操作系统实验报告_实验四
操作系统实验04 Linux 多进程编程
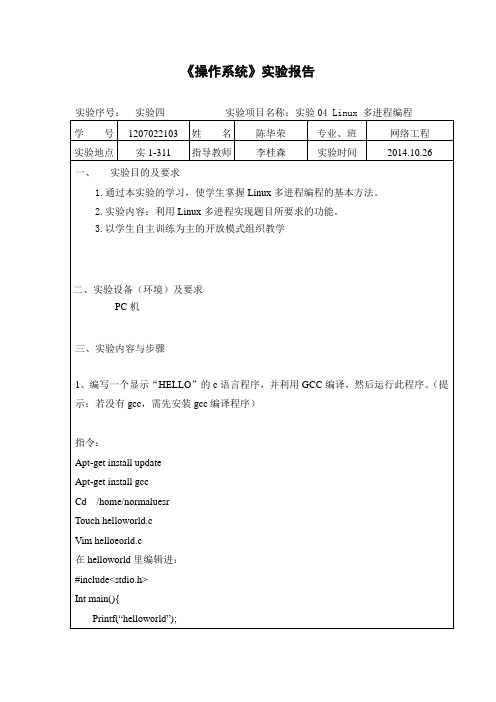
《操作系统》实验报告实验序号:实验四实验项目名称:实验04 Linux 多进程编程学号1207022103 姓名陈华荣专业、班网络工程实验地点实1-311 指导教师李桂森实验时间2014.10.26一、实验目的及要求1.通过本实验的学习,使学生掌握Linux多进程编程的基本方法。
2.实验内容:利用Linux多进程实现题目所要求的功能。
3.以学生自主训练为主的开放模式组织教学二、实验设备(环境)及要求PC机三、实验内容与步骤1、编写一个显示“HELLO”的c语言程序,并利用GCC编译,然后运行此程序。
(提示:若没有gcc,需先安装gcc编译程序)指令:Apt-get install updateApt-get install gccCd /home/normaluesrTouch helloworld.cVim helloeorld.c在helloworld里编辑进:#include<stdio.h>Int main(){Printf(“helloworld”);Return 0;}然后用gcc进行编译运行:或者直接2、进程的创建:编制一程序,利用系统调用fork()创建两个子进程。
程序运行时,系统中有一个父进程和两个子进程活动,分别让他们显示“A”、“B”和“C”,分析程序运行结果。
3、用ctrl+alt+F2切换到第二个终端(tty2)并使用另外一个用户登录(可利用第二个实验创建的用户登录),然后使用who命令查看用户登录情况。
用ctrl+alt+F1切换到第二个终端(tty1),修改第二步的程序,在每个进程退出前都加上一个sleep(20)的函数来延缓进程的退出,然后运行此程序,立即切换到tty2,使用ps -a命令查看系统运行的进程,观察程序创建的进程都有哪些?pid是多少?4、进程的管道通信:编制一程序,使用系统调用pipe()建立一管道,两个子进程P1和P2分别向管道各写一句话,父进程则从管道中读取出来并显示在屏幕。
操作系统实验实验报告

操作系统实验实验报告一、实验目的操作系统是计算机系统中最为关键的核心软件,它管理着计算机的硬件资源和软件资源,为用户提供了一个方便、高效、稳定的工作环境。
本次操作系统实验的目的在于通过实际操作和实践,深入理解操作系统的基本原理和核心概念,掌握操作系统的基本功能和操作方法,提高对操作系统的认识和应用能力。
二、实验环境本次实验使用的操作系统为 Windows 10 专业版,开发工具为Visual Studio 2019,编程语言为 C 和 C++。
实验硬件环境为一台配备Intel Core i7 处理器、16GB 内存、512GB SSD 硬盘的个人计算机。
三、实验内容(一)进程管理实验1、进程创建与终止通过编程实现创建新的进程,并在完成任务后终止进程。
在实验中,我们使用了 Windows API 函数 CreateProcess 和 TerminateProcess 来完成进程的创建和终止操作。
通过观察进程的创建和终止过程,深入理解了进程的生命周期和状态转换。
2、进程同步与互斥为了实现进程之间的同步与互斥,我们使用了信号量、互斥量等同步对象。
通过编写多线程程序,模拟了多个进程对共享资源的访问,实现了对共享资源的互斥访问和同步操作。
在实验中,我们深刻体会到了进程同步与互斥的重要性,以及不正确的同步操作可能导致的死锁等问题。
(二)内存管理实验1、内存分配与释放使用 Windows API 函数 VirtualAlloc 和 VirtualFree 进行内存的分配和释放操作。
通过实验,了解了内存分配的不同方式(如堆分配、栈分配等)以及内存释放的时机和方法,掌握了内存管理的基本原理和操作技巧。
2、内存分页与分段通过编程模拟内存的分页和分段管理机制,了解了内存分页和分段的基本原理和实现方法。
在实验中,我们实现了简单的内存分页和分段算法,对内存的地址转换和页面置换等过程有了更深入的理解。
(三)文件系统实验1、文件操作使用 Windows API 函数 CreateFile、ReadFile、WriteFile 等进行文件的创建、读取和写入操作。
《操作系统》课内实验报告

《操作系统》课内实验报告一、实验目的本次《操作系统》课内实验的主要目的是通过实际操作和观察,深入理解操作系统的基本原理和功能,掌握常见操作系统命令的使用,提高对操作系统的实际应用能力和问题解决能力。
二、实验环境本次实验在计算机实验室进行,使用的操作系统为 Windows 10 和Linux(Ubuntu 发行版)。
实验所使用的计算机配置为:Intel Core i5 处理器,8GB 内存,500GB 硬盘。
三、实验内容1、进程管理在 Windows 系统中,通过任务管理器观察进程的状态、优先级、CPU 使用率等信息,并进行进程的结束和优先级调整操作。
在 Linux 系统中,使用命令行工具(如 ps、kill 等)实现相同的功能。
2、内存管理使用 Windows 系统的性能监视器和资源监视器,查看内存的使用情况,包括物理内存、虚拟内存的占用和分配情况。
在 Linux 系统中,通过命令(如 free、vmstat 等)获取类似的内存信息,并分析内存的使用效率。
3、文件系统管理在 Windows 系统中,对文件和文件夹进行创建、复制、移动、删除等操作,了解文件的属性设置和权限管理。
在 Linux 系统中,使用命令(如 mkdir、cp、mv、rm 等)完成相同的任务,并熟悉文件的所有者、所属组和权限设置。
4、设备管理在 Windows 系统中,查看设备管理器中的硬件设备信息,安装和卸载设备驱动程序。
在 Linux 系统中,使用命令(如 lspci、lsusb 等)查看硬件设备,并通过安装内核模块来支持特定设备。
四、实验步骤1、进程管理实验(1)打开 Windows 系统的任务管理器,切换到“进程”选项卡,可以看到当前系统中正在运行的进程列表。
(2)选择一个进程,右键点击可以查看其属性,包括进程 ID、CPU 使用率、内存使用情况等。
(3)通过“结束任务”按钮可以结束指定的进程,但要注意不要随意结束系统关键进程,以免导致系统不稳定。
实验四 操作系统存储管理实验报告

实验四操作系统存储管理实验报告一、实验目的本次操作系统存储管理实验的主要目的是深入理解操作系统中存储管理的基本原理和方法,通过实际操作和观察,掌握内存分配、回收、地址转换等关键技术,提高对操作系统存储管理机制的认识和应用能力。
二、实验环境操作系统:Windows 10开发工具:Visual Studio 2019三、实验原理1、内存分配方式连续分配:分为单一连续分配和分区式分配(固定分区和动态分区)。
离散分配:分页存储管理、分段存储管理、段页式存储管理。
2、内存回收算法首次适应算法:从内存低地址开始查找,找到第一个满足要求的空闲分区进行分配。
最佳适应算法:选择大小最接近作业需求的空闲分区进行分配。
最坏适应算法:选择最大的空闲分区进行分配。
3、地址转换逻辑地址到物理地址的转换:在分页存储管理中,通过页表实现;在分段存储管理中,通过段表实现。
四、实验内容及步骤1、连续内存分配实验设计一个简单的内存分配程序,模拟固定分区和动态分区两种分配方式。
输入作业的大小和请求分配的分区类型,程序输出分配的结果(成功或失败)以及分配后的内存状态。
2、内存回收实验在上述连续内存分配实验的基础上,添加内存回收功能。
输入要回收的作业号,程序执行回收操作,并输出回收后的内存状态。
3、离散内存分配实验实现分页存储管理的地址转换功能。
输入逻辑地址,程序计算并输出对应的物理地址。
4、存储管理算法比较实验分别使用首次适应算法、最佳适应算法和最坏适应算法进行内存分配和回收操作。
记录不同算法在不同作业序列下的内存利用率和分配时间,比较它们的性能。
五、实验结果与分析1、连续内存分配实验结果固定分区分配方式:在固定分区大小的情况下,对于作业大小小于或等于分区大小的请求能够成功分配,否则分配失败。
内存状态显示清晰,分区的使用和空闲情况一目了然。
动态分区分配方式:能够根据作业的大小动态地分配内存,但容易产生内存碎片。
2、内存回收实验结果成功回收指定作业占用的内存空间,内存状态得到及时更新,空闲分区得到合并,提高了内存的利用率。
安装操作系统的实验报告

一、实验目的1. 掌握操作系统安装的基本方法。
2. 熟悉操作系统安装过程中的注意事项。
3. 提高动手操作能力,为以后使用操作系统打下基础。
二、实验环境1. 硬件环境:- CPU:Intel Core i5- 内存:8GB- 硬盘:500GB- 显卡:NVIDIA GeForce GTX 1050- 主板:华硕PRIME H310M-E2. 软件环境:- 操作系统:Windows 10- 安装工具:Windows 10安装镜像三、实验步骤1. 准备安装镜像- 将Windows 10安装镜像烧录到U盘或光盘上。
2. 设置BIOS启动顺序- 进入主板BIOS设置界面,将U盘或光盘设置为第一启动设备。
3. 启动计算机- 重启计算机,从U盘或光盘启动。
4. 开始安装操作系统- 进入Windows 10安装界面,点击“现在安装”按钮。
5. 选择安装类型- 选择“自定义:仅安装Windows(高级)”选项。
6. 选择安装磁盘- 在“驱动器选项”下,选择要安装Windows的磁盘分区,点击“新建”按钮创建新的分区,然后将所有磁盘空间分配给新分区。
7. 格式化磁盘- 在弹出的窗口中,选择“将磁盘格式化为NTFS文件系统”,点击“下一步”按钮。
8. 安装操作系统- 等待操作系统安装完成,期间会自动重启计算机。
9. 设置账户信息- 在安装完成后,根据提示设置用户名、密码等信息。
10. 安装驱动程序- 根据需要安装显卡、网卡等驱动程序。
11. 安装常用软件- 安装Office、QQ、浏览器等常用软件。
四、实验结果与分析1. 实验结果- 成功安装Windows 10操作系统,并完成了基本配置。
2. 实验分析- 本次实验中,按照步骤顺利完成操作系统安装,但在安装过程中遇到了以下问题:(1)在设置BIOS启动顺序时,需要根据主板型号进行设置,否则无法从U 盘或光盘启动。
(2)在格式化磁盘时,需要注意选择合适的文件系统,以免影响系统性能。
实验四操作系统存储管理实验报告

实验四操作系统存储管理实验报告一、实验目的本次实验的主要目的是深入理解操作系统中存储管理的基本原理和方法,通过实际操作和观察,掌握内存分配与回收、页面置换算法等关键概念,并能够分析和解决存储管理中可能出现的问题。
二、实验环境本次实验在装有 Windows 操作系统的计算机上进行,使用了 Visual Studio 等编程工具和相关的调试环境。
三、实验内容(一)内存分配与回收算法实现1、首次适应算法首次适应算法从内存的起始位置开始查找,找到第一个能够满足需求的空闲分区进行分配。
在实现过程中,我们通过建立一个空闲分区链表来管理内存空间,每次分配时从表头开始查找。
2、最佳适应算法最佳适应算法会选择能够满足需求且大小最小的空闲分区进行分配。
为了实现该算法,在空闲分区链表中,分区按照大小从小到大的顺序排列,这样在查找时能够快速找到最合适的分区。
3、最坏适应算法最坏适应算法则选择最大的空闲分区进行分配。
同样通过对空闲分区链表的排序和查找来实现。
(二)页面置换算法模拟1、先进先出(FIFO)页面置换算法FIFO 算法按照页面进入内存的先后顺序进行置换,即先进入内存的页面先被置换出去。
在模拟过程中,使用一个队列来记录页面的进入顺序。
2、最近最久未使用(LRU)页面置换算法LRU 算法根据页面最近被使用的时间来决定置换顺序,最近最久未使用的页面将被置换。
通过为每个页面设置一个时间戳来记录其最近使用的时间,从而实现置换策略。
3、时钟(Clock)页面置换算法Clock 算法使用一个环形链表来模拟内存中的页面,通过指针的移动和页面的访问标志来决定置换页面。
四、实验步骤(一)内存分配与回收算法的实现步骤1、初始化内存空间,创建空闲分区链表,并为每个分区设置起始地址、大小和状态等信息。
2、对于首次适应算法,从链表表头开始遍历,找到第一个大小满足需求的空闲分区,进行分配,并修改分区的状态和大小。
3、对于最佳适应算法,在遍历链表时,选择大小最接近需求的空闲分区进行分配,并对链表进行相应的调整。
操作系统实验四
一、实验名称实验四设备管理二、实验目的本实验着重于了解磁盘的物理组织,以及如何通过用户态的程序直接调用磁盘I/O API 函数(DeviceIoControl)根据输入的驱动器号读取驱动器中磁盘的基本信息,在Windows Server 2003环境进行。
三、实验内容(一)实验需求:(1)Windows Server 2003(2)Microsoft V isual Studio 2008(二)实验的内容:[1] 磁盘I/O API函数应用相关的API 介绍1.获取磁盘的基本信息的磁盘I/O API函数DeviceIoControl格式如下:BOOL DeviceIoControl( HANDLE hDevice, DWORD dwioControlCode,LPVOID lplnBuffer, DWORD nlnBufferSize,LPVOID lpOutBuffer, DWORD nOutBufferSize,LPDWORD lpBytesReturned,LPOVERLAPPED lpOverlapped );.hDevice:所要进行操作的设备的句柄,它通过调用CreateFile函数来获得。
.dwIoControlCode:指定操作的控制代码。
这个值用来辨别将要执行的指定的操作,以及对哪一种设备进行操作。
对磁盘应设置为IOCTL_DISK_GET_DRIVE_GEOMETRY。
.lpInBuffer:操作所要的输入数据缓冲区指针,NULL表示不需要输入数据。
.nInBufferSize:指定lpInBuffer所指向的缓冲区的大小(以字节为单位)。
.lpOutBuffer:接收操作输出的数据缓冲区指针,NULL表示操作没有产生输出数据。
输出数据的缓冲区要足够大,对磁盘它采用固定的数据结构DISK_GEOMETRY,格式如下:structDISK_GEOMETRY {unsigned bytesPerSector; unsigned sectorsPerTrack;unsigned heads; unsigned cylinders; }.nOutBufferSize:指定lpOutBuffer所指向的缓冲区的大小(以字节为单位)。
《操作系统》课程实验报告
《操作系统》课程实验报告一、实验目的本次《操作系统》课程实验的主要目的是通过实际操作和观察,深入理解操作系统的工作原理、进程管理、内存管理、文件系统等核心概念,并掌握相关的操作技能和分析方法。
二、实验环境1、操作系统:Windows 10 专业版2、开发工具:Visual Studio Code3、编程语言:C/C++三、实验内容(一)进程管理实验1、进程创建与终止通过编程实现创建新进程,并观察进程的创建过程和资源分配情况。
同时,实现进程的正常终止和异常终止,并分析其对系统的影响。
2、进程同步与互斥使用信号量、互斥锁等机制实现进程之间的同步与互斥。
通过模拟多个进程对共享资源的访问,观察并解决可能出现的竞争条件和死锁问题。
(二)内存管理实验1、内存分配与回收实现不同的内存分配算法,如首次适应算法、最佳适应算法和最坏适应算法。
观察在不同的内存请求序列下,内存的分配和回收情况,并分析算法的性能和优缺点。
2、虚拟内存管理研究虚拟内存的工作原理,通过设置页面大小、页表结构等参数,观察页面的换入换出过程,以及对系统性能的影响。
(三)文件系统实验1、文件操作实现文件的创建、打开、读取、写入、关闭等基本操作。
观察文件在磁盘上的存储方式和文件系统的目录结构。
2、文件系统性能优化研究文件系统的缓存机制、磁盘调度算法等,通过对大量文件的读写操作,评估不同优化策略对文件系统性能的提升效果。
四、实验步骤(一)进程管理实验步骤1、进程创建与终止(1)使用 C/C++语言编写程序,调用系统函数创建新进程。
(2)在子进程中执行特定的任务,父进程等待子进程结束,并获取子进程的返回值。
(3)通过设置异常情况,模拟子进程的异常终止,观察父进程的处理方式。
2、进程同步与互斥(1)定义共享资源和相关的信号量或互斥锁。
(2)创建多个进程,模拟对共享资源的并发访问。
(3)在访问共享资源的关键代码段使用同步机制,确保进程之间的正确协作。
(4)观察并分析在不同的并发情况下,系统的运行结果和资源竞争情况。
Windows操作系统实验四实验报告
Windows操作系统C/C++ 程序实验姓名:___________________学号:___________________班级:___________________院系:_________________________________年_____月_____日实验四Windows 2000/xp线程间通信一、背景知识二、实验目的三、工具/准备工作四、实验内容1. 文件对象步骤1:登录进入Windows 2000/xp Professional。
步骤2:在“开始”菜单中单击“程序”-“Microsoft Visual Studio 6.0”–“Microsoft Visual C++ 6.0”命令,进入Visual C++窗口。
步骤3:在工具栏单击“打开”按钮,在“打开”对话框中找到并打开实验源程序4-1.cpp。
步骤4:单击“Build”菜单中的“Compile 4-1.cpp”命令,并单击“是”按钮确认。
系统对4-1.cpp进行编译。
步骤5:编译完成后,单击“Build”菜单中的“Build 4-1.exe”命令,建立4-1.exe可执行文件。
操作能否正常进行?如果不行,则可能的原因是什么?____________________________________________________________________ ________________________________________________________________________步骤6:在工具栏单击“Execute Program”按钮,执行4-1.exe程序。
运行结果(如果运行不成功,则可能的原因是什么?) :____________________________________________________________________ ________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________阅读和分析程序4-1,请回答问题:1) 清单4-1中启动了多少个单独的读写线程?____________________________________________________________________2) 使用了哪个系统API函数来创建线程例程?____________________________________________________________________3) 文件的读和写操作分别使用了哪个API函数?____________________________________________________________________ ________________________________________________________________________每次运行进程时,都可看到清单4-3中的每个线程从前面的线程中读取数据并将数据增加,文件中的数值连续增加。
操作系统原理_实验报告
一、实验目的1. 理解操作系统基本原理,包括进程管理、内存管理、文件系统等。
2. 掌握操作系统的基本命令和操作方法。
3. 通过实验加深对操作系统原理的理解和掌握。
二、实验环境1. 操作系统:Linux2. 编程语言:C语言3. 开发工具:Eclipse三、实验内容本次实验主要分为以下几个部分:1. 进程管理实验2. 内存管理实验3. 文件系统实验四、实验步骤及结果1. 进程管理实验实验步骤:- 使用C语言编写一个简单的进程管理程序,实现进程的创建、调度、同步和通信等功能。
- 编写代码实现进程的创建,通过调用系统调用创建新的进程。
- 实现进程的调度,采用轮转法进行进程调度。
- 实现进程同步,使用信号量实现进程的互斥和同步。
- 实现进程通信,使用管道实现进程间的通信。
实验结果:- 成功创建多个进程,并实现了进程的调度。
- 实现了进程的互斥和同步,保证了进程的正确执行。
- 实现了进程间的通信,提高了进程的效率。
2. 内存管理实验实验步骤:- 使用C语言编写一个简单的内存管理程序,实现内存的分配、释放和回收等功能。
- 实现内存的分配,采用分页存储管理方式。
- 实现内存的释放,通过调用系统调用释放已分配的内存。
- 实现内存的回收,回收未被使用的内存。
实验结果:- 成功实现了内存的分配、释放和回收。
- 内存分配效率较高,回收内存时能保证内存的连续性。
3. 文件系统实验实验步骤:- 使用C语言编写一个简单的文件系统程序,实现文件的创建、删除、读写等功能。
- 实现文件的创建,通过调用系统调用创建新的文件。
- 实现文件的删除,通过调用系统调用删除文件。
- 实现文件的读写,通过调用系统调用读取和写入文件。
实验结果:- 成功实现了文件的创建、删除、读写等功能。
- 文件读写效率较高,保证了数据的正确性。
五、实验总结通过本次实验,我对操作系统原理有了更深入的理解和掌握。
以下是我对实验的几点总结:1. 操作系统是计算机系统的核心,负责管理和控制计算机资源,提高计算机系统的效率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验四:进程管理(二)实验内容:1.编写一个程序,打印进程的如下信息:进程标识符,父进程标识符,真实用户ID,有效用户ID,真实用户组ID,有效用户组ID。
并分析真实用户ID和有效用户ID的区别。
源代码及结果:真实用户ID和有效用户ID的区别:真实用户ID:这个ID就是我们登陆unix系统时的身份ID。
有效用户ID:定义了操作者的权限。
有效用户ID是进程的属性,决定了该进程对文件的访问权限。
2.阅读如下程序,编译并运行,分析进程执行过程的时间消耗(总共消耗的时间和CPU 消耗的时间),并解释执行结果。
再编写一个计算密集型的程序替代grep,比较两次时间的花销。
注释程序主要语句。
/*process using time */#include<stdio.h>#include<stdlib.h>#include<sys/times.h>#include<time.h>#include<unistd.h>void time_print(char *,clock_t);int main(void){//取得进程运行相关的时间clock_t start,end;struct tms t_start,t_end;start = times(&t_start);system(“grep the /usr/doc/*/* > /dev/null 2> /dev/null”);/*command >/dev/null的作用是将是command命令的标准输出丢弃,而标准错误输出还是在屏幕上。
一般来讲标准输出和标准错误输出都是屏幕,因此错误信息还是会在屏幕上输出。
>/dev/null 2> /dev/null 标准输出与标准错误输出都会被丢弃*/ // 0 1 2 标准输入标准输出错误输出// > 将信息放到该文件null中end=times(&t_end);time_print(“elapsed”,end-start);puts(“parent times”);time_print(“\tuser CPU”,t_end.tms_utime);time_print(“\tsys CPU”,t_end.tms_stime);puts(“child times”);time_print(“\tuser CPU”,t_end.tms_cutime);time_print(“\tsys CPU”,t_end.tms_cstime);exit(EXIT_SUCCESS);}void time_print(char *str, clock_t time){long tps = sysconf(_SC_CLK_TCK);/*函数sysconf()的作用为将时钟滴答数转化为秒数,_SC_CLK_TCK 为定义每秒钟有多少个滴答的宏*/printf(“%s: %6.2f secs\n”,str,(float)time/tps);}程序运行结果:因为该程序计算量很小,故消耗的时间比较少,CPU消耗时间均为0.00secs不足为奇。
而进程的执行时间等于用户CPU时间和系统CPU时间加从硬盘读取数据时间之和。
密集型的程序替代grep:更改为计算密集型的之后就较容易观察出消耗时间的差异。
3.阅读下列程序,编译并多次运行,观察执行输出次序,说明次序相同(或不同)的原因;观察进程ID,分析进程ID的分配规律。
总结fork()的使用方法。
注释程序主要语句。
/* fork usage */#include<unistd.h>#include<stdio.h>#include<stdlib.h>int main(void){pid_t child;if((child=fork())==-1){perror(“fork”);exit(EXIT_FAILURE);}else if(child==0){puts(“in child”);printf(“\tchild pid = %d\n”,getpid());printf(“\tchild ppid = %d\n”,getppid());exit(EXIT_SUCCESS);}else{puts(“in parent”);printf(“\tparent pid = %d\n”,getpid());printf(“\tparent ppid = %d\n”,getppid());}exit(EXIT_SUCCESS);}程序运行结果:(?)创建进程ID开始时一般随机分配,但若多次运行,或创建子进程时,会顺序分配内存。
此外,当父进程结束时,子进程尚未结束,则子进程的父进程ID变为1。
fork()函数的实质是一个系统调用(和write函数类似),其作用是创建一个新的进程,当一个进程调用它,完成后就出现两个几乎一模一样的进程,其中由fork()创建的新进程被称为子进程,而原来的进程称为父进程。
子进程是父进程的一个拷贝,即子进程从父进程得到了数据段和堆栈的拷贝,这些需要分配新的内存;而对于只读的代码段,通常使用共享内存方式进行访问。
4.阅读下列程序,编译并运行,等待或者按^C,分别观察执行结果并分析,注释程序主要语句。
flag有什么作用?通过实验说明。
/* usage of kill,signal,wait */#include<unistd.h>#include<stdio.h>#include<sys/types.h>#include<signal.h>int flag;void stop(); //自定义函数,使flag=0,供signal调用int main(void){int pid1,pid2;signal(3,stop); // signal()依参数3指定的信号编号来设置该信号的处理函数while((pid1=fork()) ==-1); //程序等待成功创建子进程事件的发生if(pid1>0){//当前进程为父进程while((pid2=fork()) ==-1);if(pid2>0){//当前进程为父进程,父进程发出两个中断信号Kill子进程flag=1;sleep(5);kill(pid1,16); //将16指定的信号传给进程ID为pid1 的进程kill(pid2,17); //将17指定的信号传给进程ID为pid2 的进程wait(0); //暂时停止目前进程的执行,直到有信号来到或子进程结束wait(0);printf(“\n parent is killed\n”);exit(EXIT_SUCCESS);}else{//当前进程为子进程,则发送子进程kill信号,杀死该子进程2 flag=1;signal(17,stop);printf(“\n child2 is killed by parent\n”);exit(EXIT_SUCCESS);}}else{//当前进程为子进程,则发送子进程kill信号,杀死该子进程1 flag=1;signal(16,stop);printf(“\n child1 is killed by parent\n”);exit(EXIT_SUCCESS);}}void stop(){flag = 0;}程序运行结果:每个进程(父进程,子进程)都有一个flag,起状态标志作用,flag=1时,表示进程在运行,flag=0,表示进程结束。
5.编写程序,要求父进程创建一个子进程,使父进程和个子进程各自在屏幕上输出一些信息,但父进程的信息总在子进程的信息之后出现。
程序源代码:程序运行结果:6.编写程序,要求父进程创建一个子进程,子进程执行shell命令find / -name hda* 的功能,子进程结束时由父进程打印子进程结束的信息。
执行中父进程改变子进程的优先级。
程序源代码:程序运行结果:7./**编写程序,要求父进程创建一个子进程,子进程对一个50*50的字符数组赋值,由父进程改变子进程的优先级,观察不同优先级进程使用CPU的时间。
*/8.查阅Linux系统中struct task_struct 的定义,说明每项成员的作用。
注:search in /usr/src/linux-2.6/include/linux/sched.h广义上,所有的进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。
每个进程在内核中都有一个进程控制块(PCB)来维护进程相关的信息,Linux内核的进程控制块是task_struct结构体。
task_struct是Linux内核的一种数据结构,它会被装载到RAM里并且包含着进程的信息。
每个进程都把它的信息放在task_struct 这个数据结构里,task_struct 包含了这些内容:(1)标示符:描述本进程的唯一标示符,用来区别其他进程。
(2)状态:任务状态,退出代码,退出信号等。
(3)优先级:相对于其他进程的优先级。
(4)程序计数器:程序中即将被执行的下一条指令的地址。
(5)内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
(6)上下文数据:进程执行时处理器的寄存器中的数据。
(7)I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
(8)记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号。
……保存进程信息的数据结构叫做task_struct,并且可以在include/linux/sched.h 里找到它。
所有运行在系统里的进程都以task_struct 链表的形式存在内核里。
进程的信息可以通过/proc 系统文件夹查看。
task_struct一些字段的介绍:1.调度数据成员(1) volatile long states;表示进程的当前状态(2) unsigned long flags;进程标志(3) long priority;进程优先级。
优先级可通过系统调用sys_setpriorty改变。
(4) unsigned long rt_priority;rt_priority给出实时进程的优先级,rt_priority+1000给出进程每次获取CPU后可使用的时间(同样按jiffies计)。
实时进程的优先级可通过系统调用sys_sched_setscheduler()改变(见kernel/sched.c)。
(5) long counter;在轮转法调度时表示进程当前还可运行多久。