因此,它的搜索路径类似于一条深入的迷宫路径,直到没有其他路径可走后,再原路返回。
二、代码实现以下是使用递归方式实现深度优先搜索算法的代码:```pythondef dfs(graph, start, visited):visited.add(start)print(start, end=" ")for neighbor in graph[start]:if neighbor not in visited:dfs(graph, neighbor, visited)# 示例数据graph = {'A': ['B', 'C'],'B': ['A', 'D', 'E'],'C': ['A', 'F'],'D': ['B'],'E': ['B', 'F'],'F': ['C', 'E']}start_node = 'A'visited = set()dfs(graph, start_node, visited)```上述代码首先定义了一个用于实现深度优先搜索的辅助函数`dfs`。
深度优先算法
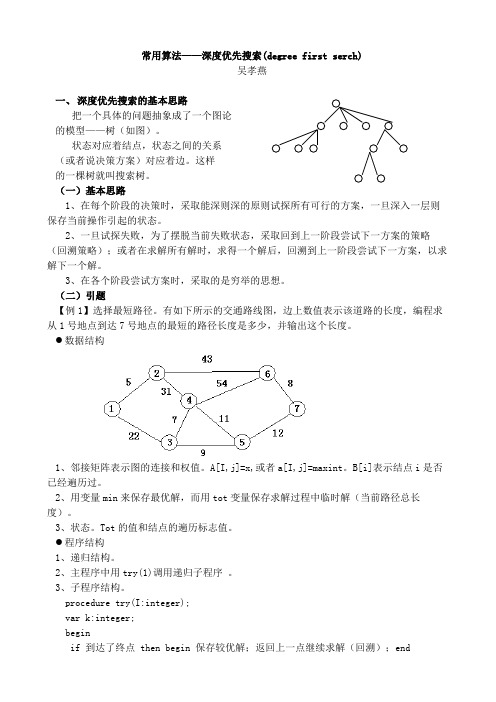
常用算法——深度优先搜索(degree first serch)吴孝燕一、深度优先搜索的基本思路把一个具体的问题抽象成了一个图论的模型——树(如图)。
状态对应着结点,状态之间的关系(或者说决策方案)对应着边。
这样的一棵树就叫搜索树。
(一)基本思路1、在每个阶段的决策时,采取能深则深的原则试探所有可行的方案,一旦深入一层则保存当前操作引起的状态。
2、一旦试探失败,为了摆脱当前失败状态,采取回到上一阶段尝试下一方案的策略(回溯策略);或者在求解所有解时,求得一个解后,回溯到上一阶段尝试下一方案,以求解下一个解。
3、在各个阶段尝试方案时,采取的是穷举的思想。
(二)引题【例1】选择最短路径。
有如下所示的交通路线图,边上数值表示该道路的长度,编程求从1号地点到达7号地点的最短的路径长度是多少,并输出这个长度。
●数据结构1、邻接矩阵表示图的连接和权值。
A[I,j]=x,或者a[I,j]=maxint。
B[i]表示结点i是否已经遍历过。
2、用变量min来保存最优解,而用tot变量保存求解过程中临时解(当前路径总长度)。
3、状态。
Tot的值和结点的遍历标志值。
●程序结构1、递归结构。
2、主程序中用try(1)调用递归子程序。
3、子程序结构。
procedure try(I:integer);var k:integer;beginif 到达了终点 then begin 保存较优解;返回上一点继续求解(回溯);endelsebegin穷举从I出发当前可以直接到达的点k;if I到k点有直接联边并且 k点没有遍历过 thenthen begin把A[I,K]累加入路径长度tot;k标记为已遍历;try(k); 现场恢复;end;end;●子程序procedure try(i:integer);var k:integer;beginif i=n then begin if tot<min then min:=tot;exit;endelsebeginfor k:=1 to n doif (b[k]=0) and (i<>k) and (a[i,k]<32700) thenbeginb[k]:=1;tot:=tot+a[i,k];try(k);b[k]:=0;tot:=tot-a[i,k]; end;end;end;●主程序数据输入readln(fi,n);for i:=1 to n dobeginfor j:=1 to n do read(fi,a[i,j]);readln(fi);end;close(fi);●主程序预处理和调用子程序tot:=0;min:=maxint;b[1]:=1;try(1);writeln('tot=',min);(三)递归程序结构框架Procedure try(i:integer);Var k:integer;BeginIf 所有阶段都已求解 thenBegin比较最优解并保存;回溯;endelsebeginfor k:=i 深度可能决策范围;do begin穷举当前阶段所有可能的决策(方案、结点)kif k方案可行 then begin记录状态变化;try(i+1);状态恢复(回溯); endend;end;End;二、深度优先搜索的应用例1:有A,B,C,D,E 5本书,要分给张、王、刘、赵、钱5位同学,每人只选一本。
信息学竞赛中的深度优先搜索算法
信息学竞赛中的深度优先搜索算法深度优先搜索(Depth First Search, DFS)是一种经典的图遍历算法,在信息学竞赛中被广泛应用。
本文将介绍深度优先搜索算法的原理、应用场景以及相关的技巧与注意事项。
一、算法原理深度优先搜索通过递归或者栈的方式实现,主要思想是从图的一个节点开始,尽可能地沿着一条路径向下深入,直到无法继续深入,然后回溯到上一个节点,再选择其他未访问的节点进行探索,直到遍历完所有节点为止。
二、应用场景深度优先搜索算法在信息学竞赛中有广泛的应用,例如以下场景:1. 图的遍历:通过深度优先搜索可以遍历图中的所有节点,用于解决与图相关的问题,如寻找连通分量、判断是否存在路径等。
2. 剪枝搜索:在某些问题中,深度优先搜索可以用于剪枝搜索,即在搜索的过程中根据当前状态进行一定的剪枝操作,提高求解效率。
3. 拓扑排序:深度优先搜索还可以用于拓扑排序,即对有向无环图进行排序,用于解决任务调度、依赖关系等问题。
4. 迷宫求解:对于迷宫类的问题,深度优先搜索可以用于求解最短路径或者所有路径等。
三、算法实现技巧在实际应用深度优先搜索算法时,可以采用以下的一些技巧和优化,以提高算法效率:1. 记忆化搜索:通过记录已经计算过的状态或者路径,避免重复计算,提高搜索的效率。
2. 剪枝策略:通过某些条件判断,提前终止当前路径的搜索,从而避免无效的搜索过程。
3. 双向搜索:在某些情况下,可以同时从起点和终点进行深度优先搜索,当两者在某个节点相遇时,即可确定最短路径等。
四、注意事项在应用深度优先搜索算法时,需要注意以下几点:1. 图的表示:需要根据实际问题选择合适的图的表示方法,如邻接矩阵、邻接表等。
2. 访问标记:需要使用合适的方式标记已经访问过的节点,避免无限循环或者重复访问造成的错误。
3. 递归调用:在使用递归实现深度优先搜索时,需要注意递归的结束条件和过程中变量的传递。
4. 时间复杂度:深度优先搜索算法的时间复杂度一般为O(V+E),其中V为节点数,E为边数。
深度优先搜索的基本原理
深度优先搜索的基本原理深度优先搜索是一种常用的搜索算法,它的主要思想是沿着搜索空间中的可能路径以深度优先的方式搜索整个空间,而不是广度优先的方式。
深度优先搜索可以用来解决多种种类的问题,包括最短路径,最大收益,最小化损失等等。
本文将对深度优先搜索的原理及应用进行简要介绍。
一、深度优先搜索原理深度优先搜索(Depth-FirstSearch,DFS)是一种搜索算法,它受到树的结构性质的启发,在给定的搜索空间中以深度优先的方式搜索整个空间,而不是广度优先的方式,也就是说,从一个节点出发之后,探索它的所有可能的路径,直到找到目标状态为止。
深度优先搜索的步骤分为以下几步:1.首先,在搜索空间中选择一个节点作为起点,并把它标记为处理过;2.然后,搜索深度优先,如果当前节点有直接相连的节点,则把它也标记为处理过,并选择一个未标记节点作为当前节点,重复上述步骤;3.最后,如果找到了目标状态,则结束搜索,否则,回退到尚未访问过的节点,重新开始搜索。
二、深度优先搜索的应用深度优先搜索可以应用于多种类的问题,其中最常用的是给定搜索空间中最短路径的搜索。
比如导航问题,给定搜索空间,从出发点到目标点,深度优先搜索可以帮助我们在最短的时间里找到最短路径。
深度优先搜索也可以应用于最大收益的搜索,比如深度优先搜索可以应用于棋盘游戏的最佳路径搜索,它可以帮助我们找到棋盘游戏中最大收益的路径。
另外,深度优先搜索也可以用来搜索最小化损失的路径。
三、深度优先搜索的优势1.深度优先搜索可以快速地找到最短路径,它可以帮助我们节省问题解决中的很多时间;2.深度优先搜索也可以应用于最大收益的搜索,比如棋盘游戏等;3.它不需要记录太多的搜索状态,从而提高搜索的效率;4.深度优先搜索不需要考虑太多的约束条件,并且也并不需要在搜索空间中记录太多的信息,使得搜索问题更加易于理解。
四、深度优先搜索的不足1.深度优先搜索只能从当前节点出发,很容易陷入死胡同,因此,有时候可能会导致搜索的中断或无法从死胡同出发,直至搜索完全空间;2.它只能找到单条最优路径,而不能找到整个搜索空间中的最优路径;3.深度优先搜索的空间复杂度较高,因此它的执行效率较低,在处理高维空间的问题时,它的效率就更低了。
算法描述的三种方法
算法描述的三种方法
1. 深度优先搜索算法:
通过递归的方式遍历图或树的每个节点,先访问当前节点,然后依次递归访问当前节点的每个邻接节点。
该算法使用栈来记录遍历的节点顺序。
示例:
对于以下图结构,初始节点为A:
A ->
B -> D
| |
V V
C E
通过深度优先搜索算法的结果为:A -> B -> D -> E -> C
2. 广度优先搜索算法:
通过迭代的方式遍历图或树的每个节点,先访问当前节点的所有邻接节点,然后将邻接节点加入队列尾部,依次访问队列中的节点。
该算法使用队列来记录遍历的节点顺序。
示例:
对于以下图结构,初始节点为A:
A ->
B -> D
| |
V V
C E
通过广度优先搜索算法的结果为:A -> B -> C -> D -> E
3. 贪心算法:
在每一步选择中,贪心算法选择当前状态下最优的选择,不考虑未来的后果。
贪心算法通常用于求解最优解问题,但并不
能保证一定能得到全局最优解。
示例:
如果要在一组物品中选择总重量不超过背包容量的物品,可以用贪心算法选择具有最高价值重量比的物品放入背包,直到背包无法再放入物品为止。
但是这种选择方式并不一定能得到真正的最优解。
c++ 深搜 dfs 教学设计
C++深搜(DFS)教学设计一、概述深度优先搜索(DFS)是一种常用的图算法,可用于解决许多实际问题,如路径搜索、图的连通性、拓扑排序等。
在C++编程语言中,深度优先搜索算法被广泛应用,因此对于学习C++编程的学生来说,掌握DFS算法是至关重要的。
二、教学目标1. 理解深度优先搜索算法的原理和基本概念2. 能够编写C++程序实现深度优先搜索算法3. 掌握DFS算法在实际问题中的应用和解决方法三、教学内容1. 深度优先搜索算法的基本原理- 深度优先搜索是一种通过递归或者栈结构来实现的算法- 深度优先搜索适用于解决图的连通性、路径搜索等问题2. C++中深度优先搜索算法的实现- 采用递归方式实现DFS算法- 采用栈结构实现DFS算法3. 深度优先搜索算法在实际问题中的应用- 图的连通性判断- 图的遍历和路径搜索- 拓扑排序等4. 代码演示和实例分析- 通过具体的案例对DFS算法进行演示和分析- 展示如何在C++中实现DFS算法,并解决实际问题四、教学方法1. 理论讲解结合实例分析:通过教师讲解和实例分析,让学生理解DFS算法的基本原理和实现方式。
2. 代码演示和实践操作:通过实际代码演示和让学生动手编写代码,加深学生对DFS算法的理解和掌握程度。
3. 课堂练习和作业布置:布置相关的课堂练习和作业,让学生独立完成DFS算法的实现和应用。
五、教学步骤1. 教师讲解深度优先搜索算法的基本原理和C++实现方式2. 通过具体案例演示DFS算法的应用和实现3. 让学生进行课堂练习和实践操作,编写DFS算法相关的代码4. 教师进行作业布置,让学生独立完成关于DFS算法的编程作业5. 教师对学生作业进行批改和指导,巩固学生对DFS算法的理解和运用六、教学评估1. 课堂讨论和提问:通过课堂讨论和提问,检测学生对DFS算法的理解程度2. 作业和实践操作:通过学生的作业和实践操作情况,评估学生对DFS算法的掌握情况3. 实际应用能力评估:通过实际案例的分析和解决,考察学生对DFS 算法在实际问题中的应用能力七、教学资源1. 教学课件:包括DFS算法的基本原理、C++实现等方面的内容2. 相关书籍和资料:提供给学生相关的C++编程和算法书籍或资料3. 网络资源和代码示例:引导学生利用网络资源和代码示例,加强对DFS算法的学习和理解八、教学反思通过对DFS算法的教学设计和实施,学生可以较好地掌握C++编程语言中深度优先搜索算法的实现和应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
当前方向入栈 x = xx,y = yy //前进一步 在地图上将 x,y 坐标标记为走过的路 判断结束 循环结束
下面贴出完整代码,比较长,做好心理准备。
public class DFS { //辅助方法:打印地图
if (map[yy][xx]==2) { d[step] = dir; System.out.println("找到出口"); break;
} if (map[yy][xx]!=0) {
//撞墙了或遇到走过的路 continue; } else { //记录当前方向 d[step] = dir; dir = 0; map[y][x] = 3; //堵回头路 x = xx; y = yy; step++; } } while (true); //下面为结果输出 System.out.println("一共走了" + step + "步!");
终于要说到代码实现了,深度优先搜索的原理不难理解,但要用代码实现,也有点小难度, 下面对各个难点进行说明:
1, 地图(迷宫)的表示 一般可以使用整形二维数组描述地图,0 代表空地,1 代表墙,2 代表出口,3 代表走过的路。 有点浪费内存,但是易于理解。 2, 下一步选择(方向)的表示 一般使用连续的整形,如表示“上下左右”四个方向就可用 1,2,3,4 来代替 3, 记录每一步选择(毛线) 上一章说过,可以使用栈或者一维数组进行记录
公主送毛线自然不是要教夫君打毛衣,而是指导他:“把线头系于迷宫入口处,一路放线 团,一边进入到迷宫,杀掉牛头怪,再循着线团走出迷宫”。
果然,忒修斯按照公主的方法顺利走到了迷宫中央,经过一番搏斗杀死了牛头怪,并沿 着毛线退出了迷宫。按理说后续应该是个大团圆的结局:忒修斯回到王国迎娶公主,三两年 后国王病逝忒修斯继承王位,于是国王与王后过上了幸福的生活。
}
public static void main(String[] args) {
//初始化地图,数组中 1 代表墙,0 代表路,2 是出口,3 是走过的路
[][] map = {
{1,1,1,1,1,1,1,1,1,1},
{1,0,0,0,0,0,0,0,0,2},
{1,0,1,0,1,0,1,1,1,1},
第一幅图是简单的迷宫,左下角是入口,右上角是出口,接下来为方便演示,我们按照“右 上左下”的优先级顺利来进行探索(即遇到岔路先选择走右面,不行选择上面,然后是左面, 下面)。
图中的线条相当于毛线,记录这每一步的选择
因为先走右边,很快就走到了右下角,右边不能再走了,下一个选择是上边。上到顶发现 右边、上边都不能再走了,选择左边,往前走发现到了死胡同,上下左都不能走,右边是走 过的也不能走,该怎么办呢?
今天来说说深度优先搜索,属于搜索回朔类的算法,相对比较有趣。 关于这个算法的最早传说出现在古希腊时代:
没落贵族的忒修斯(没落到被选为了祭品),爱上了残暴国王弥诺斯的女儿阿里阿德涅 公主,而未来的岳父却决定把可怜的忒修斯送到克里特岛喂牛头怪。
这个特里克岛可是国王的呕心沥血之作,岛上最著名的建筑就是地下迷宫,据说被扔进 去了谁都绕不出来,就算你运气好,找到正确的路,还有一头凶猛的牛头怪养在必经之路上, 送到岛上作为祭品的人从来没能活着回来。
不过古希腊的剧作家个个都是苦大仇深,不爱写大团圆的结尾,一般都要主人公死光光 或落下终身残疾才成。这个故事的详细结局可以自行搜索,反正可怜的算法大师、深度优先 搜索算法的缔造者阿里阿德涅公主最后跳入大海喂鲨鱼了。
这个故事大家在小时候肯定都或多或少的知道,现在我们作为一名算法爱好者,应该考 虑一个在原著中被忽略的很重要的细节:为什么一团毛线,就可以让忒修斯顺利的找到牛 头怪,并能成功返回迷宫出口呢?
第四幅图就不用多上了,按照“右上左下”的优先顺序,很快找到了出口。 练习时间:请使用深度优先搜索原理走完下面的迷宫
注意:每次在岔路口选择都必须按照原则进行(不一定非要是“右上左下”,也可以是“上 下左右”),不能人为的做出判断。
下面是我用画笔绘制的将行走过程模拟图
静态图片可能无法完全说明问题,强烈建议读者自己用画笔来画一画。 经过这个练习,你会发现,使用深度优先算法找到的一般并不是最短的路径,但它保证 可以找到一条路径(如果迷宫没有问题的话),如果你坚持要找最短的,后面的广度优先算 法会满足你的要求,这是后话。现在故事讲了、原理分析了、图也画了,该真刀真枪的上代 码了, 请见下回分解。
x = startX; y = startY; map[y][x] = d[0] + 10; for (int i = 0; i <= step; i++) {
if (d[i]==1) x++; if (d[i]==2) y--; if (d[i]==3) x--; if (d[i]==4) y++; map[y][x] = d[i]+10; } printArray(map); } }
变态的特里克岛,但现在是旅游胜地
按常理忒修斯也难逃厄运,但后来的故事印证了两个亘古不变的真理:1,女人是不可靠 的,女儿也不例外 2,穷小子要翻身,就得靠女人
在忒修斯出发前,小伙子费劲脑汁与阿里阿德涅公主又见了最后一面,在这次历史性的 会晤中,公主送给了穷小伙两件足以挽救其性命的礼物:一团毛线和一把据说唯一能杀死牛 头怪的剑。
请大家思考,吃午饭去了,回来再写。
接着讨论这个问题:“为什么一团毛线,就可以让忒修斯顺利的找到牛头怪,并能成功返回 迷宫出口呢?”
事实上,如果只有毛线是不可能的,至少无法保证忒修斯顺利找到牛头怪!
当你在迷宫中遇到讨厌的岔路时,毛线只能让你知道回去该走哪条路,却无法告诉前方 该如何选择。毛线只能保证忒修斯可以全身而退,却无法指引牛头怪的方向。
{1,0,1,0,1,0,1,0,0,1},
{1,1,1,1,1,0,1,1,0,1},
{1,0,0,0,0,0,0,1,0,1},
{1,1,1,1,1,1,0,1,0,1},
{1,1,1,1,1,1,0,1,0,1},
{0,0,0,0,0,0,0,0,0,1},
{1,1,1,1,1,1,1,1,1,1}
输出结果:略,大家可以自己运行一下。
现在我写这些代码算比较轻松了,但回想 N 年前刚学习深度优先时,虽然理论上明白了, 但是代码死活也整合不到一块儿去,动不动就数组下标越界或者死循环,希望大家练习这部 分代码的时候一定要有耐心,再加上细心。
深度优先搜索的应用:第一种应用自然是走迷宫啦,上一章列出的代码是寻找一条有效 的路径,深度优先也可以穷举出迷宫中所有的路径。只需要在每次找到迷宫出口时,不要结 束程序,而继续回溯,就可以继续寻找其他走出迷宫的办法,直到变量 step 为 0,程序退出。 你可以记录每一种走法的路径长度(step),最后得到最优解。
private static void printArray(int m[][]) { int v = 0; for (int y=0;y<10;y++) { for (int x = 0;x<10; x++) { v = m[y][x]; if (v==0) System.out.print(" "); if (v==1) System.out.print("■■"); if (v==2) System.out.print("XX"); if (v==3) System.out.print(" "); if (v==11) System.out.print("->"); if (v==12) System.out.print("^^"); if (v==13) System.out.print("<-"); if (v==14) System.out.print("vv"); } System.out.println(); }
这当然不能怪毛线,作为一团没有任何智能的妇女用品,它只能做到这一步了。
那可怜的忒修斯在迷宫中面对每一处岔路,是如何选择正确方向的呢?很遗憾,在大多 数情况下,他并没能做出正确的选择,但也没有像前人一样迷失在迷宫中被饿死,而是最终 找到了牛头怪并铲除了它!人和人的差距为什么这么大捏??因为在出发前,阿里阿德涅公 主在他耳边悄悄的说了一个口诀。
唯一的选择就是沿着毛线退回到上一个路口重新做出选择,先退到路口 A,刚才在路口 A 选择的方向是左边,下一个选择是下边,可下边是走过的不能走,只能继续后退。
退到路口 B,刚才在路口 B 选择的是上边,下一个选择是左边,不行,再下一个是下边, 也不行,继续后退。
退到路口 C,刚才在路口 C 选择的是右边,下一个选择是上边,可以走,ok,掉转方向, let's go。
int startX = 0, startY = 8; //迷宫的入口坐标
int x = startX ,y = startY;
int xx=0, yy=0;
//开始进入迷宫 do {
dir++; //试探下一个方向 if (dir>4) {
//回朔 if (step==0) {
System.out.println("地图没有出口!"); return; } dir = d[step-1]; //取出上一次的方向 //沿着反方向后退一步 if (dir==1) x--; if (dir==2) y++; if (dir==3) x++; if (dir==4) y--; step--; continue; } //按照方向前进一步 xx = x; yy = y; if (dir==1) xx++; if (dir==2) yy--; if (dir==3) xx--; if (dir==4) yy++;