层次分析法模型
评估模型研究_层次分析法

2•评估方法概述2.1层次分析法(AHP)层次分析法(Analytic Hierarchy Process,简称AHP)是对一些较为复杂、较为模糊的问题作出决策的简易方法,它特别适用于那些难于完全定量分析的问题。
它是美国运筹学家T. L. Saaty教授于20世纪70年代初期提出的一种简便、灵活而又实用的多准则决策方法。
人们在进行社会的、经济的以及科学管理领域问题的系统分析中,面临的常常是一个由相互关联、相互制约的众多因素构成的复杂而往往缺少定量数据的系统。
层次分析法为这类问题的决策和排序提供了一种新的、简洁而实用的建模方法,其基本思路是评价者通过将复杂问题分解为若干层次和若干要素,并在同一层次的各要素之间简单地进行比较、判断和计算。
这样就可以得出不同替代方案的重要度,从而为选择最优方案提供决策依据。
运用层次分析法建模,大体上可按下面四个步骤进行:(1)建立递阶层次结构模型;(2)构造出各层次中的所有判断矩阵;(3)层次单排序及一致性检验;(4)层次总排序及一致性检验。
下面分别说明这四个步骤的实现过程。
2.1.1递阶层次结构的建立与特点应用AHP分析决策问题时,首先要把问题条理化、层次化,构造出一个有层次的结构模型。
在这个模型下,复杂问题被分解为元素的组成部分。
这些元素又按其属性及关系形成若干层次。
上一层次的元素作为准则对下一层次有关元素起支配作用。
这些层次可以分为三类:(1)最高层:这一层次中只有一个元素,一般它是分析问题的预定目标或理想结果,因此也称为目标层。
(2)中间层:这一层次中包11 1 1 1 1 1 1 1 1 1 1Yl ¥2....Yr 21 222t采翌曰标图1 AHP评估层次结构示意图评住项目第一自讦估碘目班I第Z尉含了为实现目标所涉及的中间环节,它可以由若干个层次组成,包括所需考虑的准则、子准则,因此也称为准则层。
(3)最底层:这一层次包括了为实现目标可供选择的各种措施、决策方案等,因此也称为措施层或方案层。
层次分析法与层次分析模型

b15
1b11 2b12 5b15
b25
1b21 2b22 5b25
b35
1b31 2b32 5b35
4 层次总排序的一致性检验
设 最下层对最上层中因素的层次单排序一致性指标为 CIj, 随机一致性指为 RIj,则层次总排序的一致性比率为:
CR
a1CI1 a1RI1
a2CI 2 a2 RI 2
amCI m am RI m
当 CR 0.1时,认为层次总排序通过一致性检验。到
此,根据最下层(决策层)的层次总排序做出最后决策。
三 层次分析法建模举例
(1)建模
一、旅游问题
Z
A1, A2 , A3, A4 , A5
分别分别表示景色、费用、
A1
A2 A3 A4 A5 居住、饮食、旅途。
B1
B2
计算 CR可k知 B1, B2 , B通3, 过B4一, B致5 性检验。
(4)计算层次总排序权值和一致性检验
B1 对总目标的权值为: 0.595 0.263 0.082 0.475 0.429 0.055 0.633 0.099 0.166 0.110 0.3
饮食 1/3 1/5 2 1 1
旅途 1/3 1/5 3 1 1
由上表,可得成对比较矩阵
1
1 2
4
3
3
2 1 7 5 5
A
1 4
1 7
1
1 1 2 3
1 3
1 3
1 5
1 5
2 3
1 1
1
1
问题:两两进行比较后,怎样才能定量求出到底去哪个地 方旅游最合理?
3 层次单排序
层次分析法用权值表示各个因素的优劣性,那 如何求权值呢?
层次分析法
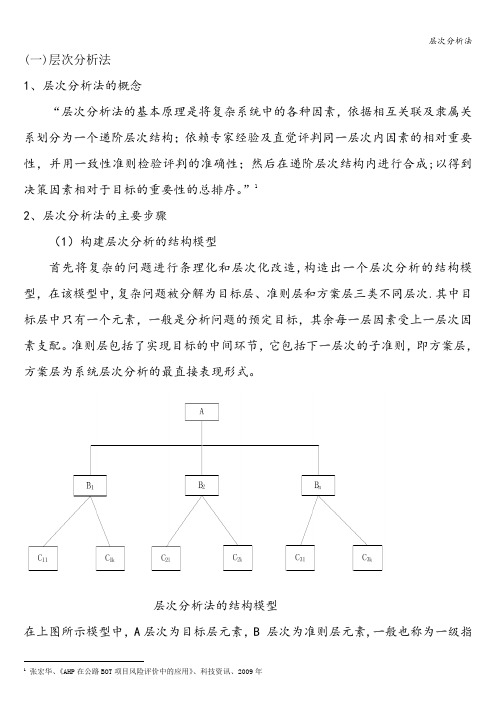
(一)层次分析法1、层次分析法的概念“层次分析法的基本原理是将复杂系统中的各种因素,依据相互关联及隶属关系划分为一个递阶层次结构;依赖专家经验及直觉评判同一层次内因素的相对重要性,并用一致性准则检验评判的准确性;然后在递阶层次结构内进行合成;以得到决策因素相对于目标的重要性的总排序。
”12、层次分析法的主要步骤(1)构建层次分析的结构模型首先将复杂的问题进行条理化和层次化改造,构造出一个层次分析的结构模型,在该模型中,复杂问题被分解为目标层、准则层和方案层三类不同层次.其中目标层中只有一个元素,一般是分析问题的预定目标,其余每一层因素受上一层次因素支配。
准则层包括了实现目标的中间环节,它包括下一层次的子准则,即方案层,方案层为系统层次分析的最直接表现形式。
层次分析法的结构模型在上图所示模型中,A层次为目标层元素,B 层次为准则层元素,一般也称为一级指1张宏华、《AHP在公路BOT项目风险评价中的应用》、科技资讯、2009年标,C层次为方案层元素,也可称为二级指标。
(2)专家评分建立层次分析法判断矩阵为了建立指标权重评判标准和构造判断矩阵,Saaty提出相对重要性比例标度,即1~9 层次比例标度,相对重要性比例标度的含义如表2—3所示。
假设有n个元素C1、C2,。
,C n给定一个准则,利用上表所给的相对重要性比例标度方,对元素C i和C j做两两比较判断,获得相对重要度的值a ij,构成矩阵。
专家根据评判准则对各个因素的权重两两比较并进行了打分之后,经过整理,可以得到因素权重的判断矩阵A:矩阵 A 中的各元素a ij 表示行指标A i 对列指标A j 相对重要性的比例标度,则判断矩阵A 中指标两两比较的特点有a ij >0,a ij =1,a ij =1/a ji (i ,j=1,2,。
..。
..n )。
如果a ij <1,表示A j 比A i 重要; 如果a ij >1,表示A i 比A j 重要; 如果a ij =1,表示A j 与A i 同样重要.根据判断矩阵A 在选择上的一致性要求,理想情况下,a ik*a jk =a ij (代表相对重要性所具有的传递性原理,满足该性质的矩阵A 称为一致矩阵),虽然在构造判断矩阵A 时并不要求判断具有一致性,但判断偏离一致性过大也是不允许的。
风险决策模型层次分析法xin

Saaty.T.L等人在 年代提出了一种以定性与定量相结合,系统化、层次化 等人在70年代提出了一种以定性与定量相结合 系统化、 等人在 年代提出了一种以定性与定量相结合, 分析问题的方法,称为层次分析法( 分析问题的方法,称为层次分析法(Analytic Hiearchy Process,简称 , AHP)。层次分析法将人们的思维过程层次化,逐层比较其间的相关因素 )。层次分析法将人们的思维过程层次化 )。层次分析法将人们的思维过程层次化, 并逐层检验比较结果是否合理, 并逐层检验比较结果是否合理,从而为分析决策提供了较具说服力的定量 依据,层次分析法的提出不仅为处理这类问题提供了一种实用的决策方法, 依据,层次分析法的提出不仅为处理这类问题提供了一种实用的决策方法, 而且也提供了一个在处理机理比较模糊的问题时,如何通过科学分析, 而且也提供了一个在处理机理比较模糊的问题时,如何通过科学分析,在 系统全面分析机理及因果关系的基础上建立数学模型的范例。 系统全面分析机理及因果关系的基础上建立数学模型的范例。 一、层次分析的基本步骤 层次分析过程可分为四个基本步骤:( )建立层次结构模型;( )构 ;(2) 层次分析过程可分为四个基本步骤:(1)建立层次结构模型;( :( 造出各层次中的所有判断矩阵;( 层次单排序及一致性检验;( ;(3) ;(4) 造出各层次中的所有判断矩阵;( )层次单排序及一致性检验;( )层 次总排序及一致性检验。 次总排序及一致性检验。 下面通过一个简单的实例来说明各步骤中所做的工作。 下面通过一个简单的实例来说明各步骤中所做的工作。
从心理学观点来看,分级太多会超越人们的判断能力, 从心理学观点来看,分级太多会超越人们的判断能力,既增加了作判断 的难度,又容易因此而提供虚假数据。 的难度,又容易因此而提供虚假数据。Saaty等人还用实验方法比较了在 等人还用实验方法比较了在 各种不同标度下人们判断结果的正确性,实验结果也表明,采用1~9标度 各种不同标度下人们判断结果的正确性,实验结果也表明,采用 标度 最为合适。 最为合适。 如果在构造成对比较判断矩阵时,确实感到仅用1~9及其倒数还不够理 如果在构造成对比较判断矩阵时,确实感到仅用 及其倒数还不够理 想时,可以根据情况再采用因子分解聚类的方法,先比较类, 想时,可以根据情况再采用因子分解聚类的方法,先比较类,再比较每 一类中的元素。 一类中的元素。 步3 层次单排序及一致性检验 上述构造成对比较判断矩阵的办法虽能减少其他因素的干扰影响, 上述构造成对比较判断矩阵的办法虽能减少其他因素的干扰影响,较 客观地反映出一对因子影响力的差别。但综合全部比较结果时, 客观地反映出一对因子影响力的差别。但综合全部比较结果时,其中 难免包含一定程度的非一致性。如果比较结果是前后完全一致的, 难免包含一定程度的非一致性。如果比较结果是前后完全一致的,则 矩阵A的元素还应当满足 的元素还应当满足: 矩阵 的元素还应当满足:
层次分析法(详细)

1
1/5 1/3 2 6.53
5
1 3 3 20
3
1/3 1 1 7.33
1/2
1/3 1 1 3.83
B
p1 p2
p1
p2
p3
p4
p5
p6
0.16 0.17 0.15 0.20 0.14 0.13 0.16 0.17 0.30 0.20 0.14 0.13
p3
p4 p5 p6
0.16 0.09 0.15 0.25 0.42 0.13
3
1
1
和积法具体计算步骤:
o将判断矩阵的每一列元素作归一 化处理,其元素的一般项为:
bij= bij 1nbij
(i,j=1,2,….n)
B
p1 p2
p1 1 1
p2 1 1
p3 1 2
p4 4 4
p5 1 1
p6 1/2 1/2
p3
p4 p5 p6
1
1/4 1 2 6.25
1/2
1/4 1 2 5.75
层次分析法(AHP)特点: 分析思路清楚,可将系统分析人 员的思维过程系统化、数学化和模 型化; 分析时需要的定量数据不多,但 要求对问题所包含的因素及其关系 具体而明确;
层次分析法(AHP)特点: 这种方法适用于多准则、多目标 的复杂问题的决策分析,广泛用于 物流系统规划与评价、地区经济发 展方案比较、科学技术成果评比、 资源规划和分析以及企业人员素质 测评。
层次分析法(AHP)具体步骤: 建立两两比较的判断矩阵 判断矩阵表示针对上一层次 某单元(元素),本层次与它有关 单元之间相对重要性的比较。一般 取如下形式:
Cs
p1 b11 b21 … … bn1
层次分析法

e1
1 4.511
0.778
0.172
,
3 0.665
0.4 6 7 e2 Ae1 0.565, e2 3.014,
1.9 9 1
01.55 0.471 e2 0.184, e3 0.559, e3 3.018,
0.661 1.988
0.156 0.473 e3 0.185, e4 0.561,
(4)定义未知参数 在这种问题中,运用层次分析法建立表达式 来表达未曾定义过的量。典型的例子是价值 工程,产品的价值V被定义为
VF C
其中F,C分别为产品的功能系数与成本系数, 它们可以用层次分析来定义。下面是一个 经济学例子。
例5 弹性系数的确定 经济学中有名的Cobb-Douglas生产函 数是
e (1,2,,n )T ,则权系数可取: wi i ,i 1,2,, n
在具体计算中,当
ek 与ek 1
接近到一定程度时,就取 e ek
例1 评价影视作品的水平, 用以下三个变量作评价指标 :
x1 教育性,x2 艺术性,x3 娱乐性
设有一名专家赋值:
x2 1, x3 5, x3 3
w1, w2 ,, wn
这 n 个常数便是权系数, 层次分析法给出了确定它们 的量化方法,其过程如下:
1.成对比较
从x1, x2,, xn中任取xi , xj ,比较它们
对y贡献的大小,给xi xj 赋值如下:
xi
xj
1,当认为“xi与x
贡献程度相同”时
j
xi
xj
3,当认为“xi比x
的贡献略大”时
x1
的概率估值为0.134+0.219+0.026=0.379,
多目标决策模型:层次分析法(AHP)、代数模型、离散模型

程中常是定性的。 例如:经济好,身体好的人:会将景色好作为第一选择; 中老年人:会将居住、饮食好作为第一选择; 经济不好的人:会把费用低作为第一选择。 而层次分析方法则应给出确定权重的定量分析方法。 (S3)将方案后对准则层的权重,及准则后对目标层的权重进行综合。 (S4)最终得出方案层对目标层的权重,从而作出决策。 以上步骤和方法即是 AHP 的决策分析方法。 三、确定各层次互相比较的方法——成对比较矩阵和权向量 在确定各层次各因素之间的权重时,如果只是定性的结果,则常常不容易被别人接受,因 而 Santy 等人提出:一致矩阵法 ..... 即:1. 不把所有因素放在一起比较,而是两两相互比较 2. 对此时採用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,提高准确度。 因素比较方法 —— 成对比较矩阵法: 目的是,要比较某一层 n 个因素 C1 , C 2 , , C n 对上一层因素 O 的影响(例如:旅游决策解 中,比较景色等 5 个准则在选择旅游地这个目标中的重要性) 。 採用的方法是:每次取两个因素 C i 和 C j 比较其对目标因素 O 的影响,并用 aij 表示,全部 比较的结果用成对比较矩阵表示,即:
分析:
W1 W2 若重量向量 W 未知时, 则可由决策者对物体 M 1 , M 2 , , M n 之间两两相比关系, W n 主观作出比值的判断,或用Delphi(调查法)来确定这些比值,使 A 矩阵(不一定有一致性)
为已知的,并记此主观判断作出的矩阵为(主观)判断矩阵 A ,并且此 A (不一致)在不一致 的容许范围内,再依据: A 的特征根或和特征向量 W 连续地依赖于矩阵的元素 aij ,即当 aij 离 一致性的要求不太远时, A 的特征根 i 和特征值(向量)W 与一致矩阵 A 的特征根 和特征向 量 W 也相差不大的道理:由特征向量 W 求权向量 W 的方法即为特征向量法,并由此引出一致 性检查的方法。 问题:Remark 以上讨论的用求特征根来求权向量 W 的方法和思路,在理论上应解决以下问题: 1. 一致阵的性质 1 是说:一致阵的最大特征根为 n (即必要条件) ,但用特征根来求特征向量 时, 应回答充分条件: 即正互反矩阵是否存在正的最大特征根和正的特征向量?且如果正互 反矩阵 A 的最大特征根 max n 时, A 是否为一致阵? 2. 用主观判断矩阵 A 的特征根 和特征向量 W 连续逼近一致阵 A 的特征根 和特征向量 W 时,即: 由 lim k
层次分析法简单介绍

1
• 每次选取两个因素比较其对目 标A的影响权重;
判断矩阵元素的表示:
b11 b12
B
b21
b22
bn1 bn2
b1n
b2n
2
bnn
• 在 用 的影b影ij来响响表目程示标度yA之i与的比y因j值的素。比yi值、目yj中标,A
• n个被比较的因素构成一个两 两比较(成对比较)的判断 矩阵B
• 在20世纪70年代中期由美国运筹学家托马斯·塞 蒂(T.L.Saaty)正式提出。它是一种定性和定量 相结合的、系统化、层次化的分析方法。
• 应用已遍及经济计划和管理、能源政策和分配、 行为科学、军事指挥、运输、农业、教育、人 才、医疗和环境等领域。
层次分析法的基本思想
寻求层次分析法的生活背景:
综合的思维方式进行决策 。
2.实用型 • 层次分析法把定性和定量方法结合起来,能处理许多用传统
量化技术技术手段无法处理的实际问题。
3.简洁性 • 层次分析法的基本原理和步骤简洁明了,计算也非常简便,
并且所得结果简单明确,容易被决策者了解和掌握。
层次分析法的局限性
1.方案局限性 • 只能从原有的方案中优选一个出来,没有办法得出更好的新
致性检验。(即最下层对最 上层总排序的权向量)
层次结构的模型的建立
将复杂问题分解为被人们称之为元素的组成部分。
这些元素又按其属性分成若干组,形成不同层次。 同一层次的元素作为准则对下一层次的某些元素 起支配作用,同时它又受上一层次元素的支配。
层次分析法的模型
层次分析法的模型
第一类
最高层,又称顶层、目标层
mn
层次排序
层次单排序
• 当判断矩阵满足一致性时,或者判断矩阵不一致 程度可接受时也可以允许特征向量作为权重向量;
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
二、模型的假设1、假设我们所统计与分析的数据,都就是客观真实的;2、在考虑影响毕业生就业的因素时,假设我们所选取的样本为简单随机抽样,具有典型性与普遍性,基本上能够集中反映毕业生就业实际情况;3、在数据计算过程中,假设误差在合理范围之内,对数据结果的影响可以忽略、三、符号说明四、模型的分析与建立1、问题背景的理解随着我国改革开放的不断深入,经济转轨加速,社会转型加剧,受高校毕业生总量的增加,劳动用工管理与社会保障制度,劳动力市场的不尽完善,以及高校的毕业生部分择业期望过高等因素的影响,如今的毕业生就业形势较为严峻、为了更好地解决广大学生就业中的问题,就需要客观地、全面地分析与评价毕业生就业的若干主要因素,并将它们从主到次依秩排序、针对不同专业的毕业生评价其就业情况,并给出某一专业的毕业生具体的就业策略、2、方法模型的建立(1)层次分析法层次分析法介绍:层次分析法就是一种定性与定量相结合的、系统化、层次化的分析方法,它用来帮助我们处理决策问题、特别就是考虑的因素较多的决策问题,而且各个因素的重要性、影响力、或者优先程度难以量化的时候,层次分析法为我们提供了一种科学的决策方法、通过相互比较确定各准则对于目标的权重,及各方案对于每一准则的权重、这些权重在人的思维过程中通常就是定性的,而在层次分析法中则要给出得到权重的定量方法、我们现在主要对各个因素分配合理的权重,而权重的计算一般用美国运筹学家T、L、Saaty教授提出的AHP法、(2)具体计算权重的AHP 法AHP法就是将各要素配对比较,根据各要素的相对重要程度进行判断,再根据W、计算成对比较矩阵的特征值获得权重向量kStep1、 构造成对比较矩阵假设比较某一层k 个因素12,,,k C C C L 对上一层因素ο的影响,每次两个因素i C 与j C ,用ij C 表示i C 与j C 对ο的影响之比,全部比较结果构成成对比较矩阵C ,也叫正互反矩阵、*()k k ij C C =,0ij C >,1ij jiC C=, 1ii C =、若正互反矩阵C 元素成立等式:* ij jk ik C C C = ,则称C 一致性矩阵、标度ij C含义1i C 与j C 的影响相同 3 i C 比j C 的影响稍强 5 i C 比j C 的影响强 7 i C 比j C 的影响明显地强 9i C 比j C 的影响绝对地强2,4,6,8i C 与j C 的影响之比在上述两个相邻等级之间11,,29Li C 与j C 影响之比为上面ij a 的互反数 Step2、 计算该矩阵的权重通过解正互反矩阵的特征值,可求得相应的特征向量,经归一化后即为权重向量12 = [ , ,..., ]T kkkkkQ q qq ,其中的ikq 就就是i C 对ο的相对权重、由特征方程A-I=0λ,利用Mathematica 软件包可以求出最大的特征值max λ与相应的特征向量、Step3、 一致性检验1)为了度量判断的可靠程度,可计算此时的一致性度量指标CI :max1kCI k λ-=-其中maxλ表示矩阵C 的最大特征值,式中k 正互反矩阵的阶数,CI 越小,说明权重的可靠性越高、2)平均随机一致性指标RI ,下表给出了1-14阶正互反矩阵计算1000次得到3)当0.1CR RI=<时,(CR 称为一致性比率,RI 就是通过大量数据测出来的随机一致性指标,可查表找到)可认为判断就是满意的,此时的正互反矩阵称之为一致性矩阵、进入Step4、 否则说明矛盾,应重新修正该正互反矩阵、转入Step2、 Step4、 得到最终权值向量将该一致性矩阵任一列或任一行向量归一化就得到所需的权重向量、计算出来的准则层对目标层的权重即不同因素的最终权重,这样一来,我们就可以按权重大小将进行排序了、 (3)组合权向量的计算成对比较矩阵显然非常好体现了我们研究对象——各个因素之间权重的比较状态,能够有效地全面而深刻地表现出有关的数据信息,显然也就是矩阵数学模型的重要应用价值、 因素往往就是有层次的,我们经常在进行决策分析时,要进行多方面、多角度、多层次的分析与研究,把我们的决策选择建立在深刻而广泛的分析研究基础之上的、一个总的指标下面可以有第一层次的各个方面的指标、因素、成份、特征性质、组成成分等等,而每个这种因素又有新的成份在里面、这就就是决策分析的数学模型的真正的意义之所在、定理1:对于三决策问题,假设第一层只有一个因素,即这就是总的目标,决策总就是最后要集中在一个总目标基础之上的东西,然后才能进行最后的比较、又假设第二层与第三层因素各有n 、m 个,并且记第二层对第一层的权向量(即构成成份的数量大小、成份的比例、影响程度的大小的数量化指标的量化结果、所拥有的这种属性的程度大小等等多方面的事情的量化的结果)为:(2)(2)(2)(2)12(,,,)Tn w w w w =L , 而第3层对第2层的全向量分别就是:(3)(3)(3)(3)12(,,,)Tk k k km w w w w =L ,这表示第3层的权重大小,具体表示的就是第2层中第k 个因素所拥有的面对下一层次的m 个同类因素进行分析对比所产生的数量指标、那么显然,第三层的因素相对于第一层的因素而言,其权重应当就是:先构造矩阵,用 (3)k w 为列向量构造一个方阵 (3)(3)(3)(3)12(,,)nWw w w=L,这个矩阵的第一行就是第3层次的m 个因素中的第1个因素,通过第2层次的n 个因素传递给第1层次因素的权重,故第3层次的m 个因素中的第i 个因素对第1层次的权重为 (2)(3)1nkkik w w=∑,从而可以统一表示为:(1)(3)(2)wWw=,它的每一行表示的就就是三层(一般就是方案层)中每一个因素相对总目标的量化指标、定理2:一般公式如果共有s 层,则第k 层对第一层(设只有一个因素)的组合权向量为()()(1),3,4,k k k k s wWw-==L ,其中矩阵 ()k W的第i 行表示第k 层中的第i 个因素,相对于第1k -层中每个因素的权向量;而列向量 (1)k w-则表示的就是第1k -层中每个因素关于第一层总目标的权重向量、于就是,最下层对最上层的的组合权向量为:()()(1)(3)(2)s s s wWWWw-=L ,实际上这就是一个从左向右的递推形式的向量运算、逐个得出每一层的各个因素关于第一层总目标因素的权重向量、 (4)灰色关联度综合评价法灰色系统的关联分析主要就是对系统动态发展过程的量化分析,它就是根据因素之间发展态势的相似或相异程度,来衡量因素间接近的程度,实质上就就是各评价对象与理想对象的接近程度,评价对象与理想对象越接近,其关联度就越大、关联序则反映了各评价对象对理想对象的接近次序,即评价对象与理想对象接近程度的先后次序,其中关联度最大的评价对象为最优、因此,可利用关联序对所要评价的对象进行排序比较、利用灰色关联度进行综合评价的步骤如下:1)用表格方式列出所有被评价对象的指标、2)由于指标序列间的数据不存在运算关系,因此必须对数据进行无量纲化处理、3)构造理想对象,即把无量纲化处理后评价对象中每一项指标的最佳值作为理想对象的指标值、4)计算指标关联系数、其计算公式为:min max imax()()ik k ρρξ+=+∆∆∆∆其中min()()minminiikk k x x =-∆,max()()maxmaxiikk k x x =-∆,()ik ∆=()()ik k x x -,1,2,i n =L ,1,2,k m =L 、式中n 为评价对象的个数;m 为评价对象指标的个数;()ik ξ为第i 个对象第k 个指标对理想对象同一指标的关联系数;A 表示在各评价对象第k 个指标值与理想对象第k 个指标值的最小绝对差的基础上,再按1,2,,i n =L 找出所有最小绝对差中的最小值;max ∆表示在评价对象第k 个指标值与理想对象第k 个指标值的最大绝对差的基础上,再按1,2,,i n =L 找出所有最大绝对差中的最大值;min ∆为评价对象第k 个指标值与理想对象第k 个指标值的绝对差、ρ为分辨系数,ρ越小分辨力越大,一般ρ的取值区间[0,1],更一般地取ρ=0、5、5)确立层次分析模型、6)确定判断矩阵,计算各层次加权系数及加权关联度,加权关联度的计算公式为:()mk iikk γξω=∑,式中7为第i 个评价对象对理想对象的加权关联度,kω为第k 个指标的权重、7)依加权关联度的大小,对各评价对象进行排序,建立评价对象的关联序,从而可以得出关联度较大的对象,关联度越大其综合评价结果也越好、 (5)线性回归分析法假如对象(因变量)y 与p 个因素(自变量)12,,,p x x x L 的关系就是线性的,为研究她们之间定量关系式,做n 次抽样,每一次抽样可能发生的对象之值为12,,ny y yL它们就是在因素(1,2,,)i i p x =L 数值已经发生的条件下随机发生的、把第j 次观测的因素数值记为:12,,,jjpj x xx L (1,2,j n =L )那么可以假设有如下的结构表达式:1111011212201213011p p p p n np p y x x y x x y x x βββεβββεβββε⎧=++++⎪⎪=++++⎪⎨⎪⎪=++++⎪⎩L L L L L L L L L L L L L L L L L L 其中,01,,,pβββL 就是1p +个待估计参数,12,,,n εεεL 就是n 个相互独立且服从同一正态分布2(0,)N σ的随机变量、这就就是多元线性回归的数学模型、若令12n y y y y ⎛⎫ ⎪ ⎪ ⎪= ⎪ ⎪ ⎪⎝⎭M ,111212122212111p p n n np x xx x xx x xxx ⎛⎫ ⎪ ⎪=⎪ ⎪⎪⎝⎭L L L LLL L L,012p βββββ⎛⎫⎪ ⎪ ⎪ ⎪= ⎪ ⎪ ⎪ ⎪⎝⎭M ,12n εεεε⎛⎫ ⎪ ⎪= ⎪ ⎪ ⎪⎝⎭M则上面多元线性回归的数学模型可以写成矩阵形式:y x βε=+在实际问题中,我们得到的就是实测容量为n 的样本,利用这组样本对上述回归模型中的参数进行估计,得到的估计方法称为多元线性回归方程,记为%011p p y b b x b x =+++L式中,012,,,,p b b b b L 分别为01,,,p βββL 的估计值、 (6)主成分分析法1)主成分的定义设有p 个随机变量12,,,p x x x L ,它们可能线性相关,通过某种线性变换,找到p 个线性无关的随机变量12,,,pz z zL ,称为初始向量的主成分、设12(,,,)Tp αααα=L为p 维空间pR 中的单位向量,并记所有单位向量的集合为{}0|1TR ααα==,且记X =12(,,,)Tp X X X L 、2)用相关矩阵确定的主成分令*i E X -=,**(,),ij i j E r X X =1,2,,j p =L 、*X=***12(,,)Tp X X X L ,则1212121211()1pp ij p p R r r r rr r r⎛⎫ ⎪⎪== ⎪ ⎪ ⎪⎝⎭L LL L LLL 为*X 的协方程、类似地,我们可对R 进行相应的分析、3)主成分分析的一般步骤 第一步、选择主成分设X 的样本数据经过数据预处理后计算出的样本相关矩阵为121*21212111*()11()()pT p p p R ij n r r r rr XX r r⎛⎫ ⎪ ⎪=== ⎪- ⎪ ⎪⎝⎭L LL L LLL %%、 由特征方程0R I λ-=,求出p 个非负实根,并按值从大到小进行排列:120p λλλ≥≥≥≥L 、将iλ带入下列方程组,求出单位特征向量iα()0,1,2,,i i R I i m λα-==L确定m的方法就是使前m个主成分的累计贡献率达到85%左右、第二步、利用主成分进行分析在实际分析时,通常把特征向量的各个分量的取值大小与符号(正负)进行对照比较,往往能对主成分的直观意义作出合理的解释、利用主成分可以进行以下分析:a)对原指标进行分类;b)对原指标进行选择;c)对样品进行分类;d)对样品进行排序;e)预测分析、。