从GoogleSpanner漫谈分布式存储与数据库技术
分布式数据库技术与应用分析

分布式数据库技术与应用分析随着互联网的发展和应用范围的拓展,数据规模也不断地扩大,因此,人们需要更高效的方式来存储、管理和处理数据。
在这样的背景下,分布式数据库技术应运而生。
本文将对分布式数据库技术进行分析及其应用。
一、分布式数据库技术的概念与优势分布式数据库技术指的是将一个数据库分为多个部分,分别存储在多个不同的计算机上,并通过网络进行通信,从而形成了一个虚拟的数据库,使得数据可以在不同的地方、不同的时间点进行存取。
与传统的集中式数据库相比,分布式数据库技术具有以下的优势:1. 可靠性更高:分布式数据库技术使用了数据备份、冗余和分布式交易等多种机制,保证了数据的复制和恢复能力,在一台计算机出现故障时,仍然可以进行数据的读取和操作。
2. 更高的性能:由于数据分布在多台计算机上,分布式数据库可以通过对各个计算机的并行处理来提高处理速度,从而提高了整个数据库的性能。
3. 扩展性更强:由于分布式数据库可以不断地添加计算机来扩展存储空间,使得整个系统的存储和处理能力可以很方便地进行扩展,以适应数据规模的增长。
二、分布式数据库技术的实现方式分布式数据库技术的实现方式主要包括:垂直划分、水平划分和复制等。
其中,垂直划分是将数据库按照数据表进行划分,每个表分别存储在不同的计算机上;水平划分是将数据表中的数据按照行或列进行划分,使得同一个数据表中的数据可以分布在不同的计算机上;而复制则是将同样的数据存储在多个不同的计算机上,以实现数据的备份和冗余。
三、应用场景及实践案例分布式数据库技术在实际应用中可以解决很多问题,如数据安全性、负载均衡和数据存取速度等方面的问题,适用于大型企业和互联网应用。
以下是一些常见的应用场景和实践案例:1. 金融行业:在交易、结算等领域,金融行业需要处理海量的交易数据,采用分布式数据库技术可以实现高效的交易系统,保证金融系统的安全性和可靠性。
2. 电商平台:电商平台的订单、库存等数据会随着用户的增多而呈指数增长,采用分布式数据库技术可以实现大规模并发操作,以及快速的数据读取和写入。
tidb 原理

tidb 原理TiDB原理:分布式数据库的新选择TiDB是一种分布式数据库,它采用了分布式事务和分布式存储技术,可以实现高可用性、高性能和高扩展性。
TiDB的核心原理是将数据分散存储在多个节点上,同时使用Raft协议保证数据的一致性和可靠性。
TiDB的分布式存储技术是基于TiKV实现的。
TiKV是一种分布式键值存储引擎,它采用了Raft协议来保证数据的一致性和可靠性。
TiKV将数据分散存储在多个节点上,每个节点都有自己的数据副本。
当一个节点发生故障时,其他节点可以接管它的工作,保证数据的可用性和一致性。
TiDB的分布式事务技术是基于TiDB实现的。
TiDB是一种分布式关系型数据库,它采用了Google Spanner的分布式事务技术。
TiDB 将数据分散存储在多个节点上,每个节点都有自己的数据副本。
当一个事务需要跨越多个节点时,TiDB会使用2PC协议来保证事务的一致性和可靠性。
TiDB的高可用性是基于Raft协议实现的。
Raft协议是一种分布式一致性协议,它可以保证数据的一致性和可靠性。
当一个节点发生故障时,其他节点可以接管它的工作,保证数据的可用性和一致性。
TiDB的高性能是基于分布式存储和分布式事务技术实现的。
TiDB将数据分散存储在多个节点上,每个节点都有自己的数据副本。
当一个事务需要跨越多个节点时,TiDB会使用2PC协议来保证事务的一致性和可靠性。
这种分布式存储和分布式事务技术可以大大提高数据库的性能和扩展性。
TiDB是一种分布式数据库,它采用了分布式事务和分布式存储技术,可以实现高可用性、高性能和高扩展性。
TiDB的核心原理是将数据分散存储在多个节点上,同时使用Raft协议保证数据的一致性和可靠性。
TiDB是分布式数据库的新选择,它可以满足大规模数据存储和处理的需求。
分布式系统Spanner

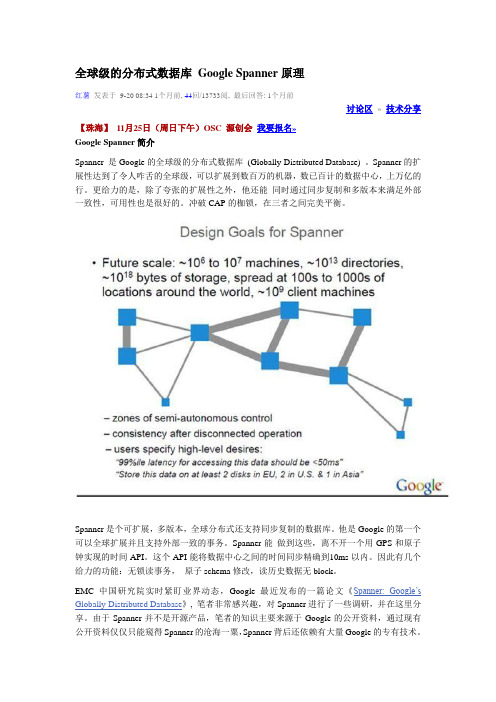
全球级分布式数据库Google Spanner原理介绍与分析1摘要Spanner 是Google的分布式数据库(Globally-Distributed Database) 。
其扩展性能达到了令人咋舌的全球级,可以扩展到数百万的机器,数已百计的数据中心,上万亿的行。
除了夸张的扩展性之外,它还能同时通过同步复制和多版本来满足外部一致性,在CAP三者之间完美平衡。
Spanner设计中一个亮点特性就是TrueTime。
在时间API中明确给出时钟不确定性,以更加强壮的时间语义来构建分布式系统。
本文对Google Spanner从提出背景、设计、原理应用等方面进行了详细的介绍。
在本文的最后,作者对GoogleSpanner进行了分析,就CAP理论和其优点谈及了自己的看法。
关键字: 分布式系统、数据库、TrueTime、RDBMS2ABSTRACTSpanner is Google's global distributed database. The expansion performance reached global level that can be extended to millions of machines, hundreds of data centers, trillion data rows. In addition to the amazing expansion performance, Spanner can meet the external consistency both through synchronized replication and multi version, achieved the perfect balance between the three CAP theorem. One of the highlights in the design of the Spanner isTrueTime. In this time API, the uncertainty of the clock is defined, and the distributed system is constructed with a more robust time semantics.In this paper, the background, design, principle and application of Spanner Google are introduced in detail. At the end of this paper, the author analyzes the Google Spanner, and talked about his own views on the CAP theory and its advantages.Keywords:Distributed System、Database、TrueTime、RDBMS目录1 摘要 (1)2 ABSTRACT (2)3 绪论 (1)3.1 背景介绍 (1)3.2 Spanner的前身——著名的Bigtable (1)3.3 可容错可扩展的RDBMS-F1 (2)3.4 Spanner简介 (2)4原理与实现 (3)4.2 Spanserver软件栈 (4)4.3目录和放置 (5)4.4数据模型 (7)4.5 TrueTime API (8)5 Spanner的应用 (9)6 总结 (11)6.1 CAP理论 (11)6.2 Spanner的优点 (12)7 参考文献 (14)3绪论3.1背景介绍Google是全球著名的互联网公司,拥有全球最大的谷歌搜索引擎,全球广泛使用的谷歌分析、谷歌地球、谷歌地图等核心业务。
细数Google核心数据库技术

细数Google核心数据库技术 2010-08-13 09:58 榆钱沽酒博客园我要评论(0)∙摘要:在这里我们将细数Google的核心数据库技术,包括大规模数据处理,分布式数据库技术和数据中心方案等等。
∙标签:Gooele∙限时报名参加“甲骨文全球大会·2010·北京”及“JavaOne和甲骨文开发者大会2010”分布式大规模数据处理MapReduce首先,在Google数据中心会有大规模数据需要处理,比如被网络爬虫(Web Crawler)抓取的大量网页等。
由于这些数据很多都是PB级别,导致处理工作不得不尽可能的并行化,而Google为了解决这个问题,引入了MapReduce这个编程模型,MapReduce是源自函数式语言,主要通过"Map(映射)"和"Reduce(化简)"这两个步骤来并行处理大规模的数据集。
Map会先对由很多独立元素组成的逻辑列表中的每一个元素进行指定的操作,且原始列表不会被更改,会创建多个新的列表来保存Map的处理结果。
也就意味着,Map操作是高度并行的。
当Map工作完成之后,系统会先对新生成的多个列表进行清理(Shuffle)和排序,之后会这些新创建的列表进行Reduce操作,也就是对一个列表中的元素根据Key值进行适当的合并。
下图为MapReduce的运行机制:图2. MapReduce的运行机制(参[19])点击查看大图接下来,将根据上图来举一个MapReduce的例子:比如,通过搜索Spider将海量的Web页面抓取到本地的GFS 集群中,然后Index系统将会对这个GFS集群中多个数据Chunk 进行平行的Map处理,生成多个Key为URL,value为html页面的键值对(Key-Value Map),接着系统会对这些刚生成的键值对进行Shuffle(清理),之后系统会通过Reduce操作来根据相同的key值(也就是URL)合并这些键值对。
GOOGLE分布式数据库技术演进研究

GOOGLE分布式数据库技术演进研究熊剑(中兴通讯股份有限公司成都研发中心)【摘要】大数据和云计算已经成为现有信息技术发展主流方向和趋势,分布式数据库技术是这些技术的基础和核心,GOOGLE作为整个业界技术的领导者,提出了BIGTABLE、DREMEL、SPANNER等一系列分布式数据库产品,让人感叹其超凡技术成就的同时,也展示出GOOGLE在分布式数据库技术上的演进路线,国内对于这些技术都有一些介绍,但是还未把这些产品串接起来,对分布式数据库技术实践和探索方向进行整合分析,作者对这些产品核心技术进行分析,结合自身对于分布式数据库的理解,力争展示出分布式数据库技术前进的脉络和方向。
【关键词】ACID;CAP;RDBS;Bigtable; Dremel; Spanner; F1;GFS;TrueTime; Colossus【中图分类号】【文献标识码】A Research of Evolution of distributed database technologyGOOGLE.Xiong Jian(ZTE Corporation Chengdu Research Center)【ABSTRACT 】Big data and cloud computing has become the current mainstream IT development trends, distributed database technology is the foundation of these technologies, GOOGLE is the role of this industry, proposed Bigtable, Dremel, Spanner series distributed database products, these products got extraordinary technical achievements, demonstrated the GOOGLE evolution path of distributed database technology, in recent years ,paper or BBS has introduction of these technologies, but these products have not yet connected in series, gave corresponding distributed database technology practice and exploration direction of meta-analysis, the authors analyze the core technology of these products, combined with their understanding of the distributed database, and strive to show the direction of distributed database technology.【KEY WORDS 】ACID;CAP;RDBS;Bigtable; Dremel; Spanner; F1;GFS;TrueTime; Colossus1 引言在传统RDBM系统中,对于事务处理必须处理为一个完整的逻辑处理过程,具备ACID四个特性,A Atonomy 事务处理的原子性,要么成功,要么失败,C Consistency 一致性,数据库必须保持原有约束的关系,数据之间必须符合数据完整性,I Isolation 事务处理必须要彼此隔离,由RDBM保证能够并发处理事务,而不需要用户显示的干预,DDurability 数据能够被持久化下来,不会出现事务涉及数据丢失的情况。
全球级的分布式数据库 Google Spanner原理
全球级的分布式数据库Google Spanner原理红薯发表于9-20 08:34 1个月前, 44回/13733阅, 最后回答: 1个月前讨论区»技术分享【珠海】11月25日(周日下午)OSC 源创会我要报名»Google Spanner简介Spanner 是Google的全球级的分布式数据库(Globally-Distributed Database) 。
Spanner的扩展性达到了令人咋舌的全球级,可以扩展到数百万的机器,数已百计的数据中心,上万亿的行。
更给力的是,除了夸张的扩展性之外,他还能同时通过同步复制和多版本来满足外部一致性,可用性也是很好的。
冲破CAP的枷锁,在三者之间完美平衡。
Spanner是个可扩展,多版本,全球分布式还支持同步复制的数据库。
他是Google的第一个可以全球扩展并且支持外部一致的事务。
Spanner能做到这些,离不开一个用GPS和原子钟实现的时间API。
这个API能将数据中心之间的时间同步精确到10ms以内。
因此有几个给力的功能:无锁读事务,原子schema修改,读历史数据无block。
EMC中国研究院实时紧盯业界动态,Google最近发布的一篇论文《Spanner: Google’s Globally-Distributed Database》, 笔者非常感兴趣,对Spanner进行了一些调研,并在这里分享。
由于Spanner并不是开源产品,笔者的知识主要来源于Google的公开资料,通过现有公开资料仅仅只能窥得Spanner的沧海一粟,Spanner背后还依赖有大量Google的专有技术。
下文主要是Spanner的背景,设计和并发控制。
Spanner背景要搞清楚Spanner原理,先得了解Spanner在Google的定位。
从上图可以看到。
Spanner位于F1和GFS之间,承上启下。
所以先提一提F1和GFS。
F1和众多互联网公司一样,在早期Google大量使用了Mysql。
Google全球级分布式数据库Spanner

Colossus系统架构
Colossus(GFS II)
GFS将整个系统的节点分为三种角色:GFS Master (总控服务器),GFS Chunkserver(数据块服务器, 简称CS)以及GFS Client(客户端)。 GFS文件被划分为固定大小的数据块(Chunk),由 Master在创建时分配一个64位全局唯一的Chunk句柄。 CS以普通的Linux文件的形式将Chunk存储在磁盘中。 为了保证可靠性,Chunk在不同的机器中复制多份,默 认为三份。 Master中维护了系统的元数据,包括文件及Chunk名字 空间,GFS文件到Chunk之间的映射,Chunk位置信息。 它也负责整个系统的全局控制,如Chunk租约管理,垃 圾回收无用Chunk,Chunk复制等等。Master会定期与 CS通过心跳的方式交换信息。
Colossus(GFS II) [kəˈl ɒsəs]
Colossus是第二代GFS,对应开源世界的新 HDFS。Google文件系统GFS是构建在廉价的 服务器之上的大型分布式系统。它将服务器故 障视为正常现象,通过软件的方式自动容错, 在保证系统可靠性和可用性的同时,大大减少 了系统的成本。 GFS是Google云存储的基石,其它存储系统, 如Google Bigtable,Google Megastore, Google Percolator [p:klet(r)]均直接或者间接 地构建在GFS之上。另外,Google大规模批处 理系统MapReduce也需要利用GFS作为海量数 据的输入输出。
Spanner背景
Spanner 是Google的全球级的分布式数 据库 (Globally-Distributed Database) 。 Spanner的扩展性达到了令人咋舌的全球 级,可以扩展到数百万的机器,数已百计 的数据中心,上万亿的行。更给力的是, 除了夸张的扩展性之外,它还能同时通过 同步复制和多版本来满足外部一致性,可 用性也是很好的。冲破CAP的枷锁,在三 者之间完美平衡。
Google全球级分布式数据库Spanner精品PPT课件

Colossus系统架构
Colossus(GFS II)
GFS将整个系统的节点分为三种角色:GFS Master (总控服务器),GFS Chunkserver(数据块服务器, 简称CS)以及GFS Client(客户端)。
GFS文件被划分为固定大小的数据块(Chunk),由 Master在创建时分配一个64位全局唯一的Chunk句柄。 CS以普通的Linux文件的形式将Chunk存储在磁盘中。 为了保证可靠性,Chunk在不同的机器中复制多份,默 认为三份。
Design Goals
Spanner背景
要搞清楚Spanner原理,先得了解Spanner在Google的 定位。
F1
和众多互联网公司一样,在早期Google 大量使用了Mysql。Mysql是单机的,可 以用Master-Slave来容错,分区来扩展。 但是需要大量的手工运维工作,有很多的 限制。因此Google开发了一个可容错可 扩展的RDBMS-F1。和一般的分布式数据 库不同,F1对应RDMS( Relational Database Management System )应有的 功能,毫不妥协。起初F1是基于Mysql的, 不过以后会逐渐迁移到Spanner。
F1特点
7×24高可用。哪怕某一个数据中心停止 运转,仍然可用。
可以同时提供强一致性和弱一致性。 可扩展 支持SQL 事务提交延迟50-100ms,读延迟5-10ms,
高吞吐
众所周知Google BigTable是重要的NoSql产品, 提供很好的扩展性,开源世界有HBase与之对 应。为什么Google还需要F1,而不是都使用 BigTable呢?因为BigTable提供的最终一致性, 一些需要事务级别的应用无法使用。同时 BigTable还是NoSql,而大量的应用场景需要有 关系模型。就像现在大量的互联网企业都使用 Mysql而不愿意使用HBase,因此Google才有 这个可扩展数据库的F1。而Spanner就是 F1的 至关重要的底层存储技术。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
从Google Spanner漫谈分布式存储与数据库技术文/曹伟Spanner 的设计反映了 Google 多年来在分布式存储系统领域上经验的积累和沉淀,它采用了 Megastore 的数据模型,Chubby 的数据复制和一致性算法,而在数据的可扩展性上使用了 BigTable 中的技术。
新颖之处在于,它使用高精度和可观测误差的本地时钟来判断分布式系统中事件的先后顺序。
Spanner 代表了分布式数据库领域的新趋势——NewSQL。
Spanner 是 Google 最近公开的新一代分布式数据库,它既具有 NoSQL 系统的可扩展性,也具有关系数据库的功能。
例如,它支持类似 SQL 的查询语言、支持表连接、支持事务(包括分布式事务)。
Spanner 可以将一份数据复制到全球范围的多个数据中心,并保证数据的一致性。
一套 Spanner 集群可以扩展到上百个数据中心、百万台服务器和上T条数据库记录的规模。
目前,Google 广告业务的后台(F1)已从 MySQL 分库分表方案迁移到了Spanner 上。
数据模型传统的 RDBMS(例如 MySQL)采用关系模型,有丰富的功能,支持 SQL 查询语句。
而NoSQL 数据库多是在 key-value 存储之上增加有限的功能,如列索引、范围查询等,但具有良好的可扩展性。
Spanner 继承了 Megastore 的设计,数据模型介于 RDBMS 和 NoSQL 之间,提供树形、层次化的数据库 schema,一方面支持类 SQL 的查询语言,提供表连接等关系数据库的特性,功能上类似于 RDBMS;另一方面整个数据库中的所有记录都存储在同一个key-value 大表中,实现上类似于 BigTable,具有 NoSQL 系统的可扩展性。
在 Spanner 中,应用可以在一个数据库里创建多个表,同时需要指定这些表之间的层次关系。
例如,图 1 中创建的两个表——用户表(Users)和相册表(Albums),并且指定用户表是相册表的父节点。
父节点和子节点间存在着一对多的关系,用户表中的一条记录(一个用户)对应着相册表中的多条记录(多个相册)。
此外,要求子节点的主键必须以父节点的主键作为前缀。
例如,用户表的主键(用户 ID)就是相册表主键(用户 ID+ 相册 ID)的前缀。
图 1 schema 示例,表之间的层次关系,记录排序后交错的存储显然所有表的主键都将根节点的主键作为前缀,Spanner 将根节点表中的一条记录,和以其主键作为前缀的其他表中的所有记录的集合称作一个 Directory。
例如,一个用户的记录及该用户所有相册的记录组成了一个 Directory。
Directory 是 Spanner 中对数据进行分区、复制和迁移的基本单位,应用可以指定一个 Directory 有多少个副本,分别存放在哪些机房中,例如把用户的 Directory 存放在这个用户所在地区附近的几个机房中。
这样的数据模型具有以下好处。
•一个 Directory 中所有记录的主键都具有相同前缀。
在存储到底层 key-value 大表时,会被分配到相邻的位置。
如果数据量不是非常大,会位于同一个节点上,这不仅提高了数据访问的局部性,也保证了在一个 Directory 中发生的事务都是单机的。
•Directory 还实现了从细粒度上对数据进行分区。
整个数据库被划分为百万个甚至更多个 Directory,每个 Directory 可以定义自己的复制策略。
这种Directory-based 的数据分区方式比 MySQL 分库分表时 Table-based 的粒度要细,而比 Yahoo!的 PNUTS 系统中 Row-based 的粒度要粗。
•Directory 提供了高效的表连接运算方式。
在一个 Directory 中,多张表上的记录按主键排序,交错(interleaved)地存储在一起,因此进行表连接运算时无需排序即可在表间直接进行归并。
复制和一致性Spanner 使用 Paxos 协议在多个副本间同步 redo 日志,从而保证数据在多个副本上是一致的。
Google 的工程师钟情于 Paxos 协议,Chubby、Megastore 和 Spanner 等一系列产品都是在 Paxos 协议的基础上实现一致性的。
Paxos 的基本协议很简单。
协议中有三个角色:Proposer、Acceptor 和 Learner,Learner 和 Proposer 分别是读者和写者,Acceptor 相当于存储节点。
整个协议描述的是,当系统中有多个 Proposer 和 Acceptor 时,每次 Proposer 写一个变量就会启动一轮决议过程(Paxos instance),如图 2 所示。
决议过程可以保证即使多个 Proposer 同时写,结果也不会在 Acceptor 节点上不一致。
确切地说,一旦某个 Proposer 提交的值被大多数Acceptor 接受,那么这个值就被选中,在整轮决议的过程中该变量就不会再被修改为其他值。
如果另一个 Proposer 要写入其他值,必须启动下一轮决议过程,而决议过程之间是串行(serializable)的。
图 2 Paxos 协议正常执行流程一轮决议过程分为两个阶段,即 prepare 阶段和 accept 阶段。
•第一阶段A:Proposer 向所有 Acceptor 节点广播 prepare 消息,消息中只包含一个序号——N。
Proposer 需要保证这个序号在这轮决议过程中是全局唯一的(这很容易做到,假如系统中有两个 Proposer,那么一个 Proposer 使用1,3,5,7,9,……,另一个 Proposer 则使用0,2,4,6,8,……)。
•第一阶段B:Acceptor 接收到 prepare 消息后,如果N是到目前为止见过的最大序号,就返回一个 promise 消息,承诺不会接受序号小于N的请求;如果已接受过其他 Proposer 提交的值,则会将这个值连同提交这个值的请求的序号一同返回。
•第二阶段A:当 Proposer 从大多数 Acceptor 节点收到了 promise 消息后,就可以选择接下来要向 Acceptor 提交的值了。
一般情况下,当然选原本打算写入的值,但如果从收到的 promise 消息中发现已经有其他值被 Acceptor 接受了,那么为了避免造成数据不一致的风险,这时 Proposer 就必须“大义灭亲”,放弃自己打算写入的值,从其他 Proposer 提交的序号中选择一个最大的值。
接下来 Proposer 向所有的 Acceptor 节点发送 accept 包,其中包含在第一阶段中挑选的序号N和刚才选择的值V。
•第二阶段B:Acceptor 收到 accept 包之后,如果N的大小不违反对其他Proposer 的承诺,就接受这个请求,记录下值V和序号N,返回一个 ack 消息。
反之,则返回一个 reject 消息。
如果 Proposer 从大多数 Acceptor 节点收到了 ack 消息,说明写操作成功。
而如果在写操作过程中失败,Proposer 可以增大序号,重新执行第一阶段。
基本的 Paxos 协议可以保证值一旦被选出后就一定不会改变,但不能保证一定会选出值来。
换句话说,这个投票算法不一定收敛。
有两个方法可以加速收敛的过程:一个是在出现冲突后通过随机延迟把机会让给其他 Proposer,另一个是尽量让系统中只有一个Proposer 去提交。
在 Chubby 和 Spanner 系统中这两种方法都用上了,先用随机延迟的方法通过一轮 Paxos 协议,在多个 Proposer 中选举出一个 leader 节点。
接下来所有的写操作都通过这个 leader 节点,而 leader 节点一般还是比较“长寿”的,在广域网环境下平均“任期”可以达到一天以上。
而 Megastore 系统中没有很好地解决这个问题,所有的Proposer 都可以发起写操作,这是 Megastore 写入性能不高的原因之一。
基本的 Paxos 协议还存在性能上的问题,一轮决议过程通常需要进行两个回合通信,而一次跨机房通信的代价为几十到一百毫秒不等,因此两个回合的通信就有点开销过高了。
不过幸运的是,绝大多数情况下,Paxos 协议可以优化到仅需一个回合通信。
决议过程的第一阶段是不需要指定值的,因此可以把 prepare/promise 的过程捎带在上一轮决议中完成,或者更进一步,在执行一轮决议的过程中隐式地涵盖接下来一轮或者几轮决议的第一阶段。
这样,当一轮决议完成之后,其他决议的第一阶段也已经完成了。
如此看来,只要 leader 不发生更替,Paxos 协议就可以在一个回合内完成。
为了支持实际的业务,Paxos 协议还需要支持并发,多轮决议过程可以并发执行,而代价是故障恢复会更加复杂。
因为 leader 节点上有最新的数据,而在其他节点上为了获取最新的数据来执行 Paxos 协议的第一阶段,需要一个回合的通信代价。
因此,Chubby 中的读写操作,以及 Spanner 中的读写事务都仅在 leader 节点上执行。
而为了提高读操作的性能,减轻 leader 节点的负载,Spanner 还提供了只读事务和本地读。
只读事务只在 leader 节点上获取时间戳信息,再用这个时间戳在其他节点上执行读操作;而本地读则读取节点上最新版本的数据。
与 Chubby、 Spanner 这种读写以 leader 节点为中心的设计相比,Megastore 体现了一定的“去中心化”设计。
每个客户端都可以发起 Paxos 写操作,而读操作则尽可能在本地执行。
如果客户端发现本地数据不是最新的,会启动 catchup 流程更新数据,再执行本地读操作返回给客户端。
最后,对比下其他系统中 replication 的实现。
在 BigTable 系统中每个 tablet 服务器是没有副本的,完全依赖底层 GFS 把数据存到多台机器上。
数据的读写都通过单个tablet 服务器,在 tablet 服务器出现故障的时需要 master 服务器将 tablet 指派到其他 tablet 服务器上才能恢复可用。
Dynamo 系统则贯彻了“去中心化”的思想,将数据保存在多个副本上,每个副本都可以写入(update everywhere)。
而不同副本同时写入的数据可能会存在不一致,则需要使用版本向量(version vector)记录不同的值和时间戳,由应用去解释或合并不一致的数据。
尽管 Dynamo 系统还提供了 NWR 的方式来支持有一致性保证的读写操作,但总的来说 Dynamo 为了高可用性牺牲了一致性。