编译原理课件1
【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集

【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集 近来复习编译原理,语法分析中的⾃上⽽下LL(1)分析法,需要构造求出⼀个⽂法的FIRST和FOLLOW集,然后构造分析表,利⽤分析表+⼀个栈来做⾃上⽽下的语法分析(递归下降/预测分析),可是这个FIRST集合FOLLOW集看得我头⼤。
教课书上的规则如下,⽤我理解的语⾔描述的:任意符号α的FIRST集求法:1. α为终结符,则把它⾃⾝加⼊FIRSRT(α)2. α为⾮终结符,则:(1)若存在产⽣式α->a...,则把a加⼊FIRST(α),其中a可以为ε(2)若存在⼀串⾮终结符Y1,Y2, ..., Yk-1,且它们的FIRST集都含空串,且有产⽣式α->Y1Y2...Yk...,那么把FIRST(Yk)-{ε}加⼊FIRST(α)。
如果k-1抵达产⽣式末尾,那么把ε加⼊FIRST(α) 注意(2)要连续进⾏,通俗地描述就是:沿途的Yi都能推出空串,则把这⼀路遇到的Yi的FIRST集都加进来,直到遇到第⼀个不能推出空串的Yk为⽌。
重复1,2步骤直⾄每个FIRST集都不再增⼤为⽌。
任意⾮终结符A的FOLLOW集求法:1. A为开始符号,则把#加⼊FOLLOW(A)2. 对于产⽣式A-->αBβ: (1)把FIRST(β)-{ε}加到FOLLOW(B) (2)若β为ε或者ε属于FIRST(β),则把FOLLOW(A)加到FOLLOW(B)重复1,2步骤直⾄每个FOLLOW集都不再增⼤为⽌。
⽼师和同学能很敏锐地求出来,⽽我只能按照规则,像程序⼀样⼀条条执⾏。
于是我把这个过程写成了程序,如下:数据元素的定义:1const int MAX_N = 20;//产⽣式体的最⼤长度2const char nullStr = '$';//空串的字⾯值3 typedef int Type;//符号类型45const Type NON = -1;//⾮法类型6const Type T = 0;//终结符7const Type N = 1;//⾮终结符8const Type NUL = 2;//空串910struct Production//产⽣式11 {12char head;13char* body;14 Production(){}15 Production(char h, char b[]){16 head = h;17 body = (char*)malloc(strlen(b)*sizeof(char));18 strcpy(body, b);19 }20bool operator<(const Production& p)const{//内部const则外部也为const21if(head == p.head) return body[0] < p.body[0];//注意此处只适⽤于LL(1)⽂法,即同⼀VN各候选的⾸符不能有相同的,否则这⾥的⼩于符号还要向前多看⼏个字符,就不是LL(1)⽂法了22return head < p.head;23 }24void print() const{//要加const25 printf("%c -- > %s\n", head, body);26 }27 };2829//以下⼏个集合可以再封装为⼀个⼤结构体--⽂法30set<Production> P;//产⽣式集31set<char> VN, VT;//⾮终结符号集,终结符号集32char S;//开始符号33 map<char, set<char> > FIRST;//FIRST集34 map<char, set<char> > FOLLOW;//FOLLOW集3536set<char>::iterator first;//全局共享的迭代器,其实觉得应该⽤局部变量37set<char>::iterator follow;38set<char>::iterator vn;39set<char>::iterator vt;40set<Production>::iterator p;4142 Type get_type(char alpha){//判读符号类型43if(alpha == '$') return NUL;//空串44else if(VT.find(alpha) != VT.end()) return T;//终结符45else if(VN.find(alpha) != VN.end()) return N;//⾮终结符46else return NON;//⾮法字符47 }主函数的流程很简单,从⽂件读⼊指定格式的⽂法,然后依次求⽂法的FIRST集、FOLLOW集1int main()2 {3 FREAD("grammar2.txt");//从⽂件读取⽂法4int numN = 0;5int numT = 0;6char c = '';7 S = getchar();//开始符号8 printf("%c", S);9 VN.insert(S);10 numN++;11while((c=getchar()) != '\n'){//读⼊⾮终结符12 printf("%c", c);13 VN.insert(c);14 numN++;15 }16 pn();17while((c=getchar()) != '\n'){//读⼊终结符18 printf("%c", c);19 VT.insert(c);20 numT++;21 }22 pn();23 REP(numN){//读⼊产⽣式24 c = getchar();25int n; RINT(n);26while(n--){27char body[MAX_N];28 scanf("%s", body);29 printf("%c --> %s\n", c, body);30 P.insert(Production(c, body));31 }32 getchar();33 }3435 get_first();//⽣成FIRST集36for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FIRST集37 printf("FIRST(%c) = { ", *vn);38for(first = FIRST[*vn].begin(); first != FIRST[*vn].end(); first++){39 printf("%c, ", *first);40 }41 printf("}\n");42 }4344 get_follow();//⽣成⾮终结符的FOLLOW集45for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FOLLOW集46 printf("FOLLOW(%c) = { ", *vn);47for(follow = FOLLOW[*vn].begin(); follow != FOLLOW[*vn].end(); follow++){48 printf("%c, ", *follow);49 }50 printf("}\n");51 }52return0;53 }主函数其中⽂法⽂件的数据格式为(按照平时做题的输⼊格式设计的):第⼀⾏:所有⾮终结符,⽆空格,第⼀个为开始符号;第⼆⾏:所有终结符,⽆空格;剩余⾏:每⾏描述了⼀个⾮终结符的所有产⽣式,第⼀个字符为产⽣式头(⾮终结符),后跟⼀个整数位候选式的个数n,之后是n个以空格分隔的字符串为产⽣式体。
第1章 概述-编译原理及实践教程(第3版)-黄贤英-清华大学出版社

《编译原理实践及应用》
1.1 程序设计语言及翻译程序
为什么要使用编译程序?
• 机器语言 (machine language)
C7 06 0000 0002
• 汇编语言 (assembler language)
MOV X , 2
为该语言编译程序能够识别的形式加入到标准源程序中。 在VC++6.0中,通过预处理后,将.c的源程序变为了.i的文 本文件。
《编译原理实践及应用》
编译
标准的C语言程序由编译程序翻译为对应于某个计算机 上的汇编语言程序。汇编语言是和机器语言一一对应的易于 阅读的文本形式的语言。编译的结果是某种机器上汇编语言 书写的程序。如在VC++6.0中,编译这一步将.i的文本文件 生成了.cod的文本文件,这就是汇编代码。有的编译器生成 .s或.asm后缀的文件。
• 解释程序:将高级程序设计语言写的源程序作为输入,
边解释边执行源程序本身,而不产生目标程序的翻译程序。
• 其他概念:
– 诊断编译程序 – 优化编译程序 – 交叉编译程序 – 可变目标编译程序
宿主机 目标机
《编译原理实践及应用》
对编译程序的一些说明
• 编译程序实质上是一个翻译程序,要注意等价变 换
• 高级语言 (high-level language)
X=2
《编译原理实践及应用》
语言层次和翻译程序大家族
翻译程序:能够将某种语言写的程序转换成另一
种语言的程序,而且后者与前者在逻辑上是等价的。
转换
高级语言层 高级语言1
程序
高级语言2
高级语言3 高级语言4
编译原理 语法分析(2)_ LL(1)分析法1
自底向上分析法
LR分析法的概念 LR分析法的概念 LR(0)项目族的构造 LR(0)项目族的构造 SLR分析法 SLR分析法 LALR分析法 LALR分析法
概述
功能:根据文法规则 文法规则, 源程序单词符号串 单词符号串中 功能:根据文法规则,从源程序单词符号串中
识别出语法成分,并进行语法检查。 识别出语法成分,并进行语法检查。
9
【例】文法G[E] 文法G[E] E→ E +T | T 消除左递归 T→ T * F | F F→(E)|i 请用自顶向下的方法分析是否字 分析表 符串i+i*i∈L(G[E])。 符串i+i*i∈L(G[E])。
E→TE’ E’→+TE’|ε T →FT’ T’→*FT’|ε F→(E)|i
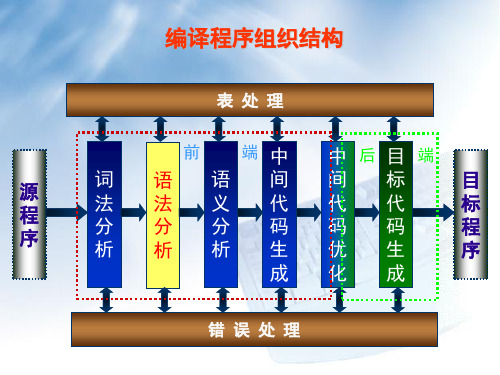
编译程序组织结构
表 处 理
前
端 中
源 程 序
词 法 分 析
语 法 分 析
语 义 分 析
间 代 码 生 成
中 后 目 端 间 标 代 代 码 码 优 生 化 成
目 标 程 序
错 误 处 理
第4章 语法分析
自顶向下分析法
递归子程序法(递归下降分析法) 递归子程序法(递归下降分析法) LL(1)分析法 LL(1)分析法
通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器
输入串
一、分析过程
#
此过程有三部分组成: 此过程有三部分组成: 分析表 总控程序) 执行程序 (总控程序) 分析栈) 符号栈 (分析栈)
编译原理

课程地位:编译理论与方法
计算机科学与技术中理论和实践相结合的最好典范 ACM 图灵奖,授予在计算机技术领域作出突出贡献的 科学家
程序设计语言、编译理论与方法约占1/3
程序的构造方法
1.1 什么是编译程序
编译程序与程序员的关系? 回顾程序执行的方式
解释型,如:BASIC 编译型,如:C 混合型,如:JAVA
1. 词法分析
任务: 对源程序字符流进行扫描和分解,识别出一 个个单词符号。 依循原则:构词规则 描述工具:有限自动机 例: Z := X + 6 * Y z : = x + 6 * y
可识别为下列单词(记号): 标识符z 赋值 := 标识符x 加号+ 数字6 乘号* 标识符y
2. 语法分析
任务:在词法分析的基础上,根据语言的语法规则把单词 符号串分解成各类语法单位。 依循的原则:语法规则 描述工具:上下文无关文法、语法树和抽象语法树 例(PASCAL): VAR Z,X,Y:real; E Z := X + 6* Y :=
PROCEDURE INCWAP(M,N:INTEGER); LABEL START; VAR K:INTEGER; BEGIN START: K:=M+1; M:=N+4; N:=K; END.
5
PROCEDURE INCWAP(M,N:INTEGER); LABEL START; VAR K:INTEGER; BEGIN START: K:=M+1; 表 0.1 符号名表 SNT M:=N+4; NAME INFORMATION N:=K; END. M 形式参数,整 型,值参数 N 形式参数,整 型,值参数 K 整型,变量
编译原理:第一章 引论

常见的表格:符号名表,常数表,标号表,入 口名表,过程引用表。 格式:
名字
信息
合肥工业大学 计算机与信息学院软件所
例: PASCAL程序段:
PROCEDURE INCWAP(M,N:INTEGER); LABEL START; VAR K:INTEGER; BEGIN START: K:=M+1; M:=N+4; N:=K; END.
合肥工业大学 计算机与信息学院软件所
5. 目标代码产生
任务: 把中间代码变换成特定机器上的目标 代码。 依赖于硬件系统结构和机器指令的含义 目标代码三种形式:
绝对指令代码: 可直接运行 可重新定位指令代码: 需要连接装配 汇编指令代码: 需要进行汇编
合肥工业大学 计算机与信息学院软件所
合肥工业大学 计算机与信息学院软件所
4. 优化
任务:对于前阶段产生的中间代码进行加工变 换,以期在最后阶段产生更高效的目标代码。 主要包括:公共子表达式提取、合并已知量、 删除无用语句、循环优化等。 依循的原则:程序的等价变换规则
FOR K:=1 TO 100 DO BEGIN X:=I+1; M := I + 10 * K; N := J + 10 * K; END
合肥工业大学 计算机与信息学院软件所
语法分析举例说明
C语言程序 Void jisuan() { int y,c,d; float x,a,b; x=a+b*50; y=c+)d*(x+b; } 现在我们对x=a+b*50; 进行语 法分析。
赋值语句的语法 规则: A V=E E T|E+T T F|T*F F V|(E)|C V 标识符 C 常数
编译原理-LR分析法 PPT

并用SLR(1)方法分析id*id+id∈L(G[E]) ?
G的拓广文法G[E]:
(0) E E
(4) TF
(1) EE+T
(5) F (E)
(2) ET
(6) F id
(3) TT*F
I0:E.E E.E+T E.T T.T*F T.F F.(E) F.id
Q = G的LR(0)项目集规范族, q0 = closure( {S.S} ), F = 所有含归约项目的有效项目集组成的集合, = go(I,X) )。
若将所有状态均视为终态,则识别活前缀的自动 机DFA M= ( = VTVN,
Q = G的LR(0)项目集规范族, q0 = closure({S.S}), F = Q, = go (I,X) )。
I8: (I4,A) AcA.
I9: (I5,B) BcB.
I10: (I4,d) Ad.
I11: (I3,d) Bd.
识别文法 活前缀的DFA
c
a
S.S
start S.aA
S
S.bB
I0
b
c
Ac.A A.cA A.d
I4 c
Sa.A A.cA A.d
I2
Sb.B B.cB B.d
J ={A X . | A . X I }
称函数go(I, X)为转移函数。
项目A X . 称为项目A . X后继。
二、识别句柄和活前缀的自动机
若文法G = ( VT, VN, S, P),则识别G的句柄的自动 机为DFA M = ( = VTVN,
B 是产生式,则项目 B . 对活前缀 = 1 也是 有效的。
编译原理语法分析(1)
例如, 考虑句子 i+i*i 按文法G[E]的推导 最左推导: EE+Ei+Ei+E*E i+i*E i+i*i 最右推导: EE+EE+E*EE+E*i E+i*ii+i*i 注意: 推导过程不唯一, 通常只考虑最左 推导或最右推导。 最右推导又称为规范推导。 规范推导的逆过程称为规范归约。
+ 。 * 意味着或 = , 或 即1 n 1 n 1 n
例如,考虑算术表达式文法G[E]: E→E+E∣E*E∣(E)│i 非终结符E代表一类算术表达式, 从E出发可进行一系列推导, 表达式 i+i*i 的推导如下: E E+E E+E*E E+E*i E+i*i i+i*I 注意: 在每一步推 导中,只能对其中一个 非终结符用其对应的产生式右部的 一个候选式来替换。
文法可表示为 VN为非空非终结符集,且VT∩VN=Φ; (3) S为文法开始符, S∈VN; (4)ξ是产生式的非空有限集, 其中每个 产生式(规则)记作 → 或 ::= 左部∈(VT∪VN)+至少含一非终结符, 右部∈(VT∪VN)*。
B
3.1.3 正规式与上下文无关文法 1. 正规式到上下文无关文法的转换 由正规式构造CFG的一种方法: (1)构造正规式的NFA; (2)若0为初始状态, 则A0为开始符; (3)若存在映射关系f(i,a)=j, 则定义产生式Ai →aAj; (4)若存在映射关系f(i,ε)=j, 则定义产生式Ai →Aj; (5) 若i为终态, 则定义产生式Ai →ε。
产生式 (也称产生式规则或规则) 是 定义语法实体的一种书写规则。一个语 法实体的相关规则可能不止一个, 如: P→1, P→2 , P→n 相同左部的产生式可合并为一个: P→ 1| 2|„| n 其中, i(i=1,2,„,n)称为P的候选式。
编译原理第6章_1
STACK REMAINING INPUT
1
(int + int)#
2(
int + int)#
3 (int
+ int)#
4 (T
+ int)#
5 (E
+ int)#
6 (E +
int)#
7 (E + int
)#
8 (E + T
)#
9 (E
)#
10 (E)
#
11 T
#
12 E
#
13 S
#
PARSER ACTION Shift Shift Reduce: T –> int Reduce: E –> T Shift Shift Reduce: T –> int Reduce: E –> E + T Shift Reduce: T –> (E) Reduce: E –> T Reduce: S –> E
的左部而得到的
文法要求
shift-reduce or reduce-reduce 冲突(conflicts)
分析程序不能决定是shift 还是 reduce 或者分析程序归约时有多个产生式可选
例子 (dangling else) : S –> if E then S | if E then S else S
LR分析算法
then begin pop || 项 令当前栈顶状态为S’ push GOTO[S’, A]和A(进栈)
end else if ACTION[s,a]=acc
then return (成功) else error end
编译原理-清华大学-第10章1-代码优化
(1)P:=0 (2)I:=0 (4)T2:=addr(A) (7)T5:=addr(B) (3)T1:=0
(5)T3:=T2[T1] (6)T4:=T1 (8)T6:=T5[T4] (9)T7:=T3*T6 (10)P:=P+T7 (11)I:=I+1 (3‘)T1:=T1+4 (12)if I<=20 goto(5)
2、代码外提
目的:减少循环中代码总数。 方法:把循环不变运算,即其结果独立
于循环执行次数的表达式提到循环的前 面,使之只在循环外计算一次。
(1)P:=0 (2)I:=0
(3)T1:=4*I (4)T2:=addr(A) (5)T3:=T2[T1] (6)T4:=T1 (7)T5:=addr(B) (8)T6:=T5[T4] (9)T7:=T3*T6 (10)P:=P+T7 (11)I:=I+1 (12)if I&l经过变换循环的控制条件后,有些变 量不被引用,可以从循环中删除。
(1)P:=0 (2)I:=0 (4)T2:=addr(A) (7)T5:=addr(B) (3)T1:=4*I
(5)T3:=T2[T1] (6)T4:=T1 (8)T6:=T5[T4] (9)T7:=T3*T6 (10)P:=P+T7 (11)I:=I+1 (3’)T1:=T1+4 (12)if I<=20
2)在运行基本块时,只能从其入口进入, 从出口退出。
2、划分基本块算法
(1)求出各基本块的入口语句 1)程序的第一个语句 ; 2)能由条件转移语句和无条件转移语句转
移到达的语句; 3)紧跟在条件转移语句后面的语句。
(2) 对以上求出的每个入口语句,确定其所 属的基本块。它是由该入口语句到下一入 口语句(不包括该入口语句) 之间的语句序 列组成的。
编译原理ch5 自下而上语法分析-part1
2013-7-6
例:设文法G(S): (1) S aAcBe (2) A b (3) A Ab (4) B d 试对abbcde进行“移进-归约”分析。
e B d B b c c A b S a a
2013-7-6
abbcde bbcde bcde cde de e
6
步骤: 1 动作: 进a
可用句柄来对句子进行归约 句型 归约规则 abbcde (2) A b aAbcde (3) A Ab aAcde (4) B d aAcBe (1) S aAcBe S
2013-7-6
12
定义:假定是文法G的一个句子,我们称序列n, n-1, ,0 是的一个规范归约,如果此序列满 足: 1、 n= 2、 0为文法的开始符号,即0=S 3、 对任何i,0 i n, i-1是从i经把句柄替换 成为相应产生式左部符号而得到的。
1. 若有产生式P→… a或P→ … aQ,则a LASTVT(P); 2. 若a LASTVT(Q),且有产生式P→… Q ,则a LASTVT(P)。
2013-7-6
25
优先关系表的构造
检查G的每个候选式,若有p→…aQb…或 p→…ab…的产生式,则置a b 若G中有形如…aP…的候选式,则对于所有的 b∈FIRSTVT(P),有a <·b 若G中有形如…Pb…的候选式,则对于所有的 a∈ LASTVT(P),有a ·> b
2013-7-6
18
■ 例:考虑文法G(E):E T | E+T T F | T*F F (E) | i 输入串为i1*i2+i3 ,分析步骤为:
步骤 9 10 11 12 13 14 符号栈 #E+ #E+i3 #E+F #E+T #E #E 输入串 i3# # # # # # 动作 进 进 归,用F→i 归,用T→F 归,用E→E+T 接受
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.4 编译程序的组织
1、遍(Pass) 、 2、前端,后端 、前端,
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
本章要点
要求理解编译程序,解释程序和遍的基本概念; 要求理解编译程序,解释程序和遍的基本概念; 掌握编译过程各阶段的任务和编译程序逻辑结构 及其各部分的基本功能。 及其各部分的基本功能。
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
《编译原理》课程基本信息 编译原理》
(一)课程名称 :编译原理 学时, (二)学时学分 :周7学时,4学分 高等数学、C (PASCAL)、离散数学、 汇编语言、 (三)预修课程 :高等数学、C (PASCAL)、离散数学、 汇编语言、 数据结构 后继课程 :形式语言与自动机等 编译原理》 (四)使用教材 :《编译原理》(第2版) 主编:张素琴、吕映芝) (清华大学出版 主编:张素琴、吕映芝)
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
1.2 编译过程概述
1、编译程序结构 、 2、编译过程 、
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
1.3 编译程序的逻辑结构
1、编译逻辑过程 、 2、编译程序各阶段任务 、
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
掌握编译程序的结构
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
教学重点
Transaction Data
解释程序
编译程序
Customer Profile
编译的过程
编译概念
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
教学难点
英语翻译成汉语进行比较
编译的5个阶段 编译的 个阶段
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
主要内容
1.1 什么是编译程序 1.2 编译过程概述 1.3 编译程序的逻辑结构 1.4 编译程序的组织
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
1.1 什么是编译程序
1、编译程序在计算机系统中的作用 、 2、程序设计语言的转换 、 翻译(Translation) 翻译 编译(Compile) 编译 解释(Interpretion) 解释 3、编译程序 、
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
本章主要阅读文献资料
Kenneth C.Louden 著:《Compiler Construction Principle and Pratice 》,机 械工业出版社。 械工业出版社。 蒋立源著: 编译原理》 ),西北工 蒋立源著:《 编译原理》(第2版),西北工 业大学出版社。 业大学出版社。 陈火旺著: 程序设计语言编译程序》 ),国 陈火旺著:《程序设计语言编译程序》(第2 版),国 防工业出版社。 防工业出版社。
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
教学参考书
1.Kenneth C.Louden 著 :《Compiler Construction Principle and Pratice》机械工业出版社。 Pratice》机械工业出版社。 编译原理》 ),西北工业大学出版社 西北工业大学出版社。 2.蒋立源著 :《 编译原理》(第2版),西北工业大学出版社。 程序设计语言编译程序》 ),国防工业出版 3.陈火旺著 :《程序设计语言编译程序》(第3版),国防工业出版 社,2001年1月版。 ,2001年 月版。 编译原理》 清华大学出版社,1998 月版。 ,1998年 4. 吕映芝著 :《 编译原理》,清华大学出版社,1998年1月版。 编译原理和技术》 ),中国科学技术大学出 5. 陈意云著 :《 编译原理和技术》(第2版),中国科学技术大学出 版社,1998年12月版。 版社,1998年12月版。 月版 编译原理课程辅导与习题解析》 ),人民邮 6. 胡元义著 :《 编译原理课程辅导与习题解析》(第1版),人民邮 电出版社,2002年 月版。 电出版社,2002年7月版。
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
讨论题
1.请画出编译程序的总框。如果你是一个编译 .请画出编译程序的总框。
程序的总设计师,应当考虑哪些问题? 程序的总设计师,应当考虑哪些问题? 对下列错误信息, 2.对下列错误信息,请指出可能是编译的那个 阶段报告的? 阶段报告的? else没有匹配的 没有匹配的if (1)else没有匹配的if (2)数组下标越界 (3)使用的函数没有定义 (4)在书中出现了非数字字符 3.试分析编译程序是否分遍应考虑的因素及多 边扫描编译程序的优缺点。 边扫描编译程序的优缺点。
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
练习题
1.解释下列术语: 解释下列术语: 编译程序,源程序,目标程序,编译程序的前端, 编译程序,源程序,目标程序,编译程序的前端, 后端和遍 2.编译程序有哪些主要构成成分?各自的主要 编译程序有哪些主要构成成分? 功能是什么? 功能是什么? 3.什么是解释程序?它与编译程序的主要不同是什么? 什么是解释程序?它与编译程序的主要不同是什么?
课 程 名 称 : 编译原理 主讲教师: 主讲教师:徐艳群
主讲教师: 主讲教师:徐艳群
课 程 名 称 : 编译原理
主教师: 主讲教师:徐艳群
第一章
教学时数 教学目的与要求 教学重点 教学难点 本章主要阅读文献资料
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
教学学时
2 学时
课 程 名 称 : 编译原理
主讲教师: 主讲教师:徐艳群
教学目的与要求
目的与要求
了解编译的过程
教师教案之
编 译 原 理
主讲教师:徐艳群
教
师
教
案
2007 — 2008 学年第一学期
课 程 名 称 : 编译原理 授 课 学 时 : 60 学时 专 年 班 业 : 级 : 级 : 计算机 06 级 专升本1 专升本1-4班
主 讲 教 师 : 徐艳群 教 师 职 称 : 助 教
教 师 系 别 : 计算机科学与技术系 教 研 室 : 软 件