《计量经济学》上机实验参考答案
计量经济学(数字教材版)课后习题参考答案

课后习题参考答案第二章教材习题与解析1、 判断下列表达式是否正确:y i =β0+β1x i ,i =1,2,⋯ny ̂i =β̂0+β̂1x i ,i =1,2,⋯nE(y i |x i )=β0+β1x i +u i ,i =1,2,⋯n E(y i |x i )=β0+β1x i ,i =1,2,⋯nE(y i |x i )=β̂0+β̂1x i ,i =1,2,⋯ny i =β0+β1x i +u i ,i =1,2,⋯ny ̂i =β̂0+β̂1x i +u i ,i =1,2,⋯n y i =β̂0+β̂1x i +u i ,i =1,2,⋯n y i =β̂0+β̂1x i +u ̂i ,i =1,2,⋯n y ̂i =β̂0+β̂1x i +u ̂i ,i =1,2,⋯n答案:对于计量经济学模型有两种类型,一是总体回归模型,另一是样本回归模型。
两类回归模型都具有确定形式与随机形式两种表达方式:总体回归模型的确定形式:X X Y E 10)|(ββ+= 总体回归模型的随机形式:μββ++=X Y 10样本回归模型的确定形式:X Y 10ˆˆˆββ+= 样本回归模型的随机形式:e X Y ++=10ˆˆββ 除此之外,其他的表达形式均是错误的2、给定一元线性回归模型:y =β0+β1x +u (1)叙述模型的基本假定;(2)写出参数β0和β1的最小二乘估计公式;(3)说明满足基本假定的最小二乘估计量的统计性质; (4)写出随机扰动项方差的无偏估计公式。
答案:(1)线性回归模型的基本假设有两大类,一类是关于随机误差项的,包括零均值、同方差、不序列相关、满足正态分布等假设;另一类是关于解释变量的,主要是解释变量是非随机的,如果是随机变量,则与随机误差项不相关。
(2)12ˆi iix yxβ=∑∑,01ˆˆY X ββ=- (3)考察总体的估计量,可从如下几个方面考察其优劣性:1)线性性,即它是否是另一个随机变量的线性函数; 2)无偏性,即它的均值或期望是否等于总体的真实值;3)有效值,即它是否在所有线性无偏估计量中具有最小方差;4)渐进无偏性,即样本容量趋于无穷大时,它的均值序列是否趋于总体真值; 5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值;6)渐进有效性,即样本容量趋于无穷大时,它在所有的一致估计量中是否具有最小的渐进方差。
计量经济学上机实验

西安郵電大学《计量经济学》课内上机实验报告书系部名称:经济与管理学院学生姓名:专业名称:班级:时间:2011-2012(2)1、教材P54 11题2、教材P91 10、11题3、教材p135 7、8题11、下表是中国1978-2000年的财政收入Y和国内生产总值(GDP)的统计资料。
单位:亿元要求,以手工和运用EViews软件(或其他软件):(1)作出散点图,建立财政收入随国内生产总值变化的一元线性回归模型,并解释斜率的经济意义;(2)对所建立的回归模型进行检验;(3)若2001年中国国内生产总值为105709亿元,求财政收入的预测值及预测区间。
Dependent Variable: YMethod: Least SquaresDate: 04/12/11 Time: 11:26Sample: 1978 2000R-squared Mean dependent varAdjusted R-squared. dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood F-statistic0200004000060000800001000007880828486889092949698001.通过已知数据得到上面得散点图,财政收入随国内生产总值变化的一元线性回归方程: Ŷi= +() () t=r ²= F= ˆσ= 估计的解释变量的系数为,说明国内生产总值每增加一元,财政收入将增加元,符合经济理论。
2.(1)样本可决系数r ²=,模拟拟合度较好。
(2)系数的显著性检验:给定α=0,05,查t 分布表在自由度为n-2=21时的临界值为(21)=因为t=> (21)=, 国内生产总值对财政收入有显著性影响。
3.2001年的财政收入的预测值:Ŷ01= + *105709=2001年的财政收入的预测区间:在1-α下,Y01的置信区间为: Y01∈()()01/2001/20ˆˆˆˆ,Yt e Y t e αασσ⎡⎤-+⎣⎦即: Y01∈[]11612.666943,14829.98478310、在一项对某社区家庭对某种消费品的消费需要调查中,得到下表所示的资料。
计量经济学上机实验手册

实验三异方差性实验目的:在理解异方差性概念和异方差对OLS回归结果影响的基础上,掌握进行异方差检验和处理的方法;熟练掌握和运用Eviews软件的图示检验、G-Q检验、怀特White 检验等异方差检验方法和处理异方差的方法——加权最小二乘法;实验内容:书P116例4.1.4:中国农村居民人均消费函数中国农村居民民人均消费支出主要由人均纯收入来决定;农村人均纯收入除从事农业经营的收入外,还包括从事其他产业的经营性收入以及工资性收入、财产收入和转移支付收入等;为了考察从事农业经营的收入和其他收入对中国农村居民消费支出增长的影响,建立双对数模型:其中,Y表示农村家庭人均消费支出,X1表示从事农业经营的纯收入,X2表示其他来源的纯收入;表4.1.1列出了中国内地2006年各地区农村居民家庭人均纯收入及消费支出的相关数据;表4.1.1 中国2006年各地区农村居民家庭人均纯收入与消费支出单位:元注:从事农业经营的纯收入由从事第一产业的经营总收入与从事第一产业的经营支出之差计算,其他来源的纯收入由总纯收入减去从事农业经营的纯收入后得到;资料来源:中国农村住户调查年鉴2007、中国统计年鉴2007;实验步骤:一、创建文件1.建立工作文件CREATE U 1 31 其中的“U”表示非时序数据2.录入与编辑数据Data Y X1 X2 意思是:同时录入Y、X1和X2的数据3.保存文件单击主菜单栏中File→Save或Save as→输入文件名、路径→保存;二、数据分析1.散点图①Scat X1 Y从散点图可看出,农民农业经营的纯收入与农民人均消费支出呈现一定程度的正相关;②Scat X2 Y从散点图可看出,农民其他来源纯收入与农民人均消费支出呈现较高程度的正相关;2.数据取对数处理Genr LY=LOG YGenr LX1=LOG X1Genr LX2=LOG X2三、模型OLS 参数估计与统计检验 LS LY C LX1 LX2得到模型OLS 参数估计和统计检验结果:Dependent Variable: LY Method: Least Squares Sample: 1 31Variable CoefficientStd. Errort-StatisticProb.C LX1 R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic 注意:在学术文献中一般以这种形式给出回归方程的输出结果,而不是把上面的软件输出结果直接粘贴到文章中可决系数,调整可决系数,显示模型拟合程度较高;同时,F 检验统计量,在5%的显着性水平下通过方程总体显着性检验;可认为农民农业经营的收入和其他收入整体与农村居民消费支出的线性关系显着成立;变量X2和截距项均在5%的显着性水平下通过变量显着性检验,但X1在10%的显着水平下仍不能通过检验;四、异方差检验对于双对数模型,由于12(0.150214)(0.477453)ββ=<=二者均为弹性系数,可认为其他来源的纯收入而不是从事农业经营的纯收入的增长,对农户人均消费的增长更有刺激作用;也就是说,不同地区农村人均消费支出的差别主要来源于非农经营收入及工资收入、财产收入等其他来源收入的差别,因此,如果模型存在异方差性,则可能是X2引起的;1.图示检验法观察残差的平方与LX2的散点图;①残差resid残差resid变量数据是模型参数估计命令完成后由Eviews软件自动生成在Workfile 框里可找到,无需人工操作获得;注意,resid保留的是最近一次估计模型的残差数据;②残差的平方与LX2的散点图Scat LX2 resid^2从上图可大体判断出模型存在递增型异方差性;2.G-Q法检验异方差补充:先定义一个变量T,取值为1、2、…、31分别代表各省市,用于在做完G-Q检验之后,再按T排序,使数据顺序还原;Data T 提示:输入1、2、…、31①将所有原始数据按照X2升序排列;Sort X2Show Y X1 X2 LY LX1 LX2显示各个变量数据的目的是查看一下,所有变量数据是否按X2升序排列好了;②将31对样本数据,去掉中间的7对,形成两个容量均为12的子样本,即1-12和20-31;③对1-12的子样本做普通最小二乘估计,并记录残差平方和RSS;1Smpl 1 12 意思是:将样本区间由1-31,改为1-12Ls LY C LX1 LX2Dependent Variable: LYMethod: Least Squares Sample: 1 12C LX1 LX2R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson statProbF-statistic子样本1:12ln 3.1412080.398385ln 0.234751ln Y X X e =+++1RSS =④对20-31的子样本做普通最小二乘估计,并记录残差平方和2RSS ; Smpl 20 31 意思是:将样本区间由1-12,改为20-31 Ls LY C LX1 LX2Dependent Variable: LY Method: Least Squares Sample: 20 31Included observations: 12C LX1 R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson statProbF-statistic子样本2:12ln 3.9936440.113766ln 0.6201681ln Y X X e =-++2RSS =⑤异方差检验在5%与10%的显着性水平下,自由度为9,9的F分布临界值分别为0.05(9,9) 3.18F=与0.10(9,9) 2.44F=;因此5%显着性水平下不能拒绝同方差假设,但在10%的显着性水平下拒绝;补充:怀特检验软件操作:在原始模型的OLS方程对象窗口中,选择view/Residual test/White Heteroskedasticity;Eviews提供了包含交叉项的怀特检验“White Heteroskedasticitycross terms”和没有交叉项的怀特检验“White Heteroskedasticityno cross terms”这样两个选择;问题:如果是刚做完上面的G-Q检验,如何得到原始模型答案:先恢复成全样本,再按T排序,然后做OLS回归;SMPL 1 31 意思是:将样本区间恢复到1-31补充:将样本数据按T升序排列,使数据顺序还原;Sort T 意思是:将数据顺序还原Ls LY C LX1 LX2下面是在原始模型的OLS方程对象窗口中,选择view/Residual test/White Heteroskedasticity,然后进行包含交叉项的怀特检验“White Heteroskedasticitycross terms”所得到的输出结果最上方显示了两个检验统计量:F统计量和White统计量nR2;下方显示的是以OLS的残差平方为被解释变量的辅助回归方程的回归结果:F-statistic ProbabilityTest Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 05/03/11 Time: 17:21Sample: 1 31C LNX1 LNX1^2 LNX1LNX2 LNX2 R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic 可见,怀特统计量nR 2==31×,大于自由度也即辅助回归方程中解释变量的个数为5的2分布临界值07.115205.0=)(χ,因此,在5%的显着性水平下拒绝同方差的原假设; 五、采用加权最小二乘法处理异方差以下内容和教材P118-120不一样,但是我们必须掌握的重点——以原始模型的OLS 回归残差的绝对值的倒数为权数,手工完成加权最小二乘估计LS LY C LX1 LX2Genr E=resid 意思是:记录双对数模型OLS 估计的残差 用残差的绝对值的倒数对LY 、LX1、LX2做加权: Genr LYE=LY/abs E Genr LX1E=LX1/abs E Genr LX2E=LX2/abs E Genr CE=1/abs E LS LYE CE LX1E LX2EDependent Variable: LYE Method: Least Squares Sample: 1 31CELX1ER-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Durbin-Watson stat可以看出,lnX1参数的t统计量有了显着改进,这表明在1%显着性水平下,都不能拒绝从事农业生产带来的纯收入对农户人均消费支出有着显着影响的假设;六、检验加权的回归模型是否还存在异方差1.检验是否由LX1E引起异方差Sort LX1E 意思是:将原始数据按LX1E升序排列①子样本1的回归:Smpl 1 12LS LYE CE LX1E LX2EDependent Variable: LYEMethod: Least SquaresSample: 1 12Variable Coefficient Std. Error t-Statistic Prob.CELX1ER-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid Schwarz criterionLog likelihood Durbin-Watson stat子样本1:RSS=1②子样本2的回归:Smpl 20 31LS LYE CE LX1E LX2EDependent Variable: LYE Method: Least Squares Date: 05/01/11 Time: 23:23 Sample: 20 31Variable CoefficientStd. Errort-StatisticProb.CE LX1E R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihoodDurbin-Watson stat子样本2:2RSS =③异方差检验 注意做题的步骤提出假设 22012:H σσ= 22112:H σσ≠ 计算检验统计量:在5%的显着性水平下,自由度为9,9的F 分布临界值分别为0.05(9,9) 3.18F =;因此5%显着性水平下不能拒绝同方差假设;2.检验是否由LX2E 引起异方差Smpl 1 31 意思是:将样本区间复原Sort lx2e 意思是:将原始数据按LX2E 升序排列 ①子样本1的回归: Smpl 1 12LS LYE CE LX1E LX2EDependent Variable: LYE Method: Least Squares Sample: 1 12CE LX1E R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihoodDurbin-Watson stat子样本1:1RSS = ②子样本2的回归: Smpl 20 31LS LYE CE LX1E LX2EDependent Variable: LYE Method: Least Squares Sample: 20 31Included observations: 12CE LX1E R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihoodDurbin-Watson stat子样本2:2RSS =③异方差检验 注意做题的步骤提出假设 22012:H σσ= 22112:H σσ≠ 计算检验统计量:在5%的显着性水平下,自由度为9,9的F 分布临界值分别为0.05(9,9) 3.18F =;因此5%显着性水平下不能拒绝同方差假设;结论:用OLS 估计的残差绝对值的倒数作为权数,对存在异方差的模型加权,然后采用OLS估计,则一定会消除异方差;最终通过异方差检验的估计方程为:实验四序列相关性实验目的:在理解序列相关性的基本概念、序列相关的严重后果的基础上,掌握进行序列相关检验和处理的方法;熟练掌握Eviews软件的图示检验、DW检验、拉格朗日乘数LM检验等序列相关性检验方法和处理序列相关性的方法——广义差分法;实验内容:书P132例4.2.1:中国居民总量消费函数建立总量消费函数是进行宏观经济管理的重要手段;为了从总体上考察中国居民收入与消费的关系,P56表2.6.3给出了中国名义支出法国内生产总值GDP、名义居民总消费CONS以及表示宏观税负的税收总额TAX、表示价格变化的居民消费价格指数CPI1990=100,并由这些数据整理出实际支出法国内生产总值GDPC=GDP/CPI、居民实际消费总支出Y=CONS/CPI,以及实际可支配收入X=GDP-TAX/CPI;表2.6.3 中国居民总量消费支出与收入资料单位:亿元年份GDP CONS CPI TAX GDPC X Y19781979198019811982198319841985198619871988198919901991199219931994199519961997199819992000200120022003200420052006资料来源:根据中国统计年鉴2001,2007整理;实验步骤:一、创建文件1.建立工作文件CREATE A 1978 2006 其中的“A”表示年度数据2.录入与编辑数据Data X Y3.保存文件单击主菜单栏中File→Save或Save as→输入文件名、路径→保存;二、数据分析:趋势图Plot X Y 意思是:同时画出Y和X的趋势图从X和Y的趋势图中可看出它们存在共同变动趋势;三、OLS参数估计与统计检验LS Y C XDependent Variable: YMethod: Least Squares Sample: 1978 2006C R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterion Sum squared residSchwarz criterion Log likelihood F-statistic Durbin-Watson statProbF-statistic从OLS 估计的结果看,模型拟合较好:可决系数20.9880R =,截距项和斜率项的t 检验值均大于5%显着性水平下自由度为n-2=27的临界值0.025(27) 2.05t =;而且,斜率项符合经济理论中边际消费倾向在0与1之间的绝对收入假说;斜率项表明,在1978—2006年间,以1990年价计算的中国居民可支配总收入每增加1亿元,居民消费支出平均增加亿元;四、序列相关性检验 1.图示检验法①残差与时间t 的关系图趋势图 Plot resid②相邻两期残差之间的关系图 Scat resid-1 resid从两个关系图看出,随机误差项呈正序列相关性;.检验值为,表明在5%显着性水平下,n=29,k=2包括常数项,查表得1.34L d =, 1.48U d =,由于.= 1.34L d <=,故存在正序列相关;五、处理序列相关1.修正模型设定偏误剔除虚假序列相关首先面临的问题是,模型的序列相关是纯序列相关,还是由于模型设定有偏误而导致的虚假序列相关;从X 和Y 的趋势图中看到它们表现出共同的变动趋势,因此有理由怀疑较高的2R =部分地是由这一共同的变化趋势带来的;为了排除时间序列模型中这种随时间变动而具有的共同变化趋势的影响,一种解决方案是在模型中引入时间趋势项,将这种影响分离出来;由于本例中可支配收入X 与消费支出Y 均呈非线性变化态势,因此引入的时间变量TT=1,2,……,29以平方的形式出现,回归模型变化为:①编辑变量T data T在数据表中输入1-29; ②做如下的回归 Ls Y C X T^2Dependent Variable: Y Method: Least Squares Sample: 1978 2006 Included observations: 29C X T ^2R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid 6054792. Schwarz criterionLog likelihood F-statistic 得到如下的修正模型:可见,T 2的t 统计量显着;但是,修正的模型.值仍然较低,没有通过5%显着性水平下的.检验n=29,k=3时,27.1=L D ,56.1=U D ,因此该模型仍存在正序列相关性;补充:序列相关性的拉格朗日乘数检验LM检验在EViews软件中,如果在上面的OLS回归方程界面直接做残差序列的LM检验,那么得到的是如下结果,和书上P133结果不一致:原因:EViews在做LM检验时,为了不损失样本,把滞后残差序列的“前样本”缺失值设定为0Presample missing value lagged residuals set to zero.;这样,它的样本容量仍然是n,而不是n-p;回归结果和书上也有不同;解决办法:要使软件的LM检验结果和教材P133结果一致,办法是进行OLS估计之后,先把残差序列resid用genr生成另一序列e,再做辅助回归,即:genr e=resid先做含1阶滞后残差的辅助回归:ls e c x t^2 e-1Dependent Variable: EMethod: Least SquaresDate: 04/26/13 Time: 07:08Sample adjusted: 1979 2006Included observations: 28 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CXT^2E-1R-squared Mean dependent varAdjusted R-squared . dependent var. of regression Akaike info criterionSum squared resid 2103016. Schwarz criterionLog likelihood Hannan-Quinn criter.F-statistic Durbin-Watson statProbF-statisticLM检验统计量必须自己算:LM=n-pR2=29-1=由于该值大于显着性水平为5%、自由度为1的2分布临界值84.31205.0=)(χ,由此判断原模型存在1阶序列相关;再做含2阶滞后残差的辅助回归: ls e c x t^2 e-1 e-2Dependent Variable: E Method: Least Squares Date: 04/26/13 Time: 07:32 Sample adjusted: 1980 2006Included observations: 27 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob. C X T^2 E-1 E-2R-squaredMean dependent var Adjusted R-squared . dependent var . of regressionAkaike info criterion Sum squared resid 1806465. Schwarz criterion Log likelihood Hannan-Quinn criter. F-statistic Durbin-Watson statProbF-statisticLM 检验统计量必须自己算:LM=n-pR 2=29-2=由于该值大于显着性水平为5%、自由度为2的2分布临界值99.52205.0=)(χ,由此判断原模型存在序列相关;但2~-t e 的系数未通过5%的显着性检验,表明在5%的显着性水平下不存在2阶序列相关性;所以,结合前面含1阶、2阶滞后残差的辅助回归结果,可以判断在5%的显着性水平下仅存在1阶序列相关性;2.广义差分法处理序列相关①Ls Y C X T^2 AR1Dependent Variable: Y Method: Least Squares Sampleadjusted: 1979 2006Included observations: 28 after adjusting endpoints Variable CoefficientStd. Errort-StatisticProb.C X T^2 AR1R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid 2164144. Schwarz criterionLog likelihood F-statistic AR1前的参数值即为随机扰动项的1阶序列相关系数,在5%的显着性水平下显着;.= ,在5%显着性水平下,1.18.. 1.65L U d DWd =<<=样本容量为28,无法判断广义差分变换后模型是否已不存在序列相关;②继续引入AR2以下内容和教材P133-134的做法不同,但是我们必须掌握的基本做法Ls Y C X T ^2 AR1 AR2Dependent Variable: Y Method: Least Squares Sampleadjusted: 1980 2006Included observations: 27 after adjusting endpointsC X T^2 AR1 AR2R-squaredMean dependent var Adjusted R-squared. dependent var. of regression Akaike info criterionSum squared resid 1834086. Schwarz criterionLog likelihood F-statisticInverted AR Roots .53 .53+.32iAR2前的参数在10%的显着性水平下显着不为0;且.= ,接近于2,认为在10%显着性水平下,已不存在序列相关;但是,在5%的显着性水平下,则没必要引入AR2;注意:教材P133用LM检验的结果是,引入AR1 的回归方程在5%的显着性水平下已不存在序列相关性,因而不需要引入AR2;补充:下面是针对引入AR1的回归方程式的LM检验的命令操作和检验结果:首先,采用上面得到的1阶自回归系数1也即AR1的系数,做如下的1阶广义差分变量的OLS回归注:与式等价:Ls y-1 c x-1 t^t-1^2Dependent Variable: Y-1Method: Least SquaresDate: 06/02/13 Time: 11:07Sample adjusted: 1979 2006Included observations: 28 after adjustmentsVariable Coefficient Std. Error t-Statistic Prob.CX-1T^T-1^2R-squared M ean dependent varAdjusted R-squared . dependent var. of regression A kaike info criterionSum squared resid 2164144. S chwarz criterionLog likelihood H annan-Quinn criter.F-statistic D urbin-Watson statProbF-statistic然后,将上述1阶广义差分方程的残差序列resid 记为e :genr e=resid 最后,做如下的辅助回归:ls e c x-1 t^t-1^2 e-1Dependent Variable: E Method: Least Squares Date: 06/02/13 Time: 11:16 Sample adjusted: 1980 2006Included observations: 27 after adjustmentsVariable CoefficientStd. Errort-StatisticProb.C X-1 T^T-1^2 E-1R-squaredM ean dependent var Adjusted R-squared . dependent var . of regression A kaike info criterionSum squared resid 1965048. S chwarz criterionLog likelihood H annan-Quinn criter. F-statistic D urbin-Watson statProbF-statistic于是,LM 检验统计量:LM=27=;查表,当显着性水平为5%时,自由度为1的2的临界值)(1205.0χ为;上述LM <)(1205.0χ,表明模型的随机误差项已不存在序列相关;。
计量经济学实验答案--第三版

实验一P42第二章第6题=+GDP+Dependent Variable: YMethod: Least SquaresDate: 01/11/08 Time: 09:03Sample: 1985 1998Included observations: 14Variable Coefficient Std.Errort-Statistic Prob.C12596.271244.56710.121010.0000GDP26.954154.1203006.5417920.0000 R-squared0.781002 Meandependent var20168.57Adjusted R-squared 0.762752 S.D. dependentvar3512.487S.E. of regression 1710.865 Akaike infocriterion17.85895Sum squared resid 35124719 Schwarzcriterion17.95024Log likelihood-123.0126 F-statistic42.79505Durbin-Watsonstat0.859998 Prob(F-statistic)0.000028(10.1) ( 6.5), =0.78 =0.76(一)对回归方程的结构分析:是这个样本回归方程的斜率,它表示GDP每增加1亿元,某市将增加26.95的货物运输量;是样本回归方程的截距,它表示不受GDP影响的某市的货物运输量。
(二)统计检验=0.78,说明总离差平方和的78%被样本回归直线解释,有22%未被解释,因此,样本回归直线的拟合优度是可以的。
给出显著水平,查自由度v=14-2=12的t分布表,得临界值,,,固回归系数均显著不为零,回归模型中应包含常数项,GDP对Y有显著影响。
(三)预测2000年的某市货物运输量假如2000年某市以1980年不变价的国内生产总值为620亿元,得到2000年货物运输量的预测值29307.84万吨。
计量经济学上机实验

计量经济学上机实验上机实验一:一元线性回归模型实验目的:EViews软件的基本操作实验内容:对线性回归模型进行参数估计并进行检验上机步骤:中国内地2011年中国各地区城镇居民每百户计算机拥有量和人均总收入一.建立工作文件:1.在主菜单上点击File\New\Workfile;2.选择时间频率,A3.键入起始期和终止期,然后点击OK;二.输入数据:1.键入命令:DATA Y X2.输入每个变量的统计数据;3.关闭数组窗口(回答Yes);三.图形分析:1.趋势图:键入命令PLOT Y X2.相关图:键入命令 SCAT Y X 散点图:趋势图:上机结果:Yˆ11.958+0.003X=s (βˆ) 5.6228 0.0002t (βˆ) 2.1267 11.9826prob 0.0421 0.00002=0.831 R2=0.826 FR=143.584 prob(F)=0.0000上机实验二:多元线性回归模型实验目的:多元回归模型的建立、比较与筛选,掌握基本的操作要求并能根据理论对分析结果进行解释实验内容:对线性回归模型进行参数估计并进行检验上机步骤:商品的需求量与商品价格和消费者平均收入趋势图:散点图:上机结果:i Yˆ=132.5802-8.878007X1-0.038888X2s (βˆ) 57.118 4.291 0.419t (βˆ) 2.321 -2.069 -0.093prob 0.0533 0.0773 0.9286 R2=0.79 R2=0.73 F =13.14 prob(F)=0.00427三:非线性回归模型实验目的:EViews软件的基本操作实验内容:对线性回归模型进行参上机步骤:我国国有独立核算工业企业统计资料一.建立工作文件:1.在主菜单上点击File\New\Workfile;2.选择时间频率,A3.键入起始期和终止期,然后点击OK;二.输入数据:1.键入命令:DATA Y L K2.输入每个变量的统计数据;3.关闭数组窗口(回答Yes);三.图形分析:1.趋势图:键入命令PLOT Y K L2.相关图:键入命令 SCAT Y K L四.估计回归模型:键入命令LS Y C K L上机结果:Y =4047.866K1.262204L-1.227157s (βˆ) 17694.18 0232593 0.759696t (βˆ) 0.228768 5.426669 -1.615325prob 0.8242 0.0004 0.1407R2=0.989758 R2=0.987482 F=434.8689 prob(F)=0.0000上机实验四:异方差实验目的::掌握异方差的检验与调整方法的上机实现实验内容:我国制造工业利润函数行业销售销售行业销售销售实验步骤:一.检验异方差性1.图形分析检验:1) 观察Y、X相关图:SCAT Y X2) 残差分析:观察回归方程的残差图LS Y C X在方程窗口上点击Residual按钮;2. Goldfeld-Quant检验:SORT XSMPL 1 10LS Y C X(计算第一组残差平方和)SMPL 19 28LS Y C X(计算第二组残差平方和)计算F统计量,判断异方差性3.White检验:SMPL 1 28LS Y C X在方程窗口上点击:View\Residual\Test\White Heteroskedastcity 由概率值判断异方差性。
计量经济学上机作业试题以及答案
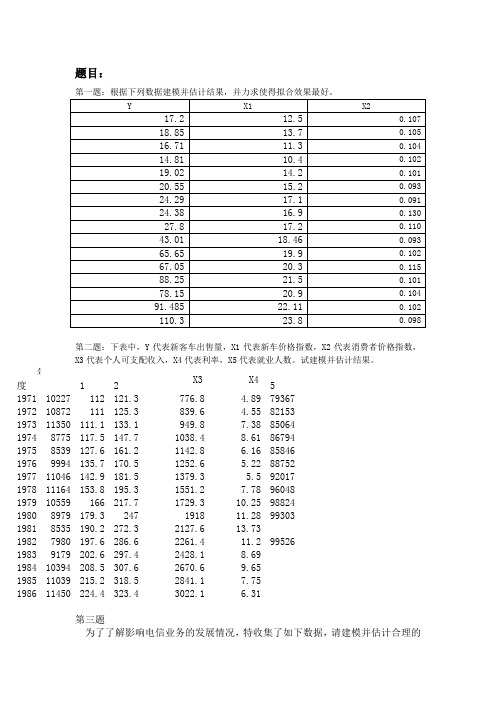
题目:第二题:下表中,Y代表新客车出售量,X1代表新车价格指数,X2代表消费者价格指数,X3代表个人可支配收入,X4代表利率,X5代表就业人数。
试建模并估计结果。
年度 1X2X3 X451971 10227 112 121.3 776.8 4.89 793671972 10872 111 125.3 839.6 4.55 821531973 11350 111.1 133.1 949.8 7.38 850641974 8775 117.5 147.7 1038.4 8.61 867941975 8539 127.6 161.2 1142.8 6.16 858461976 9994 135.7 170.5 1252.6 5.22 887521977 11046 142.9 181.5 1379.3 5.5 920171978 11164 153.8 195.3 1551.2 7.78 960481979 10559 166 217.7 1729.3 10.25 988241980 8979 179.3 247 1918 11.28 993031981 8535 190.2 272.3 2127.6 13.731982 7980 197.6 286.6 2261.4 11.2 995261983 9179 202.6 297.4 2428.1 8.691984 10394 208.5 307.6 2670.6 9.651985 11039 215.2 318.5 2841.1 7.751986 11450 224.4 323.4 3022.1 6.31第三题为了了解影响电信业务的发展情况,特收集了如下数据,请建模并估计合理的结果。
年电信业务总量邮政业务总量中国人口数市镇人口比重人均GDP人均消费水平1991 1.5163 0.5275 11.5823 0.2637 1.879 0.896 1992 2.2657 0.6367 11.7171 0.2763 2.287 1.070 1993 3.8245 0.8026 11.8517 0.2814 2.939 1.331 1994 5.9230 0.9589 11.9850 0.2862 3.923 1.746 1995 8.7551 1.1334 12.1121 0.2904 4.854 2.236 1996 12.0875 1.3329 12.2389 0.2937 5.576 2.641 1997 12.6895 1.4434 12.3626 0.2992 6.053 2.834 1998 22.6494 1.6628 12.4810 0.3040 6.307 2.972 1999 31.3238 1.9844 12.5909 0.3089 6.534 3.143第四题:X代表职工的工龄,Y代表薪水。
计量经济学上机实验报告
Sample: 1 31Included observations: 31Variable Coefficient Std. Error t-Statistic Prob.C 246.8540 51.97500 4.749476 0.0001X2 5.996865 1.406058 4.265020 0.0002X3 -0.524027 0.179280 -2.922950 0.0069X4 -2.265680 0.518837 -4.366842 0.0002R-squared 0.666062 Mean dependent var 16.77355Adjusted R-squared 0.628957 S.D.dependent var 8.252535S.E.of regression 5.026889 Akaike info criterion 6.187394Sum squared resid 682.2795 Schwarz criterion 6.372424Log likelihood -91.90460 F-statistic 17.95108Durbin-Watson stat 1.147253 Prob(F-statistic) 0.000001根据上图中数据,模型估计的结果为(51.9750) (1.4060) (0.1793) (0.5188)t= (4.7495) (4.2650) (-2.9229) (-4.3668)R2 =0.6289 F=17.9511 n=31对模型进行检验:拟合优度检验:=0.6660,R2 =0.6289 接近于1,说明模型对样本拟合较好F 检验:F=17.9511>,这说明在显著性水平a=0.05 下,回归方程是显著的。
T 检验:t 统计量分别为4.749476,4.265020,-2.922950,-4.366842,其绝对值均大于查表所得的(27)=2.0518,这说明在显著性水平a=0.05 下都是显著的。
江西财经大学计量经济学上机实验报告一答案
计量经济学实验报告实验(一):一元线性回归模型实验实验名称:一元线性回归模型实验【教学目标】《计量经济学》是实践性很强的学科,各种模型的估计通过借助计算机能很方便地实现,上机实习操作是《计量经济学》教学过程重要环节。
目的是使学生们能够很好地将书本中的理论应用到实践中,提高学生动手能力,掌握专业计量经济学软件EViews的基本操作与应用。
利用Eviews做一元线性回归模型参数的OLS估计、统计检验、点预测和区间预测。
【实验目的】使学生掌握1.Eviews基本操作:(1)数据的输入、编辑与序列生成;(2)散点图分析与描述统计分析;(3)数据文件的存贮、调用与转换。
2. 利用Eviews做一元线性回归模型参数的OLS估计、统计检验、点预测和区间预测【实验内容】1.Eviews基本操作:(1)数据的输入、编辑与序列生成;(2)散点图分析与描述统计分析;(3)数据文件的存贮、调用与转换;2. 利用Eviews做一元线性回归模型参数的OLS估计、统计检验、点预测和区间预测。
实验内容以课后练习:以62页计算题为例进行操作。
【实验步骤】1、建立深圳地方预算内财政收入对GDP的回归模型,建立EViews文件,利用地方预算内财政收入(Y)和GDP的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ利用EViews 估计其参数结果为即 tt GDP Y 134582.0611151.3ˆ+-= (4.16179) (0.003867)t=(-0.867692) (34.80013)R 2=0.99181 F=1211.049经检验说明,GDP 对地方财政收入确有显著影响。
R 2=0.99181,说明GDP 解释了地方财政收入变动的99%,模型拟合程度较好。
模型说明当GDP 每增长1亿元,平均说来地方财政收入将增长0.134582亿元。
计量经济学-参考答案chapter10
第十章一、名词解释1、结构式模型:根据经济理论和行为规律建立的描述经济变量之间直接关系结构的计量经济学方程系统称为结构式模型。
结构式模型中的每一个方程都是结构方程,将一个内生变量表示为其它内生变量、先决变量和随机误差项的函数形式,被称为结构方程的正规形式。
2、先决变量:模型中的外生变量和滞后内生变量被统称为先决变量,其含义是在模型求解时,这些变量已有所赋的值。
3、不可识别:如果联立方程计量经济学模型中某个结构方程不具有确定的统计形式,则称该方程为不可识别。
或者说如果从参数关系体系无法求出其结构方程的参数,则称该方程为不可识别。
如果一个模型系统中存在一个不可识别的随机方程,则认为该联立方程系统是不可识别的。
4、间接最小二乘法:先对关于内生解释变量的简化式方程采用普通最小二乘法估计简化式参数,得到简化式参数估计量,然后通过参数关系体系,计算得到的结构式参数的估计量,这种方法称为间接最小二乘法。
二、判断题1、√2、×3、√4、√5、√6、×7、×8、×三、单项选择题1、C2、B3、A4、 C5、 C6、 B7、B8、B9、B 10、B11、A 12、C 13、C 14、A15、D 16、C 17、C 18、D 19、B 20、B21、B 22、D 23、C 24、A四、多项选择题1、ADF2、ABCDE3、ABE4、ABCE五、简答题1、联立方程计量经济学模型的结构式BΓNY X+=中的第i个方程中包含gi个内生变量和ki 个先决变量,模型系统中内生变量和先决变量的数目用g和k表示,矩阵()BΓ00表示第i个方程中未包含的变量在其它g-1个方程中对应系数所组成的矩阵。
于是,判断第i个结构方程识别状态的结构式条件为:如果R g()BΓ001<-,则第i个结构方程不可识别;如果R g()BΓ001=-,则第i个结构方程可以识别,并且如果k k gi i-=-1,则第i个结构方程恰好识别,如果k k gi i->-1,则第i个结构方程过度识别。
第一次上机实习答案
2009年秋季学期经济学院本科生计量经济学上机考试题姓名:王麻子(学号后四位:XXX )考试成绩:注意:1.在规定时间内按照要求完成并提交:进行Eviews机上实例操作,将结果到WORD文档,进行判断,并作简要说明和分析。
2.题一为必做,题二鼓励做。
能做题二者可得加分,一二题全部做对者成绩评优秀。
题一:表1为1994-2004年我国出口贸易额与国内生产总值的两个时间序列。
试通过Eviews 建立随机计量模型:y t = β0 + β1 x t + u t来反映国内生产总值与出口额间的变化关系,并对估计结果进行讨论说明。
表1:历年出口贸易额与国内生产总值,(单位:亿元)年份EXP(Y)GDP(X)1994 46759.4 1210.11995 58478.1 1487.81996 67884.6 1510.51997 74462.6 1827.91998 78345.2 1837.11999 82067.5 1949.32000 89468.1 24922001 97314.8 26612002 105172.3 36562003 117390.2 4382.32004 136875.9 5933.2答:1.写出Eviews结果:那一张表Dependent Variable: YMethod: Least SquaresDate: 12/21/09 Time: 11:07Sample: 1994 2004C 41414.59 5118.481 8.091188 0.0000R-squared 0.917762 Mean dependent var 86747.15Adjusted R-squared 0.908625 S.D. dependent var 26282.71S.E. of regression 7944.830 Akaike info criterion 20.96140Sum squared resid 5.68E+08 Schwarz criterion 21.03374Log likelihood -113.2877 F-statistic 100.4388140000120000100000Y800006000040000100020003000400050006000X2.写出分析结果:那一个模型Y= 41414.59 + 17.22647XS.E. (5118.481)(1.718881)T (8.091188) (10.02191)R2=0.917762F=100.4388 DW=0.5533913.简要分析说明:从整体和局部给予评判其中括号里的为t检验值,R2 是可决系数,F与DW是有关两个检验统计量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《计量经济学》上机实验参考答案实验一:线性回归模型的估计、检验和预测(3 课时)实验设备:个人计算机,计量经济学软件Eviews,外围设备如U 盘。
实验目的:(1)熟悉Eviews 软件基本使用功能;(2)掌握一元线性回归模型的估计、检验和预测方法;正态性检验;(3)掌握多元线性回归模型的估计、检验和预测方法;(4)掌握多元非线性回归模型的估计方法;(5)掌握模型参数的线性约束检验与参数的稳定性检验。
实验方法与原理:Eviews 软件使用,普通最小二乘法(OLS),拟合优度评价、t 检验、F 检验、J-B 检验、预测原理。
实验要求:(1)熟悉和掌握描述统计和线性回归分析;(2)选择方程进行一元线性回归;(3)选择方程进行多元线性回归;(4)进行经济意义检验、拟合优度评价、参数显著性检验和回归方程显著性检验;(5)掌握被解释变量的点预测和区间预测;(6)估计对数模型、半对数模型、倒数模型、多项式模型模型等非线性回归模型。
实验内容与数据1(第2 章思考与练习:三、简答、分析与计算题第12 小题):12. 表1 数据是从某个行业的5 个不同的工厂收集的,请回答以下问题:ˆˆˆˆ(1)估计这个行业的线性总成本函数:yˆt= b0 + b1 x t ;(2)b0 和b1 的经济含义是什么?;(3)估计产量为10 时的总成本。
表1 某行业成本与产量数据参考答案:(1)总成本函数(标准格式):yˆt = 26.27679 + 4.25899xts = (3.211966) (0.367954)t = (8.180904) (11.57462)R 2 = 0.978098 S.E = 2.462819 DW =1.404274 F =133.9719ˆˆ(2) b0 =26.27679 为固定成本,即产量为0 时的成本;b1 =4.25899 为边际成本,即产量每增加1 单位时,总成本增加了4.25899 单位。
(3)产量为10 时的总成本为:yˆt = 26.27679 + 4.25899xt= 26.27679 + 4.25899 ×10 =68.86669实验内容与数据2(第2 章思考与练习:三、简答、分析与计算题第15 小题):15. 我国1978-2001 年的财政收入(y)和国民生产总值(x)的数据资料如表4 所示:表 4 我国1978-2001 年财政收入和国民生产总值数据iib 0 011 111试根据资料完成下列问题:(1)给出模型 y t = b 0 + b 1 x t + u t 的回归报告和正态性检验,并解释回归系数的经济意义;(2)求置信度为 95%的回归系数的置信区间;(3)对所建立的回归方程进行检验(包括估计标准误差评价、拟合优度检验、参数的显 著性检验);(4)若 2002 年国民生产总值为 103553.60 亿元,求 2002 年财政收入预测值及预测区 间(α = 0.05 )。
参考答案:(1)yˆt = 324.6844 + 0.133561x t s (b ˆ ) = (317.5155) (0.007069)t (b ˆ ) = (1.022578) (18.89340)R 2 = 0.941946SE = σˆ =1065.056DW = 0.30991 F = 356.9607ˆ = 0.133561 ,说明 GNP 每增加 1 亿元,财政收入将平均增加 1335.61 万元。
(2) b 0 = b ˆ ± t α / 2 (n − 2) ⋅ s (b ˆ ) =324.6844 ± 2.0739 × 317.5155=(-333.8466 983.1442)b = b ˆ ± t α / 2 (n − 2) ⋅ s (b ˆ ) =0.133561 ± 2.0739 × 0.007069=(0.118901 0.148221)(3)①经济意义检验:从经济意义上看,b ˆ = 0.133561〉0 ,符合经济理论中财政收入随着 GNP 增加而增加,表明 GNP 每增加 1 亿元,财政收入将平均增加 1335.61 万元。
1x 2 ②估计标准误差评价: SE = σˆ = 1065.056 ,即估计标准误差为1065.056亿元,它代表我国财政收入估计值与实际值之间的平均误差为1065.056亿元。
③拟合优度检验: R 2= 0.941946 ,这说明样本回归直线的解释能力为94.2%,它代表 我国财政收入变动中,由解释变量GNP 解释的部分占94.2%,说明模型的拟合优度较高。
④参数显著性检验:t (b ˆ ) = 18.8934 〉 t0.025 (22) = 2.0739 ,说明国民生产总值对财政收入的影响是显著的。
(4) x 2002 = 103553.6 ,yˆ2002 = 324.6844 + 0.133561×103553.6 = 14155.41根据此表可计算如下结果:∑( x t− x )2= σ 2 ⋅ (n − 1) = (32735.47)2 × 23 = 2.27 ×1010( x 2002 − x ) = (103553.6 − 32735.47)2 = 5.02 ×109 ,1 ( x f − x )2y ˆ f ± t α / 2 (n − 2) ⋅ σˆ ⋅ 1 + + n ∑( x t − x )215.02 ×109= 14155.41 ± 2.0739 ×1065.506 × 1 + +24 2.27 ×1010=(11672.2 16638.62)实验内容与数据 3(第 3 章思考与练习:三、简答、分析与计算题第 12 小题):12. 表1 给出某地区职工平均消费水平 y t ,职工平均收入 x 1t 和生活费用价格指数 x 2t ,试根据模型y t = b 0 + b 1 x 1t + b 2 x 2t + u t 作回归分析报告。
表 1 某地区职工收入、消费和生活费用价格指数年份y t x 1t x 2t年份y t x 1t x 2tii12(1)yˆt = 10.45741 + 0.634817 x 1t − 8.963759x 2t s (b ˆ ) = (6.685015) (0.031574) (5.384905)t (b ˆ ) = (1.564306) (20.10578) (-1.664608)R 2 = 0.980321R 2 = 0.975948 SE = σˆ =208.5572F = 224.1705(2) ①经济意义检验:从经济意义上看, 0〈b ˆ = 0.6348〈1 ,符合经济理论中绝对收入假说边际消费倾向在 0 与 l 之间,表明职工平均收入每增加 100 元,职工消费水平平均增加 63.48 元。
b ˆ = −8.964〈0 ,符合经济意义,表明职工消费水平随着生活费用价格指数的提高而下降,生活费用价格指数每提高 1 单位时,职工消费水平将下降-8.964 个单位。
②估计标准误差评价: SE = σˆ = 208.5572 ,即估计标准误差为208.5572单位,它代表职工平均消费水平估计值与实际值之间的平均误差为208.5572单位。
③拟合优度检验: R 2= 0.975948 ,这说明样本回归直线的解释能力为 97.6%,它代 表职工平均消费水平变动中,由解释变量职工平均收入解释的部分占 97.6%,说明模型的拟12合优度较高。
④F 检验: F = 224.1705 〉 F α (k , n − k − 1) = F α (2,12 − 2 − 1) = 4.26 ,表明总体回归 方程显著,即职工平均收入和生活费用价格指数对职工消费水平的影响在整体上是显著的。
⑤t 检验:t (b ˆ ) = 20.10578 〉 t0.025(9) = 2.262 ,说明职工平均收入对职工消费水平的影响是显著的; t (b ˆ ) = 1.664608〈 t0.025 (9) = 2.262 ,说明生活费用价格指数对职工消费水平的影响是不显著的。
实验内容与数据 4(第 3 章思考与练习:三、简答、分析与计算题第 14 小题):14. 某 地区统计了机电行业的销售额 y (万元)和汽车产量 x 1 (万辆)以及建筑业产值 x 2 (千万 元)的数据如表 2 所示。
试按照下面要求建立该地区机电行业的销售额和汽车产量以及建筑 业产值之间的回归方程,并进行检验(显著性水平α = 0.05 )。
表 2 某地区机电行业的销售额、汽车产量与建筑业产值数据i i121997877.6 7.752 47.38(1)根据上面的数据建立对数模型:ln y t = b 0 + b 1 ln x 1t + b 2 ln x 2t + u t(1)(2)所估计的回归系数是否显著?用 p 值回答这个问题。
(3)解释回归系数的意义。
(4)根据上面的数据建立线性回归模型:y t = b 0 + b 1 x 1t + b 2 x 2t + u t(2)(5)比较模型(1)、(2)的 R 2值。
(6)如果模型(1)、(2)的结论不同,你将选择哪一个回归模型?为什么? 参考答案: (1)回归结果yˆt = 3.734902 + 0.387929 l n x 1t + 0.56847 l n x 2t s (b ˆ ) = (0.212765) (0.137842) (0.055677)t (b ˆ ) = (17.5541) (2.814299) (10.21006)F = 99.81632R 2 = 0.934467R 2 = 0.925105SE = σˆ = 0.097431(2) t 检验: t (b ˆ ) = 2.814299 〉 t0.025(14) = 2.145 , p 1= 0.0138〈0.05 ,说明汽车产量对机电行业销售额的影响是显著的;t (b ˆ ) = 10.21006 〉 t0.025 (14) = 2.145 ,p 2 = 0.0000〈0.05 , 说明建筑业产值对机电行业销售额的影响是显著的。
F 检验:F = 99.81632 〉 F α (k , n − k − 1) = F α (2,17 − 2 − 1) = 3.74 ,p = 0.0000〈0.051b i i2表明总体回归方程显著,即汽车产量、建筑业产值对机电行业销售额的影响在整体上是显著的。
(3)b ˆ= 0.387929 ,说明汽车产量每增加 1%,机电行业的销售额将平均增加 0.39%;ˆ = 0.56847 ,说明建筑业产值每增加 1%,机电行业的销售额将平均增加 0.57%。