STATA与SPSS各省市第三产业生产总值
SPSS统计分析- 第2章 数据文件建立和管理

4.读取“*.txt”数据文件
现需将“人居收入.txt”文件中的数据读入SPSS,如图所示: (1) 打开“数据编辑器”对话框,选择“文件”|“打开文本数据”命令,打 开“打开数据”对话框。选择文本文件,单击“打开”按钮,打开“文本导入向 导”对话框,如图所示:
(2) 在“您的文本文件与 预定义的格式匹配吗? ” 选项组中选择 “ 是 ” 单选 按钮,可单击“浏览” 按 钮,选择已预定义好的 格式;单击 “ 否 ” 则需要 建立一个新格式。
2.1.1 打开定义变量视图
• 按前一章所述打开SPSS主界面,视图切换标签处单击“变 量视图”,即打开“变量视图”窗口,如图所示。在该视 图可对变量的以下属性进行定义:名称、类型、宽度、小 数、标签、值、缺失、列、对齐、度量标准和角色。
2.1.2 定义变量名称
• 在“变量视图”变量栏的“名称”栏中定义变量名称,用 户可根据数据需要或个人习惯进行定义,如果不对变量进 行定义,系统将自动默认变量名为var00001、var00002、 var00003等。一般根据变量的实质意义来命名,例如:年 龄、性别、年级等变量,可用Age,Gender,Grade命名,也 可用中文意义命名,但当出现变量数量较大时,一般使用 流水编号,即防混淆又方便。虽然变量可根据用户的需求 自行编辑,但仍有其需共同遵循的原则: • 若用英文命名,变量名首字必须为英文字母,其后方可接 数字、英文字母、@等。若用中文命名,则可直接使用。 • 不可使用空格和特殊字符(如键盘上的!、#、$、%、&、 ^、*、(、)、?等字符)。
(9) 之后进入下一步,如图所示。在“变量之间有哪些分隔符?”中,可根据 文本数据中变量间的分隔符,可选择“制表符”、 “空格”、“逗号 ”、“分号” 和“其他”复选框。在“文本限定符是什么?”中,可选择“无”、“单引号”、“ 双引号”和“其他”单选按钮,一般默认为“无”,选择完毕后单击“下一步” 。
使用Stata进行数据分析的教程

使用Stata进行数据分析的教程第一章:介绍StataStata是一种统计软件,经常被研究人员和学者用于数据分析和统计建模。
它提供了强大的数据处理和分析功能,可以应用于不同领域的研究项目。
本章介绍了Stata的基本功能和特点,包括数据管理、数据操作和Stata的界面等。
1.1 Stata的起源和发展Stata最初是由James Hardin和William Gould创建的,旨在为统计学家和社会科学研究人员提供一个数据分析工具。
随着时间的推移,Stata得到了广泛的应用,并逐渐发展成为一种强大的统计软件。
1.2 Stata的功能和特点Stata提供了许多数据处理和分析函数,包括描述性统计、回归分析、因子分析和生存分析等。
它还具有数据的管理功能,可以导入、导出和编辑数据文件。
Stata的界面友好,并且支持批处理和交互模式。
第二章:数据管理与准备在进行数据分析之前,首先需要准备和管理数据集。
本章将详细介绍Stata中的数据导入、数据清洗和数据变换等操作。
2.1 数据导入与导出Stata可以导入各种格式的数据文件,包括CSV、Excel和SPSS 等。
同时,Stata也支持将分析结果导出为不同的格式,如PDF和HTML等。
2.2 数据清洗和缺失值处理在实际研究中,数据常常存在缺失值和异常值。
Stata提供了处理缺失值和异常值的方法,可以通过删除、替换或插补来处理这些问题。
2.3 数据变换和指标构造数据变换是指将原始数据转化为适合分析的形式,常见的变换包括对数变换、差分和标准化等。
指标构造是指根据已有变量构造新的变量,如计算平均值和构造虚拟变量等。
第三章:描述性统计和数据可视化描述性统计是对数据集的基本统计特征进行总结和分析,而数据可视化则是通过图表和图形展示数据的特征和关系。
本章将介绍在Stata中进行描述性统计和数据可视化的方法。
3.1 中心趋势和离散程度的度量通过计算平均值、中位数和众数等指标来描述数据的中心趋势。
SPSS软件(英文版)各条目介绍
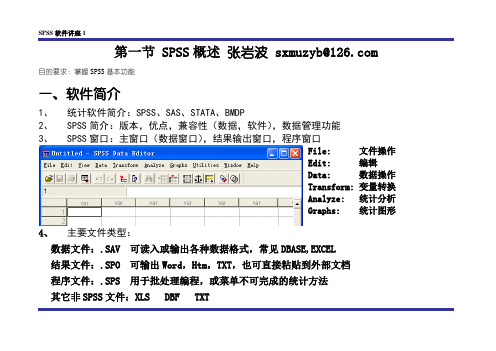
第一节 SPSS 概述 张岩波 sxmuzyb@目的要求:掌握SPSS 基本功能一、软件简介1、 统计软件简介:SPSS 、SAS 、STATA 、BMDP2、 SPSS 简介:版本,优点,兼容性(数据,软件),数据管理功能3、SPSS 窗口:主窗口(数据窗口),结果输出窗口,程序窗口File: 文件操作Edit: 编辑Data: 数据操作 Transform: 变量转换 Analyze: 统计分析 Graphs: 统计图形4、 主要文件类型:数据文件:.SAV 可读入或输出各种数据格式,常见DBASE,EXCEL 结果文件:.SPO 可输出Word ,Htm ,TXT ,也可直接粘贴到外部文档 程序文件:.SPS 用于批处理编程,或菜单不可完成的统计方法 其它非SPSS 文件:XLS DBF TXT二、数据的建立,调用与存储1、创建或打开数据文件:2、数据文件格式:同Dbase,变量名的命名规则;二维格式行(记录):通常每个个体或观察单位为一个记录列(变量):各种统计方法中注意各类变量的区分:观察效应,处理因素3、数据类型:变量设置变量名类型宽度小数位数变量标签赋值4、数据文件的存储调用:兼容EXCEL,SAS,dBASE,ACCESS等各种格式,可调用/导出三、善于利用帮助系统四、数据库的管理Data(数据操作)Transform(变量转换)五、统计方法:Graphs第二节统计描述一、计量资料、计数资料的统计描述(一)目标与教学要求1.掌握常用统计方法的选择、频数分布分析、描述统计量、探索分析及平均数分析。
2.熟悉资料统计工作的步骤、资料的分类、变量变换。
(二)课程内容:1. 常用统计方法的选择:●定量资料与定性资料●统计描述与统计推断●比较分析与关联性分析2. 频数分布分析:●正态分布:连续性资料,分布对称●二项分布:二分类资料,数据独立(非传染/遗传性疾病)●POISSION分布:稀有事件的发生率3. 描述统计量定量资料统计描述常用的统计指标及其适用场合描述内容指标意义适用场合平均水平均数个体的平均值对称分布。
中国工业企业数据库与Stata简介

2.Stat-Transfer介绍
➢ 在变量选择上,可选择全部变量,亦可选择部分变量,同时 还可在转换中重新设置变量输出的数据类型,如浮点型(float), 日期型(date),时间型(time),字符型(string) 等。软件还支持 优化(Optimize)功能;Use Doubles选项在转换时可将有小 数位的变量设置成双精度型 (double),保证数据的精度; Drop Constants选项,则自动将变量值恒为常数或缺失值 的变量略去,这在数据繁多时特别能体现出其优越性。
➢ Stata默认的数据文件扩展名为.dta,打开stata内置的 auto.dta数据库,命令:use auto
注意:Stata 中字母的大小写是严格区分的,因此Stata 建议对于变量名 一律使用小写字母。
4.3 将数据导入Stata
➢use命令的基本语句,具体格式如下: use [varlist] [if] [in] using filename [, clear nolabel] ➢含义说明:use是打开数据的命令语句,varlist代表变量名 称,if是条件语句,in是范围语句,using filename代表数据 文件路径。 ➢(1)打开数据文件中的全部数据 ➢如果想要打开auto数据文件中的全部数据,输入命令:
2stattransfer介绍?transfer软件还提供了一些其它的功能如在转换过程中更换变量名自动运行变量输出类型的优化功能设置日期时间型数据的读写格式对缺失值的各种处理方式的设定随机种子的产生或设定设置文本格式文件的读取格式excel工作簿中工作表的选取覆盖文件前确认提示等其它功能
SPSS 软件功能简介1

常用生物统计软件关键词:SAS,SPSS,S-PLUS,MinitabMinitab,Statistica,Stata,DPS,统计软件R,生物统计软件摘要:生物统计学作为生物研究必不可少的学科,需要许多与之对口的软件用于数据收集、整理、分析。
正文在生物学高度发展的今天,许多与之有关的学科也得到了较快的发展,生物统计学作为生物研究必不可少的学科,需要许多与之对口的软件用于数据收集、整理、分析。
目前,有很多软件可以解决生物统计学研究人员从立项到最后写论文的实际问题。
各个软件开发环境、运行平台和操作方法都各有千秋!现就与之相关的统计软件做简要介绍。
国外常用软件:SAS,美国SAS软件研究所研制的一套大型集成应用软件系统,具有完备的数据管理,数据分析和数据展现功能,SAS系统中提供的主要分析功能包括统计分析、经济计量分析、时间序列分析和质量管理工具,广泛应用与政府行政管理、科研、教育等领域。
SPSS,是世界上最早的统计分析软件,也是现今仅次于SAS的软件工具包,由美国斯坦福大学的三位研究生与20世纪60年代研制,并很快应用于自然科学、社会科学、技术科学等各个领域。
S-PLUS,S-PLUS基于S语言,并由MathSoft公司的统计科学部进一步完善。
作为统计学家及一般研究人员的通用方法工具箱,S-PLUS强调演示图形、探索性数据分析、统计方法、开发新统计工具的计算方法,以及可扩展性。
MinitabMinitab,是美国宾州大学研制的国际上流行的一个统计软件包,其特点是简单易懂,在国外大学统计学系开设的统计软件课程中,Minitab与SAS、BMDP相互并列,有的学术研究机构甚至专门教授Minitab之概念及其使用。
Minitab for Windows统计软件比SAS、SPSS等小得多,但功能并不弱,特别是它的试验设计与质量控制等功能。
MiniTab目前的最高版本为V14.1,它提供了对二维工作表中的数据进行分析的多种功能,包括:基本统计分析、回归分析、方差分析、多元分析、非参数分析、时间序列分析、试验设计、质量控制、模拟、绘制高质量三维图形等,从功能来看,Minitab除各种统计模型外,还具有许多统计软件不具备的功能——矩阵运算。
Stata数据分析

Stata是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。
它提供许许多多功能,包含线性混合模型、均衡重复反复及多项式普罗比模式。
新版本的STATA采用最具亲和力的窗口接口,使用者自行建立程序时,软件能提供具有直接命令式的语法。
Stata提供完整的使用手册,包含统计样本建立、解释、模型与语法、文献等超过一万余页的出版品。
[1]除了之外,Stata软件可以透过网络实时更新每天的最新功能,更可以得知世界各地的使用者对于STATA公司提出的问题与解决之道。
使用者也可以透过StataJournal获得许许多多的相关讯息以及书籍介绍等。
另外一个获取庞大资源的管道就是Statalist,它是一个独立的listserver,每月交替提供使用者超过1000个讯息以及50个程序。
参见“"、“[2]”、“网”、”等。
编辑本段Stata的统计功能Stata的统计功能很强,除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如Cox比例风险回归,指数与Weibull回归,多类结果与有序结果的logistic回归,Poisson回归,负二项回归及广义负二项回归,随机效应模型等。
具体说,Stata具有如下统计分析能力:数值变量资料的一般分析:参数估计,t检验,单因素和多因素的方差分析,协方差分析,交互效应模型,平衡和非平衡设计,嵌套设计,随机效应,多个均数的两两比较,缺项数据的处理,方差齐性检验,正态性检验,变量变换等。
分类资料的一般分析:参数估计,列联表分析(列联系数,确切概率),流行病学表格分析等。
等级资料的一般分析:秩变换,秩和检验,秩相关等相关与回归分析:简单相关,偏相关,典型相关,以及多达数十种的回归分析方法,如多元线性回归,逐步回归,加权回归,稳键回归,二阶段回归,百分位数(中位数)回归,残差分析、强影响点分析,曲线拟合,随机效应的线性回归模型等。
其他方法:质量控制,整群抽样的设计效率,诊断试验评价,kappa等。
常用到的stata命令

安装estat:ssc install estout,replace\2010-10-14 11:38:15来自: 杨囡囡(all a woman lack is a wife)(转自人大论坛)调整变量格式:format x1 %10.3f ——将x1的列宽固定为10,小数点后取三位format x1 %10.3g ——将x1的列宽固定为10,有效数字取三位format x1 %10.3e ——将x1的列宽固定为10,采用科学计数法format x1 %10.3fc ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符format x1 %10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符format x1 %-10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐合并数据:use "C:\Documents and Settings\xks\桌面\2006.dta", clearmerge using "C:\Documents and Settings\xks\桌面\1999.dta"——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来use "C:\Documents and Settings\xks\桌面\2006.dta", clearmerge id using "C:\Documents and Settings\xks\桌面\1999.dta" ,unique sort——将1999和2006的数据按照唯一的(unique)变量id来合并,在合并时对id进行排序(sort)建议采用第一种方法。
对样本进行随机筛选:sample 50在观测案例中随机选取50%的样本,其余删除sample 50,count在观测案例中随机选取50个样本,其余删除查看与编辑数据:browse x1 x2 if x3>3 (按所列变量与条件打开数据查看器)edit x1 x2 if x3>3 (按所列变量与条件打开数据编辑器)数据合并(merge)与扩展(append)merge表示样本量不变,但增加了一些新变量;append表示样本总量增加了,但变量数目不变。
STATA命令应用及详细解释(汇总)

STATA命令应用及详细解释(汇总)调整变量格式:format x1 .3f ——将x1的列宽固定为10,小数点后取三位format x1 .3g ——将x1的列宽固定为10,有效数字取三位format x1 .3e ——将x1的列宽固定为10,采用科学计数法format x1 .3fc ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符format x1 .3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符format x1 %-10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐合并数据:use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge using "C:\Documents and Settings\xks\桌面\1999.dta" ——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge id using "C:\Documents and Settings\xks\桌面\1999.dta" ,unique sort——将1999和2006的数据按照唯一的(unique)变量id来合并,在合并时对id进行排序(sort)建议采用第一种方法。
对样本进行随机筛选:sample 50在观测案例中随机选取50%的样本,其余删除sample 50,count在观测案例中随机选取50个样本,其余删除查看与编辑数据:browse x1 x2 if x3>3 (按所列变量与条件打开数据查看器)edit x1 x2 if x3>3 (按所列变量与条件打开数据编辑器)数据合并(merge)与扩展(append)merge表示样本量不变,但增加了一些新变量;append表示样本总量增加了,但变量数目不变。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于STATA与SPSS各省市第三产业生产总值 K-均值聚类对比分析报告
姓 名: 学 号: 专 业: 北京科技大学东凌经济管理学院 2012年 10月 25 日 基于STATA与SPSS各省市第三产业生产总值 K-均值聚类对比分析报告 一、K-均值聚类 1、聚类分析 聚类分析按照对象之间的“相似”程度把对象进行分类,聚类分析的“对象”可以是所观察的多个样本,也可以是针对每个样本测得的多个变量。 2、K-均值聚类 K-均值聚类事先需要确定要分的类别数据,计算量要小得多,效率比层次聚类要高,也被称为快速聚类。 3、K-均值聚类步骤 第1步:确定要分的类别数目K(需要研究者自己确定)在实际应用中,往往需要研究者根据实际问题反复尝试,得到不同的分类并进行比较,得出最后要分的类别数量。 第2步:确定K个类别的初始聚类中心 要求在用于聚类的全部样本中,选择K个样本作为K个类别的初始聚类中心;与确定类别数目一样,原始聚类中心的确定也需要研究者根据实际问题和经验来综合考虑 。 第3步:根据确定的K个初始聚类中心,依次计算每个样本到K个聚类中心的距离欧氏距离,并根据距离最近的原则将所有的样本分到事先确定的K个类别中。 第4步:根据所分成的K个类别,计算出各类别中每个变量的均值,并以均值点作为新的K个类别中心。根据新的中心位置,重新计算每个样本到新中心的距离,并重新进行分类。 第5步:重复第4步,直到满足终止聚类条件为止。迭代次数达到研究者事先指定的最大迭代次数;新确定的聚类中心点与上一次迭代形成的中心点的最大偏移量小于指定的量 。 K-均值聚类法是根据事先确定的K个类别反复迭代直到把每个样本分到指定的里类别中。类别数目的确定具有一定的主主观性,究竟分多少类合适,需要研究者对研究问题的了解程度、相关知识和经验。
二、数据来源 本文数据选自《2011中国统计年鉴》2-15 按三次产业分地区生产总值部分,见表1。 本表绝对数按当年价格计算,指数按不变价格计算 单位:亿元 表1 各省市第三产业地区生产总值
三、STATA应用 1、运行命令 cluster kmeans var1 var2 var3 var4 var5, k(4) cluster completelinkage var1 var2 var3 var4 var5, name(L2clnk3) cluster dendrogram L2clnk3 2、K-均值聚类结果 通过运行命令,得到聚类结果见表2和图1。
总和物流批发和零售业住宿和餐饮业金融业房地产业 北 京5787.99712.011888.51317.341863.611006.52 天 津2784.29585.371090.68157.66572.99377.59 河 北4853.401745.911529.26265.02615.42697.79 山 西2221.51654.08695.51231.62448.30192.00 内蒙古2915.50875.611051.96332.24346.44309.250.00 辽 宁4320.72926.811651.66369.61639.27733.37 吉 林1709.75373.93753.37180.01190.12212.32 黑龙江2249.25469.31880.83240.13288.19370.790.00 上 海6648.65834.402594.34266.451950.961002.50 江 苏11633.651768.304447.50710.982105.922600.95 浙 江8191.231076.672646.14523.672326.581618.17 安 徽2536.80527.02887.66193.78396.17532.17 福 建3895.18871.161310.94266.47767.58679.03 江 西1895.87446.22666.89200.71241.49340.56 山 东9882.971971.004257.40670.971361.451622.150.00 河 南4242.94873.301293.50605.23697.68773.23 湖 北3556.08753.611291.68385.11561.27564.41 湖 南3549.24832.281434.68354.91463.16464.21 广 东13020.611825.294647.761074.852658.762813.95 广 西2168.66480.17656.83241.34384.53405.79 海 南658.45101.90220.6569.4578.12188.330.00 重 庆1918.93389.55624.33142.11496.56266.38 四 川3281.46573.751016.03478.42654.70558.56 贵 州1399.72480.32367.52180.73231.51139.64 云 南1667.51193.26685.38190.34375.08223.45 西 藏110.9222.1231.4315.7527.0814.540.00 陕 西2250.11474.60856.65218.16384.75315.95 甘 肃807.27227.18272.1397.40100.54110.02 青 海238.9461.2681.4416.3054.5325.41 宁 夏424.07145.1789.5031.0097.8760.53 新 疆935.45222.47276.2868.06225.20143.44表2:STATA聚类结果 图1:STATA树状聚类图 四、SPSS应用 用SPSS进行K-均值聚类,得到的结果见表3和图2.
1234山 西江 苏天 津 北 京吉 林山 东河 北 浙 江黑龙江广 东内蒙古 上 海安 徽辽 宁江 西福 建广 西河 南海 南湖 北重 庆湖 南贵 州四 川云 南西 藏陕 西甘 肃青 海宁 夏新 疆表3:SPSS聚类结果
图2:SPSS树状聚类图 五、结论 通过STATA和SPSS两种统计软件运行,可以看出聚类的结果大致相同,但是存在一些类别中包含数量的差异。 通过聚类的结果可以得出我国第三产业发展不平衡,东部沿海省市第三产业比较发达,中部地区次之,西部地区相对落后,这和我国当前的第三产业发展现状比较吻合。 长期以来,由于各地区生产力发展水平不同,社会劳动力分布不均,各地区
1234山 西江 苏天 津北 京吉 林广 东河 北上 海江 西内蒙古浙 江广 西黑龙江山 东海 南辽 宁重 庆安 徽贵 州福 建云 南河 南西 藏湖 北陕 西湖 南甘 肃四 川青 海宁 夏新 疆经济发展的重点不一样,因而第三产业的区域发展仍有明显的差异。总体来看,从沿海到内地呈现出明显的层次特征。以增加值为例,经济实力比较强的广东省,2010年第三产业的增加值13020亿元,而经济实力比较弱的西藏和青海合计也只有338亿元,两者相差四十几倍。同时,由于我国在政策上采取地区经济发展梯进推移战略,从东到西分为三级梯度,分别实行不同的发展战略,因而我国东、中、西部三大地区第三产业发展水平差异现在仍比较大。 我国第三产业在区域间的发展过程中呈现出了不平衡状况,要促进各个区域第三产业可持续发展,解决第三产业对国民经济总体发展水平和产业结构的约束作用,促进经济结构的高级化和现代化。地区第三产业的发展应以区域的资源为基础,优势的资源才能支撑起优势的产业。东部沿海地区毗邻港澳,可以充分发挥此项优势,扩大第三产业与它们以及东南亚的交流,在商业、房地产和其它一些行业中吸引港澳人士参与,把东南沿海地区建成我国与东南亚地区进行经济交流与合作的基地。中西部地区旅游资源丰富,正好可以借助此项有利条件,可在这些自然资源基础上,加大旅游基础设施投资力度,改善旅游消费环境,大力加强旅游促销,推广新景点、新线路、新城市,不断形成新的旅游热点和亮点,逐步提高区域旅游业的国内和国际竞争力,促进各地区特别是中西部地区省份第三产业的全面进步。
参考文献 1、张鹏伟 李嫣怡. 《Stata统计分析与应用》.电子工业出版社,2011, 5. 2、Joseph F. Hair, Rolph E. Anderson.《Multivariate data analysis》. Prentice Hall, 2010 3、薛薇. 《统计分析与SPSS的应用》中国人民大学出版社,2011, 1. 4、各省市第三产业地区生产总值. http://www.stats.gov.cn/tjsj/ndsj/2011/indexch.htm 5、Abdelmonem A. Afifi, Virginia Clark, Susanne May.《Computer-aided multivariate analysis》. Chapman & Hall/CRC, 2004