语料库检索使用指南

Homework for Introduction part
http://211.69.132.28/ 检索的库为:introduction 子语料库
语料库使用练习
目标一:熟悉语步与词汇的对应关系;
目标二:学习以扩展意义单位为基础的新语义观(核心词、搭配、类联接、语义倾向、语义韵);
目标三:掌握有语言问题后如何查找相应答案的技能。
提交的作业文件名为:姓名+introduction
提交的内容: 1. 在三个introductions,标注:1)M1, M2, M3;2)每个move的内容要点(用汉语);3)每个语步的经典句型划线,4)红颜色标注:语步1中的评价性形容词、语步2的转折连词(引出现有研究的问题),语步3中代表弥补现有研究不足的表达(如研究目的等)
2. 回答表格中基于语料库检索的8个问题。
提交时间:周二上课的班级提交时间为周一晚9:30:提交给刘琴同学的QQ邮箱
周三上课的班级提交时间为周二晚9:30 ,提交到周颖同学的QQ邮箱
Direction :
1.Download 3 introduction parts from 3 journal articles in your own professional fields. Identify the 3 moves of the introduction part and mark them respectively by M1, M2, M3.and point out the main point of each move inChinese in barckets. Mark evaluative adj.in M1(评价性形容词), disjunctive conj.(转折连词)in M2, and the expressions implying filling gaps, such as research purpose in M3 in red.
Move1 : statements about the subjects. (M1), (main points :problems, background information, definition, importance ,etc) , Move2 : review of relevant studies(M2) (description & comments , point out the weakness of existing researches)
Move3: introduction of the present study(M3)(purposes to fill the gaps, research focuses, questions, hypothesis,etc.)
2.Underline the representative sentence patterns in each move and summarize it in the bracket such as [importance]
3.Answer the questions in the right column of the form based on the corpus data.
(注意:如果你不会调节表格,请把答案写在表格外)
Sample :
The separation of mixtures of alkanes is an important activity in the petroleum and petrochemical industries. For example, the products from a catalytic催化isomerization reactor consist of a mixture of linear, mono-methyl and di-methyl alkanes. Of these, the di-branched molecules are the most desired ingredients in petrol because they have the highest octane number. It is therefore required to separate the di-methyl alkanes and recycle the linear and mono-methyl alkanes back to the isomerization reactor. In the detergent industry, the linear alkanes are the desired components and need to be separated from the alkanes mixture[M1: 通过现实需要突出研究的重要性与意义]
.Selective sorption on zeolites is often used for separation of alkanes mixture(1-7文献被省略). The choice of the zeolite depends on the specific separation task in hand. For example, small-pore Zeolite A are used for separation of linear alkanes using the molecular sieving principle. However, the branched molecules cannot enter the zeolite structure[M2:指出现有研究方法及方法中存在的问题]. This study aims to overcome this limitation. Both linear and branched molecules are allowed inside the medium-pore MFI matrix and the sorption hierarchy in MFI will be dictated both by the alkanes chain length and degree of branching.[M3:本研究目的和采用新方法的优势]
Introduction的写作方法:说明论文特定主题与较为广泛的研究领域之间的关系,同时提供足够的背景资料。句子内容的范围逐步缩小。通过问题的展示,揭示研究的目的与意义。
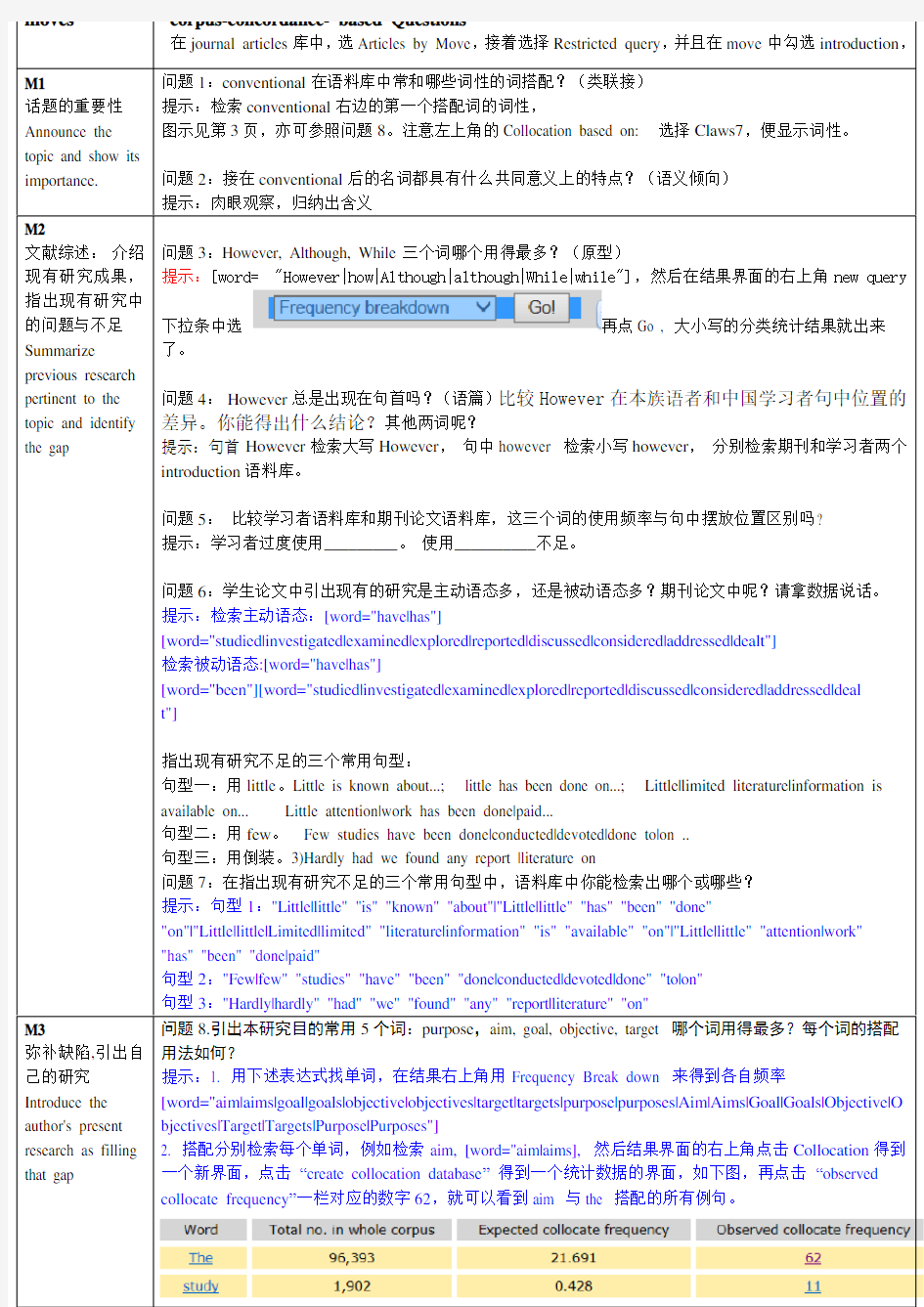
moves corpus-concordance- based Questions
在journal articles库中,选Articles by Move,接着选择Restricted query,并且在move中勾选introduction,
M1
话题的重要性Announce the topic and show its importance. 问题1:conventional在语料库中常和哪些词性的词搭配?(类联接)
提示:检索conventional右边的第一个搭配词的词性,
图示见第3页,亦可参照问题8。注意左上角的Collocation based on: 选择Claws7,便显示词性。
问题2:接在conventional后的名词都具有什么共同意义上的特点?(语义倾向)
提示:肉眼观察,归纳出含义
M2
文献综述:介绍现有研究成果,指出现有研究中的问题与不足Summarize previous research pertinent to the topic and identify the gap 问题3:However, Although, While三个词哪个用得最多?(原型)
提示:[word= "However|how|Although|although|While|while"],然后在结果界面的右上角new query 下拉条中选再点Go , 大小写的分类统计结果就出来了。问题4:However总是出现在句首吗?(语篇)比较However在本族语者和中国学习者句中位置的
差异。你能得出什么结论?其他两词呢?
提示:句首However检索大写However,句中however 检索小写however,分别检索期刊和学习者两个introduction语料库。
问题5:比较学习者语料库和期刊论文语料库,这三个词的使用频率与句中摆放位置区别吗?
提示:学习者过度使用_________。使用__________不足。
问题6:学生论文中引出现有的研究是主动语态多,还是被动语态多?期刊论文中呢?请拿数据说话。提示:检索主动语态:[word="have|has"]
[word="studied|investigated|examined|explored|reported|discussed|considered|addressed|dealt"]
检索被动语态:[word="have|has"]
[word="been"][word="studied|investigated|examined|explored|reported|discussed|considered|addressed|deal
t"]
指出现有研究不足的三个常用句型:
句型一:用little。Little is known about...; little has been done on...; Little|limited literature|information is available on... Little attention|work has been done|paid...
句型二:用few。Few studies have been done|conducted|devoted|done to|on ..
句型三:用倒装。3)Hardly had we found any report |literature on
问题7:在指出现有研究不足的三个常用句型中,语料库中你能检索出哪个或哪些?
提示:句型1:"Little|little" "is" "known" "about"|"Little|little" "has" "been" "done"
"on"|"Little|little|Limited|limited" "literature|information" "is" "available" "on"|"Little|little" "attention|work" "has" "been" "done|paid"
句型2:"Few|few" "studies" "have" "been" "done|conducted|devoted|done" "to|on"
句型3:"Hardly|hardly" "had" "we" "found" "any" "report|literature" "on"
M3
弥补缺陷,引出自己的研究Introduce the author's present research as filling that gap 问题8.引出本研究目的常用5个词:purpose,aim, goal, objective, target 哪个词用得最多?每个词的搭配用法如何?
提示:1. 用下述表达式找单词,在结果右上角用Frequency Break down 来得到各自频率
[word="aim|aims|goal|goals|objective|objectives|target|targets|purpose|purposes|Aim|Aims|Goal|Goals|Objective|O bjectives|Target|Targets|Purpose|Purposes"]
2. 搭配分别检索每个单词,例如检索aim, [word="aim|aims], 然后结果界面的右上角点击Collocation得到一个新界面,点击“create collocation database”得到一个统计数据的界面,如下图,再点击“observed collocate frequency”一栏对应的数字62,就可以看到aim 与the 搭配的所有例句。
问题1图示:
BCC语料库使用指南
1 、字处理(包括标点符号) [C]:错字标记,用于标示考生写的不成字的字。用[C]代表错字,在[C]前填写正确的字。 例如:地球[C](“球”是错字)、这[C]。 [B]:别字标记,用于标示把甲字写成乙字的情况。别字包括同音的、不同音而只是形似的、既不同音也不形似但成字的等等。把别字移至[B]中B的后面,并在[B]前填写正确的字。 例如:提[B题]高、考虑[B虎]。 [L]:漏字标记,用于标示作文中应有而没有的字。用[L]表示漏掉的字,并在[L]前填写所漏掉的字。 例如: 后悔[L],表示“悔”在原文中是漏掉的字。 农[L]药,表示“农”在原文中是漏掉的字。 [D]:多字标记,用于标示作文中不应出现而出现的字。把多余的字移至[D]中D的后面。 例如:我的[D的],表示括号中的“的”是多余的字(原文中写了两个“的”)。[F]:繁体字标记,用于标示繁体字。把繁体字移至[F]中F的后面,并在[F]前填写简体字。 例如:记忆[F憶]、单{F單}纯、养{F養}分{F份}。 注意: 1)繁体字标记标示的是使用正确的繁体字,如果该繁体字同时又是别字,则先标繁体字标记,再标别字标记。
例如:俭朴[F樸[B僕]]。 2)繁体字写错了,标为:后[F後[C]]。 [Y]:异体字标记,用于标示异体字。把异体字移至[Y]中Y的后面,并在[Y]前填写简体字。 例如:偏[Y徧]、沉[Y沈]。 [P]:拼音字标记,用于标示以汉语拼音代替汉字的情况。把拼音字移至[P]中P的后面,并在[P]前填写简体字。 例如:缘[Pyúan]分、保护[Phù]。 [#]:无法识别的字的标记,用于标示无法识别的字。每个不可识别的字用一个[#]表示。例如:更[#][#]保存自己的生命,…… [BC]:错误标点标记,用于标示使用错误的标点符号。把错误标点移至[BC]中BC的后面,并在[BC]前填写正确的标点符号。 例如:勤奋、[BC,]刻苦的精神。 [BQ]:空缺标点标记,用于标示应用标点符号而未用的情况。把[BQ]插入空缺标点之处,并在[BQ]中BQ的后面填写所缺的标点符号。 例如:周围的环境很安静[BQ,]生活也非常平凡。 [BD]:多余标点标记,用于标示不应用标点符号而用了的情况。把多余的标点移至[BD]中BD的后面。 例如:我家周围的[BD,]美丽风景。 2、词处理:(包括成语) {CC}:错词标记,用于标示错误的词和成语。包括4种情况: 1)把词的构成成分写错顺序的。
外来词使用状况的语料库考察
外来词使用状况的语料库考察 研究一种语言面对外来词时如何反应――拒绝它们,翻译它们,或是任意接受它们-- 对看清这种语言内在的形式趋势很有 价值。研究现代汉语对外来词的接受和使用状况有助于了解现代汉语的发展趋势;也只有摸清外来词在汉语中的生存和发展状况,才有可能给“外来词”一个符合实际的定义,并对其进行科学分类,为进一步的深入研究奠定基础。 一、研究目的与方法 本研究通过语料库考察和统计分析,定量研究人们对外来词的接受度及使用现状,探索和总结当前汉语外来词的使用特点和表现趋势。 为此,笔者通过分层随机抽样的方法选取了99 条外来词作为研究样本,按照引人方式对样本进行分类,然后进行语料库检索,并运用相关的统计方法对数据进行分析,最后对提出的原假设进行检验和分析。 本研究使用了国家语委语料库和中国传媒大学的生语料库。前者是大型的、通用的现代汉语平衡语料库,反映汉语笔语的总体使用情况;中国传媒大学的生语料库则包含2000 篇电视节目文字稿,基本反映较为正式的汉语口语使用情况。两者参照,能够较好地体现当前汉语对外来词吸收和使用的一般状况。 研究中引入了外来词的“出现率”、“出现频次”和“平均频
次”三个测度指标,并将其分别设定为变量r、f 。设外来词 分别属于八个类型组G1, G2……G8任意一组中有外来词W 个;其中在语料库中出现n 个。 r 可以显示某类型外来词中有多少个在语料库中出现f 为某个外来词在语料库中出现的次数f 则说明某类型外来词在语料库中出现的平均密度。 二、研究假设 假设1 :外来词的使用相当普遍 目前学术界和相关人士普遍认为:汉语对通过不同翻译方法引入的外来词接受度不同,最易接受符合汉语构词习惯的纯意译词,其次是含音译成份的词,最后是近年来似乎有些泛滥的字母词。该假设是对当前流行的学术界普遍看法进行定量检验。 假设2:外来词在现代汉语中处于上升状态该假设认为不同类型的外来词在汉语中的发展状况并不平衡,但整体而言,外来词在现代汉语中是处于上升状态的,无论从规模还是速度上看都是如此。 假设3:外来词的使用频率高 该假设认为外来词的使用频率较高,甚至有可能高于某些较为常用的汉语词汇。对该假设的进一步研究将会对外来词的科学划分提供理论依据。 三、研究结果 (一)外来词的出现率和平均频次 两个通用语料库的检索结果均表明,以往的定性研究虽然没有
语料库术语中英对照
Aboutness 所言之事 Absolute frequency 绝对频数 Alignment (of parallel texts) (平行或对应)语料的对齐 Alphanumeric 字母数字类的 Annotate 标注(动词) Annotation 标注(名词) Annotation scheme 标注方案 ANSI/American National Standards Institute 美国国家标准学会 ASCII/American Standard Code for Information Exchange 美国信息交换标准码Associate (of keywords) (主题词的)联想词 AWL/Academic word list 学术词表 Balanced corpus 平衡语料库 Base list 底表、基础词表 Bigram 二元组、二元序列、二元结构 Bi-hapax 两次词 Bilingual corpus 双语语料库 CA/Contrastive Analysis 对比分析 Case-sensitive 大小写敏感、区分大小写 Chi-square (χ2) test 卡方检验 Chunk 词块 CIA/Contrastive Interlanguage Analysis 中介语对比分析 CLAWS/Constituent Likelihood Automatic Word-tagging System CLAWS词性赋码系统Clean text policy 干净文本原则 Cluster 词簇、词丛 Colligation 类联接、类连接、类联结 Collocate n./v. 搭配词;搭配 Collocability 搭配强度、搭配力 Collocation 搭配、词语搭配 Collocational strength 搭配强度 Collocational framework/frame 搭配框架 Comparable corpora 类比语料库、可比语料库 ConcGram 同现词列、框合结构 Concordance (line) 索引(行) Concordance plot (索引)词图 Concordancer 索引工具 Concordancing 索引生成、索引分析 Context 语境、上下文 Context word 语境词 Contingency table 连列表、联列表、列连表、列联表 Co-occurrence/Co-occurring 共现 Corpora 语料库(复数) Corpus Linguistics 语料库语言学 Corpus 语料库 Corpus-based 基于语料库的
雅思王听力真题语料库的使用方法
哈喽宝宝们,今天给大家带来王陆老师语料库正确使用方法 首先说一下同学们雅思听力存在的问题,听到某些单词反应慢,或者拼写速度慢,或者写出来不正确,所以可能造成分数比想象的少个0.5 - 1分左右。 雅思听力7分以上要求更多的不常见单词写对,比如technician、secretary。雅思在2019年5月出现了一个新词,saliva(唾液,口水),这个估计很多同学反应不出来或者压根不会。 很多同学问,语料库对选择题有帮助吗?答案是肯定的,比如,给的选项是fruit、vegetables.假设听到的原文是asparagus,那么可能同学们不一定知道这个是芦笋。如果原文是cabbage,那么估计多数同学会选对。 这样来总结:听力想多分数,必须要增加一些会听会写,反应快的词汇! 语料库是一本学习雅思听力比较有帮助的词汇书。现在最新版的语料库是机考笔试综合版,通过雅思考试,我们可以看出语料库覆盖雅思考试中的听力词汇,请同学们一定要练习拼写和发音。 剑桥雅思系列4-14对于同学们考雅思熟悉题型有帮助,但是可能考试中出现的答案词同学在剑桥系列中没有见过,所以这就是语料库练习的好处了! 2020年的语料库重点章节:11章+5章+3章+4章 第11章和5章尤其重要。例如在2019年5月18日考试中,caravan出现在section 答案中,很多学生说多亏提前练习了,才能写对,今年1月18考试中也出现了这个词。 特别注意:同学可能3章正确率到95%,但是11章80%多,但是最后可能你遇到的答案词就是来源于不熟悉的11章。所以请同学们以最差章节正确率为自己的分数基准! 原因:可能有些人不会什么就考什么!!特别注意:只练习横向听力,不用练习纵向听力。 其中的预测试词汇重要度排第二位,在保证了普通词汇正确率95%之后或雅思听力7分之后再练习这些。(预测试单词很难,这些词来源于2016年雅思听力真题答案)所以,建议同学先保证普通的词汇听见能写对,再来预测试练习! 语料库第8章适合数字字母,地址等信息不能快速捕捉到的考生,这部分练习对于Section1想得分的同学尤其重要。 语料库听写的目标: 第3章第4章第5章+11章:单词加速1.6倍速度,95%正确率(5章不用加速)同学们会问,其它章节不重要吗?答案是重要重要重要。可是,如果练习时间不够,先把3、4、5、11章节练习好。 同学们只有在这四章听写正确率到了95%以上之后,才可以继续听写其它章节,这样听力分数提高更快。如果时间短,那么只能把这四章听写好。在练习这本书时,我们只需要听写横向听力就可以了,纵向听力不用练习(这是给雅思听力已经考到7分,又有时间准备,想到更高分数的同学准备)。其它同学不用练习纵向听力。 错误的学习方法: 很多同学觉得自己基础不好,所以听写完一个章节之后,立刻对答案,发现正确率太低,然后就猛背错词,然后就再重新刷,发现正确率高了之后又刷,来得到成就感,满足感,但是这样的方法存在的问题是你正确率高了,等刷到后面别的章节之后一两周再回来,正确率
语料库常用统计方法
3.5语料库常用统计方法 第3章前几节对语料库应用中的几种主要技术做了介绍。通过语料检索、词表和主题词表的生成,可以得到一定数量的句子、词汇或结构。为能更好说明所得到的结果的真正意义,常常需要对它们加以统计学分析。本章主要介绍语料分析中的一些常用统计方法。 3.5.1 语料库与统计方法 介绍相关统计方法之前,首先需要了解为什么语料库应用中需要运用统计方法。在2.1节讲到文本采集时,我们知道文本或会话构成了最终的语料库样本。这些样本是通过一定的抽样方法获得的。研究中,我们需要描述这些样本的出现和分布情况。此外,我们还经常需要观察不同语言项目之间在一定语境中共同出现(简称共现)的概率;以及观察某个(些)语言项目在不同文本之间出现多少的差异性。这些需要借助统计学知识来加以描写和分析。 理论上说,几乎所有统计方法都可以用于语料库分析。本章只择其中一些常用方法做一介绍。我们更注重相关统计方法的实际应用,不过多探讨其统计学原理。这一章我们主要介绍语料分析中的频数标准化(normalization )、频数差异检验和搭配强度的计算方法。 3.5.2 频数标准化 基本原理 通常语料检索、词表生成结果中都会报告频数(frequency, freq 或raw frequency )。那么某词(如many )在某语料库中出现频数为100次说明什么呢?这个词在另一个语料库中出现频数为105次,是否可以说many 在第二个语料库中更常用呢?显然,不能因为105大于100,就认定many 在第二个语料库中更常用。这里大家很容易想到,两个语料库的大小未必相同。按照通常的思维,我们可以算出many 在两个语料库中的出现百分比,这样就可比了。这种情况下,我们是将many 在两个语料库中的出现频数归到一个共同基数100之上,即每100词中出现多少个many 。这里通过百分比得到的频率即是一种标准化频率。有些文献中标准化频率也称归一频率或标称频率,即基于一个统一基准得出的频率。 实例及操作 频数标准化,首先需要用某个(些)检索项的实际观察频数(原始频数,raw frequency )除以总体频数(通常为文本或语料库的总词数),这样得到每一个单词里会出现该检索项多少次。在频数标准化操作中,我们通常会在此基础上乘以1千(1万、1百万)得到平均每千(万、百万)词的出现频率。即: 1000?=总体频数 观测频数标准化频率(每千词) (注:观测频数即检索词项实际出现的次数;总体频数即语料库的大小或总形符数。) 例如,more 在中国学生的作文里出现251次,在英语母语者语料中出现475次。两个语料库的大小分别为37,655词次和174,676词次。我们可以根据上面的公式很容易计算出251和475对应的标准化频率。另外,我们还可以利用Excel 或SPSS 等工具来计算标准化频率。比如,可以将实际观察频数和语料库大小如图3.5.1输入相应的单元格,然后在C1单元格里输入=(A1/B1)*1000即可得到中国学生每千词使用more 约为6.67次。要得到母语
语料库检索分析在高级英语语篇教学中的应用_语料库检索
语料库检索分析在高级英语语篇教学中的应用_ 语料库检索 语料库检索分析在高级英语语篇教学中的应用_语料库检索摘要语料库语言学通过对自然文本的检索、统计,实现文本的语篇结构、文体风格、语言特征等的量化分析。语料库软件工具如Wordsmith、Concordancer软件等为语篇教学提供了量化分析手段。本文依据语料库语言学的研究方法,主要运用Wordsmith、Antconc软件,以课文"Blackmail"为小型教学语料库,探索高级英语语篇教学的新途径。 关键词语料库检索分析;高级英语;语篇教学1.引言高级英语是英语专业高年级阶段的一门主干课程,其教学目标是"通过阅读和分析内容广泛的材料,扩大学生知识面,加深学生对社会和人生的理解,培养学生对名篇的分析和欣赏能力、逻辑思维与独立思考的能力,巩固和提高学生英语语言技能"1。鉴于此,围绕高级英语课程的教学研究与改革长期以来备受专家、学者和广大师生的关注,如朱传枝2、杨志亭3、刘采敏和楚向群4、李洁平5、黄文英6等。十多年来,随着语言教学理论研究的深入以及计算机网络和多媒体技术的快速发展,高级英语课程改革成绩斐然,教学效果显著提高。然而,在语篇教学中不难发现,由于缺乏科学的文本分析手段和工具,学生对语篇的分析和欣赏"多来自
教师在反复阅读全文的基础上根据某种理论框架或自身独特的理解能力及审美取向所做的解释"7,或者依赖于教学参考书籍上的注解,学习效果大打折扣,成为了困扰教师的一大教学瓶颈。语料库语言学的出现为高级英语语篇教学提供了有力的理论和技术支持,对于解决教学中存在的难题有着重大的启示和意义。 2.语料库与语料库检索分析软件的应用20世纪90年代以来,语料库语言学的迅速发展"给语言研究以及语言应用研究带来了一场革命性的变化"8,而"基于语料库的研究方法已经逐渐扩展到语言教学、话语分析、翻译研究、词典编纂和自然语言处理等多个领域"9。语料库语言学以真实的语言数据为研究对象,通过对大量语言事实进行分析,寻找语言应用的规律和模式。由于语料库研究中的统计数据以实际使用中语言现象的出现概率为依据,且基于语料库而得到的数据避免了偶然性,从而提升了分析结果的可信度。 因此,语料库语言学为语言研究和教学提供了一种全新的模式。 随着计算机信息技术的日新月异,语料库为语言研究提供了空前广泛的语言资料。目前,国际上影响较大的语料库有英国COBUILD语料库(CollinsBirminghamUniversityInternationalLanguageDatabas e)、BNC英语国家语料库(TheBritishNationalCorpus)、CIC 语料库CambridgeInternationalCorpus、ICE语料库
学为贵雅思:雅思备考资料
学为贵雅思给不同雅思水平阶段的考生推荐备考书籍 许多烤鸭对于雅思学习的教材有着各种各样的疑问:这本书写的是什么?我应该买什么书?今天小贵贵就为大家介绍一下咱们学为贵的雅思真经教材,并为不同阶段的你做一个修炼手册的推荐! 一.听力真经修炼手册 1.《雅思王听力真题语料库》 语料库是每个烤鸭的必备书籍,语料库中所有材料首先建立在对2015年之前所有的语言类书籍的研究成果,特别是对剑桥1-10计算机分析成果之上还包括广大考生所提供的考试回忆。 书里面归纳总结了许多的听力考点词包括:名词,动词,形容词,数词,字母,词组等,这些词都是雅思考试中会听到甚至需要写出类的单词。王陆老师独创的点听,复听,魔鬼跟读法在这本书上都有详细的使用说明和介绍。 本书适合听力基础比较薄弱,刚刚接触雅思的“小白”,建议没有考过雅思的考生先用语料库打好单词基础,在此之上再加入听力技巧的使用,并用剑桥真题来做考前模拟。 2.《剑桥雅思听力考点词真经(剑10版)》 所谓考点词就是在测试环节中表征测试目的的词汇。雅思听力考试题目的本质和雅思阅读一样,是考查考生的同义替换能力。而这本听力考点词真经就是总结了剑4到剑10真题中,所有题目所对应的同义替换词。这些同义替换是剑桥官方要求考生所必需掌握的听力词汇,也是雅思听力考试的精髓。 这本书在总结这些考点词的基础上还配有词汇的音频。本书有两种排列形式,一种是按照雅思真题的分类方式,一种是按照九宫格的方式排列。无论是哪一种排列方式,都可以作为考生记忆和自我测试的工具。 本书适合具备一定词汇量,并已经开始做雅思真题的烤鸭。建议在做完一套真题后,对照本书中这套题的考点词来进行归纳,总结。这样才算真正做完,做懂一套雅思真题。
国家语委十五科研重大项目-现代汉语语料库的建设及深加
国家语委十五科研重大项目-现代汉语语料库的建设及深加工 国家语委语料库科研成果简介 教育部语言文字应用研究所计算语言学研究室 一、国家语委现代汉语语料库介绍 语料库是存储于计算机中并可利用计算机进行检索、查询、分析的语言素材的总体。基于语料库的分析方法是对传统的基于规则的分析语言的方法的一个重要补充。语料库具有“大规模”和“真实”这两个特点,因此是最理想的语言知识资源,是直接服务于语言文字信息处理等领域的基础工程。近十几年来,美、英、法、德、日等国家都投入巨资,相继建立了大规模的语料库,如英国国家语料库BNC等。我国从1990年开始由国家语言文字工作委员会主持,组织了语言学界和计算机界的专家学者共同建立了大型的国家级语料库,即国家语委现代汉语语料库。 国家语委现代汉语语料库是一个大型的通用的语料库,以语言文字的信息处理、语言文字规范和标准的制定、语言文字的学术研究、语文教育和语言文字的社会应用为主要服务目标。国家语委现代汉语语料库作为国家级语料库,在汉语语料库系统开发技术上具有国际领先水平,在语料可靠、标注准确等方面具有权威性。国家语委现代汉语语料库面向国内外的长远需要,选材有足够的时间跨度,语料抽样合理、分布均匀、比例适当,能够比较科学地反映现代汉语全貌。 国家语委现代汉语语料库由人文与社会科学、自然科学及综合三个大类约40个小类组成。具体类别如下: 1.人文与社会科学类划分为8个大类和30个小类:(1)政法:哲学、政治、宗教、法律;(2)历史:历史、考古、民族;(3)社会:社会学、心理、语言文字、教育、文艺理论、新闻、民俗;(4)经济:工业经济、农业经济、政治经济、财贸经济;(5)艺术:音乐、美术、舞蹈、戏剧;(6)文学:小说、散文、传记、报告文学、科幻、口语;(7)军体:军事、体育;(8)生活。
语料库简单dye 第二讲
2008/7/31 语料库简单DIY 第二讲语料库软件初探-- 语料库软件初探--MonoConcPro 2.2 本软件是Athelstan开发小组https://www.360docs.net/doc/ba14729339.html,/ ,于1996年开发的语料库比较检索工具。目前,我的服务器上提供学术性下载,下载地址: http://vu.flare.hiroshima-u.ac.jp/whistle/corpus/MoconcPro2. 2.rar (本软件为学术交流使用,所有权归本软件开发小组所有,一切商务性盈利目的的违法使用,所带来的连带责任关系与本人及本论坛无关。请慎重下载,小心使用!!!) 功能介绍: 软件主界 面 基本功能: MonoConc Pro 2.2 的软件界面比较简单。适合语料库初学者和初级研究人员使用。 本软件据作者的研究,其内部主核使用UTF-8编码,基本支持欧洲几种主要语言。当然,其主要的应用领域还是针对英语。本软件主要处理的文本素材是以TXT结尾的记事本文件,当然,本软件还可以导入RTF文档和其他格式的操作系统默认文档格式。不过,从DIY的角度来说,我们自己收集到的语料,为了免除格式,字体,行距等等文本要求,最好全部使用TXT文档,方便,省
事!用了都说好!(谁用谁知道) 我们按照自己的研究目的,研究方向,收集我们所需要的语料素材,具体的收集方法因人而异。可以从报纸杂志的电子文文档上直接下载,也可以从网站上直接下载整理好的TXT版本的小说,资料素材等,还可以直接从各大语料库中检索需要的语用素材,然后拷贝粘贴到TXT文本中。由于MonoConc Pro 强大的跨文档处理系统,一次可以同时导入多个TXT文档进行比较处理,所以我们可以把文章或者资料按照自己喜好的分类标准进行分类,然后存成不同的TXT文件名。检索的时候,只需要同时导入这些文件就可以了。(异常强大~)下载好软件,解压缩,然后打开MP22.EXE文件,你就可以看到上图那个简单的主界面了。 之后,选择File→Lord Corpus File(s),找到你需要导入处理的TXT文档,一个或者多个都可以,然后选择[打开]。指定的TXT文件就被全部导入进MonoConc Pro中了。 如果导入了过多的TXT文档,比如您导入了莎士比亚全集+马克思选+恩格斯选+列宁选+毛泽东选+邓小平选.....(不能否认,真的有这样的朋友存在)。那么,为了方便您查询检索结果所出现的文章,你可以选择File→View Corpus File/URL,这样就能看到查询结果所在的文章,还可以删除不需要的文章,或者添加新的文章,非常简单。 *这里的URL,指的是在HTTP或者FTP上,可以直接打开的文字页面的链接。一般朋友们DIY的语料库都是存在本地硬盘上的,所以基本上可以无视这个选项。不过,将来我们的个人语料库要实现点对点,点对多的平台连接。连接后,我们就可以相互查询对方个人语料库中的资料,此时在导入对方语料库中的文档的时候,就要用这个了。(这个目前还很遥远,大家还是踏踏实实做自己的DIY语料库吧!) 当我们要删除所有的文章的时候,这个时候仅仅关闭文章的窗口,是不能实
陆陆教你语料库的正确打开方式
陆陆教你语料库的正确打开方式 写在前面的话 雅思王听力真题语料库是一本学习雅思听力比较有帮助的词汇书。当当,亚马逊,卓越都有卖的。现在最新版的语料库是剑10版,通过2016年1月的四场考试,我们可以得出结论,现在经常出现ABC卷,所以请同学们认真准备雅思,这样才能得到理想的雅思成绩。 很多同学可能认为语料库只对于听力填空题有帮助,但是各位同学学习久了就会发现,词汇是基础,没有单词,选择题很难做出正确的判断。同学们可以想象:文章由段落组成,段落由句子组成,句子由词组组成,词组由单词组成,所以反过来,如果单词有问题了,文章也很难理解。 特别注意:淘宝网有好多盗版的语料库,如果封面没有烫金字VOICE OF CAMBRIDGE, 那么就是盗版的,盗版是没有光碟的.目前有封面IELTS (旧版) 和剑10(新版)的。最佳版本:剑10是最新的,IELTS,2013也可以使用,但是2011,和2012封面的就是古董啦。中间加了很多词,建议大家使用最新版本(807听力非常有名,如果大家是网上下载的王陆807升级版,建议扔掉啦(因为那是我2006年录的,雅思变化太大了,已经无法跟上时代了)如果是807那本书,大家如果喜欢,可以继续使用,但是没有重点,必须1-9章
都听写好)2016年语料库重点章节重点章节为:5章,11章,3章,4章。如果数字字母等第一部分的基本功有问题,推荐每周练习1-2次8章,这个尤其在有干扰的情形下练习效果最好了。5章:就是词组搭配比较多的章节,也是吞音连读的章节。这些词组就是雅思考试中的神组合,意思就是经常出现的搭配,如果在考试题目要求中看到了NO MORE THAN THREE WORDS, 那么一定要注意听词组搭配,尤其是同学们不太熟悉的搭配,例如,hall of residence (学生宿舍),blue folder (蓝色文件夹)这样的不常用搭配,另外,也要注意guided tour,有下划线的代表容易漏写的,请小心。1月9日考试的3,4部分答案大量来自于这个章节。例如,unsocial hours, internal clock, articles from journals, photocopies of notes等。11章:2014-2015年的雅思听力新增词汇,按照四个部分排列的,其中很多单词都是首次出现在雅思听力考试中,请同学们一定要加强练习,这个部分在1月23,30日的考试中出现在1,4部分。 最后的目标:单词1.6倍速,词组原速,正确率达到95%。经过基于大量数据基础上的统计,语料库听写正确率与听力分数的关系是这样的 通过4年的统计,大量数据表明: 语料库听写正确率20%左右,听力考试实际分数3.5.语料库听写正确率70%左右,听力考试实际分数5.0.语料库听写正
CCL语料库与检索系统方案
一关于CCL语料库及其检索系统 (如果时间紧张,可直接跳到最后的举例部分!) 1.1 CCL语料库及其检索系统为纯学术非盈利性的。不得将本系统及其产生的检索结果用于任何商业目的。CCL不承担由此产生的一切后果。 1.2 本语料库仅供语言研究参考之用。语料本身的正确性需要您自己加以核实。 1.3 语料库中所含语料的基本内容信息可以在“高级搜索”页面上,点击相应的链接查看。比如: “作者列表”:列出语料库中所包含的文件的作者 “篇名列表”:列出语料库中所包含的篇目名 “类型列表”:列出语料库中文章的分类信息 “路径列表”:列出语料库中各文件在计算机中存放的目录 “模式列表”:列出语料库中可以查询的模式 1.4 语料库中的中文文本未经分词处理。 1.5 检索系统以汉字为基本单位。 1.6 主要功能特色: ?支持复杂检索表达式(比如不相邻关键字查询,指定距离查询,等等); ?支持对标点符号的查询(比如查询“?”可以检索语料库中所有疑问句); ?支持在“结果集”中继续检索; ?用户可定制查询结果的显示方式(如左右长度,排序等); ?用户可从网页上下载查询结果(text文件); 二关于查询表达式 本节对CCL语料库检索系统目前支持的查询表达式加以说明。 2.1 特殊符号 查询表达式中可以使用的特殊符号包括8个: | $ # + - ~ ! : 这些符号分为四组: Operator1: | Operator2: $ # + - ~ Operaotr3: !
Delimiter: : 符号的含义如下: (一) Operator1: Operator1是二元操作符,它的两边可以出现“基本项”(关于“基本项”的定义见2.2) (1) | 相当于逻辑中的“或”关系。 (二) Operator2:Operator2是二元操作符,它的两边可以出现“简单项”(关于“简单项”的定义见2.3) (2) $ 表示它两边的“简单项”按照左边在前、右边在后的次序出现于同一句中。两个“简单项”之间相隔字数小于或等于Number (3) # 表示它两边的“简单项”出现于同一句中,不考虑前后次序。两个“简单项”之间相隔字数小于或等于Number (4) + 表示它两边的“简单项”按照左边在前、右边在后的次序出现于同一句中。两个“简单项”之间相隔字数刚好等于Number (5) - 表示它左边的“简单项”出现于句子中,并且,在右边相隔Number个字的范围内,-号右边的“简单项”不出现。 (6) ~ 表示它左边的“简单项”出现于句子中,并且,在左边相隔Number个字的范围内,~号右边的“简单项”不出现。 (三)Operator3:Operator3是一元操作符。 (7) ! 表示它后面的“简单项”是本次查询的主关键字符串,显示查询结果时以该“简单项”作为中心来进行定位。 注意: Operator2后面的Number是必须的,不能省略。Number=0表示相 邻,Number=1表示间隔1个单位,其余依此类推。 (四)Delimiter:西文冒号 : 是分隔符 (8) : 跟在 path,author,name,type,pattern 等关键字后面,用于分隔关键字和它们的取值。这样形成的查询式我们称之为“过滤项”(见下面2.5) 注意:上述特殊字符不能作为基本项在语料库中进行检索。path,author等关键字可以作为基本项进行检索。 2.2 基本项 指不包含特殊符号和空格的连续字符串
基于语料库的海明威作品《雨中的猫》分析
基于语料库的海明威作品《雨中的猫》分析 ——以写作风格和小说主题为例 王树振 (天津师范大学外国语学院,天津, 300387) 【摘要】美国著名作家厄内斯特·海明威的短篇小说《雨中的猫》(1922),自发表以 来便引起文学评论界的极大关注。在作品中,通过对一个日常生活片段的叙述,作者 揭示了女性生存困境的主题。而基于语料库的文学研究,则是通过利用语料库检索软 件来考察作者的写作风格、解读作品的主题。在前人研究的基础之上,笔者拟运用语 料库语言学的方法对这部小说进行更深入的研究。通过使用Wordsmith和AntConc等 语料库检索软件,笔者拟对《雨中的猫》进行词语、句子及篇章结构进行统计分析, 最后不仅能够分析得出海明威用词简单、句子简短的写作风格,还能利用关键词检索 和自动生成的语境,来了解小说的主要内容和人物形象的塑造,这为解读小说的主题 提供了新的研究方法和途径。 【关键词】语料库检索;写作风格;主题 近年来, 国内外不少学者将语料库研究方法应用到文学领域,利用语料库检索软件对文本进行分析, 如Sinclair(1991)、Biber(2000)、张厚振(2004)、肖普勤(2005)等。他们的研究大胆创新,为后来的文学研究者带来很大的启示。正如Sinclair(1991: 36)所论述的那样,“(语料库检索)最激动人心的方面不是对描述进行直观的分类,而是为找到新的方法、新的证据以及新的描述提供可能。在这里,计算机技术的客观性和表面的正当性变成了一种优势,而不是没有放弃直觉前提下的一种责任。当然,我们要尽力找到符合证据的解释,而不是为了迎合现有的解释而去修改我们的证据。” 《雨中的猫》是美国著名小说家海明威的著名短篇,故事情节主要围绕一只雨中的猫展开,叙述了旅居意大利的一对美国夫妻的一段生活场景。本文用Wordsmith及AntConc的Wordlist、Concordance和Keyword对《雨中的猫》的文本特征、主要内容、人物形象和文本主题进行分析,以展示语料库检索软件在文学分析方面的强大功能。 一、基于词表的文本总体特征分析 基于语料库的语言研究一般采取定性与定量相结合的研究方法,要进行定量研究就要涉及文本检索和数据统计。Wordsmith软件中的Wordlist工具可以对文本的基本信息进行统计,自动生成词表(图1)。它可以提供文本中的简略统计数据,从而有助于分析文本的总体统计特征和基本情况。
王陆雅思王听力真题语料库名词Test paper 1
Test paper 1 ability abstract accountant accuracy 能力概述会计准确性 acid action activity actor 酸行动活动男演员 adult adventureadvertisement advertising 成人冒险广告,宣传广告 advice age agency agreement 建议年纪代理机构同意 agriculture aidaim air 农业帮助瞄准,对准,目标空气allergy alley allowance alteration 过敏小巷津贴改变 altitudeambition ambulance amount 海拔高度野心报复救护车数量 analysis analyst anger animal 分析分析家生气动物 ankle answerAntarcticape 脚踝回答,答案南极洲猿 appearance architect architecture area 外貌建筑师建筑学地区 argument aristocrat army art
论证贵族军队艺术 article aspirin assignment atlas 文章阿司匹林作业地图册 audience auditorium author authority 观众礼堂作者权威 average awardbachelorbackground 平均奖励学士,单身汉背景 bacteria badge badminton backpack 细菌徽章羽毛球肩背包自助旅行baldness band bandage bands 秃头乐队绷带乐队(复数) bank banquet base basement 银行宴会基础地下室 bases basis bath batteries 基地基础洗澡电池(复数) battery beachbeard beats 电池海滩胡子调动的次数 beauty bed bedroom bedsheet 美女床卧室床单 bedsit behaviour belt benefit 小套房行为带子优势 beverage bibliographybicycle bill
多语种在线语料库检索平台使用简明手册.pdf
多语种在线语料库检索平台使用简明手册 许家金 中国外语与教育研究中心 、访问及登录 访问(用户名:和密码:),可点击使用相应的语料库。目前平台上已安装英语、汉语、德语、日语、俄语、阿拉伯语、冰岛语等数十个语料库。 图:主界面 、功能概要 按()对语料库分析工具的时代划分,属于第四代语料库工具,即在线语料库分析工具。四代工具的突出代表是美国杨百翰()大学教授创建的系列语料库检索界面()。类似的在线语料库检索系统还有、、、等。而当前主流的语料库工具属于第三代,其中以、和等为代表。 第四代语料库工具,将语料库与分析工具合二为一,越来越受到普通用户的青睐。在线语料库工具通常将语料库文本按特定格式建成索引(),存储在服务器上。用户检索响应速度要远高于三代软件在本地电脑上的检索速度。其操作也较三代语料库软件简便得多。 四代语料库工具可完成三代语料库几乎所有的功能,其中又以所能实现的功能最多最全。更重的是,是开源软件。概括说来,可以实现以下功能。 ()在线生成语料库的词频表(); ()查询()字词、语言结构等,以获取大量语言实例或相应结构的出现频次(),并可以按语体、年代、章节、学生语言水平级别、写作题材等分别呈现查询结果; ()计算特定词语在语料库中的典型搭配(); ()计算语料库中的核心关键词(),等。
、使用实例 标准查询模式 在简单查询模式()下,可输入单词、短语等进行检索。 图:语料库查询界面 图:查询结果界面
点击查询结果页面右上角下拉菜单,显示(新查询)时,按键,即可重新回到语料库检索界面。相当于返回按钮。 新查询,返回语料库检索首页 查询结果随机抽样 频数分解、分解频数 查询结果的分布展示 查询结果排序设定 搭配计算 下载保存查询结果 (随机取样),比如,可从万行结果中,随机抽取行。 (频数分解)表示在进行复杂查询时,对命中的不同词项分别计算频数。比如,查询时,会按这个词项分别报告命中频数和频率。 图:动词查询(频数分解)结果示例 :按语体、年代、章节、学生语言水平、写作题材等分别呈现查询结果 图:语料库中"lov.*"的分布情况()
语料库常用术语
语料库常用术语 Type 类符 Tokens 形符 例如“I see a cat and a dog”类符6个,形符7个 Type/token ratio =TTR TTR 是衡量文本中词汇密度的常用方法,可以辅助说明文本的词汇难度。但是,文本中有大量功能词出现,文本每增加一个词,形符就会增加一个,但类符却未必随之增加。这样文本越长,功能词重复次数越多,TTR会越低。因此用TTR衡量词汇密度不合理,于是,出现了标准化类符/形符比,即STTR。例如,计算每个文本1000词的TTR,均值处理,得出STTR。Frequency(频率) 例如每百万词、十万词中,某单词出现次数。常常将某个单词在两个语料库中出现的频率参照两个语料库的容量,用卡方检验或对数似然率进行对比,来确定两个库中该单词的使用是否有差异。 Wordlist词表 根据单词或词组在语篇中出现的频率大小而排列形成的列表。 Ranks Lemma词目,词元 比如go是lemma,对应各种屈折变化形式(inflections),go,goes,went,going,gone共5种屈折变化形式。在分析语言时,需要将它们全部归到go名下,这个过程叫词形还原。Keywords关键词、主题词positive keywords 正关键词negative keywords 负关键词Concordance 索引(KWIC 语境中的关键词key words in context) 运用索引软件在语料库中查询某词或短语的使用实例,然后将所有符合条件的语言使用实例及其语境以清单的形式列出。通过前后语境,可以分析“collocation词汇搭配”“colligation 类连接、语法搭配”“semantic preference语义倾向”“semantic prosody语义韵”Collocation词汇搭配 搭配强度MI,T-score ,Z-score Colligation类连接、语法搭配 semantic prosody语义韵 词汇的语义韵大体可分为积极语义韵、中性语义韵、消极语义韵。 POS tagging 词性赋码 Regular expression regex 正则表达式
chapter 3雅思王听力特别名词语料库
Test Paper 1 ability abstract accountant accuracy acid action activity actor adult adventure advertisements advertising advice age agency agreement agriculture aid aim air allergy alley allowance alteration altitude ambition ambulance amount analysis analyst anger animal ankle answer Antarctica ape appearance architect architecture area argument aristocrat army art article aspirin assignment atlas audience auditorium author authority average award bachelor background bacteria badge badminton backpack baldness band bandage bands bank banquet base basement bases basis bath batteries battery beach beard beats beauty bed bedroom bed sheet bedsit behaviors belt benefit beverage bibliography bicycle bill biologist bird birth blanket blast block blouse board boarder boat bone bowl bowling branch breakfast brick bridge brochures building bungalow burger burglar bus cab
语料库
关于语料库的三点基本认识:语料库中存放的是在语言的实际使用中真实出现过的语言材料;语料库是以电子计算机为载体承载语言知识的基础资源;真实语料需要经过加工(分析和处理),才能成为有用的资源; 在语言学中,语料库(Corpus)指大量文本的集合,库中的文本(称为语料)通常经过整理,具有既定的格式与标记,特指计算机存储的数字化语料库。 语料库是语料库语言学研究的基础资源,也是经验主义语言研究方法的主要资源。应用于词典编纂,语言教学,传统语言研究,自然语言处理中基于统计或实例的研究等方面。 分类 语料库有多种类型,确定类型的主要依据是它的研究目的和用途,这一点往往能够体现在语料采集的原则和方式上。有人曾经把语料库分成四种类型:(1)异质的(Heterogeneous):没有特定的语料收集原则,广泛收集并原样存储各种语料;(2)同质的(Homogeneous):只收集同一类内容的语料;(3)系统的(Systematic):根据预先确定的原则和比例收集语料,使语料具有平衡性和系统性,能够代表某一范围内的语言事实;(4)专用的(Specialized):只收集用于某一特定用途的语料。 除此之外,按照语料的语种,语料库也可以分成单语的(Monolingual)、双语的(Bilingual)和多语的(Multilingual)。按照语料的采集单位,语料库又可以分为语篇的、语句的、短语的。双语和多语语料库按照语料的组织形式,还可以分为平行(对齐)语料库和比较语料库,前者的语料构成译文关系,多用于机器翻译、双语词典编撰等应用领域,后者将表述同样内容的不同语言文本收集到一起,多用于语言对比研究。目前已经累积了大量各种类型的语料库,如:葡萄牙语种树库、面向文本分类研究的中英文新闻分类语料库、路透社文本分类训练语料库、中文文本分类语料库、大开放字幕库OpenSubtitles的多语言平行语料数据(OpenSubtitles Corpus)、《圣经》双语语料库("Bible" bilingual corpus)、Short messages service(SMS ) corpus(短消息服务(SMS)语料)等。 特征 语料库有三点特征 1.语料库中存放的是在语言的实际使用中真实出现过的语言材料,因此例句库通常不应算作语料库; 2.语料库是承载语言知识的基础资源,但并不等于语言知识;