Bootstrap及jackknife刀切法中文讲解
Stata入门手册 STATA操作方法概述

统计分析与计量分析的结合
单元统计:描述统计、假设检验(参数、非参数)、ANOVA、质量控制、统计 作图
多元统计:MANOVA、主成分、因子分析、典型相关、聚类、判别分析、对应 分析、多维标度 线性回归、非线性回归、工具变量回归、广义线性回归、分位数回归(稳健回 归)、系统方程模型(SUR、联立方程)、离散选择模型(二项选择、排序选择、 多项选择、条件Logit、嵌套Logit模型、二元选择模型等)、计数模型(泊松回归、 负二项回归)、截断与归并模型、海克曼选择模型、逐步回归(stepwise)等。 时间序列分析:时间序列的平滑、相关图、ARIMAX、GARCH、单位根检验、 Johansen协整检验、 VAR、VEC、滚动回归等。 面板数据(线性模型、工具变量回归、动态面板、分层混合效应、广义估计方 程(GEE)、随机边界模型等)。
语法结构(varlist)
已存在的变量
varlist表示若干变量。对于数据中存在的变量,允许的表达形式包括 *、?和。其中,*表示任意字符,?表示一个字符,表示两个变量 之间的所有变量(根据数据中变量的存放位置)。 比如,数据文件中共有20个变量,依次为var1、var2、… 、 var20,则var* 表示所有变量var1-var20,var?表示变量var1、 var2、… 、var9,var1-var6表示变量var1、var2、… 、var6。 新变量
生成新变量时,变量名称不能简化。如果变量具有相同的前缀并且 都以数字结尾,可以用-表示。比如,生成新变量V1、V2、V3、V4 input v1 v2 v3 v4 或者 . input v1-v4。
16
《STATA应用高级培训教程》 南开大学数量经济研究所 王群勇
语法结构(varlist)
系统发育分析
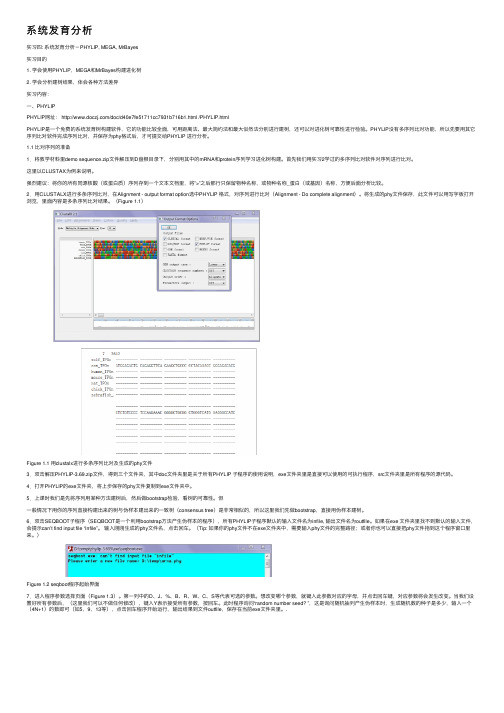
系统发育分析实习四: 系统发育分析-PHYLIP, MEGA, MrBayes实习⽬的1. 学会使⽤PHYLIP,MEGA和MrBayes构建进化树2. 学会分析建树结果,体会各种⽅法差异实习内容:⼀、PHYLIPPHYLIP⽹址: /doc/d40e7fe51711cc7931b716b1.html /PHYLIP.htmlPHYLIP是⼀个免费的系统发育树构建软件,它的功能⽐较全⾯,可⽤距离法、最⼤简约法和最⼤似然法分别进⾏建树,还可以对进化树可靠性进⾏检验。
PHYLIP没有多序列⽐对功能,所以先要⽤其它序列⽐对软件完成序列⽐对,并保存为phy格式后,才可提交给PHYLIP 进⾏分析。
1.1 ⽐对序列的准备1.将教学材料⾥demo sequence.zip⽂件解压到D盘根⽬录下,分别⽤其中的mRNA和protein序列学习进化树构建。
⾸先我们⽤实习2学过的多序列⽐对软件对序列进⾏⽐对。
这⾥以CLUSTAX为例来说明。
强烈建议:将你的所有同源核酸(或蛋⽩质)序列存到⼀个⽂本⽂档⾥,将”>”之后那⾏只保留物种名称,或物种名称_蛋⽩(或基因)名称,⽅便后⾯分析⽐较。
2.⽤CLUSTALX进⾏多条序列⽐对,在Alignment - output format option选中PHYLIP 格式,对序列进⾏⽐对(Alignment - Do complete alignment)。
将⽣成的phy⽂件保存,此⽂件可以⽤写字板打开浏览,⾥⾯内容是多条序列⽐对结果。
(Figure 1.1)Figure 1.1 ⽤clustalx进⾏多条序列⽐对及⽣成的phy⽂件3.双击解压PHYLIP-3.69.zip⽂件,得到三个⽂件夹,其中doc⽂件夹⾥是关于所有PHYLIP ⼦程序的使⽤说明,exe⽂件夹⾥是直接可以使⽤的可执⾏程序,src⽂件夹⾥是所有程序的源代码。
4.打开PHYLIP的exe⽂件夹,将上步保存的phy⽂件复制到exe⽂件夹中。
【机器学习】Jackknife,Bootstraping,bagging,boosting。。。

【机器学习】Jackknife,Bootstraping,bagging,boosting。
Jackknife,Bootstraping, bagging, boosting, AdaBoosting, Rand forest 和 gradient boosting这些术语,我经常搞混淆,现在把它们放在⼀起,以⽰区别。
(部分⽂字来⾃⽹络,由于是之前记的笔记,忘记来源了,特此向作者抱歉)Bootstraping: 名字来⾃成语“pull up by your own bootstraps”,意思是依靠你⾃⼰的资源,称为⾃助法,它是⼀种有放回的抽样⽅法,它是⾮参数统计中⼀种重要的估计统计量⽅差进⽽进⾏区间估计的统计⽅法。
其核⼼思想和基本步骤如下: (1)采⽤重抽样技术从原始样本中抽取⼀定数量(⾃⼰给定)的样本,此过程允许重复抽样。
(2)根据抽出的样本计算给定的统计量T。
(3)重复上述N次(⼀般⼤于1000),得到N个统计量T。
(4)计算上述N个统计量T的样本⽅差,得到统计量的⽅差。
应该说Bootstrap是现代统计学较为流⾏的⼀种统计⽅法,在⼩样本时效果很好。
通过⽅差的估计可以构造置信区间等,其运⽤范围得到进⼀步延伸。
Jackknife:和上⾯要介绍的Bootstrap功能类似,只是有⼀点细节不⼀样,即每次从样本中抽样时候只是去除⼏个样本(⽽不是抽样),就像⼩⼑⼀样割去⼀部分。
(pku, sewm,shinningmonster.)============================================================================================================================下列⽅法都是上述Bootstraping思想的⼀种应⽤。
bagging:bootstrap aggregating的缩写。
Bootstrap和Jackknife的初步认识

Bootstrap和Jackknife的初步认识作者:乔汭熙来源:《东方教育》2017年第11期摘要:本文总结了Bootstrap和Jackknife的相关理论知识与已有研究;利用R语言进行模拟,设计复杂抽样方案并进行抽样,对Bootstrap和Jackknife的部分性质进行了验证与解释。
除此之外,本文还对Bootstrap和Jackknife估计量的性质进行了简要的介绍,并对方法的改进进行了讨论。
关键词:复杂抽样;Bootstrap;Jackknife;估计一、发展历史与研究现状Jackknife是由Quenouille(1949)引入的一种方法,又称刀切法。
Jackknife方法的思想是,通过从原始数据集中每次删除一个数据并利用其余数据重新计算估计量,根据得到的一组估计值,可以对待估参数及其他性质进行估计。
Quenouille在1949年提出,可以通过将样本划分为两个半样本的方式,以减少序列相关的估计量的偏差。
在其1956年的研究中,提出将样本量为n的样本划分为g组大小为h的样本的方法,并讨论了这种方法的可行性[1][2]。
Jackknife方法在对残差的估计(P.S.R.S Rao and J.N.K.Rao,1970)、区间估计(Tukey)、极大似然估计(Fryer,1970)等方面优良性质均已被证明[1]。
对于多元的Jackknife,Dempster在其1966的研究中,提出了一种改进的Jackknife方法,用于处理典型相关问题。
Layard(1972)指出,当传统正态方法对两个协方差矩阵相等性的检验不稳健时,Jackknife方法可以很好的处理。
Lachenbruch和Mickey[1]提出了U方法(实际是Jackknife方法的应用)进行判别分析。
L.B.Jaeckel提出一种无穷细分的刀切法,虽然此方法不如原始Jackknife方法实用,但却在Jackknife和稳健估计量之间建立了桥梁(1972)。
Bootstrap方法及其在生物学研究中的应用

收稿日期:2009-10-12接受日期:2009-12-06基金项目:安徽省教育厅重点项目(KJ2009A052Z );宿州学院人才基金(2007YSS10)作者简介:赵亮,男,博士,副教授,研究方向:保护遗传学,E-mail :zhaoliang@ioz.ac.cn *通讯作者Corresponding author ,E-mail :lim@ioz.ac.cn Bootstrap 方法及其在生物学研究中的应用赵亮1,3,程锦秀2,许木启3,李明3*(1.安徽宿州学院化学与生命科学系,安徽宿州234000;2.安徽宿州学院继续教育学院,安徽宿州234000;3.中国科学院动物研究所,动物生态与保护遗传学重点实验室,北京100101)摘要:Bootstrap 方法是以原始数据为基础的模拟抽样统计推断法,特别适用于那些难以用常规方法导出的参数的区间估计、假设检验等问题。
本文介绍了该方法的基本思想及具体步骤,并附有生物学研究中应用的实例。
生物科学中有许多数据总体分布信息往往很难确定,难以用常规的方法进行统计分析,因此Bootstrap 方法在生物科学研究中具有很大的应用价值。
关键词:Bootstrap 方法;区间估计;假设检验中图分类号:O212文献标识码:B文章编号:1000-7083(2010)04-0638-04Bootstrap Method and its Application in BiologyZHAO Liang 1,3,CHENG Jin-xiu 2,XU Mu-qi 3,LI Ming 3*(1.Department of Biology ,Suzhou College ,Suzhou ,Anhui Province 234000,China ;2.Department of Continuing Education ,Suzhou College ,Suzhou ,Anhui Province 234000,China ;3.Key Laboratory of Animal Ecology andConservation Biology ,Institute of Zoology ,Chinese Academy of Sciences ,Beijing 100101,China )Abstract :The bootstrap method is a data-based simulation to carry out familiar statistical calculations ,such as confidence intervals estimated ,statistic inference ,et al .By purely computation means rather than using of statistical formulas ,it is useful especially when the statistical formulas are hard to be got.This article introduced the bootstrap method ,including bootstrap basic ideas and procedures and illustrated its application in biology with some examples.Along with the quick de-velopment of computer techniques ,this method is now surging into widely practical use in biological studies.Key words :bootstrap ;confidence intervals estimated ;statistic inference统计推断是从样本资料推断相应的总体特征,包括参数估计和假设检验。
基于Bootstrap方法的统计数据质量评价研究

146金融经济FINANCIAL AND ECONOMIC课题名称:山西省社会经济统计科学研究立项课题 编号 KY 〔2020〕121基于Bootstrap 方法的统计数据质量评价研究张会清 晋中信息学院摘要:统计的作用在于服务国家宏观决策和人民生产生活,它在反映国民经济和社会发展水平、为党和国家制定正确的决策、预测未来发展趋势等方面发挥着举足轻重的作用。
统计数据要实现以上功能,必须保证统计数据高质量。
数据作为生产要素,在数据要素市场化过程中,如果不能保证其质量,数据价值不但得不到体现,反而会给使用者带来不良的后果。
本文首先介绍了数据质量的概念和Bootstrap 方法的基本原理,然后基于Bootstrap 抽样并应用统计分布验证方法对统计数据质量进行评估,最后对山西统计局公布的地区国内生产总值数据质量进行验证评估。
关键词:数据质量;Bootstrap 方法;统计分布引言毋庸置疑,大数据时代下,数据充分发挥其价值的必备条件是要有高质量数据。
2021年1月19日统计局局长宁吉喆在题为“推进统计现代改革”中指出:“统计数据作为国家经济发展的晴雨表已经取得了显著的成绩,但它发挥的作用还不够充分,还有待开发,数据质量需要进一步提升”。
统计数据质量的内涵也不再仅仅是准确,大数据背景下,适合的才是最好的,用户需求也是衡量数据质量的一个方面。
近年来,科技发展迅猛,新型技术的发展突飞猛进,物联网、人工智能、云计算的发展让人应接不暇,海量的数据纷繁复杂,如何保证数据的质量,已成为上到国家,下到每一位统计相关者关注的问题,也是我们亟待解决的问题。
在此背景下,数据质量评估无疑是保证高质量数据的前提条件。
在数据评估研究方面,祝君仪(2015)6在《大数据时代背景下统计数据质量的评估方法及适用性分析》一文中分析了目前常用的包括逻辑规则检验、核算数据重估、计量模型分析、统计分布验证、调查偏差评估、多维评估延伸六种评估数据质量的方法,但仅仅是定性分析。
水文随机模拟进展_王文圣(1)
水文随机模拟进展王文圣1,2,金菊良3,李跃清1(11中国气象局成都高原气象研究所,四川成都 610072;21四川大学水利水电工程学院,四川成都 610065;31合肥工业大学土建学院,安徽合肥 230009)摘要:综述了近20年来水文随机模拟的新进展,包括三方面:¹随机水文模型改进和创新;º水文随机模拟应用研究新进展;»水文随机模拟认识新进展。
并指出了今后的研究重点:¹对水文过程的重要物理特性和统计特性作深入的分析;º加强非参数模型和非线性模型的研究;»加强流域系统随机模型的研究;¼加强建立模型时如何综合利用多种信息的研究;½加强模型的各种检验和合理分析。
关 键 词:随机模拟;随机模型;非参数模型;进展中图分类号:P33316;G353111 文献标识码:A 文章编号:100126791(2007)0520768208收稿日期:2005212225;修订日期:2006203215基金项目:国家自然科学基金资助项目(50779042,70771035,50739002)作者简介:王文圣(1970-),男,四川宣汉人,副教授,博士,主要从事水文水资源水环境系统分析。
E 2mail:wang w s70@sina 1co m1 水文随机模拟水文系统受气候和人类活动影响,呈现出非常复杂的行为特征。
在现有社会、经济和技术条件下,对水文系统进行真实的物理实验以揭示其结构和功能,显然是十分困难的。
由于系统的复杂性,目前还不能用准确的数理方程描述并求解。
要了解水文系统各组成间的相互关系,预测水资源开发方案可能产生的效果及对生态的影响,分析系统的发展趋势,当前可行的一类方法就是水文随机模拟。
所谓水文随机模拟[1],指根据水文系统观测资料的统计特性和随机变化规律,建立能预估系统未来水文情势的随机模型,由模型通过统计试验获得大量的模拟序列,再进行水文系统分析计算,解决系统的规划、设计、运行与管理问题的方法。
新指南CLSIEP9–A3在方法学比对及偏移评估中的应用(最全版)
新指南CLSIEP9–A3在方法学比对及偏移评估中的应用(最全版)新指南CLSI EP9–A3在方法学比对及偏移评估中的应用(最全版)XXX(CLSI)一直致力于制定系列评价临床检验方法的文件,其在制定相关标准和指南时采用特有的协商一致过程,包括方案的建立、认可和公开,对有关文件进行广泛、细致、全面的评论,根据使用者的意见进行文件修订,以保证其适应性等[1]。
CLSI在1986年1月首先推出EP9–P(proposed guideline)版本,1993年4月推出EP9–T(tentative guideline)版本,再经过修订,1995年12月推出批准指南EP9–A(approved guideline)版本[2]。
随后,又经过3次修订,即2002年9月的EP9–A2[3]、2010年7月的EP9–A2–IR(n)和2013年8月的最新版本EP9–A3文件[4],即《用患者样本进行方法比对及偏移评估:批准指南––第三版》,EP9–A3为生产厂家和临床实验室提供了最新的方法学比对和偏移评估指南。
笔者将简要介绍其基本结构、主要用途、比对要求、实验方案、统计方法等内容,供同行参考。
一、EP9–A3概述EP9–A3主要有3个方面用途:(1)临床实验室新引进测量方法与参比方法比对;(2)厂家新建立的测量方法与参比方法相关性研究;(3)厂家对新建立的测量方法比对声明标准确认;3种用途的具体要求见表1.EP9–A3也可进行方法内比对,对于已建立或确认的方法,厂家或实验室可利用40个系列浓度标本对该方法不同条件进行比对分析,如同一方法不同样本类型、不同批号试剂等。
表1EP9–A3对厂家和实验室比对研究具体要求三、比对要求1.标本要求:比对时应使用未经过处理的患者标本,分析物浓度应尽可能在测量范围内均匀分布,各标本基本信息如临床诊断或状态(是否溶血、黄疸、脂血、浑浊)均应记录。
如需使用处理过的标本(如添加纯的高浓度物质),应<比对标本总数的20%。
调查研究中复杂抽样的SUDAAN统计分析软件介绍
方检验;比率过程步(Ratio procedure)可以对一般性的
比率的标准误进行估计和计算;回归过程步(Regres—
sion
Data:Misuse of Standard Pack・ Enc”10pedia of Biostatistics,edited by Peter心rnitage aIId TheDdore C0lton.New York:John wiley嬲d Sons,1998(5):4167-
weighted data)和无归还样本(without—replacement
samples)等聚集性数据进行分析,此外也用来分析随 机试验、观察性或实验流行病学研究数据。在统计分 析中,SUDA AN软件允许规定数据的相关方式和给定 权重值。当调查的抽样权重发生变化时,通常会改变
下运行的版本。下面对SUD从N统计软件进行简要
的介绍。 理论依据 在大规模流行病学抽样调查时,通常采用分层 (stratification)、重复(replication)与整群(clustering)等 复杂抽样方法获得数据。这些抽样方法对统计分析结 果有影响。例如,如果研究变量为分类变量,可将总体 分成不同的类别,然后在各类内进行随机抽样,由于分 层抽样所得到的层间抽样误差明显小于简单随机抽 样,所以分层抽样将获得更为精确的总体参数估计值。 通常情况下,总体参数估计的精确性依赖于权重的大 小,如果对分层或整群效应不进行校正,方差、标准误 和可信区间的估计均会出现错误。如果采用不加权简 单随机抽样计算变异度指标的方法来计算分层抽样的 变异度,将扩大分层抽样的变异度大小。为了合理估 计分层抽样的变异度,有必要对此校正。 一般的统计分析程序包在分析过程中均假定抽样 方法为简单随机抽样,换言之,他们没有自行对复杂抽 样设计的方法进行校正。在许多复杂抽样设计中,对 于选择的不均衡性、无应答偏倚和采用分层、重复与整 群等方法的抽样,必须通过加权的方式进行统计学校 正,因为这些效应导致了精确度的丢失和样本含量效 应的下降。另外,当开展普查时,对计数资料和调查中 的访问性应答(interview response)资料也要单独进行 加权调整。如果研究者忽视了加权的问题,显著性检 验将会得到一个假阳性结果,从而导致统计推断的偏 倚。因此应该对流行病学调查中复杂抽样的数据进行 校正以期得到更为准确的统计学结论。
STATA高级视频教程简介(连玉君)
STATA高级视频教程简介培训目的:STATA高级视频教程的目的是使学员熟练使用STATA进行实证分析工作,主要包括:(1) 掌握多种常用的估计方法(如普通最小二乘法、广义最小二乘法、非线性最小二乘法、最大似然估计、IV估计和GMM);(2) 学会估计和分析时间序列和面板数据常用模型(如单位根检验、协整分析、VAR、固定效应模型、随机效应模型、动态面板模型、面板单位根检验和面板协整分析等等);(3) 学会编写一个完整的STATA程序;(4) 学会应用STATA进行抽样和模拟分析,包括Bootstrap和Monte Carlo 模拟分析。
课程简介:(详见课程目录)STATA高级视频教程共9讲,共48个视频文件,总计50余个学时。
第1-5讲介绍计量经济学中最为常用的五种估计方法,包括:普通最小二乘法(OLS)、广义最小二乘法(GLS)、非线性最小二乘法(NLS)、最大似然法(MLE)和广义矩估计法(GMM)。
第6讲介绍时间序列模型,包括:ARIMA模型、VAR模型、单位根检验、协整分析、误差修正模型、GARCH模型。
这些模型基本上涵盖了宏观时间序列、金融时间序列分析中的常用工具。
第7讲介绍面板数据模型,包括:固定效应模型、随机效应模型、异方差和序列相关、动态面板模型、面板随机系数模型、面板随机前沿模型、面板单位根检验、面板协整分析等。
这些模型由浅入深,基本上涵盖了目前文献中使用的多数面板分析方法。
第8讲介绍STATA编程技巧,包括:输入项、输出项的设定,子程序、可分组执行、可重复执行等程序高级功能,以及帮助文件的编写方法。
通过本讲的学习,学员将能够独立编写复杂的STATA程序,这些程序和STATA官方提供的程序完全一致。
第9讲介绍自抽样和模拟分析,包括:Bootstrap(自抽样)、组合检验(Permutation tests)、刀切法(Jackknife)和蒙特卡洛模拟。
不同于传统的假设检验和统计推断方法,这些方法都是以计算机模拟和抽样为基础的,在最近十年中得到了越来越广泛的应用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
X 2 = ( X1, X 3 , X1, X 4 , X 5 )
6
… *
计算bootstrap样本
重复B次,
1. 随机选择整数 i1 ,..., in,每个整数的取值范围为[1, n], 选择每个[1, n]之间的整数的概率相等,均为1 n 2. 计算bootstrap样本为:X * = ( X i1 ,..., X in )
5
重采样
通过从原始数据 X = ( X 1,..., X n ) 进行n次有放回采 * * * 样n个数据,得到bootstrap样本 X b = ( X 1 ,..., X n )
对原始数据进行有放回的随机采样,抽取的样本数目 同原始样本数目一样
如:若原始样本为 X = ( X 1, X 2 , X 3 , X 4 , X 5 ) 则bootstrap样本可能为 * X1 = ( X 2 , X 3 , X 5 , X 4 , X 5 )
也就是说,如果我们从 Gn中抽取大量样本,我们 可以用样本均值 Tn来近似 E (Tn ) 当样本数目B足够大时,样本均值 T 与期望 E (T ) 之间 n n
的差别可以忽略不计
9
模拟
更一般地,对任意均值有限的函数h,当 B
P 1 B h (Tn,b )? å B b= 1
有
ò h (t )dG (t )
Bootstrap也可用于偏差、置信区间和分布估计等计算
1
本节课内容
重采样技术(resampling)
Bootstrap 刀切法(jackknife)
2
引言
Tn = g ( X1 ,..., X n )是一个统计量,或者是数据的某个函数, 数据来自某个未知的分布F,我们想知道 的某些性质 Tn (如偏差、方差和置信区间)
上节课内容总结
统计推断基本概念
统计模型:参数模型与非参数模型 统计推断/模型估计:点估计、区间估计、假设检验 估计的评价:无偏性、一致性、有效性、MSE
偏差、方差、区间估计
ቤተ መጻሕፍቲ ባይዱ
CDF估计:
点估计、偏差、方差及区间估计
统计函数估计
点估计 区间估计/标准误差
影响函数 Bootstrap
假设我们想知道 Tn的方差 VF (Tn ) 如果 VF (Tn ) 的形式比较简单,可以直接用上节课学习 VF 的嵌入式估计量 ˆ (Tn ) 作为 VF (Tn ) 的估计 n 例: Tn = n- 1 å X i,则
n
i= 1
VF (Tn ) = s 2 ˆ VF T = s ( ) ˆ n
计算机的引导程序boot也来源于此 意义:不靠外界力量,而靠自身提升自己的性能,翻译为自助/ 自举
1980年代很流行,因为计算机被引入统计实践中来
4
Bootstrap简介
Bootstrap:利用计算机手段进行重采样 一种基于数据的模拟(simulation)方法,用于统计推断。 基本思想是:利用样本数据计算统计量和估计样本分布, 而不对模型做任何假设(非参数bootstrap) 无需标准误差的理论计算,因此不关心估计的数学形式有 多复杂 Bootstrap有两种形式:非参数bootstrap和参数化的 bootstrap,但基本思想都是模拟
Tn = g ( X 1 ,..., X n )
* * *
1
n
ˆ 代替(嵌入式估计量) 怎样得到F?用 F n ˆ 中采样? 怎样从 F n ˆ 对每个数据点 X1 ,..., X n 的质量都为1/n 因为 F n ˆ 中抽取一个样本等价于从原始数据随机抽取一个样本 所以从 F n * * ˆ,可以通过有放回地随机 也就是说:为了模拟 X ,..., X ~ F n 1 n
n
E (h (Tn ))
则当 h (Tn,b ) = (Tn,b - Tn ) 时,有 2 P 2 1 B (Tn,b - Tn ) ? E (Tn Tn ) = V (Tn ) å B b= 1
2
(
)
用模拟样本的方差来近似方差 V (Tn )
10
模拟
怎样得到 Tn 的分布?
已知的只有X,但是我们可以讨论X的分布F 如果我们可以从分布F中得到样本 X * ,..., X *,我们可以计算
7
Bootstrap样本
在一次bootstrap采样中,某些原始样本可能没被 采到,另外一些样本可能被采样多次
在一个bootstrap样本集中不包含某个原始样本X i 的概率为 n 骣 1÷ - 1 ç P ( X j ? X i , j 1,...n) = ç1- ÷ 换e 0.368 ÷ ç 桫 n
Web上有matlab代码:
BOOTSTRAP MATLAB TOOLBOX, by Abdelhak M. Zoubir and D. Robert Iskander, .au/downloads/bootstrap_ toolbox.html Matlab函数:bootstrp
2
n
n,其中 s = n ( x - m) dF ( x), m = 2 2 n,其中 sˆ = å ( X i - X n ) n
2
蝌
i= 1
2
xdF ( x)
问题:若 VF (Tn ) 的形式很复杂(任意统计量),如何 3 计算/估计?
Bootstrap简介
Bootstrap是一个很通用的工具,用来估计标准误差、置 信区间和偏差。由Bradley Efron于1979年提出,用于计 算任意估计的标准误差 术语“Bootstrap”来自短语“to pull oneself up by one’s bootstraps” (源自西方神话故事“ The Adventures of Baron Munchausen”,男爵掉到了深湖底,没有工具, 所以他想到了拎着鞋带将自己提起来)
一个bootstrap样本集包含了大约原始样本集的1-0.368 = 0.632,另外0.368的样本没有包括
8
模拟
假设我们从 Tn 的分布Gn中抽取IID样本 Tn,1 ,..., Tn, B , 当 B 时,根据大数定律, P 1 B Tn = å Tn ,b ? ò tdGn (t ) E (Tn ) B b= 1