数据挖掘作业
上海交大网络教育数据挖掘第一次作业

数据挖掘
题目1
标记题目
选择一项:
A.
分类
B.
聚类
C. 自然语言处理
D. 关联规则发现
反馈
你的回答正确
正确答案是:关联规则发现题目2
标记题目
b.
聚类
c. 分类
d. 隐马尔可夫链
反馈
你的回答正确
正确答案是:
聚类
题目3
标记题目
什么是KDD?
选择一项:
A.
数据挖掘与知识发现
B. 动态知识发现
C.
领域知识发现
D.
文档知识发现
反馈
你的回答正确
正确答案是:
数据挖掘与知识发现
题目4
标记题目
使用交互式的和可视化的技术,对数据进行探索属于数据挖掘的哪一类任务
选择一项:
A. 探索性数据分析
B.
建模描述
C. 寻找模式和规则
D.
预测建模
反馈
你的回答正确
正确答案是:探索性数据分析
题目5
标记题目
建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?
选择一项:
A. 探索性数据分析
B. 寻找模式和规则
C.
预测建模
D.
建模描述
反馈
你的回答正确
正确答案是:
预测建模
结束回顾。
数据挖掘作业讲解

《数据挖掘》作业第一章引言一、填空题(1)数据库中的知识挖掘(KDD)包括以下七个步骤:数据清理、数据集成、数据选择、数据变换、数据挖掘、模式评估和知识表示(2)数据挖掘的性能问题主要包括:算法的效率、可扩展性和并行处理(3)当前的数据挖掘研究中,最主要的三个研究方向是:统计学、数据库技术和机器学习(4)在万维网(WWW)上应用的数据挖掘技术常被称为:WEB挖掘(5)孤立点是指:一些与数据的一般行为或模型不一致的孤立数据二、单选题(1)数据挖掘应用和一些常见的数据统计分析系统的最主要区别在于:(B )A、所涉及的算法的复杂性;B、所涉及的数据量;C、计算结果的表现形式;D、是否使用了人工智能技术(2)孤立点挖掘适用于下列哪种场合?(D )A、目标市场分析B、购物篮分析C、模式识别D、信用卡欺诈检测(3)下列几种数据挖掘功能中,( D )被广泛的应用于股票价格走势分析A. 关联分析B.分类和预测C.聚类分析D. 演变分析(4)下面的数据挖掘的任务中,( B )将决定所使用的数据挖掘功能A、选择任务相关的数据B、选择要挖掘的知识类型C、模式的兴趣度度量D、模式的可视化表示(5)下列几种数据挖掘功能中,(A )被广泛的用于购物篮分析A、关联分析B、分类和预测C、聚类分析D、演变分析(6)根据顾客的收入和职业情况,预测他们在计算机设备上的花费,所使用的相应数据挖掘功能是( B )A.关联分析B.分类和预测C. 演变分析D. 概念描述(7)帮助市场分析人员从客户的基本信息库中发现不同的客户群,通常所使用的数据挖掘功能是( C )A.关联分析B.分类和预测C.聚类分析D. 孤立点分析E. 演变分析(8)假设现在的数据挖掘任务是解析数据库中关于客户的一般特征的描述,通常所使用的数据挖掘功能是( E )A.关联分析B.分类和预测C. 孤立点分析D. 演变分析E. 概念描述三、简答题(1)什么是数据挖掘?答:数据挖掘是指从大量数据中提取或“挖掘”知识。
数据挖掘的功能及应用作业

数据挖掘的其他基本功能介绍一、关联规则挖掘关联规则挖掘是挖掘数据库中和指标(项)之间有趣的关联规则或相关关系。
关联规则挖掘具有很多应用领域,如一些研究者发现,超市交易记录中的关联规则挖掘对超市的经营决策是十分重要的。
1、 基本概念设},,,{21m i i i I =是项组合的记录,D 为项组合的一个集合。
如超市的每一张购物小票为一个项的组合(一个维数很大的记录),而超市一段时间内的购物记录就形成集合D 。
我们现在关心这样一个问题,组合中项的出现之间是否存在一定的规则,如A 游泳衣,B 太阳镜,B A ⇒,但是A B ⇒得不到足够支持。
在规则挖掘中涉及到两个重要的指标:① 支持度 支持度n B A n B A )()(⇒=⇒,显然,只有支持度较大的规则才是较有价值的规则。
② 置信度 置信度)()()(A n B A n B A ⇒=⇒,显然只有置信度比较高的规则才是比较可靠的规则。
因此,只有支持度与置信度均较大的规则才是比较有价值的规则。
③ 一般地,关联规则可以提供给我们许多有价值的信息,在关联规则挖掘时,往往需要事先指定最小支持度与最小置信度。
关联规则挖掘实际上真正体现了数据中的知识发现。
如果一个规则满足最小支持度,则称这个规则是一个频繁规则;如果一个规则同时满足最小支持度与最小置信度,则通常称这个规则是一个强规则。
关联规则挖掘的通常方法是:首先挖掘出所有的频繁规则,再从得到的频繁规则中挖掘强规则。
在少量数据中进行规则挖掘我们可以采用采用简单的编程方法,而在大量数据中挖掘关联规则需要使用专门的数据挖掘软件。
关联规则挖掘可以使我们得到一些原来我们所不知道的知识。
应用的例子:* 日本超市对交易数据库进行关联规则挖掘,发现规则:尿片→啤酒,重新安排啤酒柜台位置,销量上升75%。
* 英国超市的例子:大额消费者与某种乳酪。
那么,证券市场上、期货市场上、或者上市公司中存在存在哪些关联规则,这些关联规则究竟说明了什么?关联规则挖掘通常比较适用与记录中的指标取离散值的情况,如果原始数据库中的指标值是取连续的数据,则在关联规则挖掘之前应该进行适当的数据离散化(实际上就是将某个区间的值对应于某个值),数据的离散化是数据挖掘前的重要环节,离散化的过程是否合理将直接影响关联规则的挖掘结果。
数据挖掘作业——林雪燕——2012E8018661082

数据挖掘Part I:手写作业:Part II: 上机作业:Recommendation Systems Hand-in: The list of association rules generated by the model.设置min-support=5%,min-confidence=50%,如图所示:结果如下图所示:关联规则如下:⇒biscuits m ilk yoghurt milk⇒⇒tom ato souse pastatomato souse milk⇒∧⇒pasta water milk⇒juices milk∧⇒biscuits pasta milk⇒rice pasta∧⇒tomato souse pasta milk∧⇒coffee pasta milk∧⇒tomato souse milk pasta∧⇒biscuits w ater m ilkbrioches pasta milk∧⇒∧⇒yoghurt pasta milkSort the rules by lift, support, and confidence, respectively to see the rules identified. Hand-in: For each case, choose top 5 rules (note: make sure no redundant rules in the 5 rules) and give 2-3 lines comments. Many of the rules will be logically redundant and therefore will have to be eliminated after you think carefully about them.按support排序:support最高的5个规则是:1.biscuits m ilk⇒2.yoghurt milk⇒3.tom ato souse pasta⇒4.tomato souse milk⇒5.pasta water milk∧⇒按support排序的前5个规则没有冗余规则。
数据挖掘作业

证明决策树生长的计算时间最多为 m D log( D ) 。
3.4 考虑表 3-23 所示二元分类问题的数据集。 表 3-23 习题 3.4 数据集
A
B
类标号
T
F
+
T
T
+
T
T
+
T
F
-
T
T
+
F
F
-
F
F
-
F
F
-
T
T
-
T
F
-
(1) 计算按照属性 A 和 B 划分时的信息增益。决策树归纳算法将会选择那个属性?
y ax 转换成可以用最小二乘法求解的线性回归方程。
表 3-25 习题 3.8 数据集
X 0.5 3.0 4.5 4.6 4.9 5.2 5.3 5.5 7.0 9.5
Y-
-
+++-
-
+-
-
根据 1-最近邻、 3-最近邻、 5-最近邻、 9-最近邻,对数据点 x=5.0 分类,使用多数表决。
3.9 表 3-26 的数据集包含两个属性 X 与 Y ,两个类标号“ +”和“ -”。每个属性取三个不同值策略: 0,1 或
记录号
A
B
C
类
1
0
0
0
+
2
0
0
1
-
3
0
1
1
-
4
0
1
1
-
5
0
0
1
+
6
1
0
1
+
7
1
数据挖掘大作业例子

数据挖掘大作业例子1. 超市购物数据挖掘呀!想想看,如果把超市里每个顾客的购买记录都分析一遍,那岂不是能发现很多有趣的事情?比如说,为啥周五晚上大家都爱买啤酒和薯片呢,是不是都打算周末在家看剧呀!2. 社交媒体情感分析这个大作业超有意思哦!就像你能从大家发的文字里看出他们今天是开心还是难过,那简直就像有了读心术一样神奇!比如看到一堆人突然都在发伤感的话,难道是发生了什么大事情?3. 电商用户行为挖掘也很棒呀!通过分析用户在网上的浏览、购买行为,就能知道他们喜欢什么、不喜欢什么,这难道不是很厉害吗?就像你知道了朋友的喜好,能给他推荐最适合的礼物一样!4. 交通流量数据分析呢!想象一下,了解每个路口的车流量变化,是不是就能更好地规划交通啦?难道这不像是给城市的交通装上了一双明亮的眼睛?5. 医疗数据挖掘更是不得了!能从大量的病例中找到疾病的规律,这简直是在拯救生命啊!难道这不是一件超级伟大的事情吗?比如说能发现某种疾病在特定人群中更容易出现。
6. 金融交易数据挖掘也超重要的呀!可以知道哪些交易有风险,哪些投资更靠谱,那不就像有个聪明的理财顾问在身边吗!就好比能及时发现异常的资金流动。
7. 天气数据与出行的结合挖掘也很有趣呀!根据天气情况来预测大家的出行选择,真是太神奇了吧!难道不是像有了天气预报和出行指南合二为一?8. 音乐喜好数据挖掘呢!搞清楚大家都喜欢听什么类型的音乐,从而能更好地推荐歌曲,这不是能让人更开心地享受音乐吗!好比为每个人定制了专属的音乐播放列表。
9. 电影票房数据挖掘呀!通过分析票房数据就能知道观众最爱看的电影类型,这不是超厉害的嘛!就像知道了大家心里最期待的电影是什么样的。
我觉得数据挖掘真的太有魅力了,可以从各种看似普通的数据中发现那么多有价值的东西,真是让人惊叹不已啊!。
数据挖掘作业
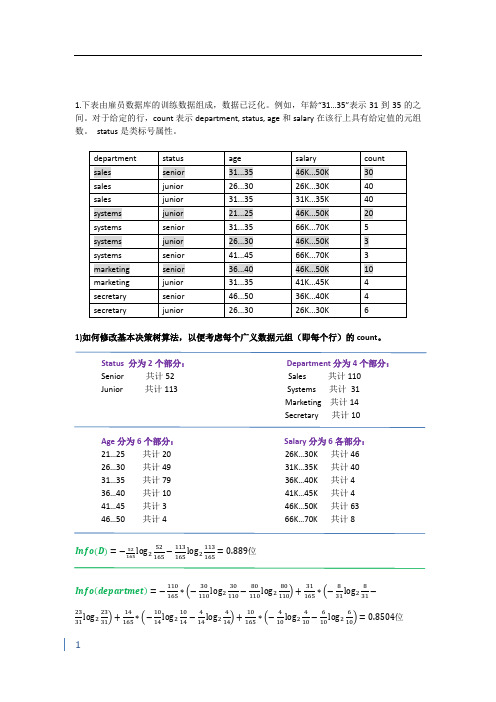
1.下表由雇员数据库的训练数据组成,数据已泛化。
例如,年龄“31…35”表示31到35的之间。
对于给定的行,count表示department, status, age和salary在该行上具有给定值的元组数。
status是类标号属性。
1)如何修改基本决策树算法,以便考虑每个广义数据元组(即每个行)的count。
Status 分为2个部分:Department分为4个部分:Senior 共计52 Sales 共计110Junior 共计113 Systems 共计31Marketing 共计14Secretary 共计10Age分为6个部分:Salary分为6各部分:21…25 共计20 26K…30K 共计4626…30 共计49 31K…35K 共计4031…35 共计79 36K…40K 共计436…40 共计10 41K…45K 共计441…45 共计3 46K…50K 共计6346…50 共计4 66K…70K 共计8Info(D)=−52165log252165−113165log2113165=0.889位Info(departmet)=−110165∗(−30110log230110−80110log280110)+31165∗(−831log2831−23 31log22331)+14165∗(−1014log21014−414log2414)+10165∗(−410log2410−610log2610)=0.8504位Gain(department)=Info(D)−Info(department)=0.0386位Info(age)=−20165∗(−020log2020−2020log22020)+49165∗(−049log2049−4949log24949)+79165∗(−3579log23575−3479log23479)+10165∗(−1010log21010−010log2010)+3165∗(−33log233−03log203)+4 165∗(−44log244−04log204)=0.4998位Gain(age)=Info(D)−Info(age)=0.3892位Info(salary)=−46165∗(−046log2046−4646log24646)+40165∗(−040log2040−4040log24040)+4165∗(−44log244−04log204)+63165∗(−3063log23063−3363log23363)+8165∗(−88log288−08log208)=0.3812位Gain(salary)=Info(D)−Info(salary)=0.5078位由以上的计算知按信息增益从大到小对属性排列依次为:salary、age、department,所以定由这个表可知department和age的信息增益将都为0。
数据挖掘作业

1、给出K D D的定义和处理过程。
KDD的定义是:从大量数据中提取出可信的、新颖的、有用的且可以被人理解的模式的高级处理过程。
因此,KDD是一个高级的处理过程,它从数据集中识别出以模式形式表示的知识。
这里的“模式”可以看成知识的雏形,经过验证、完善后形成知识:“高级的处理过程”是指一个多步骤的处理过程,多步骤之间相互影响反复调整,形成一种螺旋式上升的过程。
KDD的全过程有五个步骤:1、数据选择:确定发现任务的操作对象,即目标数据,它是根据用户的需要从原始数据库中抽取的一组数据;2、数据预处理:一般可能包括消除噪声、推到技术却只数据、消除重复记录、完成数据类型转换等;3、数据转换:其主要目的是消减数据维数或降维,即从初始特征中找出真正有用的特征以减少数据开采时要考虑的特征或变量个数;4、数据挖掘:这一阶段包括确定挖掘任务/目的、选择挖掘方法、实施数据挖掘;5、模式解释/评价:数据挖掘阶段发现出来的模式,经过用户或机器的评价,可能存在冗余或无关的模式,需要剔除;也有可能模式不满足用户的要求,需要退回到整个发现阶段之前,重新进行KDD过程。
2、阐述数据挖掘产生的背景和意义。
数据挖掘产生的背景:随着信息科技的进步以及电子化时代的到来,人们以更快捷、更容易、更廉价的方式获取和存储数据,使得数据及信息量以指数方式增长。
据粗略估计,一个中等规模企业每天要产生100MB以上的商业数据。
而电信、银行、大型零售业每天产生的数据量以TB来计算。
人们搜集的数据越来越多,剧增的数据背后隐藏着许多重要的信息,人们希望对其进行更高层次的分析,以便更好的利用这些数据。
先前的数据库系统可以高效的实现数据的录入、查询、统计等功能,但无法发现数据中存在的关系与规则,无法根据现有的数据来预测未来的发展趋势。
缺乏挖掘数据背后隐藏的知识的手段。
导致了“数据爆炸但知识贫乏”的现象。
于是人们开始提出“要学会选择、提取、抛弃信息”,并且开始考虑:如何才能不被信息淹没?如何从中及时发现有用的知识、提高信息利用率?如何从浩瀚如烟海的资料中选择性的搜集他们认为有用的信息?这给我们带来了另一些头头疼的问题:第一是信息过量,难以消化;第二是信息真假难以辨别;第三是信息安全难以保证;第四是信息形式不一致,难以统一处理面对这一挑战,面对数量很大而有意义的信息很难得到的状况面对大量繁杂而分散的数据资源,随着计算机数据仓库技术的不断成熟,从数据中发现知识(Knowledge Discovery in Database)及其核心技术——数据挖掘(Data Mining)便应运而生,并得以蓬勃发展,越来越显示出其强大的生命力。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1•下表由雇员数据库的训练数据组成,数据已泛化。
例如,年龄“ 31…3表示31到35的之
间。
对于给定的行,count表示department, status, age和salary在该行上具有给定值的元组数。
status是类标号属性。
1)如何修改基本决策树算法,以便考虑每个广义数据元组(即每个行)的count。
Status分为2个部分:Department分为4个部分:
Senior 共计52 Sales 共计110
Junior 共计113 Systems 共计31
Marketi ng 共计14
Secretary 共计10
Age分为6个部分:Salary分为6各部分:
21-25 共计20 26K …30K 共计46
26-30 共计49 31K …35K 共计40
31-35 共计79 36K-40K 共计 4
36-40 共计10 41K-45K 共计 4
41-45 共计3 46K-50K 共计63
46-50 共计4 66K-70K 共计8
—位
位
位
位
由以上的计算知按信息增益从大到小对属性排列依次为:salary、age、department,所以定
salary作为第一层,之后剩下的数据如下:
由这个表可知department和age的信息增益将都为0。
所以第二层可以为age也可以为
department。
2)构造给定数据的决策树。
由上一小问的计算所构造的决策树如下:
3)给定一个数据元组,
它在属性department, age 和salary 上的值分别为 “ systems "“ 26 (30)
和“46...50K 。
"该元组status 的朴素贝叶斯分类结果是什么?
P(status=se nior)=52/165=0.3152 P(status=ju nior)=113/65=0.6848
P(departme nt=systems|status=se ni or)=8/52=0.1538 P(departme nt=systems|status=ju nior)=23/113=0.2035 P(age=26 •-30|status=se nior)=1/52=0.0192 P(age=26…30|status=ju nior)=49/113=0.4336 P(salary=46K- 50K|status=se nior)=40/52=0.7692 P(salary=46K- 50K|status=ju nior)=23/113=0.2035
使用上面的概率,得到:
P(X|status=se ni or)=P(departme nt=systems|status=se ni or)*P(age= 26 •-30|status=se ni or)* P(salary=46K- 50K|status=se nior)=0.0023
P(X|status=j uni or)=P(departme nt=systems|status=j uni or)*P(age= 26 •-30|status=j unior)*
P(salary=46K- 50K|status= ju ni or)=0.0180
26:30
:35
Senior
Salary
26K:30K
Junior
41K:45K
Jun ior
Senior
Jun ior
Jun ior
66K:70K
31K:35K
46K:50K
21:25
36:40
Jun ior
Sen ior
36K:40
Sen ior
P(X|status=se nior)* P(status=se nior)= 7.2496e-004
P(X|status=junior)* P(status=junior)=0.0123
因此,对于元组X,朴素贝叶斯分类预测元组X的类为status=junior 2.运用决策树或者贝叶斯算法,对鸢尾花数据集进行分类,显示分类结果。
(可以采用Weka工具或者其他方法)
在weka上运用决策树算法对鸢尾花数据集进行分类,分类结果如下图所示:
Iris-virginica (46.DM .0)
lris-versicolor (3
.
0/1.0)
在weka上运用贝叶斯算法对鸢尾花数据进行分类,结果的具体情况如下:
■<= □
S'
'=0.6'
'> r?1
■Iri-s-virginica (3.0)'
Iris-versicolor (46.OH 0)
'--1,5'
Btfiyusi Clni f lex*
Attr xB-ute
CXass
Ixxs —setasa I ras—versi-co^lox Jirxs—vi
<0.33>
<0*33)<0 ・ 33)
ae>pa 1 1 en^t:K
mean4»99I35•9379 6.5795
O. 3550 ・ 50420 ・€353 x ghl: sum90SO SO pr-ecisxon□•L0590•loss0 .J.OS9
sepalwidrh
xnaan3»40152•7€«7 2 ・X29•td・•0.39250 ・ 303e o.3oee vreight sum SO so so pr-eclaJ.on0»10910 ・109X0 ・J.O91
pcca 1 lenom
mean JL.4694 4 ・ 24S2 5.3516■rd. dwv.0^X702O ・ 471.^O ・ 5529 vreignT sum50SO50 pr-ecl^Xon0*14050 ・ 14050.1405
pc 匸a lwidxti
mean0.27431・ 30972.0343 Mtd. dev.0.10960 ・19150 ・2646 vreignr oum50SO50 precl^^on O»11430 ・11430.1143
Corr色ctly Classified Instances
Incorrectly Classified. In3tance3 Kappa
stariscic
Mean dbsolute error
Root mean sijuared error Relative
absolute error
Roou relative squared error
Total Number of Instaaces
==Confusion Matrix ==
a b c <■- classified, as
50 0 0 I a = Iris-set&sa
0 48 2I b = Iris-versicolor
0 4 46 I Iris-virginica
144
£
0.94
0.0342
0.155
7.6997 ¥
32.8794 *
150。