随机抽样的常用的四种方法分析一览表精编版
随机抽样的类型及实际应用案例

随机抽样的类型及实际应用案例摘要:随机抽样,即按照随机的原则,即保证总体中每个单位都有同等机会被抽中的原则抽取样本的方法。
本文主要针对常用的四种抽样法的使用优缺点及其实际应用进行介绍。
随机抽样法的类型其中常用的随机抽样方法主要有:简单随机抽样法、系统抽样法、分层抽样法及整群抽样法。
简单随机抽样法简单随机抽样法又叫单纯随机抽样法,是最基本的抽样方法,是指总体中的每个个体被抽到的机会是相同的。
∙优点:抽样误差小∙缺点:抽样手续比较繁杂系统抽样法系统抽样法又称等距抽样。
是纯随机抽样的变种。
在系统抽样中,先将总体从1~N相继编号,并计算抽样距离K=N/n。
式中N为总体单位总数,n为样本容量。
然后在1~K中抽一随机数k1,作为样本的第一个单位,接着取k1+K,k1+2K……,直至抽够n个单位为止。
∙优点:操作简便,实施不易出差错∙缺点:容易出现较大偏差∙适用场合:总体发生周期性变化的场合不宜使用这种方法分层抽样法分层抽样法又叫类型抽样法,它是从一个可以分成不同于总体的总体(或称为层)中,按规定的比例从不同层中随机抽取样品(个体)的方法。
∙优点:样本的代表性比较好,抽样误差比较小∙缺点:抽样手续较简单随机抽样还要繁杂∙适用场合:常用于产品质量验收整群抽样法整群抽样法又叫集团抽样法,是将总体分成许多群,每个群由个体按一定方式结合而成,然后随机抽取若干群并由这些群中的所有个体组成样本。
∙优点:抽样实施方便∙缺点:代表性差,抽样误差大∙适用场合:常用于工序控制中实际应用案例某种成品零件分装在20个零件箱装,每箱各装50个,总共是1000个,如果想谷取100个零件作为样本进行测试研究。
∙简单随机抽样:将20箱零件倒在一起,混合均匀,并将零件从1~1000编号,然后用查随机数表或抽签的办法从中抽出编号毫无规律的100个零件组成样本。
∙系统抽样:将20箱零件倒在一起,混合均匀,并将零件从1~1000编号,然后用查随机数表或抽签的办法先决定起始编号,按相同的尾数抽取100个零件组成样本。
卫生统计学四种随机抽样方法

卫生统计学:四种基本的抽样方法
1.单纯随机抽样:单纯随机抽样是在总体中以完全随机的方法抽取一部分观察单位组成样本(即每个观察单位有同等的概率被选入样本)。
常用的办法是先对总体中全部观察单位编号,然后用抽签、随机数字表或计算机产生随机数字等方法从中抽取一部分观察单位组成样本。
其优点是简单直观,均数(或率)及其标准误的计算简便;缺点是当总体较大时,难以对总体中的个体一一进行编号,且抽到的样本分散,不易组织调查。
2.系统抽样:系统抽样又称等距抽样或机械抽样,即先将总体中的全部个体按与研究现象无关的特征排序编号;然后根据样本含量大小,规定抽样间隔k;随机选定第i(i<k)号个体开始,每隔一个k,抽取一个个体,组成样本。
系统抽样的优点是:易于理解,简便易行;容易得到一个在总体中分布均匀的样本,其抽样误差小于单纯随机抽样。
缺点是:抽到的样本较分散,不易组织调查;当总体中观察单位按顺序有周期趋势或单调增加(减小)趋势时,容易产生偏倚。
3.整群抽样:整群抽样是先将总体划分为K个“群”,每个群包含若干个观察单位,再随机抽取k个群(k<K),由抽中的各群的全部观察单位组成样本。
整群抽样的优点是便于组织调查,节省经费,容易控制调查质量;缺点是当样本含量一定时,抽样误差大于单纯随机抽样。
4.分层抽样:分层抽样是先将总体中全部个体按对主要研究指标影响较大的某种特征分成若干“层”,再从每一层内随机抽取一定数量的观察单位组成样本。
分层随机抽样的优点是样本具有较好的代表性,抽样误差较小,分层后可根据具体情况对不同的层采用不同的抽样方法。
四种抽样方法的抽样误差大小一般是:整群抽样≥单纯随机抽样≥系统抽样≥分层抽样。
随机抽样的方法有哪些

随机抽样的方法有哪些(学习版)编制人:__________________审核人:__________________审批人:__________________编制学校:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的经典范文,如英语单词、英语语法、英语听力、英语知识点、语文知识点、文言文、数学公式、数学知识点、作文大全、其他资料等等,想了解不同范文格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor.I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!In addition, this shop provides various types of classic sample essays, such as English words, English grammar, English listening, English knowledge points, Chinese knowledge points, classical Chinese, mathematical formulas, mathematics knowledge points, composition books, other materials, etc. Learn about the different formats and writing styles of sample essays, so stay tuned!随机抽样的方法有哪些定义随机原则是在抽取被调查单位时,每个单位都有同等被抽到的机会,被抽取的单位完全是偶然性的。
随机抽样的常用的四种方法分析一览表
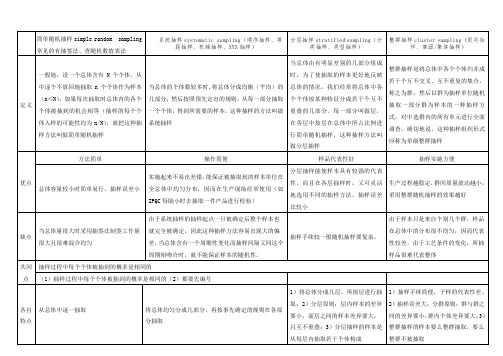
整群抽样是将总体中各个个体归并成若干个互不交叉、互不重复的集合,称之为群;然后以群为抽样单位随机抽取一部分群为样本的一种抽样方式。对中选群内的所有单元进行全面调查。确切地说,这种抽样组织形式应称为单级整群抽样
由于样本只是来自个别几个群,样品在总体中的分布很不均匀,因而代表性较差。由于工艺条件的变化,所抽样品很难代表整体
共同点
抽样过程中每个个体被抽到的概率是相同的
(1)抽样过程中每ቤተ መጻሕፍቲ ባይዱ个体被抽到的概率是相同的(2)都要先编号
各自 特点
从总体中逐一抽取
将总体均匀分成几部分,再按事先确定的规则在各部分抽取
1)将总体分成几层,再按层进行抽取;2)分层原则:层内样本的差异要小,面层之间的样本差异要大,且互不重叠;3)分层抽样的样本是从每层内抽取若干个体构成
适用 范围(场合)
适用于总体中个体数较少,抽取的样本容量也较小的抽样类型。
在实际工作中,真正做到总体中的每个个体被抽到的机会完全一样是不容易的,这往往上由各种客观条件和主观心理等许多因素综合影响造成的
总体中的个体数较多,但在总体会发生周期性变化的场合,不宜使用这种抽样法
1)总体由差异明显的几部分组成
简单随机抽样simple random sampling常见的有抽签法、查随机数值表法
系统抽样systematic sampling(顺序抽样、等距抽样、机械抽样、SYS抽样)
分层抽样stratified sampling(分类抽样、类型抽样)
常见的随机抽样方法介绍

抽样方法介绍朱一军福建省产品质量检验研究院、随机方法选择及随机数产生按照GB/T 10111-2008《随机数的产生及其在产品质量抽样检验中的应用程序》的要求,并根据受检单位的产品堆放形式、基数(批量)大小,确定抽样方法(通常包括简单随机抽样、分层随机抽样、系统抽样、整群抽样、全数抽样五种方法)。
随机数一般可使用随机数表、骰子或扑克牌中任选一种方式产生。
(一)简单随机抽样(抽签法、随机样数表法)常常用于总体个数较少时,它的主要特征是从总体中逐个抽取;优点:操作简便易行缺点:总体过大不易实行1.定义:一般地,设一个总体含有N个个体,从中逐个不放回地抽取n个个体作为样本(nW N ,如果每次抽取式总体内的各个个体被抽到的机会都相等,就把这种抽样方法叫做简单随机抽样。
2.简单随机抽样方法(1)抽签法一般地,抽签法就是把总体中的N个个体编号,把号码写在号签上,将号签放在一个容器中,搅拌均匀后,每次从中抽取一个号签,连续抽取n次,就得到一个容量为n的样本。
抽签法简单易行,适用于总体中的个数不多时。
当总体中的个体数较多时,将总体“搅拌均匀”就比较困难,用抽签法产生的样本代表性差的可能性很大)2)随机数法随机抽样中,另一个经常被采用的方法是随机数法,即利用随机数表、随机数骰子或计算机产生的随机数进行抽样。
二)分层抽样Stratified Random Sampling)主要特征分层按比例抽样,主要使用于总体中的个体有明显差异。
共同点:每个个体被抽到的概率都相等N/M。
定义般地,在抽样时,将总体分成互不交叉的层,然后按照定的比例,从各层独立地抽取一定数量的个体,将各层取出的个体合在一起作为样本,这种抽样方法是一种分层抽样stratified sampling )。
三)系统抽样当总体中的个体数较多时,采用简单随机抽样显得较为费事。
这时,可将总体分成均衡的几个部分,然后按照预先定出的规则,从每一部分抽取一个个体,得到所需要的样本,这种抽样叫做系统抽样。
精选高三数学知识点抽样方法

优选高三数学知识点抽样方法知识点是重点,为了能够使同学们在数学方面有所建树,小编特此整理了高三数学知识点抽样方法,以供大家参考。
一、简单随机抽样设一个整体的个体数为N ,假如经过逐一抽取的方法从中抽取一个样本,且每次抽取时,各个体被抽到的概率相等,就称这样的抽样为简单随机抽样。
一般地假如用简单随机抽样从个体数为N 的整体中抽取一个容量为n 的样本那么每个个体被抽到的概率等于n/N. 常用的简单随机抽样方法有:抽签法、随机数法。
1.抽签法一般地,抽签法就是把整体中的N 个个体编号,把号码写在号签上,将号签放在一个容器中,搅拌平均后,每次从中抽取一个号签,连续抽取n 次,就获得一个容量为n 的样本。
2.随机数法随机抽样中,另一个常常被采纳的方法是随机数法,即利用随机数表、随机数骰子或计算机产生的随机数进行抽样。
二、活用随机抽样课本、报刊杂志中的成语、名言警语等俯首皆是,但学生写作文运用到文章中的甚少,即便运用也很难做到恰到好处。
为什么?仍是没有完全“记死”的缘由。
要解决这个问题,方法很简第1页/共3页单,每天花3-5 分钟左右的时间记一条成语、一则名言警语即可。
能够写在后黑板的“累积专栏”上每天一换 ,能够在每天课前的3 分钟让学生轮番解说 ,也可让学生个人收集 ,每天往笔录本上抄录 ,教师按期检查等等。
这样 ,一年便可记 300 多条成语、300 多则名言警语 ,与日俱增 ,终归会成为一笔不小的财产。
这些成语典故“储藏”在学生脑中 ,自然会下笔成章 ,写作时便会为所欲为地“提取”出来 ,使文章添色添辉。
系统抽样的最基本特点是等距性,每组内所抽取的号码需要依照第一组抽取的号码和组距是独一确立,每组抽取样本的号码挨次构成一个以第一组抽取的号码 m 为首项,组距 d 为公差的等差数列{an}, 第 k 组抽取样本的号码, ak=m+(k-1)d ,如此题中根据第一组的样本号码和组距,可得第k 组抽取号码应当为9+30*(k-1)单靠“死”记还不可以 ,还得“活”用 ,临时称之为“先死后活”吧。
随机抽样的常用的四种方法分析一览表精编版

2)产品质量验收
1)样本单元的分布相对较集中的大规模抽样调查。
2)连接性生产的过程质量控制。
常见四种随机抽样(概率抽样)方式分析对比一览表
东莞宝峰金属制品有限公司/品质部唐植勇 2012-5-18
1)抽样手续简便,子样的代表性差。2)抽样误差大;分群原则:群与群之间的差异要小,群内个体差异要大;3)整群抽样的样本要么整群抽取,要么整群不被抽取
相互 联系
在起始部分抽样时采用简单随机抽样
在各层抽样时采用简单随机抽样或系统抽样
如果把每一个群看作一个单位,则整群抽样可以被理解为是一种特殊的简单随机抽样
生产过程越稳定,群间质量波动越小,采用整群随机抽样的效果越好
缺点
当总体量很大时采用抽签法制签工作量很大且很难混合均匀
随机抽样的常用的四种方法分析一览表word精品
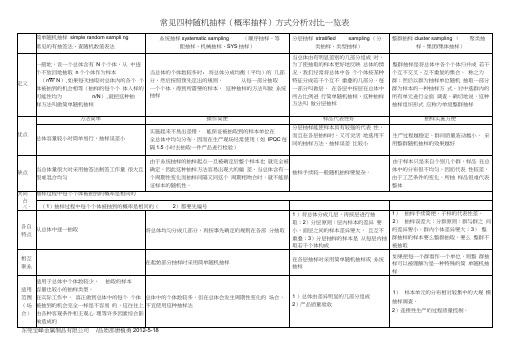
1)总体由差异明显的几部分组成
2)产品质量验收
1)样本单元的分布相对较集中的大规 模抽样调查。
2)连接性生产的过程质量控制。
东莞宝峰金属制品有限公司/品质部唐植勇2012-5-18
1)将总体分成几层,再按层进行抽 取;2)分层原则:层内样本的差异 要小,面层之间的样本差异要大, 且互不重叠;3)分层抽样的样本是 从每层内抽取若干个体构成
1)抽样手续简便,子样的代表性差。
2)抽样误差大;分群原则:群与群之 间的差异要小,群内个体差异要大;3) 整群抽样的样本要么整群抽取,要么 整群不被抽取
优点
方法简单
操作简便
样品代表性好
抽样实施方便
总体容量较小时简单易行,抽样误差小
实施起来不易出差错,能保证被抽取到的样本单位在
全总体中均匀分布,因而在生产现场经常使用(如IPQC每隔1.5小时去抽取一件产品进行检验)
分层抽样能使样本具有较强的代表 性,而且在各层抽样时,又可灵活 地选用不同的抽样方法,抽样误差 比较小
相互 联系
在起始部分抽样时采用简单随机抽样
在各层抽样时采用简单随机抽样或 系统抽样
如果把每一个群看作一个单位,则整 群抽样可以被理解为是一种特殊的简 单随机抽样
适用 范围
(场 合)
适用于总体中个体数较少,抽取的样本
容量也较小的抽样类型。
在实际工作中, 真正做到总体中的每个 个体被抽到的机会完全一样是不容易 的,这往往上由各种客观条件和主观心 理等许多因素综合影响造成的
生产过程越稳定,群间质量波动越小, 采用整群随机抽样的效果越好
缺点
当总体量很大时采用抽签法制签工作量 很大且很难混合均匀
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
适用于总体中个体数较少,抽取的样本容量也较小的抽样类型。
在实际工作中,真正做到总体中的每个个体被抽到的机会完全一样是不容易的,这往往上由各种客观条件和主观心理等许多因素综合影响造成的
总体中的个体数较多,但在总体会发生周期性变化的场合,不宜使用这种抽样法
1)总体由差异明显的几部分组成
优点
方法简单
操作简便
样品代表性好
抽样实施方便
总体容量较小时简单易行,抽样误差小
实施起来不易出差错,能保证被抽取到的样本单位在全总体中均匀分布,因而在生产现场经常使用(如IPQC每隔1.5小时去抽取一件产品进行检验)
分层抽样能使样本具有较强的代表性,而且在各层抽样时,又可灵活地选用不同的抽样方法,抽样误差比较小
简单随机抽样simple random sampling常见的有抽签法、查随机数值表法
系统抽样systematic sampling(顺序抽样、等距抽样、机械抽样、SYS抽样)
分层抽样stratified sampling(分类抽样、类型抽样)
整群抽样cluster sampling(聚类抽样、集团/集体抽样)
当总体由有明显差别的几部分组成时,为了使抽取的样本更好地反映总体的情况,我们经常将总体中各个个体按某种特征分成若干个互不重叠的几部分,每一部分叫做层,在各层中按层在总体中所占比例进行简单随机抽样,这种抽样方法叫做分层抽样
整群抽样是将总体中各个个体归并成若干个互不交叉、互不重复的集合,称之为群;然后以群为抽样单位随机抽取一部分群为样本的一种抽样方式。对中选群内的所有单元进行全面调查。确切地说,这种抽样组织形式应称为单级整群抽样
定义
一般地,设一个总体含有N个个体,从中逐个不放回地抽取n个个体作为样本(n≤N),如果每次抽取时总体内的各个个体被抽到的机会相等(抽样的每个个体入样的可能性均为n/N),就把这种抽样方法叫做简单随机抽样
当总体的个体数较多时,将总体分成均衡(平均)的几部分,然后按照预先定出的规则,从每一部分抽取一个个体,得到所需要的样本,这种抽样的方法叫做系统抽样
2)产品质量验收
1)样本单元的分布相对较集中的大规模抽样调查。
2)连接性生产的过程质量控制。
常见四种随机抽样(概率抽样)方式分析对比一览表
东莞宝峰金属制品有限公司/品质部唐植勇 2012-5-18
1)抽样手续简便,子样的代表性差。2)抽样误差大;分群原则:群与群之间的差异要小,群内个体差异要大;3)整群抽样的样本要么整群抽取,要么整群不被抽取
相互 联系
在起始部分抽样时采用简单随机抽样
在各层抽样时采用简单随机抽样或系统抽样
如果把每一个群看作一个单位,则整群抽样可以被理解为是一种特殊的简单随机抽样
生产过程越稳定,群间质量波动越小,采用整群随机抽样的效果越好
缺点
当总体量很大时采用抽签法制签工作量很大且很难混合均匀
由于系统抽样的抽样起点一旦被确定后整个样本也就完全被确定,因此这种抽样方法容易出现大的偏差,当总体含有一个周期性变化而抽样间隔又同这个周期相吻合时,就不能保证样本的随机性。
抽样手续较一般随机抽样要复杂。
由于样本只是来自个别几个群,样品在总体中的分布很不均匀,因而代表性较差。由于工艺条件的变化,所抽样品很难代表整体
共同点
抽样过程中每个个体被抽到的概率是相同的
(1)抽样过程中每个个体被抽到的概率是相同的(2)都要先编号
各自 特点
从总体中逐一抽取
将总体均匀分成几部分,再按事先确定的规则在各部分抽取
1)将总体分成几层,再按层进行抽取;2)分层原则:层内样本的差异要小,面层之间的样本差异要大,且互不重叠;3)分层抽样的样本是从每层内抽取若干个体构成