多元统计分析报告整理版.doc
多元统计分析实验报告
第二部分:实验过程记录(可加页) (包括实验原始数据记录,实验现象记录,实验过程发现的问题
等) 操作步骤: 1、 执行“分析”—“比较均值”—“单因素方差分析” ; 2、 在弹出的单因素方差分析对话框中,将时期选为因子,将 X1、X2、X3、X4 选为因变量; 3、 单击“对比” ,选择“多项式” ,在后面的下拉菜单中选择“线性” ,然后继续; 4、 单击“两两比较” ,选择“LSD”和“S-N-K” ,显著性水平默认为 0.05,然后继续; 5、 单击“选项” ,选择“方差同质性检验”和“均值图” ,然后继续,点击“确定”后即可输出结果。
12
题目:研究者提出,随着时间的推移头骨尺寸会发生变化,这是外来移民与原住民人口民族融合的证据。表 6.13 是古埃及三个时期的男性头骨的四个观测值得观测数据,这是个观测变量是: X1=头骨最大的最大宽度 X2=头骨高度 X3=头骨底穴至齿槽的长度 X4=头骨鼻梁高度 对古埃及头骨数据构造单因子 MANOVA 表, a=0.05.并构造 95%联合置信区间来判断在三个时期中哪个分 令 量的均值发生了改变。同常的 MANOVA 假设对这些数据是不是合理的?请解释。 部分数据如下:
实验课程名称:多元统计分析-均值向量检验
实验项目名称 实 验 者 同 组 者
均值向量检验习题 均值向量检验习题 6.24
专业班级
实验成绩 实验成绩 组 别 年 月 日
实验日期
一部分:实验预习报告(包括实验目的、意义,实验基本原理与方法,主要仪器设备及耗材,实验
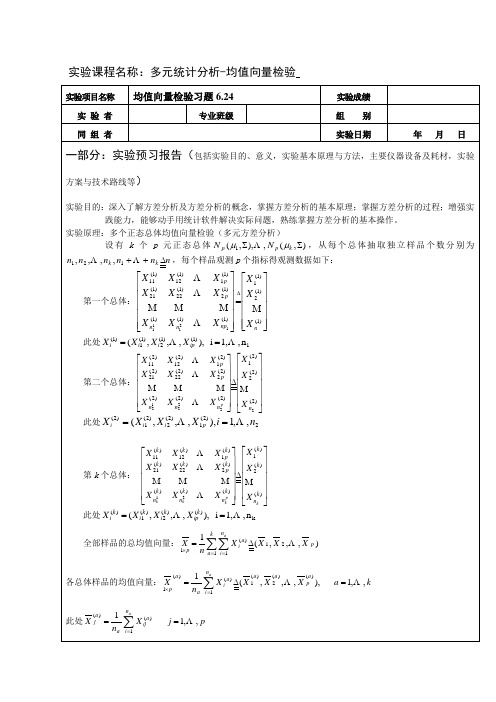
方案与技术路线等) 实验目的:深入了解方差分析及方差分析的概念,掌握方差分析的基本原理;掌握方差分析的过程;增强实 践能力,能够动手用统计软件解决实际问题,熟练掌握方差分析的基本操作。 实验原理:多个正态总体均值向量检验(多元方差分析) 设 有 k 个 p 元 正 态 总 体 N p ( µ1 , Σ), L , N p ( µ k , Σ) , 从 每 个 总 体 抽 取 独 立 样 品 个 数 分 别 为
多元统计分析.doc

作业一1.2 分析2016年经济发展情况排名省gdp 占比累计占比1 广东79512.05 10.30 10.302 江苏76086.2 9.86 20.173 山东67008.2 8.68 28.854 浙江46485 6.02 34.875 河南40160.01 5.20 40.086 四川32680.5 4.24 44.317 湖北32297.9 4.19 48.508 河北31827.9 4.12 52.629 湖南31244.7 4.05 56.6710 福建28519.2 3.70 60.3711 上海27466.2 3.56 63.9312 北京24899.3 3.23 67.1613 安徽24117.9 3.13 70.2814 辽宁22037.88 2.86 73.1415 陕西19165.39 2.48 75.6216 内蒙古18632.6 2.41 78.0417 江西18364.4 2.38 80.4218 广西18245.07 2.36 82.7819 天津17885.4 2.32 85.1020 重庆17558.8 2.28 87.3721 黑龙江15386.09 1.99 89.3722 吉林14886.23 1.93 91.3023 云南14869.95 1.93 93.2224 山西12928.3 1.68 94.9025 贵州11734.43 1.52 96.4226 新疆9550 1.24 97.6627 甘肃7152.04 0.93 98.5928 海南4044.51 0.52 99.1129 宁夏3150.06 0.41 99.5230 青海2572.49 0.33 99.8531 西藏1150.07 0.15 100.00将2016各省的GDP进行排名,可以发现,经济发达的的地区主要集中在东部地区。
西部gdp的占比较小。
作出2016各省的gdp直方图如下:作业二 多元回归分析2.1多元线性回归 2.1.1数据来源《福建省统计年鉴-2017》 年份 商品零售价格指数y 农业生产资料价格指数x1 工业生产价格指数x2 工业生产者购进价格指数x3 固定资产投资价格总指数x4 2000 98.9 97.4 100.5 112.4 100.2 2001 98 98.7 98.1 96.7 99.5 2002 98.3 99.9 97.6 97.6 99.7 2003 99.1 101.8 100.7 106.3 101.4 2004 102.7 112.5 102.6 113.3 103.4 2005 100.6 108.1 100.2 108.1 100.7 2006 100.5 100.9 99.2 103.9 102 2007 104.3 110.3 100.8 104.3 105.9 2008 105.7 123.6 102.7 110.2 105.9 2009 97.9 93.3 95.5 93.2 98 2010 103.4 102.4 103.2 107.7 103.3 2011 104.8 111.8 103.9 108 106.2 2012 101.8 103.3 98.7 97.7 100.3 2013 101.1 99.5 98.4 98.4 100.1 2014 101.1 99.5 98.6 98.3 100.4 2015 99.9 101.4 97 96.1 98.3 2016 100.7100.2 99.198 1002.1.2模型假设商品的零售价格会受很多因素的影响,对于影响零售价格指数y 的影响现在仅考虑农业生产资料指数x1、工业生产价格指数x2、工业生产者购进价格指数x3、固定资产投资的影响x4。
多元统计数据分析报告(3篇)

第1篇一、引言随着大数据时代的到来,数据量急剧增加,传统的统计分析方法已无法满足复杂数据关系的挖掘需求。
多元统计分析作为一种处理多个变量之间关系的方法,在社会科学、自然科学、工程技术等领域得到了广泛应用。
本报告旨在通过对某研究项目的多元统计分析,揭示变量之间的关系,为决策提供科学依据。
二、研究背景与目的本研究以某企业员工绩效评估数据为研究对象,旨在通过多元统计分析方法,探究员工绩效与个人特质、工作环境等因素之间的关系,为企业人力资源管理部门提供决策支持。
三、数据与方法1. 数据来源本研究数据来源于某企业员工绩效评估系统,包括员工的基本信息、个人特质、工作环境、绩效评分等。
2. 研究方法本研究采用以下多元统计分析方法:(1)描述性统计分析:对员工绩效、个人特质、工作环境等变量进行描述性统计分析,了解数据的分布情况。
(2)相关分析:分析变量之间的线性关系,找出相关系数较大的变量对。
(3)因子分析:将多个变量归纳为少数几个因子,揭示变量之间的内在关系。
(4)聚类分析:将员工根据绩效、个人特质、工作环境等因素进行分类,分析不同类别员工的特点。
(5)回归分析:建立员工绩效与个人特质、工作环境等因素之间的回归模型,分析各因素对绩效的影响程度。
四、数据分析结果1. 描述性统计分析通过对员工绩效、个人特质、工作环境等变量的描述性统计分析,得出以下结论:(1)员工绩效评分呈正态分布,平均绩效评分为75分。
(2)个人特质得分集中在中等水平,其中创新能力得分最高,稳定性得分最低。
(3)工作环境得分普遍较高,其中工作压力得分最低。
2. 相关分析通过对员工绩效、个人特质、工作环境等变量进行相关分析,得出以下结论:(1)绩效与创新能力、稳定性、工作环境等因素呈正相关。
(2)创新能力与稳定性呈负相关。
3. 因子分析通过对员工绩效、个人特质、工作环境等变量进行因子分析,得出以下结论:(1)提取了3个因子,分别对应创新能力、稳定性、工作环境。
多元统计分析 实验报告

多元统计分析实验报告1. 引言多元统计分析是一种用于研究多个变量之间关系的统计方法。
在实验中,我们使用了多元统计分析方法来探索一组数据中的变量之间的关系。
本报告将介绍我们的实验设计、数据收集和分析方法以及结果和讨论。
2. 实验设计为了进行多元统计分析,我们设计了一个实验,收集了一组相关变量的数据。
我们选择了X、Y和Z这三个变量作为我们的研究对象。
为了获得准确的结果,我们采用了以下实验设计:1.确定研究目的:我们的目标是探索X、Y和Z之间的关系,并确定它们之间是否存在任何相关性。
2.数据收集:我们通过调查问卷的方式收集了一组数据。
我们请参与者回答与X、Y和Z相关的问题,以获得关于这些变量的定量数据。
3.数据整理:在收集完数据后,我们将数据进行整理,将其转化为适合多元统计分析的格式。
我们使用Excel等工具进行数据整理和清洗。
4.数据验证:为了确保数据的准确性,我们对数据进行验证。
我们检查数据的有效性,比较数据之间的一致性,并排除任何异常值。
3. 数据分析在数据收集和整理完毕后,我们使用了一些常见的多元统计分析方法来分析我们的数据。
以下是我们使用的方法和步骤:1.描述统计分析:我们首先对数据进行了描述性统计分析。
我们计算了X、Y和Z的均值、标准差、最大值和最小值等。
这些统计量帮助我们了解数据的基本特征。
2.相关性分析:接下来,我们进行了相关性分析,以确定X、Y和Z之间是否存在相关关系。
我们计算了变量之间的相关系数,并绘制了相关系数矩阵。
这帮助我们确定变量之间的线性关系。
3.回归分析:为了更进一步地研究X、Y和Z之间的关系,我们进行了回归分析。
我们建立了一个多元回归模型,通过回归方程来预测因变量。
同时,我们还计算了回归系数和R方值,以评估模型的拟合度和预测能力。
4. 结果和讨论根据我们的实验设计和数据分析,我们得出了以下结果和讨论:1.描述统计分析结果显示,X的平均值为x,标准差为s;Y的平均值为y,标准差为s;Z的平均值为z,标准差为s。
多元统计实验报告

多元统计实验报告一、实验目的多元统计分析是统计学的一个重要分支,它能够处理多个变量之间的复杂关系。
本次实验的主要目的是通过实际操作和数据分析,深入理解多元统计分析的基本原理和方法,并掌握其在实际问题中的应用。
二、实验数据本次实验使用了一组来自某市场调研公司的数据集,包含了消费者的年龄、性别、收入、消费习惯等多个变量,共计_____个样本。
三、实验方法1、主成分分析(PCA)主成分分析是一种降维方法,它通过将多个相关变量转换为一组较少的不相关变量(即主成分),来简化数据结构并提取主要信息。
2、因子分析因子分析用于发现潜在的公共因子,这些因子能够解释多个观测变量之间的相关性。
3、聚类分析聚类分析将数据对象分组,使得同一组内的对象具有较高的相似性,而不同组之间的对象具有较大的差异性。
四、实验过程1、数据预处理首先,对原始数据进行了清洗和预处理,包括处理缺失值、异常值和数据标准化等操作,以确保数据的质量和可用性。
2、主成分分析使用统计软件进行主成分分析,计算出特征值、贡献率和累计贡献率。
根据特征值大于 1 的原则,确定了保留的主成分个数。
通过主成分载荷矩阵,解释了主成分的实际意义。
3、因子分析运用因子分析方法,提取公共因子,并通过旋转因子载荷矩阵,使得因子的解释更加清晰和具有实际意义。
计算因子得分,用于进一步的分析和应用。
4、聚类分析采用 KMeans 聚类算法,根据选定的变量对样本进行聚类。
通过不断调整聚类中心和重新分配样本,最终得到了较为合理的聚类结果。
五、实验结果与分析1、主成分分析结果提取了_____个主成分,它们累计解释了_____%的方差。
第一个主成分主要反映了_____,第二个主成分主要与_____相关,以此类推。
这为我们理解数据的主要结构提供了重要的线索。
2、因子分析结果成功提取了_____个公共因子,它们能够较好地解释原始变量之间的相关性。
每个因子所代表的潜在因素也得到了清晰的解释,有助于深入了解消费者的行为特征和市场结构。
多元统计分析数据.doc

第二章数据习题2.4地区人均GDP 三产比重人均消费人口增长文盲半文盲内蒙古5068 31.1 2141 8.23 15,83广西4076 34.2 2040 9.01 13.32贵州2342 29.8 1551 14.26 28.98云南4355 31.1 2059 12.1 25.48西藏3716 43.5 1551 15.9 57.97宁夏4270 37.3 1947 13.08 25.56新疆6229 35.4 2745 12.81 11.44甘肃3456 32.8 1612 10..04 28.65青海4367 40.9 2047 14.48 42.92第三章数据例3-1X1 职工标准工资收入 X5 单位得到的其他收入X2 职工奖金收入 X6 其他收入X3 职工津贴收入 X7 性别X4 其他工资性收入 X8 就业身份X1 X2 X3 X4 X5 X6 X7 X8 540.00 0.0 0.0 0.0 0.0 6.00 男国有1137.00 125.00 96.00 0.0 109.00 812.00 女集体1236.00 300.00 270.00 0.0 102.00 318.00 女国有1008.00 0.0 96.00 0.0 86.0 246.00 男集体1723.00 419.00 400.00 0.0 122.00 312.00 男国有1080.00 569.00 147.00 156.00 210.00 318.00 男集体1326.00 0.0 300.00 0.0 148.00 312.00 女国有1110.00 110.00 96.00 0.0 80.00 193.00 女集体1012.00 88.00 298.00 0.0 79.00 278.00 女国有1209.00 102.00 179.00 67.00 198.00 514.00 男集体1101.00 215.00 201.00 39.00 146.00 477.00 男集体例3-3English Norwegian Danish Dutch German French One En en een ein unTwo To to twee zwei deux Three Tre tre drie drei troisFour Fire fire vier vier quatre Five Fem fem vijf funf einqSix Seks seks zes sechs sixseven Sju syv zeven siebcn septEight Ate otte acht acht huitNine Ni ni negen neun neufTen Ti ti tien zehn dixSpanish Italian Polish Hungarian FinnishUno uno jeden egy yksiDos due dwa ketto kaksiTres tre trzy harom kolmecuatro quattro cztery negy neuaCinco cinque piec ot viisiSeix sei szesc hat kuusiSiete sette siedem het seitsemanOcho otto osiem nyolc kahdeksaunueve nove dziewiec kilenc yhdeksanDiez dieci dziesiec tiz kymmenen例3-4X1 食品支出(元/人)X5 交通和通讯支出(元/人)X2 衣着支出(元/人)X6 娱乐、教育和文化服务支出(元/人)X3 家庭设备、用品及服务支出(元/人)X7 居住支出(元/人)X4 医疗保健支出(元/人)X8 杂项商品和服务支出(元/人)X1 X2 X3 X4 X5 X6 X7 X8 辽宁1772.14 568.25 298.66 352.20 307.21 490.83 364.28 202.50 浙江2752.25 569.95 662.31 541.06 623.05 917.23 599.98 354.39 河南1386.76 460.99 312.97 280.78 246.24 407.26 547.19 188.52 甘肃1552.77 517.16 402.03 272.44 265.29 563.10 302.27 251.41 青海1711.03 458.57 334.91 307.24 297.72 495.34 274.48 306.45例3-5x1 人均粮食支出(元/人) x5 人均衣着支出(元/人)x2 人均副食支出(元/人)x6 人均日用杂品支出(元/人)x3 人均烟、酒、饮料支出(元/人)x7 人均水电燃料支出(元/人)4 人均其他副食支出(元/人)8 人均其他非商品支出(元/人)第四章数据例4-3x1人均食品支出(元/人)x5 人均交通和通信支出(元/人)x2 人均衣着支出(元/人)x6 人均文教娱乐用品及服务支出(元/人)x3 人均住房支出(元/人)x7 人均医疗保健支出(元/人)4 人均家庭设备及服务支出(元/人)其他商品及服务支出(元/人)例4-4x1工业增加值率(%) x5 工业成本费用利润率(%)x2 总资产贡献率(%)x6 全员劳动生产率(万元/人·年)x3 资产负债率(%)x7 产品销售率(%)x4 流动资产周转次数(次)例4-5x1人均粮食支出(元/人) x5 人均衣着支出(元/人)x2 人均副食支出(元/人)x6 人均日用杂品支出(元/人)x3 人均烟、酒、饮料支出(元/人)x7 人均水电燃料支出(元/人)x4 人均其他副食支出(元/人)人均其他非商品支出(元/人)习题4.6X1:0岁组死亡概率 X2:1岁组死亡概率 X4:55岁组死亡概率 X5:80岁组死亡概率第五章数据例5-3100固定资产原值实现值(%)100元固定资产原值实现利税(%)100元资金实现利税(%)100元工业总产值实现利税(%)100元销售收入实现利税(%)每吨标准煤实现工业产值(元)每千瓦时电力实现工业产值(元)全员劳动生产率(元/人.年)100元流动资金实现产值(元)北京(1)119.29 30.98 29.92 25.97 15.48 2178 3.41 21006 296.7天津(2)143.98 31.59 30.21 21.94 12.29 2852 4.29 20254 363.1 河北(3)94.8 17.2 17.95 18.14 9.37 1167 2.03 12607 322.2 山西(4)65.8 11.08 11.06 12.15 16.84 8.82 1.65 10166 284.7 内蒙(5)54.79 9.24 9.54 16.86 6.27 894 1.8 7564 225.4 辽宁(6)94.51 21.12 22.83 22.35 11.28 1416 2.36 13.386 311.7 吉林(7)80.49 13.36 13.76 16.6 7.14 1306 2.07 9400 274.1 黑龙江(8)75.86 15.82 16.67 20.86 10.37 1267 2.26 9830 267 上海(9)187.79 45.9 39.77 24.44 15.09 4346 4.11 31246 418.6 江苏(10)205.96 27.65 22.58 13.42 7.81 3202 4.69 23377 407.2 浙江(11)207.46 33.06 25.78 15.94 9.28 3811 4.19 22054 385.5 安徽(12)110.78 20.7 20.12 18.69 6.6 1468 2.23 12578 341.1 福建(13)122.76 22.52 19.93 18.34 8.35 2200 2.63 12164 301.2 江西(14)94.94 14.7 14.18 15.49 6.69 1669 2.24 10463 274.4 山东(15)117.58 21.93 20.89 18.65 9.1 1820 2.8 17829 331.1 河南(16)85.98 17.3 17.18 20.12 7.67 1306 1.89 11247 276.5 湖北(17)103.96 19.5 18.48 18.77 9.16 1829 2.75 15745 308.9 湖南(18)104.03 21.47 21.28 20.63 8.72 1272 1.98 13161 309 广东(19)136.44 23.64 20.83 17.33 7.85 2959 3.71 16259 334 广西(20)100.72 22.04 20.9 21.88 9.67 1732 2.13 12441 296.4 四川(21)84.73 14.35 14.17 16.93 7.96 1310 2.34 11703 242.5 贵州(22)59.05 14.48 14.35 24.53 8.09 1068 1.32 9710 206.7 云南(23)73.72 21.91 22.7 29.72 9.38 1447 1.94 12517 295.8 陕西(24)78.02 13.13 12.57 16.83 9.19 1731 2.08 11369 220.3甘肃(25)59.62 14.07 16.24 23.59 11.34 926 1.13 13084 246.8 青海(26)51.66 8.32 8.26 16.11 7.05 1055 1.31 9246 176.49 宁夏(27)52.95 8.25 8.82 15.57 6.58 834 1.12 10406 245.4 新疆(28)60.29 11.26 13.14 18.68 8.39 1041 2.9 10983 266例5-4厂家编号及指标固定资产利税率资金利税率销售收入利税率资金利润率固定资产产值率流动资金周转天数万元产值能耗全员劳动生产率1 琉璃河16.68 26.75 31.84 18.4 53.25 55 28.83 1.752 邯郸19.7 27.56 32.94 19.2 59.82 55 32.92 2.873 大同15.2 23.4 32.98 16.24 46.78 65 41.69 1.534 哈尔滨7.29 8.97 21.3 4.76 34.39 62 39.28 1.635 华新29.45 56.49 40.74 43.68 75.32 69 26.68 2.146 湘乡32.93 42.78 47.98 33.87 66.46 50 32.87 2.67 柳州25.39 37.82 36.76 27.56 68.18 63 35.79 2.438 峨嵋15.05 19.49 27.21 14.21 6.13 76 35.76 1.759 耀县19.82 28.78 33.41 20.17 59.25 71 39.13 1.8310 永登21.13 35.2 39.16 26.52 52.47 62 35.08 1.7311 工源16.75 28.72 29.62 19.23 55.76 58 30.08 1.5212 抚顺15.83 28.03 26.4 17.43 61.19 61 32.75 1.613 大连16.53 29.73 32.49 20.63 50.41 69 37.57 1.3114 江南22.24 54.59 31.05 37 67.95 63 32.33 1.5715 江油12.92 20.82 25.12 12.54 51.07 66 39.18 1.83第六章数据例6-3x1 x2 x3 x4 x5 x6北京830.8 38103630 30671.14 127.4 5925388 64413910天津549.74 40496103 34679 15.38 2045295 18253200石家庄331.33 11981505 10008.48 8.07 493429 10444919太原222.63 5183200 15248.11 2.43 333473 6601300呼和浩特97.81 2407794 4155.1 2 205779 2554496沈阳440.6 10643612 14635.74 7.3 810889 14229575长春313.05 15115270 10891.98 6.94 459709 8313564哈尔滨454.52 7215089 9517.8 24.99 763600 11536951上海1041.39 1.03E+08 63861 35.22 8992850 60546000南京391.67 25093816 14804.68 7.62 1364788 11336202 杭州263.67 32025226 16815.2 8.36 1503888 14664200 合肥160.18 5348605 4640.84 3.39 358694 3592488 福州205.43 12889573 8250.39 4.69 674522 8762245 南昌195.46 4149169 4454.45 3.62 314094 4828029 济南297.21 13185425 14354.4 6.6 761054 7583525 郑州249.72 9270494 7846.91 8.77 658737 10484859 武汉474.98 13344938 16610.34 13.58 804368 12855341 长沙205.83 5339304 10630.5 6.31 598930 7048500 广州493.32 40178324 28859.45 21.47 2747707 37273276 南宁167.99 2083763 5893.09 4.95 362435 4514961 海口76.05 2025643 3304.4 2.72 122541 2843664 成都386.23 9700976 28798.2 8.06 895752 14944197 贵阳165.27 3569419 5317.55 5.75 403855 3449487 昆明205.34 5809573 12337.86 7.07 601101 7085278 西安312.88 6386627 9392 12.21 648037 12105607 兰州175.54 5215490 5580.8 3.7 205660 4683830 西宁105.13 1148959 2037.15 1.24 84397 1749293 银川79.2 1464867 2127.17 1.65 122605 1930771 乌鲁木齐142.94 3110943 12754.02 3.94 409119 4203000 大连297.48 15468641 21081.47 6.6 1105405 13101986 宁波168.81 26302862 13797.38 4.8 1394162 10596339 厦门83.74 13201500 3054.82 2.83 701456 3971559 青岛329.96 25588695 30552.6 6.72 1201398 9084693 深圳122.39 52451037 6792.66 10.84 2908370 21994500 重庆753.92 15889928 32450.2 12.83 1615618 18965569 x7 x8 x9 x10 x11 x12北京434.15 10989365 15 17.3 8.56 44.94 天津174.5 3254148 18 7.99 7.23 17.45 石家庄86.74 1067432 18 7.23 8.28 21.56 太原74.55 945212 16 5.06 7.88 20.58 呼和浩特28.9 407963 18 3.81 8.92 26.58 沈阳101.7 1521548 15 9.32 6.7 28.36 长春89.7 1244167 15 11.87 7.03 18.75 哈尔滨168.83 2102165 14 12.75 6.34 18.51 上海281.51 7686511 19 14.57 12.92 19.11 南京87.91 1950742 16 9.06 12.13 136.72 杭州75.72 1867776 17 8.93 6.5 23.19 合肥37.88 526577 17 14.11 15.72 28.74 福州71.3 1073262 18 9.65 7.9 31.6南昌49.79 692717 17 7.37 7.67 23.98 济南78.38 1256160 19 7.77 10.62 19.54 郑州83.99 1137056 19 10.11 7.63 17.77 武汉136.08 1868350 17 6.87 4.16 8.34 长沙60.04 1019924 18 10.09 9.1 29.1 广州182.16 5247087 17 11.16 12.76 178.76 南宁50.79 668976 18 9.91 9.32 35.12 海口22.97 340392 20 5.09 7.07 15.79 成都124.03 1894496 17 8.95 10.17 25.59 贵阳54.53 664234 16 9.37 3.11 105.35 昆明73.34 1045469 15 15.33 4.49 23.33 西安113.73 1535896 15 7.32 4.48 8.82 兰州54.91 740661 15 10.33 6.3 11.22 西宁20.6 301364 17 11.47 4.92 14.2 银川29.12 393035 15 9.26 10.43 40.21 乌鲁木齐47.42 782873 19 22.89 6.49 20.53 大连82.13 1442215 14 13.79 6.24 40.21 宁波59.88 1418635 17 9.88 6.81 17.65 厦门54.78 1042111 20 15.5 8.15 26.44 青岛104.55 1603305 15 14.78 11.41 35.78 深圳104.98 3259900 21 114.91 47.29 177.62 重庆203.79 2535070 21 4.94 4.24 10.8第七章数据第九章数据例9-3第十章数据例10-2分行号不良贷款贷款余额应收贷款项目数固定资产投资额10.90 67.30 6.80 551.902 1.10 111.30 19.80 1690.903 4.80 173.00 7.70 1773.704 3.20 80.80 7.20 1014.5057.80 199.70 16.50 1963.206 2.70 16.20 2.20 1 2.207 1.60 107.40 10.70 1720.20812.50 185.40 27.10 1843.809 1.00 96.10 1.70 1055.9010 2.60 72.80 9.10 1464.30110.30 64.20 2.10 1142.7012 4.00 132.20 11.20 2376.70130.80 58.60 6.00 1422.8014 3.50 174.60 12.70 26117.101510.20 263.50 15.60 34146.7016 3.00 79.30 8.90 1522.90170.20 14.80 0.60 242.10180.40 73.50 5.90 1125.3019 1.00 24.70 5.00 413.4020 6.80 139.40 7.20 2864.302111.60 368.20 16.80 32163.9022 1.60 95.70 3.80 1044.5023 1.20 109.60 10.30 1467.90247.20 196.20 15.80 1639.7025 3.20 102.20 12.00 1097.10第十二章数据例12-1例12-2品牌内存容量/MB CPU/GHZ 单价/元方正联想惠普25651210242344200720010039第十三章数据例13-4第十四章数据例14-7城市天津北京锦州沈阳长春哈尔滨满洲里齐齐哈尔牡丹江吉林天津0北京137 0锦州499 486 0沈阳741 728 242 0长春1046 1033 547 305 01288 1275 789 547 242 0哈尔滨2326 2210 1724 1482 1177 935 0满洲里1451 1335 849 760 530 288 693 0齐齐哈尔牡丹1746 1630 1144 902 597 355 1290 643 0江吉林1187 1174 688 446 128 275 1210 563 630 0。
多元统计分析整理版.doc

1、主成分分析的目的是什么?主成分分析是考虑各指标间的相互关系,利用降维的思想把多个指标转换成较少的几个相互独立的、能够解释原始变量绝大部分信息的综合指标,从而使进一步研究变得简单的一种统计方法。
它的目的是希望用较少的变量去解释原始资料的大部分变异,即数据压缩,数据的解释。
常被用来寻找判断事物或现象的综合指标,并对综合指标所包含的信息进行适当的解释。
2、主成分分析基本思想?主成分分析就是设法将原来指标重新组合成一组新的互相无关的几个综合指标来代替原来指标。
同时根据实际需要从中选取几个较少的综合指标尽可能多地反映原来的指标的信息。
● 设p 个原始变量为 ,新的变量(即主成分)为 ,主成分和原始变量之间的关系表示为?3、在进行主成分分析时是否要对原来的p 个指标进行标准化?SPSS 软件是否能对数据自动进行标准化?标准化的目的是什么?需要进行标准化,因为因素之间的数值或者数量级存在较大差距,导致较小的数被淹没,导致主成分偏差较大,所以要进行数据标准化; 进行主成分分析时SPSS 可以自动进行标准化;标准化的目的是消除变量在水平和量纲上的差异造成的影响。
求解步骤⏹ 对原来的p 个指标进行标准化,以消除变量在水平和量纲上的影响 ⏹ 根据标准化后的数据矩阵求出相关系数矩阵 ⏹ 求出协方差矩阵的特征根和特征向量⏹ 确定主成分,并对各主成分所包含的信息给予适当的解释版本二:根据我国31个省市自治区2006年的6项主要经济指标数据,表二至表五,是SPSS 的输出表,试解释从每张表可以得出哪些结论,进行主成分分析,找出主成分并进行适当的解释:(下面是SPSS 的输出结果,请根据结果写出结论) 表一:数据输入界面p 21p x x x ,,, 21p ,21p y y y ,,, 21表二:数据输出界面a)此表为相关系数矩阵,表示的是各个变量之间的相关关系,说明变量之间存在较强的相关系数,适合做主成分分析。
观察各相关系数,若相关矩阵中的大部分相关系数小于0.3,则不适合作因子分析。
多元统计分析课程设报告计参考Word

XXXX课程设计任务书课程名称多元统计分析课题判别分析与因子分析专业班级学生姓名学号指导老师审批任务书下达日期任务完成日期目录课题一判别分析摘要 (1)一、指标和数据 (1)二、聚类分析的实施 (1)三、判别分析的实施 (2)四、结果分析 (5)课题二因子分析摘要 (6)一、数据 (6)二、因子分析的实施 (6)三、结果分析 (10)总结 (11)参考文献 (11)评分标准 (12)附表 (13)课题一判别分析摘要聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。
而判别分析是根据表明事物特点的变量值和它们所属的类,求出判别函数。
根据判别函数对未知所属类别的事物进行分类的一种分析方法。
核心是考察类别之间的差异。
本课题正是基于多元统计分析中聚类分析和判别分析的方法,以《各地区按行业分城镇单位就业人员平均工资》的调查数据为对象(预留出待判样本),借助Spss统计软件用聚类分析进行分类,并以分好的类别为依据对待判样本进行判别分类以及对已分类样本进行回判分析。
一、指标和数据按要求于国家统计局网站查找变量数大于等于10,样本数大于等于20的合适数据并整理。
得到整理后的《各地区按行业分城镇单位就业人员平均工资》(见附表一)。
其体系共有31个地区,19项指标。
具体指标x1:农、林、牧、渔业就业人员平均工资,简写“农、林、牧、渔业”(以下具以简写形式省略“就业人员平均工资”);x2:采矿业;x3:制造业;x4:电力、燃气及水的生产和供应;x5:建筑业;x6:交通运输、仓储和邮政业;x7:信息传输、计算机服务和软件业;x8:批发和零售业;x9:住宿和餐饮业;x10:金融业;x11:房地产业;x12:租赁和商务服务业;x13:科学研究、技术服务和地质勘查业;x14:水利、环境和公共设施管理业;x15:居民服务和其他服务业;x16:教育;x17:卫生、社会保障和社会福利业;x18:文化、体育和娱乐业;x19:公共管理和社会组织。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、主成分分析的目的是什么?主成分分析是考虑各指标间的相互关系,利用降维的思想把多个指标转换成较少的几个相互独立的、能够解释原始变量绝大局部信息的综合指标,从而使进一步研究变得简单的一种统计方法。
它的目的是希望用较少的变量去解释原始资料的大局部变异,即数据压缩,数据的解释。
常被用来寻找判断事物或现象的综合指标,并对综合指标所包含的信息进展适当的解释。
2、主成分分析根本思想?主成分分析就是设法将原来指标重新组合成一组新的互相无关的几个综合指标来代替原来指标。
同时根据实际需要从中选取几个较少的综合指标尽可能多地反映原来的指标的信息。
● 设p 个原始变量为 ,新的变量(即主成分)为 , 主成分和原始变量之间的关系表示为?3、在进展主成分分析时是否要对原来的p 个指标进展标准化?SPSS 软件是否能对数据自动进展标准化?标准化的目的是什么?需要进展标准化,因为因素之间的数值或者数量级存在较大差距,导致较小的数被淹没,导致主成分偏差较大,所以要进展数据标准化; 进展主成分分析时SPSS 可以自动进展标准化;标准化的目的是消除变量在水平和量纲上的差异造成的影响。
求解步骤⏹ 对原来的p 个指标进展标准化,以消除变量在水平和量纲上的影响 ⏹ 根据标准化后的数据矩阵求出相关系数矩阵 ⏹ 求出协方差矩阵的特征根和特征向量⏹ 确定主成分,并对各主成分所包含的信息给予适当的解释版本二:根据我国31个省市自治区2006年的6项主要经济指标数据,表二至表五,是SPSS 的输出表,试解释从每X 表可以得出哪些结论,进展主成分分析,找出主成分并进展适当的解释:〔下面是SPSS 的输出结果,请根据结果写出结论〕 表一:数据输入界面p 21p x x x ,,, 2121p y y y ,,, 21表二:数据输出界面a〕此表为相关系数矩阵,表示的是各个变量之间的相关关系,说明变量之间存在较强的相关系数,适合做主成分分析。
观察各相关系数,假如相关矩阵中的大局部相关系数小于,如此不适合作因子分析。
表三为各成分的总解释方差表。
ponent为各成分的序号;initial Eigenvalues是初始特征值,total是各成分的特征值,% of variance是各成分的方差占总方差的百分比〔贡献率〕。
Cumulative%是累计贡献率,明确前几个成分可以解释总方差的百分数。
Extraction sums 是因子提取结果。
一般来说,当特征根需大于1,主成分的累计方差贡献率达到80%以上的前几个主成分,都可以选作最后的主成分。
由表可知,第一个主成分的特征根为,方差贡献率为66.052%,这表示第一个主成分解释了原始6个变量66.052%的信息,可以看出前两个成分所解释的方差占总方差的95.57%,仅丢失了4.43%的信息。
因此最后结果是提取两个主成分。
在extraction sums of squared loadings一栏,自动提取了前两个公因子,因为前两个公因子就可以解释总方差的绝大局部95.6%。
表四是表示各成分特征值的碎石图。
可以看出因子1与因子2,以与因子2与因子3之间的特征值之差值比拟大。
而因子3、4、5之间的特征值差值都比拟小,可以初步得出保存两个因子将能概括绝大局部信息。
明显的拐点为3,因此提取2个因子比拟适宜。
证实了表三中的结果。
碎石图(Scree Plot),从碎石图可以看到6个主轴长度变化的趋势。
实践中,通常选择碎石图中变化趋势出现拐点的前几个主成分作为原先变量的代表,该例中选择前两个主成分即可。
表五是初始提取的成分矩阵,它显示了原始变量与各主成分之间的相关系数,表中的每一列表示一个主成分作为原来变量线性组合的系数,也就是主成分分析模型中的系数a ij 。
比如,第一主成分所在列的系数表示第1个主成分和原来的第一个变量(人均GDP)之间的线性相关系数。
这个系数越大,说明主成分对该变量的代表性就越大。
第一主成分〔ponent 1〕对财政收入,固定资产投资,社会消费品零售总额有绝对值较大的相关系数;第二主成分〔ponent 2〕对人均gdp ,年末总人口,居民消费水平有绝对值较大的相关系数。
可以分别对其进展命名。
版本一:根据我国31个省市自治区2006年的6项主要经济指标数据,进展因子分析,对因子进展命名和解释,并计算因子得分和排序。
表一数据输入界面:⎩⎨⎧-+--+=+++++=65432126543211263.0721.0728.0351.0055.0725.0950.0674.0633.0896.0976.0670.0x x x x x x y x x x x x x y表二因子分析SPSS输出界面a〕KMO统计量为,接近,明确6个变量之间有较强的相关关系。
适合作因子分析。
Bartlett球度检验统计量为。
检验的P值接近0,拒绝原假设,认为相关系数与单位阵有显著差异。
可以因子分析。
表三因子分析SPSS输出界面b〕表三为公因子提取前和提取后的共同度表,initial列提取因子前的各变量的共同度;extraction 列是按特定条件〔如特征值>1〕提取公因子时的共同度,表中的共同度都很高,说明提取的成分能很好的描述这些变量。
所有变量的共同度量都在80%以上,因此,提取出的公因子对原始变量的解释能力应该是很强的。
变量x i的信息能够被k个公因子解释的程度表四因子分析SPSS输出界面c〕表四为各成分的总解释方差。
ponent表示按特征值大小排序的因子编号。
Initial下分别给出了相关系数矩阵的特征值、方差贡献率和累计方差贡献率。
Extraction是所提取的公因子未经旋转情况下的特征值,方差贡献了和累计方差贡献率。
Rotation项下是旋转后的。
“Rotation Sums of Squared Loadings〞局部是因子旋转后对原始变量方差的解释情况。
旋转后的累计方差没有改变,只是两个因子所解释的原始变量的方差发生了一些变化。
95.57%明确提取的两个公共因子的方差可以解释总方差的95.57%。
第j个公因子对变量x i的提供的方差总和,反映第j个公因子的相对重要程度旋转后成分矩阵。
第一个因子与年末总人口、固定资产投资、社会消费品零售总额、财政收入这几个载荷系数较大,主要解释了这几个变量。
从实际意义上看,可以把因子1姑且命名为“经济水平〞因子。
而第二个因子与人均GDP、居民消水平这两个变量的载荷系数较大,主要解释了这两个变量,从实际意义看,可以将因子2姑且命名为“消费水平〞因子表五是因子得分系数矩阵。
根据因子得分和原始变量的标准化值可计算每个观测量的各因子的分数。
4、因子分析根本思想?因子分析是利用降维的思想,由研究原始变量相关矩阵内部的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。
因子分析的根本思想是根据相关性的大小将原始变量分组,使得组内的变量之间相关性较高,而不同组的变量之间相关性较低。
每组变量代表一个根本结构,并用一个不可观测的综合变量表示,这个根本结构就称为公共因子。
对于所研究的某一具体问题,原始变量可以分解为两局部之和的形式,一局部是少数几个不可测的所谓公共因子的线性函数,另一局部是与公共因子无关的特殊因子。
设p 个原始变量为 ,要寻找的m 个因子(m<k )为 ,因子和原始变量之间的关系表达式为? mm km k k m m m m e f a f a f a x e f a f a f a x e f a f a f a x k +++=+++=+++=2211222221211121211112系数a ij 为第个i 变量与第k 个因子之间的线性相关系数,反映变量与因子之间的相关程度,也称为载荷(loading)。
由于因子出现在每个原始变量与因子的线性组合中,因此也称为公因子。
ε为特殊因子,代表公因子以外的因素影响 5、因子分析的目的是什么?k 21kx x x ,,, 21m 21mf f f ,,, 21因子分析是从多个变量指标中选择出少数几个综合变量指标,以较少的几个因子反映原始资料的大局部信息的一种降维的多元统计方法。
求解步骤1) 对原始数据标准化2) 建立相关系数矩阵R 〔因子提取〕 3) 求R 的单位特征根λ与特征向量U ; 4) 因子旋转求因子载荷矩阵A ; 5) 写出因子模型X=AF+E 6〕建立因子得分矩阵P7〕写出因子得分模型F=P ’X(因子提取的方法:主成分法、不加权最小平方法、加权最小平方法、最大似然法、主轴因子法;旋转方法为:方差最大正交旋转、四次方最大正交旋转、平方最大正交旋转、斜交旋转、Promax :该方法在方差最大正交旋转的根底上进展斜交旋转) 6、什么是变量共同度?写出变量共同度的表达式。
变量x i 的信息能够被k 个公因子解释的程度,用 k 个公因子对第i 个变量x i 的方差贡献率表示∑==+++=mj ij imi i i a a a a D 1222221)21(122k j a h pi iji,,, ==∑=7、什么是公共因子方差贡献率?写出公共因子方差贡献率表达式。
第j 个公因子对变量x i 的提供的方差总和,反映第j 个公因子的相对重要程度)21(122p i a g kj ij j,,, ==∑=8、因子分析中KMO 检验主要检验什么? KMO 越接近1,变量间的相关性越强KMO 在以上,说明该问题适合做因子分析。
KMO 统计量在以上时,因子分析效果较好; KMO 统计量在以下时,因子分析效果很差KMO 〔Kaiser-Meyer-Olkin)检验统计量是用于比拟原始变量间简单相关系数和偏相关系数的指标。
当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO 值接近1,KMO 越接近1,变量间的相关性越强。
当所有变量间的简单相关系数平方和接近0时,KMO 值接近0.KMO 值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。
Kaiser 给出了常用的kmo 度量标准:0.9以上表示非常适合;0.8表示适合;0.7表示一般;0.6表示不太适合;0.5以下表示极不适合。
Bartlett 球度检验:以变量的相关系数矩阵为根底,假设相关系数矩阵是单位阵(对角线元素不为0,非对角线元素均为0)。
如果相关矩阵是单位阵,如此各变量是独立的,无法进展因子分析。
9、因子分析中公因子个数确定的依据是什么?用公因子方差贡献率提取:一般累计方差贡献率达到80%以上的前几个因子可以作为最后的公因子用特征根提取:一般要求因子对应的特征根要大于1,因为特征根小于1说明该公因子的解释力度太弱,还不如使用原始变量的解释力度大碎石图中变化趋势出现拐点的前几个主成分10、因子分析中因子旋转(factor rotation)的目的是什么?什么是因子得分(factor score)? 因子旋转的目的使得因子载荷系数尽可能两极分化,使因子载荷系数向±1或0靠近,使得某一个变量值在某一个因子上的载荷系数大,从而更清楚地看出各因子与原始变量的相关性大小,使因子的含义更加清楚,以便于对因子的命名和解释。