21秋东财《数据分析与决策》单元作业二
东北财经大学《大数据——概念、方法与应用》在线作业2-0017

东财《大数据——概念、方法与应用》在线作业2-0017
大数据的核心是( )。
A:预测
B:匿名化
C:规模化
D:告知与许可
参考选项:A
采样分析的精确性随着采样随机性的增加而( ),但与样本数量的增加关系不大。
A:提高
B:降低
C:不变
D:无关
参考选项:A
( )一些基金公司开始借助社交媒体大数据,分析市场情绪变动。
A:美国
B:法国
C:英国
D:中国
参考选项:A
在大数据时代,我们需要设立一个不一样的隐私保护模式,这个模式应该更着重于( )为其行为承担责任。
A:数据分析者
B:数据提供者
C:数据使用者
D:个人许可
参考选项:C
对于大数据,其最大的风险就是( )。
A:隐私
B:非结构化
C:数据量大
D:成本
参考选项:A
小数据时代,( )成为现代社会、现代测量领域的主心骨。
A:统计分析
B:主观采样
C:随机采样
1。
东北财经大学《大数据——概念、方法与应用》在线作业2-0002

东财《大数据——概念、方法与应用》在线作业2-0002
根据国家数据公司(IDC)统计,2010年人类已经进入( )时代。
A:ZB
B:GB
C:MB
D:TB
参考选项:A
两个或多个变量的( )之间存在某种规律性,就称为关联。
A:范围
B:特点
C:取值
D:字段
参考选项:C
下列属于半结构化数据的是( )。
A:视频数据
B:网络日志
C:文本数据
D:音频数据
参考选项:B
关于数据创新,下列说法正确的是( )。
A:数据只有开放价值才能得到真正释放
B:由于数据的再利用,数据应该永久保存下去
C:多个数据集的总和价值等于单个数据集价值相加
D:相同数据多次用于相同或类似用途,其有效性会降低
参考选项:A
大数据的样本空间是数据的( )。
A:抽样
B:关键部分
C:总体
D:部分
参考选项:C
数据挖掘的分类方法是找出数据库中一组数据对象的( )并按照分类模式将其划分为不同的类。
A:属性
B:值
C:不同点
D:共同点
1。
东北财经大学《数据分析与决策》综合作业

东财《数据分析与决策》综合作业
绝大多数的数据分析算法均是按照()的输入来实现的。
A:关系型
B:网状型
C:树型
D:混合型
参考选项:A
两步聚类算法是一种()算法。
A:分层聚类
B:K均值聚类
C:凝聚聚类
D:Kohonen network
参考选项:A
下列选项中,对有监督的建模技术理解错误的是()。
A:有监督的建模技术必须有一个模型的训练过程
B:模型训练的目的是“在已知目标值的情况下,试图找出预测变量与目标值之间的有效推理方式”
C:输出数据是预测变量
D:有监督的建模技术分为分类或者倾向和估计或回归
参考选项:C
当一个项目集I的相对支持度满足预先指定的()支持度阈值,项目集I就是一个频繁项目集。
A:最大
B:最小
C:固定
D:随机
参考选项:B
决策者在使用决策管理系统时,使用频度最高的是()。
A:测试
B:场景分析
C:What-If分析
D:验证
参考选项:A
下列说法中关于“分箱”的说法错误的是()。
A:数据分箱可以用来对数据进行平滑处理与去除噪声
B:数据分箱不可以对数据进行离散化处理
C:可视化分箱可以将现有字段的连续指进行分组
1。
《数据、模型和决策》习题解答
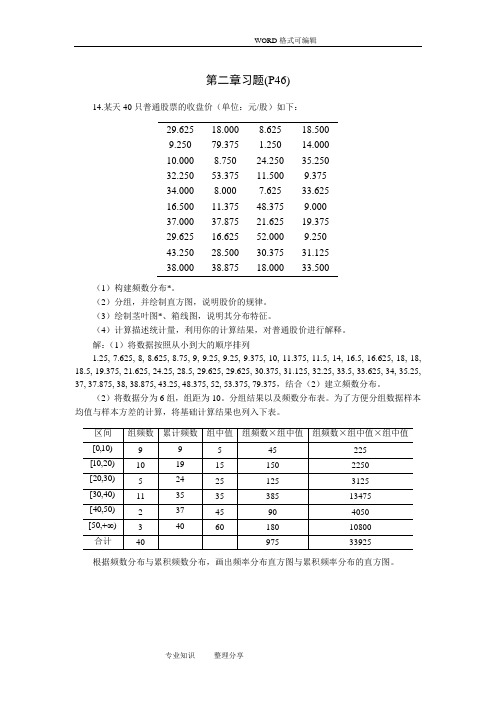
第二章习题(P46)14.某天40只普通股票的收盘价(单位:元/股)如下:29.625 18.000 8.625 18.5009.250 79.375 1.250 14.00010.000 8.750 24.250 35.25032.250 53.375 11.500 9.37534.000 8.000 7.625 33.62516.500 11.375 48.375 9.00037.000 37.875 21.625 19.37529.625 16.625 52.000 9.25043.250 28.500 30.375 31.12538.000 38.875 18.000 33.500(1)构建频数分布*。
(2)分组,并绘制直方图,说明股价的规律。
(3)绘制茎叶图*、箱线图,说明其分布特征。
(4)计算描述统计量,利用你的计算结果,对普通股价进行解释。
解:(1)将数据按照从小到大的顺序排列1.25, 7.625, 8, 8.625, 8.75, 9, 9.25, 9.25, 9.375, 10, 11.375, 11.5, 14, 16.5, 16.625, 18, 18, 18.5, 19.375, 21.625, 24.25, 28.5, 29.625, 29.625, 30.375, 31.125, 32.25, 33.5, 33.625, 34, 35.25, 37, 37.875, 38, 38.875, 43.25, 48.375, 52, 53.375, 79.375,结合(2)建立频数分布。
(2)将数据分为6组,组距为10。
分组结果以及频数分布表。
为了方便分组数据样本均值与样本方差的计算,将基础计算结果也列入下表。
根据频数分布与累积频数分布,画出频率分布直方图与累积频率分布的直方图。
频率分布直方图从频率直方图和累计频率直方图可以看出股价的规律。
股价分布10元以下、10—20元、30—40元占到60%,股价在40元以下占87.5%,分布不服从正态分布等等。
《数据分析与决策》20年秋 东财在线机考 模拟试题答案

一、单项选择题(下列每小题的备选标准答案中,只有一个正确标准答案)
1. 下列对于随机误差的理解错误的是()。
A. 随机误差是由于众多其他未考虑因素导致的
B. 在选择自变量时,如果遗漏了重要的因变量,则随机误差就比较大
C. 回归函数的类型选择不会对随机误差产生任何影响
D. 随机误差的方差越小,则回归函数就越逼近与因变量
标准答案:C
2. 显著性水平主要看()区间所能承担的风险来决定。
A. 接受
B. 拒绝
C. 置信
D. 极限
标准答案:B
3. 下列选项中不属于噪声数据产生原因的是()。
A. 数据收集的设备不稳定
B. 人们在人机界面的操作失误
C. 用户在应用过程中导致某些字段信息丢失
D. 数据转化过程中的逻辑错误
标准答案:C。
东北财经大学《大数据——概念、方法与应用》在线作业2-0030

东财《大数据——概念、方法与应用》在线作业2-0030
从商业层面上看,数据挖掘是一类( )数据分析方法。
A:浅层次的
B:深层次的
C:多元化的
D:多方法的
参考选项:B
偏差检测的基本方法是寻找( )之间有意义的差别。
A:期望值与预测值
B:预测值与参照值
C:观测值与参照值
D:期望值与参照值
参考选项:C
在小数据时代,当样本数量达到某个值之后,我们从个体上得到的信息会( )。
A:不确定
B:不变
C:越多
D:越少
参考选项:D
( )是一些管理方面的最佳实践。
A:数据质量和管理
B:数据挖掘
C:可视化分析
D:预测性分析
参考选项:A
大数据的核心是( )。
A:预测
B:匿名化
C:规模化
D:告知与许可
参考选项:A
小数据时代,( )成为现代社会、现代测量领域的主心骨。
A:统计分析
B:主观采样
C:随机采样
D:大数据分析
参考选项:C
1。
《数据、模型与决策》习题解答 (2)

第二章习题(P46)14.某天40只普通股票的收盘价(单位:元/股)如下:29.625 18.000 8.625 18.5009.250 79.375 1.250 14.00010.000 8.750 24.250 35.25032.250 53.375 11.500 9.37534.000 8.000 7.625 33.62516.500 11.375 48.375 9.00037.000 37.875 21.625 19.37529.625 16.625 52.000 9.25043.250 28.500 30.375 31.12538.000 38.875 18.000 33.500(1)构建频数分布*。
(2)分组,并绘制直方图,说明股价的规律。
(3)绘制茎叶图*、箱线图,说明其分布特征。
(4)计算描述统计量,利用你的计算结果,对普通股价进行解释。
解:(1)将数据按照从小到大的顺序排列1.25, 7.625, 8, 8.625, 8.75, 9, 9.25, 9.25, 9.375, 10, 11.375, 11.5, 14, 16.5, 16.625, 18, 18, 18.5, 19.375, 21.625, 24.25, 28.5, 29.625, 29.625, 30.375, 31.125, 32.25, 33.5, 33.625, 34, 35.25, 37, 37.875, 38, 38.875, 43.25, 48.375, 52, 53.375, 79.375,结合(2)建立频数分布。
(2)将数据分为6组,组距为10。
分组结果以及频数分布表。
为了方便分组数据样本均值与样本方差的计算,将基础计算结果也列入下表。
根据频数分布与累积频数分布,画出频率分布直方图与累积频率分布的直方图。
频率分布直方图从频率直方图和累计频率直方图可以看出股价的规律。
股价分布10元以下、10—20元、30—40元占到60%,股价在40元以下占87.5%,分布不服从正态分布等等。
数据分析与决策支持练习题

数据分析与决策支持练习题在当今数字化的时代,数据已成为企业和组织决策的重要依据。
数据分析能够帮助我们从海量的数据中提取有价值的信息,为决策提供有力的支持。
下面让我们通过一些练习题来深入理解数据分析与决策支持的关系和应用。
一、数据收集与整理假设我们是一家电商公司,想要了解用户的购买行为和偏好。
首先,我们需要收集相关的数据。
以下是可能需要收集的数据类型:1、用户基本信息:包括年龄、性别、地域、职业等。
2、购买记录:购买的商品名称、价格、购买时间、购买数量等。
3、浏览记录:浏览的商品页面、停留时间、搜索关键词等。
现在,我们已经收集到了大量的数据,但是这些数据往往是杂乱无章的。
接下来,我们需要对数据进行整理和清洗。
例如,去除重复的数据、纠正错误的数据、补充缺失的数据等。
练习题:1、给定一份包含用户购买记录的数据集,其中存在一些重复的记录和错误的价格信息。
请编写代码或使用工具来去除重复记录,并纠正错误的价格信息。
2、有一个用户信息表,其中部分用户的年龄字段缺失。
请根据其他相关字段(如购买的商品类型、消费金额等),使用合适的方法来估算缺失的年龄值。
二、数据分析方法在整理好数据后,我们就可以运用各种数据分析方法来挖掘数据中的潜在规律和趋势。
常见的数据分析方法包括:1、描述性统计分析:计算数据的均值、中位数、众数、标准差等统计量,以了解数据的集中趋势和离散程度。
2、相关性分析:研究两个或多个变量之间的关系,例如用户年龄与购买金额之间是否存在相关性。
3、分类与聚类分析:将数据按照一定的规则进行分类或聚类,比如将用户分为不同的消费群体。
练习题:1、针对上述电商公司的用户购买数据,计算每个商品类别的平均购买金额和购买频率,并绘制图表展示结果。
2、分析用户的购买行为与地域之间的相关性,判断不同地域的用户在购买偏好上是否存在显著差异。
三、数据可视化数据可视化能够将复杂的数据以直观、易懂的形式展现出来,帮助决策者快速获取关键信息。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
21秋东财《数据分析与决策》单元作
业二
数据分析与决策-东财《数据分析与决策》单元作业二
试卷总分:100得分:100
第1题,通常用时间转换方法将季节性变化转换为
A、加法季节性变化
B、减法季节性变化
C、乘法积极性变化
D、除法季节性变化
正确:
第2题,CARMA算法只需要对数据进行次扫描就可以获得比Apriori算法更低的支持度的结果
A、
一
B、两
C、三
D、四
正确:
第3题,Apriori算法中的发现频繁项目集步骤中首先扫描数据从中发现包含个项的项目集
A、1
B、2
C、3
D、4
正确:
第4题,下列关于聚类的说法错误的是
A、聚类分析适合探讨样本间相互关联关系从而对一个样本结构做一个初步的评价
B、聚类是一种监督的学习方法。
C、聚类不依赖于事先确定的数据类别
D、聚类是观察式学习
正确:
决定选择何种时间序列分析法的原则包括
A、要解决的问题
B、目的
C、时间
D、时间序列数据的特点
正确:B,D
第6题,利用时间散点图可以分析时间序列是否存在
A、趋势
B、季节性变化
C、离群值
D、缺失值
正确:,B,C,D
第7题,时间序列的特征主要有
A、趋势
B、季节性周期性变化
C、连续值
D、离群值
正确:B,D
第8题,K均值聚类算法的输入包括
A、聚类个数K
B、初始中心
C、n个数据对象
D、方差
正确:C
第9题,BIRCH聚类算法在决定将某个记录划归到某个树上的节点时会考虑该记录的特征
A、变量的均值
B、变量的标准差
C、变量的方差
D、变量每一个分类的个数
正确:,C,D
发现关联规则的步骤是
A、预选指定一个最小支持度计数阈值
B、找到所有超过这个值的项目集
C、从频繁项目集中产生强关联规则
D、从频繁项目集中产生弱关联规则
正确:,B,C
第11题,同指数平滑法相比自回归模型具有
A、灵便性
B、通用性
C、可靠性
D、合用性
正确:B
考察聚类内的特征主要有
A、标准差
B、聚类半径
C、SSE
D、SSB
正确:B,C
第13题,通过BIRCH聚类算法处理过的数据需要进行离群值的处理
T、对
F、错
第14题,从数据中发现关联规则的问题可以转变为发现频繁项目集
T、对
F、错
如果将自回归模型和挪移平均模型结合就能得到一个既包含自回归又包含挪移平均的更精确的时间序列分析方法
T、对
F、错
第16题,当提升度小于1时表明其中一个项集的浮现降低了另一个项集浮现的可能性T、对
F、错
第17题,聚类中相似或者不相似是基于数据描
述属性的取值来确定的
T、对
F、错
第18题,如果当前时间点的值需要通过前两个时间点值的回归加之随机误差来计算则称之为二阶自回归AR2
T、对
F、错
Word 文档下载后可自行编辑
第19题,对于时间序列的测量值既可以是连续数据也可以是离散数据
T、对
F、错
简单挪移平均法的各元素的权重要有所差
力门
T、对
F、错
正确:F。