集成学习 boosting与bagging
机器学习中的集成学习算法

机器学习中的集成学习算法一、集成学习简介集成学习(Ensemble Learning)是机器学习中的一种重要算法。
它的主要思想是将多个弱学习算法集合起来形成一个强学习算法。
二、集成学习分类按照分类器的生成方式可将集成学习分类为Bagging算法、Boosting算法和Stacking算法。
1. Bagging算法Bagging全称为Bootstrap AGGregating,是自举聚合的缩写。
它的基本思想是采用自助法来产生k个新的训练集,在每个训练集上训练出一个基学习器,然后将这k个基学习器的结果进行平均或多数表决等方式来得到最终的结果。
2. Boosting算法Boosting算法基本思想是将一系列弱分类器相互结合,构成一个强分类器的过程。
它的主要特点是每一轮都学习一个新的分类器,并使得之前所有分类器的分类准确率加权相加。
3. Stacking算法Stacking算法是一种用来组合多个学习器的方法。
与传统的集成学习方法不同,Stacking算法通过加入一个“次级学习器”来对多个基学习器进行组合,从而构建出一个强学习器。
三、集成学习的优点1. 集成学习可显著提高机器学习算法的准确率和性能,并且对于许多不同类型的学习算法均有效。
2. 集成学习能够减轻模型过拟合问题,提高模型鲁棒性和泛化能力。
3. 集成学习能够减少各个单个模型产生的误差或者偏差,从而提高模型的精度。
四、集成学习案例1. 随机森林(Random Forest)随机森林是一种集成学习方法,它基于决策树算法创建多个随机子集的基学习器,最终将这些基学习器合并成一个强学习器。
2. AdaBoostAdaBoost是一种常见的Boosting算法,它通过不断调整训练样本的权重来训练机器学习模型,从而提高模型准确率。
3. Gradient Boosting Machines(GBM)GBM也是一种常见的Boosting算法,它采用一种梯度下降算法来学习弱学习器的加权。
集成式学习
集成式学习1.1什么是集成式学习 (boosting and bagging)集成式学习是基于这样一种思想:对于一个复杂任务来说,将多个专家的判断进行适当的综合所得出的判断,要比其中任何一个专家单独的判断好。
通俗点说,就是“三个臭皮匠顶个诸葛亮”。
其中所说的专家相当于一个分类器,但面临某一个复杂的问题时,单一的分类器未必能将问题有效的解决。
我们把这种分类器称之为若分类器,一般说来弱分类器只给出比随机猜测好一点的一个分类结果。
面对这种复杂的问题,我们又无法轻松的找到一个强分类器,因此一个自然的想法就是能不能利用多个这种弱分类器构成出某种强分类器。
这便是集成学习的思想。
我们用e表示一个弱分类器的错误概率,因为弱分类只比随机猜测强一点,因此e<0.5,但e又和我们期望的错误率相差较远。
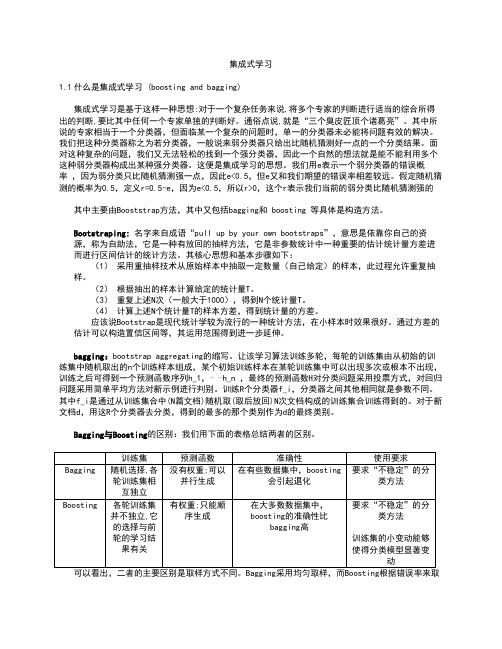
假定随机猜测的概率为0.5,定义r=0.5-e,因为e<0.5,所以r>0,这个r表示我们当前的弱分类比随机猜测强的其中主要由Booststrap方法,其中又包括bagging和boosting 等具体是构造方法。
Bootstraping:名字来自成语“pull up by your own bootstraps”,意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法。
其核心思想和基本步骤如下:(1)采用重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样。
(2)根据抽出的样本计算给定的统计量T。
(3)重复上述N次(一般大于1000),得到N个统计量T。
(4)计算上述N个统计量T的样本方差,得到统计量的方差。
应该说Bootstrap是现代统计学较为流行的一种统计方法,在小样本时效果很好。
通过方差的估计可以构造置信区间等,其运用范围得到进一步延伸。
bagging:bootstrap aggregating的缩写。
机器学习基础—集成学习Bagging和Boosting

机器学习基础—集成学习Bagging和Boosting集成学习就是不断的通过数据⼦集形成新的规则,然后将这些规则合并。
bagging和boosting都属于集成学习。
集成学习的核⼼思想是通过训练形成多个分类器,然后将这些分类器进⾏组合。
所以归结为(1)训练样本数据如何选取?(2)分类器如何合并?⼀、baggingbagging 通过将全部数据集中均匀随机有放回的挑选部分数据,然后利⽤挑选出的数据训练模型,然后再随机挑选部分数据训练⼀个新的模型,经过多次选择,形成多个模型,把每⼀个模型的值加权取平均就是bagging。
所以baging (1)样本数据均匀随机有放回的选取。
(2)分类器取均值。
左边这幅图,随机有放回的取5个数据,取五次,⽤三阶多项式拟合出5条曲线,看以看出这五条曲线基本上符合图像上点的⾛势。
右边这幅图红⾊的曲线是⽤bagging实现的,蓝⾊的曲线是⽤四阶多项式实现的。
在训练集上蓝⾊的拟合度优于红⾊,但是在测试集上红⾊要由于蓝⾊。
可以看出baggin⽅法有很强的泛化能⼒。
⼆、boostingboosting 不再均匀随机的挑选数据了,⽽是把重点放在那些不易进⾏分类的数据上或者是分错的数据上,增加分错样本的权值,然后再进⾏训练,经过多次样本数据选择,哪些最难分类的权值会不断增⼤,直到被分类正确。
将形成的多个分类器进⾏投票,分类类别选择票数最多的那个。
boosting (1)调整权值,选择分错的样本。
(2)分类器合并采取投票的⽅式。
要理解boosting中如何增加分错样本的权重必须了解“误差”的概念。
误差:在已知样本分布的情况下,某⼀个样本x上的假设和真实值间不⼀致的概率。
如上⾯这幅图,有四个点,分别出现的频率是1/2,1/20,4/10,1/20,所以由上⾯误差的概念,分错的概率为1/10。
所以样本出现的频率会影响误差,也就是样本的分布会随着权值的变化⽽变化。
相⽐我们已经分对的样本,分错的样本获得正确结果的概率就越⾼。
bagging,boosting,stacking基本流程

bagging,boosting,stacking基本流程
以下是bagging、boosting、stacking三种集成学习方法的流程:
1. Bagging:
从原始样本集中使用Bootstraping方法随机抽取n个训练样本,共进行k 轮抽取,得到k个训练集(k个训练集之间相互独立,元素可以有重复)。
对于抽取的k个训练集,可以训练出k个模型。
对于分类问题,由投票表决产生的分类结果。
2. Boosting:
对训练集中的每个样本建立权值wi,表示每个样本的权重。
在随后的运算中,对于被错误分类的样本,权重会在下一轮的分类中获得
更大的权重。
对于误差率较小的弱学习器,加大权值,使其在表决中起到更大的作用。
对于误差率较大的弱学习器,减小权值,使其在表决中起到较小的作用。
Boosting算法基于错误提升模型性能,根据前面分类器分类错误的样本,调整训练集中各个样本的权重,构建新的分类器。
其训练过程是呈阶梯状的,后一个基模型会在前一个基模型的基础上进行学习,最终以某种综合方式,比如加权法,对所有模型的预测结果进行加权来产生最终的结果。
3. Stacking:
将训练数据D划分为两个不相交的子集D1,D2。
用训练集的第一部分D1训练多个不同的基模型。
将多个基模型用于预测训练集的第二部分D2。
将基模型的预测结果当作输入,D2的样本标签当作学习目标,训练一个高层的模型。
以上是三种集成学习方法的基本流程,请注意这些方法各有特点,适用于不同的情况和问题类型。
在实际应用中需要根据具体需求和数据特点来选择合适的方法。
机器学习算法中的集成学习方法

机器学习算法中的集成学习方法在机器学习领域中,我们需要选取一种合适的算法来解决问题。
但是,不同的算法特点各不相同,会存在着一定的优劣势。
为了提高算法的精度和鲁棒性,我们通常会采用集成学习方法来将多个算法进行融合,使其形成一个更强大的整体。
集成学习方法是通过将多个基学习器组合起来来构建一个更强大的学习器,在实现具体应用时,它可以使得精度更高、泛化能力更强。
在本文中,我们将介绍几种常见的集成学习方法,并探究它们的优缺点。
1. Bagging方法Bagging是集成学习中最基础的一种方法。
它常用于解决一些对分类器模型较为敏感的问题。
Bagging的思路是通过对数据集进行有放回的随机重抽样(Bootstrap),选出一些新的训练集,然后使用这些新的训练集分别训练出多个基学习器。
这些基学习器之间是独立的,它们的结果可以通过简单平均、投票等方式进行集成。
Bagging方法的优点在于它减小了单个基学习器的方差,提高了整体模型的泛化能力。
同时,Bagging可以降低过拟合的风险,降低了模型的误差。
但是,Bagging的缺点在于,它无法降低单个基学习器的偏差,可解决的问题类型也相对较少。
2.Boosting方法Boosting是Bagging方法的一种改进。
它也是通过多个基学习器的组合来实现模型的优化,但与Bagging不同的是,Boosting是通过加强那些被之前的模型错误分类,并将其重点关注的数据实例,从而提高他们被正确分类的概率。
多次训练权值分布不同的基学习器,再对基学习器进行线性组合,并对错误分类的数据增加权重,形成一个新的基学习器。
重复这一过程,直到测试数据集的精度达到要求。
Boosting方法的优点在于它可以提高单个基学习器的准确性,降低误差和偏差。
同时,它也可以通过加重错误数据的权重来降低模型对样本的误差。
但是 Boosting方法的缺点在于它对噪音数据比较敏感,在面对噪声数据时,模型的性能往往会明显下降。
机器学习技术中的Bagging与Boosting算法比较

机器学习技术中的Bagging与Boosting算法比较Bagging和Boosting是机器学习中常用的集成学习方法,它们通过将多个弱学习器组合成一个强学习器,提高了模型的性能表现。
虽然这两种方法都属于集成学习,但它们采取不同的策略来组合弱学习器,本文将对Bagging和Boosting算法进行比较。
首先,我们来了解Bagging算法(Bootstrap aggregating)。
Bagging算法通过对训练集进行有放回的随机采样,生成多个自助采样集(bootstrap sample)。
然后,使用这些采样集分别训练多个基学习器。
最后,通过对基学习器的预测结果进行投票或平均等方式得到最终的集成模型。
典型的Bagging方法有随机森林(Random Forest)。
Bagging算法的优势在于通过平均多个基学习器的预测结果,能够减小模型的方差,从而提高模型的泛化能力。
此外,由于每个基学习器使用的数据集是独立的,并行化计算的效率较高。
接下来,我们转到Boosting算法。
Boosting算法的思想是通过迭代地训练多个基学习器,每个基学习器都根据先前学习器的表现进行调整。
迭代的过程主要分为两个步骤:加权(Weighting)和重采样(Resampling)。
在每一轮迭代中,加权过程根据上一轮的错误率为当前样本分配权重,即增加错误分类样本的权重,减小正确分类样本的权重。
这样能够让模型对错误分类的样本更加关注。
而在重采样过程中,根据样本的权重,对训练集进行有放回的采样,使得在下一轮迭代中,那些高权重的错误分类样本被选中。
Boosting算法最终通过将多个基学习器进行线性加权组合得到集成模型。
典型的Boosting算法有AdaBoost和Gradient Boosting。
相对于Bagging算法,Boosting算法在处理难样本(hard example)上表现更为出色。
因为Boosting算法能够不断地调整样本的权重,使得在迭代过程中模型更加关注于错误分类的样本,并且以此提高分类效果。
集成学习方法
集成学习方法集成学习是一种通过结合多个模型来完成学习任务的机器学习方法。
它通过整合多个模型的预测结果,从而获得更加准确和稳定的预测结果。
集成学习方法已经在各种机器学习任务中取得了显著的成功,包括分类、回归、特征选择等。
集成学习方法的核心思想是“三个臭皮匠赛过诸葛亮”。
即使单个模型可能存在局限性,但通过结合多个模型的预测结果,可以弥补单个模型的不足,从而获得更加鲁棒和准确的预测结果。
在实际应用中,集成学习方法通常能够取得比单个模型更好的性能。
目前,集成学习方法主要分为两大类,bagging和boosting。
bagging方法通过随机抽样的方式训练多个模型,然后将它们的预测结果进行平均或投票。
这样可以降低模型的方差,从而提高整体的预测准确度。
而boosting方法则是通过迭代训练的方式,每一轮训练都会根据上一轮的结果调整样本的权重,从而逐步提高模型的准确度。
除了bagging和boosting,还有一些其他的集成学习方法,比如stacking和blending。
这些方法都有各自的特点和适用场景,可以根据具体的任务选择合适的集成学习方法。
在实际应用中,集成学习方法已经被广泛应用于各种领域。
比如在金融领域,可以利用集成学习方法来进行信用评分和风险控制;在医疗领域,可以利用集成学习方法来进行疾病诊断和预测;在电商领域,可以利用集成学习方法来进行用户行为分析和推荐系统。
总的来说,集成学习方法是一种强大的机器学习方法,它能够通过整合多个模型的预测结果,从而获得更加准确和稳定的预测结果。
在实际应用中,可以根据具体的任务选择合适的集成学习方法,并结合领域知识和数据特点来进行模型的构建和优化。
希望本文对集成学习方法有所帮助,谢谢阅读!。
机器学习中的集成学习模型
机器学习中的集成学习模型机器学习是现代技术发展中的重要领域之一。
其应用范围广泛,包括图像识别、语音识别、自然语言处理等多个领域。
在机器学习的过程中,集成学习(Ensemble Learning)模型被认为是最常用和最有效的一种方法。
本文将对机器学习中的集成学习模型进行介绍和讨论。
集成学习模型是指使用多个学习算法来解决同一个问题。
这些算法可能各自独立地产生预测结果,然后将这些预测结果进行集成,形成最终的预测结果。
与单个学习算法相比,集成学习模型更能够减少预测误差,因为它可以利用多个算法的优势,对潜在的误差进行互补和抵消。
集成学习模型可分为三种类型:Bagging、Boosting和Stacking。
我们将对这些类型的集成学习模型进行详细介绍。
BaggingBagging模型全称为Bootstrap Aggregating,其主要思想是重取样法。
在这种模型中,每个学习算法将独立地从原始数据集中进行重取样,以便在每个样本集上训练不同的模型。
这样,我们可以利用多个模型来解决一个问题。
在集成的过程中,每个独立模型的输出将被合并以获得最终的预测。
BoostingBoosting模型基于"加强"(boost)的思想,它的目的是通过每次迭代来提高预测精度。
在Boosting中,学习算法通过迭代的方式逐步进行训练,每次迭代都会加入强化因子,以纠正前一次训练期间的预测误差。
这种方式可以有效地增强每个模型的性能,最终得到更准确的预测结果。
StackingStacking是不同于前两种模型的一种技术。
在这种情况下,基本上有两种类型的学习算法:一种是将训练数据分成几份,每份使用不同的算法处理,然后将结果合并,作为最终结果。
另一种则是将不同的算法组合在一起,使用某种形式的"元学习器"来合并它们的预测结果。
尽管这三种集成学习模型在实践中各有优缺点,但在大多数机器学习问题中,它们都被广泛使用。
集成学习算法与单个模型的比较研究论文素材
集成学习算法与单个模型的比较研究论文素材集成学习算法与单个模型的比较研究引言:在机器学习领域,集成学习算法是一种将多个单独的模型集成起来以获得更好性能的方法。
通过将多个模型的预测结果进行组合,集成学习算法能够减少模型的偏差,提高性能。
本文将介绍几种常见的集成学习算法,并对它们与单个模型在不同数据集上的表现进行比较。
一、集成学习算法的概述集成学习算法主要分为两大类:bagging和boosting。
Bagging算法是基于自助采样的集成学习方法,通过对原始数据进行有放回的采样,生成多个训练集。
然后针对每个训练集分别建立模型,并将它们的预测结果进行平均或投票来获得最终的预测结果。
Boosting算法则是一种迭代的集成学习方法,它通过逐步调整样本权重,使得模型能够更关注分错的样本。
Boosting算法会针对每个模型的错误进行加权,以纠正之前模型的错误,最终将多个模型进行线性组合。
二、集成学习算法的应用集成学习算法在众多领域中都有广泛的应用。
在分类问题中,集成学习算法能够提高预测准确率,并降低过拟合风险。
在回归问题中,集成学习算法能够通过组合多个模型来提高预测精度。
此外,在异常检测、聚类分析等问题中,集成学习算法也取得了较好的效果。
三、集成学习算法的性能比较实验为了评估集成学习算法和单个模型的性能,我们在多个数据集上进行了实验比较。
我们选择了常用的决策树算法作为单个模型,以及常用的Random Forest和Adaboost算法作为集成学习算法。
实验结果显示,在绝大多数数据集上,集成学习算法的性能要优于单个模型。
在某些数据集上,集成学习算法甚至提升了10%以上的准确率。
这表明通过集成多个模型,我们可以获得更好的预测性能。
此外,我们还对集成学习算法的模型复杂度和运行时间进行了分析。
结果显示,集成学习算法相对于单个模型而言,模型更为复杂,运行时间也更长。
这是因为集成学习算法需要训练多个模型,并进行预测结果的组合。
机器学习中的模型融合方法
机器学习中的模型融合方法机器学习是一门非常重要的学科,涉及到了众多的方法和技术。
其中,模型融合方法是一种常用的技术,用于提高机器学习模型的性能和泛化能力。
本文将介绍几种常见的机器学习中的模型融合方法。
一、集成学习集成学习是一种常用的模型融合方法。
它的基本思想是将多个弱学习器集成在一起,形成一个强学习器,从而提高模型的性能。
常见的集成学习方法包括投票方法、bagging和boosting。
1. 投票方法投票方法是一种简单而有效的集成学习方法。
它的思想是通过结合多个模型的预测结果进行投票,最终选择预测结果最多的类别作为最终的预测结果。
投票方法适用于分类问题,在实际应用中较为常见。
2. BaggingBagging是一种基于自助采样技术的集成学习方法。
它的思想是通过对训练集进行多次有放回的采样,产生多个不同的训练集,然后用这些训练集分别训练出多个模型,再将这些模型的预测结果进行平均或投票,得到最终的预测结果。
Bagging方法可以降低模型的方差,提高模型的泛化能力。
3. BoostingBoosting是一种迭代的集成学习方法。
它的基本思想是通过训练多个弱学习器,每个弱学习器都试图修正前一个弱学习器的错误,最终将这些弱学习器进行加权结合。
Boosting方法可以提高模型的准确率,特别适用于处理复杂的数据集和任务。
二、深度学习中的模型融合方法深度学习是机器学习的一个重要分支,近年来在众多领域取得了重大突破。
在深度学习中,模型融合方法也起到了关键的作用。
下面介绍几种常见的深度学习中的模型融合方法。
1. 神经网络融合神经网络融合是一种常用的深度学习模型融合方法。
它的思想是通过将多个神经网络进行融合,获得更好的预测性能。
常见的神经网络融合方法包括平均融合、投票融合和学习融合等。
2. 迁移学习迁移学习是一种将已经学习好的模型迁移到新的任务上的方法。
它的思想是通过使用已经学习好的模型生成的特征来辅助新任务的学习。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
( x1 , y1 ), ( x2 , y2 ), ..., ( xn , yn )
Step 2: 初始化权值
1 1 , for yi 0,1, 2m 2l m 和 l分别为正样本和负样本的个数。 w1,i
For t = 1, … , T 1. 归一化权值, wt ,i
wt ,i
n j 1
图像 Step 1: 训练集
TheHAdaBoost算法 J ( )为此特征集合的目标函数值,
m
( x1 , y1 ), ( x2 , y2 ), ... , ( xm , ym )
正样本 =1 负样本=-1 Step 2: 初始化权值 Step 3: 弱分类器训练
min J m 是目前m个特征构成的集合义一个若分类器h j ( x),其学习算法如下: 1, if Pj f j ( x) Pj j h j ( x) 其他 0 其中, j 是阈值 Pj 取不同符号改变不等号方向
弱分类器训练 图示说明
训练集
归一化权重
w1
fj
特征
w2
fj fj
• AdaBoost.M1 和 AdaBoost.M2 是用来解决 多分类单标签问题
Step 1: 训练集
AdaBoost.M1 算法
Step 2: 初始化权值
( x1 , y1 ), ( x2 , y2 ), ..., ( xn , yn )
w1,i
1 for yi 0,1, 2n
For t = 1, … , T 1. 归一化权值,
h( x) t 1 0
t t
2
t 1
t
t
j wi | h j ( xi ) yi |
t
others
i
选择有最小错误率 t的若分类器ht。
M Wt ( xi )exp(t yi ht ( xi )) 3. 更新权值: Wt 1 ( xi ) , Zt 是使Wt 1 ( xi )的归一化因子。 Zt i1
wt ,i
wt ,i
n j 1
wt , j
2. 对于第j个特征,在给定权值条件下训练若分类器 hj ,若分类器的分类错误率为:
j wi | h j ( xi ) yi |
i
如果 t 1/ 2, 设T t 1, 退出循环
3. 更新权值:
End 最终的强分类器:
w , wt 1,i wt ,i t1ei t ,i t wt ,i
Boosting and bagging算法
1 Boosting 算法
• Boosting 算法是近十年最有效的算法之一,其主要代表算 法有Adaboost算法和 AdaBoost算法改进等。(记单词) • AdaBoost算法基本思想:
对同一个训练集使用不同的特征训练出不同的弱分类器 , 然后 将这些弱分类器组合起来 , 提升为一个分类能力更强的强分类器 。 算法是通过数据分布的改变来实现的,根据每次弱分类器训练集 中每个样本的分类正确与否,及上次总体分类的准确率,对每个样本 的权值进行调整,降低弱分类器中分类正确的样本的权值,提高弱分 类器分类错误的样本的权值。修改过权值的新数据表集作为下层分类 器的训练集,经过多次迭代得到相应的弱分类器,对训练得到的这些 弱分类器进行融合 , 得到最终的强分类器 。
Step 1: 训练
( x1 , y1 ), ( x2 , y2 ), ..., ( xn , yn )
Bagging算法
Step 2: 初始化权值
For t = 1, … , T 1. S’ 为从给定训练集S中,随机抽样(有放回). 2. 在S’ 上训练弱学习器,得到第t 轮的预测函数 ht . 3. t = t + 1 .
如果样本被正确分类 其他
t
t 1 t
h( x)= argmax log t
yY t 1...T
Floatboost 算法
• 向前增加一个弱分类器之后,就需要向后 回馈r。r的取值取决于当前分类性能的稳定 性。这种弱分类器选择的方法相对于前向 搜索来说具有更大的灵活性,因此,增加 弱分类器组合的多样性,相比AdaBoost中 的单调搜索有更优的解集合。
级联 AdaBoost
1 2
AdaBoost
h1
Feature Select & Classifier 特征集
T
h1
T
n
AdaBoost
h2
AdaBoost
h10
h1 h2
more
100% Detection Rate 50% False Positive
False
False
非人脸
False
离散AdaBoost-AdaBoost.M1
最终的强分类器
AdaBoost 学习算法 用于特征选择
24
大约有
180,000 个矩形特征
24
弱分类器训练图示说明
f j (x)
如果 fj(x) > X 是脸部图像
False positive
j wi | h j ( xi ) yi |
i
ex
hj ( xi ) 1
False negative
如果样本被正确分类 其他
t
t 1 t
1 T 1 1 t ht ( x) 2 t (t ln ) h( x) t 1 t 1 t 0 others
T
AdaBoost 人脸检测
特征计算
Haar Basis Functions 特征提取
wn
每幅图像大约有180,000 个特征
fj
误差
1 2 3
h1 h2 h3
更新权值
min
ht
180,000
h180,000
j wi | h j ( xi ) yi |
i
选出最小误差 t , 分类器ht
w1
错误
w2
正确
wi
正确
wn
错误
wt 1,i wt ,i
t 1 t
4.
min 设h' arg min,为 M 最小特征集合,若J(H M )(为漏检率与虚警率的加权和)<Jm , hH m
则删掉此特征,当J(H M )低于预测值或循环次数大于预定值M时,停止循环。
最终的预测函数:
H ( x)sign( hm ( x))
m 1
M
2 bagging算法
原始图像
Haar Basis Functions Haar Basis Functions
大量的特征
级联结构 小部分特征训练
特征选择
Ada Boost 训练
AdaBoost 应用于分类
特征集
学习处理
各种各样的特征
若分类器 1 若分类器 2 若分类器3
人脸 非人脸 最终的强分类器
训练集 +1 正样本 -1 负样本
1.1 AdaBoost系列
• 应用AdaBoost系列主要解决了:两类问题、 多类单标签问题、多类多标签问题、大类 单标签问题,回归问题。它用全部的训练 样本进行学习。
• 注:一般无特别说明,boosting都是指AdaBoost算法
Step 1: 训练集
图像 正样本 =1 负样本=-1
The AdaBoost 算法
wt , j
2. 对于第j个特征,在给定权值条件下训练弱分类器 hj ,弱分类器的分类错误率为:
j wi | h j ( xi ) yi |
i
选择有最小错误率 t的若分类器ht。
3. 更新权值:
End 最终的强分类器:
wt 1,i wt ,i
1 ei t
wt ,i t , wt ,i
• Bagging算法的主要思想:
• 给定训练集 S (( x1, y1 ),( x2 , y2 ),...( xn , yn )) 和弱学 习算法,对该学习算法进行T次调用,每次调 用时只使用训练集S中的某个子集作为当前训 练集,每一个训练例在某轮训练集中可以多 次或根本不出现。经过T次调用后,可得到T 个不同的分类器啊,当对于一个测试实例工 进行分类时,分别调用这T个分类器,得到T 个分类结果。最后对分类问题把这T个分类结 果中出现次数多的类赋予测试实例x。
End 最终输出: 对未知样本X分类时,每个模型 ht 得到一个分类器, 得票最高的未知样本x 的分类
Bagging 和 AdaBoost 区别
• Bagging的训练集是随机的,各训练集是独的, 而Boosting训练集的选择不是独立的,每一次选 择的训练集都依赖于上一次学习的结果。 • Bagging的每个预测函数(即弱假设)没有权重,而 Boosting根据每一次训练的训练误差得到该次预 测函数的权重。 • Bagging的各个预测函数可以并行生成,而 Boosting的只能顺序生成。对于像神经网络这样 极为耗时的学习方法,Bagging可通过并行训练 节省大量时间开销。
wt (i )
1 min , i 1,...m;J m =max-value(t=1,...,Max),M=0 m
For t = 1, … , T 1. 每个弱分类器h,在权值下进行训练,得到预测函数 ht . T 1 T 2. 计算误判率,选取参数at: ln 1 ) h ( x) ( 1