计量经济学作业 第四小组
《计量经济学》习题(第四章)

《计量经济学》习题(第四章)第四章习题⼀、单选题1、如果回归模型违背了同⽅差假定,最⼩⼆乘估计量____A .⽆偏的,⾮有效的 B.有偏的,⾮有效的C .⽆偏的,有效的 D.有偏的,有效的2、Goldfeld-Quandt ⽅法⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性3、DW 检验⽅法⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性4、在异⽅差性情况下,常⽤的估计⽅法是____A .⼀阶差分法 B.⼴义差分法C .⼯具变量法 D.加权最⼩⼆乘法5、在以下选项中,正确表达了序列⾃相关的是____j i u x Cov D j i x x Cov C ji u u Cov B ji u u Cov A j i j i j i j i ≠≠≠≠≠=≠≠,0),(.,0),(.,0),(.,0),(.6、如果回归模型违背了⽆⾃相关假定,最⼩⼆乘估计量____A .⽆偏的,⾮有效的 B.有偏的,⾮有效的C .⽆偏的,有效的 D.有偏的,有效的7、在⾃相关情况下,常⽤的估计⽅法____A .普通最⼩⼆乘法 B.⼴义差分法C .⼯具变量法 D.加权最⼩⼆乘法8、White 检验⽅法主要⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性9、Glejser 检验⽅法主要⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性10、简单相关系数矩阵⽅法主要⽤于检验____A .异⽅差性 B.⾃相关性C .随机解释变量 D.多重共线性2222)(.)(.)(.)(.σσσσ==≠≠i i i i x Var D u Var C x Var B u Var A12、所谓不完全多重共线性是指存在不全为零的数k λλλ,,,21 ,有____1112211221221122.0.0..k k k k k x x x k k k k A x x x v B x x x C x x x v e D x x x v e v λλλλλλλλλλλλ++++=+++=∑?++++=++++=式中是随机误差项13、设21,x x 为解释变量,则完全多重共线性是____0.(021.0.021.22121121=+=++==+x x e x D v v x x C e x B x x A 为随机误差项)14、⼴义差分法是对____⽤最⼩⼆乘法估计其参数 11211211121121)()1(....-------+-+-=-++=++=++=t t t t t t t t t t t t t t t u u x x y y D u x y C u x y B u x y A ρρβρβρρρβρβρββββ15、在DW 检验中要求有假定条件,在下列条件中不正确的是____A .解释变量为⾮随机的 B.随机误差项为⼀阶⾃回归形式C .线性回归模型中不应含有滞后内⽣变量为解释变量D.线性回归模型为⼀元回归形式16、在下例引起序列⾃相关的原因中,不正确的是____A.经济变量具有惯性作⽤B.经济⾏为的滞后性C.设定偏误D.解释变量之间的共线性17、在DW 检验中,当d 统计量为2时,表明____A.存在完全的正⾃相关B.存在完全的负⾃相关C.不存在⾃相关D.不能判定18、在DW 检验中,当d 统计量为4时,表明____A.存在完全的正⾃相关B.存在完全的负⾃相关C.不存在⾃相关D.不能判定19、在DW 检验中,当d 统计量为0时,表明____A.存在完全的正⾃相关C.不存在⾃相关D.不能判定20、在DW 检验中,存在不能判定的区域是____A. 0﹤d ﹤l d ,4-l d ﹤d ﹤4B. u d ﹤d ﹤4-u dC. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l dD. 上述都不对21、在修正序列⾃相关的⽅法中,能修正⾼阶⾃相关的⽅法是____A. 利⽤DW 统计量值求出ρB. Cochrane-Orcutt 法C. Durbin 两步法D. 移动平均法22、在下列多重共线性产⽣的原因中,不正确的是____A.经济本变量⼤多存在共同变化趋势B.模型中⼤量采⽤滞后变量C.由于认识上的局限使得选择变量不当D.解释变量与随机误差项相关23、在DW 检验中,存在正⾃相关的区域是____A. 4-l d ﹤d ﹤4B. 0﹤d ﹤l dC. u d ﹤d ﹤4-u dD. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l d24、逐步回归法既检验⼜修正了____A .异⽅差性 B.⾃相关性 C .随机解释变量 D.多重共线性25、设)()(,2221i i i i i ix f u Var u x y σσββ==++=,则对原模型变换的正确形式为____ )()()()(.)()()()(.)()()()(..212222122121i i i i i i i i i i i i i i i i i i i i i i i i x f u x f x x f x f y D x f u x f x x f x f y C x f u x f x x f x f y B u x y A ++=++=++=++=ββββββββ 26、在修正序列⾃相关的⽅法中,不正确的是____A.⼴义差分法B.普通最⼩⼆乘法C.⼀阶差分法D. Durbin 两步法27、在检验异⽅差的⽅法中,不正确的是____A. Goldfeld-Quandt ⽅法B. spearman 检验法C. White 检验法28、在DW 检验中,存在零⾃相关的区域是____A. 4-l d ﹤d ﹤4B. 0﹤d ﹤l dC. u d ﹤d ﹤4-u dD. l d ﹤d ﹤u d ,4-u d ﹤d ﹤4-l d29.如果模型中的解释变量存在完全的多重共线性,参数的最⼩⼆乘估计量是()A .⽆偏的 B. 有偏的 C. 不确定 D. 确定的30. 已知模型的形式为u x y 21+β+β=,在⽤实际数据对模型的参数进⾏估计的时候,测得DW 统计量为0.6453,则⼴义差分变量是( )A. 1t t ,1t t x 6453.0x y 6453.0y ----B. 1t t 1t t x 6774.0x ,y 6774.0y ----C. 1t t 1t t x x ,y y ----D. 1t t 1t t x 05.0x ,y 05.0y ----31. 在具体运⽤加权最⼩⼆乘法时,如果变换的结果是x u x x x 1xy 21+β+β=,则Var(u)是下列形式中的哪⼀种?( )A. 2σxB. 2σ2x B. 2σx D. 2σLog(x)32. 在线性回归模型中,若解释变量1x 和2x 的观测值成⽐例,即有i 2i 1kx x =,其中k 为⾮零常数,则表明模型中存在( )A. 异⽅差B. 多重共线性C. 序列⾃相关D. 设定误差33. 已知DW 统计量的值接近于2,则样本回归模型残差的⼀阶⾃相关系数ρ近似等于( ) A. 0 B. –1 C. 1 D. 4⼆、多项选择1、能够检验多重共线性的⽅法有____A.简单相关系数法B. DW检验法C. 判定系数检验法D. ⽅差膨胀因⼦检验E.逐步回归法2、能够修正多重共线性的⽅法有____A.增加样本容量B.岭回归法C.剔除多余变量E.差分模型3、如果模型中存在异⽅差现象,则会引起如下后果____A. 参数估计值有偏B. 参数估计值的⽅差不能正确确定C. 变量的显著性检验失效D. 预测精度降低E. 参数估计值仍是⽆偏的4、能够检验异⽅差的⽅法是____A. gleiser检验法B. White检验法C. 图形法D. spearman检验法E. DW检验法F. Goldfeld-Quandt检验法5、如果模型中存在序列⾃相关现象,则会引起如下后果____A. 参数估计值有偏B. 参数估计值的⽅差不能正确确定C. 变量的显著性检验失效D. 预测精度降低E. 参数估计值仍是⽆偏的6、检验序列⾃相关的⽅法是____A. gleiser检验法B. White检验法C. 图形法D. DW检验法E. Goldfeld-Quandt检验法7、能够修正序列⾃相关的⽅法有____A. 加权最⼩⼆乘法B. Durbin两步法C. ⼴义最⼩⼆乘法D. ⼀阶差分法E. ⼴义差分法8、Goldfeld-Quandt检验法的应⽤条件是____A. 将观测值按解释变量的⼤⼩顺序排列B. 样本容量尽可能⼤C. 随机误差项服从正态分布D. 将排列在中间的约1/4的观测值删除掉9、在DW检验中,存在不能判定的区域是____A. 0﹤d﹤l dB. u d﹤d﹤4-u dC. l d﹤d﹤u dD. 4-u d﹤d﹤4-l dE. 4-l d﹤d﹤4。
计量第四章作业

Southwestern University of Finance andEconomics计量第四章作业天姝41112011班级:11级金融服务与管理实验题目一表中给出了美国1971-1986年期间的数据,其中Y :售出新客车的数量(千量); X2: 新车价格指数(1967=100);X3:居民消费价格指数(1967=100);X4:个人可支配收入(PDI,10亿美元);X5:利率;X6:城市就业劳动力(千人)。
考虑下面的客车需求函数:12233445566ln ln ln ln ln ln t t t t t t tY X X X X X u ββββββ=++++++(1)用OLS 法估计样本回归方程;(2)如果模型存在多重共线性,试估计各辅助回归方程,找出那些变量是高度共线性的。
(3)如果存在严重的共线性,你会除去哪一个变量,为什么?(4)在除去一个或多个解释变量后,最终的客车需求函数是什么?这个模型在哪些方面好于包括所有解释变量的原始模型?(5)你认为还有哪些变量可以更好的解释美国的汽车需求?(1)新的回归方程:2346ln 7.142989 1.942652ln -4.464915ln +2.397534ln -0.142488ln t t t t tY X X X X =+各参数的系数变化没有特别大的变化,修正后的多重可决系数有所上升、F 统计量也有所上升,各变量的t 检验的统计量显著水平有所上升。
(5)汽油价格,国外汽车的价格等因素也会影响美国的汽车需求。
(3)选择适当方法,消除多重共线性,建立一个较好的回归模型。
(1)估计的回归方程:Y=4968.295+0.557410X2+5.256011X3-0.720540X4-0.206228X5-0.4 46377X6-9.148800X7-0.618037X8。
计量经济学课后答案第四、五章(内容参考)

计量经济学课后答案第四、五章(内容参考)第四章随机解释变量问题1. 随机解释变量的来源有哪些?答:随机解释变量的来源有:经济变量的不可控,使得解释变量观测值具有随机性;由于随机干扰项中包括了模型略去的解释变量,而略去的解释变量与模型中的解释变量往往是相关的;模型中含有被解释变量的滞后项,而被解释变量本身就是随机的。
2.随机解释变量有几种情形? 分情形说明随机解释变量对最小二乘估计的影响与后果?答:随机解释变量有三种情形,不同情形下最小二乘估计的影响和后果也不同。
(1)解释变量是随机的,但与随机干扰项不相关;这时采用OLS估计得到的参数估计量仍为无偏估计量;(2)解释变量与随机干扰项同期无关、不同期相关;这时OLS估计得到的参数估计量是有偏但一致的估计量;(3)解释变量与随机干扰项同期相关;这时OLS估计得到的参数估计量是有偏且非一致的估计量。
3. 选择作为工具变量的变量必须满足那些条件?答:选择作为工具变量的变量需满足以下三个条件:(1)与所替代的随机解释变量高度相关;(2)与随机干扰项不相关;(3)与模型中其他解释变量不相关,以避免出现多重共线性。
4.对模型Y t =β+β1X1t+β2X2t+β3Yt-1+μt假设Yt-1与μt相关。
为了消除该相关性,采用工具变量法:先求Y t关于X1t与 X2t回归,得到Yt,再做如下回归:Y t =β+β1X1t+β2X2t+β3Y t?1-+μt试问:这一方法能否消除原模型中Yt的相关性? 为什么?解答:能消除。
在基本假设下,X1t,X2t与μt应是不相关的,由此知,由X1t 与X2t估计出的Yt应与μt不相关。
5.对于一元回归模型Y t =β+β1Xt*+μt假设解释变量Xt *的实测值Xt与之有偏误:Xt= Xt*+et,其中et是具有零均值、无序列相关,且与Xt不相关的随机变量。
试问:(1) 能否将X t= X t*+e t代入原模型,使之变换成Y t=β0+β1X t+νt后进行估计? 其中,νt为变换后模型的随机干扰项。
计量经济学作业,DOC

计量经济学作业第二章为了初步分析城镇居民家庭平均每百户计算机用户有量(Y)与城镇居民平均每人全年家庭总收入(X)的关系,可以作以X为横坐所估计的参数,总收入每增加1元,平均说来城镇居民每百户计算机拥有量将增加0.002873台,这与预期的经济意义相符。
拟合优度和统计检验拟合优度的度量:本例中可决系数为0.8320,说明所建模型整体上对样本数据拟合较好,即解释变量“各地区城镇居民家庭人均总收入”对被解释变量“各地区城镇居民每百户计算机拥有量”的绝大部分差异做出了解释。
对回归系数的t检验:针对和,估计的回归系数的标准误差和t值分别为:,;的标准误差和t值分别为:,。
因为,绝;因,所以应拒绝。
城镇居民人均总收入对城镇居民每百取,平均置信度已经得到、、、n=31,可计算出。
当时,将相关数据代入计算得到83.7846 3.1627,即是说当地区城镇居民人均总收入达到25000元时,城镇居民每百户计算机拥有量平均值置信度95%的预测区间为(80.6219,86.9473)台。
个别置信度95%的预测区间为当时,将相关数据代入计算得到83.784616.7190是说,当地区城镇居民人均总收入达到元时,城镇居民每百户计算机拥有量化,选择“教育支出在地方财政支出中的比重”作为其代表。
探索将模型设定为线性回归模型形式:根据图中的数据,模型估计的结果写为(935.8816)(0.0018)(0.0080)(0.0517)(9.0867)(470.3214)t=(-2.5820)(6.3167)(4.9643)(2.8267)(2.5109)(1.8422)=0.9732F=181.7539n=31模型检验1.经济意义检验模型估计结果说明,在嘉定齐天然变量不变的情况下,地区生产12中数据可以得到:=0.9732可决系数为=0.9679:,性水平,在分布表中查出自由度为k-1=5何n-k=25界值.由表3.4得到F=181.7539,由于F=181.7539>,应拒绝原假设:,说明回归方程显著,即“地区生产总值”,“年末人口数”,“居民平均每人教育现金消费”,“居民教育消费价格指数”,“教育支出在地方财政支出中的比重”等变量联合起来确实对“地方财政教育支出”有显著影响。
计量经济学第四章作业参考答案

4.3(1)由题知,对数回归模型为:123ln ln ln t t t i Y G D P C PI u βββ=+++ 用最小二乘法对参数进行估计得:ˆl n 3.6491.796l n 1.208l nt tt Y G D P C P I =-+- (0.322) (0.181) (0.354)t=-11.32129 9.931363 -3.41496120.990R = 20.988R = S.E.=0.112388 F=770.602(2)存在多重共线性。
居民消费价格指数的回归系数的符号不能进行合理的经济意义解释,且其简单相关系数为0.985811,说明lnGDP 和lnCPI 存在正相关的关系。
(3)根据题目要求进行如下回归: ○1模型为:121ln ln t t i Y A A G D P v =++ 用最小二乘法对参数进行估计得: l n 3.7451.187l nt t Y G D P =-+ (0.410) (0.039) t= -9.143326 30.65940 20.982R = 20.981R = S.E.=0.143363 F=939.999 ○2模型为:122ln ln t t i Y B B C PI v =++用最小二乘法对参数进行估计得: l n 3.392.254l n t t Y CPI =-+(0.834) (0.154) t= -4.064199 14.62649 20.926R = 20.922R = S.E.=0.291842 F=213.934○3模型为:122ln ln tt i Y B B C PI v =++用最小二乘法对参数进行估计得:l n 0.1441.927l n t t GDP CPI =+ (0.431) (0.080)t= 0.334092 24.2143920.972R = 20.970R = S.E.=0.150715 F=586.337单方程拟合效果都很好,回归系数显著,判定系数较高,GDP 和CPI 对进口的显著的单一影响,在这两个变量同时引入模型引起了多重共线性。
计量经济学作业实验四、五(1)
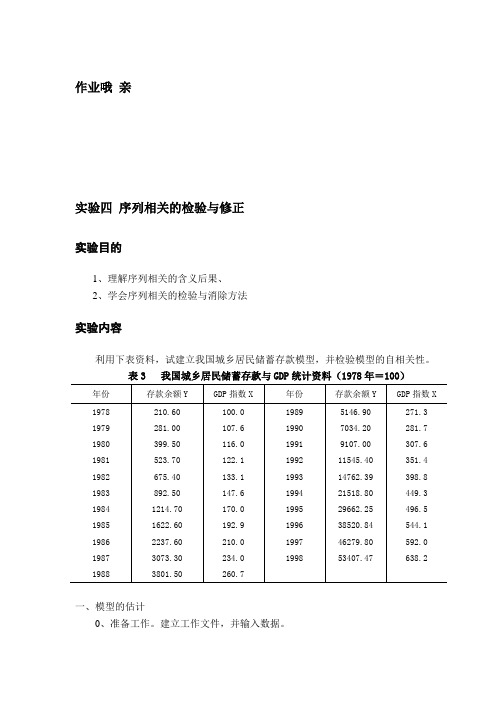
作业哦亲实验四序列相关的检验与修正实验目的1、理解序列相关的含义后果、2、学会序列相关的检验与消除方法实验内容利用下表资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。
表3 我国城乡居民储蓄存款与GDP统计资料(1978年=100)一、模型的估计0、准备工作。
建立工作文件,并输入数据。
1、相关图分析 SCAT X Y相关图表明,GDP 指数与居民储蓄存款二者的曲线相关关系较为明显。
现将函数初步设定为线性、双对数等不同形式,进而加以比较分析。
2、估计模型,利用LS 命令分别建立以下模型 ⑴线性模型: LS Y C Xx y5075.9284.14984ˆ+-= =t (-6.706) (13.862)2R =0.9100 F =192.145 S.E =5030.809⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNXx yln 9588.20753.8ˆln +-= =t (-31.604) (64.189)2R =0.9954 F =4120.223 S.E =0.12213、选择模型比较以上模型,可见各模型回归系数的符号及数值较为合理。
各解释变量及常数项都通过了t 检验,模型都较为显著。
比较各模型的残差分布表。
线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这种函数形式设置是不当的。
而且,这个模型的拟合优度也较双对数模型低,所以又可舍弃线性模型。
双对数模型具有很高的拟合优度,因而初步选定回归模型为双对数回归模型。
二、模型自相关的检验1.图示法其一,残差序列e t 的变动趋势图。
菜单:Quick→Graph→line ,在对话框中输入resid ;或者用命令操作,直接在命令行输入:line X 。
其二,作e t-1和e t 之间的散点图。
菜单:Quick→Graph→Scatter ,在对话框中输入resid(-1) resid ;或者用命令操作,直接在命令行输入:scat resid(-1) resid 。
计量经济学作业

计量经济学作业(5-7)一、作业五1. 在存在异方差情况下,普通最小二乘法(OLS )估计量是有偏的和无效的。
()2. 当存在自相关时,OLS 估计量是有偏的并且也是无效的。
()3. 如果在多元回归模型中,根据通常的t 检验,全部回归系数分别都是统计上不显著的,那么该模型不会有一个高的R 2值。
()4. 在时间序列模型中,遗漏重要解释变量既有可能导致异方差问题,又有可能导致自相关问题。
()5. 变量是非线性的回归模型在计量经济学上不被称作线性回归模型。
()6. 随机误差项μi 与残差e i 是一回事。
()7. 给定显著性水平α及自由度,若计算得到的t 值超过临界的t 值,则接受原假设。
8. 蛛网现象可能会带来计量经济模型的自相关问题。
()9. 无论模型中包括多少个解释变量,总离差平方和(TSS )的自由度总为(n-1)。
() 10. 在多元线性回归模型中,方差膨胀因子(VIF )一定是不小于1。
() 11. 在存在异方差情况下,常用的OLS 法总是高估了估计量的标准差。
() 12. 若假定自相关系数等于1,那么一阶差分变换能够消除自相关。
() 13. 存在多重共线时,模型参数无法估计。
()14. 如果在多元回归模型中,根据通常的t 检验,全部回归系数分别都是统计上不显著的,那么该模型不会有一个高的R 2值。
()15. 当我们得到参数区间估计的上下限的具体数值后,就可以说参数的真实值落入这个区间的概率为1-α. ()16. p 值和显著性水平α是一回事。
()17. 只有当μi 服从正态分布时,OLS 估计量才服从正态分布。
()18. 多元回归模型的总体显著性意味着模型中任何一个变量都是统计显著的。
() 19. 戈德菲尔德-夸特检验(GQ 检验)可以检验复杂性的异方差。
() 20. 残差平方和除以自由度(n-k )始终是随机误差项μi 方差(2σ)的无偏估计量。
() 21. 用一阶差分法消除自相关时,我们假定自相关系数等于-1。
计量经济学课后答案——张龙版

计量经济学第一次作业第二章P858.用SPSS软件对10名同学的成绩数据进行录入,分析得r=,这说明学生的课堂练习和期终考试有密切的关系,一般平时练习成绩较高者,期终成绩也高。
9.(1)一元线性回归模型如下:Y i=ß0+ß1X i+u i其中,Yi 表示财政收入,Xi表示国民生产总值,ui为随机扰动项,ß0 ß1为待估参数。
由Eviews软件得散点图如下图:(2)Ýi=+SÊ:t:R2=0.958316 F= df=28斜率ß1=表示国民生产总值每增加1亿元,财政收入增加亿元。
(3)可决系数R2=表示在财政收入Y的总变差中由模型作出的解释部分占%,即有%由国民生产总值来解释,同时说明样本回归模型对样本数据的拟合程度较高。
R2=ESS/(ESS+RSS)ESS=RSS*R2/(1-R2)=+08)*=+08F=(n-2)ESS/RSS,ESS=F*RSS/(n-2)=*E09(4)SÊ(ß0)= SÊ(ß1)=ß1的95%的置信区间是:[ß(28)S Ê(ß1),ß1+(28)S Ê(ß1)] 代入数值得: [即:[,]同理可得,ß0的95%置信区间为[,] (5)①原假设H 0:ß0=0 备择假设:H 1:ß0≠0则ß0的t 值为:t 0=当ɑ=时t ɑ/2(28)=|t 0|=>t ɑ/2(28)= 故拒绝原假设H 0,表明模型应保留截距项。
②原假设H 0:ß1=0 备择假设:H 1:ß1≠0当ɑ=时t ɑ/2(28)= 因为|t 1|=>t ɑ/2(28)=故拒绝原假设H 0表明国民生产总值的变动对国家财政收入有显著影响.计量经济学第二次作业第二章9.(10) 、建立X 与t 的趋势模型,其回归分析结果如下:Dependent Variable: X Method: Least Squares Date: 04/19/10 Time: 22:03 Sample: 1978 2008Included observations: 31Dependent Variable: Y Method: Least Squares Date: 04/10/10 Time: 17:31 Sample: 1978 2007Included observations: 30VariableCoefficien t Std. Error t-StatisticProb.C XR-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid +08 Schwarz criterionLog likelihood F-statistic Durbin-Watson statProb(F-statistic)VariableCoefficien t Std. Error t-StatisticProb.T CR-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid +10 Schwarz criterionLog likelihood F-statistic Durbin-Watson statProb(F-statistic)令t=2008,其预测结果X=再根据X 对Y 进行预测,其预测结果为Y= X 2008= Y 2008=(S Ê(e 0))2—(S Ê(Y0))2=ó2 所以S Ê(e 0)= 在95%的置信度下,Y 2008的预测区间为: [Y 0-t α/2S Ê(e 0),Y 0+t α/2S Ê(e 0)]=[,]第三章P124,6. 该家庭在衣着用品方面的开支(Y )对总开支(X 1)以及衣着用品价格(X 2)的最小二乘估计结果如下:Dependent Variable: Y Method: Least Squares Date: 04/20/10 Time: 09:24 Sample: 1991 2000Included observations: 10VariableCoefficien t Std. Error t-StatisticProb.C X1 X2R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid Schwarz criterion Log likelihoodF-statisticDurbin-Watson stat Prob(F-statistic)12- 3.755455 + 0.183866 + 0.301746 i i i Y X X = :SE (2.679575) (0.028973) (0.167644) :t (-1.401511) (6.346071) (1.799923) :P (0.2038) (0.0004) (0.1149) 20.960616R = 2 0.949364R = :F (85.36888) ():(0.000012)P F :(2.725104)DW 7df =在=5%α的显著性水平下,对解释变量的估计参数1ˆβ、2ˆβ进行检验: 0111:0,:0H H ββ=≠,1{ 6.346071}0.0004<=0.05P t t α>==,1t 落入拒绝域,接受备择假设1H ,1ˆβ不显著为0,即就单独而言,总开支(X 1)对衣着用品方面的开支(Y )影响显著。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计量经济学小组作业
论文题目:
浙江省三次产业对该地区生产总值的影响
组别:第四组
组员姓名:杨纯妮P100210129
张远平P100210130
张滕P100210133
黄晨晖P100210134
何丽芳P100210135
吴垠P100210136
分析浙江省三大产业对浙江省经济增长的影响
摘要:
地区生产总值是衡量一个地区经济增长的重要的指标,它是一个国家或者地区在一定时期内生产的所有的商品或劳务的增加量的总和。
三大产业是地区生产总值的重要组成部分,用生产法通过三大产业的增加值可以计算地区生产总值。
本次作业就是要通过三大产业分析其对地区生产总值的影响。
浙江省是我国沿海地区经济发达的省份,其三次产业结构分布比较合理,研究其经济结构有助于实现研究的目的,这是本次作业选为研究对象的原因,并且对于地区经济增长有重要的意义。
关键字:地区生产总值三大产业影响产业结构
引言:
地区生产总值的计算方法有生产法、分配法、使用法三种方法。
本次作业就是要运用生产法的原理来验证三大产业对地区生产总值的影响。
生产法的原理是:
地区生产总值=∑(各产业的总产出-改产业的中间消耗)(公式一)=∑各个产业的增加值
=∑(第一产业的增加值+第二产业的增加值+第三产业的增加值)
=∑(第一产业的生产总值+第二产业的生产总值+地三产业的生产总值)
(公式二)运用生产法知道了三次产业与地区生产总值之间的关系,我们就可以对它们进行相关的分析。
但是它们之间的关系的相关性如何?他们之间的回归线性方程会是怎样的呢?通过下面的过程我们就可以推算出该回归线性方程。
一.进行模型的建立。
通过对浙江省1978年到2010年的数据的观察和分析,我们进行了以下假设:
Y=c+β1X1+β2X2+β3X3 (方程一)
其中:
Y代表地区生产总值
c 代表常数项
β1代表第一产业的相关系数
β2代表第二产业的相关系数
β3代表第三产业的相关系数
X1代表第一产业的地区生产总值
X2代表第二产业的地区生产总值
X3代表第三产业的地区生产总值
因为地区生产总值=第一产业生产总值+第二产业生产总值+第三产业生产总值,所以通过求三大产业各自的系数来达到此次作业的目的。
二.数据的来源及整理
三.数据的基本分析
(一)对被解释变量和解释变量进行相关性分析。
相关性分析如下图所示:
相关性分析
如上图所示,从其显示出来的相关系数矩阵中可以看出,Y 分别与X 1、X 2、X 3之间的相关系数分别达到了0.937216、0.999660、0.998536,说明了Y 与X 1、X 2、X 3存在着很强的正相关关系,线性模型在解释它们的关系时是比较恰当的,即地区生产总值与三次产业之间的关系性很强。
(二)做散点图。
如下图所示:
散点图
04,000
8,000
12,000
16,000
20,000
24,000
400
8001,200
1,600
X1
Y
上面三副散点图分别显示了三次产业与地区生产总值之间的关系。
从图中我们可以看出三次产业与地区生产总值关系紧密,尤其是第二、三产业更为明显,他们之间的关系基本上呈直线关系。
其中第一产业对地区生产总值的影响分为两个部分,即,当第一产业小于600亿元的时候,它对地区生产总值的影响较小,从表中我们可以知道这段时间刚好是在20世纪90年代的前5年,也就是说,从1996年开始浙江生省的第一产业开始迅猛发展,也就是图中第一产业大于600亿元以后的那部分。
(三)对该模型进行回归分析
从相关性分析中我们已经知道变量之间有较强的线性关系,我们用(方程一)来进行模型估计,估计结果如入下图所示:
回归分析结果
根据回归分析图的回归结果我们可以得到如下的方程:
Y=6.264422+0.949553X1+0.998902X2+1.007313X3
(0.821283 )(26.69746)(55.95868)(49.54988)
R2=0.999993 DW=2.396712 F=1217724
从表中我们可以分析得到:
(1)R2、R2接近于1,表明模型的拟合优度非常好,反之,如果R2越接近于0,则说明回归直线对观测值的拟合程度很差。
从上图我们可以看出,回归直线对观测值的拟合程度很好。
(2)F检验是多总体线性显著行检验,从图中知其相伴概率是0.000000,反映了变量之间高度线性,方程的回归效果显著。
(3)t检验是检验每个解释变量对被解释变量的显著性关系的检验,图中回归系数t统计量表明第一产业产值X1、第二产业产值X2、第三产业产值X3对于地区生产总值有显著性影响。
(4)从表中可以看出C的t检验的值是0.821283,p=0.4187.根据t检验的假设,因为0.4187>0.05,所以t检验不通过,也就是说,C与地区生产总值之间没有关系或者是不存在线性关系。
原因是:本次作业是把地区生产总值作为被解释变量,把第一、二、三产业的生产总值作为解释变量,只要把三次产业的总和想加就可以得到地区生产总值,其他的因素与地区生产总值没有关系,所以常数项就没有通过检验。
因为没有通过t 检验的解释变量按常理应该被踢出的,但在模型中常数项可以被存在并且常数项对被解释变量已经没有了影响,所以在此就不在考虑常数项。
(5)利用回归方程中的各个变量的相关系数可以分析各个自变量的边际效应,即在其他变量不变的情况下自变量每变化一个单位对被解释变量带来的变化。
就对第一产业来说,它的回归系数是0.949553,在第二、三产业保持不变的情况下,每当第一产业增加一个单位时,就会0.9495个单位的第一产业的总值转换为地区生产总值,第二、三产业也同样。
以上的五点就是对案例的回归分析或者是统计检验,其中的第(5)是从经济的角度来分析的,揭示的是该模型的经济意义。
综上所述,我们可以应用该模型。
四估计预测区间
预测区间估计
从预测区间估计里面我们可以看出一些信息:X1的均值、中位数、最大值、最小值分别是463.9732、438.6500、1163.080、64.61000;X2的均值、中位数、最大值、最小值分别为2901.903、1398.120、11908.49、64.07000;X3的均值、中位数、最大值、最小值分别为2128.195、852.5100、9918.780、26.12000;地区生产总值的均值、中位数、最大值、最小值分别为5489.307、2689.280、22990.35、157.7500。
总的样本个数为31个,地区生产总值和三次产业各自的总和分别为170168.5、14383.17、89958.99、65974.05。
由于其置信区间的计算过程复杂,在加上水平有限,所以在此不便计算。
五.用该模型的预测与运用
用该模型进行预测的原理和过程如下:通过一直变量来推算出未知变量。
现在已知三次产业2010年各自的生产总值,即已知X1=1360.56,X2=14297.93,X3=12063.82,现在所要做的工作是通过一致的值来推算2010年的地区生产总值。
预测的结果如下:
预测分析
从上面预测的图中我们可以看出:预测的Y的值为27732.46,实际值为27722.31,二者的差距仅为10.15,这说明了预测值与真实值非常相近。
同时也再一次说明了样本与总体的拟合度很好,验证了上述原理。
因此,可以近似的运用此模型方程作为浙江省地区生产总值与三次产业关系的预测方程,即:
Y=6.264422+0.949553X1+0.998902X2+1.007313X3;
每个地区都会有该地区的生产总值,地区生产总值同GDP一样是可以通过某些实际的指标计算出来的。
地区的生产总值可以通过以产业产值为指标,通过加总来计算,这是计算GDP或者地区生产总值的一种方法。
参考文献:1 《计量经济学》(第三版)李子奈潘文卿编著高等教育出版社
2 《EViews应用实验教材》任英华主编湖南大学出版社
3 《统计学》(第三版)袁卫庞皓曾五一贾俊平主编高等教育出版社
4 《西方经济学》(微观部分)第五版高鸿业主编中国人民大学出版社
5 2011年浙江省统计年鉴浙江省统计局编制。