拟合,多元回归,聚类分析数据
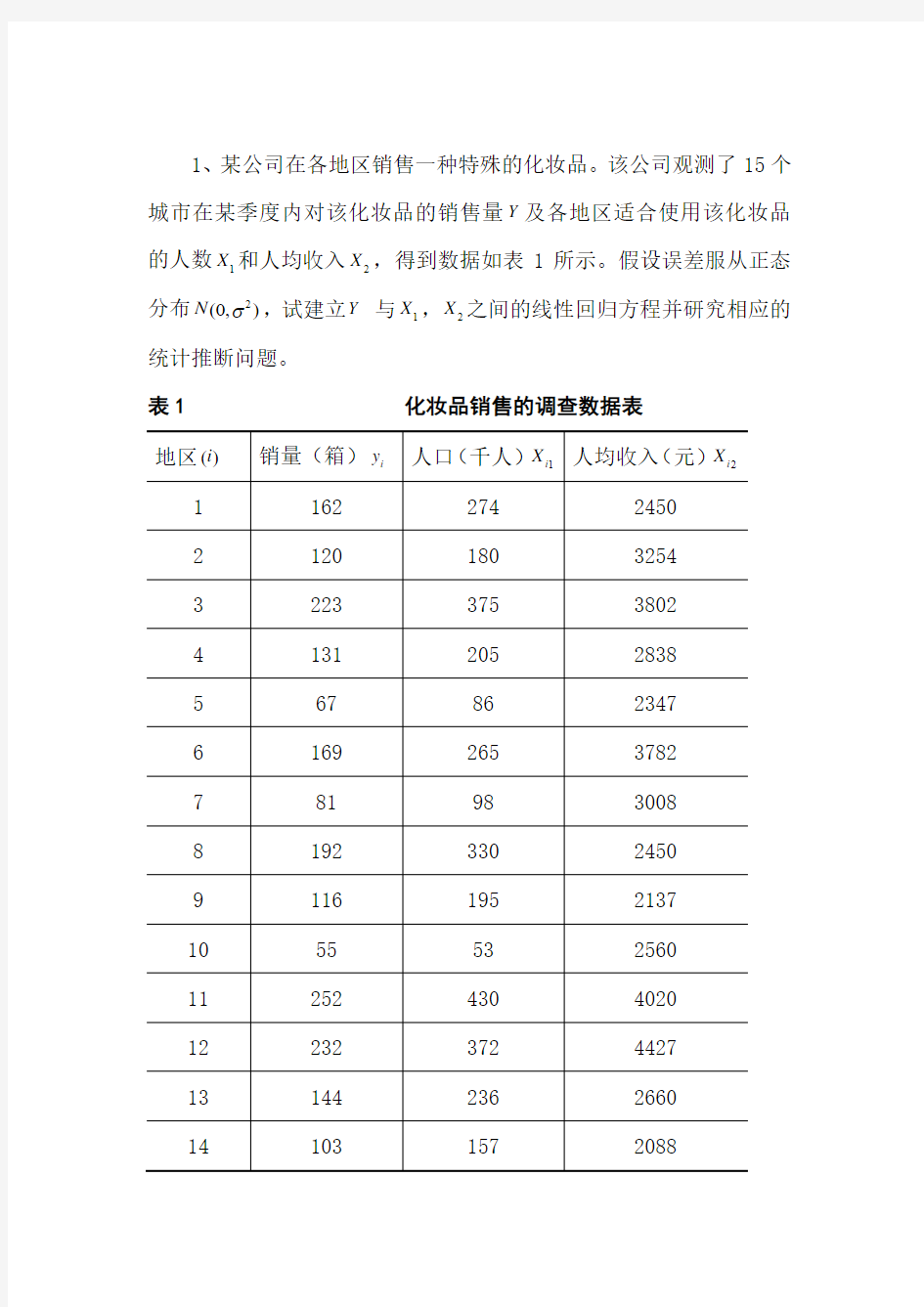

1、某公司在各地区销售一种特殊的化妆品。该公司观测了15个城市在某季度内对该化妆品的销售量Y及各地区适合使用该化妆品的人数
X和人均收入2X,得到数据如表1所示。假设误差服从正态1
分布2
N ,试建立Y与1X,2X之间的线性回归方程并研究相应的(0,)
统计推断问题。
表1 化妆品销售的调查数据表
2、1960~1986年美国人均可支配收入和个人消费的有关数据(单位:美元)。利用这些数据,建立消费预测的回归方程。
3、在某化合物的合成试验中,为了提高产量,选取了原料配比(
x)、溶剂量(2x)和反应时间(3x)三个因素,试验结果如表5所示。
1
试用线性回归模型来拟合试验数据。
表5 试验数据
4、襄樊市近几年的经济收入数据来分析该城市主要影响经济的因素,挖掘其发展潜力。
表2:襄樊市2006年3月-12月和2007年3月-11月统计数据表
5、一家电气销售公司的管理人员认为,每月的销售额是广告费用的函数,并想通过广告费用对月销售额作出估计。近8个月的销售额与广告费用数据
y
1x 2
x
月销售收入(万元)电视广告费用(万元)报纸广告费用(万元)
96 5.0 1.5
90 2.0 2.0
95 4.0 1.5
92 2.5 2.5
95 3.0 3.3
94 3.5 2.3
94 2.5 4.2
94 3.0 2.5
1)用电视广告费用作自变量,月销售额作因变量,建立估计的回
归方程。
2)用电视广告费用和报纸广告费用作自变量,月销售额作因变量,
建立估计的回归方程。
3)上述1)和2)所建立的估计方程,电视广告费用的系数是否相同?
对其回归系数分别进行解释。
4)根据问题2)所建立的估计方程,检验回归方程的线性关系是否显
著 ( =0.05)
6、某农场通过试验取得早稻收获量与春季降雨量和春季温度的数据试确定早稻收获量对春季降雨量和春季温度的二元线性回归方程。解释回归系数的实际意义。
收获量(公斤/公顷)
y 降雨量(毫米)
x1温度( )
x2
2250 25 6 3450 33 8 4500 45 10 6750 105 13 7200 110 14 7500 115 16 8250 120 17
0C
7、一家房地产评估公司想对某城市的房地产销售价格(y 1)与地产的评估价值(x 1)、房产的评估价值(x 2)和使用面积(x 3)建立一个模型,以便对销售价格作出合理预测。为此,收集了20栋住宅的房地产评估数据
销售价格(元/㎡)
地产估价(万元)
房产估价(万元)
使用面积(㎡)
6890 596 4497 18730 4850 900 2780 9280 5550 950 3144 11260 6200 1000 3959 12650 11650 1800 7283 22140 4500 850 2732 9120 3800 800 2986 8990 8300 2300 4775 18030 5900 810 3912 12040 4750 900 2935 17250 4050 730 4012 10800 4000 800 3168 15290 9700 2000 5851 24550 4550 800 2345 11510 4090 800 2089 11730 8000 1050 5625 19600 5600 400 2086 13440 3700 450 2261 9880 5000 340 3595 10760 2240 150 578
9620
写出估计的多元回归方程。
1) 在销售价格的总变差中,被估计的回归方程所解释的比例是多少?
2) 检验回归方程的线性关系是否显著( =0.05)。
y
1
x 2
x 3
x
3) 检验各回归系数是否显著(α=0.05) 。
8、随机抽取的15家大型商场销售的同类产品的有关数据
企业编号
销售价格(元)
购进价格(元)
销售费用(元)
1 1238 966 223
2 1266 894 257
3 1200 440 387
4 1193 664 310
5 110
6 791 339 6 1303 852 283
7 1313 804 302
8 1144 905 214
9 1286 771 304 10 1084 511 326 11 1120 505 339 12 1156 851 235 13 1083 659 276 14 1263 490 390 15
1246 696
316
1) 计算y 与x 1、y 与x 2之间的相关系数,是否有证据表明销售价格与购进价格、销售价格与销售费用之间存在线性关系?
2) 根据上述结果,你认为用购进价格和销售费用来预测销售价格是否有用?
3) 进行回归,并检验模型的线性关系是否显著(α=0.05) 。 4) 解释判定系数R 2,所得结论与问题2)中是否一致? 5) 计算x 1与x 2之间的相关系数,所得结果意味着什么?
y
1
x 2
x
锡克试验阴性率(%)随着年龄的增长而增高,某地查得儿童年龄(岁)X与锡克试验阴性率Y的资料如下,试拟合曲线。
年龄(岁) 1 2 3 4 5 6 7 锡克试验阴性率(%) 57.1 76.0 90.9 93.0 96.7 95.6 96.2
六组数据,分别设成x值和y值,拟合一条曲线,再总结出一个公式,用多项式的话,选用几次的多项式能够达到精度,有何评价标准。问题补充:x值y值
13.663 1095.295
15.41 1330.063
16.993 1643.16
19.513 2177.739
24.322 3330.34
26.157 3816.51
据国务院西部办公室统计数据得以下2004年数据:
省份邮电电信邮政电话总量固定电话移动电话互联网工业增加值
青海26.39 24.76 1.63 209.60 92.98 116.70 .
24.80
西藏9.82 8.89 .93 60.17 27.08 33.09 .
14.40
甘肃109.04 102.48 6.56 835.00 477.00 358.00 . 505.12
内蒙古232.20 223.60 8.60 1593.80 499.60 1094.20 . 776.84
新疆153.06 145.66 7.40 1011.60 522.26 489.40
78.10 616.85
广西268.06 256.94 11.12 1694.20 812.00 882.20 147.00 595.63
云南124.20 . . 939.00 437.00 502.00 103.00 881.19
贵州112.10 101.60 5.50 663.70 332.60 331.10 63.60 438.40
重庆174.99 165.60 . 1454.00 . . 121.80 579.67
宁夏39.20 36.90 2.30 278.20 119.60 158.60 32.10 163.07
陕西125.23 111.43 13.80 1578.91 792.02 786.89 46.43 870.71
四川336.10 . . 2884.50 1369.90 1514.60 254.00 1546.45
为了更深入了解我国人口的文化程度状况,现利用1990年全国人口普查数据对全国30个省、直辖市、自治区进行聚类分析。分析选用了三个指标:(1)大学以上文化程度的
人口占全部人口的比例(DXBZ);(2)初中文化程度的人口占全部人口的比例(CZBZ);(3)文盲半文盲人口占全部人口的比例(WMBZ)、分别用来反映较高、中等、较低文化程度人口的状况,原始数据如下表:
1990年全国人口普查文化程度人口比例(%)
数据来源:《中国计划生育全书》第886页。
计算样品之间的相似系数,使用最长距离法、重心法和Ward法,将上机计算结果按样品号画出聚类图如下:
0 5 10 15 20 25
根据聚类图把30个样品分为四类能更好地反映我国实际情况。
第一类:北京、天津、山西、辽宁、吉林、黑龙江、上海。其中大多是东部经济、文化较发达的地区。
第二类:安徽、宁夏、青海、甘肃、云南、贵州。其中大多是西部经济、文化发展较慢的地区。
第三类:西藏。经济、文化较落后的地区。
第四类:其它省、直辖市、自治区。经济、文化在全国处于中等水平。
例2根据信息基础设施的发展状况,对世界20个国家和地区进行分类。
country call movecall fee computer mips
1 美国631.60 161.90 0.36 403.00 26073.00
2 日本498.40 143.20 3.57 176.00 10223.00
3 德国557.60 70.60 2.18 199.00 11571.00
4 瑞典684.10 281.80 1.40 286.00 16660.00
5 瑞士644.00 93.50 1.98 234.00 13621.00
这里选取了发达国家、新兴工业化国家、拉美国家、亚洲发展中国家、转型国家等不同类型的20个国家作Q 型聚类分析。描述信息基础设施的变量主要有六个:(1)Call —每千人拥有电话线数,(2)movecall —每千房居民蜂窝移动电话数,(3)fee —高峰时期每三分钟国际电话的成本,(4)Computer —每千人拥有的计算机数,(5)mips —每千人中计算机功率《每秒百万指令》,(6)net —每千人互联网络户主数。数据摘自《世界竞争力报告—1997》。
由于数据存在量纲和数量级的差别,在聚类之前先进行标准化处理,计算样品之间的距离采用欧氏距离。下面分别用最长距离法、重心法、离差平方和法进行计算,其结果如下表:
最长距离法
重心法
Brazil Mexico
Porland Hungary Malasia Chile
Russian Tailand Indian Taiwan
Korea Japan German France
Singapo British Switzer Sweden
Denmar USA Brazil Mexico
Porland Hungary Chile Malasia Russian Tailand Indian
10
离差平方和法见下页图。
从聚类图看,本例用三种方法聚类结果基本一致,而最长距离法和重心法所得结果更接近一致,结合实际情况分析采用离差平方和法把20个国家分为两类:
第Ⅰ类:巴西、墨西哥、波兰、匈牙利、智利、俄罗斯、泰国、印度、马来西亚。
第Ⅱ类:瑞典、丹麦、美国、中国台湾、韩国、日本、德国、法国、新加坡、英国、瑞士。
其中第Ⅰ类中的国家为转型国家和亚洲、拉美发展中国家,这些国家经济较不发达,基础设施薄弱,属于信息基础设施比较落后的国家;第Ⅱ类中的国家是美、日、欧洲发达国家与新兴工业化国家中国台湾、新加坡、韩国。新兴工业化国家这几十年来发展迅速,努力赶超发达国家,在信息基础设施的发展上已非常接近发达国家,而发达国家中美国、瑞典、丹麦的信息基础设施发展最为良好。
物联网大数据聚类分析方法和技术探讨
物联网大数据聚类分析方法和技术探讨 发表时间:2019-09-11T15:11:03.983Z 来源:《基层建设》2019年第16期作者:吴政[导读] 摘要:文章先分析了物联网关键技术以及数据发现等相关技术,随后介绍了聚类分析方法,包括关键算法和技术流程,希望能给相关人士提供有效参考。 广州市汇源通信建设监理有限公司广东省广州市 510220 摘要:文章先分析了物联网关键技术以及数据发现等相关技术,随后介绍了聚类分析方法,包括关键算法和技术流程,希望能给相关人士提供有效参考。 关键词:物联网;大数据;聚类分析 引言:物联网感知层中的无线射频技术是无线通信技术,具有准确识别目标物的功能。在RFID技术不断发展的背景下,其在制造业和电商行业中发挥了巨大的作用,随着数据复杂度的提高,和数据量的扩大,需要对数据存储和数据处理技术进行创新研究,促进大数据技术架构优化设计。 一、物联网关键技术分析 物联网其实是指通过信息传感相关红外感应器、定位系统和激光扫描器,在射频识别条件下将待测物体和网络之间进行有效连接,从而实现全方位物体识别、定位、跟踪管理和全过程监控等功能。物联网的诞生进一步改变了原有的识别技术,对现代化信息改革具有重要的促进作用。随着时代的发展,社会中的多个领域也逐渐将注意力转移到物联网领域当中。物联网相关技术包括以下三种:第一是数据处理和现代通信。现代通信是物联网基础支持,其中具有代表性的是无线智能网络。结合宽带通信的帮助,大部分领域都开始创建多媒体通信,同时相关技术也呈现出不断发展的趋势。第二是智能终端,这部分是物联网整个网络中的核心内容,其中包括智能电话和智能型PDA,可以利用传感器精确采集信息,全面识别判断各种图像。第三是信息安全。将物联网有效应用到各个领域当中,需要进一步确保信息安全,为此需要合理使用相应的加密方法对各种实时访问进行全面监控,进行系统化的安全管理和访问。对于当下的物联网而言,只有的网络状态下才能对各种物体进行准确识别。 二、数据发现 模式识别即利用逻辑关系、文字、数值等内容表征事物现象的信息,实施识别、分析和处理的过程。模式识别也可以称作模式分类,具体包括无监督和监督模式识别,两种模式之间的差异时样本类型已知状态。其中的监督模式是在已知样本类型的基础上进行识别,而无监督则是在不知道样本类型的基础上进行识别。通过计算机识别的目标可以是抽象的也可以是具体的,具体的包括图像、声音、文字等内容,而抽象的包括程度和状态等内容,模式信息即把识别对象和数字信息清除区分开来,这种技术涉及范围较广,包括人工智能、数据库、统计学等内容,是各种技术的综合。在数据挖掘中,模式发现是其中的核心内容,数据挖掘相关任务包括分类、关联、聚类等形式。数据库相关知识模式发现流程如图1所示: 在处理RFID相关事件时,应该先详细解析事件定义,随后根据事件流中各种事件的定义关系,对已形成的模式关系实施定义分析,随后按照事件之间的对应关系实施量化,在量化后距离基础上实施聚类分析。该部分定义中,先对事件进行解析,将其转化为原子事件,随后对其定义,在已经完成定义的原子实践基础上,再对现实事件中的各种关系进行定义,同时分析交易事件中的属性量化指标。原子事件即将事件定义成一个,包括事件标识符ID,也是唯一的标记;DOMAIN是交易事件中问题域实际位置;ALIAS是事件名称,和命名事件相关的一种名称;TYPE是事件种类,和问题域具有一定联系,可以是相关研发人员进行自定义操作,同时也可以是系统自带;TIME是事件出现时间;STIMULATION是激发事件的基础条件,比如快递运输中的某一物品被RFID读取后,证明该物品处于被签收状态,其中的激发因素便是被签收,如果没有被RFID识别器解读,证明该物品尚未发出,也不会出现任何事情。LAOCATION是指事件出现的位置,和事件相关性具有一定联系。 三、聚类分析技术方法 (一)关键算法 第一是平均算法,这种算法从本质上来看是以聚类划分为基础的,在近几年平均算法逐渐广泛应用开来。利用这种算法可以对相关对象进行合理划分,将其分成各种类型的簇。也因此对象组之间也呈现出一种相似性特点。如果是针对特定类型的数据分析工作,则关注点需要放在数据集和数据簇总数上,并从中挑选出可分析数据集。对各组别数据对象进行分配,便能规划处具有较强相似性的簇平均值。第二是分解奇异值算法,这种算法是以特定矩阵为基础,其中包含实数或复数的矩阵,如果该种类型的矩阵存在,便可以直接实施分解奇异值的操作。从整个矩阵范围内分析,涉及到M×M矩阵,这种矩阵类型是一种半正定和对角矩阵。分解奇异值还会涉及到共轭矩阵,并把其看做奇异值分解。从当下的实际发展状况分析,通常可以利用特定类型仿真软件分解相关数值,随后通过归纳得到函数式[1]。 第三是主成分分析算法,这种算法也可以叫做PCA分析办法,正常情况下,如果是多种算法变量,可以利用线性变换方法促进全过程实现简化变换的目标,或利用多元统计方式进行算法分析。从信息分析和数据分析两种视角入手,分析主成分其核心价值是创建对应的数据集,但不能遗漏全方位简化运算。在分析主成分的基础上,降低数据集维度,可以适当保留一些低阶的主成分,忽略高阶成分。第四是决策树学习,其属于一种概率分析图解方法,这种方法需要以事件概率为基础前提,针对不同类型的事件进行系统解析。决策树重点针对特殊期望值,保证其最终结果大于零。同时决策树还涉及到可行性判断和决策分析等方面。
多元线性回归模型
多元线性回归模型 1 多元线性回归模型 1.1 多元回归模型的构建名称多元线性回归模型优先级高描述由于经济现象的复杂性,一个被解释变量往往受多个解释变量的影响.多元回归模型就是在方程式中有两个或两个以上自变量的线性回归模型.多元线性回归预测是用多元线性回归模型,对具有线性趋势的税收问题,使用多个影响因素所作的预测.要求输入有指标需要进行预测的cube.该cube由实施人员在实施过程中根据客户的具体需要定制,该cube中的各个测量值是相关的,各维度是与预测分析有联系的.处理由用户选择回归模型分析角度和分析指标(包括因变量和自变量.注意:此处的分析指标是指cube中的测量值,下同),系统进行回归方程的拟合以及假设检验.展示回归方程式及假设检验的结果,并利用回归方程式进行预测.具体操作步骤如下: 分析角度的选取依照以下原则: 1. 选择分析角度和分析指标(包括因变量和自变量). 若对时间序列数据的回归分析,时间维必须在同一层次上,否则,系统给出下列提示信息:"分析角度的选择有误,时间维必须在同一层次上,请做修改!",如果用户不做相应的修改,则回归模型不进行构建.其它的维度原则上只能选取一个成员,若存在选择多个的情况,系统给出相应的警告提示:"分析角度的选择可能有误,请检查!",但允许用户在不进行任何修改的情况下继续回归模型的构建;所选中的时间维成员个数必须多于"自变量的个数+3",否则给出下列提示信息:"数据量太少,不能完成回归模型的构建"; 若进行横截面数据的回归分析,除时间维外的其它维度中必须有一个是选择所有成员的,时间维只能
选择一个维成员,否则给出下列出错信息:"不同时间点的横截面数据没有可比性,不适合进行回归分析!" 如果用户不做相应的修改,则回归模型不进行构建.对于选取的所有成员的维度,其成员个数必须多于"自变量的个数+3",否则给出下列提示信息:"数据量太少,不能完成回归模型的构建"; 分析指标(包括自变量和因变量)的选取依照下列原则. 自变量的选择.自变量可以选择了多个分析指标. 因变量的选择.因变量只能选取一个指标,在编码时必须对其进行设置. 2. 回归方程的拟合回归分析原理是利用具有因果关系的经济变量的样本观测量,按照一定的实现原理来建立能够使被解释变量的计算值与实际值误差最小的回归方程,以此作为研究对象总体模型的估计参数.多元线性回归模型的构建就是求出因变量(以y表示)自变量(以表示,其中M为自变量的个数)的线性关系式: 回归模型的拟合就是利用最小二乘法求出参数的估计值(其中i=1,2,…,M).具体求解的过程如下:假设已从cube中读入了因变量(以y表示)的N(N>3)个数据,记为,自变量的(其中i=1,2,…,M)的N(N>3)个数据,记为,(注意:此处需要用一个N×M 的二维数组存放自变量的数据,数组中的每一列存放一个测量值的数据,此处与报表中所显示的格式是相同的,在报表中,一个测量值的数据也是用一个列来显示的.)参数的计算请参见下面的文档: 3. 回归结果的呈现显示回归方程式在界面上显示回归方程式 4. 回归模型的假设检验构建一个经济计量模型会涉及到模型的形式,自变量的参数,模型的总体效果等的问题,因此,利用最小二乘法估计参数构成一元线性回归模型后,还需要进行拟合优度检验,t检验和F检验等统计检验.
eviews多元线性回归案例分析
中国税收增长的分析 一、研究的目的要求 改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为519.28亿元到2002年已增长到17636.45亿元25年间增长了33倍。为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。 影响中国税收收入增长的因素很多,但据分析主要的因素可能有:(1)从宏观经济看,经济整体增长是税收增长的基本源泉。(2)公共财政的需求,税收收入是财政的主体,社会经济的发展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。(3)物价水平。我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。(4)税收政策因素。我国自1978年以来经历了两次大的税制改革,一次是1984—1985年的国有企业利改税,另一次是1994年的全国范围内的新税制改革。税制改革对税收会产生影响,特别是1985年税收陡增215.42%。但是第二次税制改革对税收的增长速度的影响不是非常大。因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。 二、模型设定 为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收”(简称“税收收入”)作为被解释变量,以放映国家税收的增长;选择“国内生产总值(GDP)”作为经济整体增长水平的代表;选择中央和地方“财政支出”作为公共财政需求的代表;选择“商品零售物价指数”作为物价水平的代表。由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。所以解释变量设定为可观测“国内生产总值(GDP)”、“财政支出”、“商品零售物价指数” 从《中国统计年鉴》收集到以下数据 财政收入(亿元) Y 国内生产总值(亿 元) X2 财政支出(亿 元) X3 商品零售价格指 数(%) X4 1978519.283624.11122.09100.7 1979537.824038.21281.79102 1980571.74517.81228.83106
空间聚类的研究现状及其应用_戴晓燕
空间聚类的研究现状及其应用* 戴晓燕1 过仲阳1 李勤奋2 吴健平1 (1华东师范大学教育部地球信息科学实验室 上海 200062) (2上海市地质调查研究院 上海 200072) 摘 要 作为空间数据挖掘的一种重要手段,空间聚类目前已在许多领域得到了应用。文章在对已有空间聚类分析方法概括和总结的基础上,结合国家卫星气象中心高分辨率有限区域分析预报系统产品中的数值格点预报(HLAFS)值,运用K-均值法对影响青藏高原上中尺度对流系统(MCS)移动的散度场进行了研究,得到了一些有意义的结论。 关键词 空间聚类 K-均值法 散度 1 前言 随着GPS、GI S和遥感技术的应用和发展,大量的与空间有关的数据正在快速增长。然而,尽管数据库技术可以实现对空间数据的输入、编辑、统计分析以及查询处理,但是无法发现隐藏在这些大型数据库中有价值的模式和模型。而空间数据挖掘可以提取空间数据库中隐含的知识、空间关系或其他有意义的模式等[1]。这些模式的挖掘主要包括特征规则、差异规则、关联规则、分类规则及聚类规则等,特别是聚类规则,在空间数据的特征提取中起到了极其重要的作用。 空间聚类是指将数据对象集分组成为由类似的对象组成的簇,这样在同一簇中的对象之间具有较高的相似度,而不同簇中的对象差别较大,即相异度较大。作为一种非监督学习方法,空间聚类不依赖于预先定义的类和带类标号的训练实例。由于空间数据库中包含了大量与空间有关的数据,这些数据来自不同的应用领域。例如,土地利用、居住类型的空间分布、商业区位分布等。因此,根据数据库中的数据,运用空间聚类来提取不同领域的分布特征,是空间数据挖掘的一个重要部分。 空间聚类方法通常可以分为四大类:划分法、层次法、基于密度的方法和基于网格的方法。算法的选择取决于应用目的,例如商业区位分析要求距离总和最小,通常用K-均值法或K-中心点法;而对于栅格数据分析和图像识别,基于密度的算法更合适。此外,算法的速度、聚类质量以及数据的特征,包括数据的维数、噪声的数量等因素都影响到算法的选择[2]。 本文在对已有空间聚类分析方法概括和总结的基础上,结合国家卫星气象中心高分辨率有限区域分析预报系统产品中的数值格点预报(HLAFS)值,运用K-均值法对影响青藏高原上中尺度对流系统(MCS)移动的散度场进行了研究,得到了一些有意义的结论。 2 划分法 设在d维空间中,给定n个数据对象的集合D 和参数K,运用划分法进行聚类时,首先将数据对象分成K个簇,使得每个对象对于簇中心或簇分布的偏离总和最小[2]。聚类过程中,通常用相似度函数来计算某个点的偏离。常用的划分方法有K-均值(K-means)法和K-中心(K-medoids)法,但它们仅适合中、小型数据库的情形。为了获取大型数据库中数据的聚类体,人们对上述方法进行了改进,提出了K-原型法(K-prototypes method)、期望最大法EM(Expectation Maximization)、基于随机搜索的方法(ClAR ANS)等。 K-均值法[3]根据簇中数据对象的平均值来计算 ——————————————— *基金项目:国家自然科学基金资助。(资助号: 40371080) 收稿日期:2003-7-11 第一作者简介:戴晓燕,女,1979年生,华东师范大学 地理系硕士研究生,主要从事空间数 据挖掘的研究。 · 41 · 2003年第4期 上海地质 Shanghai Geology
多元线性回归模型的案例分析
1. 表1列出了某地区家庭人均鸡肉年消费量Y 与家庭月平均收入X ,鸡肉价格P 1,猪肉价格P 2与牛肉价格P 3的相关数据。 年份 Y/千 克 X/ 元 P 1/(元/千克) P 2/(元/千克) P 3/(元/千克) 年份 Y/千克 X/元 P 1/(元/ 千克) P 2/(元/ 千克) P 3/(元/千克) 1980 2.78 397 4.22 5.07 7.83 1992 4.18 911 3.97 7.91 11.40 1981 2.99 413 3.81 5.20 7.92 1993 4.04 931 5.21 9.54 12.41 1982 2.98 439 4.03 5.40 7.92 1994 4.07 1021 4.89 9.42 12.76 1983 3.08 459 3.95 5.53 7.92 1995 4.01 1165 5.83 12.35 14.29 1984 3.12 492 3.73 5.47 7.74 1996 4.27 1349 5.79 12.99 14.36 1985 3.33 528 3.81 6.37 8.02 1997 4.41 1449 5.67 11.76 13.92 1986 3.56 560 3.93 6.98 8.04 1998 4.67 1575 6.37 13.09 16.55 1987 3.64 624 3.78 6.59 8.39 1999 5.06 1759 6.16 12.98 20.33 1988 3.67 666 3.84 6.45 8.55 2000 5.01 1994 5.89 12.80 21.96 1989 3.84 717 4.01 7.00 9.37 2001 5.17 2258 6.64 14.10 22.16 1990 4.04 768 3.86 7.32 10.61 2002 5.29 2478 7.04 16.82 23.26 1991 4.03 843 3.98 6.78 10.48 (1) 求出该地区关于家庭鸡肉消费需求的如下模型: 01213243ln ln ln ln ln Y X P P P u βββββ=+++++ (2) 请分析,鸡肉的家庭消费需求是否受猪肉及牛肉价格的影响。 先做回归分析,过程如下: 输出结果如下:
SPSS聚类分析和判别分析论文
S P S S聚类分析和判别分析 论文 Prepared on 22 November 2020
基于聚类分析的我国城镇居民消费结构实证分析摘要:近年来,我国城镇居民的整体消费水平逐渐提高,但各地区间的消费结构仍存在较大差别。文章选用8个城镇居民消费结构统计指标,采用欧式距离平方和离差平方和法,对我国31个省、直辖市及自治区的2013年城镇居民消费结构进行聚类分析和比较研究。这不仅从总体上掌握了我国消费结构类型的地区分布,而且系统分析了我国各地区消费结构的特点及产生原因,为国家制定消费政策提供了决策依据。 关键词:消费结构;聚类分析;判别分析;政策建议; 一、引言 近年来,随着我国经济的快速发展,城镇居民的收入不断增加,并且在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,我国各地区城镇居民的消费支出也强劲增长,消费结构发生了巨大的变化,结构不合理现象也得到了一定程度的调整。但是,由于各地区的经济发展不平衡及原有经济基础的差异,使各地区的消费结构仍存在着明显差别。为了进一步改善消费结构,正确引导消费,提高我国城市居民的消费水平和生活质量,有必要考察我国各地区城镇居民的消费结构之间的异同并进行比较研究,以期发现特点和规律,从宏观上把握各地区城镇居民的消费现状和不同地区消费水平的差异,为提高我国各地区消费水平和谐增长提供决策依据。 二、消费结构的数据分析 消费结构指居民在生活消费过程中,不同类型消费的比例及其相互之间的配合、替代、制约的关系。就其数量关系来看,消费结构是指在消费过程中不同商品或劳务消费支出占居民总消费支出的比重,反映了一定社会经济条件下人们对各类商品及劳务的需求结构,体现一国或各地区的经济发展水平和居民生活状况。 (一)数据来源 为了更加深入地了解我国城镇居民消费结构,先利用2013年全国数据(如表1所示),对全国31个省、直辖市、自治区进行聚类分析。分析采用选用了城镇居民食品、衣着、居住、家庭用品及服务设备、医疗保健、交通和通信、教育文化娱乐服务、其它商品和服务八项指标,分别用来反映较高、中等、较低居民消费结构。
多元线性回归与曲线拟合――
第十章:多元线性回归与曲线拟合―― Regression菜单详解(上) (医学统计之星:张文彤) 上次更新日期: 10.1 Linear过程 10.1.1 简单操作入门 10.1.1.1 界面详解 10.1.1.2 输出结果解释 10.1.2 复杂实例操作 10.1.2.1 分析实例 10.1.2.2 结果解释 10.2 Curve Estimation过程 10.2.1 界面详解 10.2.2 实例操作 10.3 Binary Logistic过程 10.3.1 界面详解与实例 10.3.2 结果解释 10.3.3 模型的进一步优化与简单诊断 10.3.3.1 模型的进一步优化 10.3.3.2 模型的简单诊断 回归分析是处理两个及两个以上变量间线性依存关系的统计方法。在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。回归分析就是用于说明这种依存变化的数学关系。 §10.1Linear过程 10.1.1 简单操作入门 调用此过程可完成二元或多元的线性回归分析。在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。
例10.1:请分析在数据集Fat surfactant.sav中变量fat对变量spovl的大小有无影响? 显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。 回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。 这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。 10.1.1.1 界面详解 在菜单中选择Regression==>liner,系统弹出线性回归对话框如下: 除了大家熟悉的内容以外,里面还出现了一些特色菜,让我们来一一品尝。
SPSS多元线性回归分析实例操作步骤
SPSS 统计分析 多元线性回归分析方法操作与分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK.
第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise. 进入如下界面: 2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue. 4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.
肤色在各颜色空间的聚类分析
肤色在各颜色空间的聚类分析 摘要肤色是人体表面最显著的特征之一。对不同肤色在RGB、YCbCr颜色空间内和同一肤色在不同亮度环境下的聚类情况进行深入的分析研究,发现肤色在YCbCr空间内聚类效果更好,更适合做肤色分割。然后在此基础上对黑色肤色、黄色肤色及白色肤色在YCbCr空间内进行肤色分割,达到较好的分割效果。 关键词肤色;颜色空间;肤色分割;YCbCr空间 肤色是人体表面最显著的特征之一,由于它对姿势、旋转、表情等变化不敏感,因此将人体的肤色特征应用于人脸检测与识别、表情识别、手势识别具有很大的优势,所以肤色特征是人脸识别、表情识别、与手势识别中最为常用的分割方法。然而,若要利用肤色进行分割,我们首先应该对肤色以及肤色的聚类情况进行分析。 世界上的人种主要有三种,即尼格罗—澳大利亚人种(黑色皮肤),蒙古人种(黄色皮肤),欧罗巴人种(白色皮肤)。尽管人的肤色因人种的不同而不同,呈现出不同的颜色,但是有学者指出:排除亮度、周围环境等对肤色的影响后,皮肤的色调基本一致。本文对在不同环境下的不同肤色进行取样,然后分别在RGB、YCbCr颜色空间进行统计,从而对比分析肤色在各颜色空间聚类的情况。 1肤色在各颜色空间的聚类比较 1.1不同肤色在RGB和YCbCr颜色空间上的分布 图1—图2给出了黄色、黑色和白色肤色分别在RGB、YCbcr空间的分布情况。 由图1—图2可以得出,不同肤色在RGB、YCbCr空间的分布有如下特征: 1)不同肤色在不同颜色空间均分布在很小的范围内。 2)不同肤色在不同颜色空间内不是随机分布,而是在某固定区域呈聚类分布。 3)不同肤色在YCbCr空间内分布的聚类状态要好于在RGB空间内分布的聚类状态。 4)不同肤色在亮度上的差异远远高于在色度上的差异。 1.2肤色在不同亮度下的分布 图3—图4给出了不同亮度下的同一肤色分别在RGB、YCbCr空间的分布情况。图(a)至图(d)的肤色来源于同一人在不同亮度下的照片。
多元线性回归实例分析
SPSS--回归-多元线性回归模型案例解析!(一) 多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为: 毫无疑问,多元线性回归方程应该为: 上图中的x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示: 那么,多元线性回归方程矩阵形式为: 其中:代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。 2:无偏性假设,即指:期望值为0 3:同共方差性假设,即指,所有的随机误差变量方差都相等 4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。 今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入) 如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0.05,当概率值大于等于0.1时将会被剔除)
(完整word版)多元线性回归模型案例分析
多元线性回归模型案例分析 ——中国人口自然增长分析一·研究目的要求 中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。 影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。 二·模型设定 为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。暂不考虑文化程度及人口分布的影响。 从《中国统计年鉴》收集到以下数据(见表1): 表1 中国人口增长率及相关数据
设定的线性回归模型为: 1222334t t t t t Y X X X u ββββ=++++ 三、估计参数 利用EViews 估计模型的参数,方法是: 1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对 话框“Workfile Range ”。在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。其中已有变量:“c ”—截距项 “resid ”—剩余项。在“Objects ”菜单中点击“New Objects”,在“New Objects”对话框中选“Group”,并在“Name for Objects”上定义文件名,点击“OK ”出现数据编辑窗口。 年份 人口自然增长率 (%。) 国民总收入(亿元) 居民消费价格指数增长 率(CPI )% 人均GDP (元) 1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040 2006 5.38 213132 1.5 16024
数学建模模拟题,图论,回归模型,聚类分析,因子分析等 (48)
第11章第2题 摘要 本题分析4 种化肥和3 个小麦品种对小麦产量的影响,以及二者交互作用对小麦产量的影响,可视为两因素方差分析,即化肥和小麦品种两个因素,4种化肥可看作是化肥的四个不同水平,3个小麦品种也可以看作是小麦品种的三个不同水平。 试验的目的是分析化肥的四个不同水平以及小麦品种的三个不同水平对小麦产量有无显着性影响。 关键词:方差分析显着性化肥种类小麦品种
一.问题重述 为了分析4 种化肥和3 个小麦品种对小麦产量的影响,把一块试验田等分成36个小块,分别对3种种子和四种化肥的每一种组合种植3 小块田,产量如表1所示(单位公斤),问不同品种、不同种类的化肥及二者的交互作用对小麦产量有无显着影响。 二.问题分析 本题意在分析四种化肥和三种小麦品种对小麦产量的影响,以及二者交互作用对小麦产量的影响,为两因素方差分析问题,即化肥和小麦品种两个因素,4种化肥可看作是化肥的四个不同水平,3个小麦品种也可以看作是小麦品种的三个不同水平。通过对这两种因素的不同水平及交互作用的分析,从而分析 4 种化肥和3 个小麦品种对小麦产量的影响。 三.模型假设 1.假设只有化肥种类和小麦品种两个因素,其他因素对试验结果不构成影响。 2.假设不存在数据记录错误。 3.假设每一块试验田本身各项指标相同,不会影响结果。 四.符号说明 数字1,2,3,4——不同的化肥种类 数字1,2,3——不同的小麦品种 五.模型建立 将化肥种类和小麦品种视为两个因素,四种化肥种类看作是化肥种类的四个不同水平,三个小麦品种看作是小麦品种的三个不同水平,将表1的数据进行整理,如表2所示。
六.模型求解 将表2数据导入到spss软件中,进行两因素方差检验,得到结果如下:表3
主成分分析和聚类分析
北京建筑工程学院 理学院信息与计算科学专业实验报告 课程名称《数据分析》实验名称《主成分分析和聚类分析》实验地点:基础楼C-423日期__2016.5.5_____ 姓名张丽芝班级信131 学号201307010108___指导教师王恒友成绩 (1)熟悉利用主成分分析进行数据分析,能够使用SPSS软件完成数据的主成分分析; (2)熟悉利用聚类分析进行数据分析,能够运用主成分分析的结果,做进一步分析,如聚类分析、回归分析等,能够使用SPSS软件完成该任务。 【实验要求】 根据各个题目的具体要求,分别运用SPSS软件完成实验任务。 【实验内容】 1、表4.9(数据见exercise4_5.txt)给出了1991年我国30个省市、城镇居民的月平均 消费数据,所考察的八个指标如下:(单位均为元/人) X1: 人均粮食支出; X2:人均副食支出; X3: 人均烟酒茶支出; X4: 人均其他副食支出; X5:人均衣着商品支出; X6: 人均日用品支出; X7: 人均燃料支出; X8: 人均非商品支出。 (1)求样本相关系数矩阵R。 (2)从R出发做主成分分析,求出各主成分的贡献率及前两个主成分的累积贡献率; 2、(1)对题1中的数据,按照原有的八个指标,对30个省份进行聚类,给出分为3类的聚类结果。 (2)利用题1得到的前2个主成分指标,分别按最短距离法(最近邻居距离)、最长距离法(最远邻居距离)、类平均距离法(组间平均距离)、重心距离法;其中距离均采用欧式平方距离,对样本进行谱系聚类分析,并画出谱系聚类图;给出分为3类的聚类结果。并与(1)的结果进行比较 【实验步骤】(此部分主要包括实验过程、方法、结果、对结果的分析、结论等) 1 1)
多元线性回归拟合分析
楚雄师范学院 2012年数学建模竞赛 第一次实战训练(一)第一题论文 题目多元非线性回归拟合模型 姓名郜红霞杨环刘发稳 2012年8月20日
多元非线性回归拟合模型 摘要:本文推论了多元非线性数据拟合的通用数学模型,利用最小二乘法和极值原理,导出求解多元非线性回归方程的规范方程组。并用矩阵形式对规范方程组进行表述,在所表述的诸矩阵中,结构矩阵是其基础。用它可方便地转化出其他矩阵,这将大大简化程序的编制和规范方程组的解算。计算机根据输入数据自变量的个数和实验所作次数的多少,求解出相应的多元非线性回归方程及其评估方程质量的数据。 关键字:规范方程;非线性回归方程;最小二乘法;结构矩阵;极值原理;对称矩阵;数据分析;计算机拟合;矩阵形式自变量。
1 问题重述
要求:1.检验强影响点; 2.正态性检验; 3.相关性检验; 4.自变量的多重共线性检验; 5.残差的相关性分析,模型的合理分析。 x=(470 81 82 50 13.7 225)'。 6.预测 2 问题分析 先建立基础的多元线性回归方程,以初步确定输入变量与输出变量的关系,若预测效果不理想,则需要对方程进行进一步优化,考虑建立非线性回归方程模型或其他更优模型,反复进行判断和优化,最后得到较理想的预测方程。并用一定的评价标准对得出的预测方程进行判定,最后,用实验数据对模型预测的精度进行验证。 3 基本假设与符号说明
Q 残差平方和 E 拟合误差 ε 无偏估计值 2s 方差 R 复相关系数 SE 标准误差 4 模型建立 3.1 问题分析 3.2 模型建立 (1)我们先假设输入变量和输出变量之间的关系是线性函数关系,建立多元线性回归模型。 {) ,0(~ (2) ' '110'σεε βββN x x Y m m ++++= (2)为了在研究两个指定变量之间的相关关系的同时,控制可能对其产生影 响的其他变量,我们在研究任意两个输入变量的相互作用的判断中,运用了偏相关分析先对任意两个输入变量之间是否有交互作用进行判断。 设随机变量X 、Y 、Z 之间彼此存在着相关关系,为了研究X 和Y 之间的关系,就必须在假定Z 不变的条件下,计算和Y 的偏相关系数,记为z xy r .。 在考察多个变量时,i X (i =1,2...,p )之间的p-1阶偏相关关系可由如下的递推式定义: 2 ) 1)...(1)(1...(12.2 ) 1...(1 2.0) 1)...(1)(1...(12.0)1...(12.0)1)...(1)(1...(12.0)...1)(1...(12.011-+---+---+-+---= p i i ip p p p i i ip p ip p i i i p i i i r r r r r r 计算得出输出变量的相关性检验。 (3)我们建立部分多元非线性回归模型,来判断在Y 与i X 的模型中有交互
大数据聚类算法研究(汽车类的)
大数据聚类算法研究(汽车类的) 摘要:本文分析了汽车行业基于不同思想的各类大数据聚类算法,用户应该根 据实际应用中的具体问题具体分析,选择恰当的聚类算法。聚类算法具有非常广 泛的应用,改进聚类算法或者开发新的聚类算法是一件非常有意义工作,相信在 不久的将来,聚类算法将随着新技术的出现和应用的需求而在汽车行业得到蓬勃 的发展。 关键词:汽车;大数据;聚类算法;划分 就精确系数不算太严格的情况而言,汽车行业内对各种大型数据集,通过对 比各种聚类算法,提出了一种部分优先聚类算法。然后在此基础之上分析研究聚 类成员的产生过程与聚类融合方式,通过设计共识函数并利用加权方式确定类中心,在部分优先聚类算法的基础上进行聚类融合,从而使算法的计算准度加以提升。通过不断的实验,我们可以感受到优化之后算法的显著优势,这不仅体现在 其可靠性,同时在其稳定性以及扩展性、鲁棒性等方面都得到了很好的展现。 一、汽车行业在大数据时代有三个鲜明的特征 1、数据全面数字化,第一人的行为数字化,包括所有驾驶操作、每天所有的行为习惯,甚至是座椅的习惯等等都将形成相应的数字化。以车为中心物理事件 的数字化,车况、维修保养、交通、地理、信息等等都会形成数字化,全面数字 化就会形成庞大的汽车产业链,汽车的大数据生态圈。这是第一个特点。 由于大数据拥有分析和总结的核心优势,越来越多的品牌厂商和广告营销机 构都在大力发展以数据为基础的网络营销模式,这些变化也在不断地向传统的汽 车营销领域发起进攻。从前品牌做营销仅能凭主观想法和经验去预估,而现在大 数据的出现则可以帮助客户进行精准的客户群定位。 2、第二个特点是数据互联资源化。有一个领导人讲过:未来大数据会成为石油一样的资源。这说明大数据可以创造巨大的价值,甚至可能成为石油之外,更 为强大的自然资源。 大数据首先改变了传统调研的方式。通过观察Cookie等方式,广告从业者可 以通过直观的数据了解客观的需求。之前的汽车市场调研抽样的样本有限,而且 在问题设计和角度选取过程中,人为因素总是或多或少地介入,这就可能会影响 到市场调研的客观性。大数据分析不只会分析互联网行为,也会关注人生活的更 多纬度。数据可以更加丰富,比如了解到消费者的习惯和周期、兴趣爱好、对人 的理解会更加深刻。这些因素综合在一起就会形成一笔无形且珍贵的数据资源。 有了大数据的支持,便可以实现曾经很多只能“纸上谈兵”的理论。 3、第三个特点则是产生虚拟的汽车,人和汽车可以对话,更具有智慧的新兴产业。这个就是未来在大数据时代,汽车行业会呈现的特点。 在这个情况下,我们以人、车、社会形成汽车产业大数据的生态圈,现实生 活中每个有车一族所产生的数据都对整个生态圈有积极的影响。车辆上传的每一 组数据都带有位置信息和时间,并且很容易形成海量数据。如果说大数据的特征 是完整和混杂,那么车联网与车有关的大数据特征则是完整和精准。如某些与车 辆本身有关的数据,都有明确的一个用户,根据不同用户可以关联到相应的车主 信息,并且这些信息都是极其精准的,这样形成的数据才是有价值的数据。 二、汽车行业大数据下聚类算法的含义 汽车行业大数据是指以多元形式,由许多来源搜集而组成的庞大数据组。电 子商务网站、社交网站以及网页浏览记录等都可以成为大数据的数据来源。同时,
SPSS多元线性回归分析教程.doc
线性回归分析的SPSS操作 本节内容主要介绍如何确定并建立线性回归方程。包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。 一、一元线性回归分析 1.数据 以本章第三节例3的数据为例,简单介绍利用SPSS如何进行一元线性回归分析。数据编辑窗口显示数据输入格式如下图7-8(文件7-6-1.sav): 图7-8:回归分析数据输入 2.用SPSS进行回归分析,实例操作如下: 2.1.回归方程的建立与检验 (1)操作 ①单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。具体如下图所示:
图7-9 线性回归分析主对话框 ②请单击Statistics…按钮,可以选择需要输出的一些统计量。如Regression Coefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。Model fit项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。上述两项为默认选项,请注意保持选中。设置如图7-10所示。设置完成后点击Continue返回主对话框。 图7-10:线性回归分析的Statistics选项图7-11:线性回归分析的Options选项 回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。 ③用户在进行回归分析时,还可以选择是否输出方程常数。单击Options…按钮,打开它的对话框,可以看到中间有一项Include constant in equation可选项。选中该项可输出对常数的检验。在Options对话框中,还可以定义处理缺失值的方法和设置多元逐步回归中变量进入和排除方程的准则,这里我们采用系统的默认设置,如图7-11所示。设置完成后点击Continue返回主对话框。 ④在主对话框点击OK得到程序运行结果。