线性回归方程公式证明
线性回归方程的求法(需要给每个人发)
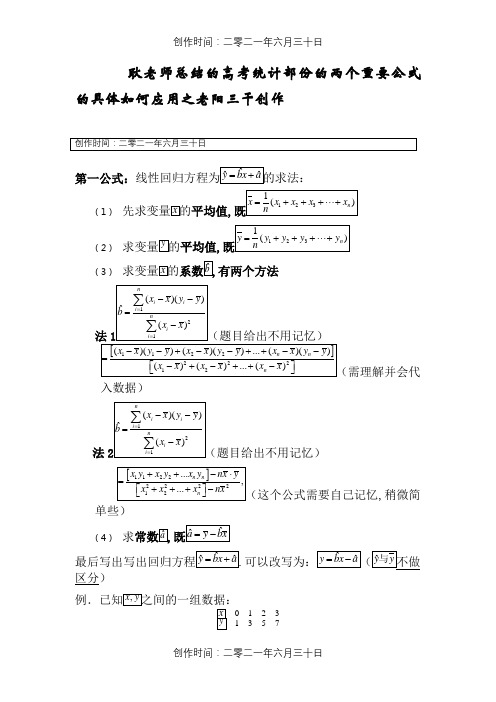
耿老师总结的高考统计部份的两个重要公式
的具体如何应用之老阳三干创作
第一公式:
(1)
平均值,
(2) 平均值,
(3
)
有两个方法
入数据)
法
,稍微简
单些)
(4)
求
区分)
0 1 2 3
1 3 5 7
解:(1
平均值,
(2平均值,
(3
有两个方法
法
(4)求
第二公式:自力性检验
两个分类变量的自力性检验:
注意:数据a
数据b 数据c d 重要.解题步伐如下
第一步:提出假设检验问题 (一般假设两个变量不相关) 第二步:列出上述表格 第三步:计算检验的指标
总计
计
上述结论都是概率性总结.切记事实结论.只是年夜概行描述.具体发生情况要和实际联系!!!!。
线性回归方程公式推导

线性回归方程公式推导从现代经济学研究看,线性回归是一种多变量经济分析方法,它能够用来研究变量之间的关系,以便确定哪些变量具有影响性。
线性回归模型是描述一个响应变量和一组predictor变量之间关系的线性关系模型。
线性回归模型有多种形式,其中最常见的是最小二乘法,即OLS,其核心思想是通过最小化以下损失函数来确定回归系数:S=1/n (yi-i)其中,yi是实际值,i是预测值,n是数据样本的个数。
有了线性回归模型,就可以推导出公式,即OLS回归方程。
它表述的意思是,假设回归系数β的值是已知的,即满足公式:β=(XX)^-1XY其中,X指的是一个有m个变量的矩阵,Y指的是一个有n个观测值的矩阵,X指的是X矩阵的转置矩阵,(XX)^-1指的是求XX的逆矩阵,XY指的是X和Y的点乘积。
由此,OLS回归模型就可以用变量yi=b1x1i+b2x2i+…+bpxpi+εi来表示,其中b1, b2,, bp分别是变量x1i, x2i,, xpi的回归系数,εi是误差项,它以期望值为零的正态分布的形式出现,表示随机噪声。
一般来说,OLS即可用来估计参数的可能性,但是,由于它们常常受到多重共线性的影响,因此需要检验其可靠性。
OLS的优点是可以提供一种最优的参数估计法,它能够有效地提高参数估计的准确性。
此外,OLS进行变量检验时,也可以有效地识别出具有影响性的变量。
不过,OLS也有其缺点,尤其是当数据存在某些问题时,可能会导致OLS的估计结果出现偏差。
主要问题包括多重共线性、异方差性和异常值。
对于这些问题,最好的解决方法是对数据进行相关性分析,从而将偏差减少到最小。
综上所述,OLS回归方程公式能够有效地描述变量之间的关系,检验其可靠性,以便确定哪些变量具有影响性。
为了确保其准确性,应当有效地处理多重共线性等问题,从而使得OLS具有更强的适用性。
线性回归方程公式

线性回归方程公式线性回归是一种用于预测连续数值变量的统计方法。
它基于一个线性的数学模型,通过寻找最佳的拟合直线来描述自变量和因变量之间的关系。
线性回归方程公式为:Y=β0+β1X1+β2X2+...+βnXn+ε其中,Y是因变量,X1,X2,...,Xn是自变量,β0,β1,β2,...,βn是回归系数,ε是误差项。
回归系数表示自变量对因变量的影响程度。
线性回归的基本假设是:1.线性关系:自变量和因变量之间存在线性关系,即因变量的变化可以通过自变量的线性组合来解释。
2.残差独立同分布:误差项ε是独立同分布的,即误差项之间不存在相关性。
3.残差服从正态分布:误差项ε服从正态分布,即在每个自变量取值下,因变量的观测值呈正态分布。
4.残差方差齐性:在每个自变量取值下,因变量的观测值的方差是相等的。
线性回归的求解方法是最小二乘法,即通过最小化实际观测值与回归方程预测值之间的平方差来估计回归系数。
具体步骤如下:1.数据收集:收集自变量和因变量的观测数据。
2.模型设定:根据自变量和因变量之间的关系设定一个线性模型。
3.参数估计:通过最小化平方误差来估计回归系数。
4.模型检验:通过检验残差的随机性、正态性和方差齐性等假设来检验模型的合理性。
5.模型拟合:利用估计的回归系数对未知自变量的观测值进行预测。
6.模型评估:通过评估预测结果的准确性来评估模型的性能。
Y=β0+β1X1+β2X2+...+βnXn+ε其中,Y是因变量,X1,X2,...,Xn是自变量,β0,β1,β2,...,βn 是回归系数,ε是误差项。
多元线性回归方程可以更准确地描述自变量和因变量之间的关系。
除了最小二乘法,还有其他方法可以用来求解线性回归模型,如梯度下降法和最大似然估计法等。
这些方法可以在不同的情况下选择使用,以获得更好的回归模型。
线性回归是一种经典的预测分析方法,被广泛应用于各个领域,如经济学、金融学、社会科学、自然科学等。
通过建立合适的线性回归模型,可以帮助我们理解自变量和因变量之间的关系,并用于预测未来的趋势和变化。
线 性 回 归 方 程 推 导

线性回归——正规方程推导过程线性回归——正规方程推导过程我们知道线性回归中除了利用梯度下降算法来求最优解之外,还可以通过正规方程的形式来求解。
首先看到我们的线性回归模型:f(xi)=wTxif(x_i)=w^Tx_if(xi?)=wTxi?其中w=(w0w1.wn)w=begin{pmatrix}w_0w_1.w_nend{pmatrix}w=?w0?w1?. wn?,xi=(x0x1.xn)x_i=begin{pmatrix}x_0x_1.x_nend{pmatrix}xi?=?x0 x1.xn,m表示样本数,n是特征数。
然后我们的代价函数(这里使用均方误差):J(w)=∑i=1m(f(xi)?yi)2J(w)=sum_{i=1}^m(f(x_i)-y_i)^2J(w) =i=1∑m?(f(xi?)?yi?)2接着把我的代价函数写成向量的形式:J(w)=(Xw?y)T(Xw?y)J(w)=(Xw-y)^T(Xw-y)J(w)=(Xw?y)T(Xw?y) 其中X=(1x11x12?x1n1x21x22?x2n?1xm1xm2?xmn)X=begin{pmatrix}1 x_{11} x_{12} cdots x_{1n}1 x_{21} x_{22} cdots x_{2n}vdots vdots vdots ddots vdots1 x_{m1} x_{m2} cdots x_{mn}end{pmatrix}X=?11?1?x11?x21?xm1?x12?x22?xm2?x1n?x2n?xmn?最后我们对w进行求导,等于0,即求出最优解。
在求导之前,先补充一下线性代数中矩阵的知识:1.左分配率:A(B+C)=AB+ACA(B+C) = AB+ACA(B+C)=AB+AC;右分配率:(B+C)A=BA+CA(B+C)A = BA + CA(B+C)A=BA+CA2.转置和逆:(AT)?1=(A?1)T(A^T)^{-1}=(A^{-1})^T(AT)?1=(A?1)T,(AT)T=A(A^T)^T=A(AT)T=A3.矩阵转置的运算规律:(A+B)T=AT+BT(A+B)^T=A^T+B^T(A+B)T=AT+BT;(AB)T=BTAT(AB)^T=B^TA^T(AB)T=BTAT然后介绍一下常用的矩阵求导公式:1.δXTAXδX=(A+AT)Xfrac{delta X^TAX}{delta X}=(A+A^T)XδXδXTAX?=(A+AT)X2.δAXδX=ATfrac{delta AX}{delta X}=A^TδXδAX?=AT3.δXTAδX=Afrac{delta X^TA}{delta X}=AδXδXTA?=A然后我们来看一下求导的过程:1.展开原函数,利用上面的定理J(w)=(Xw?y)T(Xw?y)=((Xw)T?yT)(Xw?y)=wTXTXw?wTXTy?yTXw+yT yJ(w)=(Xw-y)^T(Xw-y)=((Xw)^T-y^T)(Xw-y)=w^TX^TXw-w^TX^Ty-y^TXw+y^TyJ(w)=(Xw?y)T(Xw?y)=((Xw)T?yT)(Xw?y)=wTXTXw?wTXTy?yT Xw+yTy2.求导,化简得,δJ(w)δw=(XTX+(XTX)T)w?XTy?(yTX)T=0?2XTXw?2XTy=0?XTXw=X Ty?w=(XXT)?1XTyfrac{delta J(w)}{delta w}=(X^TX+(X^TX)^T)w-X^Ty-(y^TX)^T=0implies2X^TXw-2X^Ty=0implies X^TXw=X^Tyimplies w=(XX^T)^{-1}X^TyδwδJ(w)?=(XTX+(XTX)T)w?XTy?(yTX)T=0?2XTX w?2XTy=0?XTXw=XTy?w=(XXT)?1XTy最后补充一下关于矩阵求导的一些知识,不懂可以查阅:矩阵求导、几种重要的矩阵及常用的矩阵求导公式这次接着一元线性回归继续介绍多元线性回归,同样还是参靠周志华老师的《机器学习》,把其中我一开始学习时花了较大精力弄通的推导环节详细叙述一下。
线性回归方程公式_数学公式

线性回归方程公式_数学公式线性回归方程公式线性回归方程公式:b=(x1y1+x2y2+...xnyn-nXY)/(x1+x2+...xn-nX)。
线性回归方程公式求法:第一:用所给样本求出两个相关变量的(算术)平均值:x_=(x1+x2+x3+...+xn)/ny_=(y1+y2+y3+...+yn)/n第二:分别计算分子和分母:(两个公式任选其一)分子=(x1y1+x2y2+x3y3+...+xnyn)-nx_Y_分母=(x1^2+x2^2+x3^2+...+xn^2)-n__x_^2第三:计算b:b=分子/分母用最小二乘法估计参数b,设服从正态分布,分别求对a、b的偏导数并令它们等于零。
其中,且为观测值的样本方差.线性方程称为关于的线性回归方程,称为回归系数,对应的直线称为回归直线.顺便指出,将来还需用到,其中为观测值的样本方差。
先求x,y的平均值X,Y再用公式代入求解:b=(x1y1+x2y2+...xnyn-nXY)/(x1+x2+...xn-nX)后把x,y的平均数X,Y代入a=Y-bX求出a并代入总的公式y=bx+a得到线性回归方程(X为xi的平均数,Y为yi的平均数)线性回归方程的应用线性回归方程是回归分析中第一种经过严格研究并在实际应用中广泛使用的类型。
这是因为线性依赖于其未知参数的模型比非线性依赖于其位置参数的模型更容易拟合,而且产生的估计的统计特性也更容易确定。
线性回归有很多实际用途。
分为以下两大类:如果目标是预测或者映射,线性回归可以用来对观测数据集的和X的值拟合出一个预测模型。
当完成这样一个模型以后,对于一个新增的X值,在没有给定与它相配对的y的情况下,可以用这个拟合过的模型预测出一个y值。
给定一个变量y和一些变量X1,...,Xp,这些变量有可能与y相关,线性回归分析可以用来量化y与Xj之间相关性的强度,评估出与y不相关的Xj,并识别出哪些Xj的子集包含了关于y的冗余信息。
回归方程b的两个公式

回归方程b的两个公式第一个公式是简单线性回归方程b的公式。
简单线性回归方程b通常用来描述一个自变量对一个因变量的影响。
这个公式是y = bx + a,其中y是因变量,x是自变量,b是斜率,a是截距。
通过简单线性回归方程b,我们可以计算出斜率b的值,从而了解自变量对因变量的影响程度。
斜率b的值越大,自变量对因变量的影响越大,反之亦然。
通过简单线性回归方程b,我们可以进行预测和分析,帮助我们更好地理解数据背后的规律。
第二个公式是多元线性回归方程b的公式。
多元线性回归方程b通常用来描述多个自变量对一个因变量的影响。
这个公式是y = b0 + b1x1 + b2x2 + ... + bnxn,其中y是因变量,x1、x2、...、xn是自变量,b0是截距,b1、b2、...、bn是系数。
通过多元线性回归方程b,我们可以计算出各个自变量的系数,从而了解它们对因变量的影响程度。
不同自变量的系数可以帮助我们理解各个因素对结果的影响,进行因果分析和预测。
回归方程b的两个公式在实际应用中具有广泛的用途。
在统计学中,我们可以利用回归方程b来分析数据之间的关系,进行预测和决策。
例如,在市场营销领域,我们可以利用回归分析来预测产品销量,制定营销策略。
在经济学中,我们可以利用回归分析来研究经济现象,制定政策措施。
回归方程b的两个公式可以帮助我们更好地理解数据,作出科学的决策。
回归方程b的两个公式在统计学和经济学中扮演着重要的角色。
通过这两个公式,我们可以深入分析数据之间的关系,揭示规律,进行预测和决策。
回归分析是一种强大的工具,可以帮助我们更好地理解世界,做出明智的选择。
希望通过学习回归方程b的两个公式,我们可以更好地应用它们,提升自己的分析能力和决策水平。
线性回归方程b的公式推导

线性回归方程b的公式推导线性回归方程b是统计学中一种重要的回归分析技术,它是为了预测一个或多个变量之间的关系而拟合的数学模型,它可以帮助我们更好地理解模型中的变量之间的特定关系,并可以用来预测未知的分类问题。
线性回归方程b属于传统的机器学习算法之一,广泛用于各行各业。
线性回归方程b的定义为:Y或者Yi是解释变量,X者 Xi解释变量,b系数,u残差项。
如果某一变量Yi具有另一变量Xi的线性拟合关系,则Yi可以用Xi来描述,这个关系可以用线性回归方程b 来表达:Yi = bX1 + bX2 + + bXn + u。
线性回归模型的参数b又分成两部分,一部分是回归系数,是描述变量的关系的,一部分是残差项,即残差是形成的拟合曲线的垂直距离,表示因为未知的原因而无法拟合的数据。
有了线性回归方程b,此时我们就可以开始推导线性回归方程b 的公式来求解回归系数b了。
首先,将方程Yi = bX1 + bX2 + + bXn + u转换为矩阵形式,Yi = BX + u,其中,B为系数矩阵(由回归系数b组成),X为自变量矩阵(由解释变量Xi组成),u为残差项。
接着,在只有唯一解的前提下,可用最小二乘法(OLS)来求解回归系数b的值:BOLS=(XX)^(-1)XY,其中XX是X的转置矩阵乘以X矩阵为正定阵,XY是X的转置矩阵乘以Y矩阵。
有了上述的公式,我们就可以进行求解回归系数b的值了。
回归系数b的求解可分为以下几步:首先,从样本中抽取多个解释变量和一个被解释变量;然后,计算XX和XY;接下来,计算BOLS,即(XX)^(-1)XY;最后,根据BOLS确定其中的回归系数b。
以上就是线性回归方程b的推导过程。
线性回归方程b不仅可以用于求解拟合程度,而且可以用来预测未知的数据。
此外,它也不仅仅可以用于线性回归,还可以用于其他类型的回归分析,比如多项式回归、局部加权回归、非线性回归等。
以上就是关于线性回归方程b推导公式的相关内容,线性回归方程b是统计学中一种重要的回归分析技术,它可以用来推导回归系数b的计算,并可以用来预测未知的分类问题。
线 性 回 归 方 程 推 导

线性回归之最小二乘法线性回归Linear Regression——线性回归是机器学习中有监督机器学习下的一种简单的回归算法。
分为一元线性回归(简单线性回归)和多元线性回归,其中一元线性回归是多元线性回归的一种特殊情况,我们主要讨论多元线性回归如果因变量和自变量之间的关系满足线性关系(自变量的最高幂为一次),那么我们可以用线性回归模型来拟合因变量与自变量之间的关系.简单线性回归的公式如下:y^=ax+b hat y=ax+by^?=ax+b多元线性回归的公式如下:y^=θTx hat y= theta^T x y^?=θTx上式中的θthetaθ为系数矩阵,x为单个多元样本.由训练集中的样本数据来求得系数矩阵,求解的结果就是线性回归模型,预测样本带入x就能获得预测值y^hat yy^?,求解系数矩阵的具体公式接下来会推导.推导过程推导总似然函数假设线性回归公式为y^=θxhat y= theta xy^?=θx.真实值y与预测值y^hat yy^?之间必然有误差?=y^?yepsilon=haty-y?=y^?y,按照中心极限定理(见知识储备),我们可以假定?epsilon?服从正态分布,正态分布的概率密度公式为:ρ(x)=1σ2πe?(x?μ)22σ2rho (x)=frac {1}{sigmasqrt{2pi}}e^{-frac{(x-mu)^2}{2sigma^2}}ρ(x)=σ2π1e2σ2(x?μ)2?为了模型的准确性,我们希望?epsilon?的值越小越好,所以正态分布的期望μmuμ为0.概率函数需要由概率密度函数求积分,计算太复杂,但是概率函数和概率密度函数呈正相关,当概率密度函数求得最大值时概率函数也在此时能得到最大值,因此之后会用概率密度函数代替概率函数做计算.我们就得到了单个样本的误差似然函数(μ=0,σmu=0,sigmaμ=0,σ为某个定值):ρ(?)=1σ2πe?(?0)22σ2rho (epsilon)=frac {1}{sigmasqrt{2pi}}e^{-frac{(epsilon-0)^2}{2sigma^2}}ρ(?)=σ2π?1?e?2σ2(?0)2?而一组样本的误差总似然函数即为:Lθ(?1,?,?m)=f(?1,?,?m∣μ,σ2)L_theta(epsilon_1,cdots,e psilon_m)=f(epsilon_1,cdots,epsilon_m|mu,sigma^2)Lθ?(?1?,? ,?m?)=f(?1?,?,?m?∣μ,σ2)因为我们假定了?epsilon?服从正态分布,也就是说样本之间互相独立,所以我们可以把上式写成连乘的形式:f(?1,?,?m∣μ,σ2)=f(?1∣μ,σ2)?f(?m∣μ,σ2)f(epsilon_1,cdots,epsilon_m|mu,sigma^2)=f(epsilon_1|mu,sigma^2)*cdots *f(epsilon_m|mu,sigma^2)f(?1?,?,?m?∣μ,σ2)=f(?1?∣μ,σ2)?f(?m?∣μ,σ2) Lθ(?1,?,?m)=∏i=1mf(?i∣μ,σ2)=∏i=1m1σ2πe?(?i?0)22σ2L_theta(epsilon_1,cdots,epsilon_m)=prod^m_{i=1}f(epsilon _i|mu,sigma^2)=prod^m_{i=1}frac{1}{sigmasqrt{2pi}}e^{-frac{(epsilon_i-0)^2}{2sigma^2}}Lθ? (?1?,?,?m?)=i=1∏m?f(?i?∣μ,σ2)=i=1∏m?σ2π?1?e?2σ2(?i?0)2?在线性回归中,误差函数可以写为如下形式:i=∣yiy^i∣=∣yiθTxi∣epsilon_i=|y_i-haty_i|=|y_i-theta^Tx_i|?i?=∣yi?y^?i?∣=∣yi?θTxi?∣最后可以得到在正态分布假设下的总似然估计函数如下:Lθ(?1,?,?m)=∏i=1m1σ2πe?(?i?0)22σ2=∏i=1m1σ2πe?(yi θTxi)22σ2L_theta(epsilon_1,cdots,epsilon_m)=prod^m_{i=1} frac{1}{sigmasqrt{2pi}}e^{-frac{(epsilon_i-0)^2}{2sigma^2}}=pro d^m_{i=1}frac{1}{sigmasqrt{2pi}}e^{-frac{(y_i-theta^Tx_i)^2}{2sigma^2}}L θ?(?1?,?,?m?)=i=1∏m?σ2π?1?e?2σ2(?i?0)2?=i=1∏m?σ2π?1 e2σ2(yi?θTxi?)2?推导损失函数按照最大总似然的数学思想(见知识储备),我们可以试着去求总似然的最大值.遇到连乘符号的时候,一般思路是对两边做对数运算(见知识储备),获得对数总似然函数:l(θ)=loge(Lθ(?1,?,?m))=loge(∏i=1m1σ2πe?(yi?θTxi)22σ2)l(theta)=log_e(L_theta(epsilon_1,cdots,epsilon_m))=log_ e(prod^m_{i=1}frac{1}{sigmasqrt{2pi}}e^{-frac{(y_i-theta^Tx_i)^2}{2sigma^2}}) l(θ)=loge?(Lθ?(?1?,?,?m?))=loge?(i=1∏m?σ2π?1?e?2σ2(yi θTxi?)2?)l(θ)=loge(∏i=1m1σ2πe?(yi?θTxi)22σ2)=∑i=1mloge1σ2πexp(?(yi?θTxi)22σ2)=mloge1σ2π?12σ2∑i=1m(yi?θTxi)2l (theta) = log_e(prod^m_{i=1}frac {1}{sigmasqrt{2pi}}e^{-frac{(y_i-theta^Tx_i)^2}{2sigma^2}}) = sum_{i=1}^mlog_efrac {1}{sigmasqrt{2pi}}exp({-frac{(y_i-theta^Tx_i)^2}{2sigma^2} })=mlog_efrac{1}{sigmasqrt{2pi}}-frac{1}{2sigma^2}sum^m_{i= 1}(y^i-theta^Tx^i)^2l(θ)=loge?(i=1∏m?σ2π?1?e?2σ2(yi?θTxi?)2?)=i=1∑m?loge?σ2π?1?exp(?2σ2(yi?θTxi?)2?)=mloge?σ2π?1?2σ21?i=1∑m?(yi?θTxi)2前部分是一个常数,后部分越小那么总似然值越大,后部分则称之为损失函数,则有损失函数的公式J(θ)J(theta)J(θ):J(θ)=12∑i=1m(yi?θTxi)2=12∑i=1m(yi?hθ(xi))2=12∑i=1m (hθ(xi)?yi)2J(theta)=frac{1}{2}sum^m_{i=1}(y^i-theta^Tx^i)^2=frac{1}{2} sum^m_{i=1}(y^i-h_theta(x^i))^2=frac{1}{2}sum^m_{i=1}(h_the ta(x^i)-y^i)^2J(θ)=21?i=1∑m?(yi?θTxi)2=21?i=1∑m?(yi?hθ?(xi))2=21?i=1∑m?(hθ?(xi)?yi)2解析方法求解线性回归要求的总似然最大,需要使得损失函数最小,我们可以对损失函数求导.首先对损失函数做进一步推导:J(θ)=12∑i=1m(hθ(xi)?yi)2=12(Xθ?y)T(Xθ?y)J(theta)=fr ac{1}{2}sum^m_{i=1}(h_theta(x^i)-y^i)^2=frac{1}{2}(Xtheta-y )^T(Xtheta-y)J(θ)=21?i=1∑m?(hθ?(xi)?yi)2=21?(Xθ?y)T(Xθy)注意上式中的X是一组样本形成的样本矩阵,θthetaθ是系数向量,y也是样本真实值形成的矩阵,这一步转换不能理解的话可以试着把12(Xθ?y)T(Xθ?y)frac{1}{2}(Xtheta-y)^T(Xtheta-y)21?(Xθ?y) T(Xθ?y)带入值展开试试.J(θ)=12∑i=1m(hθ(xi)?yi)2=12(Xθ?y)T(Xθ?y)=12((Xθ)T? yT)(Xθ?y)=12(θTXT?yT)(Xθ?y)=12(θTXTXθ?yTXθ?θTXTy+yTy)J(theta)=frac{1}{2}sum^m_{i=1}(h_theta(x^i)-y^i)^2=frac{1} {2}(Xtheta-y)^T(Xtheta-y)=frac{1}{2}((Xtheta)^T-y^T)(Xtheta -y)=frac{1}{2}(theta^TX^T-y^T)(Xtheta-y)=frac{1}{2}(theta^T X^TXtheta-y^TXtheta-theta^TX^Ty+y^Ty)J(θ)=21?i=1∑m?(hθ?( xi)?yi)2=21?(Xθ?y)T(Xθ?y)=21?((Xθ)T?yT)(Xθ?y)=21?(θTXT yT)(Xθ?y)=21?(θTXTXθ?yTXθ?θTXTy+yTy)根据黑塞矩阵可以判断出J(θ)J(theta)J(θ)是凸函数,即J(θ)J(theta)J(θ)的对θthetaθ的导数为零时可以求得J(θ)J(theta)J(θ)的最小值.J(θ)?θ=12(2XTXθ?(yTX)T?XTy)=12(2XTXθ?XTy?XTy)=XTXθXTyfrac{partialJ(theta)}{partialtheta}=frac{1}{2}(2X^TXtheta-(y^TX)^T-X^Ty )=frac{1}{2}(2X^TXtheta-X^Ty-X^Ty)=X^TXtheta-X^Ty?θ?J(θ)? =21?(2XTXθ?(yTX)T?XTy)=21?(2XTXθ?XTy?XTy)=XTXθ?XTy 当上式等于零时可以求得损失函数最小时对应的θthetaθ,即我们最终想要获得的系数矩阵:XTXθ?XTy=0XTXθ=XTy((XTX)?1XTX)θ=(XTX)?1XTyEθ=(XTX)?1 XTyθ=(XTX)?1XTyX^TXtheta-X^Ty=0X^TXtheta=X^Ty((X^TX)^{-1}X^TX)theta=(X^TX)^{-1}X^TyEtheta=(X^TX)^{-1}X^Tytheta=(X^TX)^{-1}X^TyXTXθ?XTy=0XT Xθ=XTy((XTX)?1XTX)θ=(XTX)?1XTyEθ=(XTX)?1XTyθ=(XTX)?1XTy (顺便附上一元线性回归的系数解析解公式:θ=∑i=1m(xi?x ̄)(yi?y ̄)∑i=1m(xi?x  ̄)2theta=frac{sum^m_{i=1}(x_i-overline{x})(y_i-overline{y} )}{sum^m_{i=1}(x_i-overline{x})^2}θ=∑i=1m?(xi?x)2∑i=1m?( xi?x)(yi?y?)?)简单实现import numpy as npimport matplotlib.pyplot as plt# 随机创建训练集,X中有一列全为'1'作为截距项X = 2 * np.random.rand(100, 1)y = 5 + 4 * X + np.random.randn(100, 1)X = np.c_[np.ones((100,1)),X]# 按上面获得的解析解来求得系数矩阵thetatheta = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)# 打印结果print(theta)# 测试部分X_test = np.array([[0],X_test = np.c_[(np.ones((2, 1))), X_test]print(X_test)y_predict = X_test.dot(theta)print(y_predict)plt.plot(X_test[:,-1], y_predict, 'r-')plt.axis([0, 2, 0, 15])plt.show()sklearn实现import numpy as npimport matplotlib.pyplot as pltfrom sklearn.linear_model import LinearRegression X = 2 * np.random.rand(100, 1)y = 5 + 4 * X + np.random.randn(100, 1)X = np.c_[np.ones((100,1)),X]# 新建线性回归模型model = LinearRegression(fit_intercept=False)# 代入训练集数据做训练model.fit(X,y)# 打印训练结果print(model.intercept_,model.coef_)X_test = np.array([[0],X_test = np.c_[(np.ones((2, 1))), X_test]print(X_test)y_predict =model.predict(X_test)print(y_predict)plt.plot(X_test[:,-1], y_predict, 'r-')plt.axis([0, 2, 0, 15])plt.show()使用解析解的公式来求得地模型是最准确的.计算量非常大,这会使得求解耗时极多,因此我们一般用的都是梯度下降法求解.知识储备距离公式机器学习中常见的距离公式 - WingPig - 博客园中心极限定理是讨论随机变量序列部分和分布渐近于正态分布的一类定理。