GP 常用数据库命令
gpconfig参数

gpconfig参数gpconfig参数是Greenplum数据库中用于配置和管理数据库的一组参数。
这些参数可以通过gpconfig命令进行设置和修改。
本文将介绍一些常用的gpconfig参数及其作用。
1. gp_vmem_protect_limit该参数用于限制Greenplum数据库的虚拟内存使用量。
通过设置该参数,可以避免数据库使用过多的虚拟内存导致系统崩溃。
可以根据实际情况调整该参数的值,以平衡内存使用和系统稳定性。
2. gp_resqueue_memory_policy该参数用于设置Greenplum数据库中资源队列的内存分配策略。
资源队列是用于管理并发查询的一种机制,通过设置该参数,可以控制不同用户或组的查询在内存中的优先级。
可以根据实际需求,设置不同的内存分配策略,以实现资源的合理分配和查询的优化。
3. gp_max_connections该参数用于设置Greenplum数据库的最大连接数。
连接数是指同时连接到数据库的客户端数量。
通过设置该参数,可以限制数据库的并发连接数,以避免系统资源过度消耗和性能下降。
可以根据系统的硬件配置和负载情况,适当调整该参数的值。
4. gp_workfile_limit该参数用于设置Greenplum数据库中工作文件的最大限制。
工作文件是在查询执行过程中临时存储中间结果的文件。
通过设置该参数,可以限制工作文件的大小,以避免磁盘空间的过度消耗和查询的性能下降。
可以根据系统的磁盘容量和查询的需求,调整该参数的值。
5. gp_autostats_mode该参数用于控制Greenplum数据库中自动统计信息的收集方式。
统计信息是用于优化查询计划的一种关键信息。
通过设置该参数,可以指定统计信息的收集方式,如自动收集、手动收集或禁止收集。
可以根据数据库的特点和查询的需求,选择合适的统计信息收集方式。
6. gp_enable_gpperfmon该参数用于启用或禁用Greenplum数据库中的性能监控功能。
gp数据库循环语句

gp数据库循环语句GP数据库是一种关系型数据库管理系统,它可以通过循环语句来实现对数据库中数据的逐行处理。
下面列举了十个基于GP数据库的循环语句的示例。
1. 使用FOR循环语句遍历表中的所有记录```sqlFOR row IN SELECT * FROM table_name LOOP-- 处理每一行数据的逻辑-- 可以使用row.column_name来访问每一列的值END LOOP;```2. 使用WHILE循环语句实现条件控制的循环```sqlDECLAREcounter integer := 0;BEGINWHILE counter < 10 LOOP-- 处理逻辑counter := counter + 1;END LOOP;END;```3. 使用CURSOR循环语句遍历游标中的结果集```sqlDECLAREcursor_name CURSOR FOR SELECT * FROM table_name; row record;BEGINOPEN cursor_name;LOOPFETCH cursor_name INTO row;EXIT WHEN NOT FOUND;-- 处理每一行数据的逻辑-- 可以使用row.column_name来访问每一列的值END LOOP;CLOSE cursor_name;END;```4. 使用RECORD类型和FOREACH循环语句遍历表中的所有记录```sqlDECLARErow RECORD;BEGINFOREACH row IN ARRAY (SELECT * FROM table_name) LOOP-- 处理每一行数据的逻辑-- 可以使用row.column_name来访问每一列的值END LOOP;END;```5. 使用LOOP语句和EXIT条件语句实现循环的控制```sqlDECLAREcounter integer := 0;BEGINLOOP-- 处理逻辑counter := counter + 1;EXIT WHEN counter >= 10;END LOOP;END;```6. 使用FOR循环语句和RAISE NOTICE语句输出循环过程中的信息```sqlFOR i IN 1..10 LOOPRAISE NOTICE '当前循环次数:%', i;-- 处理逻辑END LOOP;```7. 使用FOR循环语句和CONTINUE条件语句实现循环的跳过```sqlFOR i IN 1..10 LOOPIF i % 2 = 0 THENCONTINUE;END IF;-- 处理逻辑END LOOP;```8. 使用FOR循环语句和EXIT条件语句实现循环的中止```sqlFOR i IN 1..10 LOOPIF i = 5 THENEXIT;END IF;-- 处理逻辑END LOOP;```9. 使用LOOP语句和RETURN NEXT语句返回逐行处理的结果集```sqlCREATE OR REPLACE FUNCTION function_name() RETURNS SETOF table_name AS $$DECLARErow record;BEGINFOR row IN SELECT * FROM table_name LOOP-- 处理每一行数据的逻辑-- 可以使用row.column_name来访问每一列的值RETURN NEXT row;END LOOP;END;$$ LANGUAGE plpgsql;```10. 使用FOR循环语句和UPDATE语句批量更新表中的数据```sqlFOR row IN SELECT * FROM table_name LOOPUPDATE table_name SET column_name = new_value WHERE id = row.id;END LOOP;```以上是十个基于GP数据库的循环语句的示例,可以根据实际需求进行灵活运用。
gp查看建表语句

gp查看建表语句
GP(Greenplum)是一种高度并行化的关系数据库管理系统,基于开源的PostgreSQL开发而来。
要查看建表语句,可以使用以下sql语句:
```
SELECT ddl
FROM gp_dist_random('pg_class')
WHERE relname = 'table_name';
```
其中,将'table_name'替换为要查看建表语句的具体表名。
这条SQL语句将返回指定表的建表语句。
如果想要拓展的话,可以了解以下GP数据库的特点:
1.高度并行化:GP是为处理大规模数据而设计的,它采用了共享-nothing架构,可以在多个节点上并行执行查询,从而提高数据库的性能和吞吐量。
2.列式存储:GP将数据按列存储,而不是按行存储,这种存储方
式在分析型查询中往往比行存储更高效。
3.分布式存储:GP将表数据划分为多个分片,并分布到不同的节
点上存储,这样可以将数据负载平均分布到不同的节点上,提高系统
的可扩展性和负载均衡性。
4.数据压缩:GP支持对数据进行压缩,可以减少存储空间的占用,并提高IO性能。
5.并行执行计划:GP使用并行执行计划来对查询进行优化,通过
将查询任务分配给多个节点并行执行,从而提高查询的响应速度。
总的来说,GP是一种适用于数据仓库和大规模数据分析的关系数
据库管理系统,它的特点包括高度并行化、列式存储、分布式存储、
数据压缩和并行执行计划等。
人大金仓数据库常用命令

人大金仓数据库常用命令人大金仓数据库是一款功能强大的数据库管理系统,常用的命令有以下几种:1. 创建数据库:CREATE DATABASE database_name;在人大金仓数据库中,可以使用CREATE DATABASE命令来创建一个新的数据库。
只需指定数据库名称即可。
2. 创建表:CREATE TABLE table_name (column1 datatype, column2 datatype, ...);在人大金仓数据库中,可以使用CREATE TABLE命令来创建一个新的表。
需要指定表名以及表中的列名和数据类型。
3. 插入数据:INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);在人大金仓数据库中,可以使用INSERT INTO命令来向表中插入数据。
需要指定表名以及要插入的列和对应的值。
4. 查询数据:SELECT column1, column2, ... FROM table_name WHERE condition;在人大金仓数据库中,可以使用SELECT命令来查询数据。
可以指定要查询的列和表名,并可以使用WHERE子句来添加条件。
5. 更新数据:UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;在人大金仓数据库中,可以使用UPDATE命令来更新数据。
需要指定要更新的表和列,并可以使用WHERE子句来添加条件。
6. 删除数据:DELETE FROM table_name WHERE condition;在人大金仓数据库中,可以使用DELETE FROM命令来删除数据。
需要指定要删除的表,并可以使用WHERE子句来添加条件。
7. 创建索引:CREATE INDEX index_name ON table_name (column1, column2, ...);在人大金仓数据库中,可以使用CREATE INDEX命令来创建索引。
GP 常用数据库命令
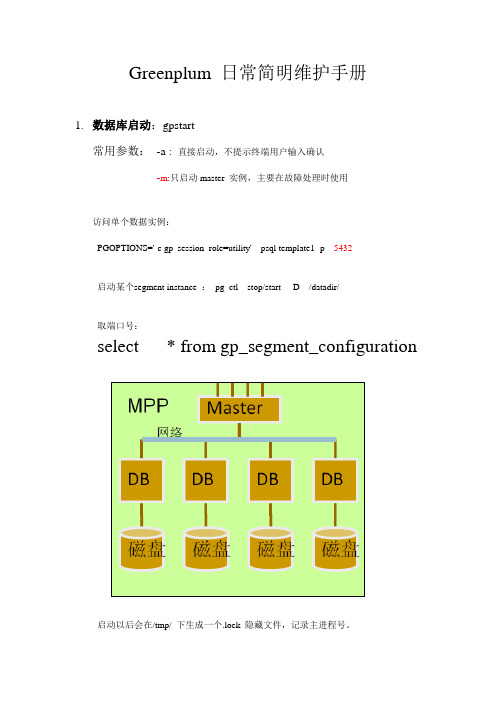
Greenplum 日常简明维护手册1.数据库启动:gpstart常用参数:-a : 直接启动,不提示终端用户输入确认-m:只启动master 实例,主要在故障处理时使用访问单个数据实例:PGOPTIONS='-c gp_session_role=utility' psql template1 -p 5432启动某个segment instance :pg_ctl stop/start -D /datadir/取端口号:select * from gp_segment_configuration 启动以后会在/tmp/ 下生成一个.lock 隐藏文件,记录主进程号。
2.数据库停止:gpstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止master 实例,与gpstart –m 对应使用-f:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
连接数,重启3.查看实例配置和状态select * from gp_segment_configuration order by content ;select * from pg_filespace_entry ;主要字段说明:Content:该字段相等的两个实例,是一对P(primary instance)和M(mirror Instance)Isprimary:实例是否作为primary instance 运行Valid:实例是否有效,如处于false 状态,则说明该实例已经down 掉。
Port:实例运行的端口Datadir:实例对应的数据目录4.gpstate :显示Greenplum数据库运行状态,详细配置等信息常用可选参数:-c:primary instance 和mirror instance 的对应关系-m:只列出mirror 实例的状态和配置信息-f:显示standby master 的详细信息该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
GP日常维护手册-常用命令

Greenp lum 日常维护手册1.数据库启动:g pstar t常用可选参数:-a : 直接启动,不提示终端用户输入ye s确认-m:只启动mas ter 实例,主要在故障处理时使用2.数据库停止:g pstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止mas t er 实例,与gpsta rt –m 对应使用-M fast:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
-f:强制停止数据库-r:重启数据库3.查看实例配置和状态select * from gp_con figur ation orderby 1 ;select * from gp_con figur ation_hist ory orderby 1 ;主要字段说明:Conten t:该字段相等的两个实例,是一对P(primar y instan ce)和M(mirrorInstan ce)Isprim ary:实例是否作为p rimary instan ce 运行V alid:实例是否有效,如处于fal se 状态,则说明该实例已经dow n 掉。
Port:实例运行的端口Datadi r:实例对应的数据目录注 4.0后,实例配置的数据表:gp_seg ment_confi gurat ion 、pg_fil espac e_ent ry、gp_fau lt_st rateg y;其它常用的系统表:pg_cla ss,pg_att ribute,pg_database,pg_tab l es……可以用tab来匹配表名;4.gpstat e :显示Gree n plum数据库运行状态,详细配置等信息常用可选参数:-c:primary instan ce 和mirror instan ce 的对应关系-m:只列出mir ror 实例的状态和配置信息-f:显示stan dby master的详细信息-s:查看详细状态,如在同步,可显示数据同步完成百分比--versio n,查看数据库v ersio n(也可使用pg_cont roldata查看数据库版本和p ostg r esql版本)该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
postgresql常用命令
postgresql常⽤命令(1)⽤户实⽤程序:createdb 创建⼀个新的PostgreSQL的数据库(和SQL语句:CREATE DATABASE 相同)createuser 创建⼀个新的PostgreSQL的⽤户(和SQL语句:CREATE USER 相同)dropdb 删除数据库dropuser 删除⽤户pg_dump 将PostgreSQL数据库导出到⼀个脚本⽂件pg_dumpall 将所有的PostgreSQL数据库导出到⼀个脚本⽂件pg_restore 从⼀个由pg_dump或pg_dumpall程序导出的脚本⽂件中恢复PostgreSQL数据库psql ⼀个基于命令⾏的PostgreSQL交互式客户端程序vacuumdb 清理和分析⼀个PostgreSQL数据库,它是客户端程序psql环境下SQL语句VACUUM的shell脚本封装,⼆者功能完全相同(2)系统实⽤程序1. pg_ctl 启动、停⽌、重启PostgreSQL服务(⽐如:pg_ctl start 启动PostgreSQL服务,它和service postgresql start相同)2. pg_controldata 显⽰PostgreSQL服务的内部控制信息3. psql 切换到PostgreSQL预定义的数据库超级⽤户postgres,启⽤客户端程序psql,并连接到⾃⼰想要的数据库,⽐如说:psql template1出现以下界⾯,说明已经进⼊到想要的数据库,可以进⾏想要的操作了。
template1=#(3).在数据库中的⼀些命令:template1=# \l 查看系统中现存的数据库template1=# \q 退出客户端程序psqltemplate1=# \c 从⼀个数据库中转到另⼀个数据库中,如template1=# \c sales 从template1转到salestemplate1=# \dt 查看表template1=# \d 查看表结构template1=# \di 查看索引[基本数据库操作]========================1. *创建数据库: create database [数据库名];2. *查看数据库列表: \d3. *删除数据库: . drop database [数据库名];创建表: create table ([字段名1] [类型1] <references 关联表名(关联的字段名)>;,[字段名2] [类型2],......<,primary key (字段名m,字段名n,...)>;);*查看表名列表: \d*查看某个表的状况: \d [表名]*重命名⼀个表: alter table [表名A] rename to [表名B];*删除⼀个表: drop table [表名]; ========================================[表内基本操作]==========================*在已有的表⾥添加字段: alter table [表名] add column [字段名] [类型];*删除表中的字段: alter table [表名] drop column [字段名];*重命名⼀个字段: alter table [表名] rename column [字段名A] to [字段名B];*给⼀个字段设置缺省值: alter table [表名] alter column [字段名] set default [新的默认值];*去除缺省值: alter table [表名] alter column [字段名] drop default;在表中插⼊数据: insert into 表名 ([字段名m],[字段名n],......) values ([列m的值],[列n的值],......);修改表中的某⾏某列的数据: update [表名] set [⽬标字段名]=[⽬标值] where [该⾏特征];删除表中某⾏数据: delete from [表名] where [该⾏特征];delete from [表名];--删空整个表 ========================== ==========================(4).PostgreSQL⽤户认证PostgreSQL数据⽬录中的pg_hba.conf的作⽤就是⽤户认证,可以在/usr/local/pgsql/data中找到。
PG数据库常用命令
PG数据库常⽤命令查看帮助命令DB=# help --总的帮助DB=# \h --SQL commands级的帮助DB=# \? --psql commands级的帮助按列显⽰,类似MySQL的\GDB=# \xExpanded display is on.查看DB安装⽬录(最好root⽤户执⾏)find / -name initdb查看有多少DB实例在运⾏(最好root⽤户执⾏)find / -name postgresql.conf查看DB版本cat $PGDATA/PG_VERSIONpsql --versionDB=# show server_version;DB=# select version();查看DB实例运⾏状态pg_ctl status查看所有数据库psql –l --查看5432端⼝下⾯有多少个DBpsql –p XX –l --查看XX端⼝下⾯有多少个DBDB=# \lDB=# select * from pg_database;创建数据库createdb database_nameDB=# \h create database --创建数据库的帮助命令DB=# create database database_name进⼊某个数据库psql –d dbnameDB=# \c dbname查看当前数据库DB=# \cDB=# select current_database();查看数据库⽂件⽬录DB=# show data_directory;cat $PGDATA/postgresql.conf |grep data_directorycat /etc/init.d/postgresql|grep PGDATA=lsof |grep 5432得出第⼆列的PID号再ps –ef|grep PID查看表空间select * from pg_tablespace;查看语⾔select * from pg_language;查询所有schema,必须到指定的数据库下执⾏select * from information_schema.schemata;SELECT nspname FROM pg_namespace;\dnS查看表名DB=# \dt --只能查看到当前数据库下public的表名DB=# SELECT tablename FROM pg_tables WHERE tablename NOT LIKE 'pg%' AND tablename NOT LIKE 'sql_%' ORDER BY tablename;DB=# SELECT * FROM information_schema.tables WHERE table_name='ff_v3_ff_basic_af';查看表结构查看表结构DB=# \d tablenameDB=# select * from information_schema.columns where table_schema='public' and table_name='XX';查看索引DB=# \diDB=# select * from pg_index;查看视图DB=# \dvDB=# select * from pg_views where schemaname = 'public';DB=# select * from information_schema.views where table_schema = 'public';查看触发器DB=# select * from information_schema.triggers;查看序列DB=# select * from information_schema.sequences where sequence_schema = 'public';查看约束DB=# select * from pg_constraint where contype = 'p'DB=# select a.relname as table_name,b.conname as constraint_name,b.contype as constraint_type from pg_class a,pg_constraint b where a.oid = b.conrelid and a.relname = 'cc';查看XX数据库的⼤⼩SELECT pg_size_pretty(pg_database_size('XX')) As fulldbsize;查看所有数据库的⼤⼩select pg_database.datname, pg_size_pretty (pg_database_size(pg_database.datname)) AS size from pg_database;查看各数据库数据创建时间:select datname,(pg_stat_file(format('%s/%s/PG_VERSION',case when spcname='pg_default' then 'base' else'pg_tblspc/'||t2.oid||'/PG_11_201804061/' end, t1.oid))).* from pg_database t1,pg_tablespace t2 where t1.dattablespace=t2.oid;按占空间⼤⼩,顺序查看所有表的⼤⼩select relname, pg_size_pretty(pg_relation_size(relid)) from pg_stat_user_tables where schemaname='public' order bypg_relation_size(relid) desc;按占空间⼤⼩,顺序查看索引⼤⼩select indexrelname, pg_size_pretty(pg_relation_size(relid)) from pg_stat_user_indexes where schemaname='public' order bypg_relation_size(relid) desc;查看参数⽂件DB=# show config_file;DB=# show hba_file;DB=# show ident_file;查看当前会话的参数值DB=# show all;查看参数值select * from pg_file_settings查看某个参数值,⽐如参数work_memDB=# show work_mem修改某个参数值,⽐如参数work_memDB=# alter system set work_mem='8MB'--使⽤alter system命令将修改postgresql.auto.conf⽂件,⽽不是postgresql.conf,这样可以很好的保护postgresql.conf⽂件,加⼊你使⽤很多alter system命令后搞的⼀团糟,那么你只需要删除postgresql.auto.conf,再执⾏pg_ctl reload加载postgresql.conf⽂件即可实现参数的重新加载。
gp简易维护
Greenplum 日常简明维护手册1. 数据库启动:gpstart 提示选择Y…常用参数: -a : 直接启动,不提示终端用户输入确认-q : 不希望屏幕输出-m:只启动master 实例,主要在故障处理时使用-R:只启动数据库在受限模式,禁止非超级用户登陆.-y:启动数据,但不启动standby启动完毕可使用gpstate查看数据库状态2. 数据库停止:gpstop 提示选择Y…常用参数:-a:直接停止,不提示终端用户输入确认-m:只停止master 实例,与gpstart –m 对应使用-f(-m faster):停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
关闭完毕后可使用gpssh控制所有服务器查看postgres进程是否已经都不存在,下面命令显示为1则表明数据库所有进程已经关闭完毕.gpadmin@dsszbyz-dw6-mst01:~> gpssh -f host_all=> ps -ef|grep postgres |wc -l[ sdw1] 1[sdw2] 1[ mdw] 1[ sdw3] 1[ smdw] 1[ sdw4] 1[ ftp1] 1=>exit3. 登陆数据库:psql登录数据库方式:psql –d 数据库名–u 用户名可以先使用psql -d template1登陆默认实例,然后使用select * from pg_database;查看已经安装的数据库名,然后登陆相应数据库。
退出psql 使用\q.使用应用模式访问单个数据实例():PGOPTIONS='-c gp_session_role=utility' psql template1 -p 54324. 查看实例配置和状态:gpstate常用参数:-c:显示primary instance和mirror instance的对应关系-m:显示mirror的状态-f:显示standby的状态(是否配置,是否同步)-e:显示错误节点的详细信息。
postgreSQL命令大全(更新中)
postgreSQL命令⼤全(更新中)1.PostgreSQL索引的建⽴;2.PostgreSQL9中索引的原理和效率查询3.删除索引DROP INDEX index;index是要删除的索引名注意:⽆法删除DBMS为主键约束和唯⼀约束⾃动创建的索引4.PostgreSQL命令⾏向表中插⼊多组数据SPJ=# insert into S(sno,sname,status,city) values('S1','精益',20,'天津'),SPJ-# ('S2','盛锡',10,'北京'),SPJ-# ('S3','东⽅红',30,'北京'),SPJ-# ('S4','丰泰盛',20,'天津'),SPJ-# ('S5','为民',30,'上海');INSERT05SPJ=# select*SPJ-# from s;sno | sname | status | city-----+--------+--------+------S1 |精益|20|天津S2 |盛锡|10|北京S3 |东⽅红|30|北京S4 |丰泰盛|20|天津S5 |为民|30|上海(5⾏记录)5.psql: 致命错误: ⽤户 "ASUS" Password 认证失败如果发⽣这样的错误,意味着你的命令⾏少写了⼀个 -Upsql -h localhost -U postgres -d "student" < "d:\student.sql"6.数据库表有NOT NULL,DEFAULT,CHECK,UNIQUE,PRIMARY KEY,FOREIGN KEY六种约束。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Greenplum 日常简明维护手册1.数据库启动:gpstart常用参数:-a : 直接启动,不提示终端用户输入确认-m:只启动master 实例,主要在故障处理时使用访问单个数据实例:PGOPTIONS='-c gp_session_role=utility' psql template1 -p 5432启动某个segment instance :pg_ctl stop/start -D /datadir/取端口号:select * from gp_segment_configuration 启动以后会在/tmp/ 下生成一个.lock 隐藏文件,记录主进程号。
2.数据库停止:gpstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止master 实例,与gpstart –m 对应使用-f:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
连接数,重启3.查看实例配置和状态select * from gp_segment_configuration order by content ;select * from pg_filespace_entry ;主要字段说明:Content:该字段相等的两个实例,是一对P(primary instance)和M(mirror Instance)Isprimary:实例是否作为primary instance 运行Valid:实例是否有效,如处于false 状态,则说明该实例已经down 掉。
Port:实例运行的端口Datadir:实例对应的数据目录4.gpstate :显示Greenplum数据库运行状态,详细配置等信息常用可选参数:-c:primary instance 和mirror instance 的对应关系-m:只列出mirror 实例的状态和配置信息-f:显示standby master 的详细信息该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
5.查看用户会话和提交的查询等信息select * from pg_stat_activity该表能查看到当前数据库连接的IP 地址,用户名,提交的查询等。
另外也可以在master 主机上查看进程,对每个客户端连接,master 都会创建一个进程。
ps -ef |grep -i postgres |grep -i con杀进程:Linux: kill -11 PIDSql :pg_cancel_backend(pid)ps –ef |grep – i postgre |grep –i con6.查看数据库、表占用空间select pg_size_pretty(pg_relation_size('schema.tablename'));select pg_size_pretty(pg_database_size('databasename));分区表:Select *from pg_partitions where …查某个schema 占用的空间:select pg_size_pretty(pg_relation_size(tablename))from pg_tables t inner join pg_namespace d on t.schemaname=d.nspname group by d.nspname必须在数据库所对应的存储系统里,至少保留30%的自由空间,日常巡检,要检查存储空间的剩余容量。
7.收集统计信息,回收空间定期使用Vacuum analyze tablename 回收垃圾和收集统计信息,尤其在大数据量删除,导入以后,非常重要将delete 或update 的“旧”数据放到Rollback Segment,与表分开存放。
并发事务为了保证数据一致性,需要从Rollback Segment 上恢复数据。
Greenplum:“旧数据”与表存放在一起,对旧的数据做了标志。
并发事务通过transaction ID(XID)判断数据是否可用系统表也是需要进行vaccum:#!/bin/bashDBNAME="databasename"VCOMMAND="VACUUM ANALYZE"#VCOMMAND="VACUUM FULL ANALYZE"psql -tc "select '$VCOMMAND' || ' pg_catalog.' || relname || ';' from pg_classa,pg_namespace b where a.relnamespace=b.oid and b.nspname= 'pg_catalog' anda.relkind='r'" $DBNAME | psql -a $DBNAME长期没有vaccum 的大表,使用重建表/drop 表的方式,消除垃圾空间。
Alter table xxx rename to yyyy.8.查看数据分布情况两种方式:Select gp_segment_id,count(*) from tablename group by 1 ;如数据分布不均匀,将发挥不了并行计算的优势,严重影响性能。
9.实例恢复:gprecoverseg通过gpstate 或gp_segment_configuration 发现有实例down 掉以后,使用该命令进行回复,恢复时候不需要停机,不影响应用10.查看锁信息:SELECT locktype, database, c.relname, l.relation,l.transactionid, l.transaction, l.pid, l.mode, l.granted,a.current_queryFROM pg_locks l, pg_class c, pg_stat_activity aWHERE l.relation=c.oid AND l.pid=a.procpid ORDER BY c.relname;主要字段说明:relname: 表名locktype、mode 标识了锁的类型MVCC: 读写相互不影响select / insert update delete避免死锁:delete 和update 是表级排他EXCLUSIVE锁。
11.数据库备份gp_dump, pg_dump常用参数:-s: 只导出对象定义(表结构,函数等)-n: 只导出某个schemagp_dump 默认在master 的data 目录上产生这些文件:gp_catalog_1_<dbid>_<timestamp> :关于数据库系统配置的备份文件gp_cdatabase_1_<dbid>_<timestamp>:数据库创建语句的备份文件gp_dump_1_<dbid>_<timestamp>:数据库对象ddl语句gp_dump_status_1_<dbid>_<timestamp>:备份操作的日志在每个segment instance 上的data目录上产生的文件:gp_dump_0_<dbid>_<timestamp>:用户数据备份文件gp_dump_status_0_<dbid>_<timestamp>:备份日志12.数据库恢复gp_restore pg_restore必选参数:--gp-k=key :key 为gp_dump 导出来的文件的后缀时间戳-d dbname :将备份文件恢复到dbname13.Master主机硬件故障时,如何切换至Stand by Master,切换成功后是否需要进行数据检查或恢复等HA答:在stand by master 主机上,运行gpactivatestandby -d /gpdata 进行切换。
由于Master 只存储系统元数据信息,切换成功后,一般不需要进行数据检查和恢复。
日常巡检中要检查Stand by master 是否同步,可以通过表gp_master_mirroring 确认,如果发现不同步,可以通过命令:gpinitstandby -s standby_master_hostname –n 使得master和standby 重新同步。
14.当Master主机硬件故障排除时,如何由Stand by切换至原Master主机。
答:1,在standby master运行:gpinitstandby –s original_master_hostname2,在standby master 上运行:gpstop –m,注意这里只停止master 实例3,在原来的maste上运行:gpactivatestandby -d /gpdata。
4,在原来的master上运行:gpinitstandby -s original_standby_master_hostn ame15.日志:master 和segment 上分别有日志:$DATADIR/pg_log/*.csv$DATADIR:select * from pg_filespace_entry ;使用外部表将日志导入数据库,进行分析。
使用xfs 文件系统。
后台存储目录结构:base 下每个目录,对应select oid ,* from pg_database ;select relfilenode from pg_class : ;16.gpconfig : 4.0 新增加管理工具,参数配置工具;-c | --change <param_name>-v | --value value-m | --mastervalue master_value-s | --show <param_name>gpconfig -c max_connections -v 100 -m 1017.gpcheckperf :网络:gpcheckperf -f hostfile_gpchecknet_ic1 -r N –netperf -d /tmp磁盘IOgpcheckperf -f hostfile_gpcheckperf -d /data1 -d /data2 -r d linux DD 命令:dd if=/dev/zero of=/vol2/a.test bs=256k count=161000dd if=/vol2/b.test of=/dev/null bs=256k count=16000018.gpssh: 同时登陆到多个机器上,进行操作Gpssh -h sdw1 –h sdw2 -h sdw319.gp_toolkit: 管理工具包:◆gp_bloat_diag◆gp_stats_missing更多详细信息参见GpadminGuide appendix I ;pg_stat_last_operation:Shows the last time certain database operations were performed on adatabase object, for example, the last time a table was vacuumed20.rolecreate role etl with SUPERUSER;alter role etl with LOGIN;修改pg_hda.conf 配置文件,local和host两种模式。