四章OpenMP多线程编程
Unix_Linux_Windows_OpenMP多线程编程

Unix_Linux_Windows_OpenMP多线程编程第三章 Unix/Linux 多线程编程[引言]本章在前面章节多线程编程基础知识的基础上,着重介绍 Unix/Linux 系统下的多线程编程接口及编程技术。
3.1 POSIX 的一些基本知识POSIX 是可移植操作系统接口(Portable Operating SystemInterface)的首字母缩写。
POSIX 是基于 UNIX 的,这一标准意在期望获得源代码级的软件可移植性。
换句话说,为一个 POSIX 兼容的操作系统编写的程序,应该可以在任何其它的 POSIX 操作系统(即使是来自另一个厂商)上编译执行。
POSIX 标准定义了操作系统应该为应用程序提供的接口:系统调用集。
POSIX是由 IEEE(Institute of Electrical andElectronic Engineering)开发的,并由 ANSI(American National Standards Institute)和 ISO(International StandardsOrganization)标准化。
大多数的操作系统(包括 Windows NT)都倾向于开发它们的变体版本与 POSIX 兼容。
POSIX 现在已经发展成为一个非常庞大的标准族,某些部分正处在开发过程中。
表 1-1 给出了 POSIX 标准的几个重要组成部分。
POSIX 与 IEEE 1003 和 2003 家族的标准是可互换的。
除 1003.1 之外,1003 和 2003 家族也包括在表中。
管理 POSIX 开放式系统环境(OSE) 。
IEEE 在 1995 年通过了这项标准。
ISO 的1003.0版本是 ISO/IEC 14252:1996。
被广泛接受、用于源代码级别的可移植性标准。
1003.1 提供一个操作系统的C 语1003.1 言应用编程接口(API) 。
IEEE 和 ISO 已经在 1990 年通过了这个标准,IEEE 在1995 年重新修订了该标准。
在C++中使用openmp进行多线程编程

在C++中使⽤openmp进⾏多线程编程在C++中使⽤openmp进⾏多线程编程⼀、前⾔多线程在实际的编程中的重要性不⾔⽽喻。
对于C++⽽⾔,当我们需要使⽤多线程时,可以使⽤boost::thread库或者⾃从C++ 11开始⽀持的std::thread,也可以使⽤操作系统相关的线程API,如在Linux上,可以使⽤pthread库。
除此之外,还可以使⽤omp来使⽤多线程。
它的好处是跨平台,使⽤简单。
在Linux平台上,如果需要使⽤omp,只需在编译时使⽤"-fopenmp"指令。
在Windows的visual studio开发环境中,开启omp⽀持的步骤为“项⽬属性 -> C/C++ -> 所有选项 -> openmp⽀持 -> 是(/openmp)”。
本⽂我们就介绍omp在C++中的使⽤⽅法。
⼆、c++ openmp⼊门简介openmp是由⼀系列#paragma指令组成,这些指令控制如何多线程的执⾏程序。
另外,即使编译器不⽀持omp,程序也也能够正常运⾏,只是程序不会多线程并⾏运⾏。
以下为使⽤omp的简单的例⼦:int main(){vector<int> vecInt(100);#pragma omp parallel forfor (int i = 0; i < vecInt.size(); ++i){vecInt[i] = i*i;}return 0;}12345678910以上代码会⾃动以多线程的⽅式运⾏for循环中的内容。
如果你删除"#pragma omp parallel for"这⾏,程序依然能够正常运⾏,唯⼀的区别在于程序是在单线程中执⾏。
由于C和C++的标准规定,当编译器遇到⽆法识别的"#pragma"指令时,编译器⾃动忽略这条指令。
所以即使编译器不⽀持omp,也不会影响程序的编译和运⾏。
OpenMP简介

OpenMP提供了schedule子句来实现任务的调度。
schedule子句
schedule(type, size), 参数type是指调度的类型,可以取值为static,dynamic,guided三种值。 参数size表示每次调度的迭代数量,必须是整数。该参数是可选的。 2. 3. 动态调度 启发式调度 dynamic guided 1. 静态调度 static 采用启发式调度方法进行调度,每次分配给线程迭代次数不同,开始比较大, 动态调度依赖于运行时的状态动态确定线程所执行的迭代,也就是线程执行完 static在编译的时候就已经确定了,那些循环由哪些线程执行。 以后逐渐减小。 已经分配的任务后,会去领取还有的任务。由于线程启动和执行完的时间不确 当不使用size 时,将给每个线程分配┌N/t┐个迭代。当使用size时,将每 size 表示每次分配的迭代次数的最小值,由于每次分配的迭代次数会逐渐减少, 定,所以迭代被分配到哪个线程是无法事先知道的。 次给线程分配size次迭代。 少到 size时,将不再减少。如果不知道 size的大小,那么默认size 为1 ,即一直减少 当不使用 size 时,是将迭代逐个地分配到各个线程。当使用 size 时,逐个 到1 。具体采用哪一种启发式算法,需要参考具体的编译器和相关手册的信息。 分配 size 个迭代给各个线程。
用for语句来分摊是由系统自动进行,只要每次循环间没有时间 上的差距,那么分摊是很均匀的,使用section来划分线程是一种手 工划分线程的方式,最终并行性的好坏得依赖于程序员。
OpenMP中的线程任务调度
OpenMP中任务调度主要针对并行的for循环,当循环中每次迭代的计算量 不相等时,如果简单地给各个线程分配相同次数的迭代,则可能会造成各个线 程计算负载的不平衡,影响程序的整体性能。
实验二 :OpenMP多线程编程
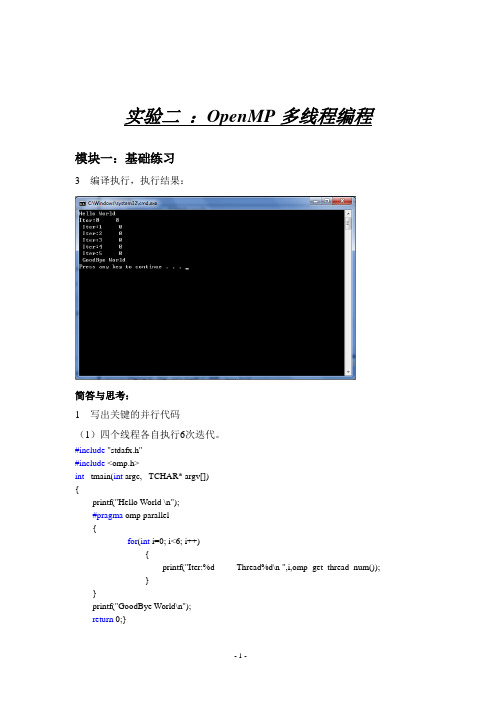
实验二:OpenMP多线程编程模块一:基础练习3 编译执行,执行结果:简答与思考:1 写出关键的并行代码(1)四个线程各自执行6次迭代。
#include "stdafx.h"#include <omp.h>int _tmain(int argc, _TCHAR* argv[]){printf("Hello World \n");#pragma omp parallel{for(int i=0; i<6; i++){printf("Iter:%d Thread%d\n ",i,omp_get_thread_num());}}printf("GoodBye World\n");return 0;}(2)四个线程协同完成6次迭代。
#include "stdafx.h"#include <omp.h>int _tmain(int argc, _TCHAR* argv[]){printf("Hello World \n");#pragma omp parallel{#pragma omp forfor(int i=0; i<6; i++){printf("Iter:%d Thread%d\n ",i,omp_get_thread_num());}}printf("GoodBye World\n");return 0;}2 附加练习:(1)编译执行下面的代码,写出两种可能的执行结果。
int i=0,j = 0;#pragma omp parallel forfor ( i= 2; i < 7; i++ )for ( j= 3; j< 5; j++ )printf(“i = %d, j = %d\n”, i, j);(2)编译执行下面的代码,写出两种可能的执行结果。
OpenMP编程指南

for,用于 for 循环之前,将循环分配到多个线程中并行执行,必须保证每次循环之 间无相关性。 parallel for, parallel 和 for 语句的结合,也是用在一个 for 循环之前,表示 for 循 环的代码将被多个线程并行执行。 sections,用在可能会被并行执行的代码段之前 parallel sections,parallel 和 sections 两个语句的结合 critical,用在一段代码临界区之前 single,用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执 行。 barrier,用于并行区内代码的线程同步,所有线程执行到 barrier 时要停止,直到所 有线程都执行到 barrier 时才继续往下执行。 atomic,用于指定一块内存区域被制动更新 master,用于指定一段代码块由主线程执行 ordered, 用于指定并行区域的循环按顺序执行 threadprivate, 用于指定一个变量是线程私有的。 OpenMP 除上述指令外,还有一些库函数,下面列出几个常用的库函数: omp_get_num_procs, 返回运行本线程的多处理机的处理器个数。 omp_get_num_threads, 返回当前并行区域中的活动线程个数。 omp_get_thread_num, 返回线程号 omp_set_num_threads, 设置并行执行代码时的线程个数 omp_init_lock, 初始化一个简单锁 omp_set_lock, 上锁操作 omp_unset_lock, 解锁操作,要和 omp_set_lock 函数配对使用。 omp_destroy_lock, omp_init_lock 函数的配对操作函数,关闭一个锁 OpenMP 的子句有以下一些 private, 指定每个线程都有它自己的变量私有副本。 firstprivate,指定每个线程都有它自己的变量私有副本,并且变量要被继承主线程中 的初值。 lastprivate, 主要是用来指定将线程中的私有变量的值在并行处理结束后复制回主线 程中的对应变量。 reduce,用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执 行指定的运算。 nowait,忽略指定中暗含的等待 num_threads,指定线程的个数 schedule,指定如何调度 for 循环迭代 shared,指定一个或多个变量为多个线程间的共享变量 ordered,用来指定 for 循环的执行要按顺序执行 copyprivate,用于 single 指令中的指定变量为多个线程的共享变量 copyin,用来指定一个 threadprivate 的变量的值要用主线程的值进行初始化。 default,用来指定并行处理区域内的变量的使用方式,缺省是 shared
c 多线程实现的四种方式

c 多线程实现的四种方式C语言是一种非常流行的编程语言,它可以用来实现多线程编程。
多线程编程可以让你的程序更高效、更快速地运行,因为它可以同时执行多个任务。
在这篇文章中,我们将介绍 C 多线程实现的四种方式。
1. 使用 pthread 库pthread 是一个 POSIX 标准定义的多线程库,它提供了一套API 接口,可以用来实现多线程编程。
使用 pthread,你可以创建多个线程并且控制它们的行为。
这种方式是 C 语言实现多线程的最常用方式之一。
2. 使用 OpenMP 库OpenMP 是一个开源的多线程库,它可以用来在 C 语言中实现多线程编程。
OpenMP 提供了一套 API 接口,可以让你更方便地编写并行程序。
使用 OpenMP,你可以使用 #pragma 指令来控制并行执行的代码块。
3. 使用 POSIX 线程POSIX 线程是一种 POSIX 标准定义的多线程接口,它可以用来实现多线程编程。
与 pthread 类似,POSIX 线程提供了一套 API 接口,可以让你更方便地编写多线程程序。
4. 使用 Windows 线程如果你在 Windows 操作系统上编写 C 语言程序,你可以使用Windows 线程来实现多线程编程。
Windows 线程提供了一套 API 接口,可以让你在 Windows 平台上创建多个线程并且控制它们的行为。
总结以上是 C 多线程实现的四种方式。
在选择使用哪种方式时,你应该考虑自己的需求和使用的操作系统。
不同的方式会有不同的 API 接口、性能和可移植性。
如果你需要了解更多关于 C 多线程编程的知识,可以参考相关的书籍和教程。
OpenMP多线程编程基础
5.1.2 OpenMP多线程编程基础OpenMP的编程模型以线程为基础,通过编译制导语句来显示地制导并行化,为编程人员提供了对并行化的完整控制。
在动手编写OpenMP程序之前,我们需要一些有关OpenMP多线程编程的基础知识。
本小节将讲解OpenMP程序的执行模型,OpenMP程序中所涉及的编译制导语句与库函数以及OpenMP程序执行环境的初步介绍,使得初学者能够有一个关于OpenMP 程序的总体印象。
OpenMP的执行模型采用Fork-Join的形式,如果读者对多线程编程有一定的经验的话,对这种执行模式应该非常熟悉。
Fork-Join执行模式在开始执行的时候,只有一个叫做主线程的运行线程存在。
主线程在运行过程中,当遇到需要进行并行计算的时候,派生出(Fork,创建新线程或者从线程池中唤醒已有线程)线程来执行并行任务。
在并行执行的时候,主线程和派生线程共同工作。
在并行代码结束执行后,派生线程退出或者挂起,不再工作,控制流程回到单独的主线程中(Join,即多线程的会和)。
图5. 2 OpenMP运行时的Fork-Join模型上图是共享内存多线程应用程序的Fork-Join模型,从图中我们可以直观地看出多线程应用程序Fork-Join的执行模型是如何运行的。
主线程在运行的过程中,遇到并行编译制导语句,根据环境变量、根据实际需要(比如循环的迭代次数)派生出若干个线程。
此时,次线程与主线程同时运行。
在运行的过程中,某一个派生线程遇到了另外一个并行编译制导语句,派生出了另外一组线程。
新的线程组共同完成一项任务,但对于原有的线程来说,新线程组的工作类似于一块串行程序,对原有的线程不会产生影响。
新线程组在通过一个隐含的同步屏障后(barrier),汇合(join)成原有的线程。
最后,原有的线程组汇合成主线程,执行完最后的程序代码并退出。
OpenMP同时支持C/C++语言和Fortran语言,可以选择任意一种语言以及支持OpenMP的编译器编写OpenMP程序。
第4章 OpenMP 多线程编程
隐式栅障 主线程
2019/2/12
3.2 parallel for ——并行执行for
#pragma omp parallel for for(i=0;i<numPixels;i++) { psum[i]= (pRed[i]*0.2+pBlue[i]*0.3+pYellow[i]*0.5);
}
说明: •for结构使用任务分配机制(work-sharing),循环的各次迭代 将被分配到多个线程上。
2019/2/12
5.2 共享化
shared(variable_name,…) float dot_prod(float* a, float* b, int N) { float sum = 0.0; #pragma omp parallel for shared(sum) for (int i=0; i<N; i++) { sum+ = a[i] * b[i]; } return sum; }
2019/2/12
存在的问题
• private(x,y) • 在并行段外的x,y的值不会被传到并行段内。
2019/2/12
练习:
将下面代码用OpenMP语句并行化 for(k=0;k<80;k++) { x=sin(k*2.0)*100+1; if(x>60) x=x%60+1; printf(“x %d =%d\n”,k,x); }
2019/2/12
练习:
将下面代码用OpenMP语句并行化 for(k=0;k<100;k++) { x=sin(k*2.0)*100+1; if(x>60) x=x%60+1; y=array[k]; array[k] = do_work(y); }
OpenMP
OpenMP是一种针对共享内存的多线程编程技术,由一些具有国际影响力的大规模软件和硬件厂商共同定义的标准.它是一种编译指导语句,指导多线程、共享内存并行的应用程序编程接口(API)OpenMP是一种面向共享内存以及分布式共享内存的多处理器多线程并行编程语言,OpenMP是一种能被用于显示指导多线程、共享内存并行的应用程序编程接口.其规范由SGI发起.OpenMP具有良好的可移植性,支持多种编程语言.OpenMP能够支持多种平台,包括大多数的类UNIX以及WindowsNT系统.OpenMP最初是为了共享内存多处理的系统结构设计的并行编程方法,与通过消息传递进行并行编程的模型有很大的区别.因为这是用来处理多处理器共享一个内存设备这样的情况的.多个处理器在访问内存的时候使用的是相同的内存编址空间.SMP是一种共享内存的体系结构,同时分布式共享内存的系统也属于共享内存多处理器结构,分布式共享内存将多机的内存资源通过虚拟化的方式形成一个同意的内存空间提供给多个机子上的处理器使用,OpenMP对这样的机器也提供了一定的支持.OpenMP的编程模型以线程为基础,通过编译指导语句来显示地指导并行化,为编程人员提供了对并行化的完整控制.这里引入了一种新的语句来进行程序上的编写和设计.OpenMP的执行模型采用Fork-Join的形式,Fork-Join执行模式在开始执行的时候,只有一个叫做“主线程“的运行线程存在.主线程在运行过程中,当遇到需要进行并行计算的时候,派生出线程来执行并行人物,在并行执行的时候,主线程和派生线程共同工作,在并行代码结束后,派生线程退出或者是挂起,不再工作,控制流程回到单独的主线程中。
OpenMP的功能由两种形式提供:编译指导语句和运行时库函数,并通过环境变量的方式灵活控制程序的运行.OpenMP和MPI是并行编程的两个手段,对比如下:∙OpenMP:线程级(并行粒度);共享存储;隐式(数据分配方式);可扩展性差;∙MPI:进程级;分布式存储;显式;可扩展性好。
多核编程4
Sections编译制导语句
sections编译制导语句指定内部的代码被划分给线程组中的 各线程 不同的section由不同的线程执行 Section语句格式:
#pragma omp sections [ clause[[,]clause]…] newline
{ [#pragma omp section newline] … [#pragma omp section newline]
OpenMP概述
OpenMP应用编程接口API是在共享存储体系结构上的一个 编程模型
包含编译制导(Compiler Directive)、运行库例程(Runtime
Library)和环境变量(Environment Variables) 支持增量并行化(Incremental Parallelization)
#pragma omp
制导指令前缀。对 所有的OpenMP语 句都需要这样的前 缀。
directive-name
OpenMP制导指 令。在制导指令前 缀和子句之间必须 有一个正确的 OpenMP制导指 令。
[clause, ...]
newline
子句。在没有其它 换行符。表明这条 约束条件下,子句 制导语句的终止。 可以无序,也可以 任意的选择。 这一 部分也可以没有。
for编译制导语句
schedule子句描述如何将循环的迭代划分给线程组中的 线程 如果没有指定chunk大小,迭代会尽可能的平均分配给 每个线程 type为static,循环被分成大小为 chunk的块,静态分配 给线程 type为dynamic,循环被动态划分为大小为chunk的块,动 态分配给线程
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
话,就只能用parallel与for子句分离的版本。 • Parallel 将紧跟的程序块扩展为若干完全等同的并行区
域,每个线程拥有完全相同的并行区域; • For 将循环中工作分配到线程组中,线程组中的每一个线
程完成循环中的一部分。 • 子句用来控制编译制导语句的具体行为。
循环并行化语句的限制
并行化的语句必须是for循环语句并具有规范格式 • 能够推测出循环的次数 • for (index = start ; index < end ;
increment_expr) • 在循环过程中不能使用break语句 • 不能使用goto和return语句从循环中跳出 • 可以使用continue语句
Fork-Join模型
并行区域
OpenMP的实现
• 编译制导语句(精髓) • 运行时库函数 • 环境变量
编译指 导语句
运行时函 数库
环境变 量
编译制导语句
• 在编译器编译程序的时候,会识别特定的注释, 而这些注释就包含着OpenMP程序的一些语 义
• 在一个无法识别OpenMP语意的普通编译器 中,这些注释会被当作普通的注释而被忽略
建立一个新的项目
配置项目属性
设置环境变量
• 在OpenMP中,主要通过对循环
或一段结构化代码定义并行区域 的方式来实现多线程并行。
#include "omp.h"
int _tmain(int argc, _TCHAR* argv[]) {
printf("Hello from serial.\n"); printf("Thread number=%d\n",omp_get_thread_num());
• 串行程序和并行程序保持在同一个源代码文件 当中,减少了维护负担.
• 编译制导语句,优势体现在编译阶段
• 运行时库函数,支持运行时对并行环境的改变和 优化
1.3 编写OpenMP程序的准备 工作
• 当前的Visual Studio .Net 2005完 全支持OpenMP 2.0标准
• 通过新的编译器选项 /openmp来支持 OpenMP程序的编译和链接
前缀。
一个正确的
ห้องสมุดไป่ตู้
OpenMP制导
指令.
子句。在没有 其它约束条件 下,子句可以 无序,也可以 任意的选择。 这一部分也可 以没有。
换行符。表明 这条制导语句 的终止。
编译制导语句
• Directive
• parallel, for, parallel for, section, sections, single, master, critical, flush, ordered, atomic
body of the loop; }
• 另一种格式:
#pragma omp parallel [clause[clause…]]
{
#pragma omp for [clause[clause…]] for( i = first ; i<last ; i++) {
body of the loop; }
• 在C/C++程序中,OpenMP所有编译制导语 句以#pragma omp开始,后面跟具体功能 指令
编译制导语句
#pragma omp directive-name [clause, ...]
newline
制导指令前缀。 OpenMP制导
对所有的
指令。在制导
OpenMP语句 指令前缀和子
都需要这样的 句之间必须有
简单循环并行化
• 各个分量之间没有数据相关性 • 循环计算的过程也没有循环依赖型
循环依赖性
• 循环迭代相关
循环迭代相关
循环分块技术创建无循环迭代相关的循环m
循环并行化编译制导语句的子句
#pragma omp parallel { printf("Hello from parallel. Thread number=%d\n", omp_get_thread_num()); } printf("Hello from serial again.\n");
getchar(); return 0; }
运行时库函数
• OpenMP运行时函数库主要用以设置和 获取执行环境相关的信息,它们当中也 包含一系列用以同步的API
• 运行时函数库 “omp.h” • omp_get_thread_num() 返回当前
线程的号码
• 通过编译制导语句,可以将串行的程序逐步地改 造成一个并行程序,达到增量更新程序的目的, 减少程序编写人员一定的负担.
第四章 OpenMP多线程编程
主要内容
1. OpenMP编程简介 2. OpenMP多线程应用程序编程技术
1. OpenMP编程简介
1.1 OpenMP多线程编程发展概况
• OpenMP是一种面向共享内存多线程并 行编程技术
• OpenMP具有良好的可移植性
• 支持多种编程语言 Fortran C/C++ • 支持多种平台
•
• OpenMP最初是为共享内存的多处 理器系统设计的并行编程方法,这与 通过消息传递进行并行编程模型有很 大的不同。
OpenMP的支持环境
• Intel的C++和Fortran编译器 • Microsoft的Visual Studio 2005 • gcc4.2以上版本
2. OpenMP多线程应用程序 编程技术
2.1 循环并行化
• 循环并行化是使用OpenMP来并行化程序的最重 要的部分
• 在C/C++语言中,循环并行化语句的编译制导语 句格式如下:
#pragma omp parallel for [clause[clause…]] for( i = first ; i<last ; i++) {
1.2 OpenMP多线程编程基础
• OpenMP的编程模型以线程为基础,通过编 译制导语句来显示地指导并行化
• OpenMP的执行模型采用Fork-Join的形式, 在开始时,只有一个叫做主线程的运行线程存 在;在运行过程中,当遇到需要进行并行计算 的时候,派生出(Fork)线程来执行并行任 务;在并行代码结束执行,派生线程退出或挂 起,控制流程回到单独的主线程中(Join)