数据结构复习提纲
数据结构复习提纲

《数据结构》复习提纲参考书:《数据结构》(C语言版)严蔚敏吴伟民编著清华大学出版社考试范围:第一章~第七章、第九章~第十章第1章绪论什么是数据结构;基本概念和术语,数据结构分类;抽象数据类型的表示和实现;逻辑结构、存储结构异同;算法和算法分析包括:算法、算法设计的要求、算法效率的度量、算法的存储空间需求第2章线性表线性表的类型定义,掌握基本概念。
线性表的顺序表示和实现线性表的链式表示和实现线性链表、循环链表、双向链表第3章栈和队列栈和队列的基本概念和基本操作栈抽象数据类型栈的定义栈的表示和实现栈的应用举例队列抽象数据类型队列的定义链队列——队列的链式表示和实现循环队列——队列的顺序表示和实现顺序表示和实现第4章串串类型的定义串的表示和实现定长顺序存储表示堆分配存储表示串的块链存储表示第5章数组和广义表数组的定义数组的顺序表示和实现矩阵的压缩存储特殊矩阵稀疏矩阵及三元组表示广义表的定义及其存储结构第6章树和二叉树掌握数和二叉树的基本概念和基本操作树的定义和基本术语二叉树二叉树的定义二叉树的性质二叉树的存储结构遍历二叉树树和森林树的存储结构森林与二叉树的转换树和森林的遍历赫夫曼树及其应用第7章图图的定义和术语图的存储结构数组表示法邻接表十字链表邻接多重表图的遍历深度优先搜索广度优先搜索图的连通性问题无向图的连通分量和生成树最小生成树有向无环图及其应用拓扑排序关键路径最短路径第9章查找静态查找表顺序表的查找有序表的查找索引顺序表的查找动态查找表二叉排序表和平衡二叉树B_树和B+树哈希表第10章内部排序了解、掌握各种排序方法的大致思路插入排序直接插入排序其它插入排序希尔排序快速排序选择排序简单选择排序树形选择排序堆排序C语言考试大纲C语言程序设计的考试内容一、C语言程序的结构1.程序的构成,main函数和其他函数。
2.头文件、数据说明、函数的开始和结束标志以及程序中的注释。
3.源程序的书写格式。
4.C语言的风格。
数据结构复习提纲(整理)

复习提纲第一章数据结构概述基本概念与术语(P3)1.数据结构是一门研究非数值计算程序设计问题中计算机的操作对象以及他们之间的关系和操作的学科.2.数据是用来描述现实世界的数字,字符,图像,声音,以及能够输入到计算机中并能被计算机识别的符号的集合2.数据元素是数据的基本单位3.数据对象相同性质的数据元素的集合4.数据结构包括三方面容:数据的逻辑结构.数据的存储结构.数据的操作. (1)数据的逻辑结构指数据元素之间固有的逻辑关系.(2)数据的存储结构指数据元素及其关系在计算机的表示( 3 ) 数据的操作指在数据逻辑结构上定义的操作算法,如插入,删除等. 5.时间复杂度分析--------------------------------------------------------------------------------------------------------------------1、名词解释:数据结构、二元组2、根据数据元素之间关系的不同,数据的逻辑结构可以分为集合、线性结构、树形结构和图状结构四种类型。
3、常见的数据存储结构一般有四种类型,它们分别是___顺序存储结构_____、___链式存储结构_____、___索引存储结构_____和___散列存储结构_____。
4、以下程序段的时间复杂度为___O(N2)_____。
int i,j,x;for(i=0;i<n:i++) n+1for(j=0;j<n;j++) n+1x+=i;------------------------------------------------------------------------------------------------------------------第二章线性表1.顺序表结构由n(n>=0)个具有相同性质的数据元素a1,a2,a3……,an组成的有穷序列//顺序表结构#define MAXSIZE 100typedef int DataType;Typedef struct{DataType items[MAXSIZE];Int length;}Sqlist,*LinkList;//初始化链表void InitList(LinkList *L){(*L)=(LinkList)malloc(sizeof(LNode));if(!L){cout<<”初始化失败!”;return;}(*L)->next=NULL;}//插入数据void InsertList(LinkList L,int pos,DataType x){LinkList p=L,q;int i=0;while(p&&i<pos-1){p=p->next;i++;}if(!p||i>pos-1){cout<<”插入位置错误”;return;}InitList(&q);q->next=p->next;p->next=q;q->data=x;}//销毁链表void DestoryList(LinkList L){LinkList t;while(L){t=L;L=L->next;free(t);}}//遍历链表void TraverseList(LinkList L){LinkList t=L;while(L){t=t->next;cout<<t->data<<” ”;}cout<<endl;}//删除元素void DeleteList(LinkList L,int pos){LinkList p=L,q;int i=0;while(p&&i<pos-1){p=p->next;i++;}if(!p||i>pos-1){cout<<”删除位置错误!!”;return;}q=p->next;p->next=q->next;free(q):}第三章栈和队列1.栈(1)栈的结构与定义(2)顺序栈操作算法:入栈、出栈、判断栈空等(3)链栈的结构与定义2.队列(1)队列的定义----------------------------------------------------------------------------------------------------------------1、一个栈的入栈序列为“ABCDE”,则以下不可能的出栈序列是()A. BCDAEB. EDACBC. BCADED. AEDCB2、栈的顺序表示仲,用TOP表示栈顶元素,那么栈空的条件是()A. TOP==STACKSIZEB. TOP==1C. TOP==0D. TOP==-13、允许在一端插入,在另一端删除的线性表称为____队列____。
(完整word版)数据结构复习提纲

数据结构复习提纲复习内容:基本概念掌握:数据结构,逻辑结构,存储结构;数据类型;算法;T(n),S(n)的理解。
要学习的数据结构定义形式:n(n〉=0)个数据元素的有限集合.将约束:1、数据元素本身.2、数据元素之间的关系。
3、操作子集。
大多有两种存储(表示、实现)方式:1、顺序存储。
2、链式存储.一、线性结构:1、线性表:n(n〉=0)个相同属性的数据元素的有限序列。
12种基本操作.顺序表:9种基本操作算法实现.单链表:11种基本操作算法实现。
(重点:插入、删除)顺序表与单链表之时间性能、空间性能比较.循环链表:类型定义与单链表同。
算法实现只体现在循环终止的条件不同。
双向链表:重点插入、删除算法。
2、操作受限的线性表有:栈、队列。
栈:顺序栈;链栈(注意结点的指针域指向)。
(取栈顶元素、入栈、出栈)队列:循环队列(三个问题的提出及解决);链队列(注意头结点的作用).(取队头元素、入队、出队。
链队列中最后一个元素出队)3、数据元素受限的线性表有:串、数组、广义表。
串:定长顺序存储;堆分配存储.块链存储(操作不方便)数组:顺序存储。
特殊矩阵的压缩存储;稀疏矩阵(三元组表示、十字链表)广义表:长度、深度.取表头(可以是原子也可以是子表);取表尾(肯定是子表)。
链式存储。
二、树型结构:1、树:n(n>=0)个数据元素的有限集合.这些数据元素具有以下关系:……。
(另有递归定义。
)术语;存储(双亲表示、孩子表示、孩子双亲表示、孩子兄弟表示)。
2、二叉树:n(n〉=0)个数据元素的有限集合。
这些数据元素具有以下关系:……。
(另有递归定义)5个性质(理解、证明;拓展)。
遍历二叉树(定义、序列给出、递归算法、非递归算法);遍历二叉树应用:表达式之前序表达式、后序表达式、中序表达式转换。
线索二叉树(中序线索二叉树)。
树森林与二叉树的转换。
树与森林的遍历.赫夫曼树及其应用:定义、构造、赫夫曼编码。
三、图形结构:n(n〉=0)个数据元素的有限集合。
数据结构复习资料复习提纲知识要点归纳

数据结构复习资料复习提纲知识要点归纳数据结构复习资料:复习提纲知识要点归纳一、数据结构概述1. 数据结构的定义和作用2. 常见的数据结构类型3. 数据结构与算法的关系二、线性结构1. 数组的概念及其特点2. 链表的概念及其分类3. 栈的定义和基本操作4. 队列的定义和基本操作三、树结构1. 树的基本概念及定义2. 二叉树的性质和遍历方式3. 平衡二叉树的概念及应用4. 堆的定义和基本操作四、图结构1. 图的基本概念及表示方法2. 图的遍历算法:深度优先搜索和广度优先搜索3. 最短路径算法及其应用4. 最小生成树算法及其应用五、查找与排序1. 查找算法的分类及其特点2. 顺序查找和二分查找算法3. 哈希查找算法及其应用4. 常见的排序算法:冒泡排序、插入排序、选择排序、归并排序、快速排序六、高级数据结构1. 图的高级算法:拓扑排序和关键路径2. 并查集的定义和操作3. 线段树的概念及其应用4. Trie树的概念及其应用七、应用案例1. 使用数据结构解决实际问题的案例介绍2. 如何选择适合的数据结构和算法八、复杂度分析1. 时间复杂度和空间复杂度的定义2. 如何进行复杂度分析3. 常见算法的复杂度比较九、常见问题及解决方法1. 数据结构相关的常见问题解答2. 如何优化算法的性能十、总结与展望1. 数据结构学习的重要性和难点2. 对未来数据结构的发展趋势的展望以上是数据结构复习资料的复习提纲知识要点归纳。
希望能够帮助你进行复习和回顾,加深对数据结构的理解和掌握。
在学习过程中,要注重理论与实践相结合,多进行编程练习和实际应用,提高数据结构的实际运用能力。
祝你复习顺利,取得好成绩!。
数据结构(复习提纲)【整理】

2010年复习提纲第一章数据、数据结构的概念;基本逻辑结构的种类;集合线性树形图状基本存储方式的种类;顺序链式散列索引算法、算法的时间复杂度以及其计算。
算法的五大特性:输入输出确定性有穷性有效性时间复杂度的计算:忽略常数与中间变量,循环套循环用乘法第二章线性表的概念;顺序存储和链接存储的线性表的数据结构、特性;顺序存储的特性:查找方便,不易扩充链接存储的特性:插入删除方便顺序存储和链接存储的线性表的基本算法:创建、插入、查找、删除等;链表的其他形式(带表头、循环、双向、双向循环等)的概念及基本算法(与一般链表的不同处)。
带表头:便于其后结点执行标准化操作循环:首尾相接双向:既可以查找前继又可以查找后继双向循环:结合以上两点链表逆转;第二章相关算法列举如下1.。
顺序线性表的插入Int sq_insert(int list[],int *p_n,int i,int x) { Int j;If(i<0||i>*p_n) return(1);If(*p_n==MAXSIZE) return(2);For(j=*p_n;j>I;j--)List[j]=list[j-1];List[i]=x;(*p_n)++;Return(0);} 2.顺序线性表的删除Int sq_delete(int list[],int *p_n,int i) {Int j;If(i<0||i>=*p_n) return(1);For(j=i+1;j<*p_n;j++)List[j-1]=list[j];(*p_n)--;Return(0);}3.链式线性表的创建NODE *create_link_list(int n){ int i;NODE *p,*q;NODE *p_head;if(n==0) return(NULL);p_head=new(NODE);p_head->data=-1;p=p_head;for(i=1;i<=n;i++){printf("请输入第%d个节点的值\n",i);q=new(NODE);scanf("%d",&(q->data));p->link=q;p=q;}q->link=NULL;return(p_head);/*返回的是假头*/ ※4.链式线性表的插入(i之后)Int insert(NODE* *p_head,int i,int a) { int n=0;NODE *p,*q,*r;p=*p_head;if(i<1) return(0);while((p!=NULL)&&(n<i)){If(p->data!=-1) n++;q=p;p=p->link;}r=new(NODE);r->data=a;r->link=q->link;q->link=r;}※5.链式线性表的删除int del(NODE* *p_head,int I) { NODE *p,*q;int n=0;p=*p_head;if(i<1) return(0);while((p!=NULL)&&(n<i)){If(p->data!=-1) n++;q=p;p=p->link;}if(p==NULL) return(0);q->link=p->link;delete(p);return(1);} 6.单链表的逆置NODE * reverse(NODE *head) {NODE *p,*q;P=head->next;Head->next=NULL;While(p){Q=p->next;p->next=head->next;head->next=p;p=q;}return(head);}7.试写一高效的算法,删除表中所有大于mink且小于maxk的元素Void Delete_between(int a[],int mink,int maxk){p=L;while(p->next->data<=mink) p=p->next;(本循环结束时p是最后一个不大于mink的元素)if(p->next)(如果还有比mink更大的元素){q=p->next;while(q->data<maxk) q=q->next;(本循环结束时q 是第一个不小于maxk 的元素)p->next=q;}}第三章栈与队列的概念;栈:只允许在一端进行插入和删除的线性表队列:只允许在一端进行插入,且只允许在另一端进行删除的线性表顺序栈和链栈的数据结构与基本算法;顺序队列(尤其是循环队列)和链队列的数据结构与基本算法;栈的应用算法;如何判断顺序栈的空与满、如何判断循环队列的空与满;判断顺序栈的空与满:若top的初始值是-1 则判空条件是if(top==-1) 判满条件是if(top==MAXN)若top的初始值是0 则判空条件是if(top==0) 判满条件是if(top==MAXN-1)判断循环队列的空与满{Head=0,tail=0;判断循环队列的空与满的条件都是if(head==tail)}中缀表达式与后缀表达式规则以及两者间的转换。
数据结构_(严蔚敏C语言版)_学习、复习提纲.
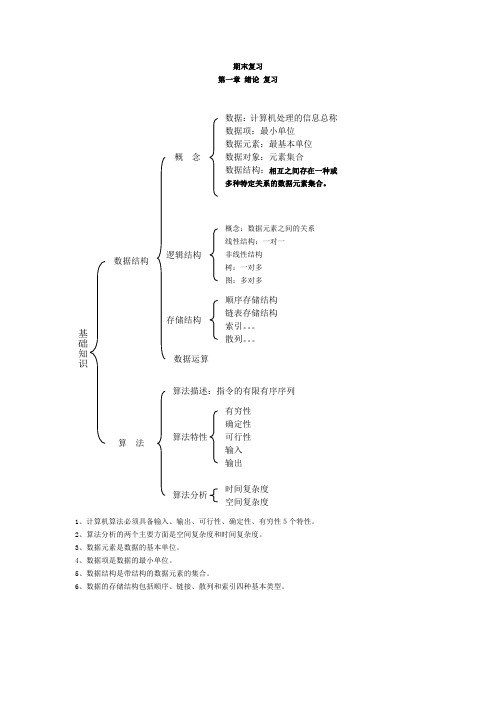
期末复习 第一章 绪论 复习1、计算机算法必须具备输入、输出、可行性、确定性、有穷性5个特性。
2、算法分析的两个主要方面是空间复杂度和时间复杂度。
3、数据元素是数据的基本单位。
4、数据项是数据的最小单位。
5、数据结构是带结构的数据元素的集合。
6、数据的存储结构包括顺序、链接、散列和索引四种基本类型。
基础知识数据结构算 法概 念逻辑结构 存储结构数据运算数据:计算机处理的信息总称 数据项:最小单位 数据元素:最基本单位数据对象:元素集合数据结构:相互之间存在一种或多种特定关系的数据元素集合。
概念:数据元素之间的关系 线性结构:一对一非线性结构 树:一对多 图:多对多顺序存储结构 链表存储结构 索引。
散列。
算法描述:指令的有限有序序列算法特性 有穷性 确定性 可行性 输入 输出 算法分析时间复杂度 空间复杂度第二章 线性表 复习1、在双链表中,每个结点有两个指针域,包括一个指向前驱结点的指针 、一个指向后继结点的指针2、线性表采用顺序存储,必须占用一片连续的存储单元3、线性表采用链式存储,便于进行插入和删除操作4、线性表采用顺序存储和链式存储优缺点比较。
5、简单算法第三章 栈和队列 复习线性表顺序存储结构链表存储结构概 念基本特点基本运算定义逻辑关系:前趋 后继节省空间 随机存取 插、删效率低 插入 删除单链表双向 链表 特点一个指针域+一个数据域 多占空间 查找费时 插、删效率高 无法查找前趋结点运算特点:单链表+前趋指针域运算插入删除循环 链表特点:单链表的尾结点指针指向附加头结点。
运算:联接1、 栈和队列的异同点。
2、 栈和队列的基本运算3、 出栈和出队4、 基本运算第四章 串 复习栈存储结构栈的概念:在一端操作的线性表 运算算法栈的特点:先进后出 LIFO初始化 进栈push 出栈pop队列顺序队列 循环队列队列概念:在两端操作的线性表 假溢出链队列队列特点:先进先出 FIFO基本运算顺序:链队:队空:front=rear队满:front=(rear+1)%MAXSIZE队空:frontrear ∧初始化 判空 进队 出队取队首元素第五章 数组和广义表 复习串存储结构运 算概 念顺序串链表串定义:由n(≥1)个字符组成的有限序列 S=”c 1c 2c 3 ……cn ”串长度、空白串、空串。
数据结构复习提纲

复习提纲:第一章:1.数据结构的基本概念;2.数据结构的4类基本结构及其特性;3.存储结构的分类及特点;4.算法的时间复杂度计算;第二章:1.线性表的基本概念;2.线性表的顺序存储结构的特点和插入删除算法;3.顺序存储结构的应用;4.单循环链表的存储结构特点,链表空的判断方法、插入、删除结点算法实现,报数游戏算法实现;5.双链表的存储特点,插入、删除结点算法实现。
第三章:1.栈的特点、对同一序列根据栈的特点进行不同入栈、出栈操作所得结果的判断;栈的实现的相关操作;2.顺序栈的4各要素和相关操作关键语句;链栈的4个要素和相关操作关键语句;3.了解队列的特点和可执行的基本操作,并能做相关判断;4.顺序循环队列的队空、队满判断条件,入队、出队操作的相关关键语句;5.顺序循环队列中对同一序列根据队列进行不同的入队、出队操作后队头和队尾指针的变化判断。
第四章:1.串的定义、串长的定义和计算、子串个数计算(注意区分:子串与非空且不同于S本身的子串);2.串的模式匹配(区分BF算法和KMP算法),掌握使用KMP算法计算next数组的值,并且要求掌握匹配过程(BF和KMP的匹配过程不同!)。
前三章程序重点掌握作业四、作业五、作业六、作业八、作业九第五章:1.特殊矩阵的压缩存储地址计算,稀疏矩阵的压缩存储结构图。
2.广义表的定义、区分原子和子表,求表头和表尾,深度和层次计算,存储结构图绘制;3.提供一广义表,写出通过head()和tail()操作求出某个原子的表达式。
4.注意:取表头时即广义表的第一个元素,外面不再加括号;而取表尾时,要将除表头元素外的其他元素一起用圆括号括起来,即将原广义表去掉表头;第六章:1.树的定义和相关基本术语;2.树的表示和各种存储结构的表示;3.二叉树的定义和结点形态;4.熟练使用二叉树的性质进行相关计算;5.掌握提供边集画树及树的存储结构图并将树转换为二叉树;6.根据后序遍历和中序遍历的序列画出二叉树直观图,并给出其先序遍历的序列,画出线索二叉树存储结构图;7.根据二叉树的顺序存储结构图,画出二叉树及二叉链存储结构图,并给出该二叉树转换后的森林。
数据结构复习提纲

数据结构复习提纲一、线性表线性表是最基本的数据结构之一,它是具有相同数据类型的 n 个数据元素的有限序列。
1、顺序表定义和特点:顺序表是用一组地址连续的存储单元依次存储线性表的数据元素。
存储结构:通常使用数组来实现。
基本操作:插入、删除、查找、遍历等。
时间复杂度分析:插入和删除操作在平均情况下的时间复杂度为O(n),查找和遍历操作的时间复杂度为 O(n)。
2、链表定义和特点:链表是通过指针将各个数据元素链接起来的一种存储结构。
单链表:每个节点包含数据域和指针域,指针域指向链表的下一个节点。
双链表:节点包含两个指针域,分别指向前驱节点和后继节点。
循环链表:尾节点的指针指向头节点,形成一个环形结构。
基本操作:插入、删除、查找等。
时间复杂度分析:插入和删除操作在平均情况下的时间复杂度为O(1),查找操作的时间复杂度为 O(n)。
二、栈和队列1、栈定义和特点:栈是一种限制在一端进行插入和删除操作的线性表,遵循“后进先出”的原则。
存储结构:顺序栈和链栈。
基本操作:入栈、出栈、栈顶元素获取等。
应用:表达式求值、括号匹配、函数调用等。
2、队列定义和特点:队列是一种在一端进行插入操作,在另一端进行删除操作的线性表,遵循“先进先出”的原则。
存储结构:顺序队列和链队列。
基本操作:入队、出队、队头元素获取等。
循环队列:解决顺序队列“假溢出”问题。
应用:层次遍历、消息队列等。
三、串1、串的定义和存储方式定长顺序存储堆分配存储块链存储2、串的基本操作串的赋值、连接、比较、求子串等。
3、模式匹配算法朴素的模式匹配算法KMP 算法:理解其原理和计算 next 数组的方法。
四、数组和广义表1、数组数组的定义和存储结构数组的地址计算特殊矩阵的压缩存储(如对称矩阵、三角矩阵、稀疏矩阵)2、广义表广义表的定义和表示广义表的递归算法1、树的基本概念定义、术语(如节点、度、叶子节点、分支节点、父节点、子节点、兄弟节点、层次等)树的性质2、二叉树定义和特点二叉树的性质完全二叉树和满二叉树3、二叉树的存储结构顺序存储链式存储4、二叉树的遍历先序遍历中序遍历后序遍历层序遍历5、二叉树的递归和非递归遍历算法实现线索化的目的和方法7、树、森林与二叉树的转换8、哈夫曼树定义和构造方法哈夫曼编码六、图1、图的基本概念定义、术语(如顶点、边、权、有向图、无向图、邻接矩阵、邻接表等)2、图的存储结构邻接矩阵邻接表十字链表邻接多重表3、图的遍历深度优先搜索(DFS)广度优先搜索(BFS)4、图的应用最小生成树(Prim 算法、Kruskal 算法)最短路径(Dijkstra 算法、Floyd 算法)拓扑排序关键路径七、查找1、查找的基本概念关键字、平均查找长度等2、顺序查找算法实现时间复杂度3、折半查找算法实现时间复杂度判定树4、分块查找5、二叉排序树定义和特点插入、删除操作查找算法6、平衡二叉树定义和调整方法7、 B 树和 B+树结构特点基本操作8、哈希表哈希函数的构造方法处理冲突的方法(开放定址法、链地址法等)八、排序1、排序的基本概念排序的稳定性2、插入排序直接插入排序折半插入排序希尔排序3、交换排序冒泡排序快速排序4、选择排序简单选择排序堆排序5、归并排序6、基数排序7、各种排序算法的时间复杂度、空间复杂度和稳定性比较。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
软件学院数据结构与算法复习提纲(2011秋季学期)1、Data structures and algorithms概念:Type: 类型(Type)是一组值的集合。
simple type:不含子结构的类型是简单类型(simple type)composite type, aggregate type: 一个类型里含有多项信息(子结构)的类型是复杂类型(aggregate)或组合类型(composite)data type:数据类型是指一种类型和定义在该类型上的一组操作ADT:抽象数据类型(ADT)是指数据结构作为一个软件组件的实现data structure:数据结构是ADT的实现problems:从直觉上讲,问题无非是一个需要完成的任务,即一组输入就有一组相应的输出function:函数(function)是输入和输入(定义域domain)和输出(值域range)之间的一种映射关系algorithms:算法(algorithms)是解决问题的一种方法或一个过程programs:一个计算机程序被认为是某种程序设计语言对一种算法的具体实现。
2、Mathematical preliminaries概念:Set:集合(set)是由互不相同的成员(member)和元素(element)构成的一个整体。
Sequence:序列(sequence)是一个具有顺序的元素组,并且可以有重复的元素,有时也称为元组(tuple)或向量(vector)。
Recursion:如果一种算法调用自己来完成它的部分工作,就称为这种算法是递归的(recursion)。
3、Algorithm Analysis概念:Asymptotic algorithm analysis:渐进算法分析(简称算法分析algorithm analysis)可以估算当问题规模变大时,一种算法及实现它的程序的功率和开销。
Growth rate:算法增长率(Growth rate)只当输入的值增长的时候,算法代价和增长速率。
Best/worst/average case:执行同一个算法达到目的最快/最慢/平均情况的一种输入的情形。
(自己总结)Upper/lower bound:用来表示当某一类数据的输入规模为n时,某种算法消耗某种资源(通常是时间)的最大值/最小值。
Space/time tradeoff:时间/空间权衡原则,Big-Oh/big-Omega/Theta notation:大O表示法,对于非负函数T(n),若存在两个正常数c和n0,对任意n>n0,有T(n)<=cf(n),则称T(n)在集合O(f(n))中。
大欧米伽表示法:若存在若存在两个正常数c和n0,对于n>n0,有T(n)>=cg(n),则称T(n)在集合Ω(g(n))中。
西塔表示法:当上下线相等时,可用Θ表示法,如果一种算法既在O(h(n)) 中,又在Ω(h(n)) 中,则称其为Θ(h(n))。
应用题:The efficiency of different growth rate expressions (see exercise of 3.1 and3.3 in Page 79)4、list概念:List: 线形表(List)是由成为元素的数据项组成的一种有限且有序的数列Array-based list: 顺序表是数组实现的线性表Linked list: 链表是利用指针实现的线性表Ordered/unordered list:有序线性表的元素按照值得递增顺序排列。
无序线性表在元素的值与位置之间没有特殊的联系。
Singly/doubly linked list: 只允许从一个表结点直接访问它的后继结点的链表称单链表。
可以从一个表结点出发,在线性表中随意访问它的前驱结点和后继结点的链表成为双链表。
Array:Stack: 栈(stack)是仅在一端进行插入或删除操作的线性表Queue: 队列(Queue)是一种受限的线性表,只能从队尾插入(称为入栈操作enqueue)以及从队首删除(称为出栈操作)。
算法:用list/stack/queue实现一些操作,比如:排序、括号匹配检查等5、binary trees概念:BST:二叉查找树(Binary Search Tree)是满足对于任意一个节点,设其值为K,则该结点左子树中任意一个结点的值都小于K,右子树中任意一结点的值都大于或等于K的二叉树。
A VL:A VL树是具有如下附加特性的BST,对于树结构的每个节点,其左右子树的高度最高差1。
Huffman tree:哈弗曼树的每个叶节点对应一个字母,叶节点的权重就是它对应字母的出现频率。
权大的叶节点深度小。
Full/complete binary tree:满二叉树(full binary tree)的每一个结点或者是一个分支节点,并恰有两个非空子节点或者是叶节点。
完全二叉树(Complete binary tree)有严格的形状要求:从根结点起每一层从左到右填充。
Height/depth of a binary tree:结点M的深度(depth)就是从根节点到M的路径的长度。
树的高度等于最深结点的深度加一。
应用题:BST中的插入/删除,A VL的构造,Huffman树的构造,heap的构造,基于遍历序列还原二叉树算法:基于二叉树遍历的各种算法(binary tree traversal,计算二叉树的高度,统计叶子结点个数等)证明题:(1) To any binary tree, if it has n0 leaf node, n2 internal node of degree=2(i.e., has two children), then n0=n2+1(2) The number of empty subtrees in a non-empty binary tree is one more than the number of nodes in the tree.6、general trees概念:Traversal: 按照一定的顺序访问二叉树的结点,成为一次周游或遍历树的先根(前序)周游先访问根结点,再依次从左往右对每棵子树进行先根周游。
树的后根(后序)周游先由左向右依次对每棵子树进行后根周游,再访问根结点。
中根周游对树不具有自然的定义,一般不使用。
Equivalence classes:看懂:traversal/UNION/FIND几个操作的实现思想应用题:根据树的线性表示还原树(例题)证明:The number of leaves in a non-empty full K-ary tree is (K − 1)n + 1, where n is the number of internal nodes.7、internal sorting概念:各种排序算法的best/worst/average case时间复杂度:插入排序,起泡排序,选择排序,时间代价为(Θn2)Shell排序,Θ(n1.5)快速排序,Θ(nlogn)归并排序,Θ(nlogn)堆排序,最差、最优、平均都为Θ(nlogn)分配排序和基数排序,Θ(n),仅能对一个0-n-1的排列进行排序Stable sorting algorithm: 一种排序算法不改变关键码相同的记录的相对顺序,则称算法是稳定的。
应用题:shellsort/bubble sort/quicksort/heapsort/的排序过程8、File processing and external sorting概念:Track/sector/cluster:磁头在一个盘片的某个位置上可以访问的所有数据就构成了一个磁道(Track),即这个盘片上与主轴具有相同距离的所有数据。
每个磁道分为多个扇区(sector),多个扇区通常集结成组,成为簇(cluster),是文件分配的最小单位。
Track:磁道:磁头在一个盘片的某个位置上可以访问到的所有数据构成一个磁道,即这个盘片上与主轴具有相同距离的所有数据。
Sector:扇区。
I/O的基本单位。
Cluster:簇。
多个扇区集结成的组。
簇是文件分配的最小单位。
seek time:移动I/O磁头把它定位到包含数据的磁道上的过程成为寻道,所耗费的时间就是寻道时间。
rotational delay:I/O磁头等待包含数据的扇区旋转到磁头下面所等待的时间成为旋转延迟Interleaving factor:交错因子。
同一磁道上,逻辑上相邻的扇区之间的物理距离称为交错因子locality of reference,引用的局部性。
如果读出了文件的一个扇区,很可能就要读出文件的下一个扇区。
Transfer time: Time for data to move under the I/O head.一个数据移动到i/o磁头下所需的时间Golden Rule of File Processing:使磁盘访问的次数最少logical/physical file: C++程序员把储存在磁盘中可随机访问的文件看成一段连续的字节,并且可以把这些字节结合起来构成记录。
这成为逻辑文件。
世纪初储存在磁盘中的物理文件通常不是一段连续的字节,而是成块的分布在整个磁盘中。
Buffer:一旦读取了一个扇区,就把它的信息储存在主存中,这成为缓冲(buffering)或缓存(chashing)organization of buffer pool:FIFO(First In, First Out):将缓冲区排成一个队列,如果一个缓冲区存储新信息时,就使用队列最前面的缓冲区,然后把它放在队列的最后。
LFU(Least Frequently Used):记录缓冲池中每个缓冲区的访问次数,当需要一个缓冲区重新存储新信息时,使用被访问次数最少的缓冲区。
LRU(Least Recently Used)把缓冲区放到一个链表中,每当访问了一个缓冲区中的信息时,就把这个缓冲区放到链表的最前边;当需要读取新信息时,用链表最后面的缓冲区(最简单、最常用)Locality of reference:如果读出了一个文件的一个扇区,很可能就要读出文件的下一个扇区。
这称为引用的局部性Main idea of external sorting algorithm:外部排序算法的主要目标是尽量减少读、写磁盘的信息量。
Run:在外排序时,被排序的子列成为顺串(Run)9、Searching概念:Hashing:根据关键码值直接访问表。
把关键码值映射到表中的位置来访问记录,这个过程称为散列(hashing)80/20 rule:80/20规则表明80%的访问都是对20%的记录进行的。