实验12存储过程设计-大型数据库-浙江财经学院-东方学院-信息-实验报告-免费分享,请大家评个分!
网络存储过程实验报告(3篇)

第1篇一、实验背景随着互联网技术的快速发展,数据存储和传输已成为网络通信中的关键环节。
网络存储过程是数据库中的一种高级应用,它可以将多个SQL语句封装成一个存储过程,从而实现数据库的自动化管理和提高数据库的执行效率。
本实验旨在通过实践,掌握网络存储过程的创建、调用和优化方法。
二、实验目的1. 了解网络存储过程的基本概念和特点。
2. 掌握网络存储过程的创建方法。
3. 熟悉网络存储过程的调用和优化技巧。
4. 通过实验,提高数据库管理能力。
三、实验环境1. 操作系统:Windows 102. 数据库管理系统:MySQL 5.73. 实验工具:MySQL Workbench四、实验内容1. 创建网络存储过程(1)创建一个名为“select_user_info”的存储过程,用于查询用户信息。
```sqlDELIMITER //CREATE PROCEDURE select_user_info(IN user_id INT)BEGINSELECT FROM users WHERE id = user_id;END //DELIMITER ;```(2)创建一个名为“update_user_info”的存储过程,用于更新用户信息。
```sqlDELIMITER //CREATE PROCEDURE update_user_info(IN user_id INT, IN user_name VARCHAR(50), IN user_age INT)BEGINUPDATE users SET name = user_name, age = user_age WHERE id = user_id;END //DELIMITER ;```2. 调用网络存储过程(1)调用“select_user_info”存储过程,查询用户ID为1的用户信息。
```sqlCALL select_user_info(1);```(2)调用“update_user_info”存储过程,更新用户ID为1的用户信息。
实训项目存储过程的创建和使用

实训项⽬存储过程的创建和使⽤⽹络数据库实训报告⼀、实训⽬的和要求1、了解存储过程的作⽤;2、掌握创建、修改及删除存储过程的⽅法;3、掌握执⾏存储过程的⽅法。
⼆、实训所需仪器、设备硬件:计算机软件:操作系统Windows XP、SQL Server 2005三、实训内容(⼀)不带参数的存储过程的创建和修改1、在student数据库中创建⼀个名为myp1的存储过程,该存储过程的作⽤是显⽰t_student中的全部记录。
USE STUDENTIF EXISTS(SELECT name FROM sysobjectsWHERE name='mpy1'AND type='P')DROP PROCEDURE mpy1GOCREATE PROCEDURE myp1ASSelect*FROM T_STUDENTGO2、运⾏myp1,检查是否实现功能。
use studentexec myp13、修改myp1,使其功能为显⽰t_student中班级为05541班的学⽣记录,然后测试是否实现其功能。
set ANSI_NULLS ONset QUOTED_IDENTIFIER ONgoALTER PROCEDURE [dbo].[myp1]ASSelect*FROM T_STUDENTwhere left(s_number,5)='05541'use studentexec myp14、创建⼀个存储过程myp2,完成的功能是在表t_student、表t_course和表t_score 中查询以下字段:班级、学号、姓名、性别、课程名称、考试分数。
USE STUDENTIF EXISTS(SELECT name FROM sysobjectsWHERE name='myp2'AND type='P')DROP PROCEDURE myp2GOCREATE PROCEDURE myp2ASSelect班级=SUBSTRING(T_STUDENT.S_NUMBER,1,LEN(T_STUDENT.S_NUMBER)-2),学号=SUBSTRING(T_STUDENT.S_NUMBER,LEN(T_STUDENT.S_NUMBER)-1,2),S_NAME AS姓名,SEX AS性别,T_COURSE.C_NAME AS课程名称,t_SCORE.SCORE AS考试分数FROM T_STUDENT,T_COURSE,t_SCOREWHERE T_STUDENT.S_NUMBER=t_SCORE.S_NUMBERAND T_COURSE.C_NUMBER=t_SCORE.C_NUMBERGO(⼆)带输⼊参数的存储过程的创建1、创建⼀个带有⼀个输⼊参数的存储过程stu_info,该存储过程根据传⼊的学⽣编号,在t_student中查询此学⽣的信息。
数据库原理课程设计报告报告实验创建存储过程与触发器

存储过程与触发器实验日期和时间:2016 年 5 月13 日、星期五第节实验室:DJ2-信息管理实验室班级:学号:姓名:实验环境:1.硬件:笔记本电脑2.软件:SQL Server 2012实验原理:存储过程概念:存储过程是事先编好的,存储在数据库中的一组被编译了的T-SQL命令集合,这些命令用来完成对数据库的指定操作。
存储过程可以接受用户的输入参数、向客户端返回表格或标量结果和消息、调用数据定义语言(DDL)和数据操作语言(DML)语句,然后返回输入参数。
触发器概念:触发器(trigger)是SQL server 提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动,而是由事件来触发,比如当对一个表进行操作( insert,delete, update)时就会激活它执行。
触发器经常用于加强数据的完整性约束和业务规则等。
实验任务:此作业成绩得分根据你完成的任务的难度和数量评分,完成后在实验室给老师演示验收,课后提交电子版报告。
如额外完成自拟题目应当事先将所拟题目提交给老师或在报告中明确标注题意。
假定有学校的图书馆管理信息系统,可以用于日常管理书库和同学们的借还书工作。
以下列出参考的库表情况:根据管理的业务需求来分析,该管理信息系统的数据库应至少包括如下数据表:(打★号的是必须有的表)1.★图书现有库存表。
作用:记录图书的现有库存情况。
至少包括:书号、书名、作者、简介、类别、价格、出版社、出版日期、现有库存数量、最小库存量、库存总量、库存位置等。
2.★读者信息表。
作用:记录读者信息。
至少包括:读者编号、证件类型、证件号码、姓名、性别、职业(可填写教师、学生、教工、其它……)、所属单位、地址、联系电话等。
3.★借书记录表。
作用:记录借书情况,以及是否归还。
至少包括:借阅ID(主键,可设置为自动编号)、书号、读者编号、借阅数量、借阅日期、是否归还、管理员编号……等。
存储过程-触发器-ODBC数据库编程-实验报告
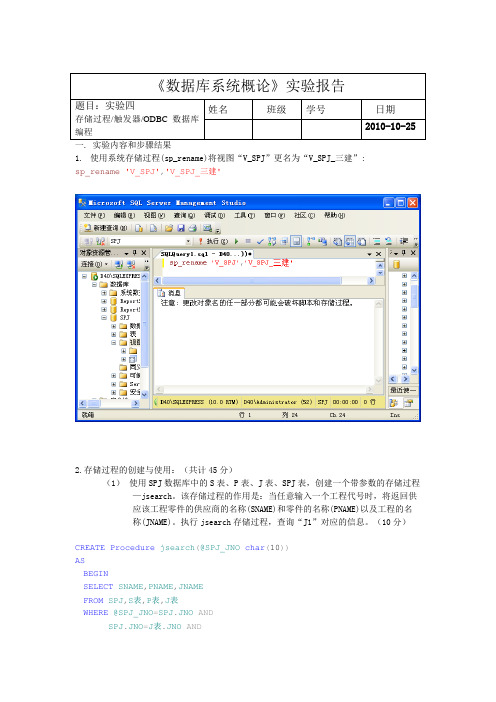
《数据库系统概论》实验报告题目:实验四存储过程/触发器/ODBC 数据库编程姓名 班级学号 日期2010-10-25一. 实验内容和步骤结果1. 使用系统存储过程(sp_rename)将视图“V_SPJ ”更名为“V_SPJ_三建”: sp_rename 'V_SPJ','V_SPJ_三建'2.存储过程的创建与使用:(共计45分)(1) 使用SPJ 数据库中的S 表、P 表、J 表、SPJ 表,创建一个带参数的存储过程—jsearch 。
该存储过程的作用是:当任意输入一个工程代号时,将返回供应该工程零件的供应商的名称(SNAME)和零件的名称(PNAME)以及工程的名称(JNAME)。
执行jsearch 存储过程,查询“J1”对应的信息。
(10分)CREATE Procedure jsearch (@SPJ_JNO char (10)) AS BEGINSELECT SNAME ,PNAME ,JNAME FROM SPJ ,S 表,P 表,J 表WHERE @SPJ_JNO =SPJ .JNO AND SPJ .JNO =J 表.JNO ANDSPJ.PNO=P表.PNO AND SPJ.SNO=S表.SNO END;jsearch'J1'(2)创建一个带有输出游标参数的存储过程jsearch2,功能同1),执行jsearch2,查询“J1”对应信息,并且将得到的结果用print语句输出到控制台。
(10分)CREATE PROCEDURE jsearch2(@jno char(10),@SPJ_CURSOR CURSOR VARYING OUTPUT)ASset @SPJ_CURSOR=CURSORFORSELECT J表.JNAME,P表.PNAME,S表.SNAMEfrom S表,P表,J表,SPJwhere SPJ.JNO=@jno andS表.SNO=SPJ.SNO andJ表.JNO=SPJ.JNO andP表.PNO=SPJ.PNOopen @SPJ_CURSORdeclare @jname char(10),@sname char(10),@pname char(10)declare @SPJ_CURSOR cursorexec jsearch2 'J1',@SPJ_CURSOR outputfetch next from @SPJ_CURSOR into @jname,@pname,@snamewhile(@@FETCH_STATUS=0)beginprint(@jname+@pname+@sname)fetch next from @SPJ_CURSOR into @jname,@pname,@sname endclose @SPJ_CURSORdeallocate @SPJ_CURSORgo(3)使用SPJ数据库中的S表,为其创建一个加密的存储过程—jmsearch。
存储过程的使用 实验报告

USEypp7
--声明四个变量,用于保存输入和输出参数
DECLARE@KECHENGMINGvarchar(20)
DECLARE@AVGCHENGJI1tinyint
DECLARE@MAXCHENGJI1tinyint
DECLARE@MINCHENGJI1tinyint
--为输入参数赋值
SELECT@KECHENGMING='高等数学'
--声明四个变量,用于保存输入和输出参数
DECLARE@KECHENGMINGvarchar(20)
DECLARE@AVGCHENGJI1tinyint
DECLARE@MAXCHENGJI1tinyint
DECLARE@MINCHENGJI1tinyint
--为输入参数赋值
SELECT@KECHENGMING='计算机基础'
1.使用if exists语句,如果存储过程“单科成绩分析”存在,就将其删除;
2.使用create proc语句创建存储过程;
3.定义所需要的输入参数和输出参数;
4.声明4个变量来保存输入和输出参数;
5.执行存储过程并显示结果。
同时,值得注意的是,在创建存储过程时,应该注意一些细节,如单词的拼写要准确无误,程序中用的是单引号而不是双引号等等。
--执行存储过程
EXEC单科成绩分析@KECHENGMING,
@AVGCHENGJI1OUTPUT,
@MAXCHENGJI1OUTPUT,
@MINCHENGJI1OUTPUT
--显示结果
SELECT@KECHENGMINGAS课程名,@AVGCHENGJI1AS平均成绩,@MAXCHENGJI1AS最高成绩,
数据库实验报告(6)

数据库实验报告(6)一实验题目1.存储过程的定义和使用2。
触发器的创建和使用二实验目的1.掌握存储过程的定义、执行和调用方法。
2.掌握触发器的创建和使用。
三实验内容1.存储过程的定义和使用(1)创建存储过程查找姓李的学生的选修课成绩信息。
(2)创建一个存储过程,计算每个学生选修课的总分,并显示得分最高的三名学生的分数。
(3)创建一个存储过程以查找课程的最高分数(带有输入参数的存储过程)。
(4)创建一个存储过程来计算同学的平均分数并返回统计结果。
(带输入和输出参数的存储过程)(5)创建一个存储过程,计算选修课的数量,然后返回数字。
(6)用存储过程统计选修课,用存储值最多的学生。
(存储过程的嵌套)2.触发器的创建与使用(1)如果学分大于5,在为表格C插入新课程信息时,定义行前级别的触发学分uu触发器分,自动修改为5分。
(2)定义行后级别触发器。
当SC表的等级发生变化时,它将自动出现在等级变化表SC_uu增加日志中加一条新的纪录,该新纪录包括:操作者名称、操作日期、操作类型。
(3)建立一个delete触发器,针对于sc表,每次只能删除一条信息。
(4)创建不允许用户更改学号的更新触发器。
如果学生号被更改,将给出提示信息:学生号不允许更改。
(5)执行相应的SQL语句来触发上面定义的触发器。
(6)删除触发信用触发四实验步骤1.存储过程的定义和格式:createproc[edure]procedure_name[;number][{@parameterdata_type}[变化][=默认值][输出][with[用于复制]assql_statement[...n]创建存储过程以查找姓李的学生的选修课分数信息。
(1)创建存储过程,统计每个学生的选修课的总成绩,显示成绩最好的前3名学生成绩。
SC表的基本信息如图1所示:图表1代码:createprocp_sumscoreas从SCGroupByNo中选择Top 3Sum(成绩)作为总分execp_sumscore运行结果:命令已成功完成。
数据库课程设计实验报告

SJTU-CS数据库课程设计实验报告姓名王亮谢明敏学号5040309458班级F0403016 F0403014 完成日期2007/7/5C O N T E N T1. Introduction (1)2. WaxBase Design (4)2.1 The Thought of Design (4)2.2 Project Part Introduce (5)2.2.1 The Paged File Component (5)2.2.1.1 Buffer_Data (6)2.2.1.2 PF_Manager (7)2.2.1.3 PF_FileHandle (8)2.2.1.4 PF_PageHandle (11)2.2.2 The Record Management Component (13)2.2.2.1 RM_Manager (13)2.2.2.2 RM_FileHandle (14)2.2.2.3 RM_FileScan (15)2.2.2.4 RM_Record (17)2.2.2.5 RM_RID (17)2.2.3 The Indexing Component (19)2.2.3.1 IX_Manager Class (19)2.2.3.2 IX_IndexHandle Class (20)2.2.3.3 IX_IndexScan Class (21)2.2.4 The System Management Component (23)2.2.4.1 SM_Manager Class (23)2.2.5 The Query Language Component (26)2.2.5.1 QL_Manager Class (26)2.3 The Algorithm Used In Program (29)2.3.1 LRU algorithm (29)2.3.2 Hashing Table (29)2.3.3 B+ Tree (29)3. Usage of WaxBase (32)3.1 Create a database (32)3.2 Destroy a database (32)3.3 Open a database (32)3.4 The commands we support in database: (32)3.4.1 DDL Commands (32)3.4.1.1 Create Table (32)3.4.1.2 Drop Table (32)3.4.1.3 Create Index (33)3.4.1.4 Drop Index (33)3.4.2 The RQL Select command (33)3.4.2.1 The syntax of the one data retrieval command in RQL (33)3.4.2.2 An alternative form of the Select command (33)3.4.3 The RQL Insert Command (33)3.4.4 The RQL Delete Command (34)4. Conclusions (35)5. Reference (36)1.IntroductionA database management system (DBMS) is computer software designed for the purpose of managing databases. Typical examples of DBMSs include Oracle, DB2, Microsoft Access, Microsoft SQL Server, Postgres, MySQL and FileMaker. DBMSs are typically used by Database administrators in the creation of Database systems.A DBMS is a complex set of software programs that controls the organization, storage and retrieval of data in a database. A DBMS includes:1. A modeling language to define the schema(relational model) of each database hosted in theDBMS, according to the DBMS data model.●The three most common organizations are the hierarchical, network and relational models. Adatabase management system may provide one, two or all three methods. Inverted lists andother methods are also used. The most suitable structure depends on the application and onthe transaction rate and the number of inquiries that will be made. The dominant model inuse today is the ad hoc one embedded in SQL, a corruption of the relational model byviolating several of its fundamental principles. Many DBMSs also support the OpenDatabase Connectivity API that supports a standard way for programmers to access theDBMS.2.Data structures (fields, records and files) optimized to deal with very large amounts of data storedon a permanent data storage device (which implies very slow access compared to volatile main memory).3. A database query language and report writer to allow users to interactively interrogate thedatabase, analyze its data and update it according to the users privileges on data.●It also controls the security of the database.●Data security prevents unauthorized users from viewing or updating the database. Usingpasswords, users are allowed access to the entire database or subsets of it called subschemas.For example, an employee database can contain all the data about an individual employee,but one group of users may be authorized to view only payroll data, while others are allowedaccess to only work history and medical data.●If the DBMS provides a way to interactively enter and update the database, as well asinterrogate it, this capability allows for managing personal databases. However, it may notleave an audit trail of actions or provide the kinds of controls necessary in a multi-userorganization. These controls are only available when a set of application programs arecustomized for each data entry and updating function.4. A transaction mechanism, that ideally would guarantee the ACID properties, in order to ensuredata integrity, despite concurrent user accesses (concurrency control), and faults (fault tolerance).●It also maintains the integrity of the data in the database.第1页The DBMS can maintain the integrity of the database by not allowing more than one user to update the same record at the same time. The DBMS can help prevent duplicate records viaunique index constraints; for example, no two customers with the same customer numbers(key fields) can be entered into the database. See ACID properties for more information(Redundancy avoidance).The components of a DBMS:The DBMS accepts requests for data from the application program and instructs the operating system to transfer the appropriate data.When a DBMS is used, information systems can be changed much more easily as the organization's information requirements change. New categories of data can be added to the database without disruption to the existing system.Organizations may use one kind of DBMS for daily transaction processing and then move the detail onto another computer that uses another DBMS better suited for random inquiries and analysis. Overall systems design decisions are performed by data administrators and systems analysts. Detailed database design is performed by database administrators.Database servers are specially designed computers that hold the actual databases and run only the DBMS and related software. Database servers are usually multiprocessor computers, with RAID disk arrays第2页used for stable storage. Connected to one or more servers via a high-speed channel, hardware database accelerators are also used in large volume transaction processing environments.DBMS's are found at the heart of most database applications. Sometimes DBMSs are built around a private multitasking kernel with built-in networking support although nowadays these functions are left to the operating system.Features and Abilities of DBMS: One can characterize a DBMS as an "attribute management system" where attributes are small chunks of information that describe something. For example, "color" is an attribute of a car. The value of the attribute may be a color such as "red", "blue", "silver", etc. Lately databases have been modified to accept large or unstructured (pre-digested or pre-categorized) information as well, such as images and text documents. However, the main focus is still on descriptive attributes.DBMS roll together frequently-needed services or features of attribute management. This allows one to get powerful functionality "out of the box" rather than program each from scratch or add and integrate them incrementally.第3页2.WaxBase Design2.1The Thought of DesignIn general, a Database managerment system will include many components, but because of the short of peoples and time, our WaxBase will include these components:Legend:●PF: Paged File●RM: Record Management●IX: Indexing●SM: System Management (DDL, utilities)●QL: Query Language●EX: Extension第4页2.2 Project Part Introduce2.2.1 The Paged File ComponentThe paged file component is the "bottom" component of the WaxBase system. This component provides facilities for higher-level client components to perform file I/O in terms of pages. In the PF component, methods are provided to create, destroy, open, and close paged files, to scan through the pages of a given file, to read a specific page of a given file, to add and delete pages of a given file, and to obtain and release pages for scratch use.The name of each class in paged file component begins with the prefix PF. Each method in the PF component except constructors and destructors returns an integer code; the same will be true of all of the methods you will see. A return code of 0 indicates normal completion. A nonzero return code indicates that an exception condition or error has occurred. Positive nonzero return codes indicate non-error exception conditions (such as reaching the end of a file) or errors from which the system can recover or exit gracefully (such as trying to close an unopened file). Negative nonzero return codes indicate errors from which the system cannot recover.Accessing data on a page of a file requires first reading the page into a buffer pool in main memory, then manipulating (reading or writing) its data there. While a page is in memory and its data is available for manipulation, the page is said to be "pinned" in the buffer pool. A pinned page remains in the buffer pool until it is explicitly "unpinned." A client unpins a page when it is done manipulating the data on that page. Unpinning a page does not necessarily cause the page to be removed from the buffer -- an unpinned page is kept in memory as long as its space in the buffer pool is not needed.If the PF component needs to read a new page into memory and there are no free spaces left in the buffer pool, then the PF component will choose an unpinned page to remove from the buffer pool and will reuse its space. The PF component uses a Least-Recently-Used (LRU) page replacement policy. When a page is removed from the buffer pool, it is copied back to the file on disk if and only if the page is marked as "dirty." Dirty pages are not written to disk automatically until they are removed from the buffer. However, a PF client can always send an explicit request to force (i.e., write to disk) the contents of a particular page, or to force all dirty pages of a file, without removing those pages from the buffer.It is important not to leave pages pinned in memory unnecessarily. The PF component clients that you will implement can be designed so that each operation assumes none of the pages it needs are in the buffer pool: A client fetches the pages it needs, performs the appropriate actions on them, and then unpins them, even if it thinks a certain page may be needed again in the near future. (If the page is used again soon then it will probably still be in the buffer pool anyway.) The PF component does allow the same page to be pinned more than once, without unpinning it in between. In this case, the page won't actually be unpinned until the number of unpin operations matches the number of pin operations. It is very important that each time you第5页fetch and pin a page, you don't forget to unpin it when you're done. If you fail to unpin pages, the buffer pool will slowly fill up until you can no longer fetch any pages at all (at which point the PF component will return a negative code).The description of classes in the PF component is in the below:2.2.1.1 Buffer_DataThe Buffer_Data class handles the buffer pool action. We use an array of char to store the buffer. The whole number of block is 40. Meanwhile, we use a hash table to save which page saved in our buffer now. In buffer, we use a chain to implement the LRU algothrim. If the block is pined in the buffer, it will not in the chain. Every time if we want to use a block in buffer to save the page, we will use the LRU place to save the page.Int getderty (int num)This method is to get if the num block in buffer is derty.Int getfname (int num)This method is to get the filename of the num block in buffer.Int getdata (int num)This method is to get the data of the num block in buffer.Int delMRU ()This method is to delete the data of the most recently used block in buffer.第6页Int addLRU (int num)This method is to add the num block in buffer to the LRU place.Int addLRU (int num)This method is to add the num block in buffer to the MRU place.Int DelChain (int num)This method is to delete the num block in buffer from the chain.Int WriteBack (int num)This method is to write back the num block in buffer from the buffer to disk, but not delete from the buffer.Int WriteBackWithDel (int num)This method is to write back the num block in buffer from the buffer to disk, and delete from the buffer.Int addMap (string str, int num)This method is to add the map of str to num in the hash table.Int delMap (string str, int num)This method is to delete the map from the hash table.Int delMap (int num)This method is to get the map from the hash table.2.2.1.2PF_ManagerThe PF_Manager class handles the creation, deletion, opening, and closing of paged files, along with the allocation and disposal of scratch pages. Your program should create exactly one instance of this class, and all requests for PF component file management should be directed to that instance. Below, the public methods of the class declaration are shown first, followed by descriptions of the methods. The first two methods in the class declaration are the constructor and destructor methods for the class; they are not explained further. Each method except the constructor and destructor methods returns a value of type RC (for "return code" -- actually an integer). A return code of 0 indicates normal completion. A nonzero return code indicates that an exception condition or error has occurred.RC CreateFile (const char *fileName)第7页This method creates a paged file called fileName. The file should not already exist.RC DestroyFile (const char *fileName)This method destroys the paged file whose name is fileName. The file should exist.RC OpenFile (const char *fileName, PF_FileHandle &fileHandle)This method opens the paged file whose name is fileName. The file must already exist and it must have been created using the CreateFile method. If the method is successful, the fileHandle object whose address is passed as a parameter becomes a "handle" for the open file. The file handle is used to manipulate the pages of the file (see the PF_FileHandle class description below).RC CloseFile (PF_FileHandle &fileHandle)This method closes the open file instance referred to by fileHandle. The file must have been opened using the OpenFile method. All of the file's pages are flushed from the buffer pool when the file is closed. It is a (positive) error to attempt to close a file when any of its pages are still pinned in the buffer pool.RC AllocateBlock (char *&buffer)This method allocates a "scratch" memory page (block) in the buffer pool and sets buffer to point to it. The scratch page is automatically pinned in the buffer pool.RC DisposeBlock (char *buffer)This method disposes of the scratch page in the buffer pool pointed to by buffer, which must have been allocated previously by PF_Manager::AllocateBlock. Similar to pinning and unpinning, you must call PF_Manager::DisposeBlock for each buffer block obtained by calling PF_Manager::AllocateBlock; otherwise you will lose pages in the buffer pool permanently.2.2.1.3 PF_FileHandleThe PF_FileHandle class provides access to the pages of an open file. To access the pages of a file, a client first creates an instance of this class and passes it to the PF_Manager::OpenFile method described above. As before, the public methods of the class declaration are shown first, followed by descriptions of the methods. The first two methods in the class declaration are the constructor and destructor methods and are not explained further.第8页PF_FileHandle (const PF_FileHandle &fileHandle)This method is the copy constructor, called if a new file handle object is created from an existing one. When a new file handle object is created from a file handle object that refers to an open file instance, the file is not opened an additional time. Instead, both file handle objects refer to the same open file instance. It is sufficient to call PF_Manager::CloseFile with one of the file handle objects to close the file.PF_FileHandle& operator= (const PF_FileHandle &fileHandle)This method overloads the = operator when it is used to assign one file handle object to another. It is not a good idea to assign one file handle object to another if the file handle object on the left-hand side of the = already refers to an open file. As with the copy constructor, if the file handle object on the right-hand side of the = refers to an open file instance, the file is not opened an additional time. Instead, both file handle objects refer to the same open file instance, and it is sufficient to call PF_Manager::CloseFile with one of the file handle objects to close the file.RC GetFirstPage (PF_PageHandle &pageHandle)For this and the following methods, it is a (positive) error if the PF_FileHandle object for which the method is called does not refer to an open file. This method reads the first page of the file into the buffer pool in memory. If the page fetch is successful, the pageHandle object becomes a handle for the page. The page handle is used to access the page's contents (see the PF_PageHandle class description below). The page read is automatically pinned in the buffer pool and remains pinned until it is explicitly unpinned by第9页calling the UnpinPage method (below). This method returns the positive code PF_EOF if end-of-file is reached (meaning there is no first page).RC GetLastPage (PF_PageHandle &pageHandle)This method reads the last page of the file into the buffer pool in memory. If the page fetch is successful, the pageHandle object becomes a handle for the page. The page read is automatically pinned in the buffer pool and remains pinned until it is explicitly unpinned by calling the UnpinPage method (below). This method returns the positive code PF_EOF if end-of-file is reached (meaning there is no last page).RC GetNextPage (PageNum current, PF_PageHandle &pageHandle)This method reads into memory the next valid page after the page whose number is current. If the page fetch is successful, pageHandle becomes a handle for the page. The page read is pinned in the buffer pool until it is unpinned by calling the UnpinPage method. This method returns PF_EOF if end-of-file is reached (meaning there is no next page). Note that it is not an error if current does not correspond to a valid page (e.g., if the page numbered current has been disposed of).RC GetPreviousPage (PageNum current, PF_PageHandle &pageHandle)This method reads into memory the valid page previous to the page whose number is current. If the page fetch is successful, pageHandle becomes a handle for the page. The page read is pinned in the buffer pool until it is unpinned by calling the UnpinPage method. This method returns PF_EOF if end-of-file is reached (meaning there is no previous page). Note that it is not an error if current does not correspond to a valid page (e.g., if the page numbered current has been disposed of).RC GetThisPage (PageNum pageNum, PF_PageHandle &pageHandle)This method reads into memory the page specified by pageNum. If the page fetch is successful, pageHandle becomes a handle for the page. Parameter pageNum must be a valid page number. As usual, the page read is pinned in the buffer pool until it is explicitly unpinned.RC AllocatePage (PF_PageHandle &pageHandle)This method allocates a new page in the file, reads the new page into memory, and pins the new page in the buffer pool. If successful, pageHandle becomes a handle for the new page.RC DisposePage (PageNum pageNum)This method disposes of the page specified by pageNum. After this method is executed, if you scan over the pages of the file, the page numbered pageNum will no longer appear. It is a (positive) error to attempt to dispose of a page that is pinned in the buffer pool.RC MarkDirty (PageNum pageNum)This method marks the page specified by pageNum as "dirty," indicating that the contents of the page have been or will be modified. The page must be pinned in the buffer pool. A page marked as dirty is written back to disk when the page is removed from the buffer pool. (Pages not marked as dirty are never written back to disk.)RC UnpinPage (PageNum pageNum)第10页This method tells the PF component that the page specified by pageNum is no longer needed in memory.RC ForcePages (PageNum pageNum = ALL_PAGES)This method copies the contents of the page specified by pageNum from the buffer pool to disk if the page is in the buffer pool and is marked as dirty. The page remains in the buffer pool but is no longer marked as dirty. If no specific page number is provided (i.e., pageNum = ALL_PAGES), then all dirty pages of this file that are in the buffer pool are copied to disk and are no longer marked as dirty. Note that page contents are copied to disk whether or not a page is pinned.2.2.1.4 PF_PageHandleThe PF_PageHandle class provides access to the contents of a given page. To access the contents of a page, a client first creates an instance of this class and passes it to one of the PF_FileHandle methods described above.PF_PageHandle (const PF_PageHandle &pageHandle)This method is the copy constructor. When a new page handle object is created from a page handle object that refers to a pinned page in the buffer pool, the page is not pinned a second time.PF_PageHandle& operator= (const PF_PageHandle &pageHandle)This method overloads the = operator when it is used to assign one page handle object to another. As with the copy constructor, if the page handle object on the right-hand side of the = refers to a pinned page, the page is not pinned a second time.RC GetData (char *&pData) constThis method provides access to the actual contents of a page. The PF_PageHandle object for which this method is called must refer to a page that is pinned in the buffer pool. If the method is successful, pData is set to point to the contents of the page in the buffer pool.RC GetPageNum (PageNum &pageNum) const第11页This method sets pageNum to the number of the page referred to by the PF_PageHandle object for which this method is called. The page handle object must refer to a page that is pinned in the buffer pool.第12页2.2.2 The Record Management ComponentThe RM component provides classes and methods for managing files of unordered records. All class names, return codes, constants, etc. in this component should begin with the prefix RM. The RM component is a client to the PF component: RM methods will make calls to the PF methods we have provided.2.2.2.1 RM_ManagerThe RM_Manager class handles the creation, deletion, opening, and closing of files of records in the RM component.RC CreateFile (const char *fileName, int recordSize)This method will call PF_Manager::CreateFile to create a paged file called fileName. The records in this file will all have size recordSize. This method will initialize the file by storing appropriate information in the header page. Although recordSize will usually be much smaller than the size of a page, you should compare recordSize with PF_PAGE_SIZE and return a nonzero code if recordSize is too large for your RM component to handle.RC DestroyFile (const char *fileName)This method should destroy the file whose name is fileName by calling PF_Manager::DestroyFile.RC OpenFile (const char *fileName, RM_FileHandle &fileHandle)This method should open the file called fileName by calling PF_Manager::OpenFile. If the method is successful, the fileHandle object should become a "handle" for the open RM component file. As in the PF component, it should not be an error if a client opens the same RM file more than once, using a different fileHandle object each time. Each call to the OpenFile method should create a new instance of the open file. You may assume if a file has more than one opened instance then each instance of the open file may be read but will not be modified. If a file is modified while opened more than once, you need not guarantee the integrity of the file or the RM component. You may also assume that DestroyFile will never be called on an open file.RC CloseFile (RM_FileHandle &fileHandle)This method should close the open file instance referred to by fileHandle by calling PF_Manager:: CloseFile.第13页2.2.2.2 RM_FileHandleThe RM_FileHandle class is used to manipulate the records in an open RM component file. To manipulate the records in a file, a client first creates an instance of this class and passes it to the RM_Manager::OpenFile method described above. Descriptions of the constructor and destructor methods are not included for this class.RC GetRec (RID &rid, RM_Record &rec)For this and the following methods, it should be a (positive) error if the RM_FileHandle object for which the method is called does not refer to an open file. This method should retrieve the record with identifier rid from the file. It should be a (positive) error if rid does not identify an existing record in the file. If the method succeeds, rec should contain a copy of the specified record along with its record identifier (see the RM_Record class description below).RC InsertRec (char *pData, RID &rid)This method should insert the data pointed to by pData as a new record in the file. If successful, the return parameter &rid should point to the record identifier of the newly inserted record.RC DeleteRec (RID &rid)This method should delete the record with identifier rid from the file. If the page containing the record becomes empty after the deletion, you can choose either to dispose of the page (by calling PF_Manager::DisposePage) or keep the page in the file for use in the future, whichever you feel will be more efficient and/or convenient.RC UpdateRec (RM_Record &rec)This method should update the contents of the record in the file that is associated with rec (see the RM_Record class description below). This method should replace the existing contents of the record in the file with the current contents of rec.第14页RC ForcePages (PageNum pageNum = ALL_PAGES) constThis method should call the corresponding method PF_FileHandle::ForcePages in order to copy the contents of one or all dirty pages of the file from the buffer pool to disk.2.2.2.3 RM_FileScanThe RM_FileScan class provides clients the capability to perform scans over the records of an RM component file, where a scan may be based on a specified condition. As usual, the constructor and destructor methods are not described.RC OpenScan (const RM_FileHandle &fileHandle, AttrType attrType, int attrLength, int attrOffset, CompOp compOp, void *value, ClientHint pinHint = NO_HINT)This method should initialize a scan over the records in the open file referred to by parameter fileHandle. During the scan, only those records whose specified attribute satisfies the specified condition (a comparison with a value) should be retrieved. If value is a null pointer, then there is no condition and all records are retrieved during the scan. If value is not a null pointer, then value points to the value that attributes are to be compared with.Parameters attrType and attrLength indicate the type and length of the attribute being compared: either a 4-byte integer, a 4-byte floating point number, or a character string with a length between 1 and MAXSTRINGLEN bytes. (MAXSTRINGLEN = 255 is defined in waxbase.h.) Type AttrType is defined in第15页waxbase.h as follows: INT for integer, FLOAT for floating point number, and STRING for character string. You will need to cast the value into the appropriate type for the attribute (or, in the case of an integer or float, copy it into a separate variable to avoid alignment problems). If a character string has length n, then the attribute and the value will each be exactly n bytes long. They will not be <= n bytes, i.e., no "padding" is required, and they are not null-terminated. Parameter attrOffset indicates where the attribute is found within the contents of each record. Parameter compOp indicates the way that the record's attribute value should be compared with the value parameter. The different values for compOp are defined in waxbase.h as follows:file scan can suggest a specific page-pinning strategy for the RM component to use during the file scan, to achieve maximum efficiency. Type ClientHint is defined in waxbase.h, and you will need to define constants in addition to NO_HINT if you plan to use it. You are free to implement only one page-pinning strategy and ignore the pinHint parameter, or you may implement more than one strategy based on pinHint values now, or you may implement one strategy now and consider adding new strategies later when you implement clients of the RM component. Please note that using pinHint is optional, and only default value NO_HINT will be passed to OpenScan in the TA's test suite.RC GetNextRec (RM_Record &rec)This method should retrieve a copy of the next record in the file scan that satisfies the scan condition. If this method succeeds, rec should contain a copy of the record along with its record identifier. This method should return RM_EOF (which you should define) if there are no records left satisfying the scan condition. You may assume that RM component clients will not close the corresponding open file instance while a scan is underway.RC CloseScan ()This method should terminate the file scan.第16页。
《SQL Server 数据库》数据库存储过程、触发器的创建于管理实验报告

北华航天工业学院《数据库系统管理》实验报告报告题目:存储过程、触发器的创建于管理所在系部:计算机科学与工程系所在专业:网络工程专业学号:姓名:教师姓名:完成时间:2011 年10 月19 日北华航天工业学院教务处制存储过程、触发器的创建与管理一、实验目的1、掌握存储过程的概念、优点、特点及用途;2、掌握创建、执行、查看、修改和删除存储过程的方法;3、了解触发器和一般存储过程的区别、概念及优点;4、掌握创建、查看、修改和删除触发器的方法。
二、实验内容(一)附加上次实验所创建的数据库“db_Library”,并回顾该数据库的数据表信息。
(二)练习创建和管理存储过程1、使用管理控制台创建一个名为“计算机系借阅信息_PROC”的无参存储过程,要求显示计算机系读者2011-1-1以后借阅的图书信息,包括“读者姓名”、“图书编号”和“借阅日期”三个字段,并执行该存储过程,查看显示结果。
2、使用T-SQL语句创建一个名为“读者借阅信息_PROC”的带参数的存储过程,要求根据输入的读者的编号显示读者的所有借阅信息,包括“读者编号”、“姓名”、“系部”、“图书编号”、“图书名称”和“借阅日期”等字段,并执行该存储过程,查看显示结果。
create proc读者借阅信息_PROC1@dzbh char(10)asbeginselect tb_reader.读者编号,姓名,系部,tb_book.图书编号,书名,借阅日期from tb_book,tb_reader,tb_borrowwhere tb_book.图书编号=tb_borrow.图书编号and tb_reader.读者编号=tb_borrow.读者编号and tb_reader.读者编号=@dzbhend--declare @srcs char(10),@fhzt intset @srcs='R10009'exec @fhzt=读者借阅信息_PROC1 @srcsprint'执行状态值为'+cast(@fhzt as varchar(10))3、使用T-SQL语句创建一个名为“图书借阅信息_PROC”的带参数的存储过程,要求根据输入的图书编号计算该图书的借阅数量,并根据程序执行结果返回不同的值,执行成功返回0,不成功返回错误号,并执行该存储过程,输出图书编号、借阅数量和程序结果返回值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
end
declare@statusint
exec@status=员工表插入'2001','王一','男','1983-03-15','1001','采购部长',4232,12
if@status=0
print'插入成功'
else
print'插入失败'
declare@statusint
exec@status=员工表插入'2015','王一','男','1983-03-15','1001','采购部长',4232,12
select部门名as参加该项目最少人的部门
from部门表
where部门号=
(select所在部门号
from#temp
where部门人数=@minNum)
exec参加项目查询'J10'
三、对员工表结构进行修改,增加‘技术职称’字段。在部门表里增加‘部门人数’字段。
(1)编写修改工资存储过程,要求由用户指定员工号,以及增长幅度(比如增长10%,则该变量的值就为0.1),存储过程完成对指定员工工资的修改,如果职称是高级工程师,增长20%,如果职称是工程师,增长15%,如果职称是助理工程师,增长10%。调用该存储过程,修改工资。
where员工号=@员工号
select*from员工表where员工号='2003'
exec工资修改'2003'
select*from员工表where员工号='2003'
(2)部门人数应该等于员工表中实际员工数,由于有员工调入调出,可能存在不等的情况。编写存储过程,检查所有部门人数的正确性,如果不正确,则进行修改。
go
create procedure参加项目查询(@项目编号char(4))
as
selectcount(所在部门号)as部门人数,所在部门号
into#temp
from员工表,员工参与项目表
where员工参与项目表.员工号=员工表.员工号
and项目编号=@项目编号
group by所在部门号
declare@maxNumchar(4),@minNumchar(4)
select*from部门表
【结论】(结果、分析)
三、指导教师评语及成绩:
评语:
成绩:指导教师签名:
批阅日期:
from员工表,部门表
where员工表.所在部门号=部门表.部门号
and员工号=@员工号
(2)执行该存储过程,查询并显示员工号为‘2004’的姓名、年龄、性别和所在部门。
exec员工基本信息'2004'
二、使用SQL语句中的CREATE PROCEDURE命令创建存储过程。
(1)设计存储过程,完成对员工表的元组插入工作。要求使用输入参数。插入操作成功返出状态值0,失败返出状态值-1。
实验(实训)报告
项目名称存储过程设计
所属课程名称高级数据库
项目类型
实验(实训)日期2010-5-12
班级计算机科学与技术
学号0720410149
姓名朱优苗
指导教师孟宪虎
浙江财经学院教务处制
一、实验(实训)概述:
【目的及要求】
【基本原理】
【实施环境】(使用的材料、设备、软件)
计算机、Widows、SQL Server 2000、Word
ifexists(select*
fromsysobjects
wherename='员工表插入'and type='p')
begin
drop procedure员工表插入
end
go
create procedure员工表插入(@员工号char(4),@姓名char(8),@性别char(2),@出生年月varchar(60),@所在部门号char(4),@技术职称char(10),@工资money,@参加的项目总数int)
二、实验(实训)内容:
【项目内容】
【方案设计】
【实验(实训)过程】(步骤、记录、数据、程序等)
一、利用企业管理器创建存储过程。
(1)创建存储过程,通过员工号查询员工姓名、年龄、性别和所在部门(注意不是部门编号)。
create procedure员工基本信息(@员工号char(4))
AS
select姓名,year(getdate())-year(cast(出生年月asdatetime))年龄,性别,部门名
into#temp
from员工表
group by所在部门号
declare@maxNumchar(4),@minNumchar(4),@nint
select@maxNum=(select max(部门号))from部门表
select@minNum=(select min(部门号))from部门表
while(cast(@minNumas int)<=cast(@maxNumas int))
from员工表
where员工号=@员工号
if@技术职称='助理工程师'
update员工表
set工资=工资*1.1
where员工号=@员工号
if@技术职称='工程师'
update员工表
set工资=工资*1.15
where员工号=@员工号
if@技术职称='高级工程师'
update员工表
set工资=工资*1.2
ifexists(select*
fromsysobjects
wherename='工资修改'and type='p')
begin
drop procedure工资修改
end
go
create procedure工资修改(@员工号char(4))
as
declare@技术职称char(10)
select@技术职称=技术职称
begin
select@n=部门人数
from#temp
where所在部门号=@minNum
update部门表
set部门人数=@n
where部门号=@minNum
set@minNum=cast((cast(@minNumas int)+1)as char(4))
end
select*from部门表
exec部门人数修改
select@maxNum=(select max(部门人数))from#temp
select@minNum=(select min(部门人数))from#temp
select部门名as参加该项目最多人的部门
from部门表
where部门号=
(select所在部门号
from#temp
where部门人数=@maxNum)
as
begin tran
insert into员工表values(@员工号,@姓名,@性别,cast(@出生年月asdatetime),@所在部门号,@技术职称,@工资,@参加的项目总数)
if@@error<>0
begin
rollback tran
return-1
end
else
begin
commit tran
if@status=0
print'插入成功'
else
print'插入失败'
(2)编写以下存储过程并执行
1、指定部门,求该部门的总人数,总工资,平均工资,最高工资和最低工资。
ifexists(select*
fromsysobjects
wherename='部门查询'and type='p')
begin
显示部门表数据;
执行存储过程;
再显示部门表数据。
ifexists(select*
fromsysobjects
wherename='部门人数修改'and type='p')
gin
drop procedure部门人数修改
end
go
create procedure部门人数修改
as
selectcount(所在部门号)as部门人数,所在部门号
where员工表.所在部门号=部门表.部门号
and部门号=@部门号
group by部门号
exec部门查询'1001'
2、利用员工号查询员工参加的项目名称和该项目所在的城市,并要求显示员工的姓名。
ifexists(select*
fromsysobjects
wherename='项目查询'and type='p')
drop procedure部门查询
end
go
create procedure部门查询(@部门号char(4))
as
select部门号,count(员工号)as部门总人数,sum(工资)as部门总工资,avg(工资)as部门平均工资,max(工资)as部门最高工资,min(工资)as部门最低工资
from部门表,员工表
begin
drop procedure项目查询
end
go
create procedure项目查询(@员工号char(4))
as
select姓名,项目名称,所在地方as项目所在的城市