指数平滑法及其在负荷预测中的应用
电力负荷预测常用方法的分析比较与应用

电力负荷预测常用方法的分析比较与应用电力负荷预测是指对未来一段时间内的电力负荷进行预测,以便电力公司合理安排发电计划、优化电网运行和保障用电需求。
电力负荷预测方法主要分为统计方法、基于模型的方法和机器学习方法,下面对这些方法进行详细分析比较与应用。
统计方法是电力负荷预测中最简单直接的方法之一,常用的统计方法有平均值法、移动平均法和指数平滑法。
这些方法通过历史负荷数据的统计特征来进行预测,在数据量较大、负荷变化较为平稳的情况下有一定的预测准确性。
然而,在面对复杂的负荷变化模式和非线性关系时,统计方法的预测效果较差。
基于模型的方法是利用电力负荷与影响其变化的相关因素之间的数学模型进行预测。
常见的基于模型的方法有回归模型、时序模型和神经网络模型。
回归模型通过建立负荷与时间、气温等因素之间的关系来进行预测,优点是简单易懂;时序模型将负荷视为一个时间序列,利用时间序列分析方法进行预测,适用于具有明显周期性的负荷变化;神经网络模型则通过训练神经网络来对负荷进行预测,可以较好地处理非线性关系。
基于模型的方法需要依赖较为完整和准确的数据,并且参数调整和模型选择较为困难,但在一些特定场景和较为规律的负荷变化中有较好的预测效果。
机器学习方法是近年来在电力负荷预测中得到广泛应用的一类方法。
这些方法通过训练预测模型来预测未知负荷,其中常见的机器学习方法有支持向量回归(SVR)、随机森林(RF)和深度学习模型等。
SVR是一种回归算法,通过非线性映射将输入数据映射到高维空间中,并在高维空间中寻找最优超平面,从而进行预测;RF基于集成学习的思想,通过随机产生多个决策树并利用投票方式进行预测;深度学习模型则是基于神经网络的一类算法,通过多层次的网络结构进行特征学习和预测。
相对于传统的统计方法和基于模型的方法,机器学习方法能够更好地处理非线性关系和复杂的负荷变化模式,在数据量较大和样本复杂的情况下取得了很好的效果。
在实际应用中,电力负荷预测方法的选择需要考虑多个因素,包括数据的可靠性、预测的时间范围、负荷变化的规律性等。
指数平滑法及其在负荷预测中的应用

指数平滑法及其在负荷预测中的应用
陈娟;吉培荣;卢丰
【期刊名称】《三峡大学学报(自然科学版)》
【年(卷),期】2010(32)3
【摘要】指数平滑法是电力系统负荷预测的主要方法之一,该方法的准确性取决于平滑系数α.对采用厚近薄远原则与远近相同原则优选α进行对比研究,结果表明采用厚近薄远原则优选α有更好的结果.在此基础上,结合相关分析,给出了厚近薄远的具体方案,并给出了负荷预测的具体实例.
【总页数】5页(P37-41)
【作者】陈娟;吉培荣;卢丰
【作者单位】三峡大学,电气与新能源学院,湖北,宜昌,443002;三峡大学,电气与新能源学院,湖北,宜昌,443002;荆州供电公司,湖北,荆州,434023
【正文语种】中文
【中图分类】TM715
【相关文献】
1.指数平滑法在电力系统负荷预测中的应用 [J], 吉博文;吴张傲
2.温斯特线性与季节性指数平滑法在电力负荷预测中的应用及改进 [J], 叶舟;陈康民
3.温斯特线性与季节性指数平滑法在电力负荷预测中的应用及改进 [J], 叶舟;陈康民
4.DF8003基于指数平滑法的短期电力负荷预测应用探讨 [J], 张云菊
5.指数平滑法在短期负荷预测中的应用 [J], 田德胜;刘厚法
因版权原因,仅展示原文概要,查看原文内容请购买。
电力系统中的电力负荷预测算法和模型优化

电力系统中的电力负荷预测算法和模型优化随着电力需求的不断增长和电力系统规模的扩大,电力负荷预测成为了电力系统运行和规划的关键。
准确的电力负荷预测可以帮助电力系统管理者合理安排电力供应,提高电力系统的可靠性和效率。
电力负荷预测是根据历史负荷数据和其他影响因素,通过建立预测模型来预测未来一段时间内的负荷需求。
在电力系统中,负荷预测涉及多种因素,包括天气状况、季节变化、节假日等。
为了提高电力负荷预测的准确性和精确度,研究人员提出了各种预测算法和模型优化方法。
下面将介绍一些常用的电力负荷预测算法和模型优化技术。
1. 时间序列分析方法时间序列分析是一种常用的电力负荷预测方法,它利用历史负荷数据的时间趋势和周期性来预测未来的负荷需求。
常用的时间序列分析方法包括ARIMA模型(自回归移动平均模型)和指数平滑模型。
ARIMA模型是一种基于统计学的负荷预测方法,它通过建立负荷数据的自回归和移动平均模型,来对未来的负荷进行预测。
指数平滑模型则是一种根据过去负荷数据的加权平均来预测未来负荷的方法,它对最近的负荷数据给予更高的权重。
2. 机器学习方法近年来,随着机器学习技术的快速发展,越来越多的研究人员开始将机器学习方法应用于电力负荷预测。
机器学习方法根据历史负荷数据和其他影响因素,通过训练模型来预测未来的负荷需求。
常用的机器学习方法包括支持向量机(SVM)、神经网络和决策树等。
支持向量机是一种常用的分类和回归分析方法,它通过构建超平面来对负荷数据进行分类和预测。
神经网络模型模拟了人脑的神经元连接,通过训练和优化权重来实现负荷预测。
决策树模型则通过建立一系列的决策规则来对负荷数据进行分类和预测。
3. 基于模型优化的方法除了选择适当的预测算法,模型优化也是提高负荷预测准确性的重要手段。
模型优化包括特征选择、参数优化和模型融合等技术。
特征选择是在建立预测模型时,选择最具相关性和重要性的特征进行建模。
通过剔除冗余和不相关的特征,可以提高模型的泛化能力和预测准确性。
电力系统中的电力负荷预测方法教程

电力系统中的电力负荷预测方法教程电力负荷预测是电力系统运行的重要组成部分,准确的负荷预测是保持电力系统的稳定运行、合理调度电力资源的关键。
在电力系统中,负荷预测的主要目标是预测未来一段时间内的电力负荷需求。
本文将介绍几种常用的电力负荷预测方法,包括传统的时间序列方法和基于机器学习的方法。
1. 时间序列方法时间序列方法是电力负荷预测中最常用的方法之一。
它基于历史负荷数据分析未来负荷的变化趋势。
时间序列方法需要建立模型来捕捉负荷数据的周期性和趋势性。
以下是一些常见的时间序列方法:1.1 移动平均法移动平均法是最简单的时间序列方法之一。
它通过计算每个时间点前几个时间点的负荷平均值来进行预测。
移动平均法适用于负荷呈现稳定的周期性变化的情况,但对于具有较大波动的负荷数据可能表现不佳。
1.2 指数平滑法指数平滑法是一种适用于具有趋势性的负荷数据的时间序列方法。
它根据历史数据的权重来预测未来负荷。
指数平滑法通过调整平滑系数来提高模型的准确性。
常见的指数平滑方法有简单指数平滑法和双指数平滑法。
1.3 季节分解法季节分解法是一种将负荷数据分解为趋势、季节和随机成分的方法。
该方法适用于数据存在明显的季节性变化的情况。
通过将负荷数据分解为不同的成分,可以更好地分析和预测负荷的未来变化。
2. 基于机器学习的方法随着机器学习算法的发展,越来越多的研究者开始将其应用于电力负荷预测领域。
相比于传统的时间序列方法,基于机器学习的方法可以更好地捕捉数据之间的非线性关系和复杂模式。
以下是一些常见的基于机器学习的方法:2.1 神经网络神经网络是基于人工智能领域的一种强大的模型,可用于负荷预测。
神经网络可以通过学习大量的历史负荷数据来预测未来负荷。
神经网络具有强大的适应性和非线性建模能力,但对于数据量较小的情况可能存在过拟合的问题。
2.2 支持向量机支持向量机是一种常用的机器学习算法,它可以通过寻找一个最优超平面来进行分类和回归问题。
电力系统中的负荷预测与调度方法

电力系统中的负荷预测与调度方法一、引言电力系统是现代社会不可或缺的基础设施之一,负荷预测与调度是电力系统运行中不可或缺的环节。
准确的负荷预测和合理的负荷调度能够提高电力系统的运行效率,保障供电的可靠性和稳定性。
本文将探讨电力系统中的负荷预测与调度方法,从而为电力系统的优化运行提供支持。
二、负荷预测方法负荷预测是指通过对历史数据的分析和建模,预测未来一段时间内的负荷需求。
常见的负荷预测方法包括统计方法、时间序列方法和人工智能方法。
1. 统计方法统计方法是根据历史数据进行统计分析和推断,预测出未来的负荷需求。
常用的统计方法包括回归分析、指数平滑法和趋势法。
回归分析通过建立负荷与影响因素之间的回归关系来预测负荷需求。
指数平滑法根据历史数据的加权平均值进行预测,适用于短期负荷预测。
趋势法则通过寻找历史数据中的趋势来预测未来负荷需求。
2. 时间序列方法时间序列方法是基于一系列数据随时间变化的规律性进行预测。
常用的时间序列方法包括移动平均法、指数平滑法、ARIMA模型和回归模型。
移动平均法通过计算历史数据的平均值来预测未来负荷需求。
指数平滑法通过对历史数据的加权平均来预测未来负荷需求。
ARIMA模型是一种常用的时间序列模型,可以捕捉到负荷的季节性和趋势性。
回归模型则通过建立负荷与影响因素之间的回归关系进行预测。
3. 人工智能方法人工智能方法包括神经网络、支持向量机和遗传算法等。
神经网络是一种模拟人脑神经元工作方式的机器学习算法,可以通过对历史数据的学习来预测未来负荷需求。
支持向量机是一种监督学习算法,能够建立负荷与影响因素之间的非线性回归关系。
遗传算法则是一种基于生物进化原理的优化算法,可以用于寻找最优的负荷预测模型参数。
三、负荷调度方法负荷调度是指在不同时间段内对电力系统中的发电机组和负荷进行合理安排和调度,以满足电力供需平衡和经济运行的要求。
1. 优化调度方法优化调度方法通过建立数学模型,以最小化电力系统的运行成本为目标,确定最优的发电机组出力和负荷供需平衡。
电力系统中的负荷预测算法与模型构建

电力系统中的负荷预测算法与模型构建随着工业化和城市化的快速发展,电力需求也不断增长。
为了满足日益增长的电力需求,电力系统必须能够准确预测未来的负荷,以便进行合理的发电规划和运行调度。
本文将介绍电力系统中常用的负荷预测算法和模型构建方法,并探讨它们的优缺点。
1. 基于统计方法的负荷预测算法基于统计方法的负荷预测算法是使用历史负荷数据进行预测的一种方法。
常用的统计方法包括移动平均法、指数平滑法和回归分析法。
移动平均法是一种简单的算法,它通过计算历史负荷数据的平均值来进行预测。
然而,这种方法没有考虑到负荷数据的趋势和季节性变化,因此在长期预测上效果较差。
指数平滑法是一种常见的算法,它通过加权计算历史负荷数据的平均值来进行预测。
这种方法考虑了近期数据的权重,能够较好地预测短期变化,但对于长期趋势的预测效果有限。
回归分析法是一种使用回归模型进行预测的方法。
它根据历史负荷数据和其他影响因素的关系,建立了一个数学模型来进行预测。
这种方法能够较好地考虑到各种因素对负荷的影响,预测精度相对较高。
2. 基于机器学习的负荷预测算法随着机器学习技术的快速发展,越来越多的电力系统开始采用基于机器学习的负荷预测算法。
基于机器学习的负荷预测算法可以通过训练模型来学习历史负荷数据和其他影响因素之间的复杂关系,从而实现更准确的负荷预测。
常用的基于机器学习的负荷预测算法包括支持向量机(SVM)、人工神经网络(ANN)和决策树等。
支持向量机是一种监督学习算法,它通过构造一个最优划分超平面来进行分类或回归。
在负荷预测中,支持向量机可以通过训练模型来学习历史负荷数据和其他影响因素之间的关系,并进行未来负荷的预测。
人工神经网络是一种模拟人脑神经元工作方式的算法。
它通过建立具有多个神经元的网络结构来进行学习和预测。
在负荷预测中,人工神经网络可以通过训练模型来学习历史负荷数据和其他影响因素之间的复杂关系,并进行准确的负荷预测。
决策树是一种基于树形结构的分类和回归算法。
电力电量负荷预测方法及应用分析

电力电量负荷预测方法及应用分析作者:刘慷来源:《科技资讯》2012年第33期摘要:为了进一步提高预测精度,则需要对传统方法进行一些改进,使预测结果具有更高的参考价值,本文主要探讨了时间序列预测法以及其实际运用。
关键词:负荷预测时间序列法中图分类号:TM93 文献标识码:A 文章编号:1672-3791(2012)11(c)-0105-02电力负荷预测具有十分重要的作用,其是调度中心制订发电计划及发电厂报价的依据,同时其也可以为发电计划程序、离线网络分析和合理的调度安排提供数据,而其准确率的高低对电力系统的运行、控制和生产计划都有着非常重要的影响。
为了更加准确的预测市场对电力电量的需求,现如今已有很多预测方法被用于电力电量的预测,各种方法都有其优缺点。
随着电力市场的发展,人们对负荷预测精度的要求也越来越高。
为了进一步提高预测精度,则需要对传统方法进行一些改进,使预测结果具有更高的参考价值。
随着现代科学技术的不断进步,理论研究的逐步深入,以灰色理论、时间序列理论、模糊数学等为代表的新兴交叉学科理论的出现,为负荷预测的飞速发展提供了坚实的理论依据和数学基础。
1 负荷预测及分类电力负荷实质上是指电力的需求量或用电量,即能量的时间变化率,也可以被定义为发电厂、供电地区或电网在某一瞬间所承担的工作负荷。
电力负荷往往具有以下一些特点:(1)电力负荷往往以天为单位不断起伏的,具有较大的周期性;(2)电力负荷的变化过程一般不会有较大的突变,属于连续性变化;(3)电力负荷对一些因素会比较敏感,比如季节、温度、天气等。
在对负荷进行预测时,需要考虑系统的运行特性、增容决策等因数,以便更加准确的确定未来某特定时刻的负荷数据。
就负荷本身而言,其主要是指电力需求量或用电量。
电力电量预测对电力系统安全经济运行和国名经济发展具有重要意义。
由于对电力负荷进行预测的目的会有所不同,所以将其分为四类即:(1)超短期负荷预测,主要是用于对未来一小时以内的负荷进行预测;(2)短期负荷预测,主要是指日负荷预测和周负荷预测,分别用于安排日调度计划和周调度计划;(3)中期负荷预测,主要是指一个月到一年的负荷预测,主要用于确定机组运行方式和设备的大规模修理计划等情况;(4)长期负荷预测,主要指未来3~5年甚至更长时间内的负荷预测,主要是用于电网规划部门。
指数平滑预测法及其在经济预测中的应用
中图分 类号 : F 2 2
文献标志码 : A 文章编 号 : 1 6 7 3 — 2 9 1 X( 2 0 1 3 ) 0 4 — 0 0 1 1 - 0 3
一
、
时 间序 列分 析
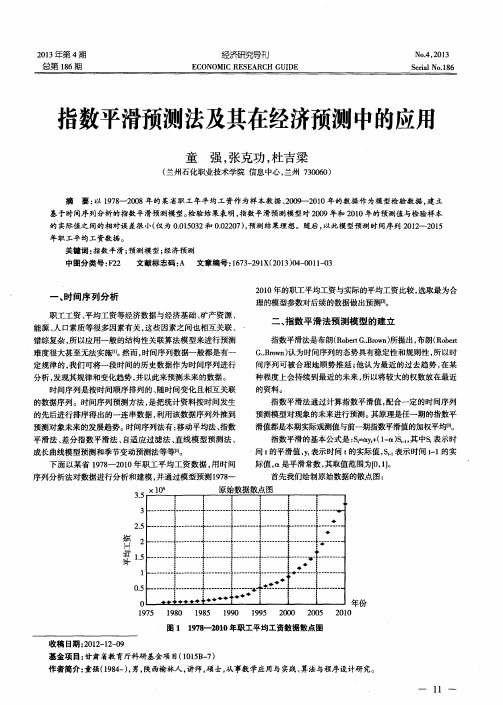
2 0 1 0 年 的职工平均工资与实际的平均工资 比较 , 选取最为合 理的模型参数对后续的数据做 出预测网 。
表1 所示 ) , 2 0 0 9 年和 2 0 1 0 年的数据作 为模型 的检验数据 。
1 9 8 1 3 2 o 0 8 3 0
年份编号 1 9 8 0 2
根据 经验 、 实 际运算 分 析和 观察 , 选取 — 5 6 — 6 + 6 3 『 2 _ 一 + 一 7 4 5 = 6 4 7 . 6 7 , 并 分 别 选 取0 【 = o _ 3 , 仅 = o . 2 5 , 0 l = O . 2 , 仅 = 0 . 1 5 , n = 0 . 1 对 原 始 数 据 做 指 数 平 滑, 预 测 情 况
摘
要: 以1 9 7 8 -2 0 0 8年的 某省 职工年平 均工资作为样本数据 、 2 0 0 9 - - 2 0 1 0年 的数据作 为模 型检 验数据 , 建立
基于时间序列分析的指数平滑预测模型。 检验结果表明 , 指数平 滑预测模型对 2 0 0 9 年和 2 0 1 0 年的预 测值 与检验样本
指数平滑 的基本公式是 : S t =  ̄ y t + ( 1 - a ) S 其 中s 表示时
间t 的平滑值 , y t 表示时间 t 的实际值 , s 。 表示时间 卜1 的实 际值 , 是平 滑常数 , 其取值范围为【 O , 1 】 。 首先我们绘制原始数据的散点图 :
( 见表 2 ) : 表2 指 数 平 滑 预 测 结 果
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
E
| Xt - X ^t | Xt
( 17)
以上 4 个公式都有一个共同点, 即把各期的模型 误差不分远近同等看待, 但实际上 , 近期的误差对预 测的影响比远期的误差要大 . 应该这样说, 衡量外推
第 32 卷
第3期
陈
娟等
指数 平滑法及其在负荷预测中的应用
39
预测误差大小的判据与衡量曲线的拟合程度, 判据应 该有所不同 , 后者可对各期的绝对误差值采用等权的 算术平均计算, 而前者宜采用/ 厚近薄远0 的加权算术 平均[ 3] , / 厚近薄远0可以体现近期误差比较重要的特 点. 2. 2 采用/ 厚近薄远0 原则优选 A 值时权重大小及判 据公式的选择 / 厚近薄远0 原则的物理意义是 , 物理量未来的变 化趋势更多地取决于历史时段中近期的发展规律, 远 期的历史数据与未来发展趋势的相关性较弱 [ 4] . / 厚近薄远0 的具体做法有多种 , 本文采用的方法 如下 : 给定一个 B( 0< B < 1) , 将模型误差用下列各式 确定 : 加权平均平方和误差 : WMSE = 1 n 加权均方根误差 : WRMSE = , St 为第 t 期的平滑值; x t 为第 t 期的实际观察 值; S t- 1 为第 t - 1 期的平滑值 ; A为平滑常数 , 其取值 范围为 ( 0, 1) ; 将 St - 1 = A x t - 1 + ( 1- A ) St - 2 , S t - 2 = A x t- 1 + ( 1- A ) St - 3 , St - 3 = A x t - 1 + ( 1- A ) St - 4 , , 代 入公式( 1) 可得 : St = A xt + A (1- A ) x t- 1 + A (1- A ) x t- 2 + A (1- A ) 3 x t- 3 + , + A (1- A ) t- 1 x 1 + ( 1 - A ) tS 0 上述公式中各项系数和为 A+ A ( 1- A )+ A (1- A ) + , + A ( 1- A )
摘要 : 指数平滑法是电力系统负荷预测的主要方法之一, 该方法的准确性取决于平滑系数 A . 对采 用厚近薄远原则与远近相同原则优选 A 进行对比研究, 结果表明采用厚近薄远原则优选 A 有更好 的结果. 在此基础上, 结合相关分析, 给出了厚近薄远的具体方案, 并给出了负荷预测的具体实例 . 关键词: 负荷预测 ; 中图分类号: TM715 指数平滑法 ; 平滑系数; 优选 文章编号 : 16722948X( 2010) 0320037205 文献标识码: A
.
电力系统负荷预测理论和方法随时代的发展而 进步 , 如今在深度和广度上都有了长足的进步. 负荷 预测总的来说可分为非数学和数学方法两大类 . 非数 学方法有国际比较法、 专家估计法等 , 数学方法主要 包括相关法和外推法两类 . 相关法有回归分析法和投 入产出法; 外推法有指数平滑法、 时间序列法、 卡尔曼 滤波法等 . 指数平滑法作为外推法中的一种重要类型 , 运用 尤为普遍 . 原因在于这种方法建立的模型较简单, 计 算简便、 需要存贮的数据少, 通过近期的观察值能很 快地计算出新的预测值 . 在电力负荷预测方面, 它既 可用于对未来周日以小时负荷为统计样本的短期预
第 32 卷 第 3 期 2010 年 6 月
三峡 大学学报 ( 自然科学版 ) J of China Three Gor ges Univ. ( Natura l Sciences)
Vol 1 32 No 13 Jun1 2010
指数平滑法及其在负荷预测中的应用
陈 娟1 吉培荣1 卢 丰2
434023) ( 1. 三峡大学 电气与新能源学院, 湖北 宜昌 443002; 2. 荆州供电公司, 湖北 荆州
1
1. 1
指数平滑法介绍
指数平滑法基本原理 指数平滑法的一般公式是 : St = A xt + (1- A ) S t- 1 ( 1)
a t = 3S (t 1) - 3S (t 2) + S(t 3) bt = A ( 1) [ ( 6- 5A )St 2( 1 - A )2
( 8)
2( 5 - 4A ) S(t 2) + ( 4 - 3 A ) S(t 3) ] ct = A ( 1) - 2S(t 2) + S(t 3) ] 2 [ St 2( 1- A )
accuracy of t he met hod depends on smoot hing coefficient A . In t his paper, a st udy of how to seek t he best A is given. T he results show t hat the use of principle of valueing near errors and cont empt ing far error s can get a bet t er model. On this basis, combined wit h correlat ive analysis, a met hod of how t o value near er rors and cont empt far err ors is proposed. A pract ical example of load forecasting is also shown here. Keywor ds load forecast ing; exponent ial smoot hing met hod; smoot hing coefficient ; opt imum seeking
Exponential Smoothing Method and Its Application to Load Forecasting
Chen Juan1 Ji Peirong1 Lu Feng2
( 1. Col lege of Elect rical Engineering & Renewable Energy, China Three Gorges Univ. , Yichang 443002, China; 2. Jingzhou Power Supply Company, Jingzhou 434023, China) Abstr act Exponent ial smoot hing met hod is one of the main load forecasting met hods for power syst em; the
t 2 t- 1 2
以上各式 中, S(t 1) 、 S (t 2) 、 S(t 3) 分别 为 t 期的一 次平滑 值、 二次平滑值、 三次平滑值. 各次平滑 值计算公式 为: 一次指数平滑值: S (t 1) = A X t + (1- A ) S (t-1)1 二次指数平滑值: S(t 2) = A X (t 1) + ( 1 - A ) S(t-2)1 三次指数平滑值: S(t 3) = A X (t 2) + ( 1 - A ) S(t-3)1 ( 13)
nWMAE = 1 E | et | B n t= 1 加权平均绝对百分比误差 : n t n t= 1
Ee B
n t= 1
2 n- t t
( 18)
图 1 优 选过程的流程图
1 n
E eB
2 t
n- t
( 19)
3
实验研究
( 20)
以下 6 组数据分别为确定性数据 ( 数据 [ 1] ) 、 有 随机偏差数据 ( 数据 [ 2] - [ 4] ) 和实际年度负荷数据 ( 数据[ 5] - [ 6] ) . 数据 [ 1] : 10, 10. 5, 11, 11. 5, 12, 12. 5, 13, 13. 5, 14, 14. 5, 15, 15. 5. 数据 [ 2] : 6, 14, 16, 24, 26, 34, 36, 44, 46, 54, 56, 64. 数据 [ 3] : 1, 2, 9, 11, 24, 28, 46, 54, 76, 88, 114, 130. 数据 [ 4] : 2, 6, 10, 8, 15, 25, 31, 49, 67, 86, 97, 95. 数据 [ 5] : 10. 2, 14. 3, 17. 6, 21. 4, 26. 9, 27. 7, 28. 9, 30. 4, 32. 1, 35. 7, 39. 9, 45. 2 ( 河 南 省 某 市 1992~ 2003 年用电量数据 ) . 数据 [ 6] : 142. 879, 164. 962, 187. 018, 223. 645, 259. 477, 279. 949, 299. 731, 320. 195, 353. 370, 401. 515, 439. 186, 496. 839( 福建省 1991~ 2002 年全社会用电 量数据) . 实验过程中, 分别采用 MA PE 和 WMAPE 作为 优选平滑系数 A 的目标函数 . 实验程序用 Delphi 语 言编制 , 用前 11 个 ( 年 ) 的数据按照远近相同原则和 厚近薄远的原则优选出的平滑系数 A值 , 见表 1. 从表 1 可以看出 , 对于确定性的数据 , 建模时采用远近相 同原则和厚近薄远的原则优选出的 A 值是一样的 ; 而 对非确定性的数据 , 总体上看两种原则优选出的平滑 系数是不一样的. 对非确定性的数据, 当 B\ 0. 95 时,
( 1) t- 1
( 11) ( 12)
+ ( 2)
t 1- (1- A ) t (1- A ) = A 1- (1- A ) ) + ( 1- A t
以上各式中 , X t 为 t 期的观察值 , S 、 S 期、 t- 1 期的一次平滑值, S 、 S 期的二次平滑值 , S 、 S 次平滑值 .