金融计量第四章EVIEWS应用案例-通货膨胀预测分析
计量经济学模型-eviews应用
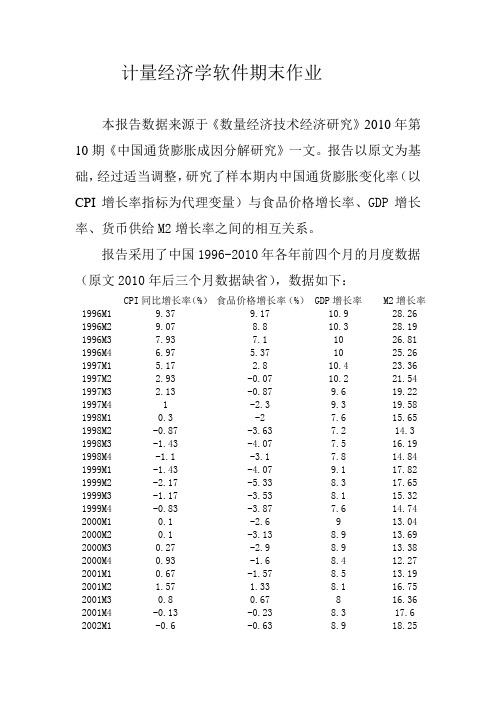
计量经济学软件期末作业本报告数据来源于《数量经济技术经济研究》2010年第10期《中国通货膨胀成因分解研究》一文。
报告以原文为基础,经过适当调整,研究了样本期内中国通货膨胀变化率(以CPI增长率指标为代理变量)与食品价格增长率、GDP增长率、货币供给M2增长率之间的相互关系。
报告采用了中国1996-2010年各年前四个月的月度数据(原文2010年后三个月数据缺省),数据如下:CPI同比增长率(%)食品价格增长率(%)GDP增长率M2增长率1996M1 9.37 9.17 10.9 28.26 1996M2 9.07 8.8 10.3 28.19 1996M3 7.93 7.1 10 26.81 1996M4 6.97 5.37 10 25.26 1997M1 5.17 2.8 10.4 23.36 1997M2 2.93 -0.07 10.2 21.54 1997M3 2.13 -0.87 9.6 19.22 1997M4 1 -2.3 9.3 19.58 1998M1 0.3 -2 7.6 15.65 1998M2 -0.87 -3.63 7.2 14.3 1998M3 -1.43 -4.07 7.5 16.19 1998M4 -1.1 -3.1 7.8 14.84 1999M1 -1.43 -4.07 9.1 17.82 1999M2 -2.17 -5.33 8.3 17.65 1999M3 -1.17 -3.53 8.1 15.32 1999M4 -0.83 -3.87 7.6 14.74 2000M1 0.1 -2.6 9 13.04 2000M2 0.1 -3.13 8.9 13.69 2000M3 0.27 -2.9 8.9 13.38 2000M4 0.93 -1.6 8.4 12.27 2001M1 0.67 -1.57 8.5 13.19 2001M2 1.57 1.33 8.1 16.75 2001M3 0.8 0.67 8 16.36 2001M4 -0.13 -0.23 8.3 17.6 2002M1 -0.6 -0.63 8.9 18.252002M2 -1.07 -1.23 8.9 14.74 2002M3 -0.77 -0.5 9.2 16.57 2002M4 -0.63 -0.03 9.1 16.87 2003M1 0.5 2.47 10.8 18.54 2003M2 0.67 1.83 9.7 20.83 2003M3 0.83 2.13 10.1 20.67 2003M4 2.67 7.27 10 19.58 2004M1 2.77 7.17 10.4 19.16 2004M2 4.4 12 10.9 16.35 2004M3 5.27 13.83 10.5 14.14 2004M4 3.17 6.93 9.5 14.46 2005M1 2.83 6.13 10.5 14.17 2005M2 1.73 2.67 10.5 15.67 2005M3 1.33 1.17 10.4 17.92 2005M4 1.37 1.7 10.4 17.99 2006M1 1.2 1.87 11.4 17.35 2006M2 1.37 1.93 12 17.03 2006M3 1.27 1.47 11.8 15.46 2006M4 2.03 4.07 11.6 15.67 2007M1 2.73 6.23 11.7 17.27 2007M2 3.6 8.9 12.2 17.06 2007M3 6.1 16.83 12.2 18.45 2007M4 6.63 17.5 11.9 16.73 2008M1 8.03 20.97 10.6 16.19 2008M2 7.77 19.77 10.4 17.29 2008M3 5.27 11.47 9.9 15.21 2008M4 2.53 6.2 9 17.79 2009M1 -0.6 0.5 6.1 25.5 2009M2 -1.53 -1 7.1 28.38 2009M3 -1.27 0.27 7.7 29.26 2009M4 0.67 3.37 8.7 27.58 2010M1 2.2 5.1 11.9 22.5其中,被解释变量为CPI增长率(以cpi表示),解释变量为食品价格增长率(以foodprice表示)、GDP增长率(以gdp 表示)、货币供给M2增长率(以M2表示)。
计量经济学论文(eviews分析)-中国食品价格指数的影响因素分析

中国食品价格指数的影响因素分析摘要:本文试从影响食品价格指数的外因粮食价格指数、肉禽及其制品价格指数、水产品价格指数、蔬菜价格指数等进行分析和探讨,并在比较相关线性回归方程后,建立合理的食品价格指数预测模型。
本文用到的模型检测方法主要有相关系数法、怀特检验。
模型修正方法有科克伦—奥克特迭代方法、逐步回归法。
关键词:食品价格指数多因素分析预测模型模型检测与修正一、文献综述众所周知,食品在我国CPI中的权重约为1/3,是我国CPI 8项分类指数中权重最大的,食品价格由于受需求和供应变化影响经常出现波动,导致我国CPI指数的上升或下跌。
分析我国食品价格指数的影响因素,对于调控市场价格总水平具有重要意义。
曾经,有一种说法,叫做“CPI的走势是由猪决定”。
这句话乍一看很荒谬,但是仔细分析,其实是有道理的,猪肉的价格会首先影响粮食价格指数,粮食价格指数通过影响食品价格指数,进而影响CPI。
从公布的数据来看,食品类价格依然领涨CPI。
7月份中国食品类价格同比上涨14.8%,影响价格总水平上涨约4.38个百分点。
其中,猪肉价格同比上涨56.7%,影响价格总水平上涨约1.46个百分点。
中国社会科学院宏观经济研究所袁钢明教授表示,虽然CPI的涨幅比上个月提高0.1个百分点,但上涨幅度明显减缓,这主要是因为食品价格、尤其是猪肉价格的下降。
2009年11月份CPI由负转正,结束了九个月的负增长过程。
自此以来,CPI持续高速增长,最高时在去年7月份达到了%6.5.从数据上看,中国经济似乎已经呈现“高通胀,高增长”的过热趋势,有关经济是“过热”还是“通胀”的议论已经不绝于耳。
中国经济增长显然“过热”。
经济过热发生时,其生产能力无法跟上日益增长的总需求。
这是普遍的特点是一个不可持续的高比率的经济增长速度。
经济处于景气时期往往是经济过热的特色。
经济过热给社会各方面造成的影响是不可忽视的。
从过去的CPI数据中可以看出,食品价格的上涨是CPI的主要推手。
计量经济学案例分析(Eviews操作)

美股行情对A股的影响性分析——标普500与沪深300相关性分析摘要:本文主要通过分析标准普尔500指数与沪深300指数的相关性,以标普500指数为解释变量,以沪深300指数为被解释变量,利用Eviews软件,使用其中的最小二乘法对其进行线性回归分析,最终得出方程。
并对其进行显著性检验(F,t)、异方差检验、自相关性检验来验证方程的可靠性。
然后解释方程的经济意义,并利用软件对未来指数变动进行预测。
最后在未来几天比较预测结果与实际两个指数的变化情况,验证实际应用情况。
关键词:标普500、沪深300、Eviews、显著性检验、异方差检验、自相关性检验。
一、研究背景1.全球化大环境在经济全球化不断深入发展的今天,全球资本市场,尤其是中美两个超级大国之间的资本流通,早已彼此嵌入,密不可分。
全世界早有不少学者对中美资本流通做了深入研究。
但美国股市发展早于中国十几年,其内部的资金也远远超过中国股市,美国股市的资本流动势必会对中国股市产生一定影响,这种影响不仅体现在情绪面,更反映在指数变动方向上。
2.对外开放资本市场的QFII政策Qualified Foreign Institutional Investor,作为一种过渡性制度安排,QFII制度是在资本项目尚未完全开放的国家和地区,实现有序、稳妥开放证券市场的特殊通道。
外资对中国股市的影响早已不可忽视,而美国市场的变动也一定程度会影响在中国股市外资的操作行为。
所以研究两个指数的变动是很有意义的。
二、数据1.数据选择沪深两个市场各自均有独立的综合指数和成份指数,这些指数不能用来反映沪深两市的整体情况,而沪深300指数则同时考虑了两市的交易情况,是中国A股市场的“晴雨表”。
标准普尔500指数英文简写为S&P 500 Index,是记录美国500家上市公司的一个股票指数。
与道琼斯指数等其他指数相比,标准普尔500指数包含的公司更多,因此风险更为分散,能够反映更广泛的市场变化。
利用EVIEWS研究中国通货膨胀诱因
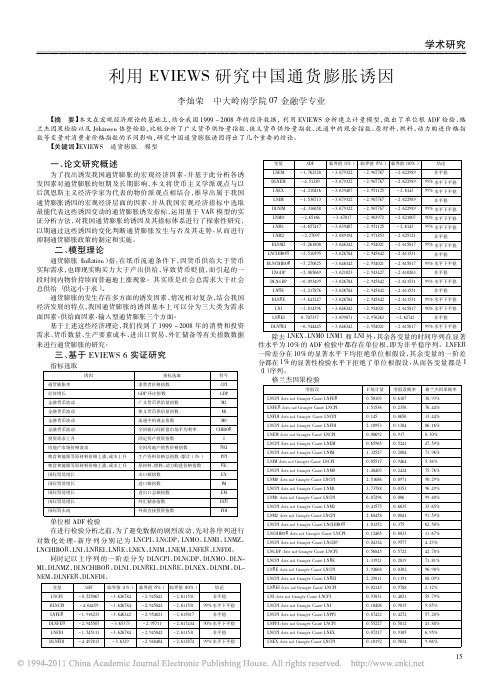
一、 论文研究概述
为了找出诱发我国通货膨胀的宏观经济因素, 并基于此分析各诱 本文将货币主义学派观点与以 发因素对通货膨胀的短期及长期影响, 后凯恩斯主义经济学家为代表的物价派观点相结合, 推导出属于我国 并从我国宏观经济指标中选取 通货膨胀诱因的宏观经济层面的因素, 运用基于 VAR 模型的实 最能代表这些诱因变动的通货膨胀诱发指标, 证分析方法, 对我国通货膨胀的诱因及其指标体系进行了探索性研究, 以期通过这些诱因的变化判断通货膨胀发生与否及其走势, 从而进行 抑制通货膨胀政策的制定和实施 。
Ml LNFDI does not Granger Cause LNCPI M0 LNCPI does not Granger Cause LNFDI CHIBOR LNEM does not Granger Cause LNCPI I LNCPI does not Granger Cause LNEM REI LNCPI does not Granger Cause LNIM PPI LNIM does not Granger Cause LNCPI RE LNCPI does not Granger Cause LNM0 EX LNM0 does not Granger Cause LNCPI IM LNCPI does not Granger Cause LNM1 EM LNM1 does not Granger Cause LNCPI FER LNCPI does not Granger Cause LNM2 FDI LNM2 does not Granger Cause LNCPI LNCPI does not Granger Cause LNCHIBOR LNCHIBOR does not Granger Cause LNCPI LNCPI does not Granger Cause LNGDP LNGDP does not Granger Cause LNCPI LNCPI does not Granger Cause LNRE LNRE does not Granger Cause LNCPI LNCPI does not Granger Cause LNREI LNREI does not Granger Cause LNCPI LNI does not Granger Cause LNCPI LNCPI does not Granger Cause LNI LNCPI does not Granger Cause LNPPI LNPPI does not Granger Cause LNCPI LNCPI does not Granger Cause LNEX LNEX does not Granger Cause LNCPI
eviews面板数据实例分析(包会)-

eviews面板数据实例分析(包会)-Eviews是一种流行的面板数据分析软件,广泛用于经济学及财务学领域。
本文将以一个面板数据实例为例,介绍Eviews的一些基本功能及应用。
数据说明本数据集为横截面面板数据,共包含11个国家(美国、加拿大、英国、法国、德国、意大利、荷兰、比利时、奥地利、瑞典、日本)在1970年至1986年间的年度数据。
变量说明如下:- gdpercap:人均GDP- invest:投资/GDP比率- consump:消费/GDP比率- inflation:通货膨胀率- popgrowth:人口增长率- literacy:成年人识字率- female:女性劳动力占比数据导入及面板设置首先,在Eviews中新建一个工作文件,并将数据导入。
打开数据文件后,我们可以看到数据已经被正确读入。
然后,我们需要将数据设为面板数据。
在Eviews中,选择“View”菜单下的“Structure of Workfile”选项,可以进入工作文件结构设置。
在弹出的窗口中,选择“Panel Data”选项,并按照数据的属性设置面板变量。
在本例中,我们选择“Country”作为单位维度,“Year”作为时间维度。
设置完成后,Eviews会自动进行面板数据检测。
检测结果显示,数据格式符合面板数据要求。
面板数据描述及汇总统计接下来,我们可以对数据进行初步的描述性统计和汇总统计。
选择“Quick”菜单下的“Descriptive Stats”选项,Eviews会自动生成数据的描述性统计报告,展示各变量在不同国家和不同年份的均值、标准差、最小值、最大值等基本信息。
我们也可以手动计算其他统计量。
例如,选择“Proc”菜单下的“Panel Data”选项,可以对选定的变量进行面板数据汇总统计。
下面是在Eviews中计算人均GDP和消费/GDP比率两个变量的面板均值统计结果:面板数据变量之间的相关性分析在分析面板数据时,我们通常需要考虑不同变量之间的相关性。
Eviews应用案例——通货膨胀预测分析

一、Eviews预测基础
预测的误差和方差 假定真实模型为:
yt xt' t
其中, 是t 服从独立同分布且均值为零的随机扰动项,β是未知参 数向量。
放宽“ t是独立的”这个约束条件 使用真实模型得到的y是不可知的,但是我们估计得到未知参数β
的估计值b,设定误差项为零。对y的点估计可以从下式中取得: yˆt xt'b
一、Eviews预测基础
系数的不确定性
在随机模式下,回归等式中的估计得到系数b不同于真实的系数β。 在回归等式输出界面给出的估计系数的标准差可以衡量估计参数 反映参数的真实值的准确程度。
系数不确定性的影响程度取决于外生变量。在计算预测值的过程 中,由于估计系数与外生变量x相乘,所以外生变量与其平均值相 差越多,预测的不确定性越大。
一、Eviews预测基础
调整缺失项 预测值的缺失项生成有两种情况:一种是某个自变量有缺失值,
另一种是某个所需的回归变量的值在工作簿的时间范围之外。
如果预测方程中没有动态变量(例如:没有滞后内生变量或 ARMA误差项),那么预测序列中的缺失值将不会影响以后各期 的预测值。
如果有动态项,预测序列中单个缺失值就会影响到未来所有的预 测值。此时,EViews会向前期移动预测样本的开始点,直至包含 一个有效预测值。如果不进行这些调整,使用者就必须自行指定 某个合适的值,否则,预测结果将会全部由缺失值组成。
预测是有误差的,这个误差其实就是实际值与预测值的差,即 et yt xt'b
一、Eviews预测基础
假设模型是正确设定的,那么预测误差 来源有两种:
残差不确定性 系数不确定性
一、Eviews预测基础
应用案例-通货膨胀预测分析
应用案例-通货膨胀预测分析引言通货膨胀是一个经济学术语,它指的是商品和服务的价格普遍上涨,导致货币价值下降。
通货膨胀对经济和人们的生活产生了深远的影响,因此准确预测通货膨胀的发展趋势对个人和企业非常重要。
本文将介绍一种基于数据分析和机器学习的方法来预测通货膨胀,并提供一个应用案例。
数据收集与准备通货膨胀预测的核心是基于历史数据来识别和利用潜在趋势。
因此,我们需要收集和准备一组包含经济指标和相关数据的时间序列数据。
这些经济指标可以包括国内生产总值(GDP)、消费者物价指数(CPI)、就业数据、产业产值等。
通过收集这些数据,我们可以建立一个包含时间和相应指标值的数据集。
数据准备的过程通常包括数据清洗、数据平滑以及特征工程等步骤。
在数据清洗阶段,我们需要处理数据中的缺失值、异常值和重复值,以确保数据集的质量。
对于数据平滑,我们可以使用Moving Average、Exponential Smoothing等技术来降低数据的噪音。
特征工程是一项重要的任务,它可以帮助我们从原始数据中提取有用的特征并构建合适的输入变量。
数据分析与建模在数据准备完成后,我们可以进行数据分析和建模。
通货膨胀预测通常使用时间序列分析和机器学习的方法。
下面介绍两种主要的建模方法:时间序列分析时间序列分析是一种用于研究随时间变化的数据的方法。
通货膨胀数据通常具有时间相关性和季节性。
因此,在时间序列分析中,我们可以使用ARIMA模型(自回归-滑动平均模型)来预测通货膨胀。
ARIMA模型是一种广泛应用于时间序列分析的模型,它考虑了自回归、差分和滑动平均的特性。
该模型可以分为三个部分:自回归(AR)、差分(I)和滑动平均(MA)。
在应用ARIMA模型进行通胀预测时,我们可以根据历史数据的相关性来选择适当的AR、I和MA的参数。
机器学习方法机器学习是一种从数据中学习模式并做出预测的方法。
与时间序列分析不同,机器学习方法可以考虑更多的影响因素,如经济数据、社会因素、政治因素等。
计量经济学案例分析Eviews
计量经济学案例分析Eviews⼀、研究课题:通过对1984——2003年某国GDP和出⼝的分析,研究GDP和出⼝量的相关关系并对参数估计值进⾏检验。
⼆、模型及数据来源:GDP为因变量,出⼝量为⾃变量。
选择模型是⼀元线性回归模型y=c0+c1x+u(y代表GDP,x代表出⼝量,u表⽰残差项)数据来⾃《计量经济学软件——eviews的使⽤》135页表12.1。
提取其进⼝和国内⽣产总值两列数据:annual export gdp1984 580.5 71711985 808.9 8964.41986 1082.1 10202.21987 1470 11962.51988 1766.7 14928.31989 1956 16909.21990 2985.8 18547.91991 3827.1 21617.81992 4676.3 26638.11993 5284.8 34634.41994 10421.8 46759.41995 12451.8 58478.11996 12576.4 67884.61997 15160.7 74462.61998 15233.6 78345.21999 16159.8 82067.52000 20634.4 89468.12001 22024.4 97314.82002 26947.4 105172.32003 36287.9 117251.9三、作业1、根据表格得到曲线图、散点图、X-Y曲线图:1200001000008000060000400002000084868890929496980002曲线图05000010000015000010000200003000040000EXPORTG D P散点图20000400006000080000100000120000100002000030000EXPORTG D PX-Y 曲线图2、数据描述统计分析024681001234563、简单的回归估计Dependent Variable: GDP Method: Least Squares Date: 06/14/09 Time: 16:38 Sample: 1984 2003 Variable Coefficient Std. Error t-Statistic Prob. C 11772.77 2862.419 4.112873 0.0007 R-squared0.946953 Mean dependent var 49439.02 Adjusted R-squared 0.944006 S.D. dependent var 36735.19 S.E. of regression 8692.656 Akaike info criterion 21.07298 Sum squared resid1.36E+09 Schwarz criterion21.17256Log likelihood -208.7298 F-statistic 321.3229Durbin-Watson stat 0.604971 Prob(F-statistic) 0.000000y t=-11772.77+3.547790x t R2=0.946953 df=18检验回归系数显著性的原假设和备择假设是(给定α = 0.05)H0:c1= 0;H1:c1≠ 0。
计量经济学案例分析报告eviews
第二章案例分析一、研究的目的要求居民消费在社会经济的持续开展中有着重要的作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体表现。
改革开放以来随着中国经济的快速开展,人民生活水平不断提高,居民的消费水平也不断增长。
但是在看到这个整体趋势的同时,还应看到全国各地区经济开展速度不同,居民消费水平也有明显差异。
例如,2002年全国城市居民家庭平均每人每年消费支出为元, 最低的某某省仅为人均元,最高的某某市达人均10464元,某某是某某的倍。
为了研究全国居民消费水平与其变动的原因,需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
二、模型设定我们研究的对象是各地区居民消费的差异。
居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例与经济结构有较大差异,最具有直接比照可比性的是城市居民消费。
而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出〞来比拟,而这正是可从统计年鉴中获得数据的变量。
所以模型的被解释变量Y选定为“城市居民每人每年的平均消费支出〞。
因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。
因此建立的是2002年截面数据模型。
影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产〞和“购物环境〞;有的与居民收入可能高度相关,如“就业状况〞、“居民财产〞;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数〞、“利率〞。
EViews统计分析在计量经济学中的应用--第4章 放宽基本假定的单方程模型
EViews统计分析在计量经济学中的应用
10
异方差检验结果
基于以上两个样本的残差平方和RSS的数据,得到 RSS1=5995343、RSS2=6.58E+08 根据G-Q检验, F的统计量为:F=RSS2/RSS1=109.75; F0.1(6,6)=4.28,得F=109.75>F0.1(6,6)=4.28
1/10/2015 EViews统计分析在计量经济学中的应用 15
实验步骤五:异方差修正(2)
求出异方差修正的回归结果.具体操作步骤 是:
(1)在主窗口中点击Quick/Estimate Equation, 在弹出的对话框中输入Y、C、X; (2)点击对话框右侧的Option,弹出新的对话框, 在Coefficient covariance选中White,在 Weights的Type选择Inverse std.dev,在 Weight series中输入w,点击确定,得到加权 最小二乘法的输出结果。
1/10/2015 EViews统计分析在计量经济学中的应用 16
异方差修正后的回归结果
1/10/2015
EViews统计分析在计量经济学中的应用
17
对加权的模型进行异方差检验
操作过程如前面White检验所述,检验结果如下图所示:
1/10/2015
EViews统计分析在计量经济学中的应用
18
结果比较
在W本范围为19911998的人均收入与人均储蓄的回归结果, 记录该残差的平方和。 用同样的方法得出2004-2011的人均收入 与人均储蓄的回归结果,记录该样本的残差 的平方和。
1/10/2015
EViews统计分析在计量经济学中的应用
8
1991-1998年样本回归结果
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 偏倚比例说明了预测均值与序列实际值的偏离程度。方差比例表 明预测值方差与序列实际方差的偏离程度。协方差比例衡量了剩余的 非系统误差的大小。 • 偏差比,方差比以及协方差比之和为1。 • 如果偏差比例和方差比例较小,协方差比例比较大,那么可以说 预测结果比较理想。
Presented By Harry Mills / PRESENTATIONPRO
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 平均预测误差可以分解为:
2 2 2 ˆ ˆ ( y y ) / h (( y / h ) y ) ( s s ) 2(1 r )sy t t t ˆ ˆ sy y y
利用Eviews进行中国CPI预测
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
预测的基础知识
• 预测序列是指在Eviews调用“预测(Forecast)”选项的预测设定 窗口后储存预测结果的序列。 • 预测样本指的是EViews计算预测值(拟合值)的样本区间。如果 预测值是不可计算的,那么就将返回一个缺失值(NA)。有些情 况下,EViews会对样本进行自动调整,以防止出现预测序列全部 为缺失值的情况。需要注意的是,预测样本有可能会与估计方程 所用的样本区间重叠。
•
ˆ /h y
t
ˆt ˆ t 和 y 的平均值和有偏标准偏差。r为 y 、y 、s yˆ 和 s y 分别是 y 和 y 的相关系数。
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 常见误差衡量指标
偏倚比例(Bias Proportion)
Eviews预测基础
• 残差的不确定性
• 公式中的残差ε在预测期是未知的并被它们的期望值代替。残差 的期望为零,但是个别值不为零,个别误差的变化越大,预测的 总体误差就越大。 • 一般使用回归标准差来衡量误差的变化程度(在回归等式输出界 面中用“S.E. of regression”表示),残差的不确定性是预测 误差的主要来源。 • 在动态预测中,残差不确定性是复合形成的,这是由于滞后因变 量和ARMA项取决于滞后残差。EViews同样将这些值设臵为等于它 们的期望值,然而这些期望值与真实值是不同的。这种额外的预 测不确定性的来源有超过预测区间的趋势,导致这种动态预测有 越来越多的预测误差。
Eviห้องสมุดไป่ตู้ws预测基础
含有滞后因变量的预测
• 如果我们在之前估计的方程的右手侧增加Y的一期滞后项: y c x z y(-1) • 在估计完成后,单击Forecast按钮然后在对话框中输入序列名称 进行预测。
• 预测是有误差的,这个误差其实就是实际值与预测值的差,即 et yt xt' b
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 假设模型是正确设定的,那么预测误差 来源有两种: • 残差不确定性 • 系数不确定性
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 如果在进行预测时,在预测标准差(S.E.)对话框中输入一个 名称,那么EViews会计算出预测标准差序列并将其保存在工作 簿中。预测标准差可以用来确定预测区间。 • 如果选择Do graph选项进行输出,EViews会通过加减两个标准 差得到预测区间,并绘制预测图。这两个标准差的范围提供了 大约95%的预测区间。也就是说如果假设你做进行了很多次预测 ,那么因变量的实际值会有95%的几率落在区间内。
其中s是回归标准差
• 预测标准差同时解释了残差不确定性和系数不确定性。利用通过 最小二乘法估计得到的线性回归模型进行的点估计预测,这从某 种意义上讲是最优的,因为它们在线性无偏估计的预测中拥有最 小的预测方差。此外,如果残差呈正态分布,那么预测误差将呈 现t分布,预测值分布的区间也就很容易确定了。
Presented By Harry Mills / PRESENTATIONPRO
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 计算预测误差的统计指标-以拟预测测试数据集结果来评估 • 假定预测期为j=T+1,T+2…,T+h,并指定预测期t中实际值与预测 ˆt 值分别为 y t 和 y
均方根误差(Root Mean Squared Error)
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
中国CPI预测 结果
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 注意事项 • 如果没有预测期因变量的实际数据的话,那么EViews将无法 给出预测效果评价。 • 预测效果评价可按两种格式保存。如果你选择了Do graph选 项,预测结果评价会出现在一张预测图旁边。如果你希望评 价结果单独以表格的形式出现,就不要选择预测对话框中的 Do graph选项。
ˆt / h)-y )2 ( y ˆt yt )2 / h (y
2 (sy ˆ - sy ) ˆt yt )2 / h (y
方差比例(Variance Proportion) 协方差比例(Covariance
Proportion)
2(1 r ) s y ˆ sy ˆt yt )2 / h (y
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 假定使用者想用下列方程项进行动态预测: y c y(-1) ar(1) • 此时如果设定预测样本和工作簿时间范围的起始点相同,那么 EViews将会把预测样本向后推迟两期,然后使用预测样本前面的 观测值作为滞后变量来进行预测。 • 向后推迟两期,是因为滞后内生变量使得残差损失一期观测值, 所以对误差项的预测只能从第三期开始。
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 预测的误差和方差 • 假定真实模型为: yt xt' t
t 是服从独立同分布且均值为零的随机扰动项,β是未知参 • 其中, 数向量。 • 放宽“ t 是独立的”这个约束条件 • 使用真实模型得到的y是不可知的,但是我们估计得到未知参数β 的估计值b,设定误差项为零。对y的点估计可以从下式中取得: ˆ t xt' b y
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 系数的不确定性
• 在随机模式下,回归等式中的估计得到系数b不同于真实的系数β 。在回归等式输出界面给出的估计系数的标准差可以衡量估计参 数反映参数的真实值的准确程度。 • 系数不确定性的影响程度取决于外生变量。在计算预测值的过程 中,由于估计系数与外生变量x相乘,所以外生变量与其平均值相 差越多,预测的不确定性越大。
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 预测效果评估
• 基于已经估计好的中国CPI的AR(2)模型,我们可以创建一个对 2005M01到2009M11中国CPI的动态预测。 • 如果我们勾选了Forecast evaluation选项,同时有预测变量在预 测期的实际数值的话,EViews将会给出评估预测结果的统计数据
T h t T 1
ˆ y) (y
t t
2
/h
平均绝对误差(Mean Absolute Error)
T h
t T 1
ˆ t yt / h y
ˆt yt y /h yt
t
平均相对误差(Mean Absolute Percentage Error) 泰勒不等系数(Theil Inequality Coefficient)
– 所有样本数据可分为两段,一段为训练数据集,用以估计(或称训 练)预测模型,另一段为测试数据集,用以测试训练出的模型的估 计效果
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 如果预测序列中不包含在预测样本中的值,有两个处理方式可供 选择。 默认情况下,EViews将把预测值序列中预测样本外的部分赋予因 变量的实际值, 如果在预测设定窗口中关掉Insert actuals for out-of-sample 选项,那么预测序列中预测样本外的值将设为缺失值(NA)。 • 如果使用已经存在的预测序列的名称,每次预测后预测值序列的 所有数据将会被重写,预测序列中已经存在的数值将会丢失
ˆt c ˆ(1) c ˆ(2) xt c ˆ(3) zt y
• 需要确保预测期内的所有观测值对应的外生变量均为有效值。如果 预测样本中有数据缺失,那么对应的预测值将为缺失值(NA)。
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
Presented By Harry Mills / PRESENTATIONPRO
Eviews预测基础
• 预测的不确定性
• 预测的不确定性由预测标准差来衡量。对于一个不包含滞后因变 量或者ARMA项的回归方程,预测标准误差计算公式如下:
forecast se s 1 xt' ( X ' X ) 1 xt
Presented By Harry Mills / PRESENTATIONPRO