基于混合模型的生物事件触发词检测
基于深层句法分析的生物事件触发词抽取

基于深层句法分析的生物事件触发词抽取王健;吴雨;林鸿飞;杨志豪【期刊名称】《计算机工程》【年(卷),期】2014(000)001【摘要】Due to the simplistic and shallow application mode, syntactic information can not effectively play a role in the trigger recognition phase of traditional biological event extraction methods based on semantic and syntactic information. This paper describes a trigger extraction method based on the deep syntactic analysis. To make more effective utilization of the deep syntactic information, a unique indirect application mode is adopted. Deep syntactic information is used for edge detection, and the result is merged into the trigger extraction phase. Experimental results on BioNLP 2009 and 2011 shared tasks data achieve F-scores of 68.8%and 67.3%, which shows that the method has a good performance on biomedical event trigger extraction.%传统利用语义和句法信息进行生物事件抽取的方法,在触发词抽取阶段句法信息运用形式单一笼统,不能有效发挥作用。
开放域事件触发词抽取技术研究

开放域事件触发词抽取 技术研究
苏 晓丹 ,周 刚 1 , 2 ,陈海 勇 ,丁 宣 宣
( 1 . 解放 军信息工程大学 ,河南 郑州 4 5 0 0 0 1 ; 2 . 数学 工程 与先进计算 国家重点实验室 ,河南 郑 州 4 5 0 0 0 1 )
摘 要 :开放 域事件定义与传统事件 定义不 同,主要 以任意领域 的事件 触发词为核 心,并 包括 与 其 关联 的 时 间、 地 点 、人 物 、数 量 等 多种 元 素 构 成 的 结构 化 数 据 ,是 不 可预 测 的 。在 开放 域o n - s p e e d a n d s t r o n g r e p r e s e n t a t i o n a b i l i t y . An d h o w e v e r t h e r e a r e a l s o s o me s h o r t c o mi n g s i n c l u d i n g
词 抽取 中 ,提 出 了一种 基 于规 则和二 值 分 类相 结合 的混合 模 型 方法 ( 简称 1 L — T wo模 型 ),规 则 方
法需人工构建规则 ,具有抽取速度快、表征能力强的优点 ,但也存在规则不完备、过分依赖 句法 分析 的 缺 点 。二值 分类 法 的训 练过 程 虽然 比较 繁 琐 ,但 抽取 的 准确 率 高且 受 句法 分 析影 响 小 ,故
Ex t r a c t i o n o f Op e n - Do ma i n Ev e n t Tr i g g e r W o r d s
S U Xi a o — d a n , ZHOU Ga ng , CHEN Ha i — y o n g , DI NG Xu a n — x u a n ,
基于BERT-CRF模型的中文事件检测方法研究

近年来,随着网络的持续普及,技术的不断发展,使用网络的用户越来越多,网络中的信息量随着用户频繁的交互行为的增加而增加,互联网成为传播大量信息的新媒介,由于信息多数是非结构化的,且一个领域的信息散布在浩瀚的信息海洋中,致使网络中的信息很难处理,因此快速从大量信息中提取有价值的信息显得越来越重要。
许多信息一般是以事件的形式存在,事件指的是由特定关键词触发的、包含一个或多个参与者参与的、特定类型的事情,事件抽取技术是从纯文本中提取人们关心的事件信息,并以结构化的形式展现出来[1],是构建特定领域的事件库以及建立知识图谱的基础。
事件抽取分为两个步骤,事件检测和元素抽取,事件检测指从一段文本中提取可以标志事件发生的触发词,包括事件触发词识别与事件触发词分类两部分。
元素抽取主要针对一句话中与触发词相关的元素进行抽取和角色匹配。
本文的重点是针对事件检测部分。
事件检测中的触发词是指直接引起事件发生的词语,一般触发词的词性为动词,也可能是表示动作或状态的名词。
事件检测任务面临着许多挑战,一是一句话中不仅只有一个事件,有多个事件就会有多个事件触发词。
例如,在句子1中有两个事件触发词,分别是“离”和“暗杀”,并且是两种不同的子事件类型“Transport”和“Attack”。
句子1:根据警方消息来源,法官与其子在上午交通基于BERT-CRF模型的中文事件检测方法研究田梓函,李欣中国人民公安大学信息网络安全学院,北京100038摘要:事件抽取是自然语言处理中信息抽取的关键任务之一。
事件检测是事件抽取的第一步,事件检测的目标是识别事件中的触发词并为其分类。
现有的中文事件检测存在由于分词造成的误差传递,导致触发词提取不准确。
将中文事件检测看作序列标注任务,提出一种基于预训练模型与条件随机场相结合的事件检测模型,采用BIO标注方法对数据进行标注,将训练数据通过预训练模型BERT得到基于远距离的动态字向量的触发词特征,通过条件随机场CRF对触发词进行分类。
两阶段问答范式的生物医学事件触发词检测

两阶段问答范式的生物医学事件触发词检测
行帅;熊玉洁;苏前敏;黄继汉
【期刊名称】《计算机工程与应用》
【年(卷),期】2024(60)10
【摘要】现有的生物医学事件触发词检测存在以下缺陷:保留了与触发词无关的冗余信息;忽略了实体与事件之间的潜在关联性;传统方法容易受到数据稀缺性的影响。
针对上述问题,提出了一种两阶段问答范式的生物医学事件触发词检测方法。
在事
件类型识别阶段,采用基于句法距离的注意力捕获更有意义的上下文特征,排除无关
信息的干扰;为了有效利用实体中的潜在特征,采用全局统计的单词-实体-事件共现
特征,指导事件类型感知注意力挖掘词与事件之间的强关联性。
在触发词定位阶段,
根据识别出的事件类型,制定问题回答该事件对应的触发词索引,从而利用丰富的问
答数据库实现数据增强。
在MLEE语料库上的结果表明,两阶段问答范式、句法距
离和事件类型感知注意力都有效地提升了模型性能,所提出的模型取得了81.39%的F1分数,并在多个事件类型上的详细结果均优于其他基线模型。
【总页数】11页(P121-131)
【作者】行帅;熊玉洁;苏前敏;黄继汉
【作者单位】上海工程技术大学电子电气工程学院;上海中医药大学药物临床研究
中心
【正文语种】中文
【中图分类】TP391.1
【相关文献】
1.生物医学事件触发词识别研究
2.基于混合模型的生物事件触发词检测
3.“事态触发词”内涵及汉语事件表述系统——以突发事件触发词为例
4.一种非监督的事件触发词检测和分类方法
5.基于SVM的生物医学事件触发词识别研究
因版权原因,仅展示原文概要,查看原文内容请购买。
化工事故案例关键信息抽取研究

化工事故案例关键信息抽取研究荆思凤;熊刚;刘希未;宫晓燕;胡斌【摘要】针对当前大部分化工事故案例因以电子文档形式存储而不利于人们对案例信息利用的问题,提出了一种化工事故案例关键信息抽取方法.该方法利用中国科学院计算所ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)系统对化工案例文本进行中文分词和词性标注,利用化工案例信息表述特点及句子语法信息制定关键信息识别规则,利用visual studio平台编制测试代码,对收集到的2000年至今的100个化工事故案例进行测试评价,结果显示该方法能抽取出化工事故案例发生的时间、地域、化工设备及事故类型等信息.该工作为提高化工事故案例信息的利用率作了有效的探索与尝试.【期刊名称】《工业安全与环保》【年(卷),期】2019(045)008【总页数】5页(P61-65)【关键词】化工事故案例;中文文本信息抽取;基于规则方法;化工安全;知识自动化【作者】荆思凤;熊刚;刘希未;宫晓燕;胡斌【作者单位】中国科学院自动化研究所复杂系统管理与控制国家重点实验室北京100190;青岛智能产业技术研究院智慧教育研究所山东青岛266109;中国科学院自动化研究所复杂系统管理与控制国家重点实验室北京100190;中国科学院云计算中心广东东莞523808;中国科学院自动化研究所复杂系统管理与控制国家重点实验室北京100190;青岛智能产业技术研究院智慧教育研究所山东青岛266109;中国科学院云计算中心广东东莞523808;中国科学院自动化研究所复杂系统管理与控制国家重点实验室北京100190;青岛智能产业技术研究院智慧教育研究所山东青岛266109;中国科学院自动化研究所复杂系统管理与控制国家重点实验室北京100190;中国科学院云计算中心广东东莞523808【正文语种】中文0 引言化工事故往往会引起较大的人员伤亡、财产损失和环境破坏。
哈工大知识图谱(KnowledgeGraph)课程概述
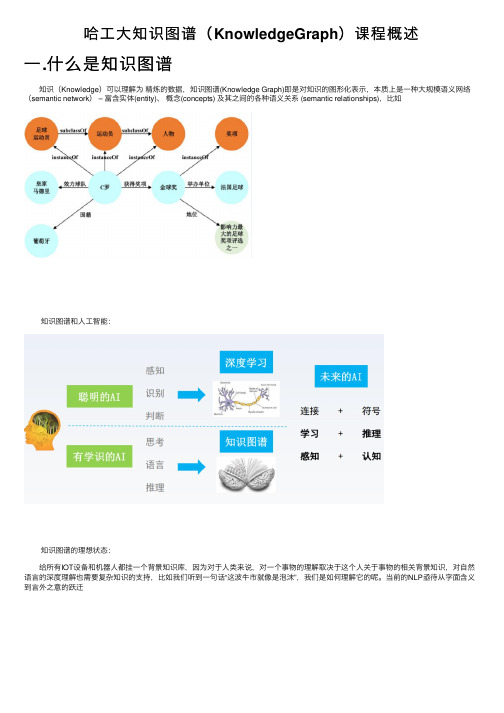
1.知 识 图 谱 中 的 概 念
实体 (entity):现实世界中可区分、可识别的事物或概念。 ➢ 客观对象:人物、地点、机构 ➢ 抽象事件:电影、奖项、赛事 关系 (relation):实体和实体之间的语义关联。 事实 (fact):陈述两个实体之间关系的断言,通常表示为 (head entity, relation, tail entity) 三元组形式。
四 .实体识别
1.信 息 抽 取
概念:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息, 并形成结构化数据输出的文本处理技术
主要任务:实体识别与抽取,关系抽取,时间抽取,实体消歧
2.命 名 实 体 识 别 ( Named Entity Recognition, 简 称 NER)
定义:狭义地讲,命名实体指现实世界中具体或抽象的实体 , 如人(张三)、机构(哈尔滨工业大学)、地点等,通常用唯一的标志符(专 有名称)表示。
Ontology(本体):通过对概念的严格定义和概念与概念之间的关系来确定概念的精确含义,表示共同认可的、可共享的知识,对于 ontology来说,author,creator和writer是同一个 概念,而doctor在大学和医院分别表示的是两个概念。因 此在语义网中,ontology具有非常 重要的地位,是解决语义层次上Web信息共享和交换的基础。简单理解就是某个领域关于自身和相关关系的描述
2.知 识 图 谱 的 特 性
知识图谱不太专注于对知识框架的定义,而专注于如何以工程的方式,从文本中自动抽取或依靠众包的方式获取并 组建广泛的、具有平铺结 构的知识实例,最后再要求使用 它的方式具有容错、模糊匹配等机制。 知识图谱的真正魅力在于其图结构,可以在知识图谱上运行搜索、 随机游走、网络流等大规模图算法,使知识图谱与图论、概率图等碰撞出火花。
基于混合模型的事件触发词抽取

基于混合模型的事件触发词抽取
杨昊;赵刚;王兴芬
【期刊名称】《计算机工程与科学》
【年(卷),期】2023(45)1
【摘要】事件结构性语法特征与事件语义特征各有优势,二者融合利于准确表征事件触发词,进而有利于完成事件触发词抽取任务。
现有的基于特征、基于结构及基于神经网络模型等的抽取方法仅能捕捉事件的部分特征,不能够准确表征事件触发词。
为解决上述问题,提出一种融合了事件结构性语法特征和事件语义特征的混合模型,完成事件触发词抽取任务。
首先,在初始化向量模型中融入句子的依存句法信息,使初始向量中包含事件结构性语法特征;然后,将初始向量依次传入神经网络模型中的CNN和BiGRU-E-attention模型中,在捕获多维度事件语义特征的同时,完成事件结构性语法特征与事件语义特征的融合;最后,进行事件触发词的抽取。
在CEC 中文突发语料库上进行事件触发词位置识别和分类实验,该模型的F值较基准模型的分别提高了0.86%和4.07%;在ACE2005英文语料库上,该模型的F值较基准模型的分别提高了1.4%和1.5%。
实验结果表明,混合模型在事件触发词抽取任务中取得了优异的效果。
【总页数】10页(P171-180)
【作者】杨昊;赵刚;王兴芬
【作者单位】北京信息科技大学信息管理学院
【正文语种】中文
【中图分类】TP391.1
【相关文献】
1.基于语义的中文事件触发词抽取联合模型
2.基于混合模型的生物事件触发词检测
3.基于预训练模型和特征融合的事件触发词抽取
4.基于CNN-BiGRU模型的事件触发词抽取方法
5.基于跨度回归的中文事件触发词抽取
因版权原因,仅展示原文概要,查看原文内容请购买。
基于混合模型的新闻事件要素提取方法

基于混合模型的新闻事件要素提取方法
YU Jin-Zhong;YANG Xian-Feng;CHEN Yan;LI Juan
【期刊名称】《计算机系统应用》
【年(卷),期】2018(027)012
【摘要】为了帮助读者从大量新闻报道信息中迅速地把握其主要内容,本文分析了事件要素对新闻主要内容的影响,结合新闻报道的基本原则和要求,提出了一种基于混合模型的事件要素提取方法.该方法首先对新闻数据中识别的实体进行加权,然后使用依存句法树分析实体在新闻事件中扮演的角色,并对关于要素的指代现象进行消解,最终融合频率及角色关系对实体加权的方法进行改进,有效地提取出新闻事件关联性较为重要的要素.实验结果表明,本文所述方法能够准确地提取出与新闻事件关联性较强的事件要素,提高了读者快速筛选新闻事件要素的效率.
【总页数】6页(P169-174)
【作者】YU Jin-Zhong;YANG Xian-Feng;CHEN Yan;LI Juan
【作者单位】
【正文语种】中文
【相关文献】
1.基于进化神经网络模型的网络安全态势要素提取方法研究 [J], 易飞
2.基于PageRank的产品方案设计SysML模型关键要素提取方法 [J], 蒋丹鼎;赵颖
3.基于实景三维模型地形图要素提取方法及应用检验 [J], 罗浩;冯艺;邵茂亮;严晓玲
4.基于K-Means和高斯混合模型的云肩色彩提取方法对比 [J], 陈思燕;方丽英
5.基于K-Means和高斯混合模型的云肩色彩提取方法对比 [J], 陈思燕;方丽英因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于混合模型的生物事件触发词检测李浩瑞;王健;林鸿飞;杨志豪;张益嘉【摘要】语义歧义增加了生物事件触发词检测的难度,为了解决语义歧义带来的困难,提高生物事件触发词检测的性能,该文提出了一种基于丰富特征和组合不同类型学习器的混合模型.该方法通过组合支持向量机(SVM)分类器和随机森林(Random Forest)分类器,利用丰富的特征进行触发词检测,从而为每一个待检测词分配一个事件类型,达到检测触发词的目的.实验是在BioNLP2009共享任务提供的数据集上进行的,实验结果表明该方法有效可行.【期刊名称】《中文信息学报》【年(卷),期】2016(030)001【总页数】7页(P36-42)【关键词】触发词;生物事件;歧义;丰富特征;组合学习器【作者】李浩瑞;王健;林鸿飞;杨志豪;张益嘉【作者单位】大连理工大学计算机科学与技术学院,辽宁大连116024;大连理工大学计算机科学与技术学院,辽宁大连116024;大连理工大学计算机科学与技术学院,辽宁大连116024;大连理工大学计算机科学与技术学院,辽宁大连116024;大连理工大学计算机科学与技术学院,辽宁大连116024【正文语种】中文【中图分类】TP391随着新的生物医学文献的爆炸性增长,越来越多的关系抽取方法得以提出,用来从生物医学文献中抽取有用的信息。
近几年,事件抽取以其有表现力的结构化呈现而流行,广泛地应用于系统生物学,涉及到从对通路的产生和标注提供支持到数据库自动产生母体数据和丰富数据库数据等领域。
生物医学事件与蛋白质-蛋白质交互关系(PPI)等二元关系不同,它包含了生物实体以及实体之间的交互关系。
这些生物事件能够完整地代表原始关系的生物医学意义,所以从文本中自动地识别生物事件变得非常有意义。
生物医学事件抽取就是一个在医学研究文章中自动检测分子交互关系描述的过程[1]。
它的目的是从非结构化的文本中抽取关于预先定义事件类型的结构化信息。
生物医学事件抽取在BioNLP2009共享任务(以下称BioNLP’09)之后开始在领域内流行。
在BioNLP’09结束之后出现了许多事件抽取系统。
一般来说这些系统可以分为两类:基于机器学习的系统和基于规则的系统。
在BioNLP’09中性能最好的Uturku系统是泛化的系统,并采用了支持向量机(SVM)来进行事件抽取[2-3]。
Uturku系统把事件抽取的整个过程分成了触发词检测和事件元素检测两个部分。
该系统的特点是严重依赖高效、先进的机器学习技术和一系列从每个句子完全依存分析中产生的特征[4]。
在BioNLP’09的任务1中排名第三的ConcordU 系统是本次评测中最好的基于规则的系统[2]。
另外,在BioNLP2011共享任务的四个大任务中获得三个任务性能第一的FAUST系统探索使用了模型的组合,它使用的基础模型是Umass对偶分解模型和斯坦福事件分析器。
该系统的先进之处在于它使用了斯坦福事件分析系统的预测结果,并通过与对偶分解模型进行组合来求得最终的结果[5]。
目前大多数的事件抽取系统关注的是整个事件抽取的过程,将触发词检测作为一个单独问题进行研究的比较少见。
检测生物事件触发词是事件抽取过程中一个非常重要的步骤,触发词检测的性能对它之后的步骤的性能有很大的影响,它在事件抽取中起到了至关重要的作用。
David等人提出了一种使用向量空间模型(VSM)和条件随机场(CRF)相结合的方法,建立触发词检测的语义消歧系统(WSD)[6]。
该方法是将每个出现的歧义词表示成一个向量,向量的每一维代表了一个特征的出现或者缺失,在该系统的训练过程中,系统为每个词类型的每个含义产生一个单一的质心向量。
该系统在BioNLP’09的数据集上进行了实验,并取得了较好的效果。
事件抽取通过识别文本中触发词和参与的实体来发现触发词和实体之间的关系。
作为整个事件抽取流程中的基础步骤,事件触发词检测的性能对整个事件抽取过程的性能有着至关重要的影响。
在触发词检测过程当中,语义歧义使得触发词检测有一定的难度。
如下面的例1~例3中,单词“expression”在例1和例3中是触发词,而在例2中不是触发词。
而是触发词的情况下,该单词在例1和例3标识的事件类型也是不同的类型。
因此,很难判定诸如“expression”这类单词是否是触发词或者在是触发词的情况下它们标识的触发词的类型。
例1 It activates Prot18 gene expression in T lymphocytes.例2 ......, the expression was enhanced at 30 min.例3 the expression of c-fos mRNA was suppressed at 30 min受到之前提及系统的启发,特别是FAUST系统的原理,本文利用组合学习器的方法,使用从原始句子和句子依存分析树中产生的特征来进行触发词检测。
在实验的过程中,除了使用一些常用的文本特征,如词特征,还从依存分析树中发掘了很多特征。
把这些特征应用到两个判别原则完全不同的学习器中,即支持向量机(SVM)和随机森林(Random Forest)。
最终,根据每个学习器单独预测性能的好坏指派权值,对两个分类器输出的结果进行线性加权组合得到最终的输出结果。
实验结果表明,组合学习器能够获得比单独使用任何一个学习器更好的效果。
2.1 依存句法分析器依存分析树是用来表示一个句子中词与词之间的语法关系。
依存分析器用来构建一个句子的依存关系树。
在依存分析树中每一个节点代表一个词,每一条边代表了两个词之间的关系。
本文使用的是GDep[7]依存分析器,图1中是句子“AML and Ets proteins regulate the I alphal germtine promoter.”的依存分析树。
2.2 相关学习器组合总是做出类似决策的学习器是毫无意义的[8]。
将决策原则不同的分类器进行组合,分类器在决策时可以进行互补。
本文采用了两个基础的分类器:一个是支持向量机,它是基于线性判别的决策理论;另一个是随机森林,它是基于决策树的决策理论。
这两个分类器在决策原理上是不相同的。
接下来简要介绍一下本文中使用的分类器和它们的决策原理。
2.2.1 支持向量机支持向量机是一种基于线性判别的方法,它使用Vapnik原则,即在解决实际问题之前总会把解决一个较为简单的问题作为第一步[9]。
支持向量机的目的是学习一个能够将训练集里的正例和负例分开的超平面。
超平面到任意一边离超平面最近点的距离标为间隔。
支持向量机的目的是找到能够使得间隔最大化的最优间隔超平面,同时又使得分类器的泛化误差最小。
假设有训练样本(xt,yt),xt是n维特征空间中的一个向量,yt 是类别标签-1代表负例,+1代表正例。
图2中超平面w*x +w0 = 0将训练样本正确的分离并且最大化超平面w*x +w0 = 1 和 w*x +w0 = -1之间的间隔。
超平面可以通过求解公式(1)而得到。
‖w‖2 s.t. yt (w*xt +w0)≥1∀通过引入拉格朗日因子α,超平面可以最终表示为公式(2)。
式(2)中的K(xt,x)被称为核函数。
经过计算,根据f(x)的符号给待预测点x分配相应的类别标签。
2.2.2 随机森林随机森林(简称RF)是一种使用了一组未修剪的决策树的分类算法。
每一棵分类树都是使用了数据的引导样例,并且在每一个数据分割中变量的候选集是整体变量的一个随机子集[10]。
随机森林使用两种方法来构建树:一种是装袋法,它是一种对于组合不稳定学习器比较有效的方法[11-12];另一种是随机变量选取法。
假设给定一组分类器C1(x), C2(x),..., Ck(x)和从随机向量的分布中随机抽取的训练集X,Y,定义间距函数为公式(3)。
此处I(x)是指标函数。
所谓间距,是用来衡量给一个样本X,Y投票时,投它是正确类票数平均数超过投它是其他类票数平均数的程度。
间距越大,学习器在分类时得到的结果就越可信。
在随机森林中,第k个分类器可以表示成另一种形式,即Ck(x) = C(X, Θk)。
对于大多数的树而言,随机森林遵循强大数定理并遵循如下的结构:随着树的数量增加,可以肯定的是对于所有的Θ序列,PE*收敛于H[13]。
其中H可表示为公式(4)。
通过描述可以看到随机森林的决策机制和之前选的第一个分类器(SVM)的决策机制是不同的。
除了决策机制,本文选用随机森林作为第二个学习器的原因是在分类任务中随机森林有非常优秀的性质。
主要有以下两点性质促使了本文的实验使用随机森林。
首先,使用强大数定律表明了随机森林是收敛的,所以过拟合不是问题;其次,是随机森林的泛化误差,泛化误差的形式为公式(5)。
此处X,Y标明了概率是在X,Y空间上的。
泛化误差的上限可以表示成两个参数的形式,这两个参数分别表示了每一个单独分类器的准确性和各分类器之间的依赖性。
3.1 相关特征本文使用一些常用的特征和一些从句子的依存分析树中发掘的特征。
主要包括下列几种特征。
词特征:词特征主要包含词本身以及由GDep产生的词干和这个词在句子中的词性。
词袋特征:词袋特征是指候选词周围的词,包括了候选词前边和后边的N个词。
考虑到特征的维数和特征的表现能力,本文将N设定为8。
依存分析特征:依存分析特征主要来自于GDep解析器的解析结果,包括了候选词的依存信息和候选词在依存分析树中的路径信息以及候选词在依存分析树中的父节点和子节点的信息。
N元特征:N元特征主要包括以候选词为中心的一个范围内的N元词组,主要是三元组和二元组。
这些N元特征丰富了词袋特征的表现[14-15]。
距离特征:距离特征用来衡量候选词和最近的蛋白质之间的距离。
触发词是和蛋白质紧密相关的,一个距离蛋白质近的候选词比一个距离蛋白质远的候选词更有可能是触发词。
本文定义的距离指的是在原始语句中候选词到最近蛋白质所包含的单词的个数(在距离统计时将蛋白质包含在内)。
统计发现,在BioNLP’09的训练集中大部分的触发词是靠近蛋白质的。
图3中表示的是在BioNLP’09的训练集中触发词和其距离最近的蛋白质的分布图,例如,有超过1 200个触发词与蛋白质相邻,距离定义为1,接近1 600个触发词与蛋白质距离是2。
依存路径特征:相同的候选词在一个句子里是触发词而在另一个句子里不是触发词。
经过研究,在例4和例5两个句子中,expression 在例4中是触发词而在例5中不是触发词。
例4 Prot24 can directly inhibit STAT-dependent early response gene expression induced by both IFNalpha and Prot25 in monocytes by suppressing the tyrosine phosphorylation of Prot23.例5 IL-10 preincubation resulted in the inhibition of gene expression for sev-eral IFN-induced genes...使用了依存分析器之后,在依存分析树中构建从蛋白质到根节点的路径。