常用汉字16进制编码表
字符串和16进制对照表的

字符串和16进制对照表的字符串和16进制对照表是一种常用的数据编码方式,通过将字符串中的每个字符映射为对应的16进制值,实现字符串和二进制数据之间的转换。
本文将介绍字符串和16进制对照表的基本概念和原理,并提供相关参考内容。
1. 字符串和16进制的关系字符串和16进制之间存在一种一一对应的关系,每个字符都可以用一个唯一的16进制数表示。
这个16进制数可以是0~9的数字,也可以是A~F的大写字母,总共有16个选择。
通过将字符串中的每个字符转换为对应的16进制数,就可以将字符串表示为16进制数据。
2. 字符串转16进制的方法将字符串转换为16进制可以使用多种方法,常见的有ASCII 码和Unicode码。
ASCII码是一种用于表示字符的标准编码,它将每个字符映射为一个唯一的数字。
Unicode是一个统一的字符编码标准,它使用16位或32位的代码表示字符,可以表示几乎所有文字系统的字符。
下面是常用的字符串转16进制的方法:- ASCII转换:可以使用ord函数将字符串中的每个字符转换为对应的ASCII码,然后再将ASCII码转换为16进制。
- Unicode转换:可以使用encode函数将字符串转换为Unicode编码,再使用hex函数将Unicode编码转换为16进制表示。
例如,将字符串"Hello"转换为16进制可以使用如下Python代码:```python# ASCII转换hex_string = ''.join([hex(ord(c))[2:] for c in "Hello"])# Unicode转换hex_string = ''.join([hex(ord(c))[2:] for c in"Hello".encode('unicode_escape')])```3. 16进制转字符串的方法将16进制转换为字符串可以使用反向的方法,即将16进制数转换为相应的字符,然后拼接起来得到字符串。
汉字转16位编码

汉字转16位编码(原创版)目录一、汉字转 16 位编码的背景和原因二、汉字转 16 位编码的方法三、汉字转 16 位编码的优缺点四、汉字转 16 位编码的应用场景五、总结正文一、汉字转 16 位编码的背景和原因汉字是中华文化的重要组成部分,包含了大量的信息和知识。
在计算机中,汉字以编码的形式存储和传输。
常见的汉字编码方式有 GBK、UTF-8 等。
然而,在某些特定的场景下,需要将汉字转换为 16 位编码,以满足特定的需求。
二、汉字转 16 位编码的方法汉字转 16 位编码,主要是将汉字从原来的编码方式转换为 16 进制数表示。
具体方法如下:1.首先,需要确定汉字的编码范围。
常用的汉字编码范围包括 GBK、Unicode 等。
2.然后,根据编码范围,将汉字转换为对应的 16 进制数。
例如,在GBK 编码中,汉字“中”的编码为“B8C4”,在 Unicode 编码中,汉字“中”的编码为“4F60”。
3.最后,将转换后的 16 进制数进行编码,即可得到汉字的 16 位编码。
三、汉字转 16 位编码的优缺点汉字转 16 位编码的优点:1.16 位编码可以包含更多的汉字,相比于常见的编码方式,可以表示更多的汉字。
2.16 位编码具有较高的安全性,由于 16 位数的组合方式更多,因此可以更好地防止编码冲突。
汉字转 16 位编码的缺点:1.16 位编码相对于常见的编码方式,其编码长度更长,存储和传输效率较低。
2.16 位编码的转换过程较为复杂,需要进行多次编码和解码,增加了处理的难度。
四、汉字转 16 位编码的应用场景汉字转 16 位编码的应用场景主要包括:1.在某些特定的系统中,需要使用 16 位编码表示汉字,如古籍数字化、特殊场景的汉字识别等。
2.对于一些对汉字编码有特殊要求的应用,如加密传输等,也需要使用 16 位编码表示汉字。
五、总结汉字转 16 位编码是一种将汉字从常见的编码方式转换为 16 进制数表示的方法。
汉字编码问题

汉字编码问题由于常常要和汉字处理打交道,因此,我常常受到汉字编码问题的困扰。
在不断的打击与坚持中,也积累了一点汉字编码方面的经验,想和大家一起分享。
一、汉字编码的种类汉字编码中现在主要用到的有三类,包括GBK,GB2312和Big5。
1、GB2312又称国标码,由国家标准总局发布,1981年5月1日实施,通行于大陆。
新加坡等地也使用此编码。
它是一个简化字的编码规范,当然也包括其他的符号、字母、日文假名等,共7445个图形字符,其中汉字占6763个。
我们平时说6768个汉字,实际上里边有5个编码为空白,所以总共有6763个汉字。
GB2312规定“对任意一个图形字符都采用两个字节表示,每个字节均采用七位编码表示”,习惯上称第一个字节为“高字节”,第二个字节为“低字节”。
GB2312中汉字的编码范围为,第一字节0xB0-0xF7(对应十进制为176-247),第二个字节0xA0-0xFE(对应十进制为160-254)。
GB2312将代码表分为94个区,对应第一字节(0xa1-0xfe);每个区94个位(0xa1-0xfe),对应第二字节,两个字节的值分别为区号值和位号值加32(2OH),因此也称为区位码。
01-09区为符号、数字区,16-87区为汉字区(0xb0-0xf7),10-15区、88-94区是有待进一步标准化的空白区。
2、Big5又称大五码,主要为香港与台湾使用,即是一个繁体字编码。
每个汉字由两个字节构成,第一个字节的范围从0X81-0XFE(即129-255),共126种。
第二个字节的范围不连续,分别为0X40-0X7E(即64-126),0XA1-0XFE(即161-254),共157种。
3、GBK是GB2312的扩展,是向上兼容的,因此GB2312中的汉字的编码与GBK中汉字的相同。
另外,GBK中还包含繁体字的编码,它与Big5编码之间的关系我还没有弄明白,好像是不一致的。
GBK中每个汉字仍然包含两个字节,第一个字节的范围是0x81-0xFE(即129-254),第二个字节的范围是0x40-0xFE(即64-254)。
ASCII码表与数制转换
█ ▄ ▌ ▐ ▀ α ß Γ π Σ σ µ τ Φ Θ Ω δ ∞ φ ε ∩ ≡ ± ≥ ≤ ⌠ ⌡ ÷ ≈ ≈ · · √ ⁿ
6
以上内容 David 整理,如有错误请告知: David_daik@
189 190 191
BD BE BF
╜ ╛ ┐
253 254 255
数据链路转意
设备控制1 设备控制2 设备控制3 设备控制4 反确认 同步空闲 传输块结束 取消 媒体结束 替换 转意 文件分隔符 组分隔符 记录分隔符 单元分隔符
以上内容 David 整理,如有错误请告知: David_daik@
2
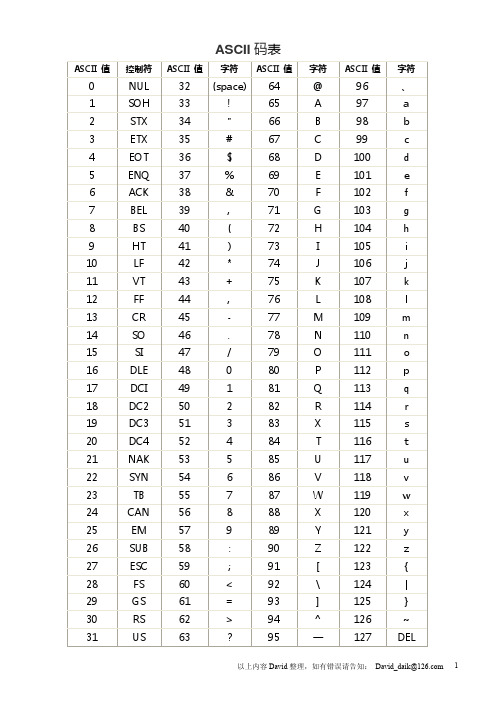
ASCII打印字符表
数字32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。数字127 代表DELETE 命令。 十进制 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 十六进制 20 21 22 23 24 25 26 27 28 29 2A 2B 2C 2D 2E 2F 30 31 32 33 34 35 36 37 38 39 3A 3B 3C 3D . / 0 1 2 3 4 5 6 7 8 9 : ; < = 字符 space 十进制 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 十六进制 50 51 52 53 54 55 56 57 58 59 5A 5B 5C 5D 5E 5F 60 61 62 63 64 65 66 67 68 69 6A 6B 6C 6D 字符
从16进制转换成汉字

从16进制转换成汉字/// <summary>/// 从汉字转换到16进制/// </summary>/// <param name="s"></param>/// <returns></returns>public static string GetHexFromChs(string s){if ((s.Length % 2) != 0){s += " ";//空格//throw new ArgumentException("s is not valid chinese string!");}System.Text.Encoding chs = System.Text.Encoding.GetEncoding("gb2312");byte[] bytes = chs.GetBytes(s);string str = "";for (int i = 0; i < bytes.Length; i++){str += string.Format("{0:X}", bytes[i]);}return str;}/// <summary>/// 从16进制转换成汉字/// </summary>/// <param name="hex"></param>/// <returns></returns>public static string GetChsFromHex(string hex){if (hex == null)throw new ArgumentNullException("hex");if (hex.Length % 2 != 0){hex += "20";//空格//throw new ArgumentException("hex is not a valid number!", "hex");}// 需要将 hex 转换成 byte 数组。
字符编码

23
GB码区位示例
01区
78位
24
GB码区位示例(续)
16 区 1 2 3 4 5 6 7 8 9 0 啊 阿 埃 挨 哎 唉 哀 皑 癌 1 蔼 矮 艾 碍 爱 隘 鞍 氨 安 俺 2 按 暗 岸 胺 案 肮 昂 盎 凹 敖 3 熬 翱 袄 傲 奥 懊 澳 芭 捌 扒 4 叭 吧 笆 八 疤 巴 拔 跋 靶 把 5 耙 坝 霸 罢 爸 白 柏 百 摆 佰 6 败 拜 稗 斑 班 搬 扳 般 颁 板 7 版 扮 拌 伴 瓣 半 办 绊 邦 帮 8 梆 榜 膀 绑 棒 磅 蚌 镑 傍 谤 9 苞 胞 包 褒 剥 17 区 1 2 3 4 5 6 7 8 9 0 薄 雹 保 堡 饱 宝 抱 报 暴 1 豹 鲍 爆 杯 碑 悲 卑 北 辈 背 2 贝 钡 倍 狈 备 惫 焙 被 奔 苯 3 本 笨 崩 绷 甭 泵 蹦 迸 逼 鼻 4 比 鄙 笔 彼 碧 蓖 蔽 毕 毙 毖 5 币 庇 痹 闭 敝 弊 必 辟 壁 臂 6 避 陛 鞭 边 编 贬 扁 便 变 卞 7 辨 辩 辫 遍 标 彪 膘 表 鳖 憋 8 别 瘪 彬 斌 濒 滨 宾 摈 兵 冰 9 柄 丙 秉 饼 炳
19
二、计算机中中文字符的表示 汉字交换码
国家标准将每个汉字和图形符号的两个字节分 别用两位的十进制编码(不足补0),前字节的编 码称为区码,后字节的编码称为位码,排列在一个 94行94列的二维代码表中,形成区位码表。 如“保”字在二维代码表中处于17区第03位 ,区位码即为1703D 。 把区位码按一定的规则转换成的二进制代码叫 做信息交换码(简称国标码)。
字 符 编 码
1
提
纲
一 计算机中字符的表示(ASCII码) 二 计算机中中文字符的表示
2
概 述
unicode编码表

unicode编码表Unicode编码表是一种通用字符编码标准,旨在为世界上所有书写系统中的所有字符提供唯一的数字代码。
它由Unicode联盟维护,Unicode编码表一般包括字符的名称、代码点、通用字符名称(如果有的话),以及所属的块等信息。
Unicode编码表包括了大量的字符,覆盖了各个语言所需要的字符以及其他特殊字符,包括但不限于字母、数字、符号、标点、箭头、数学符号、货币符号、音乐符号、表情符号等等。
不同的语言所需的字符数量有所不同,虽然有些语言具有相同或相近的字符,但是它们所对应的码位是不同的。
同时,Unicode编码表还定义了各种文本处理操作和格式化代码。
Unicode编码表是一个16进制数的列表,每个字符都对应一个固定的代码点。
代码点是一个整数,用于标识特定字符。
Unicode编码表目前的最大值为0x10FFFF,共有超过1.1万个字符。
Unicode编码表的编码方案分为UTF-8、UTF-16和UTF-32等多种格式,可以根据需要选择不同的格式。
在计算机系统中,字符以数字形式进行存储和传输。
由于不同的计算机系统采用不同的编码方案,不同的字符集之间不能直接进行转换,因此需要Unicode编码表的标准化。
目前,几乎所有的计算机操作系统和应用程序都支持Unicode编码表。
Unicode编码表的使用以及支持程度在各个国家和地区是不同的。
在中国,Unicode编码表由GB 18030标准所覆盖。
GB 18030是中华人民共和国推出的字符编码标准,包括了基本拉丁字母、汉字、日文及朝鲜文等字符。
总之,Unicode编码表是计算机所使用的一种标准化字符编码,它使得不同语言的文字、符号等可以在计算机中被正确地存储、传输和显示。
它是现代计算机领域中非常重要的标准之一。
常用汉字 进制编码表

李 C0EE 亲 C7D7 土 CDC1 也 D2B2
里 C0EF 琴 C7D9 退 CDCB 叶 D2B6
丽 C0F6 青 C7E0 外 CDE2 夜 D2B9
莲 C1AB 清 C7E5 万 CDF2 一 D2BB 林 C1D6 情 C7E9 汪 CDF4 毅 D2E3 玲 C1E1 人 C8CB 王 CDF5 因 D2F2 刘 C1F5 荣 C8D9 为 CEAA 莹 D3A8 六 C1F9 三 C8FD 我 CED2 咏 D3BD 绿 C2CC 上 C9CF 吴 CEE2 勇 D3C2 猫 C3A8 少 C9D9 五 CEE5 有 D3D0 没 C3BB 生 C9FA 西 CEF7 右 D3D2 美 C3C0 失 CAA7 下 CFC2 鱼 D3E3 妹 C3C3 十 CAAE 香 CFE3 雨 D3EA 喵 DFF7 时 CAB1 想 CFEB 远 D4B6 敏 C3F4 士 CABF 小 D0A1 宅 D5AC 明 C3F7 事 CAC2 晓 CFFE 张 D5C5 命 C3FC 是 CAC7 笑 D0A6 珍 D5E4 木 C4BE 水 CBAE 谢 D0BB 真 D5E6 男 C4D0 思 CBBC 心 D0C4 正 D5FD 南 C4CF 四 CBC4 新 D0C2 郑 D6A3 你 C4E3 苏 CBD5 星 D0C7 知 D6AA 念 C4EE 酸 CBE1 行 D0D0 值 D6B5 女 C5AE 太 CCAB 雄 D0DB 只 D6BB 培 C5E0 天 CCEC 许 D0ED 智 D6C7 七 C6DF 甜 CCF0 雪 D1A9 中 D6D0 千 C7A7 甜 CCF0 言 D1D4 猪 D6ED 前 C7B0 婷 E6C3 燕 D1E0 左 D7F3
常用汉字16进制编码(按பைடு நூலகம்母排列)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
汉字 16进制 汉字 16进制 汉字 16进制 汉字 16进制 爱 B0AE 地 B5D8 好 BAC3 见 BCFB 八 B0CB 东 B6AB 浩 BAC6 健 BDA1 白 B0D7 多 B6E0 何 BACE 江 BDAD 百 B0D9 二 B6FE 黑 BADA 蕉 BDB6 败 B0DC 发 B7A2 很 BADC 杰 BDDC 北 B1B1 房 B7BF 恨 BADE 今 BDF1 波 B2A8 放 B7C5 红 BAEC 金 BDF0 不 B2BB 菲 B7C6 虹 BAE7 近 BDFC 蔡 B2CC 锋 B7E6 猴 BAEF 进 BDF8 车 B3B5 敢 B8D2 后 BAF3 景 BEB0 陈 B3C2 感 B8D0 狐 BAFC 九 BEC5 成 B3C9 哥 B8E7 华 BBAA 旧 BEC9 程 B3CC 个 B8F6 坏 BBB5 娟 BEEA 橙 B3C8 功 B9A6 黄 BBC6 钧 BEFB 聪 B4CF 狗 B9B7 辉 BBD4 俊 BFA1 大 B4F3 光 B9E2 慧 BBDB 看 BFB4 道 B5C0 郭 B9F9 火 BBF0 康 BFB5 德 B5C2 国 B9FA 佳 BCD1 苦 BFE0 的 B5C4 海 BAA3 嘉 BCCE 苦 BFE0 迪 B5CF 豪 BAC0 假 BCD9 块 BFE9 蓝 C0B6 钱 C7AE 间 BCE4 辣 C0B1
李 C0EE 亲 C7D7 土 CDC1 也 D2B2
里 C0EF 琴 C7D9 退 CDCB 叶 D2B6
丽 C0F6 青 C7E0 外 CDE2 夜 D2B9
莲 C1AB 清 C7E5 万 CDF2 一 D2BB 林 C1D6 情 C7E9 汪 CDF4 毅 D2E3 玲 C1E1 人 C8CB 王 CDF5 因 D2F2 刘 C1F5 荣 C8D9 为 CEAA 莹 D3A8 六 C1F9 三 C8FD 我 CED2 咏 D3BD 绿 C2CC 上 C9CF 吴 CEE2 勇 D3C2 猫 C3A8 少 C9D9 五 CEE5 有 D3D0 没 C3BB 生 C9FA 西 CEF7 右 D3D2 美 C3C0 失 CAA7 下 CFC2 鱼 D3E3 妹 C3C3 十 CAAE 香 CFE3 雨 D3EA 喵 DFF7 时 CAB1 想 CFEB 远 D4B6 敏 C3F4 士 CABF 小 D0A1 宅 D5AC 明 C3F7 事 CAC2 晓 CFFE 张 D5C5 命 C3FC 是 CAC7 笑 D0A6 珍 D5E4 木 C4BE 水 CBAE 谢 D0BB 真 D5E6 男 C4D0 思 CBBC 心 D0C4 正 D5FD 南 C4CF 四 CBC4 新 D0C2 郑 D6A3 你 C4E3 苏 CBD5 星 D0C7 知 D6AA 念 C4EE 酸 CBE1 行 D0D0 值 D6B5 女 C5AE 太 CCAB 雄 D0DB 只 D6BB 培 C5E0 天 CCEC 许 D0ED 智 D6C7 七 C6DF 甜 CCF0 雪 D1A9 中 D6D0 千 C7A7 甜 CCF0 言 D1D4 猪 D6ED 前 C7B0 婷 E6C3 燕 D1E0 左 D7F3