计量经济学 第二章习题

1.最小二乘法对随机误差项u作了哪些假定?说明这些假定条件的意义。
答:假定条件:
(1)均值假设:E(u i)=0,i=1,2,…;
(2)同方差假设:Var(u i)=E[u i-E(u i)]2=E(u i2)=σu2 ,i=1,2,…;
(3)序列不相关假设:Cov(u i,u j)=E[u i-E(u i)][u j-E(u j)]=E(u i u j)=0,i≠j,i,j=1,2,…;
(4)Cov(u i,X i)=E[u i-E(u i)][X i-E(X i)]=E(u i X i)=0;
(5)u i服从正态分布, u i~N(0,σu2)。
意义:有了这些假定条件,就可以用普通最小二乘法估计回归模型的参数。
2.阐述对样本回归模型拟合优度的检验及回归系数估计值显著性检验的步骤。
答:样本回归模型拟合优度的检验:可通过总离差平方和的分解、样本可决系数、样本相关系数来检验。
回归系数估计值显著性检验的步骤:
(1)提出原假设H0 :β1=0;
(2)备择假设H1 :β1≠0;
(3)计算t=β1/Sβ1;
(4)给出显著性水平α,查自由度v=n-2的t分布表,得临界值tα/2(n-2);
(5)作出判断。如果|t|
4.试说明为什么∑e i2的自由度等于n-2。
答:在模型中,自由度指样本中可以自由变动的独立不相关的变量个数。当有约束条件时,自由度减少,其计算公式:自由度=样本个数-受约束条件的个数,即df=n-k。一元线性回归中SSE残差的平方和,其自由度为n-2,因为计算残差时用到回归方程,回归方程中有两个未知参数β0和β1,而这两个参数需要两个约束条件予以确定,由此减去2,也即其自由度为n-2。
5.试说明样本可决系数与样本相关系数的关系及区别,以及样本相关系数与β^1的关系。答:样本相关系数r的数值等于样本可决系数的平方根,符号与β1相同。但样本相关系数与样本可决系数在概念上有明显的区别,r建立在相关分析的理论基础之上,研究两个随机变量X与Y之间的线性相关关系;样本可决系数r2建立在回归分析的理论基础之上,研究非随机变量X对随机变量Y的解释程度。
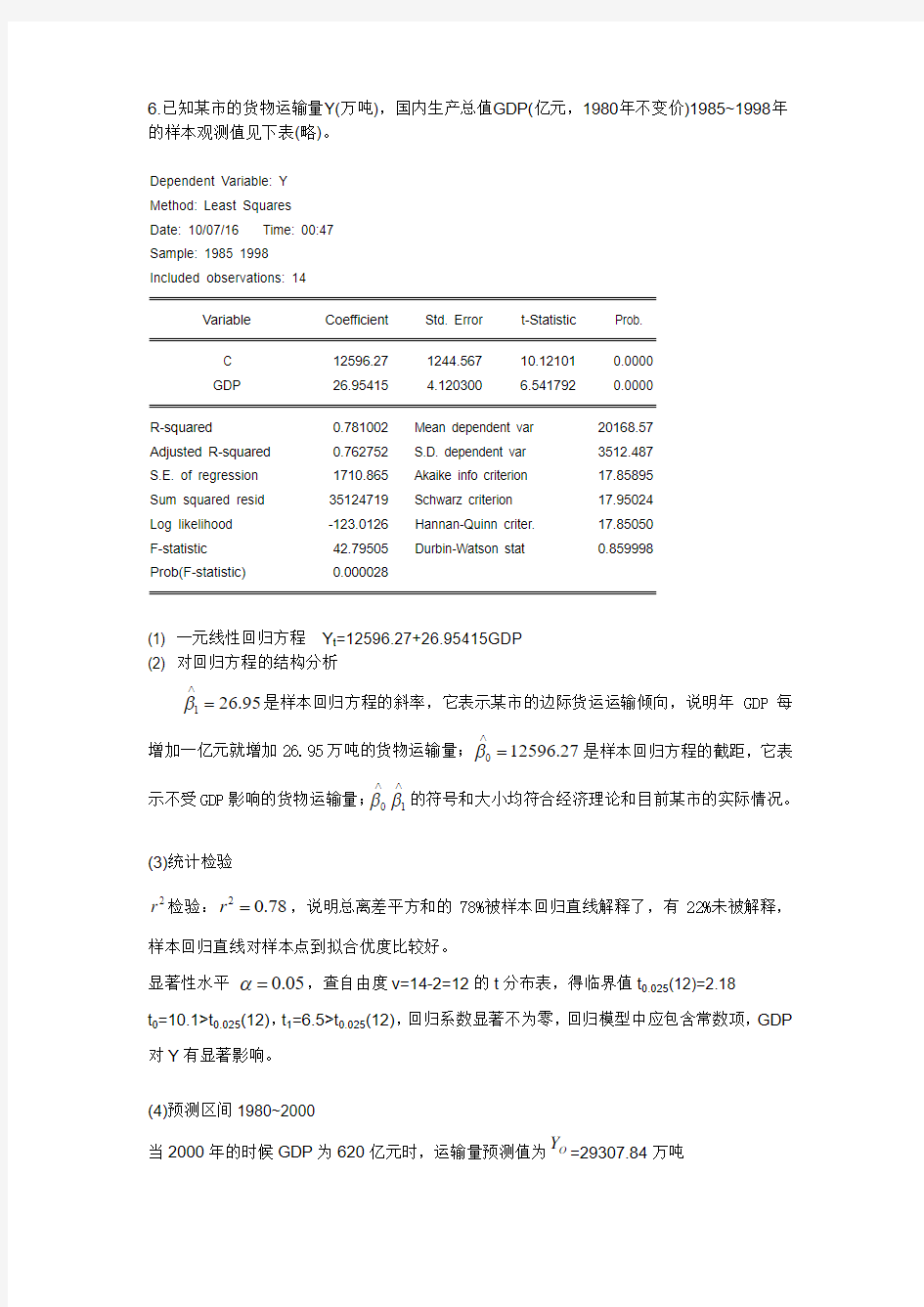
6.已知某市的货物运输量Y(万吨),国内生产总值GDP(亿元,1980年不变价)1985~1998年的样本观测值见下表(略)。
Dependent Variable: Y Method: Least Squares Date: 10/07/16 Time: 00:47 Sample: 1985 1998 Included observations: 14
Variable Coefficient Std. Error t-Statistic Prob. C 12596.27 1244.567 10.12101 0.0000 GDP
26.95415
4.120300
6.541792
0.0000
R-squared 0.781002 Mean dependent var 20168.57 Adjusted R-squared 0.762752 S.D. dependent var 3512.487 S.E. of regression 1710.865 Akaike info criterion 17.85895 Sum squared resid 35124719 Schwarz criterion 17.95024 Log likelihood -123.0126 Hannan-Quinn criter. 17.85050 F-statistic 42.79505 Durbin-Watson stat 0.859998
Prob(F-statistic)
0.000028
(1) 一元线性回归方程 Y t =12596.27+26.95415GDP (2) 对回归方程的结构分析
126.95β∧
=是样本回归方程的斜率,它表示某市的边际货运运输倾向,说明年GDP 每
增加一亿元就增加26.95万吨的货物运输量;012596.27β∧
=是样本回归方程的截距,它表
示不受GDP 影响的货物运输量;01ββ∧∧
的符号和大小均符合经济理论和目前某市的实际情况。
(3)统计检验
2r 检验:20.78r =,说明总离差平方和的78%被样本回归直线解释了,有22%未被解释,
样本回归直线对样本点到拟合优度比较好。
显著性水平 0.05α=,查自由度v=14-2=12的t 分布表,得临界值t 0.025(12)=2.18 t 0=10.1>t 0.025(12),t 1=6.5>t 0.025(12),回归系数显著不为零,回归模型中应包含常数项,GDP 对Y 有显著影响。
(4)预测区间1980~2000
当2000年的时候GDP 为620亿元时,运输量预测值为
O
Y =29307.84万吨
计算得到:280.93X =
21277340
i
x
=∑
213262.66
e s =
则:
()22
22
11e i X X s n x σ∧??
-??=++????∑=15403.69 0022,O Y Y t Y t αασσ∧∧∧∧??
??
∈-+????
即
[]
29037.28,29578.40O Y ∈
7. 我国粮食产量Q (万吨)、农业机械总动力X1(万瓦时)、化肥施用量X2(万吨)、土地灌溉面积X3(千公顷)1978~1998年样本观测值见下表。(略) (1)我国粮食产量Q (万吨)和农业机械总动力X1(万瓦时)
1) 估计模型
Dependent Variable: Q Method: Least Squares Date: 10/07/16 Time: 01:42 Sample: 1978 1998 Included observations: 21
Variable Coefficient Std. Error t-Statistic Prob. C 40772.47 1389.795 29.33704 0.0000 X1
0.001220
0.001909
0.639194
0.5303
R-squared 0.021051 Mean dependent var 40996.12 Adjusted R-squared -0.030473 S.D. dependent var 6071.868 S.E. of regression 6163.687 Akaike info criterion 20.38113 Sum squared resid 7.22E+08 Schwarz criterion 20.48061 Log likelihood -212.0019 Hannan-Quinn criter. 20.40272 F-statistic 0.408568 Durbin-Watson stat 0.206201
Prob(F-statistic)
0.530328
估计一元回归模型:011t t t Q X e αα∧∧
=++
即样本回归模型为:140774.470.00122t t
Q X ∧
=+
2)对估计结果作结构分析
10.00122α∧
=是样本回归方程的斜率,说明农业机械总动力每增加1万瓦时我国粮食
产量就增加0.00122万吨;040772.47α∧
=是样本回归方程的截距,它表示不受农业机械总动力影响的粮食总量;01αα∧
∧的符号和大小均符合经济理论和我国的实际情况。 3)对估计结果进行统计检验
2r 检验:20.02r =,
说明总离差平方和的2%被样本回归直线解释了,有98%未被解释,样本回归直线对样本点到拟合优度很差。
T 检验:给出显著水平0.05α=,查自由度v=19的t 分布表,得()0.02519 2.09t =,
023.34 2.09t =>,故回归系数均显著为零,回归模型中应包含常数项,X1对Q 无显著影
响.
(2) 我国粮食产量Q (万吨)和化肥施用量X2(万吨) 1)作散点图并估计模型
估计一元回归模型:012t
t t Q X e ββ∧∧
=++
Dependent Variable: Q Method: Least Squares Date: 10/07/16 Time: 01:51
Sample: 1978 1998 Included observations: 21
Variable Coefficient Std. Error t-Statistic Prob. C 26925.65 915.8657 29.39912 0.0000 X2
5.912534
0.356423
16.58851
0.0000
R-squared 0.935413 Mean dependent var 40996.12 Adjusted R-squared 0.932014 S.D. dependent var 6071.868 S.E. of regression 1583.185 Akaike info criterion 17.66266 Sum squared resid 47623035 Schwarz criterion 17.76214 Log likelihood -183.4579 Hannan-Quinn criter. 17.68425 F-statistic 275.1787 Durbin-Watson stat 1.264400 Prob(F-statistic) 0.000000
即样本回归模型为:226925.65 5.91t t
Q X ∧
=+
2)对估计结果作结构分析
1 5.91β∧
=是样本回归方程的斜率,说明化肥施用量每增加1万吨我国粮食产量就增加
5.91万吨;026925.65β∧
=是样本回归方程的截距,它表示不受化肥施用量影响的粮食总量;01ββ∧
∧
的符号和大小均符合经济理论和我国的实际情况。 3)对估计结果进行统计检验
2r 检验:20.94r =,
说明总离差平方和的94%被样本回归直线解释了,有6%未被解释,样本回归直线对样本点到拟合优度很高。
T 检验:给出显著水平0.05α=,查自由度v=19的t 分布表,得()0.02519 2.09t =,
029.40 2.09t =>,1 5.91 2.09t =>,故回归系数均显著不为零,回归模型中应包含常数
项,X2对Q 有显著影响.
(3) 我国粮食产量Q (万吨)和土地灌溉面积X3(千公顷) 1)作散点图并估计模型 估计一元回归模型:013t
t t Q X e γγ∧∧
=++
Dependent Variable: Q Method: Least Squares Date: 10/07/16 Time: 01:55 Sample: 1978 1998 Included observations: 21
Variable Coefficient Std. Error t-Statistic Prob. C -49865.39 12638.40 -3.945545 0.0009 X3
1.948700
0.270634
7.200498
0.0000
R-squared 0.731817 Mean dependent var 40996.12 Adjusted R-squared 0.717702 S.D. dependent var 6071.868 S.E. of regression 3226.087 Akaike info criterion 19.08632 Sum squared resid 1.98E+08 Schwarz criterion 19.18580 Log likelihood -198.4064 Hannan-Quinn criter. 19.10791 F-statistic 51.84718 Durbin-Watson stat 0.304603 Prob(F-statistic) 0.000001
即样本回归模型为:349865.39 1.9487t t Q X ∧
=-+ 2)对估计结果作结构分析
1 1.95γ∧
=是样本回归方程的斜率,说明土地灌溉面积每增加1千公顷我国粮食产量就
增加1.95万吨;049865.39γ∧
=-是样本回归方程的截距,它表示不受化肥施用量影响的粮食总量;
3)对估计结果进行统计检验
2r 检验:20.73r =,说明总离差平方和的73%被样本回归直线解释了,有27%未被解
释,样本回归直线对样本点到拟合优度较好。
T 检验:给出显著水平0.05α=,查自由度v=19的t 分布表,得()0.02519 2.09t =,
0 3.95 2.09t =-<,17.2 2.09t => 。故0γ显著为0,则常数项0γ不应该出现在模型中;1
γ显著不为零,表明3X 对Q 有显著影响。 最好的模型是第二个模型。即226925.65 5.91t t
Q X ∧
=+
2000年的预测值为:51440.80O Y ∧
= 计算得到:22673.563X =
2
209787280i
x
=∑
2
1295365e s = 则:()22
022
11e i X X s n x σ∧??-??=++????
∑=136**** ****,O Y Y t Y t αασσ∧∧∧∧????∈-+???? 给出显著水平0.05α= 0.025(23) 2.07t = 即[]49026.28,53855.32O Y ∈
8.查中国统计年鉴,利用1978~2000的财政收入和GDP 的统计资料,要求以手工和EViews
软件。 (1)散点图
Dependent Variable: Y Method: Least Squares Date: 10/07/16 Time: 02:40 Sample: 1978 2000
20,000
40,00060,000
80,000
100,000
Y
G D P
Included observations: 23
Variable Coefficient Std. Error t-Statistic Prob.
GDP 0.986097 0.001548 637.0383 0.0000
C 174.4171 50.39589 3.460939 0.0023
R-squared 0.999948 Mean dependent var 22634.30
Adjusted R-squared 0.999946 S.D. dependent var 23455.82
S.E. of regression 172.6972 Akaike info criterion 13.22390
Sum squared resid 626310.6 Schwarz criterion 13.32264
Log likelihood -150.0748 Hannan-Quinn criter. 13.24873
F-statistic 405817.8 Durbin-Watson stat 0.984085
Prob(F-statistic) 0.000000
一元线性回归方程Y=174.4174+0.98GDP t
经济意义国名收入每增加1亿元,将有0.98亿元用于国内生产总值。
(2)检验r2=99%,说明总离查平方和的99%被样本回归直线解释,仅有1%未被解释,所以说样本回归直线对样本点的拟合优度很高。
显著性水平α=0.05,查自由度v=23-2=21的t分布表,得临界值t0.025(21)=2.08。
(3)预测值及预测区间
obs Y YF YFSE GDP
1978 3645.2 3768.93952756
0003
178.879907887
3616 3645.2
1979 4062.6 4180.53660248
6764
178.774077728
9417 4062.6
1980 4545.60000000
0001
4656.82167002
3003
178.654453123
7366
4545.60000000
0001
1981 4889.5 4998.01138714
0059
178.570634469
0318
4891.60000000
0001
1982 4889.5 4998.01138714
0059
178.570634469
0318
4891.60000000
0001
1983 5330.5 5423.80826532
2558
178.468230113
8803
5323.39999999
9999
1984 5985.6 6054.22036403
0461
178.321108326
6242 5962.7
1985 7243.8 7282.30612616
2203
178.049950484
8901 7208.1
1986 9040.70000000
0001
9065.07170297
124
177.692806300
9931 9016
1987 12050.6 12065.3717992
1504
177.189939863
8916 12058.6
1988 10274.4 10306.7656098
8973
177.469705227
4058 10275.2
1989 12050.6 12065.3717992
1504
177.189939863
8916 12058.6
1990 15036.8 15008.0838044
7724
176.817239439
1318 15042.8
1991 17000.9 16930.4807799
6771
176.638587454
0277 16992.3
1992 18718.3 18582.6870546
1982
176.526126442
3878 18667.8
1993 35260 35017.0857379
8564
177.479184885
4038 35333.9
1994 21826.2 21653.0986794
3883
176.418239372
4463 21781.5
1995 26937.3 26723.6117586
7555
176.528268981
9769 26923.5
1996 35260 35017.0857379
8564
177.479184885
4038 35333.9
1997 48108.5 47702.2433131
1228
180.747077071
1596 48197.9
1998 59810.5 60122.9295526
0078
185.968135704
4579 60793.7
1999 88479.2 88604.7765912
6783
204.561247885
8191 89677.1
2000 70142.5 70361.4807487
1261
191.661404210
2092 71176.6
2001 104413.792272
9122
218.176634678
1298 105709
单个值的预测区间Y2000∈[104413.8-2.07×218.2,104413.8+2.07×218.2] 均值预测区间E(Y2000)∈[104413.8-2.07×218.2,104413.8+2.07×218.2]
计量经济学习题及答案汇总
《 期中练习题 1、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则是指( ) A .使 ∑=-n t t t Y Y 1)?(达到最小值 B.使∑=-n t t t Y Y 1达到最小值 C. 使 ∑=-n t t t Y Y 1 2 )(达到最小值 D.使∑=-n t t t Y Y 1 2)?(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为 ?ln 2.00.75ln i i Y X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( ) A. B. % C. 2 D. % 3、设k 为回归模型中的参数个数,n 为样本容量。则对总体回归模型进行显著性检验的F 统计量与可决系数2 R 之间的关系为( ) ~ A.)1/()1()/(R 2 2---=k R k n F B. )/(1)-(k )R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. ) 1()1/(2 2R k R F --= 6、二元线性回归分析中 TSS=RSS+ESS 。则 RSS 的自由度为( ) 9、已知五个解释变量线形回归模型估计的残差平方和为 8002=∑t e ,样本容量为46,则随机误 差项μ的方差估计量2 ?σ 为( ) D. 20 1、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2 i )V ar(u i σ= C. 0)u E(u j i ≠ ) D.随机解释变量X 与随机误差i u 不相关 E. i u ~),0(2 i N σ 2、对于二元样本回归模型i i i i e X X Y +++=2211???ββα,下列各式成立的有( ) A.0 =∑i e B. 0 1=∑i i X e C. 0 2=∑i i X e D. =∑i i Y e E. 21=∑i i X X 4、能够检验多重共线性的方法有( )
计量经济学习题第2章-一元线性回归模型
第2章 一元线性回归模型 一、单项选择题 1、变量之间的关系可以分为两大类__________。 A 函数关系与相关关系 B 线性相关关系和非线性相关关系 C 正相关关系和负相关关系 D 简单相关关系和复杂相关关系 2、相关关系是指__________。 A 变量间的非独立关系 B 变量间的因果关系 C 变量间的函数关系 D 变量间不确定性的依存关系 3、进行相关分析时的两个变量__________。 A 都是随机变量 B 都不是随机变量 C 一个是随机变量,一个不是随机变量 D 随机的或非随机都可以 4、表示x 和y 之间真实线性关系的是__________。 A 01???t t Y X ββ=+ B 01()t t E Y X ββ=+ C 01t t t Y X u ββ=++ D 01t t Y X ββ=+ 5、参数β的估计量?β 具备有效性是指__________。 A ?var ()=0β B ?var ()β为最小 C ?()0β β-= D ?()ββ-为最小 6、对于01??i i i Y X e ββ=++,以σ?表示估计标准误差,Y ?表示回归值,则__________。 A i i ??0Y Y 0σ∑ =时,(-)= B 2 i i ??0Y Y σ∑=时,(-)=0 C i i ??0Y Y σ∑=时,(-)为最小 D 2 i i ??0Y Y σ∑=时,(-)为最小 7、设样本回归模型为i 01i i ??Y =X +e ββ+,则普通最小二乘法确定的i ?β的公式中,错误的是__________。 A ()() () i i 1 2 i X X Y -Y ?X X β--∑∑= B ()i i i i 1 2 2 i i n X Y -X Y ?n X -X β ∑∑∑∑∑= C i i 1 2 2 i X Y -nXY ?X -nX β ∑∑= D i i i i 1 2x n X Y -X Y ?β σ ∑∑∑= 8、对于i 01i i ??Y =X +e ββ+,以?σ表示估计标准误差,r 表示相关系数,则有__________。 A ?0r=1σ =时, B ?0r=-1σ =时, C ?0r=0σ =时, D ?0r=1r=-1σ =时,或 9、产量(X ,台)与单位产品成本(Y ,元/台)之间的回归方程为?Y 356 1.5X -=,这说明__________。 A 产量每增加一台,单位产品成本增加356元 B 产量每增加一台,单位产品成本减少1.5元 C 产量每增加一台,单位产品成本平均增加356元 D 产量每增加一台,单位产品成本平均减少1.5元
计量经济学习题及全部答案
《计量经济学》习题(一) 一、判断正误 1.在研究经济变量之间的非确定性关系时,回归分析是唯一可用的分析方法。() 2.最小二乘法进行参数估计的基本原理是使残差平方和最小。() 3.无论回归模型中包括多少个解释变量,总离差平方和的自由度总为(n-1)。() 4.当我们说估计的回归系数在统计上是显着的,意思是说它显着地异于0。() 5.总离差平方和(TSS)可分解为残差平方和(ESS)与回归平方和(RSS)之和,其中残差平方和(ESS)表示总离差平方和中可由样本回归直线解释的部分。() 6.多元线性回归模型的F检验和t检验是一致的。() 7.当存在严重的多重共线性时,普通最小二乘估计往往会低估参数估计量的方差。() 8.如果随机误差项的方差随解释变量变化而变化,则线性回归模型存在随机误差项的 自相关。() 9.在存在异方差的情况下,会对回归模型的正确建立和统计推断带来严重后果。() 10... DW检验只能检验一阶自相关。() 二、单选题
1.样本回归函数(方程)的表达式为( )。 A .i Y =01i i X u ββ++ B .(/)i E Y X =01i X ββ+ C .i Y =01??i i X e ββ++ D .?i Y =01??i X ββ+ 2.下图中“{”所指的距离是( )。 A .随机干扰项 B .残差 C .i Y 的离差 D .?i Y 的离差 3.在总体回归方程(/)E Y X =01X ββ+中,1β表示( )。 A .当X 增加一个单位时,Y 增加1β个单位 B .当X 增加一个单位时,Y 平均增加1β个单位 C .当Y 增加一个单位时,X 增加1β个单位 D .当Y 增加一个单位时,X 平均增加1β个单位 4.可决系数2R 是指( )。 A .剩余平方和占总离差平方和的比重 B .总离差平方和占回归平方和的比重 C .回归平方和占总离差平方和的比重 D .回归平方和占剩余平方和的比重 5.已知含有截距项的三元线性回归模型估计的残差平方和为2i e ∑=800,估
计量经济学例题
一、单项选择题 4.横截面数据是指(A )。 A .同一时点上不同统计单位相同统计指标组成的数据 B .同一时点上相同统计单位相同统计指标组成的数据 C .同一时点上相同统计单位不同统计指标组成的数据 D .同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C )。 A .时期数据 B .混合数据 C .时间序列数据 D .横截面数据 9.下面属于横截面数据的是( D )。 A .1991-2003年各年某地区20个乡镇企业的平均工业产值 B .1991-2003年各年某地区20个乡镇企业各镇的工业产值 C .某年某地区20个乡镇工业产值的合计数 D .某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A .设定理论模型→收集样本资料→估计模型参数→检验模型 B .设定模型→估计参数→检验模型→应用模型 C .个体设计→总体估计→估计模型→应用模型 D .确定模型导向→确定变量及方程式→估计模型→应用模型 13.同一统计指标按时间顺序记录的数据列称为( B )。 A .横截面数据 B .时间序列数据 C .修匀数据 D .原始数据 14.计量经济模型的基本应用领域有( A )。 A .结构分析、经济预测、政策评价 B .弹性分析、乘数分析、政策模拟 C .消费需求分析、生产技术分析、 D .季度分析、年度分析、中长期分析 18.表示x 和y 之间真实线性关系的是( C )。 A .01???t t Y X ββ=+ B .01()t t E Y X ββ=+ C .01t t t Y X u ββ=++ D .01t t Y X ββ=+ 19.参数β的估计量?β具备有效性是指( B )。 A .?var ()=0β B .?var ()β为最小 C .?()0ββ-= D .?()ββ-为最小 25.对回归模型i 01i i Y X u ββ+=+进行检验时,通常假定i u 服从( C )。 A .2i N 0) σ(, B . t(n-2) C .2N 0)σ(, D .t(n) 26.以Y 表示实际观测值,?Y 表示回归估计值,则普通最小二乘法估计参数的准则是使( D )。 A .i i ?Y Y 0∑(-)= B .2i i ?Y Y 0∑(-)= C .i i ?Y Y ∑(-)=最小 D .2 i i ?Y Y ∑(-)=最小 27.设Y 表示实际观测值,?Y 表示OLS 估计回归值,则下列哪项成立( D )。 A .?Y Y = B .?Y Y = C .?Y Y = D .?Y Y =
计量经济学第二章主要公式
第二章主要公式 资料地址:https://www.360docs.net/doc/872109831.html,/jl 1、回归模型概述 (1)相关分析与回归分析 经济变量之间的关系:函数关系、相关关系 相关关系:单相关和复相关,完全相关、不完全相关和不相关,正相关与负相关,线性相关和负相关,线性相关和非线性相关。 相关分析: ——总体相关系数XY ρ= ——样本相关系数()() n i i XY X X Y Y r --= ∑ ——多个变量之间的相关程度可用复相关系数和偏相关系数度量 回归分析:相关关系 + 因果关系 (2)随机误差项:含有随机误差项是计量经济学模型与数理经济学模型的一大区别。 (3)总体回归模型 总体回归曲线:给定解释变量条件下被解释变量的期望轨迹。 总体回归函数:(|)()i i E Y X f X = 总体回归模型:(|)()i i i i i Y E Y X f X μμ=+=+ 线性总体回归模型:011,2,...,i i i Y X i n ββμ=++= (4)样本回归模型 样本回归曲线:根据样本回归函数得到的被解释变量的轨迹。 (线性)样本回归函数: 01???i i Y X ββ=+ (线性)样本回归模型:01???i i i Y X e ββ=++ 2、一元线性回归模型的参数估计 (1)基本假设 ① 解释变量:是确定性变量,不是随机变量 var()0i X = ② 随机误差项:零均值、同方差,在不同样本点之间独立,不存在序列相关等 ()01,2,...,i E i n μ== 2var()1,2,...,i i n μσ==
cov(,)0;,1,2,...,i j i j i j n μμ=≠= ③ 随机误差项与解释变量:不相关 cov(,)01,2,...,i i X i n μ== ④ (针对最大似然法和假设检验)随机误差项: 2~(0,)1,2,...,i N i n μσ= ⑤ 回归模型正确设定。 【前四条为线性回归模型的古典假设,即高斯假设。满足古典假设的线性回归模型称为古典线性回归模型。】 (2)参数的普通最小二乘估计(OLS ) 目标:21 min n i i e =∑ 对于一元线性回归模型:011,2,...,i i i Y X i n ββμ=++= 正规方程组: 011 011 ?? 2[()]0??2[()]0n i i i n i i i i Y X X Y X ββββ==?--+=????--+=??∑∑ 解得: 011 112 211??()()?()n n i i i i i i n n i i i i Y X X X Y Y x y X X x βββ====?=-???--?==??-?? ∑∑∑∑ (3)最大似然估计(ML ) 对于一元线性回归模型:011,2,...,i i i Y X i n ββμ=++= 重要的基本假设: 2~(0,)1,2,...,cov(,)0;,1,2,...,var()01,2,...,i i j i N i n i j i j n X i n μσμμ?=? =≠=?? ==? 得到:2 01~(,)1,2,...,i i Y N X i n ββσ+= 【且cov(,)0;,1,2,...,i j Y Y i j i j n =≠=,这个对最大似然法的估计很重要】 则目标:12,,...,n Y Y Y 的联合概率密度最大,即
计量经济学答案部分Word版
第一章导论 一、单项选择题 1-6: CCCBCAC 二、多项选择题 ABCD;ACD;ABCD 三.问答题 什么是计量经济学? 答案见教材第3页 四、案例分析题 假定让你对中国家庭用汽车市场发展情况进行研究,应该分哪些步骤,分别如何分析?(参考计量经济学研究的步骤) 第一步:选取被研究对象的变量:汽车销售量 第二步:根据理论及经验分析,寻找影响汽车销售量的因素,如汽车价格,汽油价格,收入水平等 第三步:建立反映汽车销售量及其影响因素的计量经济学模型 第四步:估计模型中的参数; 第五步:对模型进行计量经济学检验、统计检验以及经济意义检验; 第六步:进行结构分析及在给定解释变量的情况下预测中国汽车销售量的未来值为汽车业的发展提供政策实施依据。 第二章简单线性回归模型 一、填空题 1、线性、无偏、最小方差性(有效性),BLUE。 2、解释变量;参数;参数。 3、随机误差项;随机误差项。 二、单项选择题 1-4:BBDA;6-11:CDCBCA 三、多项选择题 1.ABC; 2.ABC; 3.BC; 4.ABE; 5.AD; 6.BC 四、判断正误: 1. 错; 2. 错; 3. 对; 4.错; 5. 错; 6. 对; 7. 对; 8.错 五、简答题: 1.为什么模型中要引入随机扰动项? 答:模型是对经济问题的一种数学模型,在模型中,被解释变量是研究的对象,解释变量是其确定的解释因素,但由于实际问题的错综复杂,影响被解释变量的因素中,除了包括在模型中的解释变量以外,还有其他一些因素未能包括在模型中,但却影响被解释变量,我们把这类变量统一用随机误差项表示。随机误差项包含的因素有:
计量经济学练习题答案完整
1、已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X (45.2)(1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题: (1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 答:(1)系数的符号是正确的,政府债券的价格与利率是负相关关系,利率的上升会引起政府债券价格的下降。 (2)i Y 代表的是样本值,而i ?Y 代表的是给定i X 的条件下i Y 的期望值,即?(/)i i i Y E Y X 。此模型是根据样本数据得出的回归结果,左边应当是i Y 的期望值,因此是i ?Y 而不是i Y 。 (3)没有遗漏,因为这是根据样本做出的回归结果,并不是理论模型。 (4)截距项101.4表示在X 取0时Y 的水平,本例中它没有实际意义;斜率项-4.78表明利率X 每上升一个百分点,引起政府债券价格Y 降低478美元。 2、有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y
Variable Coefficient Std. Error X 0.202298 0.023273 C 2.172664 0.720217 R-squared 0.904259 S.D. dependent var 2.233582 Adjusted R-squared 0.892292 F-statistic 75.55898 Durbin-Watson stat 2.077648 Prob(F-statistic) 0.000024 (1)说明回归直线的代表性及解释能力。 (2)在95%的置信度下检验参数的显著性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在95%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其中29.3x =,2()992.1x x -=∑) 答:(1)回归模型的R 2=0.9042,表明在消费Y 的总变差中,由回归直线解释的部分占到90%以上,回归直线的代表性及解释能力较好。 (2)对于斜率项,11 ? 0.20238.6824?0.0233 ()b t s b ===>0.05(8) 1.8595t =,即表明斜率项 显著不为0,家庭收入对消费有显著影响。对于截距项, 00? 2.1727 3.0167?0.7202 ()b t s b ===>0.05(8) 1.8595t =, 即表明截距项也显著不为0,通过了显著性检验。 (3)Y f =2.17+0.2023×45=11.2735 0.025(8) 1.8595 2.2336 4.823t ?=?= 95%置信区间为(11.2735-4.823,11.2735+4.823),即(6.4505,16.0965)。
计量经济学(第四版)习题及参考答案详细版
计量经济学(第四版)习题参考答案 潘省初
第一章 绪论 1.1 试列出计量经济分析的主要步骤。 一般说来,计量经济分析按照以下步骤进行: (1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项? 为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。 1.3什么是时间序列和横截面数据? 试举例说明二者的区别。 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。 横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。 1.4估计量和估计值有何区别? 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。在一项应用中,依据估计量算出的一个具体的数值,称为估计值。如Y 就是一个估计量,1 n i i Y Y n == ∑。现有一样本,共4个数,100,104,96,130,则 根据这个样本的数据运用均值估计量得出的均值估计值为 5.1074 130 96104100=+++。 第二章 计量经济分析的统计学基础 2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间 N S S x = =45 =1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684 也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。 2.3 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH 备择假设 120:1≠μH 检验统计量 () 10/25X X μσ-Z == == 查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。 2.4 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH 备择假设 : 2500:1≠μH ()100/1200.83?X X t μσ-= === 查表得 131.2)116(025.0=-t 因为t = 0.83 < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
计量经济学第三版课后习题答案 第一章 绪论
第一章 绪论 (一)基本知识类题型 1-1. 什么是计量经济学? 1-2. 简述当代计量经济学发展的动向。 1-3. 计量经济学方法与一般经济数学方法有什么区别? 1-4.为什么说计量经济学是经济理论、数学和经济统计学的结合?试述三者之关系。 1-5.为什么说计量经济学是一门经济学科?它在经济学科体系中的作用和地位是什么? 1-6.计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征? 1-7.试结合一个具体经济问题说明建立与应用计量经济学模型的主要步骤。 1-8.建立计量经济学模型的基本思想是什么? 1-9.计量经济学模型主要有哪些应用领域?各自的原理是什么? 1-10.试分别举出五个时间序列数据和横截面数据,并说明时间序列数据和横截面数据有和异同? 1-11.试解释单方程模型和联立方程模型的概念,并举例说明两者之间的联系与区别。 1-12.模型的检验包括几个方面?其具体含义是什么? 1-13.常用的样本数据有哪些? 1-14.计量经济模型中为何要包括随机误差项?简述随机误差项形成的原因。 1-15.估计量和估计值有何区别?哪些类型的关系式不存在估计问题? 1-16.经济数据在计量经济分析中的作用是什么? 1-17.下列假想模型是否属于揭示因果关系的计量经济学模型?为什么? ⑴ S R t t =+1120012.. 其中S t 为第t 年农村居民储蓄增加额(亿元)、R t 为第t 年城镇 居民可支配收入总额(亿元)。 ⑵ S R t t -=+144320030.. 其中S t -1为第(1-t )年底农村居民储蓄余额(亿元)、R t 为第t 年农村居民纯收入总额(亿元)。 1-18.指出下列假想模型中的错误,并说明理由: (1)RS RI IV t t t =-+83000024112... 其中,RS t 为第t 年社会消费品零售总额(亿元),RI t 为第t 年居民收入总额(亿元)(城镇 居民可支配收入总额与农村居民纯收入总额之和),IV t 为第t 年全社会固定资产投资总额
计量经济学习题及答案
第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间__________的关系,用__________性的数学方程加以描述。 3.经济数学模型是用__________描述经济活动。 4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。 5.计量经济学模型包括__________和__________两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即__________、____________________、____________________。 7.确定理论模型中所包含的变量,主要指确定__________。 8.可以作为解释变量的几类变量有__________变量、__________变量、__________变量和__________变量。 9.选择模型数学形式的主要依据是__________。 10.研究经济问题时,一般要处理三种类型的数据:__________数据、__________数据和__________数据。 11.样本数据的质量包括四个方面__________、__________、__________、__________。 12.模型参数的估计包括__________、__________和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是__________检验、__________检验、__________检验和__________检验。 14.计量经济模型的计量经济检验通常包括随机误差项的__________检验、__________检验、解释变量的__________检验。 15.计量经济学模型的应用可以概括为四个方面,即__________、__________、__________、__________。 16.结构分析所采用的主要方法是__________、__________和__________。 二、单选题: 1.计量经济学是一门()学科。 A.数学 B.经济
计量经济学-案例分析-第二章
第二章案例分析 一、研究的目的要求 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我们研究的对象是各地区居民消费的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2002年截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 从2002年《中国统计年鉴》中得到表2.5的数据: 表2.52002年中国各地区城市居民人均年消费支出和可支配收入
计量经济学教程(赵卫亚)课后答案第二章汇编
第二章 回归模型思考与练习参考答案 2.1参考答案 ⑴答:解释变量为确定型变量、互不相关(无多重共线性);随机误差项零的值、同方差、非自相关;解释变量与随机误差项不相关。 现实经济中,这些假定难以成立。要解决这些问题就得对古典回归理论做进一步发展,这就产生了现代回归理论。 ⑵答:总体方差是总体回归模型中随机误差项i ε的方差;参数估计误差则属于样本回归模型中的概念,通常是指参数估计的均方误。参数估计的均方误为 MSE ()i i b b ?=E ()2?i i b b -=D ()i b ?=()[]ii u 12-'χχσ 即根据参数估计的无偏线,参数估计的均方误与其方差相等。而参数估计的方差又源于总体方差。因此,参数估计误差是总体方差的表现,总体方差是参数估计误差的根源。 ⑶答:总体回归模型 ()i i i x y E y ε+= 样本回归模型i i i e y y +=? i ε是因变量y 的个别值i y 与因变量y 对i x 的总体回归函数值() i x y E 的偏差;i e 为因变量y 的观测值i y 与因变量y 的样本回归函数值i y ?的偏差。 i e 在概念上类似于i ε,是对i ε的估计。 对于既定理论模型,OLS 法能使模型估计的拟和误差达最小。但或许我们可选择更理想的理论模型,从而进一步提高模型对数据的拟和程度。 ⑷答:2R 检验说明模型对样本数据的拟和程度;F 检验说明模型对总体经济关系的近似程度。 ()()()k k n R R k n Model Total k Model k m Error k Model F 111122--?-=---=--= 由02>??R F 可知,F 是2R 的单调增函数。对每一个临界值?F ,都可以找到一个2?R 与之对应,当22?>R R 时便有?>F F 。 ⑸答:在古典回归模型假定成立的条件下,OLS 估计是所有的线形无偏估计量中的有效估计量。 ⑹答:如果模型通过了F 检验,则表明模型中所有解释变量对被解释变量的影响显著。但这并不说明多个解释变量的影响都是显著的。建模开始时,常根据先验知识尽可能找出影响被解释变量的所有因素,这样就可能会选择不重要的因素作为解释变量。对单个解释变量的显著性检验可以剔除这些不重要的影响因素。 ⑺答:考虑两个经济变量y 与x ,及一组观测值(){},,2,1,,n i y x i i =。
计量经济学例题
计量经济学例题The final revision was on November 23, 2020
一、单项选择题 4.横截面数据是指(A )。 A .同一时点上不同统计单位相同统计指标组成的数据 B .同一时点上相同统计单位相同统计指标组成的数据 C .同一时点上相同统计单位不同统计指标组成的数据 D .同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C )。 A .时期数据 B .混合数据 C .时间序列数据 D .横截面数 据 9.下面属于横截面数据的是( D )。 A .1991-2003年各年某地区20个乡镇企业的平均工业产值 B .1991-2003年各年某地区20个乡镇企业各镇的工业产值 C .某年某地区20个乡镇工业产值的合计数 D .某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A .设定理论模型→收集样本资料→估计模型参数→检验模型 B .设定模型→估计参数→检验模型→应用模型 C .个体设计→总体估计→估计模型→应用模型 D .确定模型导向→确定变量及方程式→估计模型→应用模型 13.同一统计指标按时间顺序记录的数据列称为( B )。 A .横截面数据 B .时间序列数据 C .修匀数据 D .原 始数据 14.计量经济模型的基本应用领域有( A )。 A .结构分析、经济预测、政策评价 B .弹性分析、乘数分析、政策模拟 C .消费需求分析、生产技术分析、 D .季度分析、年度分析、中长期分析 18.表示x 和y 之间真实线性关系的是( C )。 A .01???t t Y X ββ=+ B .01()t t E Y X ββ=+ C .01t t t Y X u ββ=++ D .01t t Y X ββ=+ 19.参数β的估计量?β 具备有效性是指( B )。 A .?var ()=0β B .?var ()β为最小 C .?()0ββ-= D .?()β β-为最小 25.对回归模型i 01i i Y X u ββ+=+进行检验时,通常假定i u 服从( C )。 A .2i N 0) σ(, B . t(n-2) C .2N 0)σ(, D .t(n) 26.以Y 表示实际观测值,?Y 表示回归估计值,则普通最小二乘法估计参数的准则是使
第二章习题及答案-计量经济学
第二章 简单线性回归模型 一、单项选择题(每题2分): 1、回归分析中定义的( )。 A 、解释变量和被解释变量都是随机变量 B 、解释变量为非随机变量,被解释变量为随机变量 C 、解释变量和被解释变量都为非随机变量 D 、解释变量为随机变量,被解释变量为非随机变量 2、最小二乘准则是指使( )达到最小值的原则确定样本回归方程。 A 、1 ?()n t t t Y Y =-∑ B 、1?n t t t Y Y = -∑ C 、?max t t Y Y - D 、21 ?()n t t t Y Y =-∑ 3、下图中“{”所指的距离是( )。 A 、随机误差项 B 、残差 C 、i Y 的离差 D 、?i Y 的离差 4、参数估计量?β是i Y 的线性函数称为参数估计量具有( )的性质。 A 、线性 B 、无偏性 C 、有效性 D 、一致性 5、参数β的估计量β? 具备最佳性是指( )。 A 、0)?(=βVar B 、)? (βVar 为最小 C 、0?=-ββ D 、)? (ββ-为最小 6、反映由模型中解释变量所解释的那部分离差大小的是( )。 A 、总体平方和 B 、回归平方和 C 、残差平方和 D 、样本平方和 7、总体平方和TSS 、残差平方和RSS 与回归平方和ESS 三者的关系是( )。 X 1?β+ i Y
A 、RSS=TSS+ESS B 、TSS=RSS+ESS C 、ESS=RSS-TSS D 、ESS=TSS+RSS 8、下面哪一个必定是错误的( )。 A 、 i i X Y 2.030? += ,8.0=XY r B 、 i i X Y 5.175?+-= ,91.0=XY r C 、 i i X Y 1.25? -=,78.0=XY r D 、 i i X Y 5.312?--=,96.0-=XY r 9、产量(X ,台)与单位产品成本(Y ,元/台)之间的回归方程为?356 1.5Y X =-,这说明( )。 A 、产量每增加一台,单位产品成本增加356元 B 、产量每增加一台,单位产品成本减少1.5元 C 、产量每增加一台,单位产品成本平均增加356元 D 、产量每增加一台,单位产品成本平均减少1.5元 10、回归模型i i i X Y μββ++=10,i = 1,…,n 中,总体方差未知,检验 010=β:H 时,所用的检验统计量1 ? 1 1?βββS -服从( )。 A 、)(22 -n χ B 、)(1-n t C 、)(12-n χ D 、)(2-n t 11、对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值的( )。 A 、i C (消费)i I 8.0500+=(收入) B 、di Q (商品需求)i I 8.010+=(收入)i P 9.0+(价格) C 、si Q (商品供给)i P 75.020+=(价格) D 、i Y (产出量)6.065.0i K =(资本)4 .0i L (劳动) 12、进行相关分析时,假定相关的两个变量( )。 A 、都是随机变量 B 、都不是随机变量 C 、一个是随机变量,一个不是随机变量 D 、随机或非随机都可以 13、假设用OLS 法得到的样本回归直线为i i i e X Y ++=2 1 ??ββ ,以下说法不正确的是( )。 A 、∑=0i e B 、),(Y X 一定在回归直线上 C 、Y Y =? D 、0),(≠i i e X COV 14、对样本的相关系数γ,以下结论错误的是( )。 A 、γ越接近0,X 和Y 之间的线性相关程度越高
计量经济学课后习题答案
计量经济学课后习题答案
业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。 ⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、 预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒等关系。 三、简答题 ⒈什么是计量经济学?它与统计学的关系是怎样的? 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与
计量经济学题库及答案
计量经济学题库(超完整版)及答案 一、单项选择题(每小题1分) 1。计量经济学就是下列哪门学科得分支学科(C ). A.统计学B 。数学C 。经济学D.数理统计学 2.计量经济学成为一门独立学科得标志就是(B )。 A .1930年世界计量经济学会成立 B .1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D 。1926年计量经济学(Economics )一词构造出来 3.外生变量与滞后变量统称为(D )。 A。控制变量B .解释变量C .被解释变量 D 。前定变量 4.横截面数据就是指(A )。 A 。同一时点上不同统计单位相同统计指标组成得数据B.同一时点上相同统计单位相同统计指标组成得数据 C .同一时点上相同统计单位不同统计指标组成得数据 D .同一时点上不同统计单位不同统计指标组成得数据 5。同一统计指标,同一统计单位按时间顺序记录形成得数据列就是(C )。 A .时期数据 B .混合数据 C 。时间序列数据D.横截面数据 6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定得概率分布得随机变量,其数值受模型中其她变量影响得变量就是()。 A .内生变量B.外生变量 C 。滞后变量D 。前定变量 7。描述微观主体经济活动中得变量关系得计量经济模型就是(). A.微观计量经济模型B。宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型得被解释变量一定就是( )。 A 。控制变量B。政策变量C 。内生变量D .外生变量 9.下面属于横截面数据得就是()。 A .1991-2003年各年某地区20个乡镇企业得平均工业产值 B。1991-2003年各年某地区20个乡镇企业各镇得工业产值 C .某年某地区20个乡镇工业产值得合计数 D 。某年某地区20个乡镇各镇得工业产值10.经济计量分析工作得基本步骤就是()。 A 。设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C .个体设计→总体估计→估计模型→应用模型 D .确定模型导向→确定变量及方程式→估计模型→应用模型 11。将内生变量得前期值作解释变量,这样得变量称为(). A .虚拟变量 B 。控制变量C.政策变量 D 。滞后变量 12.()就是具有一定概率分布得随机变量,它得数值由模型本身决定。 A。外生变量B.内生变量C.前定变量D。滞后变量 13.同一统计指标按时间顺序记录得数据列称为(). A 。横截面数据 B 。时间序列数据 C 。修匀数据 D .原始数据 14.计量经济模型得基本应用领域有()。 A 。结构分析、经济预测、政策评价 B .弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D。季度分析、年度分析、中长期分析 15.变量之间得关系可以分为两大类,它们就是( ).
安徽财经大学计量经济学 第二章练习题及参考解答
第二章练习题及参考解答 2.1 为研究中国的货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相互依存关系,分析表中1990年—2007年中国货币供应量(M2)和国内生产总值(GDP )的有关数据: 表2.9 1990年—2007年中国货币供应量和国内生产总值(单位:亿元) 资料来源:中国统计年鉴2008,中国统计出版社 对货币供应量与国内生产总值作相关分析,并说明相关分析结果的经济意义。 练习题2.1 参考解答: 计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为: 计算方法: XY n X Y X Y r -= 或 ,()()X Y X X Y Y r --= 计算结果: M2 GDP M2 1 0.996426148646 GDP 0.996426148646 1 经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性
相关程度相当高。 2.2 为研究美国软饮料公司的广告费用X与销售数量Y的关系,分析七种主要品牌软饮料公司的有关数据 表2.10 美国软饮料公司广告费用与销售数量 资料来源:(美) Anderson D R等. 商务与经济统计.机械工业出版社.1998. 405 绘制美国软饮料公司广告费用与销售数量的相关图, 并计算相关系数,分析其相关程度。能否在此基础上建立回归模型作回归分析? 练习题2.2参考解答 美国软饮料公司的广告费用X与销售数量Y的散点图为 说明美国软饮料公司的广告费用X与销售数量Y正线性相关。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为 x 4036.147857.21y ?+= (96.9800)(1.3692) t= (-0.131765) (10.5200) 9568.02=R F=110.6699 S.E=92302.73 D.W=1.4389 经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。 2.3 为了研究深圳市地方预算内财政收入与国内生产总值的关系,得到以下数据: 表2.11 深圳市地方预算内财政收入与国内生产总值