平行语料库的相似语句去重算法
AI自然语言处理 文本去重与质量评估

AI自然语言处理文本去重与质量评估AI自然语言处理:文本去重与质量评估引言近年来,随着人工智能技术的发展和应用领域的拓宽,自然语言处理(NLP)作为AI的重要分支之一,受到了广泛关注和研究。
而在NLP中,文本去重和质量评估是两个至关重要的任务,本文将详细介绍这两个课题的概念、方法和挑战。
一、文本去重1. 概念文本去重即为在大规模文本数据集中寻找并删除重复的或者相似度较高的文档。
对于海量数据而言,文本去重可以降低存储空间的要求,并简化后续处理过程,提升系统效率。
2. 方法文本去重的方法主要包括基于哈希的方法、基于特征的方法和基于机器学习的方法。
基于哈希的方法常用的有MinHash和SimHash算法。
MinHash通过随机排列和哈希函数生成固定长度的签名,比较文档间的签名相似度来判断是否重复。
SimHash基于向量表示和海明距离,通过位向量计算文档的哈希值,进而确定文档的相似性。
基于特征的方法则主要利用文档的语义和结构信息进行比对。
常用的特征包括文档中的单词、短语、句子或者其他结构,通过提取和匹配这些特征来判断文本的重复性。
基于机器学习的方法通过构建适当的分类模型,将文本去重问题转化为二分类问题,即判断一对文档是否相似。
这需要大量的训练数据和特征工程的支持,但可以获得较高的准确率。
3. 挑战文本去重面临着准确度和效率两方面的挑战。
对于准确度而言,不同语种、领域和文本形式的差异都会影响去重效果。
例如,在处理非结构化文本时,基于特征的方法可能遇到词序问题,导致匹配结果不准确。
而在效率方面,由于数据规模庞大,快速高效的去重算法对于实际应用至关重要。
因此,如何在保证准确性的前提下,实现高效的去重成为了一个挑战。
二、文本质量评估1. 概念文本质量评估旨在确定文本的可用性和可靠性。
在NLP任务中,文本质量评估可以用于过滤垃圾信息、判断文件的真实性和提高后续任务的效果等。
2. 方法文本质量评估的方法包括基于规则的方法、基于机器学习的方法和基于深度学习的方法。
jaccard文本相似度算法

jaccard文本相似度算法Jaccard文本相似度算法是一种常用的文本相似度计算方法,它通过计算两个文本之间的交集与并集的比值来衡量其相似程度。
本文将介绍Jaccard文本相似度算法的原理、计算步骤以及应用场景。
一、Jaccard文本相似度算法原理Jaccard文本相似度算法是基于集合论的思想,它将文本看作是由词语构成的集合。
算法的核心思想是通过计算两个文本集合的交集与并集的比值来衡量它们的相似程度。
具体而言,假设文本A和文本B的词语集合分别为Set(A)和Set(B),则Jaccard相似度可以通过以下公式计算:J(A, B) = |Set(A) ∩ Set(B)| / |Set(A) ∪ Set(B)|其中,|Set(A) ∩ Set(B)|表示文本A和文本B的词语交集的大小,|Set(A) ∪ Set(B)|表示文本A和文本B的词语并集的大小。
二、Jaccard文本相似度算法计算步骤1. 对文本A和文本B进行预处理,包括分词、去除停用词等操作,得到词语集合Set(A)和Set(B)。
2. 计算词语交集的大小,即|Set(A) ∩ Set(B)|。
3. 计算词语并集的大小,即|Set(A) ∪ Set(B)|。
4. 将交集大小除以并集大小,即得到Jaccard相似度J(A, B)。
三、Jaccard文本相似度算法应用场景Jaccard文本相似度算法在自然语言处理领域有着广泛的应用。
以下是几个常见的应用场景:1. 文本去重:通过计算不同文本之间的相似度,可以识别出重复的文本,从而进行去重操作。
这在信息检索、网络爬虫等领域都有重要的应用。
2. 文本聚类:通过计算不同文本之间的相似度,可以将相似的文本聚类在一起,从而实现文本的分类和归纳。
这在文本挖掘、舆情分析等领域具有重要意义。
3. 推荐系统:通过计算用户对不同文本的相似度,可以为用户推荐其感兴趣的文本。
这在电商、新闻推荐等领域有着广泛的应用。
英汉双语平行语料库人工对齐方法说明
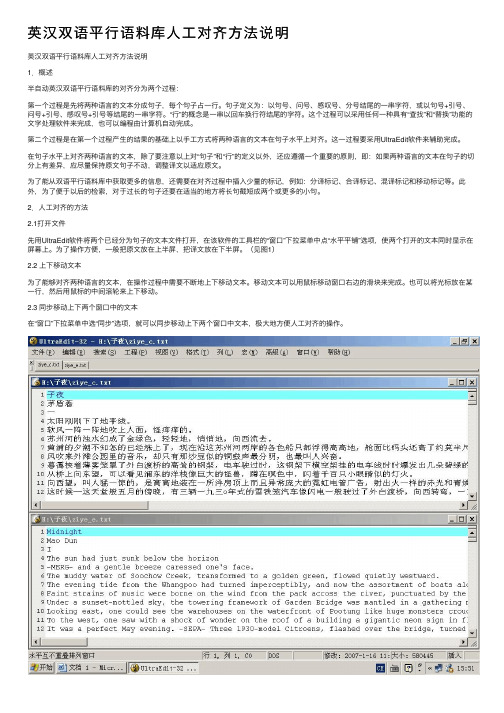
英汉双语平⾏语料库⼈⼯对齐⽅法说明英汉双语平⾏语料库⼈⼯对齐⽅法说明1.概述半⾃动英汉双语平⾏语料库的对齐分为两个过程:第⼀个过程是先将两种语⾔的⽂本分成句⼦,每个句⼦占⼀⾏。
句⼦定义为:以句号、问号、感叹号、分号结尾的⼀串字符,或以句号+引号、问号+引号、感叹号+引号等结尾的⼀串字符。
“⾏”的概念是⼀串以回车换⾏符结尾的字符。
这个过程可以采⽤任何⼀种具有“查找”和“替换”功能的⽂字处理软件来完成,也可以编程由计算机⾃动完成。
第⼆个过程是在第⼀个过程产⽣的结果的基础上以⼿⼯⽅式将两种语⾔的⽂本在句⼦⽔平上对齐。
这⼀过程要采⽤UltraEdit软件来辅助完成。
在句⼦⽔平上对齐两种语⾔的⽂本,除了要注意以上对“句⼦”和“⾏”的定义以外,还应遵循⼀个重要的原则,即:如果两种语⾔的⽂本在句⼦的切分上有差异,应尽量保持原⽂句⼦不动,调整译⽂以适应原⽂。
为了能从双语平⾏语料库中获取更多的信息,还需要在对齐过程中插⼊少量的标记,例如:分译标记、合译标记、混译标记和移动标记等。
此外,为了便于以后的检索,对于过长的句⼦还要在适当的地⽅将长句截短成两个或更多的⼩句。
2.⼈⼯对齐的⽅法2.1打开⽂件先⽤UltraEdit软件将两个已经分为句⼦的⽂本⽂件打开,在该软件的⼯具栏的“窗⼝”下拉菜单中点“⽔平平铺”选项,使两个打开的⽂本同时显⽰在屏幕上。
为了操作⽅便,⼀般把原⽂放在上半屏,把译⽂放在下半屏。
(见图1)2.2 上下移动⽂本为了能够对齐两种语⾔的⽂本,在操作过程中需要不断地上下移动⽂本。
移动⽂本可以⽤⿏标移动窗⼝右边的滑块来完成。
也可以将光标放在某⼀⾏,然后⽤⿏标的中间滚轮来上下移动。
2.3 同步移动上下两个窗⼝中的⽂本在“窗⼝”下拉菜单中选“同步”选项,就可以同步移动上下两个窗⼝中⽂本,极⼤地⽅便⼈⼯对齐的操作。
图1:⽤UltraEdit同时打开两种语⾔的⽂本。
2.4 译⽂句⼦的合并如上所述,对齐的原则是尽量保持原⽂不变。
如何利用自然语言处理技术进行文本去重和去噪

如何利用自然语言处理技术进行文本去重和去噪文本去重和去噪是自然语言处理技术中两个重要的任务。
在海量文本数据中,存在大量近似或完全相同的文本,这些文本可能是重复的、冗余的或者噪音数据。
为了提高信息搜索和处理的效率,以及确保数据的准确性和一致性,文本去重和去噪技术变得尤为关键。
文本去重是指在海量文本数据中,通过计算文本之间的相似性,找出并去除相似或重复的文本,以减少数据冗余和重复计算。
而文本去噪任务则是清洗文本数据,去除其中的噪音,如HTML标签、非语义字符、乱码等,提高数据的质量。
自然语言处理技术在文本去重和去噪任务中发挥着重要的作用。
下面将从两个方面介绍如何利用自然语言处理技术进行文本去重和去噪。
一、文本去重文本去重的目标是识别和删除重复文本,以避免重复计算和冗余存储。
常用的文本去重方法包括基于hash的方法和基于相似性的方法。
基于hash的方法利用哈希函数将文本转换为固定长度的hash码,并通过比较hash码来判断文本的相似性。
常用的hash算法包括MD5和SHA。
通过计算文本的hash值,可以快速判断两个文本是否相同。
基于相似性的方法则通过比较文本之间的相似性来进行去重。
常用的相似性度量方法包括编辑距离、余弦相似度、Jaccard相似系数等。
通过计算文本之间的相似性,可以找出相似度高于阈值的文本对,并进行去重处理。
自然语言处理技术在文本去重任务中发挥着关键作用。
例如,可以利用分词技术将文本切分成词语的序列,利用词语序列的信息来计算文本的相似性。
另外,还可以利用词向量模型,如Word2Vec和BERT,将文本映射为低维的向量表示,通过计算向量之间的相似性来进行去重。
二、文本去噪文本去噪是指清洗文本数据,去除其中的噪音,提高数据的质量。
常见的文本噪音包括HTML标签、非语义字符、乱码等。
利用自然语言处理技术进行文本去噪的方法主要包括正则表达式、规则匹配和机器学习等。
通过正则表达式可以方便地匹配和替换特定模式的文本。
如何使用ChatGPT进行文本去重与相似度计算

如何使用ChatGPT进行文本去重与相似度计算近年来,随着人工智能技术的迅猛发展,ChatGPT成为了一款备受关注的文本生成模型。
然而,除了生成文本外,ChatGPT还可以用于文本去重与相似度计算,为用户提供更加精确和高效的检索。
本文将探讨如何利用ChatGPT进行文本去重与相似度计算,并探索其在实际应用中的潜力。
首先,让我们来了解一下文本去重的概念。
文本去重是指通过比较多个文本的内容,找出其中重复的部分,并将其去除,从而实现精简和提高检索效率的目的。
传统的文本去重方法主要依赖于哈希算法,但其对于语义重复的文本却表现不佳。
而ChatGPT作为一种具有强大语言理解能力的模型,可以通过深度学习技术对文本进行建模和分析,从而实现更加准确的文本去重。
那么,如何使用ChatGPT进行文本去重呢?首先,我们需要将待去重的文本输入ChatGPT模型中进行编码。
ChatGPT模型会将输入的文本转化为一个高维向量表示,该向量包含了文本的语义信息。
接下来,我们可以通过计算不同文本之间的向量相似度来判断它们是否重复。
通常,欧几里得距离或余弦相似度被用于度量向量之间的相似程度。
如果两个向量的相似度超过一个设定的阈值,我们就可以认为它们是相似或重复的文本。
然而,仅仅进行文本去重是不够的,在某些情况下,我们需要计算文本的相似度,以了解不同文本之间的相似程度。
ChatGPT同样可以胜任这项任务。
与文本去重类似,我们可以使用ChatGPT模型将待比较的文本编码为向量表示,然后计算它们之间的相似度。
这种相似度计算可以为用户提供更加准确的信息,并帮助他们快速找到所需的内容。
当然,使用ChatGPT进行文本去重和相似度计算也存在一些挑战和限制。
首先,ChatGPT作为一个预训练的模型,需要大量的计算资源和时间来训练。
其次,ChatGPT对于长文本的处理能力有限,当待去重或比较的文本过长时,可能会导致模型性能下降。
此外,ChatGPT对于稀缺的数据集或特定领域的文本理解能力较差。
平行证明相似

平行证明相似
平行证明相似是指通过证明两个或多个直线或线段平行,从而得出两个或多个图形相似的结论。
以下是一种常见的平行证明相似的方法:
假设有两个图形,分别为图形ABC和图形DEF。
要证明这两个图形相似,需要证明它们的对应角度相等,并证明它们的对应边依次成比例。
1. 证明角度相等:首先,观察图形ABC和图形DEF中的对应角,如果能够证明它们都相等,就可以说明这两个图形的角度相等。
常用的证明方法有直角对应、平行线与转角定理等。
2. 证明边成比例:接下来,需要证明图形ABC和图形DEF中的对应边之间成比例关系。
如果能够证明它们的对应边比例相等,就可以说明这两个图形的边成比例。
常用的证明方法有平行线与截固定比例定理等。
通过以上两个步骤的证明,可以得出图形ABC与图形DEF是相似的结论。
这意味着它们的对应部分既有相等的角度,又有成比例的边长。
需要注意的是,平行证明相似只是相似性的一种证明方法,具体的证明过程可能因题目而异。
因此,在具体的问题中,可能需要运用不同的几何性质和定理来进行证明。
中文相似度匹配算法
中文相似度匹配算法相似度匹配算法是自然语言处理领域的一项重要任务,可以通过比较两个文本的相似程度来进行文本分类、信息检索、摘要生成等应用。
在中文文本中,相似度匹配算法也起着重要的作用。
下面将介绍几种常用的中文相似度匹配算法。
1. 余弦相似度算法(Cosine Similarity)余弦相似度通过计算两个向量之间的夹角余弦值来衡量它们的相似程度。
在文本匹配问题中,通常将文本向量化表示为词袋模型,然后计算两个文本向量之间的余弦相似度。
该算法简单、易于理解,且在实践中通常表现良好。
3. Jaccard相似度算法(Jaccard Similarity)Jaccard相似度算法用于衡量两个集合之间的相似程度。
在中文文本中,可以将文本切分成词语,并将词语作为集合的元素,然后计算两个文本集合之间的Jaccard相似度。
该算法常用于文本分类、信息检索等任务。
4. 词共现矩阵算法(Co-occurrence Matrix)词共现矩阵算法通过统计两个文本中词语的共现频率来计算它们的相似度。
在中文文本中,可以将文本切分成词语,并构建词语的共现矩阵。
然后可以使用余弦相似度等算法来计算两个文本之间的相似度。
该算法常用于文本聚类、关键词提取等任务。
随着深度学习在自然语言处理领域的广泛应用,基于深度学习的相似度匹配算法取得了显著的进展。
例如,可以使用卷积神经网络(CNN)或循环神经网络(RNN)来学习句子级别或词语级别的表示,并通过计算表示之间的距离来进行相似度匹配。
此外,还可以使用预训练的语言模型(如BERT、GPT等)来计算文本之间的相似度。
paperfree降重逻辑
paperfree降重逻辑
paperfree的降重逻辑主要包括以下几个方面:
1. 摸清楚查重的算法:paperfree的算法是总体相似度=相似字数/检测字数。
被系统自动识别出来的非正文部分(如目录,标题,公式,图表,参考文献等)不参与检测,检测字数一般略小于论文字数。
2. 句子相似度计算:paperfree会将文章分解为一个个小句,根据某个算法算出单句相似度。
把其中相似度大于50%的句子的相似字数加总再除以论文总字数即为重复率。
3. 重复内容的修改:对于查重结果中显示的重复内容,可以通过修改语言表达、使用同义词、删减内容、打乱字序、将文字转换为图片等方法进行降重。
4. 注意格式和字数:在降重过程中,需要注意格式的正确引用以及字数的控制。
不要直接抄袭文献,要多转换成自己的句子来表达。
同时,字数减少意味着重复率可能更高,因此要使用更多的原创句子来有效降低重复率。
5. 参考纸质书籍:paperfree的数据库主要是期刊杂志论文和互联网文文献数据库,但很多书很难收录在数据库里。
因此,参考书本内容比网上找资料被检测重复率的概率要小。
6. 翻译外语资料:查阅高水平期刊的外语文献,将其中的理论内容改为自己的语言,放入自己的论文中。
总的来说,paperfree的降重逻辑是通过理解查重算法和句子相似度计算方式,对重复内容进行有针对性的修改和转换,同时注意格式和字数的控制,以达到降低重复率的目的。
数据去重方法
数据去重方法数据去重是在数据处理过程中常见的一个任务,目的是从一组数据中删除重复的元素,以提高数据质量和处理效率。
本文将介绍几种常见的数据去重方法。
一、基于哈希的方法基于哈希的方法是一种常用的数据去重技术。
它通过将数据元素转化为哈希值,并利用哈希函数将这些元素映射到一个哈希表中。
如果两个元素的哈希值相同,则认为它们可能相同,需要进一步比较确认。
这种方法的优点是速度快,适用于大规模数据的处理。
常见的基于哈希的去重算法有Bloom Filter、Hash Set等。
二、排序去重方法排序去重方法是通过先对数据进行排序,然后再顺序扫描删除重复元素的方法。
这种方法的基本思想是相同的元素在排序后会相邻,通过一次扫描就可以完成去重操作。
由于排序需要消耗额外的时间和空间,适用于数据规模较小的场景。
三、位图法位图法是一种适用于处理大规模数据的高效去重方法。
它利用位图的特性,将数据映射到一系列位上,并设置相应的标记来表示元素是否存在。
通过位运算等操作可以快速判断元素的去重情况。
这种方法的优点是占用内存小、查询速度快,适用于处理大规模数据集合。
四、采样法采样法是一种通过随机抽样来进行数据去重的方法。
它基于概率统计的原理,通过从原始数据中抽取部分样本,并对样本进行去重操作来推断整个数据集合的去重结果。
采样法可以在保证较高准确率的同时,减少数据处理的开销。
五、机器学习方法机器学习方法在数据去重中也有一定的应用。
通过训练模型,可以识别重复数据并进行去重操作。
常用的机器学习算法有支持向量机(SVM)、决策树等。
机器学习方法一般适用于复杂的数据去重场景,需要有一定的训练数据和模型构建过程。
六、基于去重库的方法除了自行实现去重算法,还可以使用现有的去重库或工具来完成数据去重任务。
例如,Python中的pandas库提供了drop_duplicates()函数可以方便地去除DataFrame或Series中的重复值;在关系型数据库中,可以使用SQL语句的DISTINCT关键字来实现数据去重。
句子相似度计算方法
句子相似度计算方法
句子相似度的计算方法有多种,以下是一些常见的方法:
1. 欧氏距离:欧氏距离是一种计算多维空间中两点之间距离的方法,它可以通过句子中的词向量来表示句子,然后计算两个句子之间的欧氏距离。
2. 余弦相似度:余弦相似度是一种衡量两个向量之间相似度的方法,它通过计算两个向量的夹角的余弦值来衡量相似度。
在句子相似度计算中,可以将句子表示为词向量,然后计算两个句子向量的余弦值。
3. 词袋模型:词袋模型是一种将句子表示为词频向量的方法,通过统计每个词在句子中出现的次数来构建词频向量,然后计算两个句子向量之间的相似度。
4. 深度学习方法:深度学习方法是一种模拟人脑神经网络的机器学习方法,可以通过训练神经网络来计算句子之间的相似度。
深度学习方法可以通过多种形式来实现,如卷积神经网络、循环神经网络等。
以上是常见的句子相似度计算方法,每种方法都有其优缺点,可以根据具体需求选择合适的方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
广西科学院学报 2009,25(4):248~250,256
JournalofGuangxiAcademyofSciences Vol.25,No.4 November2009
收稿日期:2009210210
作者简介:申文明(19842),男,硕士研究生,主要从事信息检索和自然语言处理方面的研究工作。3南宁市人才小高地基金项目(No.2007007)资助。
平行语料库的相似语句去重算法3AlgorithmforRemovingSimilarSentenceonParallelCorpus
申文明1,黄家裕2,刘连芳1,2SHENWen2ming1,HUANGJia2yu2,LIULian2fang1,2
(1.广西大学计算机与电子信息学院,广西南宁 530004;2.南宁平方软件新技术有限公司,广
西南宁 530003
)
(1.SchoolofComputer,ElectronicandInformation,GuangxiUniversity,Nanning,Guangxi,
530004,China;2.PingsoftNewTechnologyCo.Ltd.ofNaning,Nanning,Guangxi,530004,China)
摘要:尝试对平行语料库中需要去重的中文句子相似情况作分类,利用整体相似因子和局部相似因子计算句子的相似度,并借鉴KMP算法的匹配跳跃思想,提出中文字符串匹配的类KMP算法,并对算法进行实验验证。结果表明,算法具有较好的效果,能够实现平行语料库中相似句子的去重。算法开放测试的召回率达94%,
去重准确率达到84%。算法可以应用于任何长度的语句比对,适用范围广。关键词:去重 相似句子 平行语料库 类KMP
中图法分类号:TP39113 文献标识码:A 文章编号:100227378(2009)0420248203
Abstract:ThesimilarityofChinesesentenceisclassifiedandduplicatedsentenceisremoved.Sentencesimilaritydependsonsimilarityofunitaryfactorandpartialfactor.AccordingtotheideaofKMP’sjump,thesimularKMPinchinesesentenceisused.Theexperimentresultsshowthatthealgorithmiseffective,therecallrateofduplicateremovalreach94%,andtheprecisionratereach84%inlargescaletesting.Keywords:duplicateremoval,similarsentence,parallelcorpus,similarKMP
平行语料库是语料库的一种,是由原文本及其对应的翻译文本构成的语料库[1]。平行语料库将原文和译文经过对齐处理,可以提取出翻译对应语,因而广泛应用于基于实例的机器翻译(EBMT)。平行语料库不仅可以用于机器翻译,还可以在人机交互翻译中给译员提供翻译范例,帮助译员快速、高质量地完成翻译工作。 平行语料库的语料对齐单位根据粒度的大小可以分为篇章、段落、句子、短语、词等多个档次,其中最为重要而且较为成熟的是基于句子的对齐。平行语料库中句子的质量关系着整个机器翻译系统的效果和效率,所以对原始语料句的筛选是保证语料库质量的重要前提。 当前,语料库语料的重要收集方法之一是通过网络自动获取,但是在网络中存在着大量重复或相似的句子。基于平行语料库的机器翻译系统所需要的双语句对一般在百万级以上,如果把这些冗余的句子放入平行语料库,不但会浪费存储资源,而且还会影响翻译系统的工作效率和翻译质量。因此在构建语料库的前期工作中,根据中文语句去掉大量重复或相似的句对是一项具有实际意义的工作。 句子去重就是在收集语料的时候把重复的或者极其相似的句子去除。对于完全重复的字串,陈桂林等通过字串的首字符和字串的长度进行Hash运算,
将首字符或长度相等的字串聚成一个子类,然后对每个子类进行快速排序,对每个子类进行去重[2]。但是我们在语料库的收集中发现:不仅要去掉完全重复的句子,还需要去掉极其相似的句子。例如当一个句子中的某个分句或短语整体发生移动之后,它与© 1994-2011 China Academic Journal Electronic Publishing House. All rights reserved. http://www.cnki.net原来的句子仍很相似,此类相似句子往往对应相同或相近的译文,在语料库中同时保留这两个句子对翻译的贡献不大,所以对句子去重还要对相似的句子进行去重,而不只限于完全重复的句子。本文实现一种中文相似句子的去重算法,对平行语料库句对的去重具有较好的效率和效果。1 相似句子类型 目前,对相似度还没有统一的定义,在不同的具体应用中,相似度的含义也有所不同。DekangLin给出了一个统一的、与应用领域无关的非形式化定义:A与B之间的相似度一方面与它们的共性相关,共性越多,相似度越高;另一方面与它们的区别相关,区别越大,相似度越低[3]。我们在本文中两个句子的相似度指两个句子的字符重复程度。根据句子相似的程度把确定需要去掉的句子分成4种类型:(1)句子完全重复。两个句子长度相等,而且每个位置上的字符也相等,两个句子完全一致。(2)句子包含。一个句子完全被另一个句子包含。例如:A:越南被视外国投资者的乐土。B:近几年来,越南被视为外国投资者的乐土。(3)句型变换。句子中短语位置调换,句型发生变化。例如:A:越南因为有大量廉价的劳动力才能吸引外国的投资。B:越南能吸引外国的投资是因为有大量廉价的劳动力。(4)小部分同义转换。句子中部分短语被同义词替换。例如:A:中国的上海在吸引外资方面独占鳌头。B:中国的上海在吸引外资方面首屈一指。2 相似句子去重算法设计2.1 相似句子去重算法 从待检测的文本中取一个句子si与当前所得的句子集合S(s0,s1,……,st-1)中的句子逐个进行相似度计算,如果存在某一个句子sj与si相似度超过某一个阈值,则si不能作为一个新的句子加入到S,否则将si添加到S中。算法的过程如下: (1)k=0; (2)计算si和sk的相似度,如果判定相似则退出循环并输出,否则转到(3); (3)k=k+1,如果k小于t则转到(2),否则转到(4); (4)将si加入S中,t=t+1并退出。 算法最为关键的是句子相似度的计算,王莹莹[4]通过计算短语间相匹配字符的位置和匹配位置的偏移值来计算中文短语的相似度。但是两个句子间存在短语的多次匹配和字符的连续匹配现象,显然针对短语的相似度计算方法并不适用于长度较长的句子。本算法利用字符串匹配的方法统计两个句子中字符重复的总个数和两个句子的最大相等字串,分别得到整体相似因子和局部相似因子,然后综合两个相似因子得到句子的相似度。算法可以应用于任何长度的语句比对,适用范围广。2.2 句子相似度计算2.2.1 定义 在下列定义中,s
i
(i为正整数)为待处理的完整
语句。 定义1 句子整体相似因子EN
ij
(si,sj)=2
PNij(sli+slj)。ENij为两个句子si、sj
中相同字符
占两个句子的比例,取值范围[0,1];sli为句子i的长度;slj为句子j的长度;PNij是两个句子si、sj匹配时,短句子中的字符在长句子中出现的个数。 因为句子相对比较短,汉字出现重复的现象比较少,所以如果字符在长句中出现则仅统计1次。 考虑如下现象:一个短句的所有字符都在长句出现,但是语义完全不相关。例如:“天气好热”和“天上好像飞过一个热气球”。为了防止这种情况的出现,本文引入了局部相似因子。 定义2 句子局部相似因子SEN
ij
(si,sj)=
PSNijmin(sli,slj)。SENij为两个句子si、sj
最大相
同字符串占短句的比例,取值范围[0,1];PSNij为两个句子si、sj匹配时对应字符连续相等的最大个数;min(sli,sl
j
)为两个句子中短句的长度。
定义3 句子相似度Sim
ij
(si,sj)=Κ
1
ENij(si,sj)+Κ2SENij(si,sj
),其中:Κ1和Κ2是属于
[0,1]的常数,且满足Κ1+Κ2=1。 两个句子si、sj的相似度由整体相似因子EN
ij
和局部相似因子SENij来决定,通过参数Κ1和Κ2来
调配它们在整个相似度计算中所占的比例。显然0
÷Sim
ij(si,sj)÷1。
2.2.2 算法步骤 判断两个句子是否相似的步骤如下。 (1)根据经验设定相似度阈值t;
(2)提取两个句子si、s
j;
(3)分别计算长度sli,sl
j;
(4)计算PNij和PSN
ij;
(5)根据两个句子的比例设定平衡参数Κ1和Κ2,计算两个句子的相似度Simij,当Simij大于设定
的阈值t则句子si、sj被认定相似,否则不相似。
942申文明等:平行语料库的相似语句去重算法
© 1994-2011 China Academic Journal Electronic Publishing House. All rights reserved. http://www.cnki.net