计量经济学-第一章 简单回归模型
计量经济学实验一 一元回归模型
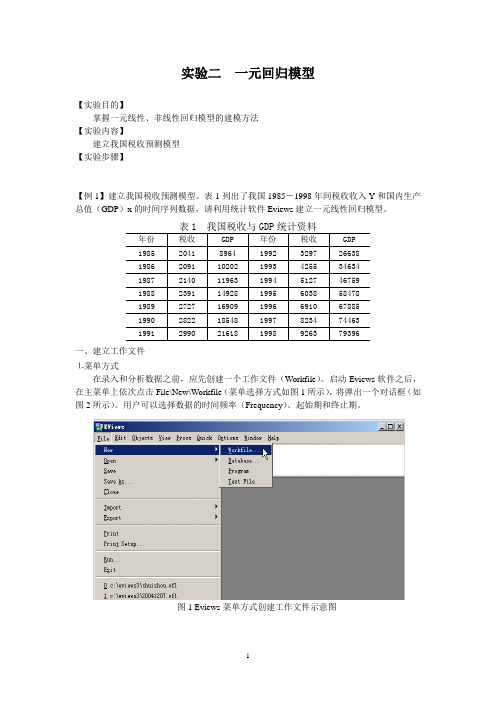
实验二一元回归模型【实验目的】掌握一元线性、非线性回归模型的建模方法【实验内容】建立我国税收预测模型【实验步骤】【例1】建立我国税收预测模型。
表1列出了我国1985-1998年间税收收入Y和国内生产总值(GDP)x的时间序列数据,请利用统计软件Eviews建立一元线性回归模型。
一、建立工作文件⒈菜单方式在录入和分析数据之前,应先创建一个工作文件(Workfile)。
启动Eviews软件之后,在主菜单上依次点击File\New\Workfile(菜单选择方式如图1所示),将弹出一个对话框(如图2所示)。
用户可以选择数据的时间频率(Frequency)、起始期和终止期。
图1 Eviews菜单方式创建工作文件示意图图2 工作文件定义对话框本例中选择时间频率为Annual(年度数据),在起始栏和终止栏分别输入相应的日期85和98。
然后点击OK,在Eviews软件的主显示窗口将显示相应的工作文件窗口(如图3所示)。
图3 Eviews工作文件窗口一个新建的工作文件窗口内只有2个对象(Object),分别为c(系数向量)和resid(残差)。
它们当前的取值分别是0和NA(空值)。
可以通过鼠标左键双击对象名打开该对象查看其数据,也可以用相同的方法查看工作文件窗口中其它对象的数值。
⒉命令方式还可以用输入命令的方式建立工作文件。
在Eviews软件的命令窗口中直接键入CREATE命令,其格式为:CREATE 时间频率类型起始期终止期本例应为:CREATE A 85 98二、输入数据在Eviews软件的命令窗口中键入数据输入/编辑命令:DA TA Y X此时将显示一个数组窗口(如图4所示),即可以输入每个变量的数值图4 Eviews数组窗口三、图形分析借助图形分析可以直观地观察经济变量的变动规律和相关关系,以便合理地确定模型的数学形式。
⒈趋势图分析命令格式:PLOT 变量1 变量2 ……变量K作用:⑴分析经济变量的发展变化趋势⑵观察是否存在异常值本例为:PLOT Y X⒉相关图分析命令格式:SCAT 变量1 变量2作用:⑴观察变量之间的相关程度⑵观察变量之间的相关类型,即为线性相关还是曲线相关,曲线相关时大致是哪种类型的曲线说明:⑴SCAT命令中,第一个变量为横轴变量,一般取为解释变量;第二个变量为纵轴变量,一般取为被解释变量⑵SCAT命令每次只能显示两个变量之间的相关图,若模型中含有多个解释变量,可以逐个进行分析⑶通过改变图形的类型,可以将趋势图转变为相关图本例为:SCA T Y X图5 税收与GDP趋势图图5、图6分别是我国税收与GDP时间序列趋势图和相关图分析结果。
《计量经济学》eviews实验报告一元线性回归模型

《计量经济学》实验报告一元线性回归模型
三、实验步骤(简要写明实验步骤)
1、数据的输入、编辑
2、图形分析与描述统计分析
3、数据文件的存贮、调用
4、一元线性回归的过程
点击view中的Graph-scatter-中的第三个获得
在上方输入ls y c x回车得到下图
在上图中view处点击view-中的actual,Fitted,Residual中的第一个得到回归残差
打开Resid中的view-descriptive statistics得到残差直方图
打开工作文件第二个中的structure将workfiels选中第一个,将右边改为16个
之后打开工作文件xy右键双击,open-as grope
在回归方程中有Forecast,残差立为yfse,点击ok后自动得到下图
在上方空白处输入ls y c s---之后点击proc 中的forcase 根据
公式)|(0^
0X Y Y E 得到2015估计量
四、实验结果及分析(将本问题的回归模型写出,并作出经济意义检。
计量经济学作业——简单线性回归模型

计量经济学作业姓名:***班级:08级数学一班学号:***********简单线性回归模型一、建立模型为了研究四川省城镇具名消费支出以及可支配收入之间的关系,又经济理论分析可知,收入是影响居民消费支出的主要因素,居民消费支出Y与可支配收入X之间存在密切的关系,消费支出随着收入的增加而增加,但变动的幅度相比较低,即边际消费倾向MPC有0<MPC<1。
因此可设定居民消费支出Yi与Xi的关系为:Yi=ß1+ß2Xi+ui,其中ß1表示四川省城镇居民家庭平均每人年生活性消费支出(元);Xi为城镇居民家丁平均没人年可支配收入(元)。
变量采用年度数据,样本期为1978-1998年。
这里的ß1为居民没有收入来源时的最低消费。
二、估计模型中的位置参数假设模型中的随机误差项ui满足古典假定,运用OLS方法估计模型的参数,利用计量经济学计算机软件EViews计算过程如下:简历文档,输入数据首先点击EViews图标,进入EViews主页。
点击File后,在File菜单的New选项中点击Workfile,这时屏幕上出现Workfile Range对话框,在Srart Date里键入1978,在End Date里键入1998,点击OK后屏幕出现Workfile工作框。
在Object菜单栏,点击New Object对话框里选Group并在Name for Object上定义文件名,点击OK,屏幕出现数据编辑框。
也可在光标出直接输入Data Y X,回车后即可出现数据编辑框。
此时可录入数据,首先按上行键,这时对应“obs”字样的空格会自动上跳,在对应第二个“obs”字样,有边框的空格里键入变量名,再按下行键,这时对应变量名下的这一列出现“NA”字样,便可依时间顺序键入相应的数据。
其他变量的数据类似输入。
可以几个变量同时录入数据。
在主页上选Quick菜单,点击Eatimate Equation项,屏幕上出现估计对话框(Equation Spacification),在Easmation Setting中选OLS估计,即Least Squares,键入Y C X或Y X C(C为EViews固定的截距系数)。
伍德里奇《计量经济学导论》 第 版 笔记和课后习题详解 章

使用普通最小二乘法,此时最小化的残差平方和为()211niii y x β=-∑利用一元微积分可以证明,1β必须满足一阶条件()110niiii x y x β=-=∑从而解出1β为:1121ni ii nii x yxβ===∑∑当且仅当0x =时,这两个估计值才是相同的。
2.2 课后习题详解一、习题1.在简单线性回归模型01y x u ββ=++中,假定()0E u ≠。
令()0E u α=,证明:这个模型总可以改写为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
证明:在方程右边加上()0E u α=,则0010y x u αββα=+++-令新的误差项为0e u α=-,因此()0E e =。
新的截距项为00αβ+,斜率不变为1β。
2(Ⅰ)利用OLS 估计GPA 和ACT 的关系;也就是说,求出如下方程中的截距和斜率估计值01ˆˆGPA ACT ββ=+^评价这个关系的方向。
这里的截距有没有一个有用的解释?请说明。
如果ACT 分数提高5分,预期GPA 会提高多少?(Ⅱ)计算每次观测的拟合值和残差,并验证残差和(近似)为零。
(Ⅲ)当20ACT =时,GPA 的预测值为多少?(Ⅳ)对这8个学生来说,GPA 的变异中,有多少能由ACT 解释?试说明。
答:(Ⅰ)变量的均值为: 3.2125GPA =,25.875ACT =。
()()15.8125niii GPA GPA ACT ACT =--=∑根据公式2.19可得:1ˆ 5.8125/56.8750.1022β==。
根据公式2.17可知:0ˆ 3.21250.102225.8750.5681β=-⨯=。
因此0.56810.1022GPA ACT =+^。
此处截距没有一个很好的解释,因为对样本而言,ACT 并不接近0。
如果ACT 分数提高5分,预期GPA 会提高0.1022×5=0.511。
(Ⅱ)每次观测的拟合值和残差表如表2-3所示:根据表可知,残差和为-0.002,忽略固有的舍入误差,残差和近似为零。
计量经济学复习要点

计量经济学复习要点第1章 绪论数据类型:截面、时间序列、面板用数据度量因果效应,其他条件不变的概念 习题:C1、C2第2章 简单线性回归回归分析的基本概念,常用术语现代意义的回归是一个被解释变量对若干个解释变量依存关系的研究,回归的实质是由固定的解释变量去估计被解释变量的平均值;简单线性回归模型是只有一个解释变量的线性回归模型; 回归中的四个重要概念1. 总体回归模型Population Regression Model,PRMt t t u x y ++=10ββ--代表了总体变量间的真实关系;2. 总体回归函数Population Regression Function,PRFt t x y E 10)(ββ+=--代表了总体变量间的依存规律;3. 样本回归函数Sample Regression Function,SRFtt t e x y ++=10ˆˆββ--代表了样本显示的变量关系; 4. 样本回归模型Sample Regression Model,SRMtt x y 10ˆˆˆββ+=---代表了样本显示的变量依存规律; 总体回归模型与样本回归模型的主要区别是:①描述的对象不同;总体回归模型描述总体中变量y 与x 的相互关系,而样本回归模型描述所关的样本中变量y 与x 的相互关系;②建立模型的依据不同;总体回归模型是依据总体全部观测资料建立的,样本回归模型是依据样本观测资料建立的;③模型性质不同;总体回归模型不是随机模型,而样本回归模型是一个随机模型,它随样本的改变而改变;总体回归模型与样本回归模型的联系是:样本回归模型是总体回归模型的一个估计式,之所以建立样本回归模型,目的是用来估计总体回归模型; 线性回归的含义线性:被解释变量是关于参数的线性函数可以不是解释变量的线性函数 线性回归模型的基本假设简单线性回归的基本假定:对模型和变量的假定、对随机扰动项u 的假定零均值假定、同方差假定、无自相关假定、随机扰动与解释变量不相关假定、正态性假定 普通最小二乘法原理、推导最小二乘法估计参数的原则是以“残差平方和最小”;Min21ˆ()niii Y Y =-∑01ˆˆ(,)ββ: 1121()()ˆ()nii i n ii XX Y Y X X ==--β=-∑∑ , 01ˆˆY X β=-βOLS 的代数性质拟合优度R 2离差平方和的分解:TSS=ESS+RSS“拟合优度”是模型对样本数据的拟合程度;检验方法是构造一个可以表征拟合程度的指标——判定系数又称决定系数;121SSE SST SSR SSRR SST SST SST-===-,表示回归平方和与总离差平方和之比;反映了样本回归线对样本观测值拟合优劣程度的一种描述; 2 2[0,1]R ∈;3 回归模型中所包含的解释变量越多,2R 越大改变度量单位对OLS 统计量的影响函数形式对数、半对数模型系数的解释101ˆˆˆi iY X =β+β:X 变化一个单位Y 的变化 201ˆˆˆln ln i i Y X =β+β: X 变化1%,Y 变化1ˆβ%,表示弹性; 301ˆˆˆln i i Y X =β+β:X 变化一个单位,Y 变化百分之1001ˆβ 401ˆˆˆln i i Y X =β+β:X 变化1%,Y 变化1ˆβ%; OLS 无偏性,无偏性的证明 OLS 估计量的抽样方差 误差方差的估计 OLS 估计量的性质1线性:是指参数估计值0β和1β分别为观测值t y 的线性组合; 2无偏性:是指0β和1β的期望值分别是总体参数0β和1β; 3最优性最小方差性:是指最小二乘估计量0β和1β在在各种线性无偏估计中,具有最小方差;高斯-马尔可夫定理OLS 参数估计量的概率分布2^22()iVar x σβ=∑OLS 随机误差项μ的方差σ2的估计 简单回归的高斯马尔科夫假定 对零条件均值的理解习题:4、5、6;C2、C3、C4第3章 多元回归分析:估计1、变量系数的解释剔除、控制其他因素的影响对斜率系数1ˆβ的解释:在控制其他解释变量X2不变的条件下,X1变化一个单位对Y 的影响;或者,在剔除了其他解释变量的影响之后,X1的变化对Y 的单独影响2、多元线性回归模型中对随机扰动项u 的假定,除了零均值假定、同方差假定、无自相关假定、随机扰动与解释变量不相关假定、正态性假定以外,还要求满足无多重共线性假定;3、多元线性回归模型参数的最小二乘估计式;参数估计式的分布性质及期望、方差和标准误差;在基本假定满足的条件下,多元线性回归模型最小二乘估计式是最佳线性无偏估计式;最小二乘法 OLS 公式:Y ' X X)' (X ˆ-1=β 估计的回归模型:的方差协方差矩阵:残差的方差 : 估计的方差协方差矩阵是: 拟合优度 遗漏变量偏误 多重共线性多重共线性的概念多重共线性的后果 多重共线性的检验 多重共线性的处理习题:1、2、6、7、8、10;C2、C5、C6第4章 多元回归分析:推断经典线性模型假定 正态抽样分布2^22i e n σ=-∑变量显着性检验,t 检验 检验β值的其他假设 P 值实际显着性与统计显着性 检验参数的一个线性组合假设 多个线性约束的检验:F 检验 理解排除性约束 报告回归结果习题:1、2、3、4、6、7、10、11;C3、C5、C8第6章 多元回归分析:专题测度单位对OLS 统计量的影响 进一步理解对数模型 二次式的模型 交互项的模型 拟合优度修正可决系数的作用和方法;习题:1、3、4、7;C2、C3、C5、C9、C12第7章 虚拟变量虚拟变量的定义如何引入虚拟变量:如果一个变量分成N 组,引入该变量的虚拟变量形式是只能放入N-1个虚拟变量 虚拟变量系数的解释虚拟变量系数的解释:不同组均值的差基准组或对照组与处理组 以下几种模型形式表达的不同含义;1tt t t u D X Y +++=210βββ:截距项不同; 2tt t t t u X D X Y +++=210βββ:斜率不同;3tt t t t t u X D D X Y ++++=3210ββββ:截距项与斜率都不同;其中D 是二值虚拟变量,X 是连续的变量;虚拟变量陷阱虚拟变量的交互作用习题:2、4、9;C2、C3、C6、C7、C11第8章异方差异方差的后果异方差稳健标准误BP检验异方差的检验White检验加权最小二乘法习题:1、2、3、4;C1、C2、C8、C9Eviews回归结果界面解释表计量经济学复习题第1章习题:C1、C2第2章习题:4、5、6;C2、C3、C4第3章习题:1、2、6、7、8、10;C2、C5、C6 第4章习题:1、2、3、4、6、7、10、11;C3、C5、C8 第6章习题:1、3、4、7;C2、C3、C5、C9、C12 第7章习题:2、4、9;C2、C3、C6、C7、C11 第8章习题:1、2、3、4;C1、C2、C8、C9 1、判断下列表达式是否正确2469 2、给定一元线性回归模型:1叙述模型的基本假定;2写出参数0β和1β的最小二乘估计公式; 3说明满足基本假定的最小二乘估计量的统计性质; 4写出随机扰动项方差的无偏估计公式; 3、对于多元线性计量经济学模型:1该模型的矩阵形式及各矩阵的含义; 2对应的样本线性回归模型的矩阵形式; 3模型的最小二乘参数估计量;4、根据美国1961年第一季度至1977年第二季度的数据,我们得到了如下的咖啡需求函数的回归方程:D D D P I P t t t t t t tT Q 321'0097.0157.00961.00089.0ln 1483.0ln 5115.0ln 1647.02789.1ˆln ----++-=其中,Q=人均咖啡消费量单位:磅;P=咖啡的价格以1967年价格为不变价格;I=人均可支配收入单位:千元,以1967年价格为不变价格;P '=茶的价格1/4磅,以1967年价格为不变价格;T=时间趋势变量1961年第一季度为1,…,1977年第二季度为66;D 1=1:第一季度;D 2=1:第二季度;D 3=1:第三季度; 请回答以下问题:① 模型中P 、I 和P '的系数的经济含义是什么 ② 咖啡的需求是否很有弹性③ 咖啡和茶是互补品还是替代品 ④ 你如何解释时间变量T 的系数 ⑤ 你如何解释模型中虚拟变量的作用 ⑥ 哪一个虚拟变量在统计上是显着的 ⑦ 咖啡的需求是否存在季节效应5、为研究体重与身高的关系,我们随机抽样调查了51名学生其中36名男生,15名女生,并得到如下两种回归模型:h W5662.506551.232ˆ+-= t=h D W7402.38238.239621.122ˆ++-= t=其中,Wweight=体重 单位:磅;hheight=身高 单位:英寸 请回答以下问题:① 你将选择哪一个模型为什么② 如果模型确实更好,而你选择了,你犯了什么错误 ③ D 的系数说明了什么6、简述异方差对下列各项有何影响:1OLS 估计量及其方差;2置信区间;3显着性t 检验和F 检验的使用;4预测;7、假设某研究者基于100组三年级的班级规模CS 和平均测试成绩TestScore 数据估计的OLS 回归为:(1) 若某班级有22个学生,则班级平均测试成绩的回归预测值是多少 (2) 某班去年有19个学生,而今年有23个学生,则班级平均测试成绩变化的回归预测值是多少(3) 100个班级的样本平均班级规模为,则这100个班级的样本平均测试成绩是多少(4) 100个班级的测试成绩样本标准差是多少提示:利用R 2和SER 的公式 (5) 求关于CS 的回归斜率系数的95%置信区间;(6) 计算t 统计量,根据经验法则t=2来判断显着性检验的结果; 8、设从总体中抽取一容量为200的20岁男性随机样本,记录他们的身高和体重;得体重对身高的回归为:其中体重的单位是英镑,身高的单位是英寸;(1) 身高为70英寸的人,其体重的回归预测值是多少65英寸的呢74英寸的呢(2) 某人发育较晚,一年里蹿高了英寸;则根据回归预测体重增加多少 (3) 解释系数值和的含义;(4)假定不用英镑和英寸度量体重和身高而分别用厘米和千克,则这个新的厘米-千克回归估计是什么给出所有结果,包括回归系数估计值,R2和SER;(5)基于回归方程,能对一个3岁小孩的体重假设身高1米作出可靠预测吗9、假设某研究使用250名男性和280名女性工人的工资Wage数据估计出如下OLS回归:标准误其中WAGE的单位是美元/小时,Male为男性=1,女性=0的虚拟变量;用男性和女性的平均收入之差定义工资的性别差距;1性别差距的估计值是多少2计算截距项和Male系数的t统计量,估计出的性别差距统计显着不为0吗5%显着水平的t统计量临界值为3样本中女性的平均工资是多少男性的呢4对本回归的R2你有什么评论,它告诉了你什么,没有告诉你什么这个很小的R2可否说明这个回归模型没有什么价值5另一个研究者利用相同的数据,但建立了WAGE对Female的回归,其中Female为女性=1,男性=0的变量;由此计算出的回归估计是什么10、基于美国CPS人口调查1998年的数据得到平均小时收入对性别、教育和其他特征的回归结果,见下表;该数据集是由4000名全年工作的全职工人数据组成的;其中:AHE=平均小时收入;College=二元变量大学取1,高中取0;Female女性取1,男性取0;Age=年龄年;Northeast居于东北取1,否则为0;Midwest居于中西取1,否则为0;South居于南部取1,否则为0;West居于西部取1,否则取0;表1:基于2004年CPS数据得到的平均小时收入对年龄、性别、教育、地区的回归结果概括统计量和联合检验SERR2注:括号中是标准误;(1)计算每个回归的调整R2;(2)利用表1中列1的回归结果回答:大学毕业的工人平均比高中毕业的工人挣得多吗多多少这个差距在5%显着性水平下统计显着吗男性平均比女性挣的多吗多多少这个差距在5%显着性水平下统计显着吗(3)年龄是收入的重要决定因素吗请解释;使用适当的统计检验来回答; (4)Sally是29岁女性大学毕业生,Betsy是34岁女性大学毕业生,预测她们的收入;(5)用列3的回归结果回答:地区间平均收入存在显着差距吗利用适当的假设检验解释你的答案;(6)为什么在回归中省略了回归变量West如果加上会怎样;解释3个地区回归变量的系数的经济含义;7Juantia是南部28岁女性大学毕业生,Jennifer是中西部28岁女性大学毕业生,计算她们收入的期望差距计量经济学补充复习题一、填空题1、 计量经济学常用的三类样本数据是_横截面数据__、__时间序列数据__和_面板数据;2、虚拟解释变量不同的引入方式产生不同的作用;若要描述各种类型的模型在截距水平的差异,则以 加法形式 引入虚拟解释变量;若要反映各种类型的模型的不同相对变化率时,则以 乘法形式 引入虚拟解释变量;二、选择题1、参数的估计量βˆ具备有效性是指 BA Var βˆ=0B Var βˆ为最小C βˆ-=0D βˆ-为最小2、产量x,台与单位产品成本y, 元/台之间的回归方程为yˆ=356-,这说明 DA 产量每增加一台,单位产品成本增加356元B 产量每增加一台,单位产品成本减少元C 产量每增加一台,单位产品成本平均增加356元D 产量每增加一台,单位产品成本平均减少元3、在总体回归直线E x y10)ˆ(ββ+=中,1β表示 B A 当x 增加一个单位时,y 增加1β个单位B 当x 增加一个单位时,y 平均增加1β个单位C 当y 增加一个单位时,x 增加1β个单位D 当y 增加一个单位时,x 平均增加1β个单位4、以y 表示实际观测值,yˆ表示回归估计值,则普通最小二乘法估计参数的准则是使 DA )ˆ(i i yy -∑=0 B 2)ˆ(i i y y -∑=0 C )ˆ(i i yy -∑为最小 D 2)ˆ(i i y y -∑为最小 5、设y 表示实际观测值,yˆ表示OLS 回归估计值,则下列哪项成立 D A yˆ=y B y ˆ=y C yˆ=y D y ˆ=y 6、用普通最小二乘法估计经典线性模型t t t u x y ++=10ββ,则样本回归线通过点 DA x,yB x,yˆ C x ,yˆ D x ,y 7、判定系数2R 的取值范围是 CA 2R -1B 2R 1C 02R 1D -12R 18、对于总体平方和TSS 、回归平方和RSS 和残差平方和ESS 的相互关系,正确的是 BA TSS>RSS+ESSB TSS=RSS+ESSC TSS<RSS+ESSD TSS 2=RSS 2+ESS 29、决定系数2R 是指 CA 剩余平方和占总离差平方和的比重B 总离差平方和占回归平方和的比重C 回归平方和占总离差平方和的比重D 回归平方和占剩余平方和的比重10、如果两个经济变量x 与y 间的关系近似地表现为当x 发生一个绝对量变动x 时,y 有一个固定地相对量y/y 变动,则适宜配合地回归模型是 BA i i i u x y ++=10ββB ln i i i u x y ++=10ββC i ii u x y ++=110ββ D ln i i i u x y ++=ln 10ββ 11、下列哪个模型为常数弹性模型 AA ln i i i u x y ++=ln ln 10ββB ln i i i u x y ++=10ln ββC i i i u x y ++=ln 10ββD i ii u x y ++=110ββ 12、模型i i i u x y ++=ln 10ββ中,y 关于x 的弹性为 C A i x 1β B i x 1β C iy 1β D i y 1β 13、模型ln i i i u x y ++=ln ln 10ββ中,1β的实际含义是 BA x 关于y 的弹性B y 关于x 的弹性C x 关于y 的边际倾向D y 关于x 的边际倾向14、当存在异方差现象时,估计模型参数的适当方法是 AA 加权最小二乘法B 工具变量法C 广义差分法D 使用非样本先验信息15、加权最小二乘法克服异方差的主要原理是通过赋予不同观测点以不同的权数,从而提高估计精度,即 BA 重视大误差的作用,轻视小误差的作用B 重视小误差的作用,轻视大误差的作用C 重视小误差和大误差的作用D 轻视小误差和大误差的作用16、容易产生异方差的数据是 CA 时间序列数据B 修匀数据C 横截面数据D 年度数据17、设回归模型为i i i u x y +=β,其中var i u =22i x σ,则的最小二乘估计量为 CA. 无偏且有效 B 无偏但非有效C 有偏但有效D 有偏且非有效18、如果模型t t t u x b b y ++=10存在序列相关,则 DA cov t x ,t u =0B cov t u ,s u =0tsC cov t x ,t u 0D cov t u ,s u 0ts19、下列哪种形式的序列相关可用DW 统计量来检验i v 为具有零均值,常数方差,且不存在序列相关的随机变量 AA t t t v u u +=-1ρB t t t t v u u u +++=-- 221ρρC t t v u ρ=D ++=-12t t t v v u ρρ20、DW 的取值范围是DA -1DW0B -1DW1C -2DW2D 0 DW421、当DW =4是时,说明 DA 不存在序列相关B 不能判断是否存在一阶自相关C 存在完全的正的一阶自相关D 存在完全的负的一阶自相关22、模型中引入一个无关的解释变量 CA 对模型参数估计量的性质不产生任何影响B 导致普通最小二乘估计量有偏C 导致普通最小二乘估计量精度下降D 导致普通最小二乘估计量有偏,同时精度下降23、如果方差膨胀因子VIF =10,则认为什么问题是严重的 CA 异方差问题B 序列相关问题C 多重共线性问题D 解释变量与随机项的相关性24、某商品需求函数为i i i u x b b y ++=10,其中y 为需求量,x 为价格;为了考虑“地区”农村、城市和“季节”春、夏、秋、冬两个因素的影响,拟引入虚拟变量,则应引入虚拟变量的个数为 BA 2B 4C 5D 625、根据样本资料建立某消费函数如下:tC ˆ=+tD +t x ,其中C 为消费,x 为收入,虚拟变量D =农村家庭城镇家庭⎩⎨⎧01,所有参数均检验显着,则城镇家庭的消费函数为AA t C ˆ=+t xB tC ˆ=+t xC t C ˆ=+t xD tC ˆ=+t x 26、假设某需求函数为i i i u x b b y ++=10,为了考虑“季节”因素春、夏、秋、冬四个不同的状态,引入4个虚拟变量形式形成截距变动模型,则模型的 DA 参数估计量将达到最大精度B 参数估计量是有偏估计量C 参数估计量是非一致估计量D 参数将无法估计27、对于模型i i i u x b b y ++=10,为了考虑“地区”因素北方、南方,引入2个虚拟变量形式形成截距变动模型,则会产生 DA 序列的完全相关B 序列不完全相关C 完全多重共线性D 不完全多重共线性28、如果一个回归模型中不包含截距项,对一个具有m 个特征的质的因素要引入虚拟变量的数目为 AA mB m-1C m-2D m+129、某一时间序列经一次差分变换成平稳时间序列,此时间序列称为A;A .1阶单整B .2阶单整C .K 阶单整D .以上答案均不正确30、当随机误差项存在自相关时,进行单位根检验是由B 来实现;A . DF 检验B .ADF 检验C .EG 检验D .DW 检验三、多项选择题:1、一元线性回归模型t t t u x y ++=10ββ的经典假设包括 ABCDEA 0)(=t u EB 2)(σ=t u Var 常数C 0),cov(=j i u uD t u ~N0,1E x 为非随机变量,且0),cov(=t t u x2、以带“”表示估计值,u 表示随机误差项,如果y 与x 为线性相关关系,则下列哪些是正确的 BEA t t x y 10ββ+=B t t t u x y ++=10ββC t t t u x y ++=10ˆˆββD tt t u x y ++=10ˆˆˆββ E tt x y 10ˆˆˆββ+= 3、用普通最小二乘法估计模型t t t u x y ++=10ββ的参数,要使参数估计量具备最佳线性无偏估计性质,则要求: ABCDEA 0)(=t u EB 2)(σ=t u Var 常数C 0),cov(=j i u uD t u 服从正态分布E x 为非随机变量,且0),cov(=t t u x4、假设线性回归模型满足全部基本假设,则其参数估计量具备 CDEA 可靠性B 合理性C 线性D 无偏性E 有效性5、下列哪些非线性模型可以通过变量替换转化为线性模型 ABC A i i i u x y ++=210ββ B i ii u x y ++=110ββ C ln i i i u x y ++=ln 10ββ D i i i u x y ++=210ββE i i i i u x y ++=ββ06、异方差性将导致 BCDEA 普通最小二乘估计量有偏和非一致B 普通最小二乘估计量非有效C 普通最小二乘估计量的方差的估计量有偏D 建立在普通最小二乘估计基础上的假设检验失效E 建立在普通最小二乘估计基础上的预测区间变宽7、当模型中解释变量间存在高度的多重共线性时 ACDA 各个解释变量对被解释变量的影响将难于精确鉴别B 部分解释变量与随机误差项之间将高度相关C 估计量的精度将大幅下降D 估计量对于样本容量的变动将十分敏感E 模型的随机误差项也将序列相关8、下述统计量可以用来检验多重共线性的严重性 ACDA 相关系数B DW 值C 方差膨胀因子D 特征值E 自相关系数三、判断题1、随机误差项u i 与残差项e i 是一回事; F2、当异方差出现时,常用的t 检验和F 检验失效; T3、在异方差情况下,通常预测失效; T四、计算分析题1、指出下列模型中的错误,并说明理由;1 tt Y C 2.1180ˆ+= 其中,C 、Y 分别为城镇居民的消费支出和可支配收入;2 tt t L K Y ln 28.0ln 62.115.1ˆln -+= 其中,Y 、K 、L 分别为工业总产值、工业生产资金和职工人数;2、对下列模型进行适当变换化为标准线性模型:(1) y =0β+1βx 1+2β21x +u ; (2) Q =A u e L K βα;(3) Y =exp 0β+1βx+u ;3、一个由容量为209的样本估计的解释CEO 薪水的方程为:其中,Y 表示年薪水平单位:万元, 1X 表示年收入单位:万元, 2X 表示公司股票收益单位:万元; 321D D D ,,均为虚拟变量,分别表示金融业、消费品工业和公用事业;假设对比产业为交通运输业;(1) 解释三个虚拟变量参数的经济含义;(2) 保持1X 和2X 不变,计算公用事业和交通运输业之间估计薪水的近似百分比差异;这个差异在1%的显着性水平上是统计显着吗消费品工业和金融业之间估计薪水的近似百分比差异是多少。
第一章计量经济学

获奖者名单 2003 Robert F. Engle, Clive W. J. Granger 2002 Daniel Kahneman, Vernon L. Smith 2001 George A. Akerlof, A. Michael Spence, Joseph E. Stiglitz 2000 James J Heckman, Daniel L McFadden 1999 Robert A. Mundell 1998 Amartya Sen 1997 Robert C. Merton, Myron S. Scholes 1996 James A. Mirrlees, William Vickrey 1995 Robert E. Lucas Jr.
计量经济学 Econometrics
石红溶 西北政法大学经管学院
1
教材和参考书
《计量经济学》庞浩,科学出版社 计量经济学》庞浩, 计量经济学导论:现代观点》 《计量经济学导论:现代观点》伍德里奇 费剑平等译, 著,费剑平等译,中国人民大学出版社 计量经济学》古扎拉蒂著,林少宫译, 《计量经济学》古扎拉蒂著,林少宫译, 中国人民大学出版社 应用计量经济学》 施图德蒙德, 《应用计量经济学》(美)施图德蒙德, 王少平译, 王少平译,机械工业出版社 计量经济模型与经济预测》 《计量经济模型与经济预测》(美)平狄 克,钱小军译 ,机械工业出版社
(1)理论或假说的陈述
凯恩斯消费理论: 基本的心理定律是,一般而言,人们倾向于 随着他们收入的增加而增加其消费,但比不 上收入增加的那么多。 简言之,凯恩斯设想,边际消费倾向 (MPC),即收入每变化一个单位的消费变 化率,大于零而小于1。 0 < MPC < 1
25
3、计量经济学【一元线性回归模型——参数估计】

ˆ Y i
(8) 651.8181 753.6363 855.4545 957.2727 1059.091 1160.909 1262.727 1364.546 1466.364 1568.182 11100
ˆ ei Yi Y i
(9)=(2)-(8) 48.18190 -103.6363 44.54550 -7.272700 40.90910 -10.90910 -62.72730 35.45450 83.63630 -68.18190
假设 5:随机误差项服从 0 均值,同方差的正态 分布,即
2 i ~ N (0, ), ,,,,,,,,, ,, i 1,2, n
以上这些假设称为线性回归模型的经典假
设,满足这些假设的线性回归模型,也称为 经典线性回归模型(classical linear regression model)。在回归分析的参数估计和统计检验 理论中,许多结论都是以这些假定作为基础 的。如果违背其中的某一项假定,模型的参 数估计就会存在问题,也就是说最小二乘法 (OLS)就不再适用,需对模型进行修正或 采用其他的方法来估计模型了。
二、参数的普通最小二乘估计(OLS) 三、最小二乘估计量的性质 四、参数估计量的概率分布及随机误差项
方差的估计
给出一元线性回归模型的一般形式:
Yi 0 1 X i i ,,,, , i 1, 2, ,n
其中 Yi :被解释变量,X i :解释变量,0 和 1 :待估参 数; i :随机误差项;
ei2
(10) 2321.495 10740.48 1984.302 52.89217 1673.554 119.0085 3934.714 1257.022 6995.031 4648.771 33727.27
伍德里奇计量经济学导论ppt课件
E(Y|Xi) = 0 + 1 Xi,
ppt课件.
21
Ø 随机误差项u的意义:
l 反映被忽略掉的因素对被解释变量的影响。 或者理论不够完善,或者数据缺失;或者影响轻微。
l 模型设定误差 l 度量误差 l 人类行为内在的随机性
ppt课件.
22
Ø 随机误差项主要包括下列因素:
在解释变量中被忽略的因素的影响; 变量观测值的观测误差的影响; 残缺数据; 模型关系的设定误差的影响; 其他随机因素的影响。
l 对于某一个家庭,如何描述可支配收入和消费支出的关系?
Yi=E(Y|Xi) + ui =0 + 1 Xi + ui
某个家庭的消费支出分为两部分:一是E(Y|Xi)=0 + 1 Xi ,称为系统成
分或确定性成分;二是ui,称为非系统或随机性成分。
ppt课件.
20
l 随机性总体回归函数
Yi=0 + 1 Xi + ui
260
— 152
— — 180 185 — 3 517
ppt课件.
26
样本回归线
样本均值连线
ppt课件.
27
Ø 总体回归模型和样本回归模型的比较
ppt课件.
28
注意:分清几个关系式和表示符号
E(Y|Xi) = 0 + 1 Xi (1)总体(真实的)回归直线: Yi
E(Y|Xi)01Xi
Y2
Y1
或: Yi ˆ0ˆ1Xi ei
其中: Yˆi 为Yi的估计值(拟合值); ˆ0 , ˆ1 为 0 , 1 的估计值;
110 115 120 130 135 140
- 6 750
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
yi = b0 + b1xi + ui
10
Population regression line, sample data points
and the associated error terms
y = b0 + b1x + u
In the simple linear regression of y on x, we typically refer to x as the
Independent Variable, or Right-Hand Side Variable, or Explanatory Variable, or Regressor, or Covariate, or Control Variables
of the OLS estimators
2
What is the simple regression model?
y = b0 + b1 x + u
3
Some Terminology
In the simple linear regression model,
where y = b0 + b1x + u, we typically
第一章 简单回归模型
y = b0Hale Waihona Puke + b1x + u
要求: 1、普通最小二乘估计方法(OLS) 2、OLS的统计特性
1
Contents
What is the simple regression model? How to derive the ordinary least
squares (OLS) estimates? Properties of OLS statistics and R2 Unbiasedness of OLS and Variances
We want it to be the case that knowing something about x does not give us any information about u, so that they are completely unrelated. That is, that
5
A Simple Assumption
y = b0 + b1x + u
The average value of u, the error term, in the population is 0. That is,
E(u) = 0
This is not a restrictive assumption,
Cov(x,u) = E(xu) = 0
Why? Remember from basic probability that Cov(X,Y) = E(XY) – E(X)E(Y)
12
Deriving OLS continued
We can write our 2 restrictions just in
9
Ordinary Least Squares
Basic idea of regression is to estimate the population parameters from a sample
Let {(xi,yi): i=1, …,n} denote a random sample of size n from the population
terms of x, y, b0 and b1 , since y = b0 + b1x + u,
u = y – b0 – b1x
E(y – b0 – b1x) = 0 E[x(y – b0 – b1x)] = 0
These are called moment restrictions
y y4
E(y|x. ) = b0 + b1x
u4 {
y3 y2
u2{.
.} u3
y1
.} u1
x1
x2
x3
x4
x
11
Deriving OLS Estimates
To derive the OLS estimates we need to realize that our main assumption of E(u|x) = E(u) = 0 also implies that
since we can always use b0 to
normalize E(u) to 0
wage = b0 + b1educ + u
6
Zero Conditional Mean
y = b0 + b1x + u
We need to make a crucial assumption about how u and x are related
refer to y as the
Dependent Variable, or Left-Hand Side Variable, or Explained Variable, or Response Variable, or Regressand
4
Some Terminology, cont.
y
f(y)
.
.
E(y|x) = b0 + b1x
Population
Regression
Function
x1
x2
How to estimate the
parameters b0 and b1?
8
How to derive the ordinary least squares (OLS) estimates?
E(u|x) = E(u) = 0, which implies
E(y|x) = b0 + b1x, which is often called
Population Regression Function (PRF)
7
E(y|x) as a linear function of x, where for any x the distribution of y is centered about E(y|x)