聚类算法 --以K-means算法为例
基于K-means算法的亚洲足球聚类研究
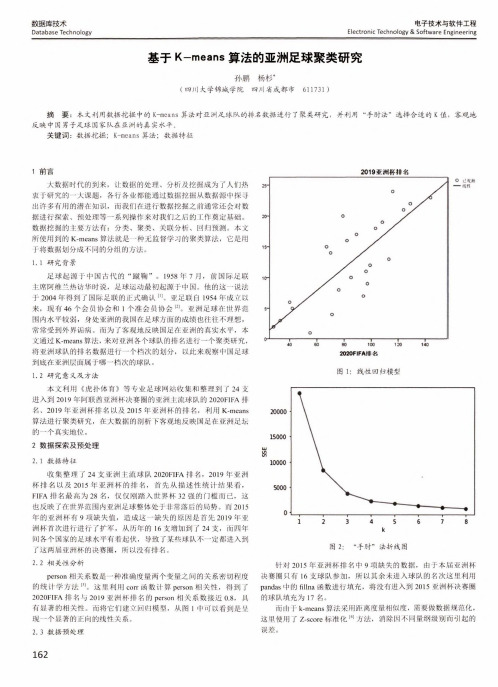
电子技术与软件工程Electronic Technology & Software Engineering数据库技术Database Technology 基于K-means 算法的亚洲足球聚类研究孙鹏杨杉*(四川大学锦城学院 四川省成都市 611731 )摘 要:本文利用数据挖掘中的K-means 算法对亚洲足球队的排名数据进行了聚类研究,并利用“手肘法”选择合适的K 值,客观地 反映中国男子足球国家队在亚洲的真实水平。
关键词:数据挖掘;K-means 算法;数据特征1前言大数据时代的到来,让数据的处理、分析及挖掘成为了人们热 衷于研究的一大课题,各行各业都能通过数据挖掘从数据源中探寻 出许多有用的潜在知识,而我们在进行数据挖掘之前通常还会对数 据进行探索、预处理等一系列操作来对我们之后的工作奠定基础。
数据挖掘的主要方法有:分类、聚类、关联分析、回归预测。
本文 所使用到的K-means 算法就是一种无监督学习的聚类算法,它是用 于将数据划分成不同的分组的方法。
1. 1研究背景足球起源于中国古代的“蹴鞠”。
1958年7月,前国际足联 主席阿维兰热访华时说,足球运动最初起源于中国。
他的这一说法 于2004年得到了国际足联的正式确认⑴。
亚足联自1954年成立以 来,现有46个会员协会和1个准会员协会⑵。
亚洲足球在世界范 围内水平较弱,身处亚洲的我国在足球方面的成绩也往往不理想, 常常受到外界诟病。
而为了客观地反映国足在亚洲的真实水平,本 文通过K-means 算法,来对亚洲各个球队的排名进行一个聚类研究, 将亚洲球队的排名数据进行一个档次的划分,以此来观察中国足球 到底在亚洲层面属于哪一档次的球队。
1. 2研究意义及方法本文利用《虎扑体育》等专业足球网站收集和整理到了 24支 进入到2019年阿联酋亚洲杯决赛圈的亚洲主流球队的2020FIFA 排 名、2019年亚洲杯排名以及2015年亚洲杯的排名,利用K-means 算法进行聚类研究,在大数据的剖析下客观地反映国足在亚洲足坛 的一个真实地位。
聚类算法介绍(K-means+DBSCAN+典型案例)

排序,速度相对于K-Means较慢,一般只适合小数据量。
二,DBSCAN
在DBSCAN算法中将数据点分为一下三类:
01
核心点:在半径r内含有超过minPoints数目的点
边界点:在半径r内点的数量小于minPoints,但是落在核心点的邻域内
噪音点:既不是核心点也不是边界点的点
算密度单元的计算复杂度大,
每一簇内较大的点代表核心对象,较
小的点代表边界点(与簇内其他点密
度相连,但是自身不是核心对象)。
黑色的点代表离群点或者叫噪声点。
三,凝聚层级聚类(HAC)
HAC是自下而上的一种聚类算法。
1
HAC首先将每个数据点视为一个单一的簇,然后计算所有簇之间的距离来合并
簇,直到所有的簇聚合成为一个簇为止。
之间具有更多的相似性。
是一种探索性的分析。聚类分析所
使用方法的不同,常常会得到不同
的结论。不同研究者对于同一组数
据进行聚类分析,所得到的聚类数
未必一致。
从机器学习的角度讲,簇相当
于隐藏模式。聚类是搜索簇的
无监督学习过程。
01
02
04
03
05
06
从统计学的观点看,聚类分析
是通过数据建模简化数据的一
种方法。
典型的应用案例
例3:基于DBSCAN算法的交通事故读法点段排查方法
核心思想:对于构成交通事故多发点段的每个交通事敌,其发生的地点半径e(邻域)公里范围以内的其它交通
事故的个数,必须不小于一个给定的阈值(MinPts),也就是说其邻域的密度必须不小于某个阈值。
下面是DBSCAN算法的交通事故多发点段排查方法在交通事故黑点排查中的一些定义:
一种基于遗传算法的Kmeans聚类算法

一种基于遗传算法的K-means聚类算法一种基于遗传算法的K-means聚类算法摘要:传统K-means算法对初始聚类中心的选取和样本的输入顺序非常敏感,容易陷入局部最优。
针对上述问题,提出了一种基于遗传算法的K-means聚类算法GKA,将K-means算法的局部寻优能力与遗传算法的全局寻优能力相结合,通过多次选择、交叉、变异的遗传操作,最终得到最优的聚类数和初始质心集,克服了传统K-means 算法的局部性和对初始聚类中心的敏感性。
关键词:遗传算法;K-means;聚类聚类分析是一个无监督的学习过程,是指按照事物的某些属性将其聚集成类,使得簇间相似性尽量小,簇内相似性尽量大,实现对数据的分类[1]。
聚类分析是数据挖掘技术的重要组成部分,它既可以作为独立的数据挖掘工具来获取数据库中数据的分布情况,也可以作为其他数据挖掘算法的预处理步骤。
聚类分析已成为数据挖掘主要的研究领域,目前已被广泛应用于模式识别、图像处理、数据分析和客户关系管理等领域中。
K-means算法是聚类分析中一种基本的划分方法,因其算法简单、理论可靠、收敛速度快、能有效处理较大数据而被广泛应用,但传统的K-means算法对初始聚类中心敏感,容易受初始选定的聚类中心的影响而过早地收敛于局部最优解,因此亟需一种能克服上述缺点的全局优化算法。
遗传算法是模拟生物在自然环境中的遗传和进化过程而形成的一种自适应全局优化搜索算法。
在进化过程中进行的遗传操作包括编码、选择、交叉、变异和适者生存选择。
它以适应度函数为依据,通过对种群个体不断进行遗传操作实现种群个体一代代地优化并逐渐逼近最优解。
鉴于遗传算法的全局优化性,本文针对应用最为广泛的K-means方法的缺点,提出了一种基于遗传算法的K-means聚类算法GKA(Genetic K-means Algorithm),以克服传统K-means算法的局部性和对初始聚类中心的敏感性。
用遗传算法求解聚类问题,首先要解决三个问题:(1)如何将聚类问题的解编码到个体中;(2)如何构造适应度函数来度量每个个体对聚类问题的适应程度,即如果某个个体的编码代表良好的聚类结果,则其适应度就高;反之,其适应度就低。
somk-means聚类分区案例

somk-means聚类分区案例K-means聚类分区案例第一篇在数据分析领域,聚类是一种常用的无监督学习方法,能够将数据集中具有相似特征的数据样本划分为不同的类别或群组。
其中,K-means聚类是一种常见而有效的方法,它通过为每个数据样本分配一个与之最相似的聚类中心来实现分类。
在本文中,我们将介绍一个关于K-means聚类分区的案例。
将我们的案例定位于零售行业,想象一家超市的连锁店正计划在不同区域开设新的分店。
为了确定最佳的分店位置,他们决定利用K-means聚类算法对特定区域的顾客进行分析。
这样可以使他们对不同的市场细分,更好地了解各个区域的消费者需求和购物习惯。
通过这种方式,企业可以制定更有针对性的市场营销策略,提高销售额和市场份额。
首先,我们需要收集一些与消费者行为相关的数据。
这些数据可以包括每个顾客的购买记录、年龄、性别、消费金额等信息。
假设我们已经获得了一份包含500个顾客的数据集。
接下来,我们需要对数据进行预处理。
这包括去除异常值、处理缺失值以及数据标准化等步骤。
这些步骤旨在保证数据质量和可靠性,在分析过程中不会产生误导性的结果。
一旦数据预处理完成,我们可以开始使用K-means聚类算法。
该算法的基本思想是,通过计算每个数据样本与聚类中心的距离,将其归类到距离最近的聚类中心。
为了完成这个过程,我们首先需要确定聚类的数量K,也就是分店的数量。
为了确定最佳的K值,我们可以使用一种称为肘方法的技巧。
该方法基于聚类误差平方和(SSE),即聚类中心与其所包含数据样本距离的平方和,来评估聚类质量。
我们可以通过尝试不同的K值,计算相应的SSE,然后选择SSE曲线上的“肘点”作为最佳的K值。
在确定了最佳的K值之后,我们可以应用K-means算法进行聚类分析。
通过迭代更新聚类中心和重新分配样本,我们可以获取最终的聚类结果。
这些结果可以帮助我们理解不同区域顾客的消费行为和购物偏好。
最后,我们可以将聚类结果可视化,并提取有关每个聚类的关键特征。
K-means

d M 2 , O3
0 1.52 2 02 2.5
0 1.52 0 02 1.5
显然 d M 2 , O3 d M 1 , O3 ,故将O3分配给C 2 ;同理,将O4 分配 O 给 C 2 , 4 分配给 C1 。 更新,得到新簇 C1 O1 ,O5 和 C1 O1 ,O5 计算平方误差准则,单个方差为 2 2 2 2 E2 27.25 E1 0 0 2 2 0 5 2 2 25
划分聚类方法对数据集进行聚类时包括如下 三个要点: (1)选定某种距离作为数据样本间的相似性度 量 上面讲到,k-means聚类算法不适合处理离散型 属性,对连续型属性比较适合。因此在计算数据样 本之间的距离时,可以根据实际需要选择欧式距离、 曼哈顿距离或者明考斯距离中的一种来作为算法的 相似性度量,其中最常用的是欧式距离。下面我给 大家具体介绍一下欧式距离。
k-means算法的改进方法——k-中心点算法
k-中心点算法:k -means算法对于孤立点是敏感的。为 了解决这个问题,不采用簇中的平均值作为参照点,可以 选用簇中位置最中心的对象,即中心点作为参照点。这样 划分方法仍然是基于最小化所有对象与其参照点之间的相 异度之和的原则来执行的。
总体平均方差是: E E1 E2 25 27.25 52.25 (3)计算新的簇的中心。
M 2 0 1.5 5 3, 0 0 0 3 2.17,0
M1 0 5 2, 2 2 2 2.5,2
重复(2)和(3),得到O1分配给C1;O2分配给C2,O3分配 给C2 ,O4分配给C2,O5分配给C1。更新,得到新簇 C1 O1 ,O5 ,
K-Means算法实验报告

题目: K-Means 聚类算法分析与实现学 院 xxxxxxxxxxxxxxxxxxxx 专 业 xxxxxxxxxxxxxxxx 学 号 xxxxxxxxxxx 姓 名 xxxx 指导教师 xxxx20xx 年x 月xx 日装 订 线K-Means聚类算法KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。
然后按平均法重新计算各个簇的质心,从而确定新的簇心。
一直迭代,直到簇心的移动距离小于某个给定的值。
K-Means聚类算法主要分为三个步骤:(1)第一步是为待聚类的点寻找聚类中心(2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去(3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止下图展示了对n个样本点进行K-means聚类的效果,这里k取2:(a)未聚类的初始点集(b)随机选取两个点作为聚类中心(c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去(d)计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心(e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去(f)重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心Matlab实现:%随机获取150个点X =[randn(50,2)+ones(50,2);randn(50,2)-ones(50,2);randn(50,2)+[ones(50,1),-ones( 50,1)]];opts = statset('Display','final');%调用Kmeans函数%X N*P的数据矩阵%Idx N*1的向量,存储的是每个点的聚类标号%Ctrs K*P的矩阵,存储的是K个聚类质心位置%SumD 1*K的和向量,存储的是类间所有点与该类质心点距离之和%D N*K的矩阵,存储的是每个点与所有质心的距离;[Idx,Ctrs,SumD,D] = kmeans(X,3,'Replicates',3,'Options',opts);%画出聚类为1的点。
K-Means聚类算法

K-Means聚类算法K-Means聚类算法是一种常用的无监督学习算法,在数据挖掘、图像处理、信号处理等领域有广泛的应用。
聚类算法是将相似的对象归为一类,不同的类之间尽可能的不相似。
K-Means聚类算法是一种基于距离测量的算法,它将数据点分为K个簇,每个簇的中心点与相应的数据点之间的距离最小。
1.初始化K个簇的中心点。
2.将每个数据点分配到离它最近的簇中。
3.计算每个簇的新中心点。
4.重复步骤2和3,直到簇的中心点不再发生变化或达到预定的循环次数。
在算法中,K是指聚类的簇数,每个簇的中心点是从数据点中随机选择的。
在第二个步骤中,每个数据点会被分配到离它最近的簇中,这一步是K-Means聚类算法最重要的一步。
在第三个步骤中,每个簇的新中心点是通过计算该簇中所有数据点的平均值得到的。
1.简单易懂:K-Means聚类算法实现简单,易于理解。
2.计算速度快:该算法的时间复杂度为O(K*n*I),其中n是数据点的数量,I是迭代次数,因此算法速度较快。
3.可用于大规模数据:K-Means聚类算法可以处理大规模的数据集。
1.对初始值敏感:算法中随机选择簇的中心点,这会影响聚类结果。
如果初始值不理想,聚类结果可能会很糟糕。
2.需要指定簇数:需要事先指定簇的数量K,这对于有些问题来说可能是一个难点。
3.对数据分布的要求较高:K-Means聚类算法对数据分布的要求较高,如果数据分布不太符合预期,聚类结果可能会非常差。
在实际应用中,K-Means聚类算法可以用于数据挖掘、模式识别、图像分割等领域。
例如,在图像处理中,可以使用K-Means聚类算法将像素分为不同的颜色组。
在信号处理中,可以使用K-Means聚类算法将信号分为不同的频段组。
实际应用中,需要根据具体问题来选择聚类算法。
k-means聚类算法实验总结

K-means聚类算法实验总结在本次实验中,我们深入研究了K-means聚类算法,对其原理、实现细节和优化方法进行了探讨。
K-means聚类是一种无监督学习方法,旨在将数据集划分为K个集群,使得同一集群内的数据点尽可能相似,不同集群的数据点尽可能不同。
实验步骤如下:1. 数据准备:选择合适的数据集,可以是二维平面上的点集、图像分割、文本聚类等。
本实验中,我们采用了二维平面上的随机点集作为示例数据。
2. 初始化:随机选择K个数据点作为初始聚类中心。
3. 迭代过程:对于每个数据点,根据其与聚类中心的距离,将其分配给最近的聚类中心所在的集群。
然后,重新计算每个集群的聚类中心,更新聚类中心的位置。
重复此过程直到聚类中心不再发生明显变化或达到预设的迭代次数。
4. 结果评估:通过计算不同指标(如轮廓系数、Davies-Bouldin指数等)来评估聚类效果。
实验结果如下:1. K-means聚类能够有效地将数据点划分为不同的集群。
通过不断迭代,聚类中心逐渐趋于稳定,同一集群内的数据点逐渐聚集在一起。
2. 在实验中,我们发现初始聚类中心的选择对最终的聚类结果有一定影响。
为了获得更好的聚类效果,可以采用多种初始聚类中心并选择最优结果。
3. 对于非凸数据集,K-means算法可能会陷入局部最优解,导致聚类效果不佳。
为了解决这一问题,可以考虑采用其他聚类算法,如DBSCAN、层次聚类等。
4. 在处理大规模数据集时,K-means算法的时间复杂度和空间复杂度较高,需要进行优化。
可以采用降维技术、近似算法等方法来提高算法的效率。
通过本次实验,我们深入了解了K-means聚类算法的原理和实现细节,掌握了其优缺点和适用场景。
在实际应用中,需要根据数据集的特点和需求选择合适的聚类算法,以达到最佳的聚类效果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
应用实例
距离D
5. 由于Zj(2)≠Zj(1),所以用调整后的中心点再次计算 所有球队分别到三个新中心点的距离D如图所示, 所以,第二次迭代后的结果为: 中国C,日本A,韩国A,伊朗B,沙特B,伊拉 克C,卡塔尔C,阿联酋C,乌兹别克斯坦B,泰国C, 越南C,阿曼C,巴林B,朝鲜B,印尼C。 结果无变化,说明结果已收敛,最终聚类结果为:
SSE是数据库中所有对象的平方误差总和,p为数据对象, mi是簇Ci的平均值。这个准则函数使生成的结果尽可能的紧 凑和独立。
k-means算法描述
下面给出k-means算法的具体步骤: (l) 给定大小为n的数据集,令I=1,选取k个初始聚类中心
Zj(I),j=1,2,3,…,k;
(2) 计算每个数据对象与聚类中心的距离D(xi,Zj(I)),i=1, 2,3…n,j=l,2,3,…,k,如果满足 D(xi,Zk(I)) =min{D(xi,Zj(I)),i=l,2,3,…n} 则 xi∈C k; (3) 计算k个新的聚类中心: 即取聚类中所有元素各自维度的算术平均数; (4) 判断:若Zj(I+1)≠Zj(I),j=l,2,3,…,k,则I=I+1, 返回(2);否则算法结束。
最广泛使用的聚类算法k-means算法属于划分法。
划分法
给定一个有N个元组或者纪录的数据集,划分法将构造K 个分组,每一个分组就代表一个聚类,K<N。而且这K个分 组满足下列条件: (1) 每一个分组至少包含一个数据纪录; (2)每一个数据纪录属于且仅属于一个分组(某些模糊 聚类算法中该条件可以放宽); 对于给定的K,算法首先给出一个初始的分组方法,以后 通过反复迭代的方法改变分组,使得每一次改进之后的分组 方案都较前一次好,而所谓好的标准就是:同一分组中的记 录越近越好,而不同分组中的纪录越远越好。
A簇的新中心点为:{(0.3+0)/2=0.15, (0+0.15)/2=0.075, (0.19+0.13)/2=0.16} = {0.15, 0.075, 0.16}
B簇的新中心点为: {(0.24+0.3+0.7*3)/5=0.528, (0.76*4+0.68)/5=0.744, (0.25+0.06+0.25+0.5+1)/5=0.412} ={ 0.528,0.744,0.412} C簇的新中心点={ 1,0.94, 0.40625}。
亚洲一流:日本,韩国;
亚洲二流:乌兹别克斯坦,巴林,朝鲜,伊朗, 沙特; 亚洲三流:中国,伊拉克,卡塔尔,阿联酋,泰国,越南,阿曼,印尼。
应用实例
其实分析数据不仅告诉我们聚类信息,还提
供了一些其它有趣的信息,例如从中可以定
量分析出各个球队之间的差距。例如,在亚 洲二流队伍中,伊朗与沙特水平最接近,另
k-means算法
k-means算法,也被称为k-均值或k-平均。 该算法首先随机地选择k个对象作为初始的k个簇的质心; 然后对剩余的每个对象,根据其与各个质心的距离,将它赋 给最近的簇,然后重新计算每个簇的质心;这个过程不断重 复,直到准则函数收敛。通常采用的准则函数为平方误差和 准则函数,即 SSE(sum of the squared error),其定义如下:
2. 选取k个初始聚类中心
应用实例
设k=3,即将这15支球队分成三个集团。抽取日 本、巴林和泰国的值作为三个簇的种子,即初始化 三个簇的中心为A:{0.3, 0, 0.19},B:{0.7, 0.76, 0.5} 和C:{1, 1, 0.5}。
应用实例
图中从左到右依次表示各支球队到当前中 心点的欧氏距离,将每支球队分到最近的 簇,可对各支球队做如下聚类:
聚类算法
在商业上,聚类可以帮助市场分析人员从消费者数据 库中区分出不同的消费群体来,并且概括出每一类消 费者的消费习惯。它作为数据挖掘中的一个模块,可 以作为一个单独的工具来发现数据库中分布的一些深 层的信息,并且概括出每一类的特点,或者把注意力 放在某一个特定的类上做进一步的分析。 聚类分析的算法可以分为划分法、层次法、基于密度 的方法、基于网格的方法、基于模型的方法。其中,
在簇的平均值被定义的情况下才能使用,这对于处理符号属性的数据不适用。对于
“躁声”和孤立点数据是敏感的,少量的该类数据能够对平均值产生极大的影响。
外,乌兹别克斯坦和巴林虽然没有打进近两
届世界杯,不过凭借预选赛和亚洲杯上的出 色表现占据B组一席之地,而朝鲜由于打入
了2010世界杯决赛圈而有幸进入B组。其它
有趣的信息还可以进一步挖掘。
k-means算法的性能分析
主要优点:
是解决聚类问题的一种经典算法,简单、快速。
对处理大数据集,该算法是相对可伸缩和高效率的。因为它的复杂度是O(nkt ) ,其 中,n 是所有对象的数目,k 是簇的数目,t 是迭代的次数。通常k < <n 且t < <n 。 当结果簇是密集的,而簇与簇之间区别明显时,它的效果较好。
应用实例
1. 规格化数据
由于取值范围大的属性对距离的影响高于取值范围小的属性, 这样不利于反映真实的相异度,因此聚类前,一般先对属性值进行 规格化。所谓规格化就是将各个属性值按比例映射到相同的取值区 间,来平衡各个属性对距离的影响。通常将各个属性均映射到[0,1] 区间,映射公式为: 其中max(ai)和min(ai)表示所有元素项中第i个属性的最大值和最小值。
安英博 2013.12.26
ห้องสมุดไป่ตู้
分类和聚类
分类是指将数据归于一系列已知类别之中的某个 类的分类过程。分类作为一种监督学习方法,要 求必须事先明确知道各个类别的信息,并且断言 所有待分类项都有一个类别与之对应。但是很多 时候上述条件得不到满足,尤其是在处理海量数 据的时候。 聚类是根据客体属性对一系列未分类的客体进行 类别的识别,把一组个体按照相似性归成若干类。 聚类属于无监督学习。
中国C,日本A,韩国A,伊朗B,沙特B,伊拉克 C,卡塔尔C,阿联酋C,乌兹别克斯坦B,泰国C, 越南C,阿曼C,巴林B,朝鲜B,印尼C。
应用实例
第一次聚类结果: A:日本,韩国;
B:伊朗,沙特,乌兹别克斯坦,巴林,朝鲜;
C:中国,伊拉克,卡塔尔,阿联酋,泰国,越南,阿曼,印尼。 4. 根据第一次聚类结果,调整3个簇的中心点
k-means算法描述
距离D的计算方法
1. 欧几里得距离:
其意义就是两个元素在欧氏空间中的集合距离,因为 其直观易懂且可解释性强,被广泛用于标识两个标量元 素的相异度。 2. 曼哈顿距离: 3. 闵可夫斯基距离:
从图中可以看到,A, B, C, D, E
是五个在图中点。而灰色的点是 种子点,也就是我们用来找点群 的点。有两个种子点,所以k=2。 K-Means 的算法如下: ① 随机在图中取k(这里k=2)个种子点。 ② 对图中的所有点求到这k个种子点的距离,假如点 Pi 离种子点 Si 最近,那么 Pi 属于 Si 点群。(上图中,我们可以看到A、B属于上 面的种子点,C、D、E属于下面中部的种子点) ③ 移动种子点到属于他的“点群”的中心。(见图上的第三步)
主要缺点:
结果对初值敏感,对于不同的初始值,可能会导致不同结果。
必须事先给出k 值,但很多时候并不知道数据集应该分成多少个类别才最合适。聚类 初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法 得到有效的聚类结果。可以多设置一些不同的初值,对比最后的运算结果,一直到 结果趋于稳定来解决这一问题,但比较耗时、浪费资源。
举例概述
④ 然后重复第2)和第3)步,直到种子点不再移动(图中的第四步上 面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
应用实例
——中国男足近几年在亚洲处于几流水平?
下图是采集的亚洲15只球队在2006年-2010年间大型比赛的
战绩(澳大利亚未收录)。数据做了如下预处理:对于世界杯, 进入决赛圈则取其最终排名,没有进入决赛圈的,打入预选赛 十强赛赋予40,预选赛小组未出线的赋予50。对于亚洲杯,前 四名取其排名,八强赋予5,十六强赋予9,预选赛没出现的赋 予17。