数据库系统实现(第二版)答案ch6
(完整版)数据库原理和应用(第2版)习题参考答案解析

第1章数据概述一.选择题1.下列关于数据库管理系统的说法,错误的是CA.数据库管理系统与操作系统有关,操作系统的类型决定了能够运行的数据库管理系统的类型B.数据库管理系统对数据库文件的访问必须经过操作系统实现才能实现C.数据库应用程序可以不经过数据库管理系统而直接读取数据库文件D.数据库管理系统对用户隐藏了数据库文件的存放位置和文件名2.下列关于用文件管理数据的说法,错误的是DA.用文件管理数据,难以提供应用程序对数据的独立性B.当存储数据的文件名发生变化时,必须修改访问数据文件的应用程序C.用文件存储数据的方式难以实现数据访问的安全控制D.将相关的数据存储在一个文件中,有利于用户对数据进行分类,因此也可以加快用户操作数据的效率3.下列说法中,不属于数据库管理系统特征的是CA.提供了应用程序和数据的独立性B.所有的数据作为一个整体考虑,因此是相互关联的数据的集合C.用户访问数据时,需要知道存储数据的文件的物理信息D.能够保证数据库数据的可靠性,即使在存储数据的硬盘出现故障时,也能防止数据丢失5.在数据库系统中,数据库管理系统和操作系统之间的关系是DA.相互调用B.数据库管理系统调用操作系统C.操作系统调用数据库管理系统D.并发运行6.数据库系统的物理独立性是指DA.不会因为数据的变化而影响应用程序B.不会因为数据存储结构的变化而影响应用程序C.不会因为数据存储策略的变化而影响数据的存储结构D.不会因为数据逻辑结构的变化而影响应用程序7.数据库管理系统是数据库系统的核心,它负责有效地组织、存储和管理数据,它位于用户和操作系统之间,属于AA.系统软件B.工具软件C.应用软件D.数据软件8.数据库系统是由若干部分组成的。
下列不属于数据库系统组成部分的是BA.数据库B.操作系统C.应用程序D.数据库管理系统9.下列关于客户/服务器结构和文件服务器结构的描述,错误的是DA.客户/服务器结构将数据库存储在服务器端,文件服务器结构将数据存储在客户端B.客户/服务器结构返回给客户端的是处理后的结果数据,文件服务器结构返回给客户端的是包含客户所需数据的文件C.客户/服务器结构比文件服务器结构的网络开销小D.客户/服务器结构可以提供数据共享功能,而用文件服务器结构存储的数据不能共享数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
数据库系统实现课后习题答案
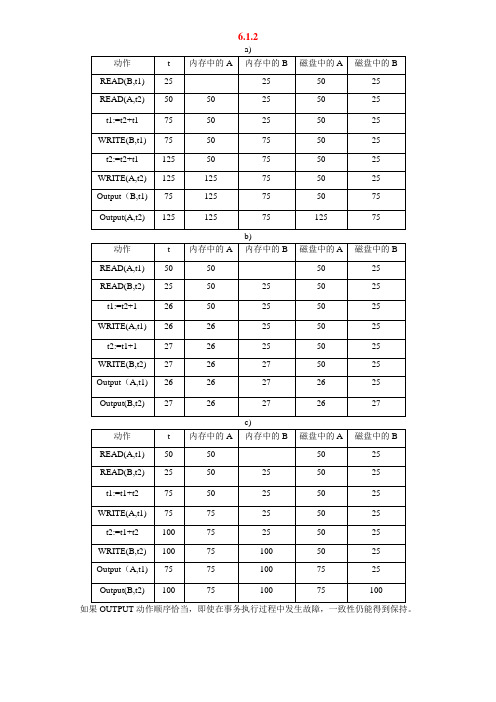
6.1.2如果OUTPUT动作顺序恰当,即使在事务执行过程中发生故障,一致性仍能得到保持。
6.2.3答案1若题目是:<START U>; <U,A,10>; <START T> ….则答案是a)首先扫描日志,发现事务T和U都未commit,将其连接到未完成事务列.按照未完成事务列,从后往前逐步扫描日志并执行undo操作,按照<U,A,10>将磁盘中A值写为10,将<ABORT T>和<ABORT U>写入日志中并刷新日志。
b)首先扫描日志,发现事务T已经commit,将其连接到已完成事务列,事务U未完成,将其连接到未完成事务列。
按照未完成事务列,从后往前扫描日志执行undo操作,按照<U,C,30>将磁盘中C值写为30,<U,A,10>将磁盘A值写为10。
将<ABORT U>写入日志中并刷新日志。
c)首先扫描日志,发现事务T已经commit,将其连接到已完成事务列,事务U未完成,将其连接到未完成事务列。
按照未完成事务列从后往前扫描日志执行undo操作,按照<U,E,50>将磁盘中E值写为50,<U,C,30>将磁盘中C值写为30,<U,A,10>将磁盘A值写为10。
将<ABORT U>写入日志中并刷新日志。
d)首先扫描日志,发现事务T、U已经commit,将其连接到已完成列,未完成列为空,不做任何操作。
答案2a) <START T>事务T、U未提交,要被撤销。
向后扫描日志,遇到记录<U,A,10>,于是将A在磁盘上的值存为10。
最后,记录<ABORT U>和<ABORT T>被写到日志中且日志被刷新。
b) <COMMIT T>事务T已提交,U未提交,要被撤销。
向后扫描日志,首先遇到记录<U,C,30>,于是将C在磁盘上的值存为30。
数据库系统实现(第二版_英文版)部分答案

⌈n/(50×80%)⌉blocks are needed for the data file, and ⌈n/(500×80%)⌉ for the index, for a total of ⌈n/40⌉ + ⌈n/400⌉ blocks. We again need ⌈n/(50×80%)⌉for the data file, but now need only room for ⌈n/(50×80%) /(500×80%)⌉pointers in the index file. The latter takes ⌈n/16000⌉blocks, for a total of ⌈n/40⌉+ ⌈n/16000⌉ blocks.
The
average tracks the heads have to move: [(1+2+……+4095)+(1+2+……(65536-4096)]/65536≈28928
1
Seek
4096
65536
time: 1+28928/4000=8.232ms Transfer time = 0.13ms Rotational latency = 4.17ms Average seek time + average rotational latency +average transfer time = 12.532ms
数据库系统及应用课后练习答案

《数据库系统及应用》(第二版)习题解答习题一1.什么是数据库?数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
2.简要概述数据库、数据库管理系统和数据库系统各自的含义。
数据库、数据库管理系统和数据库系统是三个不同的概念,数据库强调的是相互关联的数据,数据库管理系统是管理数据库的系统软件,而数据库系统强调的是基于数据库的计算机应用系统。
3.数据独立性的含义是什么?数据独立性是指数据的组织和存储方法与应用程序互不依赖、彼此独立的特性。
这种特性使数据的组织和存储方法与应用程序互不依赖,从而大大降低应用程序的开发代价和维护代价。
4.数据完整性的含义是什么?保证数据正确的特性在数据库中称之为数据完整性。
5.简要概述数据库管理员的职责。
数据库管理员的职责可以概括如下:(1)首先在数据库规划阶段要参与选择和评价与数据库有关的计算机软件和硬件,要与数据库用户共同确定数据库系统的目标和数据库应用需求,要确定数据库的开发计划;(2)在数据库设计阶段要负责数据库标准的制定和共用数据字典的研制,要负责各级数据库模式的设计,负责数据库安全、可靠方面的设计;(3)在数据库运行阶段首先要负责对用户进行数据库方面的培训;负责数据库的转储和恢复;负责对数据库中的数据进行维护;负责监视数据库的性能,并调整、改善数据库的性能,提高系统的效率;继续负责数据库安全系统的管理;在运行过程中发现问题、解决问题。
6.文件系统用于数据管理存在哪些明显的缺陷?文件系统用于数据管理明显存在如下缺陷:(1)数据冗余大。
这是因为每个文件都是为特定的用途设计的,因此就会造成同样的数据在多个文件中重复存储。
(2)数据不一致性。
这往往是由数据冗余造成的,在进行更新时,稍不谨慎就会造成同一数据在不同文件中的不一致。
数据库系统教程课后答案(施伯乐)(第二版)

目录第1部分课程的教与学第2部分各章习题解答及自测题第1章数据库概论1.1 基本内容分析1.2 教材中习题1的解答1.3 自测题1.4 自测题答案第2章关系模型和关系运算理论2.1基本内容分析2.2 教材中习题2的解答2.3 自测题2.4 自测题答案第3章关系数据库语言SQL3.1基本内容分析3.2 教材中习题3的解答3.3 自测题3.4 自测题答案第4章关系数据库的规范化设计4.1基本内容分析4.2 教材中习题4的解答4.3 自测题4.4 自测题答案第5章数据库设计与ER模型5.1基本内容分析5.2 教材中习题5的解答5.3 自测题5.4 自测题答案第6章数据库的存储结构6.1基本内容分析6.2 教材中习题6的解答第7章系统实现技术7.1基本内容分析7.2 教材中习题7的解答7.3 自测题7.4 自测题答案第8章对象数据库系统8.1基本内容分析8.2 教材中习题8的解答8.3 自测题8.4 自测题答案第9章分布式数据库系统9.1基本内容分析9.2 教材中习题9的解答9.3 自测题9.4 自测题答案第10章中间件技术10.1基本内容分析10.2 教材中习题10的解答10.3 自测题及答案第11章数据库与WWW11.1基本内容分析11.2 教材中习题11的解答第12章 XML技术12.1基本内容分析12.2 教材中习题12的解答学习推荐书目1.国内出版的数据库教材(1)施伯乐,丁宝康,汪卫. 数据库系统教程(第2版). 北京:高等教育出版社,2003(2)丁宝康,董健全. 数据库实用教程(第2版). 北京:清华大学出版社,2003(3)施伯乐,丁宝康. 数据库技术. 北京:科学出版社,2002(4)王能斌. 数据库系统教程(上、下册). 北京:电子工业出版社,2002(5)闪四清. 数据库系统原理与应用教程. 北京:清华大学出版社,2001(6)萨师煊,王珊. 数据库系统概论(第3版). 北京:高等教育出版社,2000(7)庄成三,洪玫,杨秋辉. 数据库系统原理及其应用. 北京:电子工业出版社,20002.出版的国外数据库教材(中文版或影印版)(1)Silberschatz A,Korth H F,Sudarshan S. 数据库系统概念(第4版). 杨冬青,唐世渭等译. 北京:机械工业出版社,2003(2)Elmasri R A,Navathe S B. 数据库系统基础(第3版). 邵佩英,张坤龙等译. 北京:人民邮电出版社,2002(3)Lewis P M,Bernstein A,Kifer M. Databases and Transaction Processing:An Application-Oriented Approach, Addison-Wesley, 2002(影印版, 北京:高等教育出版社;中文版,施伯乐等译,即将由电子工业出版社出版)(4)Hoffer J A,Prescott M B,McFadden F R. Modern Database Management. 6th ed. Prentice Hall, 2002(中文版,施伯乐等译,即将由电子工业出版社出版)3.上机实习教材(1)廖疆星,张艳钗,肖金星. PowerBuilder 8.0 & SQL Server 2000数据库管理系统管理与实现. 北京:冶金工业出版社,2002(2)伍俊良. PowerBuilder课程设计与系统开发案例. 北京:清华大学出版社,20034.学习指导书(1)丁宝康,董健全,汪卫,曾宇昆. 数据库系统教程习题解答及上机指导. 北京:高等教育出版社,2003(2)丁宝康,张守志,严勇. 数据库技术学习指导书. 北京:科学出版社,2003(3)丁宝康,董健全,曾宇昆. 数据库实用教程习题解答. 北京:清华大学出版社,2003 (4)丁宝康. 数据库原理题典. 长春:吉林大学出版社,2002(5)丁宝康,陈坚,许建军,楼晓鸿. 数据库原理辅导与练习. 北京:经济科学出版社,2001第1部分课程的教与学1.课程性质与设置目的现在,数据库已是信息化社会中信息资源与开发利用的基础,因而数据库是计算机教育的一门重要课程,是高等院校计算机和信息类专业的一门专业基础课。
数据库系统教程习题答案(施伯乐)(第2版)_数据库原理和应用

第2部分各章习题解答及自测题第1章数据库概论1.1 基本内容分析1.1.1 本章的重要概念(1)DB、DBMS和DBS的定义(2)数据管理技术的发展阶段人工管理阶段、文件系统阶段、数据库系统阶段和高级数据库技术阶段等各阶段的特点。
(3)数据描述概念设计、逻辑设计和物理设计等各阶段中数据描述的术语,概念设计中实体间二元联系的描述(1:1,1:N,M:N)。
(4)数据模型数据模型的定义,两类数据模型,逻辑模型的形式定义,ER模型,层次模型、网状模型、关系模型和面向对象模型的数据结构以及联系的实现方式。
(5)DB的体系结构三级结构,两级映像,两级数据独立性,体系结构各个层次中记录的联系。
(6)DBMSDBMS的工作模式、主要功能和模块组成。
(7)DBSDBS的组成,DBA,DBS的全局结构,DBS结构的分类。
(1)教材P23的图1.24(四种逻辑数据模型的比较)。
(2)教材P25的图1.27(DB的体系结构)。
(3)教材P28的图1.29(DBMS的工作模式)。
(4)教材P33的图1.31(DBS的全局结构)。
1.2 教材中习题1的解答1.1 名词解释·逻辑数据:指程序员或用户用以操作的数据形式。
·物理数据:指存储设备上存储的数据。
·联系的元数:与一个联系有关的实体集个数,称为联系的元数。
·1:1联系:如果实体集E1中每个实体至多和实体集E2中的一个实体有联系,反之亦然,那么E1和E2的联系称为“1:1联系”。
·1:N联系:如果实体集E1中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,而E2中每个实体至多和E1中一个实体有联系,那么E1和E2的联系是“1:N联系”。
·M:N联系:如果实体集E1中每个实体可以与实体集E2中任意个(零个或多个)实体有联系,反之亦然,那么E1和E2的联系称为“M:N联系”。
·数据模型:能表示实体类型及实体间联系的模型称为“数据模型”。
数据库原理及应用第2版习题参考答案...doc

第1章数据概述一.选择题1.下列关于数据库管理系统的说法,错误的是CA.数据库管理系统与操作系统有关,操作系统的类型决定了能够运行的数据库管理系统的类型B.数据库管理系统对数据库文件的访问必须经过操作系统实现才能实现C.数据库应用程序可以不经过数据库管理系统而直接读取数据库文件D.数据库管理系统对用户隐藏了数据库文件的存放位置和文件名2.下列关于用文件管理数据的说法,错误的是DA.用文件管理数据,难以提供应用程序对数据的独立性B.当存储数据的文件名发生变化时,必须修改访问数据文件的应用程序C.用文件存储数据的方式难以实现数据访问的安全控制D.将相关的数据存储在一个文件中,有利于用户对数据进行分类,因此也可以加快用户操作数据的效率3.下列说法中,不属于数据库管理系统特征的是CA.提供了应用程序和数据的独立性B.所有的数据作为一个整体考虑,因此是相互关联的数据的集合C.用户访问数据时,需要知道存储数据的文件的物理信息D.能够保证数据库数据的可靠性,即使在存储数据的硬盘出现故障时,也能防止数据丢失5.在数据库系统中,数据库管理系统和操作系统之间的关系是DA.相互调用B.数据库管理系统调用操作系统C.操作系统调用数据库管理系统D.并发运行6.数据库系统的物理独立性是指DA.不会因为数据的变化而影响应用程序B.不会因为数据存储结构的变化而影响应用程序C.不会因为数据存储策略的变化而影响数据的存储结构D.不会因为数据逻辑结构的变化而影响应用程序7.数据库管理系统是数据库系统的核心,它负责有效地组织、存储和管理数据,它位于用户和操作系统之间,属于AA.系统软件B.工具软件C.应用软件D.数据软件8.数据库系统是由若干部分组成的。
下列不属于数据库系统组成部分的是BA.数据库B.操作系统C.应用程序D.数据库管理系统9.下列关于客户/服务器结构和文件服务器结构的描述,错误的是DA.客户/服务器结构将数据库存储在服务器端,文件服务器结构将数据存储在客户端B.客户/服务器结构返回给客户端的是处理后的结果数据,文件服务器结构返回给客户端的是包含客户所需数据的文件C.客户/服务器结构比文件服务器结构的网络开销小D.客户/服务器结构可以提供数据共享功能,而用文件服务器结构存储的数据不能共享数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
(完整版)数据库原理和应用(第2版)习题参考答案解析

第1章数据概述一•选择题1 •下列关于数据库管理系统的说法,错误的是CA. 数据库管理系统与操作系统有关,操作系统的类型决定了能够运行的数据库管理系统的类型B. 数据库管理系统对数据库文件的访问必须经过操作系统实现才能实现C. 数据库应用程序可以不经过数据库管理系统而直接读取数据库文件D. 数据库管理系统对用户隐藏了数据库文件的存放位置和文件名2•下列关于用文件管理数据的说法,错误的是DA. 用文件管理数据,难以提供应用程序对数据的独立性B. 当存储数据的文件名发生变化时,必须修改访问数据文件的应用程序C. 用文件存储数据的方式难以实现数据访问的安全控制D. 将相关的数据存储在一个文件中,有利于用户对数据进行分类,因此也可以加快用户操作数据的效率3 •下列说法中,不属于数据库管理系统特征的是CA. 提供了应用程序和数据的独立性B. 所有的数据作为一个整体考虑,因此是相互关联的数据的集合C. 用户访问数据时,需要知道存储数据的文件的物理信息D. 能够保证数据库数据的可靠性,即使在存储数据的硬盘岀现故障时,也能防止数据丢失5 •在数据库系统中,数据库管理系统和操作系统之间的关系是DA. 相互调用B. 数据库管理系统调用操作系统C. 操作系统调用数据库管理系统D. 并发运行6.数据库系统的物理独立性是指DA. 不会因为数据的变化而影响应用程序B. 不会因为数据存储结构的变化而影响应用程序C. 不会因为数据存储策略的变化而影响数据的存储结构D. 不会因为数据逻辑结构的变化而影响应用程序7 •数据库管理系统是数据库系统的核心,它负责有效地组织、存储和管理数据,它位于用户和操作系统之间,属于AA. 系统软件B.工具软件C.应用软件D.数据软件8 •数据库系统是由若干部分组成的。
下列不属于数据库系统组成部分的是BA. 数据库B.操作系统C.应用程序D.数据库管理系统9 •下列关于客户/服务器结构和文件服务器结构的描述,错误的是DA. 客户/服务器结构将数据库存储在服务器端,文件服务器结构将数据存储在客户端B. 客户/服务器结构返回给客户端的是处理后的结果数据,文件服务器结构返回给客户端的是包含客户所需数据的文件C. 客户/服务器结构比文件服务器结构的网络开销小D. 客户/服务器结构可以提供数据共享功能,而用文件服务器结构存储的数据不能共享数据库是相互关联的数据的集合,它用综合的方法组织数据,具有较小的数据冗余,可供多个用户共享,具有较高的数据独立性,具有安全控制机制,能够保证数据的安全、可靠,允许并发地使用数据库,能有效、及时地处理数据,并能保证数据的一致性和完整性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Database System Implementation Solutions for Chapter 6Solutions for Section 6.1Solutions for Section 6.3Solutions for Section 6.4Solutions for Section 6.5Solutions for Section 6.6Solutions for Section 6.7Solutions for Section 6.8Solutions for Section 6.9Solutions for Section 6.10Solutions for Section 6.1Exercise 6.1.1(a)Technically, the U_S operator assumes that the arguments are sets, as well as the result. Since the arguments are really bags, the best we can do is use the SQL union operator, which removes duplicates from the output even if there are duplicates in the input. The answer is {(0,1), (2,3), (2,4), (3,4), (2,5), (0,2)}.Exercise 6.1.1(i){(1,0,1), (5,4,9), (1,0,1), (6,4,16), (7,9,16)}.Exercise 6.1.1(k){(0,1), (0,1), (2,4), (3,4)}. Note that all five tuples of R satisfy the first condition, that the first component is less than the second. The last two tuples satisfy the condition that the sum of the components is at least 6, and the tuple (0,1) satisfies the condition that the sum exceed the product. Onlythe tuple (2,3) satisfies neither of the latter two conditions, and therefore doesn't appear in the result.Exercise 6.1.2(a){(0,1,2), (0,1,2), (0,1,2), (0,1,2), (2,3,5), (2,4,5), (3,4,5)}.Exercise 6.1.2(e){(0,1,4,5), (0,1,4,5), (2,3,2,3), (2,4,2,3)}.Exercise 6.1.2(g){(0,2), (2,7), (3,4)}.Exercise 6.1.3(a)One way to express the semijoin is by projecting S onto the list L of attributes in common with R and then taking the natural join: R JOINpi_L(S).A second way is to take the natural join first, and then project onto the attributes of R.Exercise 6.1.3(c)First, we need to find the tuples of R that don't join with S and therefore need to be padded. Let T = R - pi_M(R JOIN S), where M is the schema, or list of attributes, of R. Then the left outerjoin is (R JOIN S) UNION (T x N), where N is the suitable ``null'' relation with one tuple that has NULL for each attribute of S that is not an attribute of R.Exercise 6.1.5(a)When a relation has no duplicate tuples, DELTA has no effect on it. Thus, DELTA is idempotent.Exercise 6.1.5(b)The result of PI_L is a relation over the list of attributes L. Projecting this relation onto L has no effect, so PI_L is idempotent.Return to TopSolutions for Section 6.3Exercise 6.3.1(a)The iterator for pi_L(R) can be described informally as follows:Open():R.Open()GetNext():Let t = R.GetNext(). If Found = False, return. Else, construct andreturn the tuple consisting of the elements of list L evaluated fortuple t.Close():R.Close()Exercise 6.3.1(b)Here is the iterator for delta(R):Open():First perform R.Open(). Then, initialize a main-memorystructure S that will represent a set of tuples of R seen so far. Forexample, a hash table could be used. Initially, set S is empty. GetNext():Repeat R.GetNext() until either Found = False or a tuple t that is not in set S is returned. In the later case, insert t into S and return that tuple. Close():R.Close()Exercise 6.3.1(d)For the set union R1 union R2 we need both a set S that will store the tuples of R1 and a flag CurRel as in Example 6.13. Here is a summary of the iterator:Open()Perform R1.Open() and initialize to empty the set S.GetNext()If CurRel = R1 then perform t = R1.GetNext(). If Found = True, theninsert t into S and return t. If Found = False, then R1 is exhausted.Perform R1.Close(), R2.Open(), set CurRel = R2, and repeatedlyperform t = R2.GetNext() until either Found = False (in which case,just return), or t is not in S. In the latter case, return t.Close():Perform R2.Close()Exercise 6.3.3A group entry needs a value of starName, since that is the attribute we aregrouping on. It also needs an entry for the sum of lengths, since that sum is part of the result of the query of Exercise 6.1.6(d). Finally, the group entry needs a count of the number of tuples in the group, since this count isneeded to accept or reject groups according to the HAVING clause.Exercise 6.3.5(a)Read R into main memory. Then, for each tuple t of S, see if t joins with any of the tuples of R that are in memory. Output any of those tuples that do join with t, and delete them from the main-memory set.Exercise 6.3.5(b)Read S into memory. Then, for each tuple t of R, see if t joins with any tuple of S in memory; output t if so.Exercise 6.3.5(e)Read R into main memory. Then, for each tuple t of S, find those tuples in memory with which t joins, and output the joined tuples. Also mark as``used'' all those tuples of R that join with t. After S is exhausted, examine the tuples in main memory, and for each tuple r that is not marked ``used,'' pad r with nulls and output the result.Return to TopSolutions for Section 6.4Exercise 6.4.2The formula in Section 6.4.4 gives 10000 + 10000*10000/999 or 110,101. Return to TopSolutions for Section 6.5Exercise 6.5.2(a)An iterator for delta(R) must do the first sorting pass in its Open() function. Here is a sketch:Open():Perform R.Open() and repeatedly use R.GetNext() to readmemory-sized chunks of R. Sort each into a sorted sublist and writeout the list. Each of these lists may be thought of as having its owniterator. Open each list and initialize a data structure into which the``current'' element of each list may be read into main memory.Use GetNext() for each list to initialize the main-memory structurewith the first element of each list. Finally, execute R.Close(). GetNext():Find the least tuple t in the main-memory structure, and output onecopy of it. Delete all copies of t in main memory, using GetNext() for the appropriate sublist, until all copies of t have disappeared, thenreturn. If there was no such tuple t, because all the sublists wereexhausted, set Found = False and return.Close():Close all the sorted sublists.Exercise 6.5.2(c)For R1 intersect R2 do the following:Open():Open R1 and R2, use their GetNext() functions to read all their tuples in main-memory-sized chunks, and create sorted sublists, which arestored on disk. Initialize a main-memory data structure that will hold the ``current'' tuple of each sorted sublist, and usethe Open() and GetNext() functions of an iterator from each sublist toinitialize the structure to have the first tuple from each sublist. Finally, close R1 and R2.GetNext():Find the least tuple t among all the first elements of the sorted sublists.If t occurs on a list from R1 and a list from R2, then output t, removethe copies of t, use GetNext from the two sublists involved toreplentish the main-memory structure, and return. If t appears on only one of the sublists, do not output t. Ratherm remove it from its list,replentish that list, and repeat these steps with the new least t. Ifno t exists, because all the lists are exhausted, set Found = False andreturn.Close():Close all the sorted sublists.Exercise 6.5.3(b)The formula of Fig. 6.16 gives 5*(10000+10000) = 100,000. Note that the memory available, which is 1000 blocks, is larger than the minimum required, which is sqrt(10000), or 100 blocks. Thus, the method is feasible.Exercise 6.5.5(a)We effectively have to perform two nested-loop joins of 500 and 250 blocks, respectively, using 101 blocks of memory. Such a join takes 250 +500*250/100 = 1500 disk I/O's, so two of them takes 3000. To this number, we must add the cost of sorting the two relations, which takes four disk I/O's per block of the relations, or another 6000. The total disk I/O cost is thus 9000.Exercise 6.5.7(a)The square root of the relation size, or 100 blocks, suffices.Return to TopSolutions for Section 6.6Exercise 6.6.1(a)To compute delta(R) using a ``hybrid hash'' approach, pick a number of buckets small enough that one entire bucket plus one block for each of the other buckets will just fit in memory. The number of buckets would beslightly larger than B(R)/M. On the first pass, keep all the distinct tuples of the first bucket in main memory, and output them the first time they are seen. On the second pass, do a one-pass distinct operation on each of the other buckets.The total number of disk I/O's will be one for M/B(R) of the data and three for the remaining (B(R)-M)/B(R) of the data. Since the datarequires B(R) blocks, the total number of disk I/O's is M + 3(B(R) - M) =3B(R) - 2M, compared with 3B(R) for the standard approach.Exercise 6.6.4This is a trick question. Each group, no matter how many members, requires only one tuple in main memory. Thus, no modifications are needed, and in fact, memory use will be pleasantly small.Return to TopSolutions for Section 6.7Exercise 6.7.1(a)Our option is to first copy all the tuples of R to the output. Then, for each tuple t of S, retrieve the tuples of R for which R.a matches the a-value of t. Check whether t appears among them, and output t if not.This method can be efficient if S is small and V(R,a) is large.Exercise 6.7.2(a)The values retrieved will fit on about 10000/k blocks, so that is the approximate cost of the selection.Exercise 6.7.5There is an error (see The Errata Sheet in that the relation Movie shouldbe StarsIn. However, it doesn't affect the answer to the question, as long as you believe the query can be answered at all.The point is that with the index, we have only to retrieve the blocks containing MovieStar records for the stars of ``King Kong.'' We don't know how many stars there are, but it is safe to assume that their records willoccupy many more blocks than there are stars in the two ``King Kong'' movies. Thus, using the index allows us to take the join while accessing only a small part of the MovieStar relation and is therefore to be preferred toa sort- or hash-join, each of which will access the entire MovieStar relation at least once.Return to TopSolutions for Section 6.8Exercise 6.8.1(a)One of the relations must fit in memory, which means thatmin(B(R),B(S)) >= M/2.Exercise 6.8.1(b)We can only assume that there will be M/2 blocks available during the first pass, so we cannot create more than M/2-1 buckets. Each pair of matching buckets must be joinable in a one-pass join, which means one of each pair of corresponding buckets must be no larger than M/2, as we saw in part (a). Since the average bucket size will be 1/(M/2 - 1) of the size of its relation, we require min(B(R),B(S))/(M/2 - 1) >= M/2, or approximatelymin(B(R),B(S)) >= M^2/4. This figure should be no surprise; it simply says we must make the most conservative assumption at all times about the size of memory.Return to TopSolutions for Section 6.9Exercise 6.9.1(a)The way we have defined the recursive algorithm, it always divides relations into M-1 pieces (100 pieces in this exercise) if it has to divide at all. In practice, we may have options to use fewer pieces at one or more levels or the recursion, and in this exercise there are many such options. However, we'll describe only the one that matches the policy given in the text. In what follows, all sorting and merging is based on the values of tuples in the join attributes only, since we are describing a join operation.Level 1: R and S are divided into 50 sublists each. The sizes of the lists are 400 and 1000 blocks, for R and S, respectively. Note that no disk I/O's are performed yet; the partition is conceptual.Level 2: Each of the sublists from Level 1 are divided into 100 subsublists; the sizes of these lists are 4 blocks for R, and 10 blocks for S. Again, no disk I/O's are performed for this conceptual partition.Level 3: We sort each of the subsublists from Level 2. Each block is read once from disk, and an equal number of blocks are written to disk as the sorted subsublists.Return to Level 2: We merge each of the 100 subsublists that comprise one sublist, using the standard multiway merging algorithm. Every block is read and written once during this process.Return to Level 1: We merge each of the 50 sorted sublists from R and the 50 sorted sublists from S, thus joining R and S. Each block is read once during this part.Return to TopSolutions for Section 6.10Exercise 6.10.1(a)If the division of tuples from R is as even as possible, some processors will have to perform 13 disk I/O's, but none will have to perform more. The 13 disk I/O's take 1.3 seconds, so the speedup is 10/1.3 or about 7.7.Return to Top。