loadrunner参数化
LoadRunner使用说明书

Load Runner 使用说明一、组件:(一) VuGen:用于捕获最终用户业务流程和创建怎动化性能测试脚本。
1. 录制脚本:(1) 集合点Rendezvous(2) 验证点Check Point:文本验证点Text Check、图片验证点Image Check(3) 事务Transaction:事务开始Start Transaction、事务结束End Transaction(4) 注释与消息Comment & Message:/***/2. 增强并编辑Vuser脚本(1) 参数化:在Select next now中的参数:Sequential顺序、Random随机、Unique唯一在Update value on 参数:Each iteration每次迭代、Each occurrence每次出现、Once 一次(2) 从数据库中导入数据3. 配置动行时设置Runtime settings(运行时设置)(1) Number of Iterations:迭代次数(2) 在Preferences中的Enable image and text check在脚本中添加验证点时必须选中。
4. 在独立模式下运行Vuser脚本5. 集成Vuser脚本(二) Controller:用于组织、驱动、管理和监控负载测试。
1. 创建方案(1) 创建手动方案(2) 创建百分比模式方案(3) 创建面向目标的方案2. 计划方案(1) 开始时间(2) 方案运行设置:加压Ramp Up、持续时间Duration、减压Ramp Dowm3. 运行方案4. 监视方案(1) RuntimeGraphs(运行时图)A. Running Vusers运行时图:Running正在运行的Vuser总数、Ready完成脚本初始化部分、即可以运行的Vuser数、Finished结束运行的Vuser数,包括通过的和失败的、Error执行时发生的错误VuserB. Transaction Graphs事务监视图:Trans Response Time事务响应时间、Trans/Sec(Passed)每秒事务数(通过)、Trans/Sec(Failed/Stopped)每秒事务数(失败、停止)、Total Trans/Sec(Passed)每秒事务总数(通过)。
loadrunner的使用流程

LoadRunner的使用流程1. 简介LoadRunner是一款市场上广泛使用的性能测试工具,可以帮助开发人员和测试人员对系统进行负载测试。
通过模拟多用户同时访问系统的行为,可以评估系统的性能指标,识别瓶颈,并提供优化建议。
2. 安装和配置在使用LoadRunner之前,首先需要进行安装和配置。
以下是安装和配置的步骤: - 下载LoadRunner安装包,并按照安装向导进行安装。
- 配置LoadRunner 的运行环境,包括设置系统变量、配置服务器和代理等。
3. 创建测试脚本测试脚本是LoadRunner的核心部分,它描述了用户的行为以及与系统之间的交互。
以下是创建测试脚本的步骤: - 打开LoadRunner工具,选择新建脚本的选项。
- 选择脚本类型,根据系统的特点选择不同的录制方式,包括录制脚本、使用模板创建脚本或手动编写脚本。
- 开始录制或编写脚本,描述用户的操作和与系统的交互过程。
4. 参数化和提取在进行性能测试时,通常需要模拟多个用户同时访问系统的情况。
为了模拟真实场景,可以使用参数化和提取技术。
以下是参数化和提取的步骤: - 选择需要参数化的请求或数据,例如用户名、密码、搜索关键字等。
- 使用LoadRunner的参数化功能,将这些值设置为参数。
- 在脚本中使用参数化的值,使每个虚拟用户都有不同的值。
- 如果需要提取响应中的数据,可以使用LoadRunner的提取函数将响应中的关键字提取出来,用于后续的验证和分析。
5. 设置场景和调整负载在LoadRunner中,场景是模拟用户在特定时间段内的行为和负载情况。
以下是设置场景和调整负载的步骤: - 在LoadRunner中创建场景,并设置虚拟用户数目、持续时间等参数。
- 使用LoadRunner提供的负载模型,设置每个虚拟用户的行为模式,例如Ramp-Up(逐渐增加用户数)、Peak Load(达到峰值负载)等。
- 调整场景的负载,根据系统的需求和预期的负载情况,适当增加或减少虚拟用户的数目,以模拟真实的负载情况。
LoadRunner介绍

Lr_rendezvous (“login”);
注意: 1、集合点经常和事务结合起来使用,常放在事务的前面; 2、集合点只能插入到Action部分,vuser_init和vuser_end中不能插入集合点;
增强Vuser脚本
注释 可以插入注释来描述活动或关于某个操作的信息 /* * 费用查询 */
在URL中添加要测试的web站点的地址 Record into Action中选择把录制的站点放到脚本的哪一个 部分 Record the application startup 意思是应用程序一旦启 动,就录制脚本;如果不选此项,也可以在应用程序运行过 程中选择开发录制脚本。 Options中进行录制前的选项设置
1、减少脚本的大小 2、提供使用不同的数据测试脚本的能力
参数化包括两项任务:
1、在脚本中用参数取代常量值 2、设置参数的属性以及数据源
定义参数
选中要替换的值,然后点鼠标右键, 选择“Replace with a parameter. ”,出现以下窗口
定义参数
参数类型解释:
DateTime:在需要输入日期/时间的地方,可以用DateTime类型来替代。其属性设置也很 简单,选择一种格式即可。当然也可以定制格式。
注意:不要在事务中输出消息,因为这有可能使事务执行时间变长,扭曲事务结果
定义参数
如果用户在脚本录制过程中需要填写一些提交表单的数据,比如增加数 据库的记录。这些数据会被记录到脚本中,当多个Vuser同时提交相同 数据时有可能会引起冲突,为了模拟真实情况,需要各种各样的输入。
对Vuser脚本进行参数化有两个好处:
LoadRunner组成结构
LoadRunner的组成部件主要有如下几个:
Loadrunner疑惑点,参数化,关联如何定位等

Loadrunner疑惑点,参数化,关联如何定位等⼀、脚本的录制⽅⾯1.LR中脚本浏览可以使⽤两种模式:Tree图形化模式和Script脚本模式2.LR中还提供了Tasks的标签,这⾥提供了VUG建议的脚本录制开发过程,通过⼀个任务流的⽅式知道你。
3.录制选项,对于web使⽤的录制⽅式,HTML提供了两个⼤类的录制⽅式:HTML-BASED SCRIPT 和URL-BASED SCRIPT。
第⼀种:Html-based script 这种⽅式录制出来的脚本是基于html基础的,其下有两种不同类型的脚本:1. A script describing user actions基于解释⽤户⾏为的脚本,录制的脚本中包含web_link,web_submit_form函数,主要是描述⽤户做了什么操作。
(1)思考:若⼀个页⾯中有多个同名的链接,怎么办?答:ORD这个关键字可以帮助你。
=2就是点击的第⼆个。
(2)使⽤html-base Script下的A script describing user actions的好处是脚本简洁,基于⽤户操作模拟,浅显易懂,且⾃⾝包含对象检查过程,⽆需校验。
缺点是基于⽤户⾏为的模拟,在参数化和链接多个同名时难以应⽤。
(3)A script containing explicit URLs only 基于url请求的脚本录制类型。
Web_ulr()、web_submit_data()第⼆种:url-based script 这种是基于URL请求的脚本录制⽅式,会录制所有的http请求。
(1)思考:什么时候我们该⽤html-based script还是选择url-based script呢?答:⼀般来说如果我们的标准是使⽤IE访问的B/S架构,我们应该使⽤html-based下的a script containing explicit urls only这种⽅式来录制脚本,这种脚本基于url请求完成,不会带有任何前后依赖的内容。
LoadRunner性能参数设置

加大tomcat连接数:在tomcat配置文件server.xml中的配置中,和连接数相关的参数有:minProcessors:最小空闲连接线程数,用于提高系统处理性能,默认值为10maxProcessors:最大连接线程数,即:并发处理的最大请求数,默认值为75acceptCount:允许的最大连接数,应大于等于maxProcessors,默认值为100enableLookups:是否反查域名,取值为:true或false。
为了提高处理能力,应设置为falseconnectionTimeout:网络连接超时,单位:毫秒。
设置为0表示永不超时,这样设置有隐患的。
通常可设置为30000毫秒。
其中和最大连接数相关的参数为maxProcessors和acceptCount。
如果要加大并发连接数,应同时加大这两个参数。
web server允许的最大连接数还受制于操作系统的内核参数设置,通常Windows是2000个左右,Linux是1000个左右。
weblogic 整合参数(二)2、连接池实现下面给出连接池类和连接池管理类的主要属性及所要实现的基本接口:public class DBConnectionPool implements TimerListener{private int checkedOut;//已被分配出去的连接数private ArrayList freeConnections = new ArrayList();//容器,空闲池,根据//创建时间顺序存放已创建但尚未分配出去的连接private int minConn;//连接池里连接的最小数量private int maxConn;//连接池里允许存在的最大连接数private String name;//为这个连接池取个名字,方便管理private String password;//连接数据库时需要的密码private String url;//所要创建连接的数据库的地址private String user;//连接数据库时需要的用户名public Timer timer;//定时器public DBConnectionPool(String name, String URL, String user, Stringpassword, int maxConn)//公开的构造函数public synchronized void freeConnection(Connection con) //使用完毕之后,//把连接返还给空闲池public synchronized Connection getConnection(long timeout)//得到一个连接,//timeout是等待时间public synchronized void release()//断开所有连接,释放占用的系统资源private Connection newConnection()//新建一个数据库连接public synchronized void TimerEvent() //定时器事件处理函数}public class DBConnectionManager {static private DBConnectionManager instance;//连接池管理类的唯一实例static private int clients;//客户数量private ArrayList drivers = new ArrayList();//容器,存放数据库驱动程序private HashMap pools = new HashMap ();//以name/value的形式存取连接池//对象的名字及连接池对象static synchronized public DBConnectionManager getInstance()//如果唯一的//实例instance已经创建,直接返回这个实例;否则,调用私有构造函数,创//建连接池管理类的唯一实例private DBConnectionManager()//私有构造函数,在其中调用初始化函数init()public void freeConnection(String name, Connection con)// 释放一个连接,//name是一个连接池对象的名字public Connection getConnection(String name)//从名字为name的连接池对象//中得到一个连接public Connection getConnection(String name, long time)//从名字为name//的连接池对象中取得一个连接,time是等待时间public synchronized void release()//释放所有资源private void createPools(Properties props)//根据属性文件提供的信息,创建//一个或多个连接池private void init()//初始化连接池管理类的唯一实例,由私有构造函数调用private void loadDrivers(Properties props)//装载数据库驱动程序}3、连接池使用上面所实现的连接池在程序开发时如何应用到系统中呢?下面以Servlet为例说明连接池的使用。
loadrunner 参数化取值方式

loadrunner 参数化取值方式(原创版)目录1.概述2.LoadRunner 的基本概念3.LoadRunner 参数化取值的方式4.结论正文1.概述LoadRunner 是一种用于测试应用程序性能的负载测试工具。
它可以模拟大量用户同时访问应用程序,以评估其性能和稳定性。
在 LoadRunner 中,参数化是测试脚本中的一个重要部分,它可以帮助测试人员更轻松地管理和调整测试数据。
2.LoadRunner 的基本概念在 LoadRunner 中,参数化是指将测试脚本中的某些值替换为实际运行时获取的值。
这些值可以是数据库中的记录、文件中的数据或其他来源的值。
通过参数化,测试人员可以轻松地为测试脚本设置不同的输入数据,以模拟不同的用户操作和场景。
3.LoadRunner 参数化取值的方式LoadRunner 提供了多种参数化取值的方式,包括:(1) 直接参数化:在测试脚本中直接指定参数的取值。
例如,测试脚本中可以通过`lr_param_string`函数设置一个字符串参数的值。
(2) 从文件中读取参数:测试脚本可以从文件中读取参数的取值。
例如,可以使用`lr_load_string_file`函数从文件中读取字符串参数的值。
(3) 从数据库中获取参数:测试脚本可以从数据库中获取参数的取值。
例如,可以使用`lr_get_result_set`函数从数据库中获取记录集,并将其作为参数传递给测试脚本。
(4) 使用随机数生成器:测试脚本可以使用 LoadRunner 内置的随机数生成器生成随机参数值。
例如,可以使用`lr_random_number`函数生成一个随机数。
(5) 使用 Excel 文件:测试脚本可以从 Excel 文件中读取参数的取值。
例如,可以使用`lr_load_excel_file`函数从 Excel 文件中读取数据。
4.结论LoadRunner 提供了多种参数化取值的方式,测试人员可以根据实际需求选择合适的方式为测试脚本设置参数值。
Loadrunner参数的取值方式
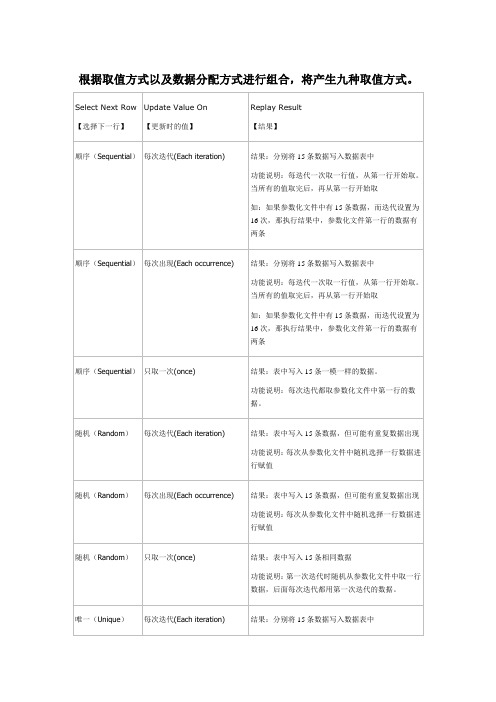
根据取值方式以及数据分配方式进行组合,将产生九种取值方式。
Select Next Row 【选择下一行】Update Value On【更新时的值】Replay Result【结果】顺序(Sequential)每次迭代(Each i t eration)结果:分别将15条数据写入数据表中功能说明:每迭代一次取一行值,从第一行开始取。
当所有的值取完后,再从第一行开始取如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条顺序(Sequential)每次出现(Each occurrence)结果:分别将15条数据写入数据表中功能说明:每迭代一次取一行值,从第一行开始取。
当所有的值取完后,再从第一行开始取如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条顺序(Sequential)只取一次(once)结果:表中写入15条一模一样的数据。
功能说明:每次迭代都取参数化文件中第一行的数据。
随机(Random)每次迭代(Each i t eration)结果:表中写入15条数据,但可能有重复数据出现功能说明:每次从参数化文件中随机选择一行数据进行赋值随机(Random)每次出现(Each occurrence)结果:表中写入15条数据,但可能有重复数据出现功能说明:每次从参数化文件中随机选择一行数据进行赋值随机(Random)只取一次(once)结果:表中写入15条相同数据功能说明:第一次迭代时随机从参数化文件中取一行数据,后面每次迭代都用第一次迭代的数据。
唯一(Unique)每次迭代(Each i t eration)结果:分别将15条数据写入数据表中自动分配块大小功能说明:第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据,以此类推。
注:如果设置迭代次数为16次。
结果:在执行第16次迭代时会抛异常,异常日志可在LoadRunner的回放日志(replayLog)中看到。
Loadrunner中参数的设置

Loadrunner中参数的设置在做负载或者压力测试时,很多人选择使用了Loadrunner测试工具。
该工具的基本流程是先将用户的实际操作录制成脚本,然后产生数千个虚拟用户运行脚本(虚拟用户可以分布在局域网中不同的PC 机上),最后生成相关的报告以及分析图。
但是在录制脚本的过程中会遇到很多实际的问题,比如不同的用户有不同的使用数据,这就牵涉到参数的设置问题。
本文就Loadrunner中参数的设置进行说明,希望对大家有所帮助。
录制程序运行的过程中,VuGen(脚本生成器)自动生成了包含录制过程中实际用到的数值的脚本。
如果你企图在录制的脚本中使用不同的数值执行脚本的活动(如查询、提交等等),那么你必须用参数值取代录制的数值。
这个过程称为参数化脚本。
本文主要包括如下内容:理解参数的局限性、建立参数、定义参数的属性、理解参数的类型、为局部数据类型设置参数的属性、为数据文件设置参数的属性、从已经存在的数据库中引入数据。
除了GUI,以下的内容适合于各种类型的用户脚本。
一、关于参数的定义在你录制程序运行的过程中,脚本生成器自动生成由函数组成的用户脚本。
函数中参数的值就是在录制过程中输入的实际值。
例如,你录制了一个Web应用程序的脚本。
脚本生成器生成了一个声明,该声明搜索名称为“UNIX”的图书的数据库。
当你用多个虚拟用户和迭代回放脚本时,也许你不想重复使用相同的值“UNIX”。
那么,你就可以用参数来取代这个常量。
结果就是你可以用指定的数据源的数值来取代参数值。
数据源可以是一个文件,也可以是内部产生的变量。
用参数表示用户的脚本有两个优点:① 可以使脚本的长度变短。
② 可以使用不同的数值来测试你的脚本。
例如,如果你企图搜索不同名称的图书,你仅仅需要写提交函数一次。
在回放的过程中,你可以使用不同的参数值,而不只搜索一个特定名称的值。
参数化包含以下两项任务:① 在脚本中用参数取代常量值。
② 设置参数的属性以及数据源。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
参数化的定义:使用指定的数据源中的值来替换脚本录制生成的语句中的参数。
对Vuser脚本进行参数化的好处:
1、减小脚本的大小
2、提供了使用不同的脚本的值执行脚本的能力
参数化涉及两个任务:
1、用参数替换Vuser脚本的常量值
2、为参数设置属性和数据源
“Select next row”定义的是如何选择下一行数据。
该处有三个选项"Sequential","Random","Unique",
Sequential:顺序地向Vuser分配数据。
Random:当测试开始运行时,“随机”方法为每个
Vuser分配一个数据表中
的随机值。
Unique:为每一个Vuser的参数分配一个唯一的顺序值。
在这种情况下必须确保表中的数据对所有的Vuser
和它们的迭代来说是充足的。
如果拥有20个Vuser并且要进行5次迭代,则测试者的表格中必须至
少包含100个数值。
“Update value on”定义的是什么时候更新数据值,备选项有每次迭代,每次出现和一次。
表 LoadRunner参数更新方法和数据分配
数据分配方法
顺序随机唯一
每次迭代
对于每次迭代
Vuser会从数据表
中提取下一个值。
对于每次迭代,
Vuser会从数据表
中提取新的随机
对于每次迭代,Vuser
会从数据表中提取下
一个唯一值。
值。
每次出现(仅数据文
件)参数每次出现时,
Vuser将从数据表
中提取下一个值,
即使在同一次迭
代中。
参数每次出现时,
Vuser将从数据表
中提取新的随机
值,即使在同一迭
代中。
参数每次出现时,
Vuser将从数据表中
提取新的唯一值,即使
在同一迭代中。
一次
对于每一个
Vuser,第一次迭
代中分配的值将
用于所有的后续
迭代
第一次迭代中分
配的随机值将用
于该Vuser的所有
迭代
第一次迭代中分配的
唯一值将用于该
Vuser的所有后续迭
代
如果LoadRunner的函数中某个参数不能直接使用LoadRunner参数,那么可以通过lr_eval_string进行转换取到参数的值。
参数表中select next row和update value on的设置
LR的参数的取值,和select next row和update value on的设置都有密不可分的关系。
下表给出了select next row和update value on不同的设置,对于LR的参数取值的结果将不同,给出了详细的描述。
实例:
loadrunner并发迭代时参数取值问题
分类:测试工具[LoadRunner2011-01-02 15:01267人阅读评论(0)收藏举报
假设存在:
数据:A、B、C
虚拟用户:Vuser1、Vuser2、Vuser3
脚本中参数出现三次,脚本迭代三次
怎样取下一行数据?
Sequential:顺序,所有虚拟用户按照顺序读取数据表
Random:随机,所有虚拟用户随机形式读取数据表
Unique:唯一,所有虚拟用户每次各取一值(不重复)
什么时候访问数据表完成数据更新?
Each iteration:每次迭代以后
Each occurrence:每次出现参数
Once:每出现一个虚拟用户
实例:
顺序
Sequential + Each iteration
第一次迭代无论参数任何时候出现Vuser1、Vuser2、Vuser3 取A
第二次迭代无论参数任何时候出现Vuser1、Vuser2、Vuser3 取B
第三次迭代无论参数任何时候出现Vuser1、Vuser2、Vuser3 取C
Sequential + Each occurrence
第N次迭代参数第一次出现Vuser1、Vuser2、Vuser3 取A
第N次迭代参数第二次出现Vuser1、Vuser2、Vuser3 取B
第N次迭代参数第三次出现Vuser1、Vuser2、Vuser3 取C
Sequential + Once
第N次迭代无论参数任何时候出现Vuser1取A Vuser2取B Vuser3取C
随机
Random + Each iteration
第N次迭代无论遇到该参数多少次Vuser1都只取A,或者B,又或者C,本次迭代不再更新
第N次迭代无论遇到该参数多少次Vuser2都只取A,或者B,又或者C,本次迭代不再更新
第N次迭代无论遇到该参数多少次Vuser3都只取A,或者B,又或者C,本次迭代不再更新
在N+1次迭代,每个Vuser重新随机抽取数据
Random + Each occurrence
第N次迭代第一次遇到该参数Vuser1、Vuser2、Vuser3在A、B、C中随机抽取一个
第N次迭代第二次遇到该参数Vuser1、Vuser2、Vuser3重新在A、B、C中随机抽取一个第N次迭代第三次遇到该参数Vuser1、Vuser2、Vuser3重新在A、B、C中随机抽取一个在N+1次迭代,每个Vuser继续保持每遇到一次参数就重新抽取一次数据
Random + Once
第N次迭代无论遇到该参数多少次Vuser1都只取A,或者B,又或者C
第N次迭代无论遇到该参数多少次Vuser2都只取A,或者B,又或者C
第N次迭代无论遇到该参数多少次Vuser3都只取A,或者B,又或者C
在N+1次迭代,每个Vuser不会重新抽取数据
唯一
注意:使用该Unique类型必须注意数据表有足够多的数。
比如Controller 中设定20 个虚拟用户进行5 次循环,那么编号为1 的虚拟用户取前5个数,编号为2 的虚拟用户取6-10 的数,依次类推,这样数据表中至少要有100个数据,否则Controller 运行过程中会返回一个错误。
因此以下例子在数据表中加入数据D、E、F、G、H、I。
Unique + Each iteration
第一次迭代无论参数出现多少次Vuser1取A Vuser2取D Vuser3取G
第二次迭代无论参数出现多少次Vuser1取B Vuser2取E Vuser3取H
第三次迭代无论参数出现多少次Vuser1取C Vuser2取F Vuser3取I
Unique + Each occurrence
第一次迭代第一次出现该参数Vuser1取A Vuser2取D Vuser3取G
第一次迭代第二次出现该参数Vuser1取B Vuser2取E Vuser3取H
第一次迭代第三次出现该参数Vuser1取C Vuser2取F Vuser3取I
Unique + Once
无论进行多少次迭代无论参数任何时候出现Vuser1取A Vuser2取B Vuser3取C
数据D、E、F、G、H、I不取
分享到:
∙上一篇:[qtp]如何构建一个QTP测试框架∙下一篇:常用软件过程——RUP。