神经元算法
(完整word版)单神经元自适应PID控制算法

单神经元自适应PID 控制算法一、单神经元PID 算法思想神经元网络是智能控制的一个重要分支,神经元网络是以大脑生理研究成果为基础,模拟大脑的某些机理与机制,由人工建立的以有向图为拓扑结构的网络,它通过对连续或断续的输入做状态响应而进行信息处理;神经元网络是本质性的并行结构,并且可以用硬件实现,它在处理对实时性要求很高的自动控制问题显示出很大的优越性;神经元网络是本质性的非线性系统,多层神经元网络具有逼近任意函数的能力,它给非线性系统的描述带来了统一的模型;神经元网络具有很强的信息综合能力,它能同时处理大量不同类型的输入信息,能很好地解决输入信息之间的冗余问题,能恰当地协调互相矛盾的输入信息,可以处理那些难以用模型或规则描述的系统信息。
神经元网络在复杂系统的控制方面具有明显的优势,神经元网络控制和辨识的研究已经成为智能控制研究的主流。
单神经元自适应PID 控制算法在总体上优于传统的PID 控制算法,它有利于控制系统控制品质的提高,受环境的影响较小,具有较强的控制鲁棒性,是一种很有发展前景的控制器。
二、单神经元自适应PID 算法模型单神经元作为构成神经网络的基本单位,具有自学习和自适应能力,且结构简单而易于计算。
传统的PID 则具有结构简单、调整方便和参数整定与工程指标联系紧密等特点。
将二者结合,可以在一定程度上解决传统PID 调节器不易在线实时整定参数,难以对一些复杂过程和参数时变、非线性、强耦合系统进行有效控制的不足。
2.1单神经元模型对人脑神经元进行抽象简化后得到一种称为McCulloch-Pitts 模型的人工神经元,如图2-1所示。
对于第i 个神经元,12N x x x 、、……、是神经元接收到的信息,12i i iN ωωω、、……、为连接强度,称之为权。
利用某种运算把输入信号的作用结合起来,给它们的总效果,称之为“净输入”,用i net 来表示。
根据不同的运算方式,净输入的表达方式有多种类型,其中最简单的一种是线性加权求和,即式 (2-1)。
神经网络自适应线性神经元Adaline的LMS算法

5
最陡下降算法 4
在步幅系数选择为 0.02 ,最小误差为 Emin 0.001 0.2633 的条件下,在 MATLAB
下编程计算,得到某一次的相应结果如下。 权值向量 W [0.3516 均方误差曲线
0.9
0.3240];
0.8
0.7
均方误差 E
0.6
0.5
0.4
0.3
0.2
2.0106 1.1515 R ; 1.1515 1.7398
P 1.1058 1.0074 ; W* 0.3517 0.3463;
E ( 2 )min 0.2623
2) 阈值待定的情况下 根据样本数据得到的运算结果如下。
2
2.0106 1.1515 0.0269 R 1.1515 1.7398 0.0422 ; 0.0269 0.0422 1.0000
5
10
15
20 迭代次数 N
25
30
35
40
图 2
随机逼近算法均方误差曲线
可以看到,经过 38 次的迭代算法,最后均方误差收敛到的计算阈值 0.2633。
4
不同的步幅系数对迭代步数的影响
表 1 给出了在不同的步幅系数的条件下测试随机逼近算法达到收敛时的迭代次数。
3
表 1
不同步幅系数下随机逼近法的迭代次数
y f ( I ) I WXT
得到的,线性函数的相比于硬限幅函数,在这里其最大的特点就是线性函数是可微的。LMS 算法基于上式右侧递推得到,三种递推算法的核心递推环节通过求导得到,因此,失去线性 函数的条件,而换成硬限幅函数作为传递函数,以上算法均无法进行。
6
若采用硬限幅函数,那么我们只能运用硬限幅函数的权值递推式来求权值 6
神经元参数计算

神经元参数计算
要进行神经元参数计算,需要考虑以下几个方面:
1. 神经元的输入:神经元通常接收多个输入信号,每个输入信号都有一个相应的权重(或连接强度)。
输入信号可以是来自其它神经元的输出,或者外部输入。
每个输入信号乘以相应的权重后,再求和作为该神经元的输入。
2. 激活函数:神经元的输入经过加权求和后,需要经过一个激活函数来产生输出。
激活函数通常是非线性的,常见的激活函数有sigmoid函数、ReLU函数等。
3. 偏置项:神经元还可以有一个偏置项,即一个常数,它不依赖于输入。
偏置项在计算神经元的输入时,与对应的输入信号相乘后再求和。
下面是一个简单的示例来说明神经元参数的计算过程:
假设一个神经元接收两个输入信号,分别为x1和x2,对应的权重为w1和w2,偏置项为b。
神经元的激活函数为sigmoid 函数。
那么神经元的输入可以表示为:z = w1 * x1 + w2 * x2 + b
然后通过激活函数进行计算:a = sigmoid(z)
其中,sigmoid函数定义为:sigmoid(z) = 1 / (1 + e^(-z))
最后得到的输出a就是神经元的输出。
需要注意的是,上述示例只是一个简单的计算过程,实际的神经网络可能包含多个神经元和多个层次,参数的计算过程更加复杂。
在实际应用中,通常使用反向传播算法来计算神经网络中的参数。
神经网络算法的应用

神经网络算法的应用随着科技的不断发展,计算机技术也得到了飞速的发展。
其中,人工智能领域的发展为这一领域注入了新的活力,神经网络算法作为人工智能领域的基础之一,也得到了广泛的应用。
本文将重点探讨神经网络算法的应用,并进一步探讨未来的发展趋势。
一、神经网络算法的概述神经网络算法是一种模拟大脑神经元、神经网络工作方式的计算模型。
它是由多个神经元之间的互相连接构成的一个复杂的网络系统,每个神经元都有自己的权重,通过对权重的调整,神经网络可以学习与预测数据。
神经网络算法的流程如下:1.数据的输入:神经网络模型将数据输入到网络中,数据可以是数值型,文本型等格式。
2.权重初始化:神经网络算法会对初始的权重进行随机初始化。
3.前向传播:数据通过该层神经元的权重进行前向传播运算,得出该层输出结果。
4.后向传播:算法根据误差进行反向传播,得到对权重的调整方向,并进行修正。
5.权重更新:根据误差进行权重的调整。
6.重复迭代:根据设定的轮数或误差要求重复进行迭代。
二、神经网络算法的应用领域非常广泛,下面列举几个典型的应用案例。
1.金融神经网络可以用于预测金融市场趋势、股票价格变化等,通过神经网络模型的学习和预测,可以为投资者提供投资建议和决策支持,增加投资成功率。
2.医疗神经网络技术可以应用于医疗领域的疾病诊断、药品治疗、医学图像识别等方面。
在疾病诊断方面,神经网络可以通过学习病例数据,提高诊断的准确性和速度。
3.交通神经网络可以用于交通流量预测、车辆识别等方面,通过神经网络模型的建立和预测,可以提高公路交通运营效率、规划交通路线等,降低拥堵情况。
4.安全神经网络技术可以应用于信息安全、生物识别等方面。
在信息安全方面,神经网络可以用于密码学、网络安全等方面,提高网络安全性和保障数据安全。
在生物识别方面,神经网络可以应用于人脸识别、指纹识别等领域,提高识别的准确性和速度。
三、未来趋势随着人工智能领域的深入发展,神经网络算法也将会得到进一步的应用和发展,未来的发展趋势主要有以下几点。
第6章人工神经网络算法ppt课件
4.随机型神经网络 随机型神经网络其基本思想是:不但让网络的误差和能量函数向减小的方
向变化,而且还可按某种方式向增大的方向变化,目的是使网络有可能跳出局部 极小值而向全局最小点收敛。随机型神经网络的典型算法是模拟退火算法。
曲线越陡。
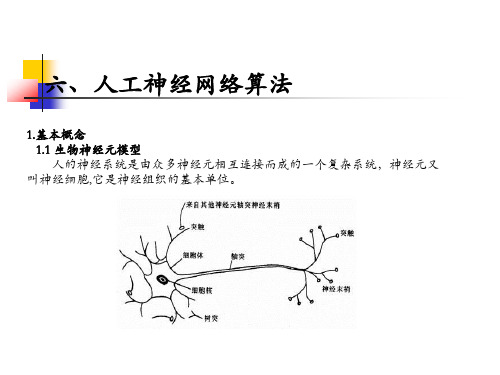
六、人工神经网络算法
1.基本概念 1.2 人工神经元模型 神经元采用了不同的激活函数,使得神经元具有不同的信息处理特性,并且
神经元的信息处理特性是决定神经网络整体性能的主要因素之一。 下面介绍四种常用的激活函数形式:
(4)高斯函数。高斯函数(也称钟型函数)也是极为重要的一类激活函数,常用 于径向基神经网络(RBF网络),其表达式为:
通过调整权值和阈值,使得误差能量达到最小时,网络趋于稳定状态,学习
结束。
(1)输出层与隐含层之间的权值调整。对每一个 wjk 的修正值为:
w jk
E
w jk
E
netk
netk w jk
J
式中: 为学习步长,取值介于(0,1),对式 netk wjkOj 求偏导得:
j0
netk wjk
Oj
x1
w1i
x2
w2ifΒιβλιοθήκη yixnwni
x0 1
六、人工神经网络算法
1.基本概念 1.2 人工神经元模型 在神经元中,对信号进行处理采用的是数学函数,通常称为激活函数、激励
函数或挤压函数,其输入、输出关系可描述为
u j
f
n
wij xi
j
i1
y f uj
式中xi i 1,2,,n是从其它神经元传来的输入信号; j 是该神经元的阈值;
单神经元自适应PID控制算法

单神经元自适应PID 控制算法一、单神经元PID 算法思想神经元网络是智能控制的一个重要分支,神经元网络是以大脑生理研究成果为基础,模拟大脑的某些机理与机制,由人工建立的以有向图为拓扑结构的网络,它通过对连续或断续的输入做状态响应而进行信息处理;神经元网络是本质性的并行结构,并且可以用硬件实现,它在处理对实时性要求很高的自动控制问题显示出很大的优越性;神经元网络是本质性的非线性系统,多层神经元网络具有逼近任意函数的能力,它给非线性系统的描述带来了统一的模型;神经元网络具有很强的信息综合能力,它能同时处理大量不同类型的输入信息,能很好地解决输入信息之间的冗余问题,能恰当地协调互相矛盾的输入信息,可以处理那些难以用模型或规则描述的系统信息。
神经元网络在复杂系统的控制方面具有明显的优势,神经元网络控制和辨识的研究已经成为智能控制研究的主流。
单神经元自适应PID 控制算法在总体上优于传统的PID 控制算法,它有利于控制系统控制品质的提高,受环境的影响较小,具有较强的控制鲁棒性,是一种很有发展前景的控制器。
二、单神经元自适应PID 算法模型单神经元作为构成神经网络的基本单位,具有自学习和自适应能力,且结构简单而易于计算。
传统的PID 则具有结构简单、调整方便和参数整定与工程指标联系紧密等特点。
将二者结合,可以在一定程度上解决传统PID 调节器不易在线实时整定参数,难以对一些复杂过程和参数时变、非线性、强耦合系统进行有效控制的不足。
2.1单神经元模型对人脑神经元进行抽象简化后得到一种称为McCulloch-Pitts 模型的人工神经元,如图2-1所示。
对于第i 个神经元,12N x x x 、、……、是神经元接收到的信息,12i i iN ωωω、、……、为连接强度,称之为权。
利用某种运算把输入信号的作用结合起来,给它们的总效果,称之为“净输入”,用i net 来表示。
根据不同的运算方式,净输入的表达方式有多种类型,其中最简单的一种是线性加权求和,即式 (2-1)。
单神经元PID算法在过热蒸汽温度控制中的应用研究

0 引言
在火 力发 电厂 中 ,锅 炉过 热蒸汽 温 度控制 系统
数 ( 123 ;K为 神 经 元 的 比例 系数 ,K> 。神 经 i ,,) - 0 元通 过关联 搜 索来 产 生控制 信 号 ,即
I 示。 N 图 中rk 为 设 定 值 ,y k 为 输 出值 ,转 换 器 () () 接 受 被 控 过 程 及 控 制 设 定 的 偏 差 状 态 ,转 换 成 为 单 神 经 元 学 习 控 制所 需 要 的状 态 量X () k , ,X( ) k
X() 其 中 X()ek ,X() ek一(一) X() 3 : k 1 = () 2 = () k1, 3 : k k e k
第3 卷 3
第1 期 O
2 1 — 0 上 ) [ 9 0 1 1 ( 81
l 匐 似 生
型 非 线 性 时 变 对 象 的动 态 品质 ,能 够 适 应 过 程 的 时 变 特 性 ,保 证 控 制 系统 在 最 佳 状 态 下 运 行 ,控
ቤተ መጻሕፍቲ ባይዱ
算 控 制 规 律 可 以得 到 所 期 望 的 优 化 效 果 ,根 据 线 性 二 次 型 最 优 控 制 ( QR)理 论 ,在 单 神 经 元 控 L 制 器 中 引入 二 次 型 性 能 指 标 ,借 助 最 优 控 制 中二
3
是提 高机组 热效 率 和保证机 组 安全运 行 的重要 组成 部分 。过 热蒸汽 温 度过高 ,可 能造 成过热 器 、蒸汽
A( = (_. u ) ∑ ( k )] } )
神经网络算法的代码实现详解

神经网络算法的代码实现详解神经网络算法是一种模拟人脑神经系统的计算模型,它通过构建多层神经元网络来实现对数据的学习与预测。
本文将对神经网络算法的代码实现进行详细解析,通过Python语言实现。
1.数据准备首先,我们需要准备训练数据和测试数据。
训练数据是用来训练神经网络的样本,通常包含一组输入数据和对应的输出数据。
测试数据则是用来测试训练后的神经网络模型的准确性。
2.构建神经网络结构接下来,我们需要构建神经网络的结构。
神经网络通常由多层神经元组成,每层神经元与上一层的神经元全连接。
我们可以使用Python的Numpy库来创建神经网络的结构,其中的矩阵运算能够高效地实现神经网络算法。
3.定义激活函数神经网络中,每个神经元都需要一个激活函数来对输入数据进行处理,并输出非线性的结果。
常用的激活函数有sigmoid函数、ReLU 函数等。
我们可以在构建神经网络结构时定义激活函数。
4.前向传播前向传播是指从输入层开始,逐层计算神经元的输出,直到输出层为止。
这一过程可以通过矩阵运算实现,其中每一层的输出都是上一层输出与权重矩阵的乘积再经过激活函数处理得到。
最终,输出层的输出即为神经网络的预测结果。
5.反向传播反向传播是指根据预测结果,逐层更新权重矩阵,以使得预测结果与实际结果尽可能接近。
反向传播算法通过计算误差项,逆向更新权重矩阵。
误差项的计算根据损失函数的不同而有所差异,常用的损失函数有均方误差、交叉熵等。
6.更新权重矩阵根据反向传播算法计算得到的误差项,我们可以更新每一层的权重矩阵。
更新的方法一般是使用梯度下降算法,通过计算每个权重的梯度值以及学习率,来逐步调整权重的取值。
7.训练神经网络模型在完成以上步骤后,我们可以开始训练神经网络模型。
训练过程即是重复进行前向传播和反向传播,以不断更新权重矩阵。
通过多次迭代,使得神经网络模型的预测结果逼近真实结果。
8.测试神经网络模型在训练完成后,我们需要使用测试数据对神经网络模型进行测试,以评估其性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Introduction--------------------------------------------------------------------------------神经网络是新技术领域中的一个时尚词汇。
很多人听过这个词,但很少人真正明白它是什么。
本文的目的是介绍所有关于神经网络的基本包括它的功能、一般结构、相关术语、类型及其应用。
“神经网络”这个词实际是来自于生物学,而我们所指的神经网络正确的名称应该是“人工神经网络(ANNs)”。
在本文,我会同时使用这两个互换的术语。
一个真正的神经网络是由数个至数十亿个被称为神经元的细胞(组成我们大脑的微小细胞)所组成,它们以不同方式连接而型成网络。
人工神经网络就是尝试模拟这种生物学上的体系结构及其操作。
在这里有一个难题:我们对生物学上的神经网络知道的不多!因此,不同类型之间的神经网络体系结构有很大的不同,我们所知道的只是神经元基本的结构。
The neuron--------------------------------------------------------------------------------虽然已经确认在我们的大脑中有大约50至500种不同的神经元,但它们大部份都是基于基本神经元的特别细胞。
基本神经元包含有synapses、soma、axon及dendrites。
Synapses负责神经元之间的连接,它们不是直接物理上连接的,而是它们之间有一个很小的空隙允许电子讯号从一个神经元跳到另一个神经元。
然后这些电子讯号会交给soma处理及以其内部电子讯号将处理结果传递给axon。
而axon会将这些讯号分发给dendrites。
最后,dendrites带着这些讯号再交给其它的synapses,再继续下一个循环。
如同生物学上的基本神经元,人工的神经网络也有基本的神经元。
每个神经元有特定数量的输入,也会为每个神经元设定权重(weight)。
权重是对所输入的资料的重要性的一个指标。
然后,神经元会计算出权重合计值(net value),而权重合计值就是将所有输入乘以它们的权重的合计。
每个神经元都有它们各自的临界值(threshold),而当权重合计值大于临界值时,神经元会输出1。
相反,则输出0。
最后,输出会被传送给与该神经元连接的其它神经元继续剩余的计算。
Learning--------------------------------------------------------------------------------正如上述所写,问题的核心是权重及临界值是该如何设定的呢?世界上有很多不同的训练方式,就如网络类型一样多。
但有些比较出名的包括back-propagation, delta rule及Kohonen训练模式。
由于结构体系的不同,训练的规则也不相同,但大部份的规则可以被分为二大类别- 监管的及非监管的。
监管方式的训练规则需要“教师”告诉他们特定的输入应该作出怎样的输出。
然后训练规则会调整所有需要的权重值(这是网络中是非常复杂的),而整个过程会重头开始直至数据可以被网络正确的分析出来。
监管方式的训练模式包括有back-propagation 及delta rule。
非监管方式的规则无需教师,因为他们所产生的输出会被进一步评估。
Architecture--------------------------------------------------------------------------------在神经网络中,遵守明确的规则一词是最“模糊不清”的。
因为有太多不同种类的网络,由简单的布尔网络(Perceptrons),至复杂的自我调整网络(Kohonen),至热动态性网络模型(Boltzmann machines)!而这些,都遵守一个网络体系结构的标准。
一个网络包括有多个神经元“层”,输入层、隐蔽层及输出层。
输入层负责接收输入及分发到隐蔽层(因为用户看不见这些层,所以见做隐蔽层)。
这些隐蔽层负责所需的计算及输出结果给输出层,而用户则可以看到最终结果。
现在,为免混淆,不会在这里更深入的探讨体系结构这一话题。
对于不同神经网络的更多详细资料可以看Generation5 essays尽管我们讨论过神经元、训练及体系结构,但我们还不清楚神经网络实际做些什么。
The Function of ANNs--------------------------------------------------------------------------------神经网络被设计为与图案一起工作- 它们可以被分为分类式或联想式。
分类式网络可以接受一组数,然后将其分类。
例如ONR程序接受一个数字的影象而输出这个数字。
或者PPDA32程序接受一个坐标而将它分类成A类或B类(类别是由所提供的训练决定的)。
更多实际用途可以看Applications in the Military中的军事雷达,该雷达可以分别出车辆或树。
联想模式接受一组数而输出另一组。
例如HIR程序接受一个…脏‟图像而输出一个它所学过而最接近的一个图像。
联想模式更可应用于复杂的应用程序,如签名、面部、指纹识别等。
The Ups and Downs of Neural Networks--------------------------------------------------------------------------------神经网络在这个领域中有很多优点,使得它越来越流行。
它在类型分类/识别方面非常出色。
神经网络可以处理例外及不正常的输入数据,这对于很多系统都很重要(例如雷达及声波定位系统)。
很多神经网络都是模仿生物神经网络的,即是他们仿照大脑的运作方式工作。
神经网络也得助于神经系统科学的发展,使它可以像人类一样准确地辨别物件而有电脑的速度!前途是光明的,但现在...是的,神经网络也有些不好的地方。
这通常都是因为缺乏足够强大的硬件。
神经网络的力量源自于以并行方式处理资讯,即是同时处理多项数据。
因此,要一个串行的机器模拟并行处理是非常耗时的。
神经网络的另一个问题是对某一个问题构建网络所定义的条件不足- 有太多因素需要考虑:训练的算法、体系结构、每层的神经元个数、有多少层、数据的表现等,还有其它更多因素。
因此,随着时间越来越重要,大部份公司不可能负担重复的开发神经网络去有效地解决问题。
NN 神经网络,Neural NetworkANNs 人工神经网络,Artificial Neural Networksneurons 神经元synapses 神经键self-organizing networks 自我调整网络networks modelling thermodynamic properties 热动态性网络模型++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++网格算法我没听说过好像只有网格计算这个词网格计算是伴随着互联网技术而迅速发展起来的,专门针对复杂科学计算的新型计算模式。
这种计算模式是利用互联网把分散在不同地理位置的电脑组织成一个“虚拟的超级计算机”,其中每一台参与计算的计算机就是一个“节点”,而整个计算是由成千上万个“节点”组成的“一张网格”,所以这种计算方式叫网格计算。
这样组织起来的“虚拟的超级计算机”有两个优势,一个是数据处理能力超强;另一个是能充分利用网上的闲置处理能力。
简单地讲,网格是把整个网络整合成一台巨大的超级计算机,实现计算资源、存储资源、数据资源、信息资源、知识资源、专家资源的全面共享。
HK算法1. 其实HK算法思想很朴实,就是在最小均方误差准则下求得权矢量。
他相对于感知器算法的优点在于,他适用于线性可分和非线性可分得情况,对于线性可分的情况,给出最优权矢量,对于非线性可分得情况,能够判别出来,以退出迭代过程。
2.在程序编制过程中,我所受的最大困扰是:关于收敛条件的判决。
对于误差矢量:e=x*w-b若e>0 则继续迭代若e=0 则停止迭代,得到权矢量若e〈0 则停止迭代,样本是非线性可分得,若e有的分量大于0,有的分量小于0 ,则在各分量都变成零,或者停止由负值转变成正值时,停机。
3.在程序编制中的注意点:1)关于0的判断,由于计算机的精度原因,严格等于零是很不容易的,而且在很多情况下也没有必要,则只要在0的一个可以接受的delta域内就可接受为零2)关于判断,迭代前后,变量是否发生变化在判断时,显然也不能直接判断a(i)==a(i+1)而应该|a(i)-a(i+1)|〈err4. HK详细代码如下:unction [w,flag]=HK(data)Iteration=20;flag=0;% [n,p]=size(data);n=size(data,1);b=ones(n,1)./10;c=0.6;xx=inv(data'*data)*data';w=xx*b;e=data*w-b;t=0;while (1)temp=min(e);temp1=max(e);if temp>-1e-4 && temp<0temp=0;endif temp>1e-3deltab=e+abs(e);b=b+c.*deltab;w=w+c.*xx*deltab;e=data*w-b;elseif temp>=0 && temp1<1e-4break;elseif temp1<0flag=1;break;elsedeltab=e+abs(e);b=b+c.*deltab;w=w+c.*xx*deltab;e=data*w-b;t=t+1;if t>=Iterationbreak;endendendendendend1.其实HK算法思想很朴实,就是在最小均方误差准则下求得权矢量。
他相对于感知器算法的优点在于,他适用于线性可分和非线性可分得情况,对于线性可分的情况,给出最优权矢量,对于非线性可分得情况,能够判别出来,以退出迭代过程。
2.在程序编制过程中,我所受的最大困扰是:关于收敛条件的判决。
对于误差矢量:e=x*w-b若e>0 则继续迭代若e=0 则停止迭代,得到权矢量若e〈0 则停止迭代,样本是非线性可分得,若e有的分量大于0,有的分量小于0 ,则在各分量都变成零,或者停止由负值转变成正值时,停机。
3.在程序编制中的注意点:1)关于0的判断,由于计算机的精度原因,严格等于零是很不容易的,而且在很多情况下也没有必要,则只要在0的一个可以接受的delta域内就可接受为零2)关于判断,迭代前后,变量是否发生变化在判断时,显然也不能直接判断a(i)==a(i+1)而应该|a(i)-a(i+1)|〈err4. HK详细代码如下:unction [w,flag]=HK(data)Iteration=20;flag=0;% [n,p]=size(data);n=size(data,1);b=ones(n,1)./10;c=0.6;xx=inv(data'*data)*data';w=xx*b;e=data*w-b;t=0;while (1)temp=min(e);temp1=max(e);if temp>-1e-4 && temp<0temp=0;endif temp>1e-3deltab=e+abs(e);b=b+c.*deltab;w=w+c.*xx*deltab;e=data*w-b;elseif temp>=0 && temp1<1e-4break;elseif temp1<0flag=1;break;elsedeltab=e+abs(e);b=b+c.*deltab;w=w+c.*xx*deltab;e=data*w-b;t=t+1;if t>=Iterationbreak;endendendendendend。