第7章排序习题参考答案
数据结构章节练习题 - 答案第7章 图

7.1选择题1.对于一个具有n个顶点和e条边的有向图,在用邻接表表示图时,拓扑排序算法时间复杂度为()A)O(n)B)O(n+e)C)O(n*n)D)O(n*n*n)【答案】B2.设无向图的顶点个数为n,则该图最多有()条边。
A)n-1B)n(n-1)/2C)n(n+1)/2【答案】B3.连通分量指的是()A)无向图中的极小连通子图B)无向图中的极大连通子图C)有向图中的极小连通子图D)有向图中的极大连通子图【答案】B4.n个结点的完全有向图含有边的数目()A)n*n B)n(n+1)C)n/2【答案】D5.关键路径是()A)AOE网中从源点到汇点的最长路径B)AOE网中从源点到汇点的最短路径C)AOV网中从源点到汇点的最长路径D)n2D)n*(n-1)D)AOV网中从源点到汇点的最短路径【答案】A6.有向图中一个顶点的度是该顶点的()A)入度B)出度C)入度与出度之和D)(入度+出度)/2【答案】C7.有e条边的无向图,若用邻接表存储,表中有()边结点。
A)e B)2eC)e-1D)2(e-1)【答案】B8.实现图的广度优先搜索算法需使用的辅助数据结构为()A)栈B)队列C)二叉树D)树【答案】B9.实现图的非递归深度优先搜索算法需使用的辅助数据结构为()A)栈B)队列C)二叉树D)树【答案】A10.存储无向图的邻接矩阵一定是一个()A)上三角矩阵B)稀疏矩阵C)对称矩阵D)对角矩阵【答案】C11.在一个有向图中所有顶点的入度之和等于出度之和的()倍A)B)1C)2D)4【答案】B12.在图采用邻接表存储时,求最小生成树的Prim 算法的时间复杂度为(A)O(n)B)O(n+e)C)O(n2)D)O(n3))【答案】B13.下列关于AOE网的叙述中,不正确的是()A)关键活动不按期完成就会影响整个工程的完成时间B)任何一个关键活动提前完成,那么整个工程将会提前完成C)所有的关键活动提前完成,那么整个工程将会提前完成D)某些关键活动提前完成,那么整个工程将会提前完成【答案】B14.具有10个顶点的无向图至少有多少条边才能保证连通()A)9B)10C)11D)12【答案】A15.在含n个顶点和e条边的无向图的邻接矩阵中,零元素的个数为()A)e B)2eC)n2-e D)n2-2e【答案】D7.2填空题1.无向图中所有顶点的度数之和等于所有边数的_____________倍。
FOXPRO基础及应用第7章作业

FOXPRO基础及应用第7章作业一、单选题(每小题4.35分,共100.05分,得分 100.05 分)1、视图设计器中包括的选卡有_______。
A、更新条件、筛选、字段B、更新条件、排序依据、显示C、显示、排序依据、分组依据D、联接、显示、排序依据你的回答: A (√) 参考答案:A2、参照完整性规则不包括______。
A、更新规则B、查询规则C、删除规则D、插入规则你的回答: B (√) 参考答案:B3、要显示"参照完整性",可以________。
A、从"数据库设计器"快捷菜单中选择"编辑参照完整性"选项B、其它选项都可以C、选择"数据库"菜单中的"编辑参照完整性"选项D、在数据库设计器中双击两个表之间的关系按钮,然后在"编辑关系"对话框中选择"参照完整性"按钮你的回答: B (√) 参考答案:B4、下列关于视图和查询的叙述中,错误的是________。
A、可以把视图当作数据库的一个定制的虚拟表B、视图被分为本地视图和远程视图两大类C、可以把查询的结果保存到一个新的数据表中D、对查询结果和视图数据的修改都会影响数据源你的回答: D (√) 参考答案:D5、查询设计器和视图设计器的主要不同表现在于________。
A、查询设计器没有"更新条件"选项卡,有"查询去向"选项B、查询设计器有"更新条件"选项卡,没有"查询去向"选项C、视图设计器没有"更新条件"选项卡,有"查询去向"选项D、视图设计器有"更新条件"选项卡,也有"查询去向"选项你的回答: A (√) 参考答案:A6、下面有关对视图的描述正确的是______。
第7章习题及参考答案
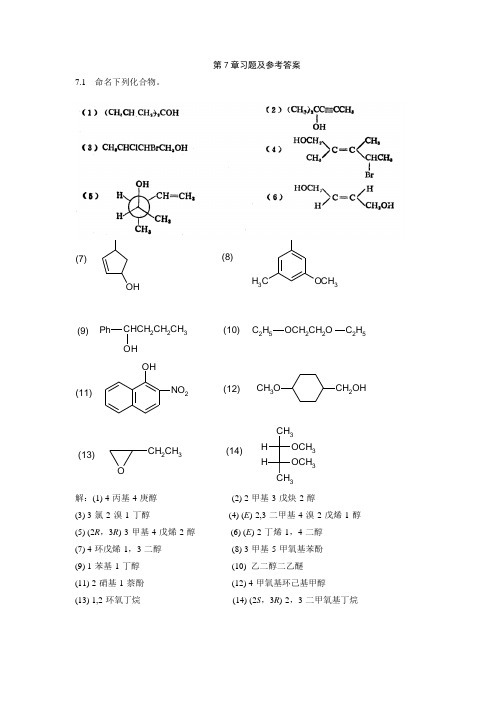
第7章习题及参考答案7.1 命名下列化合物。
OH OHOHO CH 3CH 3PhCHCH 2CH 2CH 3OHC 2H 5OCH 2CH 2O C 2H 5(7)(8)(9)(10)CH 3OHNO 2OCH 2OHCH 3OCH 2CH 3CH 3CH 3H O HO CH 3(11)(12)(13)(14)解:(1) 4-丙基-4-庚醇 (2) 2-甲基-3-戊炔-2-醇(3) 3-氯-2-溴-1-丁醇 (4) (E )-2,3-二甲基-4-溴-2-戊烯-1-醇 (5) (2R ,3R )-3-甲基-4-戊烯-2-醇 (6) (E )-2-丁烯-1,4-二醇 (7) 4-环戊烯-1,3-二醇 (8) 3-甲基-5-甲氧基苯酚 (9) 1-苯基-1-丁醇 (10) 乙二醇二乙醚 (11) 2-硝基-1-萘酚 (12) 4-甲氧基环己基甲醇 (13) 1,2-环氧丁烷 (14) (2S ,3R )-2,3-二甲氧基丁烷7.2 写出下列化合物的结构式。
(1) 3,3-二甲基环戊醇 (2) 肉桂醇(3) 环戊基叔丁基醚 (4) 3-环己烯基异丙基醚 (5) 顺-1,2-环己二醇 (6) 2,3-二巯基-1-丙醇 (7) 4-丁基-1,3-苯二酚 (8) 二苯并-18-冠-6 解:CH CHCH 2OHOHC H 3CH 3(1)(2)OOC(CH 3)3CH(CH 3)2(3)(4)SHSHOH OHCH 2CH CHOH(5)(6)OHOHC(CH 3)3O OOOO O (7)(8)7.3 将下列化合物按沸点降低的顺序排列成序。
(1)丙三醇,乙二醇二甲醚,乙二醇,乙二醇单甲醚 (2)3-己醇,正己醇,正辛醇,2-甲基-2-戊醇解:(1)丙三醇>乙二醇>乙二醇单甲醚>乙二醇二甲醚 (2)正辛醇>正己醇>3-己醇>2-甲基-2-戊醇7.4 将下列各组化合物按与卢卡斯试剂作用的速率快慢排列成序。
数据结构(C语言版)(第2版)课后习题答案

数据结构(C语言版)(第2版)课后习题答案数据结构(C语言版)(第2版)课后习题答案目录第1章绪论1 第2章线性表5 第3章栈和队列13 第4章串、数组和广义表26 第5章树和二叉树33 第6章图43 第7章查找54 第8章排序65 第1章绪论1.简述下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型。
答案:数据:是客观事物的符号表示,指所有能输入到计算机中并被计算机程序处理的符号的总称。
如数学计算中用到的整数和实数,文本编辑所用到的字符串,多媒体程序处理的图形、图像、声音、动画等通过特殊编码定义后的数据。
数据元素:是数据的基本单位,在计算机中通常作为一个整体进行考虑和处理。
在有些情况下,数据元素也称为元素、结点、记录等。
数据元素用于完整地描述一个对象,如一个学生记录,树中棋盘的一个格局(状态)、图中的一个顶点等。
数据项:是组成数据元素的、有独立含义的、不可分割的最小单位。
例如,学生基本信息表中的学号、姓名、性别等都是数据项。
数据对象:是性质相同的数据元素的集合,是数据的一个子集。
例如:整数数据对象是集合N={0,±1,±2,。
},字母字符数据对象是集合C={‘A’,‘B’,。
,‘Z’,‘a’,‘b’,。
,‘z’},学生基本信息表也可是一个数据对象。
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
换句话说,数据结构是带“结构”的数据元素的集合,“结构”就是指数据元素之间存在的关系。
逻辑结构:从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的。
因此,数据的逻辑结构可以看作是从具体问题抽象出来的数学模型。
存储结构:数据对象在计算机中的存储表示,也称为物理结构。
抽象数据类型:由用户定义的,表示应用问题的数学模型,以及定义在这个模型上的一组操作的总称。
具体包括三部分:数据对象、数据对象上关系的集合和对数据对象的基本操作的集合。
2.试举一个数据结构的例子,叙述其逻辑结构和存储结构两方面的含义和相互关系。
《数据结构(C语言版 第2版)》(严蔚敏 著)第七章练习题答案

《数据结构(C语言版第2版)》(严蔚敏著)第七章练习题答案第7章查找1.选择题(1)对n个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为()。
A.(n-1)/2B.n/2C.(n+1)/2D.n答案:C解释:总查找次数N=1+2+3+…+n=n(n+1)/2,则平均查找长度为N/n=(n+1)/2。
(2)适用于折半查找的表的存储方式及元素排列要求为()。
A.链接方式存储,元素无序B.链接方式存储,元素有序C.顺序方式存储,元素无序D.顺序方式存储,元素有序答案:D解释:折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
(3)如果要求一个线性表既能较快的查找,又能适应动态变化的要求,最好采用()查找法。
A.顺序查找B.折半查找C.分块查找D.哈希查找答案:C解释:分块查找的优点是:在表中插入和删除数据元素时,只要找到该元素对应的块,就可以在该块内进行插入和删除运算。
由于块内是无序的,故插入和删除比较容易,无需进行大量移动。
如果线性表既要快速查找又经常动态变化,则可采用分块查找。
(4)折半查找有序表(4,6,10,12,20,30,50,70,88,100)。
若查找表中元素58,则它将依次与表中()比较大小,查找结果是失败。
A.20,70,30,50B.30,88,70,50C.20,50D.30,88,50答案:A解释:表中共10个元素,第一次取⎣(1+10)/2⎦=5,与第五个元素20比较,58大于20,再取⎣(6+10)/2⎦=8,与第八个元素70比较,依次类推再与30、50比较,最终查找失败。
(5)对22个记录的有序表作折半查找,当查找失败时,至少需要比较()次关键字。
A.3B.4C.5D.6答案:B解释:22个记录的有序表,其折半查找的判定树深度为⎣log222⎦+1=5,且该判定树不是满二叉树,即查找失败时至多比较5次,至少比较4次。
(6)折半搜索与二叉排序树的时间性能()。
数据结构课后习题答案第七章
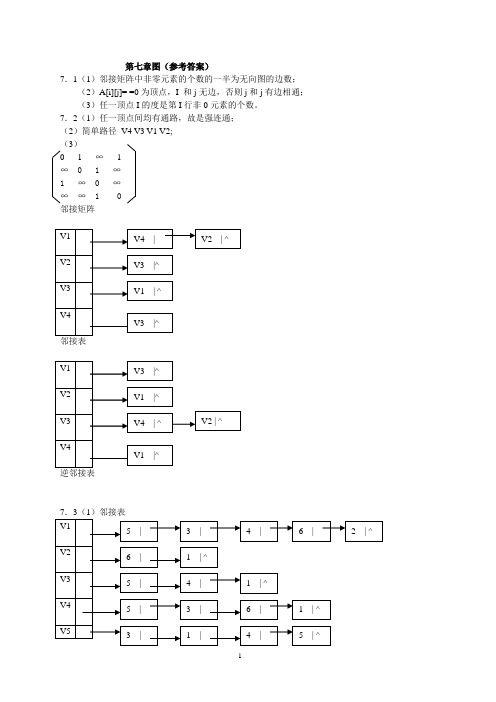
第七章图(参考答案)7.1(1)邻接矩阵中非零元素的个数的一半为无向图的边数;(2)A[i][j]= =0为顶点,I 和j无边,否则j和j有边相通;(3)任一顶点I的度是第I行非0元素的个数。
7.2(1)任一顶点间均有通路,故是强连通;(2)简单路径V4 V3 V1 V2;(3)0 1 ∞ 1∞ 0 1 ∞1 ∞ 0 ∞∞∞ 1 0邻接矩阵邻接表(2)从顶点4开始的DFS序列:V5,V3,V4,V6,V2,V1(3)从顶点4开始的BFS序列:V4,V5,V3,V6,V1,V27.4(1)①adjlisttp g; vtxptr i,j; //全程变量② void dfs(vtxptr x)//从顶点x开始深度优先遍历图g。
在遍历中若发现顶点j,则说明顶点i和j间有路径。
{ visited[x]=1; //置访问标记if (y= =j){ found=1;exit(0);}//有通路,退出else { p=g[x].firstarc;//找x的第一邻接点while (p!=null){ k=p->adjvex;if (!visited[k])dfs(k);p=p->nextarc;//下一邻接点}}③ void connect_DFS (adjlisttp g)//基于图的深度优先遍历策略,本算法判断一邻接表为存储结构的图g种,是否存在顶点i //到顶点j的路径。
设 1<=i ,j<=n,i<>j.{ visited[1..n]=0;found=0;scanf (&i,&j);dfs (i);if (found) printf (” 顶点”,i,”和顶点”,j,”有路径”);else printf (” 顶点”,i,”和顶点”,j,”无路径”);}// void connect_DFS(2)宽度优先遍历全程变量,调用函数与(1)相同,下面仅写宽度优先遍历部分。
2016年考研核心题型【数据结构部分】【第7章 排序】

温馨提示:快速排序主要考查两点:1、快速排序算法的特点;2、快速排序算法实现; 3、快速排序的过程或者一趟排序的结果。本考点历年考查很多,是复习的重点,请同学们 务必掌握。
接插入排序每次从无序表中取出第一个元素,把它插入到有序表的合适位置,使有序表仍
然有序。
折半插入排序是对直接插入排序算法的一种改进。由于前半部分为已排好序的数列,
这样我们可以不用按顺序依次寻找插入点,而是采用折半查找的方法来加快寻找插入点的
速度。折半查找的方法来寻找插入位置,可以减少比较次数。但不影响排序的趟数(仍然
本题只剩下希尔排序了,事实上,本题是利用增量为 d=5、3、1 来对关键字{50 , 26 , 38 , 80 , 70 , 90 , 8 , 30 , 40 , 20 }进行希尔排序。其排序过程如图 7.2 所示。
我方慎重声明,各盈利机构若采用我方资料,必追究法律责任
102
2016 年考研核心考点命题思路解密 数据结构 梦享团队主编
1. 对一待排序序列分别进行折半插入排序和直接插入排序,两者之间可能的不同之处是
(
)。
A. 排序的总趟数
B. 元素的移动次数
C. 使用辅助空间的数量
D. 元素之间的比较次数
【2012 年统考——第 11 题】
【考查内容】直接插入排序和折半插入排序的区别。
【解析】所谓排序算法过程,就是不断的依次将元素插入前面已排好序的序列中。直
一趟冒泡排序结束。
整个排序过程如下图所示。
其过程如图 7.1 所示。
50 40 95 20 15 70 60 45 80
50>40,50和40交换
40 50 95 20 15 70 60 45 80
第七章 练习题参考答案

V1 V3 V6
7. 对下图所示的有向图
(1) 画出它的邻接表 (2) 根据邻接表写出其拓扑排序序列
解:(1)邻接表为
0
2
5∧
2
3
4∧
2 3∧
4∧
1
2
3
6∧
1
4∧
(2)由邻接表可得拓朴排序序列:
1 5 2 3 64
8.已知n个顶点的有向图用邻接矩阵表示,编 写函数,计算每对顶点之间的最短路径。
4 18 ∧
2
1 12
32
5 22 ∧
3
1 16
22
44∧
4
1 18
34
5 10 ∧
5
2 22
4 10 ∧
解:(1) V1
12 V2
16 2
18
4 V3 22
V4
10 V5
(2)深度优先遍历的结点序列:v1,v2,v3,v4,v5
广度优先搜索的结点序列:v1,v2,v3,v4,v5
(3)最小生成树
CD CA CAB
CD CA CAB
CD CA CABΒιβλιοθήκη CD3DB
DB
DB DBC
DBCA DB DBC
DBCA DB DBC
10.对于如图所示的AOE网,求出各活动可能 的最早开始时间和允许的最晚开始时间, 哪些是关键活动?
a1=4
v2
v1
a3=2
a2=3
v3
a5=6 v4
a4=4
解:
顶点 Ve Vl V1 0 0 V2 4 4 V3 6 6 v4 10 10
if(length[i][k]+length[k][j]<length[i][j]) { length[i][j]=length[i][k]+length[k][j];
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
习题七参考答案一、选择题1.内部排序算法的稳定性是指( D)。
A.该排序算法不允许有相同的关键字记录B.该排序算法允许有相同的关键字记录C.平均时间为0(n log n)的排序方法D.以上都不对2.下面给出的四种排序算法中,( B)是不稳定的排序。
A.插入排序B.堆排序C.二路归并排序D.冒泡排序3. 在下列排序算法中,哪一种算法的时间复杂度与初始排序序列无关(D)。
A.直接插入排序B.冒泡排序C.快速排序D.直接选择排序4.关键字序列(8,9,10,4,5,6,20,1,2)只能是下列排序算法中(C )的两趟排序后的结果。
A.选择排序 B.冒泡排序 C.插入排序 D.堆排序5.下列排序方法中,( D )所需的辅助空间最大。
A.选择排序B.希尔排序C.快速排序D.归并排序6.一组记录的关键字为(46,79,56,38,40,84),则利用快速排序的方法,以第一个记录为支点得到的一次划分结果为(C )。
A.(38,40,46,56,79,84) B.(40,38,46,79,56,84)C.(40,38,46,56,79,84) D.(40,38,46,84,56,79)7.在对一组关键字序列{70,55,100,15,33,65,50,40,95},进行直接插入排序时,把65插入,需要比较( A )次。
A. 2B. 4C. 6D. 88.从待排序的序列中选出关键字值最大的记录放到有序序列中,该排序方法称为( B )。
A. 希尔排序B.直接选择排序C.冒泡排序D. 快速排序9.当待排序序列基本有序时,以下排序方法中,( B )最不利于其优势的发挥。
A. 直接选择排序B. 快速排序C.冒泡排序D.直接插入排序10.在待排序序列局部有序时,效率最高的排序算法是( B )。
A. 直接选择排序B.直接插入排序C.快速排序D.归并排序二、填空题1.执行排序操作时,根据使用的存储器可将排序算法分为内排序和外排序。
2.在对一组记录序列{50,40,95,20,15,70,60,45,80}进行直接插入排序时,当把第7个记录60插入到有序表中时,为寻找插入位置需比较3次。
3.在直接插入排序和直接选择排序中,若初始记录序列基本有序,则选用直接插入排序。
4.在对一组记录序列{50,40,95,20,15,70,60,45,80}进行直接选择排序时,第4次交换和选择后,未排序记录为{50,70,60,95,80}。
5.n个记录的冒泡排序算法所需的最大移动次数为3n(n-1)/2,最小移动次数为0。
6.对n个结点进行快速排序,最大的比较次数是n(n-1)/2。
7.对于堆排序和快速排序,若待排序记录基本有序,则选用堆排序。
8.在归并排序中,若待排序记录的个数为20,则共需要进行5趟归并。
9.若不考虑基数排序,则在排序过程中,主要进行的两种基本操作是关键字的比较和数据元素的移动。
10.在插入排序、希尔排序、选择排序、快速排序、堆排序、归并排序和基数排序中,平均比较次数最少的是快速排序,需要内存容量最多的是基数排序。
三、算法设计题1.试设计算法,用插入排序方法对单链表进行排序。
参考答案:1public static void insertSort(LinkList L) {Node p, q, r, u;p = L.getHead().getNext();L.getHead().setNext(null);//置空表,然后将原链表结点逐个插入到有序表中while (p != null) { //当链表尚未到尾,p为工作指针r = L.getHead();q = L.getHead().getNext();while (q != null && (Integer.parseInt((String) q.getData())) <=(Integer.parseInt((String) p.getData()))) {//查P结点在链表中的插入位置,这时q是工作指针r = q;q = q.getNext();}u = p.getNext();p.setNext(r.getNext());r.setNext(p);p = u;//将P结点链入链表中,r是q的前驱,u是下一个待插入结点的指针}}2.试设计算法,用选择排序方法对单链表进行排序。
参考答案://单链表选择排序算法public static void selectSort(LinkList L) {//p为当前最小,r为此过程中最小,q为当前扫描接点Node p, r, q;Node newNode = new Node();newNode.setNext(L.getHead());L.setHead(newNode);//制造一个最前面的节点newNode,解决第一个节点的没有前续节点需要单独语句的问题。
p = L.getHead();while (p.getNext().getNext() != null) {r = p.getNext();q = p.getNext().getNext();while (q.getNext() != null) {if (Integer.parseInt((String) q.getNext().getData()) <=(Integer.parseInt((String) r.getNext().getData()))) {r = q;}q = q.getNext();}if (r != p) { //交换p与rNode swap = r.getNext();r.setNext(r.getNext().getNext()); //r的next指向其后继的后继swap.setNext(p.getNext());p.setNext(swap); //p的后继为swap }p = p.getNext();}//whilep.setNext(null);}3.试设计算法,实现双向冒泡排序(即相邻两遍向相反方向冒泡)。
参考答案://产生随机数方法public static int[] random(int n) {if (n > 0) {int table[] = new int[n];for (int i = 0; i < n; i++) {table[i] = (int) (Math.random() * 100);//产生一个0~100之间的随机数}return table;}return null;}//输出数组元素方法public static void print(int[] table){if (table.length > 0) {for (int i = 0; i < table.length; i++) {+ " ");};}}//双向冒泡排序方法public static void dbubblesort(int[] table) {int high = table.length;int left = 1;int right = high - 1;int t = 0;do {//正向部分for (int i = right; i >= left; i--) {if (table[i] < table[i - 1]) {int temp = table[i];table[i] = table[i - 1];table[i - 1] = temp;t = i;3}}left = t + 1;//反向部分for (int i = left; i < right + 1; i++) {if (table[i] < table[i - 1]) {int temp = table[i];table[i] = table[i - 1];table[i - 1] = temp;t = i;}}right = t - 1;} while (left <= right);}4.试设计算法,使用非递归方法实现快速排序。
参考答案:public static void NonrecursiveQuickSort(int[] ary) { if (ary.length < 2) {return;}//数组栈:记录着高位和低位的值int[][] stack = new int[2][ary.length];//栈顶部位置int top = 0;//低位,高位,循环变量,基准点//将数组的高位和低位位置入栈stack[1][top] = ary.length - 1;stack[0][top] = 0;top++;//要是栈顶不空,那么继续while (top != 0) {//将高位和低位出栈//低位:排序开始的位置top--;int low = stack[0][top];//高位:排序结束的位置int high = stack[1][top]; //将高位作为基准位置 //基准位置int pivot = high;int i = low;for (int j = low; j < high; j++) {if (ary[j] <= ary[pivot]) {int temp = ary[j];ary[j] = ary[i];ary[i] = temp;i++;}}//如果i不是基准位,那么基准位选的就不是最大值//而i的前面放的都是比基准位小的值,那么基准位//的值应该放到i所在的位置上if (i != pivot) {int temp = ary[i];ary[i] = ary[pivot];ary[pivot] = temp;}if (i - low > 1) {//此时不排i的原因是i位置上的元素已经确定了,i前面的都是比i小的,i后面的都是比i大的stack[1][top] = i - 1;stack[0][top] = low;top++;}//当high-i小于等于1的时候,就不往栈中放了,这就是外层while循环能结束的原因//如果从i到高位之间的元素个数多于一个,那么需要再次排序if (high - i > 1) {//此时不排i的原因是i位置上的元素已经确定了,i前面的都是比i小的,i后面的都是比i大的stack[1][top] = high;stack[0][top] = i + 1;top++;}}}5.试设计算法,判断完全二叉树是否为大顶堆。
参考答案:boolean checkmax(BiTreeNode t) //判断完全二叉树是否为大顶堆{BiTreeNode p = t;if (p.getLchild() == null && p.getRchild() == null) {return true;} else {if (p.getLchild() != null && p.getRchild() != null) {if ((((RecordNode)p.getLchild().getData()).getKey()).compareTo(((RecordNode) p.getData()).getKey()) <= 0 && (((RecordNode) p.getRchild().getData()).getKey()).compareTo(((RecordNode)p.getData()).getKey()) <= 0) {return checkmax(p.getLchild()) && checkmax(p.getRchild());} else5{return false;}} else if (p.getLchild() != null && p.getRchild() == null) {if ((((RecordNode)p.getLchild().getData()).getKey()).compareTo(((RecordNode) p.getData()).getKey()) <= 0) { return checkmax(p.getLchild());} else{return false;}} else if (p.getLchild() == null && p.getRchild() != null) {if ((((RecordNode)p.getRchild().getData()).getKey()).compareTo(((RecordNode) p.getData()).getKey()) <= 0) { return checkmax(p.getRchild());} else{return false;}} else {return false;}}}。