SPSS期末大作业
spss期末考试上机试题及答案

spss期末考试上机试题及答案SPSS期末考试上机试题及答案一、选择题(每题2分,共20分)1. 在SPSS中,数据视图指的是:A. 数据编辑器B. 输出视图C. 变量视图D. 语法视图答案:A2. 以下哪个选项不是SPSS的数据文件类型?A. .savB. .csvC. .xlsxD. .txt答案:C3. 在SPSS中,要对数据进行排序,应该使用哪个命令?A. Sort CasesB. RecodeC. ComputeD. Transform答案:A4. 以下哪个不是SPSS的统计分析方法?A. 描述性统计分析B. 相关性分析C. 回归分析D. 数据可视化分析答案:D5. 在SPSS中,要计算一个新变量的平均值,应该使用哪个命令?A. ComputeB. AggregateC. Split FileD. Sort Cases答案:A二、填空题(每题3分,共15分)6. 在SPSS中,数据文件的扩展名通常是________。
答案:.sav7. 要将数据从Excel导入SPSS,可以使用________功能。
答案:Get Data8. 在SPSS中,进行频率分析时使用的命令是________。
答案:Frequencies9. 为了进行方差分析,需要在SPSS中选择________菜单下的ANOVA 命令。
答案:Analyze10. 在SPSS中,如果需要对数据进行标准化处理,可以使用________命令。
答案:Standardize三、简答题(每题5分,共10分)11. 请简述SPSS中数据清洗的一般步骤。
答案:数据清洗通常包括以下步骤:检查缺失值、异常值识别、数据类型转换、数据标准化等。
12. 描述性统计分析在SPSS中如何进行?答案:在SPSS中进行描述性统计分析,可以通过选择Analyze菜单下的Descriptive Statistics,然后根据需要选择Frequencies、Descriptives、Explore等命令来进行。
spss期末试题及答案

spss期末试题及答案一、选择题(每题2分,共20分)1. SPSS中,用于描述数据集中的变量分布情况的统计量是()。
A. 平均值B. 中位数C. 众数D. 标准差答案:ABC2. 在SPSS中,进行数据录入时,如果需要输入缺失值,应该使用以下哪个符号表示?()A. 0B. 9C. -D. *答案:C3. 以下哪个选项不是SPSS中的数据类型?()A. 数值型B. 字符串C. 逻辑型D. 图像型答案:D4. 在SPSS中,进行相关性分析时,通常使用哪种统计方法?()A. t检验B. 方差分析C. 卡方检验D. 皮尔逊相关系数答案:D5. SPSS中,用于创建数据文件的命令是()。
A. GET FILEB. SAVEC. OPEN DATAD. NEW DATA答案:A6. 在SPSS中,如果要对数据进行分组处理,应该使用以下哪个功能?()A. 分类汇总B. 数据筛选C. 数据排序D. 数据转换答案:A7. SPSS中,用于绘制数据分布直方图的命令是()。
A. GRAPHB. CHARTC. PLOTD. HISTOGRAM答案:B8. 在SPSS中,如果要进行回归分析,应该使用以下哪个菜单选项?()A. 分析B. 描述统计C. 预测D. 回归答案:D9. SPSS中,用于计算数据集中变量的方差的命令是()。
A. DESCRIPTIVESB. FREQUENCIESC. MEANSD. CORRELATIONS答案:A10. 在SPSS中,如果要对数据进行因子分析,应该使用以下哪个菜单选项?()A. 因子B. 聚类C. 多变量D. 描述统计答案:A二、填空题(每题3分,共15分)1. 在SPSS中,数据视图的窗口分为三个部分:________、变量视图和数据视图。
答案:数据结构视图2. SPSS中,用于计算数据集中变量的均值的命令是________。
答案:MEANS3. 在SPSS中,进行独立样本t检验的命令是________。
spss期末上机试题及答案

spss期末上机试题及答案在SPSS(Statistical Package for the Social Sciences)的学习过程中,上机试题是一项非常重要的评估方式。
下面将为您提供一套SPSS期末上机试题及答案,希望能帮助您更好地理解和应用SPSS。
试题一:数据导入与数据清洗通过实践操作完成以下任务:1.将Excel表格中的数据导入SPSS软件中。
2.对导入的数据进行数据清洗,去除数据缺失和异常值。
答案:导入数据:步骤1:打开SPSS软件,点击“文件”,选择“打开”,再选择“数据”选项。
步骤2:在弹出的对话框中,找到并选中Excel文件,并点击“打开”按钮。
步骤3:在“导入向导”界面上,选择“读取工作表”选项,点击“下一步”按钮。
步骤4:在“选择工作表和变量”界面上,选择要导入的工作表和变量,点击“下一步”按钮。
步骤5:在“命名新数据文件”界面上,选择保存导入后的数据文件的路径和名称,点击“完成”按钮。
数据清洗:步骤1:点击菜单栏上的“数据”选项,选择“选择变量”子菜单。
步骤2:在弹出的对话框中,选择要进行数据清洗的变量,点击“确定”按钮。
步骤3:点击菜单栏上的“数据”选项,选择“筛选”子菜单。
步骤4:在弹出的对话框中,选择要进行筛选的条件,点击“确定”按钮。
步骤5:点击菜单栏上的“数据”选项,选择“数据清理”子菜单。
步骤6:在弹出的对话框中,选择要进行数据清理的方法,点击“确定”按钮。
试题二:描述性统计分析通过实践操作完成以下任务:1.计算数据的平均值、标准差和频数统计。
2.绘制数据的直方图和散点图,并进行数据解读。
答案:计算描述统计量:步骤1:点击菜单栏上的“分析”选项,选择“描述性统计”子菜单。
步骤2:在弹出的对话框中,选择要进行统计分析的变量,点击“统计”按钮。
步骤3:在“统计”界面上,勾选“平均值”、“标准差”和“频数”,点击“确定”按钮。
绘制直方图:步骤1:点击菜单栏上的“图表”选项,选择“直方图”子菜单。
spss统计分析期末考试题及答案

spss统计分析期末考试题及答案一、选择题(每题2分,共20分)1. 在SPSS中,数据视图和变量视图分别对应于:A. 变量列表和数据表B. 数据表和变量列表C. 数据集和变量集D. 变量集和数据集答案:B2. SPSS中用于描述数据分布特征的统计量不包括:A. 平均值B. 中位数C. 众数D. 方差答案:D3. 在SPSS中进行独立样本T检验时,需要满足的假设条件不包括:A. 独立性B. 正态性C. 方差齐性D. 线性答案:D4. 下列哪个选项不是SPSS中的数据类型?A. 数值型B. 字符串型C. 日期型D. 图片型答案:D5. 在SPSS中,进行相关分析时,通常使用的统计方法是:A. 回归分析B. 方差分析C. 卡方检验D. 皮尔逊相关系数答案:D6. SPSS中,用于创建新变量的命令是:A. COMPUTEB. DESCRIPTIVESC. T-TESTD. FREQUENCIES答案:A7. 在SPSS中,执行因子分析时,通常使用的方法是:A. 主成分分析B. 聚类分析C. 回归分析D. 判别分析答案:A8. SPSS中,用于检验两个分类变量之间关系的统计方法是:A. 相关分析B. 回归分析C. 卡方检验D. 方差分析答案:C9. 在SPSS中,进行多变量回归分析时,需要满足的假设条件不包括:A. 线性关系B. 误差项独立C. 误差项同方差性D. 变量之间独立答案:D10. SPSS中,用于创建数据集的命令是:A. GET FILEB. SAVEC. OPEN DATAD. NEW答案:D二、简答题(每题10分,共40分)1. 简述SPSS中数据清洗的常用步骤。
答案:数据清洗的常用步骤包括:数据导入、数据预览、缺失值处理、异常值检测、数据转换和数据编码。
2. 解释SPSS中因子分析的目的和基本步骤。
答案:因子分析的目的是将多个变量简化为几个不相关的因子,以揭示变量之间的内在关系。
基本步骤包括:确定因子数量、提取因子、旋转因子和因子得分计算。
SPSS期末大作业-完整版

SPSS期末大作业-完整版第1题:基本统计分析1分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。
其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。
1、基本思路:(1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。
此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。
分组后进行频数分析并绘制带正态曲线的直方图。
(2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。
操作步骤:(1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。
在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。
存取款金额1频率百分比有效百分比累积百分比有效1.00 82 34.6 34.6 34.62.00 76 32.1 32.1 66.73.00 104.2 4.2 70.94.00 22 9.3 9.3 80.25.00 47 19.8 19.8 100.0 合计237 100.0 100.0(2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。
统计量存(取)款金额20岁以下N有效1 缺失0百分位数25 50.00 50 50.00 75 50.0020~35岁N有效131缺失0 百分位数25 500.0050 1000.0075 5000.0035~50岁N有效73缺失0 百分位数25 500.0050 1000.0075 4500.0050岁以上N有效32缺失0 百分位数25 525.0050 1000.0075 2000.00结果及结果描述:频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
spss的期末考试题及答案

spss的期末考试题及答案一、选择题(每题2分,共20分)1. SPSS是一款由哪个公司开发的统计分析软件?A. IBMB. MicrosoftC. AdobeD. Oracle答案:A2. 在SPSS中,数据文件的扩展名通常是什么?A. .txtB. .csvC. .savD. .xls答案:C3. SPSS中“Variable View”是用来做什么的?A. 编辑数据B. 定义变量属性C. 运行统计分析D. 制作图表答案:B4. 在SPSS中,以下哪个命令用于描述性统计分析?FREQUENCEDESCRIPTIVESCORRELATIONST-TEST答案:DESCRIPTIVES5. 以下哪种数据类型在SPSS中不能被识别?A. NumericB. StringC. DateD. Image答案:D6. SPSS中“Syntax Editor”的主要作用是什么?A. 编辑数据B. 编写和执行命令C. 制作图表D. 定义变量属性答案:B7. 在SPSS中,进行假设检验时,以下哪个选项不是t检验的类型?A. One-Sample T TestB. Paired Samples T TestC. Independent Samples T TestD. Chi-Square Test答案:D8. SPSS中“Data Entry”窗口是用于什么?A. 录入数据B. 编辑数据C. 定义变量属性D. 运行统计分析答案:A9. 在SPSS中,"Analyze"菜单下包含哪些主要功能?A. 数据录入B. 统计分析C. 图表制作D. 变量定义答案:B10. SPSS中,以下哪个命令用于执行回归分析?A. DESCRIPTIVESB. CORRELATIONSC. REGRESSIOND. T-TEST答案:C二、填空题(每空2分,共20分)1. SPSS是一款_________的统计分析软件,广泛应用于社会科学、健康研究等领域。
2020年spss期末考试题和答案

2020年spss期末考试题和答案一、单项选择题(每题2分,共20分)1. 在SPSS中,数据文件的扩展名是()。
A. .txtB. .csvC. .savD. .xls2. 在SPSS中,数据视图和变量视图分别对应于()。
A. 数据编辑和数据浏览B. 数据浏览和数据编辑C. 数据输入和数据输出D. 数据输出和数据输入3. 在SPSS中,执行描述性统计分析的菜单路径是()。
A. 分析 > 描述统计 > 频率B. 分析 > 描述统计 > 描述C. 分析 > 描述统计 > 探索D. 分析 > 描述统计 > 交叉表4. 在SPSS中,执行相关分析的菜单路径是()。
A. 分析 > 相关 > 双变量B. 分析 > 相关 > 偏相关C. 分析 > 相关 > 距离相关D. 分析 > 相关 > 聚类相关5. 在SPSS中,执行回归分析的菜单路径是()。
A. 分析 > 回归 > 线性B. 分析 > 回归 > 逻辑斯蒂C. 分析 > 回归 > 非线性D. 分析 > 回归 > 多项式6. 在SPSS中,执行因子分析的菜单路径是()。
A. 分析 > 降维 > 因子B. 分析 > 降维 > 聚类C. 分析 > 降维 > 对应分析D. 分析 > 降维 > 多维尺度分析7. 在SPSS中,执行聚类分析的菜单路径是()。
A. 分析 > 分类 > 聚类B. 分析 > 分类 > 系统聚类C. 分析 > 分类 > K均值聚类D. 分析 > 分类 > 层次聚类8. 在SPSS中,执行判别分析的菜单路径是()。
A. 分析 > 判别 > 线性判别B. 分析 > 判别 > 二次判别C. 分析 > 判别 > 逐步判别D. 分析 > 判别 > 非线性判别9. 在SPSS中,执行生存分析的菜单路径是()。
SPSS分析期末考试及答案
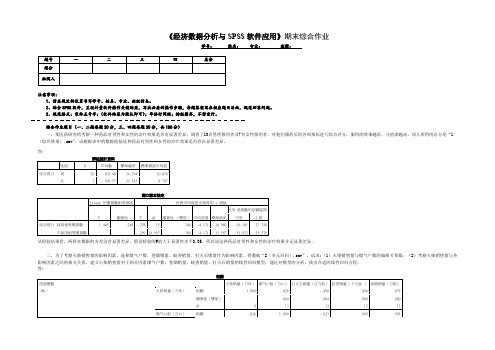
《经济数据分析与SPSS软件应用》期末综合作业学号:姓名:专业:班级:注意事项:1、请在规定的位置书写学号、姓名、专业、班级信息。
2、结合SPSS软件,呈现计量软件操作关键结果,写出必要的操作步骤,每题答案写在相应题目后面,规范回答问题。
3、规范格式:宋体五号字;(软件结果为默认即可);单倍行间距;排版整齐,不留空行。
综合作业题目(一、二题每题20分,三、四题每题30分,共100分)一、某医药研究所考察一种药品对男性和女性的治疗效果是否有显著差异,调查了10名男性服用者及7名女性服用者,对他们服药后的各项指标进行综合评分,服用的效果越好,分值就越高,每人所得的总分见“1(综合效果).sav”,试根据表中的数据检验这种药品对男性和女性的治疗效果是否存在显著差异。
答:群組統計資料性别N 平均數標準偏差標準錯誤平均值综合得分男10 105.40 34.394 10.876女7 109.57 23.143 8.747从检验结果看,两样本数据的方差没有显著差异,假设检验的P值大于显著性水平0.05,所以说这种药品对男性和女性的治疗效果并无显著差异。
二、为了考察火柴销售量的影响因素,选择煤气户数、卷烟销量、蚊香销量、打火石销量作为影响因素,得数据“2(多元回归).sav”。
试求:(1)火柴销售量与煤气户数的偏相关系数;(2)考察火柴销售量与各影响因素之间的相关关系,建立火柴销售量对于相关因素煤气户数、卷烟销量、蚊香销量、打火石销量的线性回归模型,通过对模型的分析,找出合适的线性回归方程。
答:从上表结果分析,排除显著性大于0.05的蚊香销量,对剩下的煤气户数、卷烟销量、打火石销量进行逐步分析。
打火石销量(百万粒)-.243 .017 -.465 -14.689 .000 .999 1.0013 (常數)17.420 .394 44.243 .000卷烟销量(万箱).254 .019 .698 13.228 .000 .185 5.417打火石销量(百万粒)-.243 .012 -.465 -20.526 .000 .999 1.001煤气户数(万户).049 .014 .185 3.516 .005 .185 5.415a. 應變數\: 火柴销量(万件)由逐步分析得到上表,可以建立y=17.420+0.254X1+0.049X2−0.243X4的线性回归方程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据分析方法及软件应用课程作业学号:********姓名:***班级:1306北京交通大学2013年10月第5题:方差分析(2)分析思路根据所给的表定义变量,进而进行数据录入。
在进行单因素和多因素对销售量的影响分析的时候,应先提出相应的零假设,进而选择检验统计量,对检验统计量进行计算,并计算出概率P值,将计算出的概率P值与给定的显著性水平进行比较,做出相应的决策。
目标一:给出SPSS数据集格式定义变量,进行数据录入。
从题意以及所给的表中可以得出,这里有四个变量,分别为销售地点、销售方式、月份和销售量。
其中,销售地点和销售方式为控制变量,月份为随机变量,销售量为观测变量,结合所给的表,进行数据的录入,录入四十个观测变量值。
图1 变量视图图2 数据视图目标二:分析销售地点对销售量的影响(1)操作步骤第一步:提出零假设。
零假设H0是“销售地区对销售量没有产生显著影响”。
第二步:选择检验统计量,并计算检验统计量的观测值和概率P值。
选择菜单【分析——比较均值——单因素】将销售量指定到【因变量列表(E)】中,将销售地区指定到【因子(F)】中,点击确定按钮,出现图3所示的结果。
图3 单因素方差分析销售量平方和df 均方 F 显著性组间254.600 4 63.650 1.107 .369组内2013.000 35 57.514总数2267.600 39第三步:给定显著性水平α=0.05,根据表1,做出决策。
(2)结果分析从图3中可以看出,观测变量销售量的总变差(2267.600)中“销售地区”可解释的变差为254.600,抽样误差引起的变差为2013.000,他们的方差为63.650和57.514,相除所得的F统计量为1.107,对应的概率P值接近于0.369。
(3)结论因为显著性水平α=0.05,概率P值大于α,因而应接受原假设,认为不同的销售地区度销售量不产生显著影响。
目标三:分析销售地点、销售方式和他们的交互作用对对销售量的影响(1)操作步骤第一步:提出零假设。
零假设H0是“销售地区对销售量没有产生显著影响,销售方式对销售量没有产生显著影响,销售地区和销售方式对销售量没有产生显著的交互影响。
”第二步:选择检验统计量,并计算检验统计量的观测值和概率P值。
选择菜单【分析——一般线性模型——单变量】;将销售量指定到【因变量(D)】中,将销售地区和销售方式指定到【固定因子(F)】中,将月份指定到【随机因子(A)】中;点击“模型”按钮,在指定因子中选择【设定】,在构建项中选择【交互】,将销售地区、销售方式以及销售地区*销售方式指定到【模型(M)】中,点击“继续”按钮;点击“确定”按钮,出现如图4所示的结果:第三步:给出显著性水平α=0.05,做出决策。
(2)结果分析从图4中所示的结果可以看出,第一列是对销售量总变差分解的说明,第二列是对销售量变差分析的结果,第三列是自由度,第四列是均方,第五列是对F检验量的观察值,第六列是检验统计量的概率P值。
从图中可以看到,销售量的总变差为2267.600,他被分解为四个部分,分别是销售地区不同引起的变差(254.600),销售方式不同引起的变差(1193.800),销售方式与销售地区交互作用引起的变差(708.200)以及随机因素引起的变差(111.000)。
这些变差除以各自的自由度后,得到各自的均方,可计算出各F检验统计量的观测值和在一定自由度下的概率P值,概率P值分别为0.00,0.00和0.00.(3)结论因为显著性水平α=0.05,概率P值小于显著性水平,因而应拒绝原假设,认为不同的销售地区、不同的销售方式和销售地区与销售方式的交互作用均为销售量带来了影响。
这与单因素分析时得到的结果并不相同,本人认为可能因为随机变量月份的存在所导致的结果。
R方为0.951,调整后的R方为0.905,因而拟合度还是比较高的。
第9题:回归分析(4)分析思路根据题中所给的解释变量和被解释变量建立多元回归模型,利用回归方程的统计检验对建立的多元回归模型进行检验,首先对解释变量采取强行进入策略,分析他们之间的线性关系以及多重共线性;然后对解释变量采用向前筛选策略,做方差齐性和残差的自相关性检验。
(1)操作步骤第一步:确定多元回归方程中的解释变量和被解释变量。
以课题总数Y为被解释变量,解释变量为投入人年数X1、投入科研事业费X2、论文数X3、获奖数X4。
第二步:建立多元线性回归模型。
1)强制进入,分析线性关系和多重共线性①选择菜单中【分析——回归——线性】②将课题总数指定到【因变量(D)】中,将销售地区和销售方式指定到【固定因子(F)】中,将投入人年数、投入科研事业费、论文数和获奖数指定到【自变量(I)】中,在【方法(M)】框中选择回归分析中解释变量的筛选策略为“进入”。
③点击“统计量(S)”按钮,在回归系数框中选择【估计(E)】,在回归分析框的右边选中【模型拟合度(M)】、【R方变化(S)】、【描述性】和【共线性判断(L)】,在残差框中选择【Durbin-Watson(U)】和【个案诊断(C)】,点击“继续”按钮。
④点击“绘制”按钮,在线性回归中,指定*ZPRED给“Y”,指定*ZRESID给“X”,在标准化残差图中选【正态概率图(R)】,点击“继续”按钮。
⑤点击“保存”按钮,将预测值和均值均选中“标准化”。
⑥点击“确定”按钮,出现如下图5、图6、图7和图8。
(2)结果分析及结论图5 相关性从图5中可以看出投入人年数、投入科研事业费、论文数、获奖数对课题总数的的相关性还是比较强的,其中投入人年数与课题总数的相关性最为显著。
图6 模型汇总依据图6,从调整的R方(0.927)可以看出,回归方程的拟合度较高,并且Durbin-Watson (1.776)在1.5和2.5之间,因而可以用线性回归模型来拟合数据。
图7 系数图8 共线性诊断从图7中可以看出,容忍度均小于0.5,并且论文数的容差为0.075,接近于0,方差膨胀因子投入人年数和论文数都大于10,因而有理由认为这些变量之间存在着多重共线性;依据图8,从方差比可以看出,第5个特征根既能解释投入人年数方差的93%,又能解释论文数方差的87%,因而有理由认为这些变量之间存在着多重共线性;再从条件指数来看,第5个条件指数大于10,认为其共线性较强。
2)采用“向前进入”策略,残差的自相关性检验和方差齐性。
(1)操作步骤①选择菜单中【分析——回归——线性】;②将课题总数指定到【因变量(D)】中,将销售地区和销售方式指定到【固定因子(F)】中,将投入人年数、投入科研事业费、论文数和获奖数指定到【自变量(I)】中,在【方法(M)】框中选择回归分析中解释变量的筛选策略为“向前+”。
③点击“统计量(S)”按钮,在回归系数框中选择【估计(E)】,在残差框中选择【Durbin-Watson(U)】和【个案诊断(C)】,点击“继续”按钮;④点击“确定”按钮,出现如图7、图8、图9所示。
(2)结果分析及结论图9 模型汇总图10 观察的累积频率图11 回归标准化残差从图9中可以看出,Durbin-Watson(1.776)在1.5和2.5之间,因而残差序列相对独立;从图10中可以看出,数据点围绕基准线存在一定的规律性,近似服从标准正态分布,即残差均值为0,因而残差序列相对独立,方差齐性良好;从图11中可以看出,回归标准化残差及预测值均在±3个标准差范围内,无异常点,且数据点无明显规律,因而残差序列相对独立。
第11题:聚类分析(1)分析思路因为销量和价格和其他变量存在着数量级上的差异,因而首先需要对销量和价格进行标准化。
其次,根据车种类型,对汽车销售样本数据进行层次聚类分析,将11种车型分为三类,其中个体距离采用欧式距离,类间距离采用平均组间链锁距离。
最后用频数分析对各类的竞争力进行评价。
(1)操作步骤第一步:对变量进行标准化。
选择菜单中【分析—描述统计—描述】,将销量和价格指定到变量中,选中“将标准化得分另存为变量”,点击“确定”按钮。
第二步:层次聚类分析。
①选择菜单中【分析—分类—系统聚类】;②将引擎型号、马力、轴距、宽度、长度、限重、储油量、用油效率和标准化后的销量和价格指定到“变量”框中,将车型指定到“标注个案”框中,在“聚类”中选择“个案”,在“输出”中选择“统计量”和“图”;③点击“统计量”按钮,选择“合并进程表”,在【聚类成员】框汇总选择【单一方案—聚类数:3】,点击“继续“按钮;④点击“绘制”按钮,选中“树状图”,在【冰柱】框中选择“所有聚类”,在【方向】框中选择“垂直”,点击“继续”按钮;⑤点击“方法”按钮,在【聚类方法】框中选择“组间联接”,在【度量标准】框中选择【区间—Euclidean距离】,在【标准化】框中选择“Z”得分,点击“继续”按钮;⑥点击“保存”按钮,在【聚类成员】框中选择【单一方案—聚类数:3】,点击“继续”按钮;⑦点击“确定”按钮,出现如图12、图13、图14所示。
图12 聚类表图13 冰柱图图14 树状图(2)结果分析及结论从图13、图14可以看出,Focushe和Civic相似性较高且较早地聚为了一类,Accord 和Gamry相似性较高且较早地聚为了一类,Malibu 和Grand Am相似性较高且较早的局为了一类。
根据题意,将11种车型分为三类,从图中可以看出,Cavalier 、Focus、Civic和Corolla 为一类(第1类),Malibu、Impala、Grand Am 和Mus tang为一类(第2类),Taurus、Accord 和Camry为一类(第3类)。
第三步:对各类的竞争力情况进行判别分析如图15所示,对各类的竞争力情况分析,则主要通过对各类的销量和价格均值的乘积进行比较,即可得出各类的竞争力情况。
Cavalier、Focus、Civic和Corolla为第1类,它的销量和价格之积为(121.89675*19.17625),Malibu、Impala、Grand Am 和Mus tang为第2类,它的销量和价格之积为(165.85225*12.89200),Taurus、Accord和Camry为第3类,它的销量和价格之积为(241.57033*16.91767),三类进行对比,可以看出第三类Taurus、Accord和Camry的竞争力最强,第一类Cavalier、Focus、Civic和Corolla的竞争力次之,Malibu、Impala、Grand Am 和Mus tang的竞争力最弱。
图15 各类竞争力情况分析。