大数据结构实验二叉树
数据结构二叉树实验报告
一 、实验目的和要求(1)掌握树的相关概念,包括树、节点的度、树的度、分支节点、叶子节点、孩子节点、双亲节 点、树的深度、森林等定义。
(2)掌握树的表示,包括树形表示法、文氏图表示法、凹入表示法和括号表示法等。
(3)掌握二叉树的概念,包括二叉树、满二叉树和完全二叉树的定义。
(4)掌握二叉树的性质。
(5)重点掌握二叉树的存储结构,包括二叉树顺序存储结构和链式存储结构。
(6)重点掌握二叉树的基本运算和各种遍历算法的实现。
(7)掌握线索二叉树的概念和相关算法的实现。
(8)掌握哈夫曼树的定义、哈夫曼树的构造过程和哈夫曼编码的产生方法。
(9)掌握并查集的相关概念和算法。
(10)灵活运用二叉树这种数据结构解决一些综合应用问题。
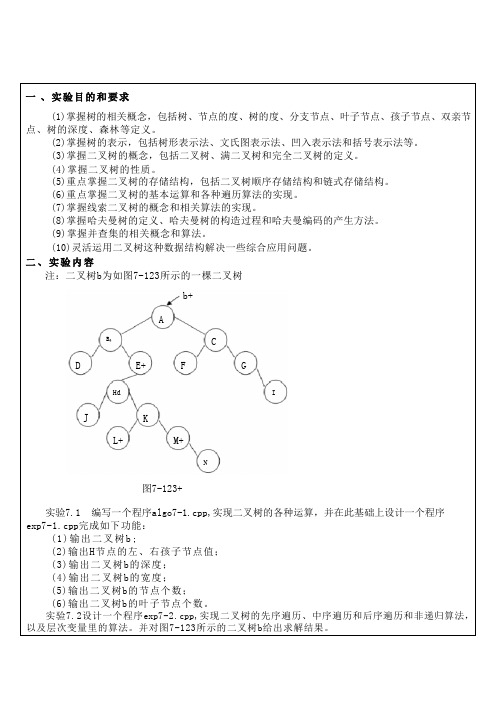
二、实验内容注:二叉树b 为如图7-123所示的一棵二叉树图7-123+实验7.1 编写一个程序algo7-1.cpp,实现二叉树的各种运算,并在此基础上设计一个程序exp7-1.cpp 完成如下功能:(1)输出二叉树b ;(2)输出H 节点的左、右孩子节点值; (3)输出二叉树b 的深度; (4)输出二叉树b 的宽度; (5)输出二叉树b 的节点个数;(6)输出二叉树b 的叶子节点个数。
实验7.2设计一个程序exp7-2.cpp,实现二叉树的先序遍历、中序遍历和后序遍历和非递归算法, 以及层次变量里的算法。
并对图7-123所示的二叉树b 给出求解结果。
b+ACF GIKL+NM+E+HdJD₄B臣1607-1.CPPif(b?-HULL)re3P4+;Qu[rear]-p-b;Qu[rear].1no=1;while(reart=front){Front++;b=Qu[front]-P;lnum-Qu[front].1no;if(b->Ichildt=NULL)rpar+t;Qu[rear]-p=b->1child;Qu[rear].Ino-lnun+1;if(D->rch11d?=NULL)1/根结点指针入队//根结点的层次编号为1 1/队列不为空1/队头出队1/左孩子入队1/右孩子入队redr+t;qu[rear]-p=b->rchild;Qu[rear].1no-lnun*1;}}nax-0;lnun-1;i-1;uhile(i<=rear){n=0;whdle(i<=rear ge Qu[1].1no==1num)n+t;it+;Inun-Qu[i].1n0;if(n>max)nax=n;}return max;田1607-1.CPPreturn max;}elsereturn o;口×int Modes(BTNode *D) //求二叉树D的结点个数int nun1,nun2;if(b==NULL)returng,else if(b->ichild==NULL&D->rchild==NULL)return 1;else{num1-Hodes(b->Ichild);num2=Nodes(b->rchild);return(num1+nun2+1);LeafNodes(BINode *D) //求二叉树p的叶子结点个数int num1,num2;1f(D==NULL)return 0;else if(b->1chi1d==NULLc& b->rch11d==NULL)return 1;else{num1-LeafModes(b->lchild);num2=LeafNodes(b->rchild);return(nun1+nun2);int程序执行结果如下:xCProrn FlslirosfViu l SudiollyPrjecslro7 LJebuglFoj7 ex<1)输出二叉树:A<B<D,E<H<J,K<L,M<,N>>>>),C<F,G<,I>>)<2)'H’结点:左孩子为J石孩子为K(3)二叉树b的深度:7<4)二叉树b的宽度:4(5)二叉树b的结点个数:14(6)二叉树b的叶子结点个数:6<?>释放二叉树bPress any key to continue实验7 . 2程序exp7-2.cpp设计如下:坠eTPT-2.EPP#include<stdio.h》winclude<malloc.h>deFn Masie 00typde chr ElemTyetypede sruct nde{ElemType data;stuc node *lclldstruct node rchild;》BTHode;extern vod reaeBNodeBTNode extrn void DispBTHode(BTNodeuoid ProrderBTNode *b)if(b?-NULL)- 回1 / 数据元素1 / 指向左孩子1 / 指向右孩子*eb car *str)xb1 / 先序遍历的递归算法1 / 访问根结点/ / 递归访问左子树1 7 递归访问右子树/ / 根结点入栈//栈不为空时循环/ / 退栈并访问该结点/ / 右孩子入栈{》v oidprintf(*c“,b->data); Preorder(b->lchild); Pre0rder(b->rchild);Preorder1(BTNode *b)BTNode xSt[Maxsize],*p;int top=-1;if(b!-HULL)top++;St[top]-b;uhle (op>-)p-St[top];top--;printf("%c“,p->data);if(p->rchild?-HULL)A约e程p7-2.CPPprintF(”后序逅历序列:\n");printf(" 递归算法=");Postorder(b);printf("\n");printf(“非递归算法:“);Postorder1(b);printf("\n");序执行结果如下:xCAPrograFleicsoftVisal SudlyrjecsProj 2Debuzlroj72ex"二叉树b:A(B(D,ECH<J,K(L,M<,N)>))),C(F,GC.I>))层次遍历序列:A B C D E F G H I J K L M N先序遍历序列:递归算法:A B D E H J K L M N C F G I非归算法:A B D E H J K L M N C F G I中序遍历序列:递归算法: D B J H L K M N E A F C G I非递归算法:D B J H L K M N E A F C G I后序遍历序列:递归算法: D J L N M K H E B F I G C A非递归算法:D J L N H K H E B F I G C APress any key to continue臼p7-3.CPP15Pp a t h[p a t h l e n]-b->d a t a;//将当前结点放入路径中p a t h l e n t+;/7路任长度培1Al1Path1(b->ichild,patn,pathlen);1/递归扫描左子树Al1Path1(b->rchild,path,pathlen); //递归扫描右子树pathlen-- ; //恢复环境uoid Longpath(BTNode *b,Elemtype path[1,int pathlen,Elemtype longpath[],int elongpatnien) int i;1f(b==NULL){if(pathlen>longpatnlen) //若当前路径更长,将路径保存在1ongpatn中for(i-pathlen-1;i>-8;i--)longpath[i]=path[1];longpathlen-pathlen;elsepath[pathlen]=b->data; pathlen4; //将当前结点放入路径中//路径长度增1iongPath(b->lchild,path₇pathlen,langpath,longpathien);//递归扫描左子树LongPath(b->rchiid,path,pathien,longpath,longpathien);//递归扫描石子树pathlen--; /7饮其环境oid DispLeaf(BTNode xb)- 口凶uoid DispLeaf(BTNode xb)iE(D!=NULL){ if(b->1child--HULL B& b->rchild--HULL)printf("3c“,b->data);elsepispLeaf(b->ichild);DispLeaf(b->rchild);oid nain()8TNodexb;ElenType patn[Maxsize],longpath[Maxsize];int i.longpathien-U;CreateBTNode(b,"A(B(D,E(H(J,K(L,H(,N))))),C(F,G(,I)))");printf("\n二灾树b:");DispBTNode(b);printf("\n\n*);printf(”b的叶子结点:");DispLeaf(b);printf("\n\n");printf("A11Path:");A11Path(b);printf("m");printf("AiiPath1:n");AliPath1(b.path.);printf("");LongPath(b,path,8,longpath,longpathlen);printf(”第一条量长路径长度=d\n”,longpathlen);printf(”"第一茶最长路径:");for(i=longpathlen;i>=0;i--)printf("c",longpatn[1]);printf("\n\n");。
数据结构实验报告 二叉树

数据结构实验报告二叉树数据结构实验报告:二叉树引言:数据结构是计算机科学中的重要基础,它为我们提供了存储和组织数据的方式。
二叉树作为一种常见的数据结构,广泛应用于各个领域。
本次实验旨在通过实践,深入理解二叉树的概念、性质和操作。
一、二叉树的定义与性质1.1 定义二叉树是一种特殊的树结构,每个节点最多有两个子节点,分别称为左子节点和右子节点。
二叉树可以为空树,也可以是由根节点和左右子树组成的非空树。
1.2 基本性质(1)每个节点最多有两个子节点;(2)左子树和右子树是有顺序的,不能颠倒;(3)二叉树的子树仍然是二叉树。
二、二叉树的遍历2.1 前序遍历前序遍历是指首先访问根节点,然后按照先左后右的顺序遍历左右子树。
在实际应用中,前序遍历常用于复制一颗二叉树或创建二叉树的副本。
2.2 中序遍历中序遍历是指按照先左后根再右的顺序遍历二叉树。
中序遍历的结果是一个有序序列,因此在二叉搜索树中特别有用。
2.3 后序遍历后序遍历是指按照先左后右再根的顺序遍历二叉树。
后序遍历常用于计算二叉树的表达式或释放二叉树的内存。
三、二叉树的实现与应用3.1 二叉树的存储结构二叉树的存储可以使用链式存储或顺序存储。
链式存储使用节点指针连接各个节点,而顺序存储则使用数组来表示二叉树。
3.2 二叉树的应用(1)二叉搜索树:二叉搜索树是一种特殊的二叉树,它的左子树上的节点都小于根节点,右子树上的节点都大于根节点。
二叉搜索树常用于实现查找、插入和删除等操作。
(2)堆:堆是一种特殊的二叉树,它满足堆序性质。
堆常用于实现优先队列,如操作系统中的进程调度。
(3)哈夫曼树:哈夫曼树是一种带权路径最短的二叉树,常用于数据压缩和编码。
四、实验结果与总结通过本次实验,我成功实现了二叉树的基本操作,包括创建二叉树、遍历二叉树和查找节点等。
在实践中,我进一步理解了二叉树的定义、性质和应用。
二叉树作为一种重要的数据结构,在计算机科学中有着广泛的应用,对于提高算法效率和解决实际问题具有重要意义。
数据结构实验报告二二叉树实验

实验报告课程名称:数据结构
第 1 页共4 页
五、实验总结(包括心得体会、问题回答及实验改进意见,可附页)
这次实验主要是建立二叉树,和二叉树的先序、中序、后续遍历算法。
通过这次实验,我巩固了二叉树这部分知识,从中体会理论知识的重要性。
在做实验之前,要充分的理解本次实验的理论依据,这样才能达到事半功倍的效果。
如果在没有真正理解实验原理之盲目的开始实验,只会浪费时间和精力。
例如进行二叉树的遍历的时候,要先理解各种遍历的特点。
先序遍历是先遍历根节点,再依次先序遍历左右子树。
中序遍历是先中序遍历左子树,再访问根节点,最后中序遍历右子树。
而后序遍历则是先依次后续遍历左右子树,再访问根节点。
掌握了这些,在实验中我们就可以融会贯通,举一反三。
其次要根据不光要懂得代码的原理,还要对题目有深刻的了解,要明白二叉树的画法,在纸上先进行自我演练,对照代码验证自己写的正确性。
第 3 页共4 页
第 4 页共4 页。
[精品]【数据结构】二叉树实验报告
![[精品]【数据结构】二叉树实验报告](https://img.taocdn.com/s3/m/5d561ae96e1aff00bed5b9f3f90f76c661374c27.png)
[精品]【数据结构】二叉树实验报告二叉树实验报告一、实验目的:1.掌握二叉树的基本操作;2.理解二叉树的性质;3.熟悉二叉树的广度优先遍历和深度优先遍历算法。
二、实验原理:1.二叉树是一种树形结构,由n(n>=0)个节点组成;2.每个节点最多有两个子节点,称为左子节点和右子节点;3.二叉树的遍历分为四种方式:前序遍历、中序遍历、后序遍历和层次遍历。
三、实验环境:1.编程语言:C++;2.编译器:Dev-C++。
四、实验内容:1.定义二叉树节点结构体:struct BinaryTreeNode{int data; // 节点数据BinaryTreeNode *leftChild; // 左子节点指针BinaryTreeNode *rightChild; // 右子节点指针};2.初始化二叉树:queue<BinaryTreeNode *> q; // 使用队列存储节点q.push(root);int i = 1; // 创建子节点while (!q.empty() && i < length){BinaryTreeNode *node = q.front();q.pop();if (data[i] != -1) // 创建左子节点 {BinaryTreeNode *leftChild = new BinaryTreeNode;leftChild->data = data[i];leftChild->leftChild = nullptr;leftChild->rightChild = nullptr;node->leftChild = leftChild;q.push(leftChild);}i++;if (data[i] != -1) // 创建右子节点 {BinaryTreeNode *rightChild = new BinaryTreeNode;rightChild->data = data[i];rightChild->leftChild = nullptr;rightChild->rightChild = nullptr;node->rightChild = rightChild;q.push(rightChild);}i++;}return root;}3.前序遍历二叉树:五、实验结果:输入:int data[] = {1, 2, 3, 4, -1, -1, 5, 6, -1, -1, 7, 8};输出:前序遍历结果:1 2 4 5 3 6 7 8中序遍历结果:4 2 5 1 6 3 7 8后序遍历结果:4 5 2 6 8 7 3 1层次遍历结果:1 2 3 4 5 6 7 8通过本次实验,我深入理解了二叉树的性质和遍历方式,并掌握了二叉树的基本操作。
数据结构二叉树的实验报告

数据结构二叉树的实验报告数据结构二叉树的实验报告一、引言数据结构是计算机科学中非常重要的一个领域,它研究如何组织和存储数据以便高效地访问和操作。
二叉树是数据结构中常见且重要的一种,它具有良好的灵活性和高效性,被广泛应用于各种领域。
本实验旨在通过实际操作和观察,深入了解二叉树的特性和应用。
二、实验目的1. 理解二叉树的基本概念和特性;2. 掌握二叉树的创建、遍历和查找等基本操作;3. 通过实验验证二叉树的性能和效果。
三、实验过程1. 二叉树的创建在实验中,我们首先需要创建一个二叉树。
通过输入一系列数据,我们可以按照特定的规则构建一棵二叉树。
例如,可以按照从小到大或从大到小的顺序将数据插入到二叉树中,以保证树的有序性。
2. 二叉树的遍历二叉树的遍历是指按照一定的次序访问二叉树中的所有节点。
常见的遍历方式有前序遍历、中序遍历和后序遍历。
前序遍历是先访问根节点,然后再依次遍历左子树和右子树;中序遍历是先遍历左子树,然后访问根节点,最后再遍历右子树;后序遍历是先遍历左子树,然后遍历右子树,最后访问根节点。
3. 二叉树的查找二叉树的查找是指在二叉树中寻找指定的节点。
常见的查找方式有深度优先搜索和广度优先搜索。
深度优先搜索是从根节点开始,沿着左子树一直向下搜索,直到找到目标节点或者到达叶子节点;广度优先搜索是从根节点开始,逐层遍历二叉树,直到找到目标节点或者遍历完所有节点。
四、实验结果通过实验,我们可以观察到二叉树的特性和性能。
在创建二叉树时,如果按照有序的方式插入数据,可以得到一棵平衡二叉树,其查找效率较高。
而如果按照无序的方式插入数据,可能得到一棵不平衡的二叉树,其查找效率较低。
在遍历二叉树时,不同的遍历方式会得到不同的结果。
前序遍历可以用于复制一棵二叉树,中序遍历可以用于对二叉树进行排序,后序遍历可以用于释放二叉树的内存。
在查找二叉树时,深度优先搜索和广度优先搜索各有优劣。
深度优先搜索在空间复杂度上较低,但可能会陷入死循环;广度优先搜索在时间复杂度上较低,但需要较大的空间开销。
数据结构实验报告—二叉树

数据结构实验报告—二叉树数据结构实验报告—二叉树引言二叉树是一种常用的数据结构,它由节点和边构成,每个节点最多有两个子节点。
在本次实验中,我们将对二叉树的基本结构和基本操作进行实现和测试,并深入了解它的特性和应用。
实验目的1. 掌握二叉树的基本概念和特性2. 熟练掌握二叉树的基本操作,包括创建、遍历和查找等3. 了解二叉树在实际应用中的使用场景实验内容1. 二叉树的定义和存储结构:我们将首先学习二叉树的定义,并实现二叉树的存储结构,包括节点的定义和节点指针的表示方法。
2. 二叉树的创建和初始化:我们将实现二叉树的创建和初始化操作,以便后续操作和测试使用。
3. 二叉树的遍历:我们将实现二叉树的前序、中序和后序遍历算法,并测试其正确性和效率。
4. 二叉树的查找:我们将实现二叉树的查找操作,包括查找节点和查找最大值、最小值等。
5. 二叉树的应用:我们将探讨二叉树在实际应用中的使用场景,如哈夫曼编码、二叉搜索树等。
二叉树的定义和存储结构二叉树是一种特殊的树形结构,它的每个节点最多有两个子节点。
节点被表示为一个由数据和指向其左右子节点的指针组成的结构。
二叉树可以分为三类:满二叉树、完全二叉树和非完全二叉树。
二叉树可以用链式存储结构或顺序存储结构表示。
- 链式存储结构:采用节点定义和指针表示法,通过将节点起来形成一个树状结构来表示二叉树。
- 顺序存储结构:采用数组存储节点信息,通过计算节点在数组中的位置来进行访问和操作。
二叉树的创建和初始化二叉树的创建和初始化是二叉树操作中的基础部分。
我们可以通过手动输入或读取外部文件中的数据来创建二叉树。
对于链式存储结构,我们需要自定义节点和指针,并通过节点的方式来构建二叉树。
对于顺序存储结构,我们需要定义数组和索引,通过索引计算来定位节点的位置。
一般来说,初始化一个二叉树可以使用以下步骤:1. 创建树根节点,并赋初值。
2. 创建子节点,并到父节点。
3. 重复步骤2,直到创建完整个二叉树。
数据结构二叉树实验报告
数据结构二叉树实验报告二叉树是一种常用的数据结构,它在计算机科学中有着广泛的应用。
本文将介绍二叉树的定义、基本操作以及一些常见的应用场景。
一、二叉树的定义和基本操作二叉树是一种特殊的树形结构,它的每个节点最多有两个子节点。
一个节点的左子节点称为左子树,右子节点称为右子树。
二叉树的示意图如下:```A/ \B C/ \D E```在二叉树中,每个节点可以有零个、一个或两个子节点。
如果一个节点没有子节点,我们称之为叶子节点。
在上面的示例中,节点 D 和 E 是叶子节点。
二叉树的基本操作包括插入节点、删除节点、查找节点和遍历节点。
插入节点操作可以将一个新节点插入到二叉树中的合适位置。
删除节点操作可以将一个指定的节点从二叉树中删除。
查找节点操作可以在二叉树中查找指定的节点。
遍历节点操作可以按照一定的顺序遍历二叉树中的所有节点。
二、二叉树的应用场景二叉树在计算机科学中有着广泛的应用。
下面将介绍一些常见的应用场景。
1. 二叉搜索树二叉搜索树是一种特殊的二叉树,它的每个节点的值都大于其左子树中的节点的值,小于其右子树中的节点的值。
二叉搜索树可以用来实现快速的查找、插入和删除操作。
它在数据库索引、字典等场景中有着重要的应用。
2. 堆堆是一种特殊的二叉树,它的每个节点的值都大于或小于其子节点的值。
堆可以用来实现优先队列,它在任务调度、操作系统中的内存管理等场景中有着重要的应用。
3. 表达式树表达式树是一种用来表示数学表达式的二叉树。
在表达式树中,每个节点可以是操作符或操作数。
表达式树可以用来实现数学表达式的计算,它在编译器、计算器等场景中有着重要的应用。
4. 平衡二叉树平衡二叉树是一种特殊的二叉树,它的左子树和右子树的高度差不超过1。
平衡二叉树可以用来实现高效的查找、插入和删除操作。
它在数据库索引、自平衡搜索树等场景中有着重要的应用。
三、总结二叉树是一种常用的数据结构,它在计算机科学中有着广泛的应用。
本文介绍了二叉树的定义、基本操作以及一些常见的应用场景。
数据结构二叉树的实验报告
数据结构实验报告1. 实验目的和内容:掌握二叉树基本操作的实现方法2. 程序分析2.1存储结构链式存储2.程序流程2.3关键算法分析算法一:Create(BiNode<T>* &R,T data[],int i,int n)【1】算法功能:创建二叉树【2】算法基本思想:利用顺序存储结构为输入,采用先建立根结点,再建立左右孩子的方法来递归建立二叉链表的二叉树【3】算法空间时间复杂度分析:O(n)【4】代码逻辑:如果位置小于数组的长度则{ 创建根结点将数组的值赋给刚才创建的结点的数据域创建左子树,如果当前结点位置为i,则左孩子位置为2i创建右子树,如果当前结点位置为i,则右孩子位置为2i+1}否则R为空算法二:CopyTree(BiNode<T>*sR,BiNode<T>* &dR))【1】算法功能:复制构造函数【2】算法基本思想:按照先创建根结点,再递归创建左右子树的方法来实现。
【3】算法空间时间复杂度分析:O(n)【4】代码逻辑:如果源二叉树根结点不为空则{创建根结点调用函数自身,创建左子树调用函数自身,创建右子树}将该函数放在复制构造函数中调用,就可以实现复制构造函数算法三:PreOrder(BiNode<T>*R)【1】算法功能:二叉树的前序遍历【2】算法基本思想:这个代码用的是优化算法,提前让当前结点出栈。
【3】算法空间时间复杂度分析:O(n)【4】代码逻辑(伪代码)如果当前结点为非空,则{访问当前结点当前结点入栈将当前结点的左孩子作为当前结点}如果为空{则栈顶结点出栈则将该结点的右孩子作为当前结点}反复执行这两个过程,直到结点为空并且栈空算法四:InOrder(BiNode<T>*R)【1】算法功能:二叉树的中序遍历【2】算法基本思想:递归【3】算法空间时间复杂度分析:未知【4】代码逻辑:如果R为非空:则调用函数自身遍历左孩子访问该结点再调用自身访问该结点的右孩子算法五:LevelOrder(BiNode<T>*R)【1】算法功能:二叉树的层序遍历【2】算法基本思想:【3】算法空间时间复杂度分析:O(n)【4】代码逻辑(伪代码):如果队列不空{对头元素出队访问该元素若该结点的左孩子为非空,则左孩子入队;若该结点的右孩子为非空,则右孩子入队;}算法六:Count(BiNode<T>*R)【1】算法功能:计算结点的个数【2】算法基本思想:递归【3】算法空间时间复杂度分析:未知【4】代码逻辑:如果R不为空的话{调用函数自身计算左孩子的结点数调用函数自身计算右孩子的结点数}template<class T>int BiTree<T>::Count(BiNode<T>*R){if(R==NULL)return 0;else{int m=Count(R->lchild);int n=Count(R->rchild);return m+n+1;}}算法七:Release(BiNode<T>*R)【1】算法功能:释放动态内存【2】算法基本思想:左右子树全部释放完毕后再释放该结点【3】算法空间时间复杂度分析:未知【4】代码逻辑:调用函数自身,释放左子树调用函数自身,释放右子树释放根结点释放二叉树template<class T>void BiTree<T>::Release(BiNode<T>*R) {if(R!=NULL){Release(R->lchild);Release(R->rchild);delete R;}}template<class T>BiTree<T>::~BiTree(){Release(root);}int main(){BiTree<int> BTree(a,10);BiTree<int>Tree(BTree);BTree.PreOrder(BTree.root);cout<<endl;Tree.PreOrder(Tree.root);cout<<endl;BTree.InOrder(BTree.root);cout<<endl;Tree.InOrder(Tree.root);cout<<endl;BTree.PostOrder(BTree.root);cout<<endl;Tree.PostOrder(Tree.root);cout<<endl;BTree.LevelOrder(BTree.root);cout<<endl;Tree.LevelOrder(Tree.root);cout<<endl;int m=BTree.Count(BTree.root);cout<<m<<endl;return 0;}3.测试数据:int a[10]={1,2,3,4,5};1 2 4 5 31 2 4 5 34 25 1 34 5 2 3 11 2 3 4 554.总结:4.1:这次实验大多用了递归的算法,比较好理解。
数据结构二叉树实验报告
数据结构二叉树实验报告1. 引言二叉树是一种常见的数据结构,由节点(Node)和链接(Link)构成。
每个节点最多有两个子节点,分别称为左子节点和右子节点。
二叉树在计算机科学中被广泛应用,例如在搜索算法中,二叉树可以用来快速查找和插入数据。
本实验旨在通过编写二叉树的基本操作来深入理解二叉树的特性和实现方式。
2. 实验内容2.1 二叉树的定义二叉树可以用以下方式定义:class TreeNode:def__init__(self, val):self.val = valself.left =Noneself.right =None每个节点包含一个值和两个指针,分别指向左子节点和右子节点。
根据需求,可以为节点添加其他属性。
2.2 二叉树的基本操作本实验主要涉及以下二叉树的基本操作:•创建二叉树:根据给定的节点值构建二叉树。
•遍历二叉树:将二叉树的节点按照特定顺序访问。
•查找节点:在二叉树中查找特定值的节点。
•插入节点:向二叉树中插入新节点。
•删除节点:从二叉树中删除特定值的节点。
以上操作将在下面章节详细讨论。
3. 实验步骤3.1 创建二叉树二叉树可以通过递归的方式构建。
以创建一个简单的二叉树为例:def create_binary_tree():root = TreeNode(1)root.left = TreeNode(2)root.right = TreeNode(3)root.left.left = TreeNode(4)root.left.right = TreeNode(5)return root以上代码创建了一个二叉树,根节点的值为1,左子节点值为2,右子节点值为3,左子节点的左子节点值为4,左子节点的右子节点值为5。
3.2 遍历二叉树二叉树的遍历方式有多种,包括前序遍历、中序遍历和后序遍历。
以下是三种遍历方式的代码实现:•前序遍历:def preorder_traversal(root):if root:print(root.val)preorder_traversal(root.left)preorder_traversal(root.right)•中序遍历:def inorder_traversal(root):if root:inorder_traversal(root.left)print(root.val)inorder_traversal(root.right)•后序遍历:def postorder_traversal(root):if root:postorder_traversal(root.left)postorder_traversal(root.right)print(root.val)3.3 查找节点在二叉树中查找特定值的节点可以使用递归的方式实现。
数据结构二叉树实验报告总结
数据结构二叉树实验报告总结一、实验目的本次实验的主要目的是通过对二叉树的学习和实践,掌握二叉树的基本概念、性质和遍历方式,加深对数据结构中树形结构的理解。
二、实验内容1. 二叉树的基本概念和性质在本次实验中,我们首先学习了二叉树的基本概念和性质。
其中,二叉树是由节点组成的有限集合,并且每个节点最多有两个子节点。
同时,我们还学习了二叉树的高度、深度、层数等概念。
2. 二叉树的遍历方式在了解了二叉树的基本概念和性质之后,我们开始学习如何遍历一个二叉树。
在本次实验中,我们主要学习了三种遍历方式:前序遍历、中序遍历和后序遍历。
其中,前序遍历指先访问节点自身再访问左右子节点;中序遍历指先访问左子节点再访问自身和右子节点;后序遍历指先访问左右子节点再访问自身。
3. 二叉搜索树除了以上内容之外,在本次实验中我们还学习了一种特殊的二叉树——二叉搜索树。
二叉搜索树是一种特殊的二叉树,它的每个节点都满足左子节点小于该节点,右子节点大于该节点的性质。
由于这个性质,二叉搜索树可以被用来进行快速查找、排序等操作。
三、实验过程1. 实现二叉树的遍历方式为了更好地理解和掌握二叉树的遍历方式,我们首先在编程环境中实现了前序遍历、中序遍历和后序遍历。
在代码编写过程中,我们需要考虑如何递归地访问每个节点,并且需要注意访问顺序。
2. 实现二叉搜索树为了更好地理解和掌握二叉搜索树的特性和操作,我们在编程环境中实现了一个简单的二叉搜索树。
在代码编写过程中,我们需要考虑如何插入新节点、删除指定节点以及查找目标节点等操作。
3. 实验结果分析通过对代码运行结果进行分析,我们可以清晰地看到每个遍历方式所得到的结果以及对应的顺序。
同时,在对二叉搜索树进行操作时,我们也可以看到不同操作所产生的不同结果。
四、实验总结通过本次实验,我们进一步加深了对二叉树的理解和掌握,学习了二叉树的遍历方式以及二叉搜索树的特性和操作。
同时,在编程实践中,我们也进一步熟悉了代码编写和调试的过程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验六:二叉树及其应用一、实验目的树是数据结构中应用极为广泛的非线性结构,本单元的实验达到熟悉二叉树的存储结构的特性,以及如何应用树结构解决具体问题。
二、问题描述首先,掌握二叉树的各种存储结构和熟悉对二叉树的基本操作。
其次,以二叉树表示算术表达式的基础上,设计一个十进制的四则运算的计算器。
如算术表达式:a+b*(c-d)-e/f三、实验要求如果利用完全二叉树的性质和二叉链表结构建立一棵二叉树,分别计算统计叶子结点的个数。
求二叉树的深度。
十进制的四则运算的计算器可以接收用户来自键盘的输入。
由输入的表达式字符串动态生成算术表达式所对应的二叉树。
自动完成求值运算和输出结果。
四、实验环境PC微机DOS操作系统或Windows 操作系统Turbo C 程序集成环境或Visual C++ 程序集成环境五、实验步骤1、根据二叉树的各种存储结构建立二叉树;2、设计求叶子结点个数算法和树的深度算法;3、根据表达式建立相应的二叉树,生成表达式树的模块;4、根据表达式树,求出表达式值,生成求值模块;5、程序运行效果,测试数据分析算法。
六、测试数据1、输入数据:2.2*(3.1+1.20)-7.5/3正确结果:6.962、输入数据:(1+2)*3+(5+6*7);正确输出:56七、表达式求值由于表达式求值算法较为复杂,所以单独列出来加以分析:1、主要思路:由于操作数是任意的实数,所以必须将原始的中缀表达式中的操作数、操作符以及括号分解出来,并以字符串的形式保存;然后再将其转换为后缀表达式的顺序,后缀表达式可以很容易地利用堆栈计算出表达式的值。
例如有如下的中缀表达式:a+b-c转换成后缀表达式为:ab+c-然后分别按从左到右放入栈中,如果碰到操作符就从栈中弹出两个操作数进行运算,最后再将运算结果放入栈中,依次进行直到表达式结束。
如上述的后缀表达式先将a 和b 放入栈中,然后碰到操作符“+”,则从栈中弹出a 和b 进行a+b 的运算,并将其结果d(假设为d)放入栈中,然后再将c 放入栈中,最后是操作符“-”,所以再弹出d和c 进行d-c 运算,并将其结果再次放入栈中,此时表达式结束,则栈中的元素值就是该表达式最后的运算结果。
当然将原始的中缀表达式转换为后缀表达式比较关键,要同时考虑操作符的优先级以及对有括号的情况下的处理,相关容会在算法具体实现中详细讨论。
2、求值过程一、将原始的中缀表达式中的操作数、操作符以及括号按顺序分解出来,并以字符串的形式保存。
二、将分解的中缀表达式转换为后缀表达式的形式,即调整各项字符串的顺序,并将括号处理掉。
三、计算后缀表达式的值。
3、中缀表达式分解DivideExpressionToItem()函数。
分解出原始中缀表达式中的操作数、操作符以及括号,保存在队列中,以本实验中的数据为例,分解完成后队列中的保存顺序如下图所示:队首队尾其算法思想是:从左往右按一个字节依次扫描原始中缀表达式m_string,碰到连续的数字或小数点就加到string 变量str 中;如果碰到括号或操作符就将原先的str 推入队列,然后将括号或操作符赋予str,再将str 推入队列,并将str 赋予空值,依次循环进行直到扫描m_string 完成。
4、转化为后缀表达式ChangeToSuffix()函数。
将保存在队列中的中缀表达式转换为后缀表达式,并保存在栈中。
这个函数也是整个表达式算法的关键,这里需要两个栈stack_A 和stack_B,分别在转换过程中临时存放后缀表达式的操作数与操作符。
依次从中缀表达式队列que 中出列一个元素,并保存在一个string 变量str 中,然后按以下几方面进行处理:①如果str 是“(”,则将str 推入栈stack_B。
②如果str 是“)”,则要考虑stack_B 的栈顶是不是“(”,是的话就将“(”出栈stack_B;如果不是,则将stack_B 出栈一个元素(操作符),然后将其推入栈stack_A。
③如果str 是“+”或“-”,则要考虑有括号和优先级的情况,如果栈stack_B 为空或者栈顶为“(”,则将str 推入栈stack_B;因为操作符“+”和“-”优先级相同(谁先出现就先处理谁进栈stack_A),并且低于“*”和“/”,所以当栈stack_B 不为空并且栈顶不为“(”,则依次循环取出stack_B 的栈顶元素并依次推入栈stack_A,循环结束后再将str 推入栈stack_B。
④如果str 是“*”或“/”,因为它们的优先级相同并且高于“+”和“-”,所以如果栈stack_B 为空或者栈顶为“+”、“-”或“(”就直接将str 推入栈stack_B;否则就将stack_B 弹出一个元素并将其推入栈stack_A 中,然后再将str 推入栈stack_B 中。
⑤除了上述情况外就只剩下操作数了,操作数就可以直接推入栈stack_A 中。
注意整个过程中栈stack_B 中的元素只能是如下几种:“(”、“+”、“-”、“*”、“/”,而最终栈stack_A 保存的是后缀表达式。
只有操作数和操作符,如下图所示:表达式二叉树栈底栈顶栈示意图注意到最后返回的是stack_B 而不是stack_A,因为考虑到为了后面的计算方便,所以将其倒序保存在stack_B 中(最后一个while循环)。
5、后缀表达式求值Calculate()函数。
剩下的计算后缀表达式就显得非常简单了,依次将倒序的后缀表达式stack_B 弹出一个元素推入保存结果的double 类型的栈stack 中,如果遇到操作符就从栈stack 中弹出两元素进行该操作符的运算并将其结果推入到栈stack 中,依次循环进行直到栈stack_B 为空,最后栈stack 只有一个元素即为表达式的结果。
八、实验报告要求实验报告应包括以下几个部分:1、设计算术表达式树的存储结构;实验中采用的是二叉树的的存储。
结点格式如下:其严格类的定义如下:template <typename T>class Binarynode //二叉树的结点类{public:Binarynode():left(NULL),right(NULL){} //默认构造函数Binarynode(const T& item,Binarynode<T> *lptr=NULL,Binarynode<T> *rptr=NULL):data(item),left(lptr),right(rptr){} //初始化T data; //结点数据Binarynode<T> *&Left() {return left;} //取leftBinarynode<T> *&Right() {return right;} //取rightprotected:Binarynode<T> *left,*right;};2、给出二叉树中叶子结点个数算法和树的深度算法描述;叶子结点个数算法:template<typename T>void Leafcount(Binarynode<T>*t,int *c) //计算树叶子的个数{ //t为构建的树,c用来返回叶子节点个数if (t) //树不为空{if (t->Left()==NULL&&t->Right()==NULL)//若该结点左右均为空,为叶子结点{*c=*c+1;}Leafcount(t->Left(),c); //左子树递归求叶子结点Leafcount(t->Right(),c); //右子树递归求叶子结点}}树的深度算法:int Depth(Binarynode<T>*t) //计算树的深度{int lh,rh; //定义左右子树的深度if (!t) return 0; //树为空返回0else{lh=Depth(t->Left()); //递归调用,求左子树深度rh=Depth(t->Right()); //递归调用,求右子树深度if (lh>rh) //判断左右子树哪个更大,更大的深度加1返回其值return lh+1;elsereturn rh+1;}return 1;}3、相应的程序要给出足够的注释部分;参见九、附录,由于在报告中分析的算法,在附录源程序中省略部分注释,以免繁杂。
4、给出程序的测试结果验证各项程序功能如下:(1)进入模块选择进入模块一:进入模块二:(2)四种遍历以先序序列为A B D E C F ,中序序列D B E A F C为例:(3)求树的叶子结点数和树的深度(4)求表达式的值1、输入数据:2.2*(3.1+1.20)-7.5/3正确结果:6.962、输入数据:(1+2)*3+(5+6*7);正确输出:56九、思考题与实验总结1、分析利用完全二叉树的性质和二叉链表存储有什么不同?分析其优缺点。
其实利用完全二叉树的性质的存储本质上是顺序存储,但是又区别于一般的顺序存储,由于树无法在顺序表直接进行存储,所以在描述二叉树的时候规定树从左到右,从上到下依次存储树结点,不存在的结点也要存储,其以0表示,对于完全二叉树来讲,只要知道结点在树中的编号,就能迅速定位该结点,但是由于要存储0来表示空结点,在结点数庞大的时候会有可能浪费空间。
最后,它若要增加结点,若新增结点已超出围,则必须要重新申请空间。
而二叉链表存储则是典型链表存储,它要利用指针来指向其左右孩子。
如果要查找某一结点,必须从根出发,但是不会像利用完全二叉树的性质存储那样浪费不必要的空间。
在增加结点时更容易。
综上分析,其优缺点:完全二叉树性质存储:优点,查找结点速度快,易于理解,在结点数少的情况下,存储方便。
缺点,存储大量结点可能会浪费大量空间,增加结点复杂。
二叉链表存储:优点,增加结点容易,易于存储结点数比较大的树。
而且指针灵活的应用,更易与在树上进行复杂的操作。
缺点,查找结点必须从根出发,依次遍历。
2、增加输入表达式进行语法判错的功能。
IsWellForm()函数。
判断原始中缀表达式的括号是否匹配,可以利用栈简单实现,即遇到“(”进栈,遇到“)”就从栈中弹出一个元素,直到表达式结束。
如果栈为空则表示括号匹配,否则不匹配。
其具体实现见附录。
下面是程序的试验:3.实验总结实验终于完成了,相对来说难度很大,不过由于这个是数据结构的重中之重,所以花了蛮多的心思的,树的确有很多优点,使得它如此举足轻重,它可以勾勒生活中的方方面面的关系,特别在当今社会数据关系如此复杂的情况下,它独享风光是可以理解的。
不过由于它结构复杂多变,所以存储起来就颇为费劲了,这造成了我在实验中吃苦头的主要因素。