预测分析程序代码
VBA 数据分析与预测技巧

VBA 数据分析与预测技巧在当今数据驱动的时代,数据分析已经成为许多企业和组织决策的重要组成部分。
作为一种强大的编程语言和工具,VBA (Visual Basic for Applications)在数据分析和预测方面发挥着重要作用。
本文将介绍一些VBA数据分析和预测的技巧,帮助你更好地利用VBA进行数据分析和预测。
1. VBA基础知识在使用VBA进行数据分析和预测之前,我们首先需要了解一些VBA的基础知识。
VBA是一种基于微软Office应用程序的编程语言,包括Excel、Access、Word等。
通过VBA,我们可以使用编程的方式自动化执行一系列的操作,如数据处理、计算、图表生成等。
2. 数据导入和清洗数据分析的第一步是导入和清洗数据。
使用VBA,我们可以编写代码自动导入外部数据,并进行数据清洗。
例如,我们可以编写代码自动将多个Excel文件中的数据合并到一个文件中,或者删除数据中的重复项和错误值。
3. 数据可视化数据可视化是数据分析中不可或缺的一部分。
VBA提供了各种方法来生成图表和图形,使得数据更易于理解和解释。
通过使用VBA,我们可以编写代码自动生成各种类型的图表,如柱状图、折线图、饼状图等,并对其进行自定义设置,如添加标题、图例、轴标签等。
4. 数据分析函数VBA提供了许多数据分析函数,可以帮助我们进行各种统计和计算操作。
例如,我们可以使用VBA中的SUM函数计算某一列或行的总和,使用AVERAGE函数计算平均值,使用MAX和MIN函数寻找最大和最小值等。
此外,VBA还提供了一些高级的统计函数,如STDEV函数计算标准差,CORREL函数计算相关系数等。
5. 数据预测模型除了数据分析,VBA还可以用于建立数据预测模型。
VBA中提供了一些统计函数和算法,如线性回归、指数平滑等。
通过编写代码,我们可以使用这些函数和算法来构建预测模型,并根据历史数据进行预测。
例如,我们可以使用VBA中的LINEST函数来拟合一条最佳拟合直线,通过这条直线进行未来值的预测。
实验5LL(1)语法分析程序的设计与实现(C语言)

实验五LL(1)文法识别程序设计之宇文皓月创作一、实验目的通过LL(1)文法识别程序的设计理解自顶向下的语法分析思想。
二、实验重难点FIRST集合、FOLLOW集合、SELECT集合元素的求解,预测分析表的构造。
三、实验内容与要求实验内容:1.阅读并理解实验案例中LL(1)文法判此外程序实现;2.参考实验案例,完成简单的LL(1)文法判别程序设计。
四、实验学时4课时五、实验设备与环境C语言编译环境六、实验案例1.实验要求参考教材93页预测分析方法,94页图5.11 预测分析程序框图,编写表达式文法的识别程序。
要求对输入的LL(1)文法字符串,程序能自动判断所给字符串是否为所给文法的句子,并能给出分析过程。
表达式文法为:E→E+T|TT→T*F|FF→i|(E)2.参考代码为了更好的理解代码,建议将图5.11做如下标注:/* 程序名称: LL(1)语法分析程序 *//* E->E+T|T *//* T->T*F|F *//* F->(E)|i *//*目的: 对输入LL(1)文法字符串,本程序能自动判断所给字符串是否为所给文法的句子,并能给出分析过程。
/********************************************//* 程序相关说明 *//* A=E' B=T' *//* 预测分析表中列号、行号 *//* 0=E 1=E' 2=T 3=T' 4=F *//* 0=i 1=+ 2=* 3=( 4=) 5=# *//************************************/#include"iostream"#include "stdio.h"#include "malloc.h"#include "conio.h"/*定义链表这种数据类型拜见:http://wenku.百度.com/link?url=_owQzf8PRZOt9H-5oXIReh4X0ClHo6zXtRdWrdSO5YBLpKlNvkCk0qWqvFFxjgO0KzueVwEQcv9aZtVKEEH8XWSQCeVTjXvy9lxLQ_mZXeS###*/struct Lchar{char char_ch;struct Lchar *next;}Lchar,*p,*h,*temp,*top,*base;/*p指向终结符线性链表的头结点,h指向动态建成的终结符线性链表节点,top和base分别指向非终结符堆栈的顶和底*/ char curchar; //存放当前待比较的字符:终结符char curtocmp; //存放当前栈顶的字符:非终结符int right;int table[5][6]={{1,0,0,1,0,0},{0,1,0,0,1,1},{1,0,0,1,0,0},{0,1,1,0,1,1},{1,0,0,1,0,0}};/*存放预测分析表,1暗示有发生式,0暗示无发生式。
LL(1)预测分析程序设计与实现

m gbsdo e a rc r. eut so a icner c y eat (eas t et h t r m ae nt s d t s ut e R sl w t tt o o ed , xc y uI e n e e h e a t u s h h r ljg t m w h a a
.
2 L () L 1预测分析方法 的设计 与实现
预测分析 的核心是构造预测分 析表 , 而预测 分析表的构造基础是文法非终结 符的候选首 终结 符集 F s A 和后 随符号集 Flw A . 以 , r( it ) o l ( )所 o 预 测分析技术 的实现可 以划分 为如下 3 步骤 : 个 ① 求文法非终结符 的候选 首终结 符集 和后 随符号 集 ; 构造预测分析表 根据输入符号和预测 ② ; ③ 分析表对句子进行分析 . 考虑到构造预测分析 表的需要 , 对非终 结符 的每个候选式求 出其对应 的候选首终结符集 , 也
gv n sn e c eo g oa ga i tn e b l s t rmma rn t e e n ro o .
K yw rs L 1 rd t eaa s ; o p e r c l ;ga m r et c e od :L ( )pe c v nl i cm ir i i e r a;sn ne ii ys l pnp s m e
分析和 L R分析方法 .L 1 预测分析方法 以其执 L () 行效率高 , 便于维护的优点而被广泛采用… .
・
收稿 日期 :0 7 6 2 2o —0 —1 基 金项 目 : 国防科工委纵向课 题资助项 目( 120A 0 ) H 006 04 . 作者简介 : (99 , , 曹琼 1 一)女 四川邻 水人 , 7 硕士 , 主要从事软件工程方 面的研究 .
实验四 非递归预测分析

《编译原理实验》—LR分析器院、系(部) 计算机科学与技术学院专业及班级计算机科学与技术专业1403班学号 1408030322姓名朱浩日期 2017年5月29日一、实验目的与任务设计一个非递归预测分析器,实现对表达式语言的分析,理解自上而下语法分析方法的基本思想,掌握设计非递归预测分析器的基本方法。
二、实验要求建立文法及其LL(1)分析表表示的数据结构,设计并实现相应的预测分析器,对源程序经词法分析后生成的二元式代码流进行预测分析,如果输入串是文法定义的句子则输出“是”,否则输出“否”。
三、文法描述及其LL(1)分析表表达式语言(XL) 的语法规则如下:1.程序→ 表达式;2. |表达式;程序3.表达式→ 表达式 + 项4. |项5.项→ 项 * 因式6. |因式7.因式→ num_or_id8. |(表达式)将该语言的文法转换为如下的LL(1)文法:1prgm → expr;prgm’ 8 term → factor term’2prgm’ → prgm 9 term’ → *factor term’3prgm’ →ε 10 term’ →ε4expr → term expr’ 11 factor → (expr)5expr →ε 12 factor → num6expr’ → +term expr’ 13 system_goal → prgm7expr’ →ε四、文法及其LL(1)分析表的数据结构文法的产生式可用数组Yy_pushtab[]存放。
数组的第一个下标是产生式号,第一个产生式的序号为0;每列按逆序存放该产生式右部各符号的常数值,并以0结束。
对于该表达式语言XL的LL(1)分析表,可用数组Yy_d[]存放。
第一个下标是非终结符数值,第二个下标是终结符数值,数组元素的值为:0(表示接受) ,1(表示产生式号) ,-1(表示语法错) 。
数组Yy_d[]的具体内容及表示如下:0 1 2 3 4 5 6prgm 256prgm’ 257expr 258term 259expr’ 260factor 261term’ 262system_goal 263数组Yy_pushtab[]的具体内容及表示如下:五、预测分析器总控程序结构预测分析器总控程序使用上面的两个表Yy_pushtab、Yy_d和一个分析栈(元素类型为int) ,其结构如下:初始化;/* 把开始符号的常数值压入分析站,输入指向第一个输入符号*/while(分析栈非空) {if(栈顶常数表示一个终结符)if(该常数与输入符号的常数不等)报语法错;else {把一个数从栈顶弹出;advance读下一输入符号;}else { /* 栈顶的常数表示一个非终结符 */what_to_do=Yy_d[栈顶常数][当前输入符号的常数];if(what_to_do== -1)报语法错;else {把栈顶元素弹出栈;把Yy_pushtab[what_to_do]中列出的全部常数压入分析栈;}}}请实现该程序。
实验二--语法分析程序的设计-

姓名:学号:专业班级
一、实验目的
通过设计、编制、调试一个典型的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析中预测分析方法。
二、实验内容
设计一个文法的预测分析程序,判断特定表达式的正确性。
三、实验要求
1、给出文法如下:
G[E]
E->T|E+T;
import java.io.*;
public class test2 {
static String[] key_word = { "main", "if", "then", "while", "do", "int",
"else" };
static String[] cal_word = { "+", "-", "*", "/", "<", ">", "{", "}", "(",
static String[] firstT = { "i", "(" };
static String[] firstTB = { "*", "@" };
static String[] firstF = { "i", "(" };
static String[][] list = { { "", "i", "+", "*", "(", ")", "#" },
预测分析方法--C++版
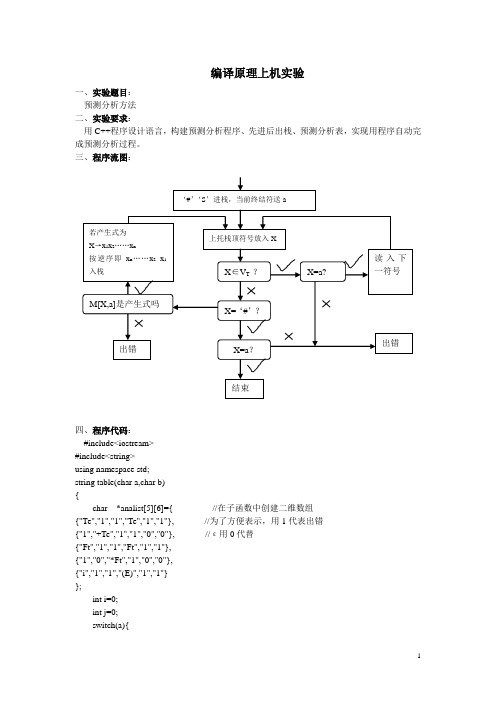
编译原理上机实验一、实验题目:预测分析方法二、实验要求:用C++程序设计语言,构建预测分析程序、先进后出栈、预测分析表,实现用程序自动完成预测分析过程。
三、程序流图:四、程序代码:#include<iostream>#include<string>using namespace std;string table(char a,char b){char *analist[5][6]={ //在子函数中创建二维数组{"Te","1","1","Te","1","1"}, //为了方便表示,用1代表出错{"1","+Te","1","1","0","0"}, //ε用0代替{"Ft","1","1","Ft","1","1"},{"1","0","*Ft","1","0","0"},{"i","1","1","(E)","1","1"}};int i=0;int j=0;switch(a){case 'E':i=0;break;case 'e':i=1;break;case 'T':i=2;break;case 't':i=3;break;case 'F':i=4;break;}switch(b){case 'i':j=0;break;case '+':j=1;break;case '*':j=2;break;case '(':j=3;break;case ')':j=4;break;case '#':j=5;break;}return analist[i][j];}bool isVt(char d) //判断是否是终结符{char vt[5] = {'i','+','*','(',')'};for(int i=0;i<5;i++){if(vt[i]==d)return true;}return false;}void main(){int op1,op2; //op1、op2分别为两个栈的栈顶指针string inputstr; //inputstr表示输入待分析的符号串int mark=0; //mark用来记录程序执行的次数string str; //定义str表示返回的产生式char a,X; //流程图中的a、Xchar stack1[30]; //用两个数组定义两个栈char stack2[30];op1=0; //初始化栈顶指针op2=0;stack1[op1]='#'; //#放入栈1op1++;stack1[op1]='E'; //E放入栈1cout<<endl; //输出所要打印的表头cout<<"****************自顶向下预测分析过程****************"<<endl;cout<<endl;cout<<endl;cout<<"LL(1)文法为:"<<endl;cout<<endl;cout<<"E->Te"<<endl;cout<<"e->+Te|ε"<<endl;cout<<"T->Ft"<<endl;cout<<"t->*Ft|ε"<<endl;cout<<"F->i|(E)"<<endl;cout<<endl;cout<<"请输入待分析符号串:"<<endl;cin>>inputstr; //输入待分析符号串cout<<endl;for(int i=1;i<inputstr.length()+1;i++){ //输入符号串入栈2stack2[i]=inputstr[inputstr.length()-i];}op2=inputstr.length();a=stack2[op2];op2--;cout<<"对符号串"<<inputstr<<" 的分析过程:"<<endl<<endl;cout<<"步骤"<<'\t'<<"分析栈"<<'\t'<<'\t'<<"剩余输入串"<<'\t'<<"推导所用产生式或匹配"<<endl;sign:mark++;cout<<mark<<'\t'; //输出程序执行的次数for(int j=0;j<(op1+1);j++) //输出分析栈1{cout<<stack1[j];}cout<<'\t'<<'\t';X=stack1[op1]; //上托栈顶符号放入Xop1--;for(int k=op2+1;k!=0;k--) //输出剩余符号串(即输出栈2){cout<<stack2[k];}cout<<'\t'<<'\t';//cout<<endl;if(isVt(X)){if(X!=a){cout<<"出错,符号串不符合文法。
预测分析程序实验报告
预测分析程序实验报告题⽬:预测分析法⼀、实验⽬的1、通过实验要学会⽤消除左递归和消除回溯的⽅法来使⽂法满⾜进⾏确定⾃顶向下分析的条件;2、学会⽤C/C++⾼级程序设计语⾔编写⼀个LL(1)分析法程序⼆、实验内容及要求LL(1)预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输⼊符号a做哪种过程的。
对于任何(X,a),总控程序每次都执⾏下述三种可能的动作之⼀:(1)若X = a =‘#’,则宣布分析成功,停⽌分析过程。
(2)若X = a ‘#’,则把X从STACK栈顶弹出,让a指向下⼀个输⼊符号。
(3)若X是⼀个⾮终结符,则查看预测分析表M。
若M[A,a]中存放着关于X的⼀个产⽣式,那么,⾸先把X弹出STACK栈顶,然后,把产⽣式的右部符号串按反序⼀⼀弹出STACK栈(若右部符号为ε,则不推什么东西进STACK栈)。
若M[A,a]中存放着“出错标志”,则调⽤出错诊断程序ERROR。
1、给定⽂法S -> a | b | (T)T -> SH | dH -> ,SH | ε2、该⽂法对应的预测分析表3、编写预测分析程序对句⼦进⾏分析三、试验程序设计说明1、相关函数说明分析栈可以采取许多的存储⽅法来设计,在这⾥采⽤的顺序栈。
根据预测分析原理,LL(1)分析程序的实现关键在于分析栈和分析表是采⽤何种数据结构来实现。
分析表是⼀个矩阵,当我们要调⽤分析表来分析时,就根据栈顶的⾮终结符和当前输⼊的终结符来决定执⾏哪种过程。
具体设计思想如下:printStack()输出分析栈内内容;printinputString()输出⽤户输⼊的字符串;Pop()弹出栈顶元素;Push()向栈内添加⼀个元素;Search()查找⾮终结符集合VT 中是否存在输⼊的⾮终结符;yuCeFenXi()进⾏输⼊串的预测分析的主功能函数;M(char A, char a)查看预测分析表M[A,a]中是否存在相应产⽣式。
利用AI技术进行恶意代码分析与检测
利用AI技术进行恶意代码分析与检测随着互联网的飞速发展,网络安全问题日益突出。
恶意代码作为网络攻击的一种常见手段,其攻击方式多样,且对个人隐私和企业安全产生不可逆的影响。
为了提升网络安全,研究和应用AI技术进行恶意代码分析与检测成为一种有效的手段。
一、恶意代码的种类和危害恶意代码分为病毒、蠕虫、木马、间谍软件、后门程序等多种类型。
其中,病毒是最常见的一种,其主要通过感染主机上的文件、驱动程序、系统进程等来进行繁殖和传播。
蠕虫则是通过寄生在网络中的其他主机上进行传播的恶意程序,其攻击方式更隐秘,传播速度更快。
木马则是一种假冒正常软件的恶意程序,其主要目的是为黑客提供远程控制权限,可以监视用户操作、窃取个人隐私等。
间谍软件则是指偷取个人隐私信息的恶意程序,比如窃取浏览历史、账户信息、银行卡号和密码等,其危害性更大,在一定程度上会对用户的财产安全造成威胁。
后门程序则是突破系统密码保护机制的一种恶意程序,可以在主机上提供一个“后门”,使得攻击者可以通过“后门”直接控制目标主机。
二、AI技术在恶意代码分析与检测中的应用传统的恶意代码分析方法往往需要大量的人工干预,效率低下,并且还面临着越来越复杂的恶意程序。
而AI技术的出现,则为恶意代码分析提供了一种全新的方案。
利用AI技术进行恶意代码的分类、特征提取、检测和预测,可以提高检测准确率,更快地响应和防御网络攻击。
1. 恶意代码分类恶意代码分类是进行恶意代码分析的第一步,而利用机器学习和深度学习技术进行恶意代码分类,则可以大大提高恶意代码分类的准确率。
通常采用的是基于静态和动态特征的分类方案,将恶意代码分成多个类别,使得分类更加精准。
在机器学习算法中,常用的算法包括决策树、朴素贝叶斯、KNN、SVM等。
而在深度学习中,常用的算法包括CNN、LSTM等。
2. 恶意代码特征提取恶意代码通过在系统中的行为和文件的特征区别于普通程序,因此提取出恶意代码的特征是恶意代码检测的另一个重要步骤。
《编译原理》考试试题及答案
《编译原理》考试试题及答案(附录)一、判断题:1.一个上下文无关文法的开始符,可以是终结符或非终结符。
( X )2.一个句型的直接短语是唯一的。
( X )3.已经证明文法的二义性是可判定的。
( X )4.每个基本块可用一个DAG表示。
(√)5.每个过程的活动记录的体积在编译时可静态确定。
(√)6.2型文法一定是3型文法。
( x )7.一个句型一定句子。
( X )8.算符优先分析法每次都是对句柄进行归约。
(应是最左素短语) ( X )9.采用三元式实现三地址代码时,不利于对中间代码进行优化。
(√)10.编译过程中,语法分析器的任务是分析单词是怎样构成的。
( x )11.一个优先表一定存在相应的优先函数。
( x )12.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。
( )13.递归下降分析法是一种自下而上分析法。
( )14.并不是每个文法都能改写成LL(1)文法。
( )15.每个基本块只有一个入口和一个出口。
( )16.一个LL(1)文法一定是无二义的。
( )17.逆波兰法表示的表达试亦称前缀式。
( )18.目标代码生成时,应考虑如何充分利用计算机的寄存器的问题。
( )19.正规文法产生的语言都可以用上下文无关文法来描述。
( )20.一个优先表一定存在相应的优先函数。
( )21.3型文法一定是2型文法。
( )22.如果一个文法存在某个句子对应两棵不同的语法树,则文法是二义性的。
( )二、填空题:1.( 最右推导 )称为规范推导。
2.编译过程可分为(词法分析),(语法分析),(语义分析和中间代码生成),(代码优化)和(目标代码生成)五个阶段。
3.如果一个文法存在某个句子对应两棵不同的语法树,则称这个文法是()。
4.从功能上说,程序语言的语句大体可分为()语句和()语句两大类。
5.语法分析器的输入是(),其输出是()。
6.扫描器的任务是从()中识别出一个个()。
编译原理预测分析程序的实现
实验二预测分析表一、实验目的预测分析表的实现二、实验内容设有文法G:E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→(E)|i;根据文法编写预测表分析总控程序,分析句子是否为该文法的句型。
当输入字符串:+i时,分析字符串是否为文法的句型三、实验步骤(详细的实验步骤)(1)文法E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→(E)|i;(2)FIRST集FIRST(E)={(,i};FIRST(E’)={+, ε};FIRST(T)={(,i};FIRST(T’)={ *, ε};FIRST(F)={(,i};(3)FALLOW集FOLLOW(E)={),#};FOLLOW(E’)={),#};FOLLOW(T)={+,),#};FOLLOW(T’)={+,),#};FOLLOW(F)={*,+,),#};(4)预测分析表(5)分析过程步骤符号栈输入串应用句型0#E i1*i2+i3#1#E’T i1*i2+i3#E->TE’2#E’T’F i1*i2+i3#E->TE’3#E’T’i i1*i2+i3#F->i4# E’T’i1*i2+i3#5# E’T’F**i2+i3#T’->*FT’6# E’T’F*i2+i3#7# E’T’i i2+i3#F->i8# E’T’i2+i3#9#E’+i3#T’->ε10# E’T++i3#E’->+TE’11#E’T+i3#12# E’T’F i3#T->FT’13# E’T’i i3#F->i14# E’T’i3#15# E’#T’->ε16# #E’->ε(6)程序伪代码BEGIN首先把‘#’然后把文法开始符号推进STACK栈;把第一个输入符号读进a;FLAG:=TRUE;WHILE FLAG DOBEGIN把STACK栈顶符号托出去并放在X中;IF X属于VT THENIF X=a THEN 把下一输入符号读进a;ELSE ERROR;ELSE IF X=’#’ THENIF X=a THEN FLAG:=FALSE ELSE ERROR;ELSE IF M[A,a]={X->X1X2…Xk} THEN把Xk,X(k-1),…,X1一一推进栈ELSE ERROR;END OF WHILESTOPEND(7)运行结果截图注:为了将E和E’区分开,所以就有e来表示E’,因为在处理中E’会被当成两个字符来处理,所以就简化的表示了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include"stdio.h"#include"string.h" /**//*程序中用到strcpy()函数*//**//*全局变量定义*/char inputString[10]; /**//*用来存储用户输入的字符串,最长为20个字符*/char stack[10]; /**//*用来进行语法分析的栈结构*/int base=0; /**//*栈底指针*/int top=1; /**//*栈顶指针*/char VT[4]={'a','d','b','e'}; /**//*用来存放5个终结符*/char chanShengShi[10]; /**//*用来存放预测分析表M[A,a]中的一条产生式*/int firstCharIntex=0; /**//*如果a匹配产生式,则每次firstCharIntex 自增 1 *//**//*firstCharIntex用来存放用户输入串的第一个元素的下标*/ /**//*自定义函数声明*/char pop() ; /**//*弹出栈顶元素*/int push(char ch) ; /**//*向栈内添加一个元素,成功返回1,若栈已满则返回0*/int search(char temp) ; /**//*查找非终结符集合VT中是否存在变量temp,存在返回1,不存在返回0*/int M(char A, char a) ; /**//* 若预测分析表M[A,a]中存在产生式,则将该产生式赋给字符数组chanShengShi[10],并返回 1,若M[A,a]中无定义产生式则返回 0*/void init() ; /**//*初始化数组inputString[10] 、栈stack[10] 和chanShengShi[10]*/int yuCeFenXi() ; /**//* 进行输入串的预测分析的主功能函数,若输入串满足文法则返回 1,不满足则返回0*/void printStack(); /**//*打印栈内元素 */void printinputString(); /**//*打印用户输入串 *//**//*进入主函数*/void main(){//clrscr();yuCeFenXi(); /**//*调用语法预测分析函数*///getch();}/**//*函数的定义*/int yuCeFenXi(){char X; /**//*X变量存储每次弹出的栈顶元素*/char a; /**//*a变量存储用户输入串的第一个元素*/int i;int counter=1; /**//*该变量记录语法分析的步骤数*/init(); /**//*初始化数组*/printf("wen fa : "); /**//*输出文法做为提示*/printf("S -> aH ");printf("H -> aMd | d ");printf("M -> Ab | ");printf("A -> aM | e ");printf(" input string ,'#' is a end sign !!(aaabd#) "); /**//*提示用户输入将要测试的字符串*/scanf("%s",inputString);push('#');push('S');printf(" Counter-----Stack---------------Input string "); /**//*输出结果提示语句*/while(1) /**//*while循环为语法分析主功能语句块*/{ printf(" \n");printf(" %d",counter); /**//*输出分析步骤数*/printf(" "); /**//*输出格式控制语句*/printStack(); /**//*输出当前栈内所有元素*/X=pop(); /**//*弹出栈顶元素赋给变量X*/printinputString(); /**//*输出当前用户输入的字符串*/if( search(X)==0 ) /**//*在终结符集合VT中查找变量X的值,存在返回 1,否则返回 0*/{if(X == '#') /**//*栈已经弹空,语法分析结果正确,返回 1*/{printf("success ... "); /**//*语法分析结束,输入字符串符合文法定义*/return 1;}else{a = inputString[firstCharIntex];if( M(X,a)==1 ) /**//*查看预测分析表M[A,a]是否存在产生式,存在返回1,不存在返回0*/{for(i=0;i<10;i++) /**//* '$'为产生式的结束符,for循环找出该产生式的最后一个元素的下标*/{if( chanShengShi[i]=='$' ) break;}i-- ; /**//*因为 '$' 不是产生式,只是一个产生式的结束标志,所以i 自减1*/while(i>=0){push( chanShengShi[i] ); /**//*将当前产生式逆序压入栈内*/i-- ;}}else{printf(" error(1) !!"); /**//*若预测分析表M[A,a]不存在产生式,说明语法错误*/return 0;}}}else /**//*说明X为终结符*/{if( X==inputString[firstCharIntex] ) /**//*如果X等于a,说明a匹配*/{firstCharIntex++; /**//*输入串的第一个元素被约去,下一个元素成为新的头元素*/}else{printf(" error(2) !! ");return 0;}}counter++; }}void init(){int i;for(i=0;i<10;i++){inputString[i]=NULL; /**//*初始化数组inputString[10] */stack[i]=NULL; /**//*初始化栈stack[10] */chanShengShi[i]=NULL; /**//*初始化数组chanShengShi[10]*/}}int M(char A, char a) /**//*文法定义因实际情况而定,该文法为课本例题的文法*/{ /**//*该函数模拟预测分析表中的二维数组 */if( A=='S'&& a=='a' ) { strcpy(&chanShengShi[0],"aH$"); return 1; }if( A=='H'&& a=='a' ) { strcpy(&chanShengShi[0],"aMd$"); return 1; }if( A=='H'&& a=='d' ) { strcpy(&chanShengShi[0],"d$"); return 1; }if( A=='M'&& a=='a' ) { strcpy(&chanShengShi[0],"Ab$"); return 1; }if( A=='M'&& a=='d' ) { strcpy(&chanShengShi[0],"$"); return 1; }if( A=='M'&& a=='b' ) { strcpy(&chanShengShi[0],"$"); return 1; }if( A=='M'&& a=='e' ) { strcpy(&chanShengShi[0],"Ab$"); return 1; }if( A=='A'&& a=='a' ) { strcpy(&chanShengShi[0],"aM$"); return 1; }if( A=='A'&& a=='e' ) { strcpy(&chanShengShi[0],"e$"); return 1; }else return 0; /**//*没有定义产生式则返回0*/}char pop() /**//*弹出栈顶元素,用topChar返回*/{char topChar;topChar=stack[--top];return topChar;}int push(char ch){if( top>9 ){printf(" error : stack overflow "); /**//*栈空间溢出*/return 0;}else{stack[top]=ch; /**//*给栈顶空间赋值*/top++;return 1;} }int search(char temp){int i,flag=0; /**//*flag变量做为标志,若找到temp则赋1,否则赋0*/ for(i=0;i<4;i++){if( temp==VT[i] ) /**//*终结符集合中存在temp*/{flag=1;break;}}if(flag==1) return 1; /**//*flag==1说明已找到等于temp的元素*/else return 0;}void printStack() /**//*输出栈内内容*/{int temp;for(temp=1;temp<top;temp++){printf("%c",stack[temp]);}}void printinputString() /**//*输出用户输入的字符串*/{int temp=firstCharIntex ;printf(" "); /**//*该句控制输出格式*/do{printf("%c",inputString[temp]);temp++;}while(inputString[temp-1]!='#');printf(" ");}。