Hadoop集群部署方案
Hadoop集群配置详细

Linux系统配置
7安装JDK 将JDK文件解压,放到/usr/java目录下 cd /home/dhx/software/jdk mkdir /usr/java mv jdk1.6.0_45.zip /usr/java/
cd /usr/java
unzip jdk1.6.0_45.zip
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
从当前用户切换root用户的命令如下:
Linux系统配置
操作步骤需要在HadoopMaster和HadoopSlave节点
上分别完整操作,都是用root用户。 从当前用户切换root用户的命令如下:
su root
从当前用户切换root用户的命令如下:
Linux系统配置
1拷贝软件包和数据包 mv ~/Desktop/software ~/
环境变量文件中,只需要配置JDK的路径
gedit conf/hadoop-env.sh
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
Hadoop配置部署
3配置核心组件core-site.xml
gedit conf/core-site.xml
<configuration> <property> <name></name> /*2.0后用 fs.defaultFS代替*/ <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/dhx/hadoopdata</value> </property> </configuration>
Hadoop安装部署手册

1.1软件环境1)CentOS6.5x642)Jdk1.7x643)Hadoop2.6.2x644)Hbase-0.98.95)Zookeeper-3.4.61.2集群环境集群中包括 3个节点:1个Master, 2个Slave2安装前的准备2.1下载JDK2.2下载Hadoop2.3下载Zookeeper2.4下载Hbase3开始安装3.1 CentOS安装配置1)安装3台CentOS6.5x64 (使用BasicServer模式,其他使用默认配置,安装过程略)2)Master.Hadoop 配置a)配置网络修改为:保存,退出(esc+:wq+enter ),使配置生效b) 配置主机名修改为:c)配置 hosts修改为:修改为:在最后增加如下内容以上调整,需要重启系统才能生效g) 配置用户新建hadoop用户和组,设置 hadoop用户密码id_rsa.pub ,默认存储在"/home/hadoop/.ssh" 目录下。
a) 把id_rsa.pub 追加到授权的 key 里面去b) 修改.ssh 目录的权限以及 authorized_keys 的权限c) 用root 用户登录服务器修改SSH 配置文件"/etc/ssh/sshd_config"的下列内容3) Slavel.Hadoop 、Slavel.Hadoop 配置及用户密码等等操作3.2无密码登陆配置1)配置Master 无密码登录所有 Slave a)使用 hadoop 用户登陆 Master.Hadoopb)把公钥复制所有的 Slave 机器上。
使用下面的命令格式进行复制公钥2) 配置Slave 无密码登录Mastera) 使用hadoop 用户登陆Slaveb)把公钥复制Master 机器上。
使用下面的命令格式进行复制公钥id_rsa 和相同的方式配置 Slavel 和Slave2的IP 地址,主机名和 hosts 文件,新建hadoop 用户和组c) 在Master机器上将公钥追加到authorized_keys 中3.3安装JDK所有的机器上都要安装 JDK ,先在Master服务器安装,然后其他服务器按照步骤重复进行即可。
hadoop集群部署之双虚拟机版

1、采用一台机器开两个虚拟机的方式构成两台电脑的环境,用root登录。
分别查看其IP地址:输入# ifconfig,可得主机IP:192.168.1.99;分机为:192.168.1.100。
2、在两台机器上的/etc/hosts均添加相应的主机名和IP地址:这里主机名命名为shenghao,分机名命名为slave:保存后重启网络:3、两台机器上均创立hadoop用户(注意是用root登陆)# useradd hadoop# passwd hadoop输入111111做为密码登录hadoop用户:注意,登录用户名为hadoop,而不是自己命名的shenghao。
4、ssh的配置进入centos的“系统→管理→服务器设置→服务,查看sshd服务是否运行。
在所有的机器上生成密码对:# ssh-keygen -t rsa这时hadoop目录下生成一个.ssh的文件夹,可以通过# ls .ssh/来查看里面产生的私钥和公钥:id_rsa和id_rsa.pub。
更改.ssh的读写权限:# chmod 755 .ssh在namenode上(即主机上)进入.ssh,将id_rsa.pub直接复制为authorized_keys(namenode的公钥):# cp id_rsa.pub authorized_keys更改authorized_keys的读写权限:# chmod 644 authorized_keys 【这个不必须,但保险起见,推荐使用】然后上传到datanode上(即分机上):# scp authorized_keys hadoop@slave:/home/hadoop/.ssh# cd .. 退出.ssh文件夹这样shenghao就可以免密码登录slave了:然后输入exit就可以退出去。
然后在datanode上(即分机上):将datanode上之前产生的公钥id_rsa.pub复制到namenode上的.ssh目录中,并重命名为slave.id_rsa.pub,这是为了区分从各个datanode上传过来的公钥,这里就一个datanode,简单标记下就可。
基于Hadoop的大数据处理平台搭建与部署

基于Hadoop的大数据处理平台搭建与部署一、引言随着互联网和信息技术的快速发展,大数据已经成为当今社会中不可或缺的重要资源。
大数据处理平台的搭建与部署对于企业和组织来说至关重要,而Hadoop作为目前最流行的大数据处理框架之一,其搭建与部署显得尤为重要。
本文将介绍基于Hadoop的大数据处理平台搭建与部署的相关内容。
二、Hadoop简介Hadoop是一个开源的分布式存储和计算框架,能够高效地处理大规模数据。
它由Apache基金会开发,提供了一个可靠、可扩展的分布式系统基础架构,使用户能够在集群中使用简单的编程模型进行计算。
三、大数据处理平台搭建准备工作在搭建基于Hadoop的大数据处理平台之前,需要进行一些准备工作: 1. 硬件准备:选择合适的服务器硬件,包括计算节点、存储节点等。
2. 操作系统选择:通常选择Linux系统作为Hadoop集群的操作系统。
3. Java环境配置:Hadoop是基于Java开发的,需要安装和配置Java环境。
4. 网络配置:确保集群内各节点之间可以相互通信。
四、Hadoop集群搭建步骤1. 下载Hadoop从Apache官网下载最新版本的Hadoop压缩包,并解压到指定目录。
2. 配置Hadoop环境变量设置Hadoop的环境变量,包括JAVA_HOME、HADOOP_HOME等。
3. 配置Hadoop集群编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等,配置各个节点的角色和参数。
4. 启动Hadoop集群通过启动脚本启动Hadoop集群,可以使用start-all.sh脚本启动所有节点。
五、大数据处理平台部署1. 数据采集与清洗在搭建好Hadoop集群后,首先需要进行数据采集与清洗工作。
通过Flume等工具实现数据从不同来源的采集,并进行清洗和预处理。
2. 数据存储与管理Hadoop提供了分布式文件系统HDFS用于存储海量数据,同时可以使用HBase等数据库管理工具对数据进行管理。
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
Hadoop集群部署有几种模式?Hadoop集群部署方法介绍
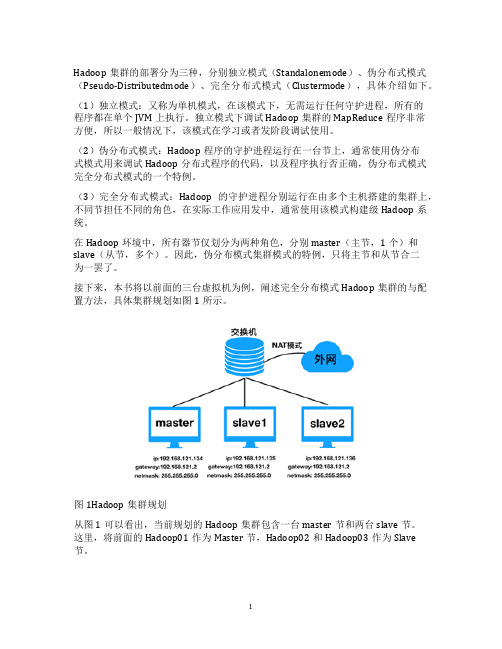
Hadoop集群的部署分为三种,分别独立模式(Standalonemode)、伪分布式模式(Pseudo-Distributedmode)、完全分布式模式(Clustermode),具体介绍如下。
(1)独立模式:又称为单机模式,在该模式下,无需运行任何守护进程,所有的
程序都在单个JVM上执行。
独立模式下调试Hadoop集群的MapReduce程序非常
方便,所以一般情况下,该模式在学习或者发阶段调试使用。
(2)伪分布式模式:Hadoop程序的守护进程运行在一台节上,通常使用伪分布
式模式用来调试Hadoop分布式程序的代码,以及程序执行否正确,伪分布式模式完全分布式模式的一个特例。
(3)完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节担任不同的角色,在实际工作应用发中,通常使用该模式构建级Hadoop系统。
在Hadoop环境中,所有器节仅划分为两种角色,分别master(主节,1个)和slave(从节,多个)。
因此,伪分布模式集群模式的特例,只将主节和从节合二
为一罢了。
接下来,本书将以前面的三台虚拟机为例,阐述完全分布模式Hadoop集群的与配置方法,具体集群规划如图1所示。
图1Hadoop集群规划
从图1可以看出,当前规划的Hadoop集群包含一台master节和两台slave节。
这里,将前面的Hadoop01作为Master节,Hadoop02和Hadoop03作为Slave
节。
1。
大数据集群部署方案

八、风险与应对措施
1.技术风险:关注技术动态,及时更新和升级相关软件。
2.数据安全风险:加强数据安全防护措施,定期进行合规性检查。
3.人才短缺:加强团队培训,提高技能水平。
4.成本控制:合理规划项目预算,控制成本。
九、总结
本方案为企业提供了一套完整、科学的大数据集群部署方案,旨在实现高效、稳定的数据处理和分析。通过严谨的技术选型和部署架构设计,确保数据安全、合规性。同时,注重运维保障和人才培养,提高大数据应用能力。在项目实施过程中,积极应对各类风险,确保项目顺利推进,为企业创造持续的业务价值。
二、项目目标
1.搭建一套完整的大数据集群环境,满足业务部门对数据处理、分析、挖掘的需求。
2.确保集群系统的高可用性、高性能、易扩展性,降低运维成本。
3.遵循国家相关法律法规,确保数据安全与合规性。
三、技术选型
1.分布式存储:采用Hadoop分布式文件系统(HDFS)进行数据存储,确保数据的高可靠性和高可用性。
- Kafka集群:用于收集和传输实时数据,支持实时数据处理。
五、数据安全与合规性
1.数据加密:对存储在HDFS上的数据进行加密,防止数据泄露。
2.访问控制:采用Kerberos进行身份认证,结合HDFS权限管理,实现数据访问控制。
3.数据脱敏:对敏感数据进行脱敏处理,确保数据合规使用。
4.审计日志:开启Hadoop审计日志,记录用户操作行为,便于审计和监控。
- ZooKeeper集群:负责集群的分布式协调服务,确保集群的高可用性。
- Kafka集群:用于收集和传输实时数据,为实时数据处理提供支持。
五、数据安全与合规性
1.数据加密:对存储在HDFS上的数据进行加密处理,防止数据泄露。
Hadoop集群配置心得(低配置集群+自动同步配置)

Hadoop集群配置⼼得(低配置集群+⾃动同步配置)本⽂为本⼈原创,⾸发到炼数成⾦。
情况是这样的,我没有⼀个⾮常强劲的电脑来搞出⼀个性能⾮常NB的服务器集群,相信很多⼈也跟我差不多,所以现在把我的低配置集群经验拿出来写⼀下好了。
我的配备:1)五六年前的赛扬单核处理器2G内存笔记本 2)公司给配的ThinkpadT420,i5双核处理器4G内存(可⽤内存只有3.4G,是因为装的是32位系统的缘故吧。
)就算是⽤公司配置的电脑,做出来三台1G内存的虚拟机也显然是不现实的。
企业笔记本运⾏的软件多啊,什么都不做空余内存也才不到3G。
所以呢,我的想法就是:⽤我⾃⼰的笔记本(简称PC1)做Master节点,⽤来跑Jobtracker,Namenode 和SecondaryNamenode;⽤公司的笔记本跑两个虚拟机(简称VM1和VM2),⽤来做Slave节点,跑Tasktracker和Datanode。
这么做的话,就需要让PC1,VM1和VM2处于同⼀个⽹段⾥,保证他们之间可以互相连通。
⽹络环境:我的两台电脑都是通过⼀个⽆线路由上⽹。
构建跟外部的电脑同⼀⽹段的虚拟机配置过程:准备⼯作:构建⼀个集群,⾸先前提条件是每台服务器都要有⼀个固定的IP地址,然后才可能进⾏后续的操作。
所以呢,先把我的两台笔记本电脑全部设置成固定IP(注意,如果像我⼀样使⽤⽆线路由上⽹,那就要把⽆线⽹卡的IP设置成固定IP)。
⽤来做Master节点的PC1:192.168.33.150,⽤来跑虚拟机的宿主笔记本:192.168.33.157。
⽬标:VM1和VM2的IP地址分别设置成192.168.33.151和152。
步骤:1)新建VM1虚拟机。
2)打开VM1的⽹卡设置界⾯,连接⽅式选Bridge。
(桥接)关于桥接的具体信息,可以百度⼀下。
我们需要知道的,就是⽤桥接的⽅式,可以让虚拟机通过本机的⽹关来上⽹,所以就可以跟本机处于同⼀个⽹段,互相之间可以进⾏通信。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop集群部署方案目录1.网络拓扑 (1)2.软件安装 (1)2.1.修改主机名 (1)2.2.修改host文件 (1)2.3.创建Hadoop 用户 (2)2.4.禁用防火墙 (2)2.5.设置ssh登录免密码 (2)2.6.安装hadoop (4)3.集群配置 (5)3.1.修改脚本 (5)3.1.1................................................ hadoop-env.sh53.1.2................................................... y arn-env.sh53.2.配置文件 (5)3.2.1................................................ core-site.xml53.2.2................................................ hdfs-site.xml73.2.3.............................................. mapred-site.xml103.2.4................................................ yarn-site.xml113.2.5.配置datanode143.3.创建目录 (14)4.启动zk集群 (14)5.启动hadoop (14)5.1.启动所有节点journalnode (14)5.2.格式化h1 namenode (15)5.3.在h1上格式化ZK (15)5.4.启动h1的namenode,zkfc (16)5.5.启动h2上namenode (16)5.6.同步h1上的格式化数据到h2 (16)5.7.启动 HDFS (17)5.8.启动 YARN (18)5.9.启动h2 ResourceManager (18)5.10........................................ h4上启动 JobHistoryServer 195.11.......................................... 查看ResourceManager状态196.浏览器访问 (19)node管理界面 (19)6.1.1............................... http://192.168.121.167:50070196.1.2............................... http://192.168.121.168:50070206.2.ResourceManager管理界面 (20)6.2.1............................... http://192.168.121.167:8088/216.2.2............................... http://192.168.121.168:8088/216.3.JournalNode HTTP 服务 (21)6.3.1............................... http://192.168.121.167:8480/216.4.Datanode HTTP服务 (22)6.4.1.............................. http://192.168.121.167:50075/226.5.jobhistory 管理界面 (22)6.5.1................... http://192.168.121.170:19888/jobhistory227.测试 (23)7.1.上传文件至hdfs (23)7.2.验证hdfs HA (23)7.3.验证yarn (24)1.网络拓扑2.软件安装2.1.修改主机名修改四台机器的主机名,h1,h2,h3,h4查看是否修改成功uname -a2.2.修改host文件修改三台机器/etc/hosts文件配置hadoop节点配置zk节点2.3.创建Hadoop 用户1)创建特定的Hadoop 用户帐号以区分Hadoop 和本机上的其他服务。
sudo groupadd hadoopuseradd hadooppasswd hadoopusermod -a -G hadoop hadoop2)给hadoop用户添加权限,打开/etc/sudoers文件:在root ALL=(ALL) ALL后面添加hadoop ALL=(ALL) ALL2.4.禁用防火墙chkconfig iptables off2.5.设置ssh登录免密码Hadoop 控制脚本(并非守护进程)依赖SSH 来执行针对整个集群的操作。
例如,Namenode是通过SSH(Secure Shell)来启动和停止各个datanode上的各种守护进程的为了支持无缝式工作, SSH 安装好之后,需要允许hadoop 用户无需键入密码即可登陆集群内的机器。
最简单的方法是每个机器创建一个无密码公钥/私钥对1)生成密钥id_dsa.pub为公钥,id_dsa为私钥2)将公钥文件复制成authorized_keys文件3)修改.ssh目录的权限以及authorized_keys 的权限sudo chmod 644 ~/.ssh/authorized_keyssudo chmod 700 ~/.ssh4)测试是否设置成功ssh h15)对h2、h3、h4这几个节点上的hadoop用户也配置ssh,配置过程和上述在h1上一样6)在h2、h3、h4这几个节点上都执行一次“cat ~/.ssh/id_rsa.pub | sshhadoop@h1 'cat >> ~/.ssh/authorized_keys'”命令,将这几个节点上的共钥id_ras.pub拷贝到h1中的authorized_keys文件中拷贝完成后,h1中的authorized_keys文件内容7)将h1中的authorized_keys文件分发到其他节点(h2、h3、h4)上,在hadoop1上,使用scp -r ~/.ssh/authorized_keys hadoop@h1:~/.ssh/ 命令分发8)测试2.6.安装hadoop计算md5值,看文件是否完整sudo tar -zxvf ./hadoop-2.7.3.tar.gz # 解压到/usr/local中sudo mv ./hadoop-2.7.3/ ./hadoop # 将文件夹名改为hadoopsudo chown -R hadoop ./hadoop为了方便,使用hadoop命令或者start-all.sh等命令,修改Master上/etc/profile 新增export HADOOP_HOME=/usr/local/hadoopexport PATH=$PATH:$HADOOP_HOME/binsource /etc/profile使生效3.集群配置3.1.修改脚本3.1.1.hadoop-env.sh$vi hadoop-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_403.1.2.yarn-env.sh$vi yarn-env.shexport JAVA_HOME=/usr/java/jdk1.8.0_403.1.3.hadoop-daemon.sh修改if [ "$HADOOP_PID_DIR" = "" ]; thenHADOOP_PID_DIR=/home/hadoop/tmpfi3.2.配置文件3.2.1.core-site.xml<configuration><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value></property><property><name>fs.defaultFS</name><value>hdfs://cluster</value></property><property><name>fs.trash.interval</name><value>4320</value></property><property><name>fs.trash.checkpoint.interval</name><value>60</value></property><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><property><name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value></property><property><name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value><property><name>ha.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value> </property><property><name>hadoop.security.authorization</name><value>false</value></property></configuration>3.2.2.hdfs-site.xml<configuration><property><name>services</name><value>cluster</value></property><property><name>nodes.cluster</name><value>nn1,nn2</value></property><property><name>node.rpc-address.cluster.nn1</name> <value>h1:8020</value></property><property><name>node.rpc-address.cluster.nn2</name> <value>h2:8020</value><property><name>node.http-address.cluster.nn1</name><value>h1:50070</value></property><property><name>node.http-address.cluster.nn2</name><value>h2:50070</value></property><property><name>node.servicerpc-address.cluster.nn1</name><value>h1:53310</value></property><property><name>node.servicerpc-address.cluster.nn2</name><value>h2:53310</value></property><property><name>node.shared.edits.dir</name><value>qjournal://h1:8485;h2:8485;h3:8485/cluster</value> </property><property><name>dfs.ha.automatic-failover.enabled.cluster</name><value>true</value></property><property><name>dfs.client.failover.proxy.provider.cluster</name><value>node.ha.ConfiguredFailoverP roxyProvider</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property><property><name>dfs.permissions</name><value>false</value></property><property><name>dfs.replication</name><value>2</value></property><property><name>.dir</name><value>file:/usr/local/hadoop/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/dfs/data</value><property><name>dfs.journalnode.edits.dir</name><value>/usr/local/hadoop/dfs/journalnode</value></property></configuration>3.2.3.mapred-site.xml<configuration><property><name></name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>h4:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>h4:19888</value></property><property><name>mapred.job.reuse.jvm.num.tasks</name><value>-1</value></property><property><name>mapreduce.reduce.shuffle.parallelcopies</name> <value>10</value></configuration>3.2.4.yarn-site.xml<configuration><!-- Node Manager Configs --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>hdfs://cluster/var/log/hadoop-yarn/apps</value> </property><!-- Resource Manager Configs --><property><name>yarn.resourcemanager.connect.retry-interval.ms</name><value>2000</value></property><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value><property><name>yarn.resourcemanager.ha.automatic-failover.enabled</name> <value>true</value></property><property><name>yarn.resourcemanager.ha.automatic-failover.embedded</name> <value>true</value></property><property><name>yarn.resourcemanager.cluster-id</name><value>cluster</value></property><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><name>yarn.resourcemanager.hostname.rm1</name><value>h1</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>h2</value></property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair. FairScheduler</value></property><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><property><name>yarn.resourcemanager.zk-address</name><value>node1:2181,node2:2181,node3:2181</value></property><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMSt ateStore</value></property><property><name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</n ame><value>5000</value></property></configuration>3.2.5.配置datanodevi slaves3.3.创建目录mkdir /usr/local/hadoop/dfs/datamkdir /usr/local/hadoop/dfs/namemkdir /usr/local/hadoop/dfs/journalnodemkdir /usr/local/hadoop/tmpmkdir /home/hadoop/tmp4.启动zk集群在zk节点(node1,node2,node3)执行:zkServer.sh start 三个节点都启动后查看状态,一个 leader 两个follower此时执行jps查看进程,启动了QuorumPeerMain5.启动hadoop5.1.启动所有节点journalnode(h1,h2,h3上执行)./hadoop-daemon.sh start journalnode5.2.格式化h1 namenodeh1上执行hdfs namenode -format成功的话,会看到“successfully formatted”和“Exitting with status 0”的提示5.3.在h1上格式化ZK仅第一次需要做,在ZooKeeper集群上建立HA的相应节点,用于保存集群中NameNode的状态数据在h1执行:hdfs zkfc -formatZK5.4.启动h1的namenode,zkfc执行:hadoop-daemon.sh start namenode,hadoop-daemon.sh start zkfc 此时查看进程,zkfc,namenode都启动了5.5.启动h2上namenode5.6.同步h1上的格式化数据到h2h2执行: hdfs namenode -bootstrapStandby5.7.启动 HDFS在h1执行:start-dfs.sh,一键启动所有hdfs进程,包括启动过的进程其他节点上的进程也都启动了也可以单独启动hadoop-daemon.sh start namenode hadoop-daemon.sh start datanode hadoop-daemon.sh start journalnode hadoop-daemon.sh start zkfc5.8.启动 YARN在h1执行:start-yarn.shh3上进程5.9.启动h2 ResourceManageryarn-daemon.sh start resourcemanager5.10.h4上启动 JobHistoryServer执行: mr-jobhistory-daemon.sh start historyserver5.11.查看ResourceManager状态./yarn rmadmin -getServiceState rm16.浏览器访问在windows中访问,某些连接打不开,需要配置host192.168.121.167 h1192.168.121.168 h2192.168.121.169 h3192.168.121.170 h4node管理界面6.1.1.http://192.168.121.167:500706.1.2.http://192.168.121.168:500706.2.ResourceManager管理界面用户可通过该地址在浏览器中查看集群各类信息6.2.1.http://192.168.121.167:8088/6.2.2.http://192.168.121.168:8088/ h2是standby namenode,会自动定向到h16.3.JournalNode HTTP 服务6.3.1.http://192.168.121.167:8480/http://192.168.121.168:8480/http://192.168.121.169:8480/6.4.Datanode HTTP服务6.4.1.http://192.168.121.167:50075/http://192.168.121.168:50075/http://192.168.121.169:50075/http://192.168.121.170:50075/6.5.jobhistory 管理界面6.5.1.http://192.168.121.170:19888/jobhistory7.测试7.1.上传文件至hdfs7.2.验证hdfs HAkill掉h1的namenode查看hadoop fs -ls /,文件还可以正常访问http://192.168.121.167:50070/已经无法访问了http://192.168.121.168:50070/显示变成了active启动kill掉的namenode,变成了standby7.3.验证yarn●添加测试文件●执行map reducehadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2 .7.3.jar wordcount /test /out查看结果。