市场调查中有关态度的测量量表
第七章 态度测量及量表

能力导航
阅读本章后,你将能够: 理解态度测量的内涵及其作用; 懂得类别量表、顺序量表、差距量表、等比量表 的特点; 懂得评比量表、等级顺序量、语意差别量表、沙 斯通量表、利克特量表的特点并能运用; 掌握选择量表的考虑因素; 熟悉评估量表的标准。
第一个问题:什么是态度测量?一、 态度和态度测量
(三)采用奇数个还是偶数个层次
(四)采用强迫选择还是非强迫选择
(五)量级层次的描述方式
(六)量表的形式
二、评价量表的标准
1测量误差及其产生原因
2信度与效度
信度与效度
效度是指用测量工具测出变量的准确程度, 即准确性。
信度
可靠性是指评价结果的一致性。
思考题
一、态度和态度测量
(一)态度
在市场调查研究中,“态度”主要有三方面 的含义: 一是指对某事物的了解和认识; 二是指对某事物的偏好; 三是指对未来行为或状态的预期和意向。
(二)态度测量
态度测量就是市场调查与预测人员根据被调 查者的可能认识或认识态度,就某一问题列 出若干答案,设计态度测量表,再根据被调 查者的选择来确定其认识或认识程度(态度) 的行为和过程。简言之,态度测量就是测量 态度。
(4)对每个回答打分。
(5)受测者划分为高分组和低分组。
(6)选出有较大区分能力的项目构成一个李克特 量表。
第三个问题:怎么选择、评价态度 测量量表?
一、选择态度量表的考虑因素 二、评价量表的标准
一、选择态度量表的考虑因素
(一)量级层次的个数 (二)采用平衡的还是不平衡的量表
市场调研之市场调查的测量与量表

构造李克量表的步骤
收集和编写大量围绕研究问题的陈述或说法 随机抽取样本一个样本进行试调查 根据试调查的数据进行量表的信度和效度分析。
在分析中需要对负说法的的得分作逆向处理 根据信度和效度分析,去除影响信度和效度的陈
述和说法,从而得到较高信度和效度的李克量表
李克量表例子:测量观众对名人引导时 尚的看法
测量的效度
测量的效度是测量的有效性,即测量工具能否准 确、真实、客观地度量事物属性的程度,主要表 现在测量项目和欲测量的测量属性相一致的程度、 概念的操作化定义反映概念的本质定义的程度等。
内容效度:表面效度,从表面上来观察和判断所 测量的是否就是应该测量的项目。首先要清楚了 解被测概念的定义,其次要判断所测量的变量是 否与之紧密相关
语意差别量表是定距量表,把要测量的名字和概念先分 解出若干个描述角度,然后用一系列的7级或9级量表从 这些角度进行描述,量表的两端代表两极化的态度
步骤:1确定描述、判断或评价研究对象的角度,然后 在每个角度上找出一对反义词。要尽量全面有意义。
2将各对形容词分别置于一系列有7个或9个刻度的标尺 的两端,将正反形容词之间的差距分成7等分,中间的 一级表示中立态度
态度量表的类型
1李克量表:也叫累加量表,是市场调查最常用 的量表,常用于测量观念、态度或意见。它的形 式是给出一组问题,请被调查者做出“非常同 意”、“同意”、“说不准”、“不同意”、 “非常不同意”五种回答,然后给各种回答分别 记为1、2、3、4、5或5、4、3、2、1。这样每 个被调查者对各道题目的回答分数的加总就得出 一个总分,这一个总分就说明了被调查者的态度 强弱
2舍史东量表
主要用于测量被访者对特定事物的态度
收集和编写大量与所测事物有关的陈述或说法,其表述应有正向的、 中间的和负面的
第八章 测量量表

(二)、基本量表类型
1、类别量表:
用数据识别不同的物体、群体、个人、 事件。将其分成各种互相排斥、互不相容 的各种类别。 作用:分类。赋予目标或现象不同的 数字是用于识别和分类的。
示例: 性别 地理区域
特征 (1)男 (2)女 (1)城市 (2)农村
赋值 1 2 3 4
这些数字不能比较、排序、或加减乘
第八章
态度测量
态度和行为之间的一般关系: 顾客的态度越积极,使用产品的可 能性越大; 顾客的态度越消极,使用产品的可 能性越小;
人们对一种产品的态度越是不赞成, 他们停止使用它的可能性就越大; 那些从未尝试使用某产品的人们的态 度将在均值左右呈正态分布;
当态度以对某产品的实际试用或使用 经历为基础时,通过态度就能很好地 预测行为。相反,当态度是以广告为 基础时,态度和行为的一致性明显减 弱。 —因此,准确地测量消费者的态度, 对于预测其购买行为很有帮助。
除。 量化处理只能对每一类别的客体进行 频次或百分比计算。 平均态度值不能用算术平均、中位数 (顺序),只能用众数(多寡)表示。
2、顺序量表:
表中所列答案之间有顺序关系。 示例: 请对下列品牌的手机按1到5进行 排序,1表示最喜欢,5表示最不喜 欢 诺基亚— 摩特罗拉—联想—三 星—
顺序量表除具有类别量表的特征识别 功能外,其主要功能是对数据排序。 如上例中,可以赋予20、24、50、53 等。数字只是反映顺序。 但也不能进行算术运算。量度用众数 或中位数以测中心趋势,百分位数或 四分位数以测量离散程度。
假设驱蚊器调查的结果如下: 40%——肯定会买 20%——可能会买 30%——可能不会买 10%——肯定不会买 ( 0 . 4 ) x(63%) 十 ( 0 . 2 ) × ( 2 8 % ) + (0.3)x(12%)十(0.1)x(3%)=34.7%市 场份额
态度测量量表

配对比较量表结果的统计计算
访问结束之后,将受测者的回答整理成偏好矩阵如下 华夏靓妹白珊瑚双面针洁齿灵
华夏 /
001源自0靓妹 1/
0
1
0
白珊瑚 1
1
/
1
1
双面针 0
0
0
/
0
洁齿灵 1
1
0
1
/
合计 3
2
0
4
1
表中每一行列交叉点上元素表示该行的品牌与该列的品 牌进行比较的结果
其中元素1表示受测者更喜欢这一列的品牌,0表示更喜 欢这一行的品牌,
品牌名称品牌等级 美菱 上菱 容声 海尔 西门子 新飞 万宝
量表B牙膏
品牌名称品牌等级 华夏 蓝海 双面针 白珊瑚 洁齿灵 靓妹 露洁
等级量表优点
等级量表也是使用很广泛的一种态度测量技 术,这种题目容易设计,受测者也比较容易掌 握回答的方法,
等级量表强迫受测者在一定数目的评价对象 中作出比较和选择,从而得到对象间相对性 或相互关系的测量数据,
配对比较量表的优缺点
优点:
对受测者来说,从一对对象中选出一个肯定比从一大组对 象中选出一个更容易;
配对比较也可以避免等级量表的顺序误差,
缺点:
比较次数可能太多, 因为一般要对所有的配对进行比较,所以对于有n个对象
的情况,要进行nn-1/2次配对比较,是关于n的一个几何级 数,
表6-4配对比较量表实例
将各列取值进行加总,得到表中合计栏,这表明各列的品 牌比其它品牌更受偏爱的次数,
假设调查样本容量为100人,将每个人的回答 结果进行汇总,将得到下表的次数矩阵,
华夏靓妹白珊瑚双面针洁齿灵
华夏 / 20 30 15 20 靓妹 80 / 50 40 65 白珊瑚 70 50 / 60 45 双面针 85 60 40 / 75 洁齿灵 80 35 55 25 /
市场调查中有关态度的测量量表
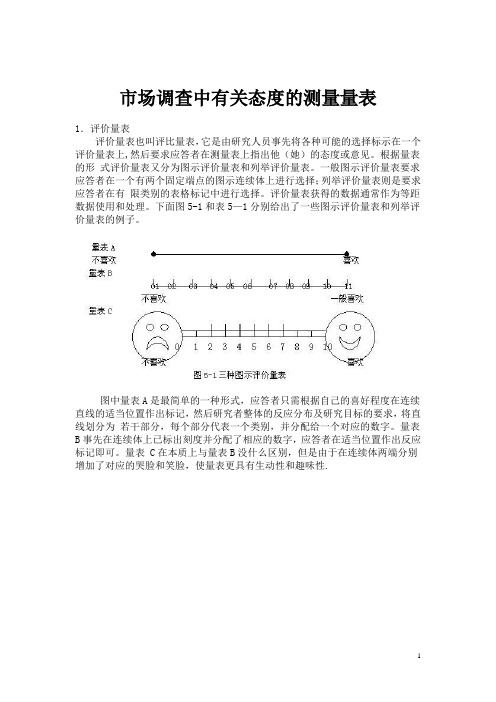
市场调查中有关态度的测量量表1.评价量表评价量表也叫评比量表,它是由研究人员事先将各种可能的选择标示在一个评价量表上,然后要求应答者在测量表上指出他(她)的态度或意见。
根据量表的形式评价量表又分为图示评价量表和列举评价量表。
一般图示评价量表要求应答者在一个有两个固定端点的图示连续体上进行选择;列举评价量表则是要求应答者在有限类别的表格标记中进行选择。
评价量表获得的数据通常作为等距数据使用和处理。
下面图5-1和表5—1分别给出了一些图示评价量表和列举评价量表的例子。
图中量表A是最简单的一种形式,应答者只需根据自己的喜好程度在连续直线的适当位置作出标记,然后研究者整体的反应分布及研究目标的要求,将直线划分为若干部分,每个部分代表一个类别,并分配给一个对应的数字。
量表B事先在连续体上已标出刻度并分配了相应的数字,应答者在适当位置作出反应标记即可。
量表 C在本质上与量表B没什么区别,但是由于在连续体两端分别增加了对应的哭脸和笑脸,使量表更具有生动性和趣味性.上表中量表A和量表B都是列举评价量表最普通的一种形式,此时访问人员通常向应答者出示一个基本量表的复制卡片,卡片上标有相应的有限选择答案,在访问人员读出一个品牌时应答者作出自己的选择。
整个问卷中品牌的起始位置是循环的,因为相同的起点会给应答者带来影响,可能成为误差的一个来源。
量表C适用于针对儿童进行的调查,“小人头”的表情有助于儿童的理解和反应,同时也增加了调查的趣味性。
列举评价量表比图示评价量表容易构造和操作,研究表明在可靠性方面也比图示评价量表要好,但是不能像图示评价量表那样衡量出客体的细微差别。
总体上讲,评价量表有许多优点:省时、有趣、用途广、可以用来处理大量变量等,因此在市场营销研究中被广泛采用.但是这种方法也可能会产生三种误差:(1)仁慈误差:有些人对客体进行评价时,倾向于给予较高的评价,这就产生了所谓的仁慈误差;反之,有些人总是给予较低的评的价,从而引起负向的仁慈差。
第4讲 态度测量与量表技术

3. 配对比较量表
配对比较量表:给调查对象提供两个或两个以 上的同类物体,并要求他们根据某些标准对这 些物体进行两两比较,所获数据是顺序数据。 常用于产品属性的调研,如价格、品牌、商品 外观等方面。 优点:判断简单,易于回答,但只适合少量物 体的比较,当比较对象较多时,受访者可能会 感到难以回答。
顺序量表(ordinal
scale):
是一种排序尺度,分配给对象的数字 具有比较性,可以说明孰优孰劣,但不能 知道具体差距究竟有多大。顺序量表不仅 可以进行“=”或“≠” ,还可以进行 “<”或“>”运算,所获得的数据可用 作中位数分析。 如:产品质量等级,考试成绩的排名等。
等距量表(interval
对事物的特性可以用不同的规则分配 数字,因此形成了不同测量水平的测 量尺度。
类别量表(nominal
scale):
类别量表中的数字只用作对事物进行识别和 分类。类别量表之间只能进行“=”或“≠”的 逻辑运算,即进行“是”或“否”的逻辑运算。 如性别编号、学生的学号、球员的编号等。 类别量表的数字不能反映对象具体特征的性质和 数量。 类别量表的调研结果一般做众数分析,即各 种备选答案占全部答案的比例。
scale):
也称区间量表,不仅能说明不同态度之 间的先后顺序,还说明相邻两种态度之间的 差异程度是相等的。等距量表包含顺序量表 提供的一切信息,并且还可以比较对象间的 差别。等距量表之间除了可以进行“=”或 “≠” ,“<”或“>”的运算外,还可 以进行“+”或“-”的运算。 如:温度、质量评分。
上菱容声来自新飞万宝两面针
白珊瑚
华夏
高露洁
蓝海
靓妹
态度测量量表

配对比较量表的优缺点
优点:
对受测者来说,从一对对象中选出一个肯定比从一大组 对象中选出一个更容易; 配对比较也可以避免等级量表的顺序误差。
缺点:
比较次数可能太多。 因为一般要对所有的配对进行比较,所以对于有n个对象 的情况,要进行n(n-1)/2次配对比较,是关于n的一个几 何级数。
等级量表缺点
只能得到顺序数据,因此不能对各等级间的差距进 行测量,同时卡片上列举对象的顺序也有可能带来 所谓顺序误差。 用于排序的对象个数也不能太多,一般要少于10 个,否则很容易出现错误、遗漏。
不能排序、不能衡量距离、沒有原 点可言
可以排序、但不能衡量距离、沒有 原点可言 可以排序,及用区间了解距离之差 異,但沒有绝对的原点 可以排序,可了解距离的差异,且 有绝对原点
(五) 量表实例
类别量表
栏目名称 栏目编号
顺序量表
按喜好程度排序
等距量表
按喜好程度打分
等比量表
上月内收视时间(小时)
表6-4 配对比较量表实例
下面是十对牙膏的品牌,对于每一对品牌,请指出你更喜欢其 中的哪一个。在选中的品牌旁边□处打勾(√)。 量表A 十对牙膏品牌配对比较 ① 华 夏 □ 白珊瑚 □ ② 华 夏 □ 双面针 □ ③ 华 夏 □ 洁齿灵 □ ④ 华 夏 □ 靓 妹 □ ⑤ 白珊瑚 □ 双面针 □ ⑥ 白珊瑚 □ 洁齿灵 □ ⑦ 白珊瑚 □ 靓 妹 □ ⑧ 双面针 □ 洁齿灵 □ ⑨ 双面针 □ 靓 妹 □ ⑩ 洁齿灵 □ 靓 妹 □
量表中用数字代表态度的特性是出于两个原因。首先,数字便于统 计分析;其次,数字使态度测量活动本身变得容易、清楚和明确。
二、测量的量表(scale)
测量调查者态度时的量表

测量调查者态度时的量表
测量调查者态度时可以使用李克特量表(Likert Scale)或者语义差异量表(Semantic Differential Scale)。
李克特量表是一种常用的态度测量方法,它采用定距测量法,将态度分为五级或七级,每个等级对应一个分数,调查者根据自己对问题的态度选择最符合的等级,然后根据选择的结果计算得分。
李克特量表具有简单易用、客观准确的优点,广泛应用于市场调查、社会调查等领域。
语义差异量表是一种更为复杂的态度测量方法,它将态度分为多个方面,每个方面设计多个描述词语,调查者需要根据自己的态度对每个描述词语打分,然后将各个方面的得分进行加权平均,得出总的态度得分。
语义差异量表能够更全面地测量态度,特别是对于一些抽象的概念和情感,但是操作起来较为繁琐,需要较高的专业水平。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
市场调查中有关态度的测量量表1.评价量表评价量表也叫评比量表,它是由研究人员事先将各种可能的选择标示在一个评价量表上,然后要求应答者在测量表上指出他(她)的态度或意见。
根据量表的形式评价量表又分为图示评价量表和列举评价量表。
一般图示评价量表要求应答者在一个有两个固定端点的图示连续体上进行选择;列举评价量表则是要求应答者在有限类别的表格标记中进行选择。
评价量表获得的数据通常作为等距数据使用和处理。
下面图5-1和表5-1分别给出了一些图示评价量表和列举评价量表的例子。
图中量表A是最简单的一种形式,应答者只需根据自己的喜好程度在连续直线的适当位置作出标记,然后研究者整体的反应分布及研究目标的要求,将直线划分为若干部分,每个部分代表一个类别,并分配给一个对应的数字。
量表B事先在连续体上已标出刻度并分配了相应的数字,应答者在适当位置作出反应标记即可。
量表C在本质上与量表B没什么区别,但是由于在连续体两端分别增加了对应的哭脸和笑脸,使量表更具有生动性和趣味性。
上表中量表A和量表B都是列举评价量表最普通的一种形式,此时访问人员通常向应答者出示一个基本量表的复制卡片,卡片上标有相应的有限选择答案,在访问人员读出一个品牌时应答者作出自己的选择。
整个问卷中品牌的起始位置是循环的,因为相同的起点会给应答者带来影响,可能成为误差的一个来源。
量表C适用于针对儿童进行的调查,“小人头”的表情有助于儿童的理解和反应,同时也增加了调查的趣味性。
列举评价量表比图示评价量表容易构造和操作,研究表明在可靠性方面也比图示评价量表要好,但是不能像图示评价量表那样衡量出客体的细微差别。
总体上讲,评价量表有许多优点:省时、有趣、用途广、可以用来处理大量变量等,因此在市场营销研究中被广泛采用。
但是这种方法也可能会产生三种误差:(1)仁慈误差:有些人对客体进行评价时,倾向于给予较高的评价,这就产生了所谓的仁慈误差;反之,有些人总是给予较低的评的价,从而引起负向的仁慈差。
(2)中间倾向误差:有些人不愿意给予被评价的客体很高或很低的评价,特别是当不了解或难于用适当的方式表示出来时,往往倾向于给予中间性的评价。
可以用以下方法防止这种误差的发生;①调整叙述性形容词的强度。
②增加中间的评价性语句在整个量表中的空间。
③使靠近量表两端的各级在语意上的差别加大,使其大于中间各级间的语意差别。
④增加测量量表的层次。
(3)晕轮效果:如果受测者对被评价的对象有一种整体印象,可能会导致系统偏差。
预防的方法是对所有要被评价的对象,每次只评价一个变量或特性;或者问卷每一页只列一种特性,而不是将所有要被评的变量或特性全部列出。
2.等级量表等级量表是一种顺序量表,它是将许多研究对象同时展示给受测者,并要求他们根据某个标准对这些对象排序或分成等级。
例如,要求受访者根据总体印象对不同品牌的商品进行排序。
典型地,这种排序要求受测者对他们认为最好的品牌排“1”号,次好的排“2”号,依次类推,直到量表中列举出的每个品牌都有了相应的序号为止。
一个序号只能用于一种品牌。
等级量表也是使用很广泛的一种态度测量技术,这种题目容易设计,受测者也比较容易掌握回答的方法。
等级量表强迫受测者在一定数目的评价对象中作出比较和选择,从而得到对象间相对性或相互关系的测量数据。
等级法也比较节省时间。
等级量表最大的缺点在于只能得到顺序数据,因此不能对各等级间的差距进行测量,同时卡片上列举对象的顺序也有可能带来所谓顺序误差。
此外,用于排序的对象个数也不能太多,一般要少于10个,否则很容易出现错误、遗漏。
3、配对比较量表在配对比较量表中,受测者被要求对一系列对象两两进行比较,根据某个标准在两个被比较中的对象中做出选择。
配对比较量表也是一种使用很普遍的态度测量方法。
它实际上是一种特殊的等级量表,不过要求排序的是两个对象,而不是多个。
配对比较方法克服了等级排序量表存在的缺点。
首先,对受测者来说,从一对对象中选出一个肯定比从一大组对象中选出一个更容易;其次,配对比较也可以避免等级量表的顺序误差。
但是,因为一般要对所有的配对进行比较,所以对于有n个对象的情况,要进行n(n-1)/2次配对比较,是关于n的一个几何级数。
因此,被测量的对象的个数不宜太多,以免使受测者产生厌烦而影响应答的质量。
下面的表5-2是一个配对比较量表的例子。
访问结束之后,可以将受测者的回答整理成表格的形式,下面的表5-3是根据某受访者的回答整理得到的结果。
表中每一行列交叉点上元素表示该行的品牌与该列的品牌进行比较的结果,其中元素“1”表示受测者更喜欢这一列的品牌,“0”表示更喜欢这一行的品牌。
将各列取值进行加总,得到表中合计栏,这表明各列的品牌比其它品牌更受偏爱的次数。
从上表中看到该受测者在华夏牙膏和靓妹牙膏中更偏爱前者(第二行第一列数字为1)。
在“可传递性”的假设下,可将配对比较的数据转换成等级顺序。
所谓“可传递性”是指,如果一个人喜欢A品牌甚于B品牌,喜欢B品牌甚于C品牌,那么他一定喜欢A品牌甚于C品。
将表6-5的各列数字分别加总,计算出每个品牌比其他品牌更受偏爱的次数,就得到该受测者对于5个牙膏品牌的偏好,从最喜欢到最不喜欢,依次是两面针、华夏、靓妹、洁齿灵和白珊瑚。
假设调查样本容量为100人,将每个人的回答结果进行汇总,将得到表5-4的次数矩阵。
再将次数矩阵变换成比例矩阵(用次数除以样本数),如表5-5所示,在品牌自身进行比较时,我们令其比例为0.5。
从表5-5中的合计栏中,可以看出5个品牌中华夏牌牙膏被认为是最好的,洁齿灵次之,再次是白珊瑚和靓妹,两面针最差。
但这是一个顺序量表,只能比较各品牌的相对位置,不能认为“华夏牙膏比洁齿灵要好1.1,白珊瑚要比靓妹好0.1”。
要想衡量各品牌偏好间的差异程度必须先将其转化为等距量表,这里就不再深入讨论了。
当要评价的对象的个数不多时,配对比较法是有用的。
但如果要评价的对象超过10个,这种方法就太麻烦了。
另外一个缺点是“可传递性”的假设可能不成立,在实际研究中这种情况常常发生。
同时对象列举的顺序可能影响受测者,造成顺序反应误差。
而且这种“二中选一”的方式和实际生活中作购买选择的情况也不太相同,受访者可能在A、B两种品牌中对A要略为偏爱些,但实际上却两个品牌都不喜欢。
4.沙氏通量表在市场营销研究中,经常涉及到对某一主题的态度测量,如人们对于电视商业广告的态度、对人寿保险的态度等。
沙氏通量表通过应答者在若干(一般9—15 条)与态度相关的语句中选择是否同意的方式,获得应答者关于主题的看法。
沙氏通量表的实地测试和统计汇总都很简单,只是量表的构做相对来说比较麻烦。
一个测量态度的沙氏通量表,其构做的基本步骤如下:(1)收集大量的与要测量的态度有关的语句,一般应在100条以上,保证其中对主题不利的、中立的和有利的语句都占有足够的比例,并将其分别写在特制的卡片上。
(2)选定二十人以上的评定者,按照各条语句所表明的态度有利或不利的程度,将其分别归入十一类。
第一类代表最不利的态度,依次递推,…,第六类代表中立的态度,…,第十一类代表最有利的态度。
(3)计算每条语句被归在这十一类中次数分布。
(4)删除那些次数分配过于分散的语句。
(5)计算各保留语句的中位数,并将其按中位数进行归类,如果中位数是n,则该态度语句归到第n类。
(6)从每个类别中选出一、二条代表语句(各评定者对其分类的判断最为一致的),将这些语句混合排列,即得到所谓的沙氏通量表。
下面的表5-6给出了一个典型的沙氏通量表所包含的十一条态度语句。
沙氏通量表通常在设计时,将有关态度语句划分为十一类,其实并不一定非要划分成十一类不可,多些少些都可以,但最好划分成奇数个类别,以中点作为中间立场。
分类后在每个类别中至少选择一条代表语句,也可以选择多于一条语句,这样组成的沙氏通量表就不止包含与类别数相同的语句,可能多达二十几条态度语句,但一般来讲在每个类别中选择多条语句没有特别的必要。
沙氏通量表构作比较麻烦但使用操作很简单,只要求受测者指出量表中他同意的陈述或语句。
每条语句根据其类别都有一个分值,量表中的语句排列可以是随意的,但每个受测者都应该只同意其中的分值相邻的几个意见,如果在实际中一个受测者的语句或意见其分值过于分散,则判定此人对要测量的问题没有一个明确一致的态度,或者量表的构作可能存在问题。
沙氏通量表根据受测者所同意的陈述或意见的分值,通过分值平均数的计算求得受测者的态度分数。
例如某人同意第八个意见,他们态度分数就是8,如果同意七、八、九三条意见,他们态度分数为(7+8+9)/3=8。
在上例中,分数越高,说明受测都对某一问题持有的态度越有利;分数越低,说明持有的态度越不利。
沙氏通量表是顺序量表,可以用两个受测者的态度分数比较他们对某一问题所持态度的相对有利和不利的情况,但不能测量其态度的差异大小。
沙氏通量表在市场营销研究中使用得不是太多,主要原因是沙氏通量表的构作非常麻烦,即使单一主题的量表构作也要耗费大量的时间,对于多个主题的沙氏通量表制作就更加困难。
另外,不同的人即使态度完全不同,也有可能获得相同的分数。
例如一个人同意第5个意见,得5分,另一个人同意第3、4、8条意见,也得5分。
再有,沙氏通量表无法获得受测者对各条语句同意或不同意程度的信息,这也是其缺点之一。
5.李克特量表李克特量表形式上与沙氏通量表相似,都要求受测者对一组与测量主题有关陈述语句发表自已的看法。
它们的区别是,沙氏通量表只要求受测者选出他所同意的陈述语句,而李克特量表要求受测者对每一个与态度有关的陈述语句表明他同意或不同意的程度。
另外,沙氏通量表中的一组有关态度的语句按有利和不利的程度都有一个确定的分值,而李克特量表仅仅需要对态度语句划分是有利还是不利,以便事后进行数据处理。
李克特量表构作的基本步骤如下:(1)收集大量(50~100)与测量的概念相关的陈述语句。
(2)有研究人员根据测量的概念将每个测量的项目划分为“有利”或“不利”两类,一般测量的项目中有利的或不利的项目都应有一定的数量。
(3)选择部分受测者对全部项目进行预先测试,要求受测者指出每个项目是有利的或不利的,并在下面的方向-强度描述语中进行选择,一般采用所谓“五点”量表:a.非常同意b.同意c.无所谓(不确定)d.不同意e.非常不同意(4)对每个回答给一个分数,如从非常同意到非常不同意的有利项目分别为1、2、3、4、5分,对不利项目的分数就为5、4、3、2、1。
(5)根据受测者的各个项目的分数计算代数和,得到个人态度总得分,并依据总分多少将受测者划分为高分组和低分组。
(6)选出若干条在高分组和低分组之间有较大区分能力的项目,构成一个李克特量表。
如可以计算每个项目在高分组和低分组中的平均得分,选择那些在高分组平均得分较高并且在低分组平均得分较低的项目。