编译原理Chapter 11
编译原理第六章到第十一章课后习题答案
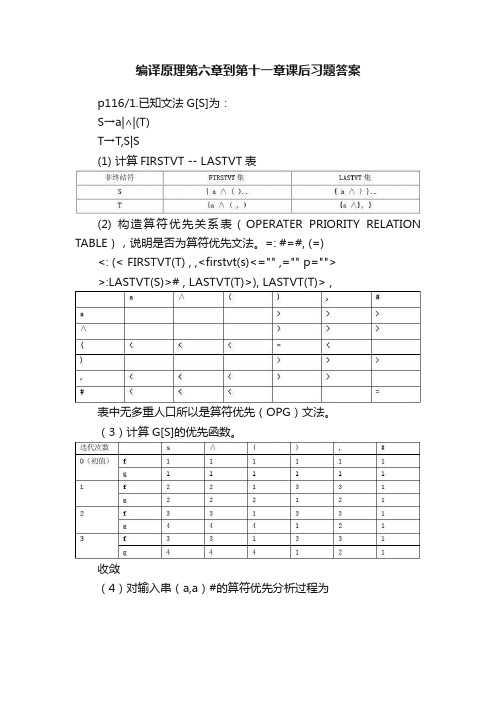
编译原理第六章到第十一章课后习题答案p116/1.已知文法G[S]为:S→a|∧|(T)T→T,S|S(1) 计算FIRSTVT -- LASTVT表(2) 构造算符优先关系表(OPERATER PRIORITY RELATION TABLE),说明是否为算符优先文法。
=: #=#, (=)<: (< FIRSTVT(T) , ,<firstvt(s)<="" ,="" p="">>:LASTVT(S)># , LASTVT(T)>), LASTVT(T)> ,表中无多重人口所以是算符优先(OPG)文法。
(3)计算G[S]的优先函数。
收敛(4)对输入串(a,a)#的算符优先分析过程为Success!3.有文法G(S):s->Vv->T/ViTT->F/T+FF->)V*|((1)(+(i(的规范推导S=>V=>ViT=>ViF=>Vi(=>Ti(=>T+Fi(=>T+(i(=>F+(i(=>(+(i((2)F+Fi(的短语、句柄、素短语。
短语S: F+Fi(T1:F+F (素短语)T2:F (句柄)F:( (素短语)(3) G(S)是否为OPG?若是,给出(1)中句子的分析过程!S’->#S# S->V V->T/ViT T->F/T+F F->)V*|(算符优先关系表(OPERATER PRIORITY RELATION TABLE)对输入串(+(I(的算符优先分析过程为:p152/2文法:S→L.L|LL→LB|BB→0|1拓广文法为G′,增加产生式S′→SI3若产生式排序为:0 S' →S1 S →L.L2 S →L3 L →LB4 L →B5 B →06 B →1由产生式知:First (S' ) = {0,1}First (S ) = {0,1}First (L ) = {0,1}First (B ) = {0,1}Follow(S' ) = {#}Follow(S ) = {#}Follow(L ) = {.,0,1,#}Follow(B ) = {.,0,1,#}G′的LR(0)项目集族及识别活前缀的DFA如下图所示:I5B →.0和B →.1为移进项目,S →L.为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
编译原理 课件第十一章

11.2 局部优化:基本块内的优化 局部优化:
基本块:是指程序中一顺序执行的语句序列, 基本块:是指程序中一顺序执行的语句序列,其中只有一个 入口语句和一个出口语句。 入口语句和一个出口语句。 入口语句: 入口语句: 1. 程序的第一个语句;或者, . 程序的第一个语句;或者, 2. 条件转移语句或无条件转移语句的转移目标语句;或者 . 条件转移语句或无条件转移语句的转移目标语句; 3. 紧跟在条件转移语句后面的语句。 . 紧跟在条件转移语句后面的语句。
main() { int x, y, z; x = (1+20)*( -x); ( ) y = x*x+(x/y); y = z = (x/y)/(x*x); }
tmp1 = 1 + 20 ; tmp2 = -x ; x = tmp1 * tmp2 ; tmp3 = x * x ; tmp4 = x / y ; y = tmp3 + tmp4 ; tmp5 = x / y ; tmp6 = x * x ; z = tmp5 / tmp6 ; y = z ;
11.1 11.2 11.3 11.4
什么是代码优化 局部优化 控制流程分析和循环 数据流分析举例
11.1 优化技术简介
何谓代码优化: 宗旨: 获得较好性能的代码 宗旨: 等价 意图,结果, 意图,结果,权衡 目标代码优化 阶段: source front I.R code target code generator code 用户 中间代码优化
第十一章 代码优化
为了让编译程序能够生成效率高的目标代码, 为了让编译程序能够生成效率高的目标代码, 应对中间代码进行优化 注意:优化≠ 注意:优化≠最佳化 要求:相对合理性。 要求:相对合理性。应考虑空间和时间上的 取舍,及二者的平衡。 取舍,及二者的平衡。 本章将介绍基于结构信息的优化 基于结构信息的优化。 本章将介绍基于结构信息的优化。 假定 优化对象是四元式序列的中间代码
编译原理 11章

11.2 优化举例
6:循环中不变式的外提 • Tl=2*j外提 • 由于这里的循环中不 变式的外提是在非线 性块上的优化,所以 是全局优化。 • 经这两步优化后,便 得到图11.4中所示的 中间程序。
① i:=1; ② T1:=2*j; ③ T2:=T1;
④ T2:=100+T2; ⑤ R1:=B[T2]; ⑥ A[T5]:=R1+15.708; ⑦ i:=i+1; ⑧ if i≤100 then goto ② ≤
11.2 优化举例
3:常量合并
① i:=1;
② T1:=2*j; ③ T2:=100i+T1; ④ T3:=5*3.1416; ⑤ R1:=B[T2]; ⑥ T4:=2*j; ⑦ T5:=100*i+T4; ⑧ A[T5]:=R1+T3; ⑨ i:=i+1; ⑩ if i≤100 then goto ② ≤
n4 n3
图11.6 环路图
11.5 借助 借助DAG进行优化 进行优化
2: 无环有向图描述四元式
• 可用无环有向图来描述四元式。 例如,与四元式(op B C A)对应的DAG如图11.7所示。 利用DAG来进行优化的主要思想是: 将一基本块中的每一个四元式依次表示成对应的一个DAG, 该基本块就对应一较大的DAG(即其中各个四元式的DAG的合成)。 再按原来构造DAG结点的顺序重写四元式序列,便可得到“合并 了已知量”、“删除了无用赋值”、“删除了多余运算”的等价 的基本块——优化了的基本块。
11.1 基本块及其求法
• 1:基本块 基本块: 一个入口(第一语句) 一个出口(最后一语句) 入口语句集: 程序的第一个语句号; goto语句的下一条语句号; goto语句转到的语句号。 基本块划分: 入口语句集排序后每一入口语句到下一入口语句号 的前一语句。 最后一基本块为最后入口语句号到最后语句。
编译原理蒋宗礼课件第11章

关键任务
进行类型检查、确定符号引 用的含义,以及生成中间代 码等。
工具
语义分析是编译过程中相当 复杂的一部分,通常需要使 用自定义的算法和工具进行 实现。
中间代码生成
1 什么是中间代码生成?
在编译过程的中间阶段,将源代码转化为计算机独立的中间表示形式。
2 优点
中间代码的生成可以简化编译器的设计和实现,并提供了优化和代码生成的灵活性。
编译原理蒋宗礼课件第11章
在本章中,我们将深入探讨编译原理的各个方面,包括词法分析、语法分析、 语义分析等等。
编译原理概述
什么是编译原理?
编译原理是计算机科学中的重要领域,研究如 何将高级语言编写的程序转化为计算机能够理 解和执行的机器码。
编译原理的应用
编译原理在各个领域都有广泛的应用,包括编 译器设计、程序语言设计以及软件工程等。
通过使用上下文无关文法 (Context-Free Grammar),语法 分析器可以验证源代码是否符合 语言的语法规则。
工具
常用的语法分析工具包括ANTLR、 Bison等,它们能够根据预先定义 好的文法生成语法分析器。
语义分析
什么是语义分析?
语义分析是编译过程中的第 三步,通过对语法树进行遍 历和分析,对源代码进行意 义的理解和检查。
为不同的Token类型,如标识符、关键字、
运算符等。
3
什么是词法分析?
词法分析是编译过程中的第一步,将源 代码转化为单词序列(Token Sequence)。
工具
常用的词法分析工具包括Flex等,它们能 够根据预先定义好的规则生成词法分析 器。
语法分析
什么是语法分析?
关键概念
语法分析是编译过程中的第二步, 将词法分析得到的Token序列转化 为语法树(Parse Tree)。
《编译原理-刘善梅》第11章 代码生成

尽可能用:后续的目标代码尽可能引用变量 在寄存器中的值,而不访问内存。
及时腾空:在离开基本块时,把存在寄存器 中的现行的值放到主存中。
ppt课件
15
11.3.1 待用信息
如果在一个基本块内,四元式i对A定值, 四元式j要引用A值,而从i到j之间没有A 的其他定值,那么,我们称j是四元式i的 变量A的待用信息。(即下一个引用点)
编译原理
第十一章 代码生成
ppt课件
1
源程序
词法分析器
符 号
语法分析器
错 误
管
处
理
语义分析器
理
表
器
中间代码生成器
代码优化器
代码生成器
ppt课件
2
第十一章 代码生成
基本问题 目标机器模型 一个简单代码生成器
ppt课件
3
代码生成是把语法分析后或优化后的中间代 码变换成目标代码。
目标代码一般有以下三种形式:
(4) W:=V+U (^,y)
(^,^)
(^,^)
(3) V:=T+U (4,y)
(^,^)
(4,y)
(2) U:=A-C (3,y) (1) T:=A-B (3,y)
(^,^) (2,y)
(^,^) (^,^)
变量名 T A B C U V W
初始状态→信息链(待用/活跃信息栏) (^,^) → (3,y) → (^,^) (^,^) → (2,y) → (1,y) (^,^) → (1,y) (^,^) → (2,y) (^,^) → (4,y) → (3,y) → (^,^) (^,^) → (4,y) → (^,^) (^,y) → (^,^)
编译原理第11章

W:= V + U
ADD R0 , R1
R0含有W
W在R0中
§11.3一个简单的代码生成器
§11.4寄存器分配
一、问题引入:如何有效的利用寄存器; 1、基本块内: ①运算对象的值在寄存器中,则把该寄存器作为操作数地址; ②尽可能把各变量的现行值保存在寄存器中; ③基本块中不再引用的变量所占用的寄存器及早释放; 2、循环内: 按执行代价把寄存器固定分配给几个变量单独使用; 二、指令的执行代价 1、定义:指令的执行代价=指令访问内存单元的次数+1 2、例:op Ri,Ri执行代价为1; op Ri,M执行代价为2; op Ri,*Ri执行代价为2; op Ri,*M执行代价为3 3、应用:对循环中每个变量计算把某寄存器分配给它时执行代 价能节省多少,以决定寄存器的固定分配方案;
三、寄存器描述和地址描述 1、寄存器描述数组RValue:记录寄存器使用情况(空闲或已分配) 2、变量地址描述数组AValue:记录各变量现行值的存放位置(在 寄存器或内存单元); 四、基本块内代码生成算法 对块内每个中间代码 i: A:= B op C,依次执行:
调用GetReg(i:A:=B op C)得一寄存器R,用以存放A现行值; 利用AValue[B]和AValue[C]确定B和C现行值的存放位置B 和C 若B ≠R 则生成目标代码:LD R,B 和op R,C 若B =R 则生成op R,C 若B 或C 为R 则删除AValue[B]或AValue[C]中的R 令AValue[A]={R},RValue[R]={A} 若B或C的现行值在块内不再被引用且也不是块出口后的活跃变量 (由中间代码i的附加信息可知)且现行值在某寄存器Rk中 则删除RValue[Rk]中的B或C及AValue[B]或AValue[C]中的Rk
编译原理课后第十一章答案
对假设(2) B:=3 D:=A+C E:=A*C F:=D+E K:=B*5 L:=K+F
计算机咨询网()陪着您
10
《编译原理》课后习题答案第十一章
第7题 分别对图 11.25 和 11.26 的流图: (1) 求出流图中各结点 n 的必经结点集 D(n)。 (2) 求出流图中的回边。 (3) 求出流图中的循环。
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13)
i:=m-1 j:=n t1:=4*n v:=a[t1] i:=i+1 t2:=4*i t3:=a[t2] if t3< v goto (5) j:=j-1 t5:=4*j t5:=a[t4] if t5> v goto (9) if i >=编译原理》课后习题答案第十一章
第 5 题: 如下程序流图(图 11.24)中,B3 中的 i∶=2 是循环不变量,可以将其提到前置结点吗? 你还能举出一些例子说明循环不变量外移的条件吗?
图 11.24 答案: 不能。因为 B3 不是循环出口 B4 的必经结点。 循环不变量外移的条件外有: (a)(I)s 所在的结点是 L 的所有出口结点的必经结点 (II)A 在 L 中其他地方未再定值 (III)L 中所有 A 的引用点只有 s 中 A 的定值才能到达 (b)A 在离开 L 之后不再是活跃的,并且条件(a)的(II)和(III)成立。所谓 A 在离开 L 后不再是活跃的是指,A 在 L 的任何出口结点的后继结点的入口处不是活跃的(从此点后 不被引用) (3)按步骤(1)所找出的不变运算的顺序,依次把符合(2)的条件(a)或(b)的 不变运算 s 外提到 L 的前置结点中。如果 s 的运算对象(B 或 C)是在 L 中定值的,则只有 当这些定值四元式都已外提到前置结点中时,才可把 s 也外提到前置结点。
编译原理课件chap11
•
窥孔优化 几种窥孔优化的方法都比较好理解,这里不再重述课本 内容。
第十一章 目标代码生成
例题与习题解答
[例11。1]假设只有R0和R1两个寄存器,对赋值语句d
= (a-b) + (a-c) + (a-c)生成目标代码。并写出寄存器描 述数组RVALUE和变量地址描述数组AVALUE. 该赋值语句的三地址序列: t := a-b t1 := a-c t2 := t + t1 d := t1 + t2 将此代码看成一基本块,并设在基本块末尾,变量 d是活跃的。生成目标代码表如图:
(3)汇编语言代码,尚须经过汇编程序汇编,转换成
可执行的机器代码。 代码生成器着重考虑两个问题: 一是如何使生成的 目标代码较短;另一个是如何充分利用计算机的寄存 器,减少目标代码中访问存储单元的次数。这两个问 题直接影响代码的执行速度。
第十一章 目标代码生成
• 基本问题:所有代码生成器都要面对何种中间代码输入,
下面我们学习一个例子,一加深其理解:
[例11。6] 考察下面中间代码序列 G1:
第十一章 目标代码生成
T1 := A+B T2 := A- B F := T1 * T2 T1 := A- B T2 := A – C T3 := B - C T1 := T1 * T2 G := T1 * T3 其对应的DAG如图 * F - n2 * T1
第十一章 目标代码生成
第十二章并行编译基础
并行计算机是近二十几年来发展迅速的一类计 算机。并行编译系统已经成为了现代高性能计算 机系统中一个重要的部分。并行程序设计主要有 两种途径,即使用并行程序设计语言编写并行程 序,或将串行程序并行化。因此,并行编译系统 就是能够处理并程序设计语言,能够实现串行程 序并行化。具有并行优化能力的编译系统。在这 个问题上我们只是要求了解。
编译原理考试习题及答案
( T ② S ① a
T ,
T ④ S ③ a
2019/1/29
CH.5.练习题3(P133.)
3.(1) 计算练习2文法G2的FIRSTVT和LASTVT。 S→a||(T) T→T,S|S
(1) 解: (执行相应的算法可求得) FIRSTVT(S)={ a, ∧, ( } FIRSTVT(T)={ , , a, ∧, ( } LASTVT(S)={ a, ∧, ) } LASTVT(T)={ , , a, ∧, ) }
(1) 正规式 1(0|1)*101
0
0
DFA:
3,2
1 0
3,5,2
1 1 0
x
1
1,3,2
1
0
3,4,2
1
3,Y,4,2 I0 I1 1 3 3 3 5 3
I {X} {1,3,2} {3,2} {3,4,2} {3,5,2} {3,Y,4,2}
I0 {3,2} {3,2} {3,5,2} {3,2} {3,5,2}
2019/1/29 22
CH.5.练习题2(P133.)
2.(2).给出(a,(a,a))“移进-归约”的过程。 (2) 解: (a,(a,a))的“移进-归约”过程: 步骤 符号栈 输入串 动作 9 #(T,( S ,a))# 归约 S → a 10 #(T,(T , a ))# 归约 T → S 11 #(T,(T, a ))# 移进 , 12 #(T,(T, a ))# 移进 a 13 #(T,( T,S ))# 归约 S → a 14 #(T, (T ) )# 归约 T → T,S 15 #(T, (T) )# 移进 ) 16 #( T, S )# 归约 S → (T)
编译原理第11章
确定映射方式的两种方法 1.由声明时的语法确定映射方式: a:array[d1] of array[d2]of...array[dn] of integer; 引用方式:a[i1,i2, ...,in]或a[i1][i2]...[in] 2.由编译器确定映射方式: a : array [d1, d2, ..., dn] of integer; 引用方式:a[i1,i2, ...,in] 数组元素引用时地址的确定: 1.根据映射方式求出计算公式; 2.根据计算公式设计语义规则。
B if C then false else true false
15
<3> 短路计算的必要性 对于语句: while ptr<>nil and ptr^.data=x do ... 短路计算可以回避对ptr^.data=x的判断,从而避免程序运行 时错误。 可以用语法规定短路计算。例如, Ada语言中提供两组运算: and 和 and then or 和 or else 短路计算时使用and then和or else,否则使用and和or。 于是上述语句可以改写为: while ptr/=null and then ptr^.data/=x loop ...
8
<3>语义规则(续1) (6) E→E1+E2 { T:=newtemp; emit(T ':=' E1.place '+' E2.place); E.place:=T;} (7) E→(E1){ E.place:=E1.place;} (8) E→V { if V.offset=null; then E.place:=V.place; else T:=newtemp; emit(T ':=' V.place '['V.offset']'); E.place:=T; end if;}
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基本块划分算法
prev
STEP1 求出各个入口语句 STEP2 对每个入口语句,构造其所属的基本块。 即由该入口语句到下一个入口语句(不包含该 语句), 或到一转移语句(包含该语句), 或到一停语句(包含该语句) 之间的语句序列组成 STEP3 凡是未被纳入某个基本块中的语句,都 是程序控制流程中无法到达的语句,也是不会 被执行的语句,因此,可以删除掉
B1
B2
prev
12
next 12
合并已知量和复写传播
dir
合并已知量
(3)计算4*I时,I必为1, 故在编译时即可知T1的值 为4
1 2 4 7 3 5 6 8 9 10 3’ 12
P :=0 I :=1 T2:=addr(A)-4 T5:=addr(B)-4 4 T1:=4*I T3:=T2[T1] T4:=T1 T6:=T T5[T4 1] T7:=T3*T6 P :=P+T7 T1:=T1+4 If T1<=80 goto(3)
根据代码优化的阶段
源代码 前端 中间代码 代码生成 目标代码
中间代码优化
prev
目标代码优化
next 3
dir
依据优化所涉及的程序范围
局部优化 指的是在只有一个入口、一个出 口的基本程序块上进行的优化 循环优化 是对循环中的代码进行优化 全局优化 是整个程序范围内进行优化
prev
next 4
P :=0 I :=1 T2:=addr(A)-4 T5:=addr(B)-4 T1:=4 T3:=T2[T1] T4:=T1 T6:=T5[T1] T7:=T3*T6 P :=P+T7 T1:=T1+4 If T1<=80 goto(3)
B1
B2
prev
next 14
11.2 局部优化
dir
局部优化是指基本块内的优化
源程序
dir
优化技术举例 中间代码
1 P :=0 I :=1 T1:=4*I T2:=addr(A)-4 T3:=T2[T1] 2 3 4 5
P:=0
B1
for I:=1 to 20 do
P:=P+A[I]*B[I]; 设数组A[1..20]、B[1..20], 且元素大小为4个字节 ————————————— 对源程序编译后得到中间代码中 间代码由B1和B2两部分组成B2为 循环部分
prev
next 22
基本块DAG的表示
dir
0型 1型
A:=B A:=op B
2型
A:=B op C
A:=B[C]
说明: • 结点下面的符号表示各 结点的标记 • 结点右侧的标识符是结 点的附加标识符
n3 A op
n1 B n2 C n1 B
n1 A
B
n1 A op
n2 B
n3 A
=[]
n2 C
B1
复写传播
T1的值复写到T4中,(8) 要引用T4的值,而(6)到 (8)之间未改变T4和T1的 值,则(8)改为 T6:=T5[T1],结果不变
B2
prev
next 13
删除无用赋值
dir
将代码中无用的四元式 删除 I和T4在程序中没有被 引用所以应删除
1 2 4 7 3 5 6 8 9 10 3’ 12
B1
6
7 8 9 10 11 12
B2
prev
next 7
代码外提
dir
目的 在于减少循环 中代码总数 操作
把循环中不变运算, 即其结果独立于循环 执行次数的表达式, 提到循环外(前面)
使之只在循环外计算 一次 将(4)和(7)提到循 环外
prev
1 2 3 4 5 6
P :=0 I :=1 T1:=4*I T2:=addr(A)-4 T3:=T2[T1] T4:=T1
B1
7
8 9 10 11
T5:=addr(B)-4
T6:=T5[T4] T7:=T3*T6 P :=P+T7 I :=I+1
B2
12
If I<=20 goto (3)
next 8
代码外提
dir
目的 在于减少循环 中代码总数 操作
把循环中不变运算, 即其结果独立于循环 执行次数的表达式, 提到循环外(前面)
n8
有向图
next 21
说明:本节的有向图是一种其结点有下述标
dir
记或附加信息DAG
图的叶节点,即无后继的节点。 以一标识符(变量名)或常数作为标记,表示该 节点代表该变量或常数 图的内部节点,即有后继的节点。 以一运算符作为标记,表示该节点代表应用该运 算符对其后继节点所代表的值进行运算的结果 图中各个节点上可能附加一个或多个标识符,表 示这些变量具有该节点所代表的值
A:=B
prev
A:=op B
step2
A:=B op C
step3
A:=B[C]
step1
next
23
dir
if B rop C goto (s)
3型 D[C]:=B goto(s)
n3 (s) rop
n3 (s)
[]=
n1 (S)
n1
B
n2 C
n1
D
n2 C
n3 B goto(s)
if B rop C goto (s)
17
next
基本块划分举例
dir
1 2 3
P :=0 I :=1 T1:=4*I
1 2 3 4
P :=0 I :=1 T1:=4*I T2:=addr(A)-4
B1
4
5 6 7 8 9 10 11
prev
T2:=addr(A)-4
T3:=T2[T1] T4:=4*I T5:=addr(B)-4 T6:=T5[T4] T7:=T3*T6 P :=P+T7 I :=I+1 If I<=20 goto (3)
prev next 20
DAG的概念
dir
如果有向图中任一个通路都不是环路,则称
该有向图为无环路有向图。简称DAG 在DAG中,如果(n1,n2„nk)是其中一条通 路,则称结点n1为nk的祖先,结点nk为n1的后 代
n1 n4
prev
n2 n2 n3
n1
n4
n6
n3 n5
n7 n9 DAG
5
6 7 8 9 10 11
T3:=T2[T1]
T4:=4*I T5:=addr(B)-4 T6:=T5[T4] T7:=T3*T6 P :=P+T7 I :=I+1
B2
12
12
If I<=20 goto (3)
18
next
基本块的变换
dir
变换条件
变换必须是等价的
基本块的变换通常有两类
保结构的变换 删除公共子表达式、删除无用 代码、重新命名临时变量、交换语句次序 代数变换 把基本块计算的表达式集合变换成 代数等价的集合。目的是简化表达式或者用较 快运算代替较慢运算
prev next 19
基本块的DAG表示
dir
相关概念
一个有向图中有n个节点。对于任意一个有
向边 ni→nj,ni为前驱(父节点),nj为后 继(子节点) 对于任意一个有向边序列,n1→n2、n2→n3 „、nk-1→nk ,称为从节点n1到nk的一条通路。 如果n1=nk ,则称该通路为环路
使之只在循环外计算 一次 将(4)和(7)提到循 环外
prev
1 2 4 7 3 5 6 8
P :=0 I :=1 T2:=addr(A)-4 T5:=addr(B)-4 T1:=4*I T3:=T2[T1] T4:=T1 T6:=T5[T4]
B1
B2
9
10 11 12
T7:=T3*T6
P :=P+T7 I :=I+1 If I<=20 goto (3)
prev
D[C]:=B
next 24
基本块DAG的构造算法
dir
说明:该算法只针对0、1、2型四元式
DAG
首先,DGA为空。 然后,对基本块的每个四元式,依次执行 第一步骤 ——构造四元式的叶结点
如果NODE(B)无定义,则构造一标记为B的叶结点并定 义NODE(B)为这个结点 1. 如果当前四元式是0型,则记NODE(B)的值为n,转4 2. 如果当前四元式是1型,则转2(1) 3. 如果当前四元式是2型,则:如果NODE(C)无定义,则 构造一标记为C的叶结点并定义NODE(C)为这个结点; 转2(3)
next 9
强度削弱
dir
强度削弱的思想是把强 度大的运算换算成强度 小的运算
将乘法换算成加法的运算 就是强度削弱
1 2 4 7 3 5 6 8
P :=0 I :=1 T2:=addr(A)-4 T5:=addr(B)-4 T1:=4*I T3:=T2[T1] T4:=T1 T6:=T5[T4]
将乘法换算成加法的运算 就是强度削弱
1 2 4 7 3 5 6 8 9 10 11 3’
P :=0 I :=1 T2:=addr(A)-4 T5:=addr(B)-4 T1:=4*I T3:=T2[T1] T4:=T1 T6:=T5[T4] T7:=T3*T6 P :=P+T7 I :=I+1 T1:=T1+4
North china electric power university
第十一章
dir
代码优化
11.1
优化技术简介 11.2 局部优化 11.3 控制流分析和循环优化 11.4 数据流的分析和全局优化