短面板数据分析的基本程序
面板数据分析方法

面板数据分析方法面板数据分析方法面板数据是指在时间序列上取多个截面,在这些截面上同时选取样本观测,也叫“平行数据”。
下面是小编想跟大家分享的面板数据分析方法,欢迎大家浏览。
面板数据的分析方法面板数据分析方法是最近几十年来发展起来的新的统计方法,面板数据可以克服时间序列分析受多重共线性的困扰,能够提供更多的信息、更多的变化、更少共线性、更多的自由度和更高的估计效率,而面板数据的单位根检验和协整分析是当前最前沿的领域之一。
在本文的研究中,我们首先运用面板数据的单位根检验与协整检验来考察能源消费、环境污染与经济增长之间的长期关系,然后建立计量模型来量化它们之间的内在联系。
面板数据的单位根检验的方法主要有Levin,Lin and CHU(2002)提出的LLC检验方法。
Im,Pesearn,Shin(2003)提出的'IPS检验, Maddala和Wu(1999),Choi(2001)提出的ADF和PP检验等。
面板数据的协整检验的方法主要有Pedroni[8] (1999,2004)和Kao(1999)提出的检验方法,这两种检验方法的原假设均为不存在协整关系,从面板数据中得到残差统计量进行检验。
Luciano(2003)中运用Monte Carlo模拟对协整检验的几种方法进行比较,说明在T较小(大)时,Kao检验比Pedroni检验更高(低)的功效。
具体面板数据单位根检验和协整检验的方法见参考文献。
面板数据的实证分析指标选取和数据来源经济增长:本文使用地区生产总值,以1999年为基期,根据各地区生产总值指数折算成实际,单位:亿元。
能源消费:考虑到近年来我国能源消费总量中,煤炭和石油供需存在着明显低估,而电力消费数据相当准确。
因此使用电力消费更能准确反映能源消费与经济增长之间的内在联系(林伯强,2003)。
所以本文使用各地区电力消费量作为能源消费量,单位:亿千瓦小时。
环境污染:污染物以气休、液体、固体形态存在,本文选取工业废水排放量作为环境污染的量化指标,单位:万吨。
EVIEWS面板数据分析操作教程及实例解析

模型选择对分析结果影响
模型适用性
根据研究目的和数据特征选择合 适的面板数据模型,如固定效应 模型、随机效应模型等。
模型假设
确保所选模型满足基本假设,如 线性关系、误差项独立同分布等 ,否则可能导致结果不准确。
模型比较与选择
通过比较不同模型的拟合优度、 参数显著性等指标,选择最优模 型进行分析。
操作规范性与结果可靠性保障措施
操作步骤规范
结果验证与解读
对分析结果进行验证,确保结果的合理性和准确性 ;同时,正确解读分析结果,避免误导读者。
严格按照EVIEWS软件的操作步骤进行分析 ,避免操作失误或遗漏关键步骤。
数据分析报告
编写详细的数据分析报告,包括数据来源、 处理方法、模型选择、分析结果及解读等, 以便读者全面了解分析过程。
方和来估计模型参数。
广义最小二乘法(GLS)
02
当存在异方差性或自相关性时,采用广义最小二乘法进行参数
估计,以提高估计效率。
最大似然法(ML)
03
适用于随机效应模型等复杂面板数据模型,通过最大化似然函
数来估计模型参数。
模型诊断与检验
残差分析
检查残差是否满足独立同分布等假设条件, 以评估模型的拟合效果。
07 EVIEWS面板数 据分析操作注意 事项
数据质量对分析结果影响
数据来源
确保数据来自可靠、权威的来源,避免使用不准确或存在偏见的数 据。
数据完整性
检查数据是否存在缺失值、异常值或重复值,这些问题可能导致分 析结果失真。
数据处理
对数据进行适当的预处理,如清洗、转换和标准化,以提高数据质量 和一致性。
增强了解决实际问题的能力
通过实例解析和操作演示,学员们学会了如何运用所学知识解决实际问题,提高了分析 问题和解决问题的能力。
面板数据的操作方法

面板数据的操作方法面板数据是管理和操作数据的一种常见方式,通常用于数据分析和数据可视化。
面板数据可以在数据中心中进行操作,以便更好地理解和利用数据。
下面将介绍一些面板数据的常用操作方法。
1. 数据清洗:面板数据通常包含大量的原始数据,需要进行数据清洗。
数据清洗可以包括删除重复数据、填补缺失值、处理异常值等。
通过数据清洗,可以确保面板数据的质量和准确性。
2. 数据合并:面板数据通常由多个数据源组成,需要将这些数据源合并为一个面板数据集。
数据合并可以通过数据表连接、字段匹配等方式进行。
合并后的面板数据可以更好地反映数据的整体情况。
3. 数据变换:面板数据可以进行数据变换,以便更好地理解和利用数据。
常见的数据变换方法包括数据聚合、数据透视等。
通过数据变换,可以从不同角度和维度分析数据。
4. 数据分析:面板数据可以进行各种数据分析。
常见的数据分析方法包括描述性统计、回归分析、时间序列分析等。
通过数据分析,可以发现数据的规律和趋势,提供决策支持。
5. 数据可视化:面板数据可以通过数据可视化的方式呈现。
数据可视化可以使用折线图、柱状图、饼图等。
通过数据可视化,可以更直观地展示数据的特征和关系,帮助用户更好地理解数据。
6. 数据挖掘:面板数据可以进行数据挖掘,以发现隐藏在数据中的规律和模式。
常见的数据挖掘方法包括聚类分析、关联规则挖掘、预测建模等。
通过数据挖掘,可以发现数据的潜在价值。
7. 数据导出:面板数据可以导出为其他格式,如Excel、CSV等。
导出后的数据可以在其他平台或软件中使用。
通过数据导出,可以更灵活地利用面板数据。
8. 数据更新:面板数据通常会不断更新,需要进行数据更新。
数据更新可以通过定期采集新数据、增量更新等方式进行。
通过数据更新,可以保证面板数据的时效性和完整性。
9. 数据权限管理:面板数据通常需要设置数据权限,以控制数据的访问和使用。
数据权限管理可以包括用户身份认证、数据访问控制等。
通过数据权限管理,可以保护面板数据的安全和隐私。
《面板数据分析》课件

面板数据分析的步骤
1
数据描述
对数据进行描述性统计,确定数据在时间和个体方面的特征。
2
ห้องสมุดไป่ตู้
分类讨论
分析不同情况下个体间行为的差异和影响因素,如何影响个体行为的内部因素和外部 环境。
3
建模和估计
根据分类讨论的结论,运用面板数据模型建立样本分布,通过极大似然法和广义矩估 计法进行参数估计。
4
结果解释
对估计的结果进行解释,如何分析因素对个体行为的影响和相关关系等。
生产领域
跟踪生产的进度和效果,寻找 提高生产效率的方法。
总结和展望
总结
面板数据分析是一种高通量数据分析方法,通 过对个体间微观差异的捕捉和分析,提高了分 析数据的精确性,研究结果更具有真实性和普 遍性。
展望
随着数据分析和研究技术的不断发展,面板数 据分析将进一步被广泛接受和使用,为各行各 业的发展与创新提供支持。
《面板数据分析》PPT课 件
欢迎各位来到《面板数据分析》课件。本课程将向大家介绍如何运用面板数 据分析各种数据,并运用不同的分析方法提升数据的价值。
面板数据的定义和特点
什么是面板数据?
面板数据指的是在一定时间内,对相同个体做重复观测所得到的数据。
面板数据的特点
相对于横截面数据和时间序列数据,面板数据能够更精确地反映个体间的差异和发展。
面板数据模型的建立
线性回归模型
用于研究数值型因变量和数值 型自变量之间的关系。
逻辑回归模型
用于研究分类因变量和数值型 自变量之间的关系。
混合效应模型
考虑组间差异和个体内部差异, 更为精确地分析面板数据的特 点。
面板数据分析的常用方法
1 固定效应模型
详细的EVIEWS面板数据分析操作

详细的EVIEWS面板数据分析操作引言EVIEWS是一款专业的经济统计软件,广泛应用于经济学和金融领域的数据分析和建模。
EVIEWS提供了丰富的面板数据分析功能,可以帮助用户进行面板数据的处理、描述统计、回归分析等操作。
本文将详细介绍EVIEWS中面板数据分析的操作流程和常用功能。
EVIEWS面板数据的导入首先,我们需要将面板数据导入到EVIEWS中进行分析。
EVIEWS支持多种数据格式的导入,包括Excel、CSV、数据库等。
在导入面板数据时,需要保证数据具有正确的格式,例如面板数据应包含个体(cross-sectional)和时间(time-series)的维度,且面板数据的变量应按照一定的顺序排列。
在导入面板数据后,我们可以利用EVIEWS提供的数据操作命令对数据进行处理和调整。
例如,可以通过group命令将数据按照个体或时间进行分组,通过sort命令对数据进行排序,以便后续的面板数据分析。
面板数据的描述统计分析在面板数据导入并处理完毕后,我们可以进行面板数据的描述统计分析。
EVIEWS提供了丰富的统计功能,可以计算面板数据的平均值、标准差、相关系数等指标。
下面介绍几个常用的描述统计功能:1.summary命令:该命令可以计算面板数据每个变量的平均值、标准差、最大值、最小值等统计指标,并输出到EVIEWS的结果窗口中。
2.correlation命令:该命令可以计算面板数据各变量之间的相关系数矩阵,并输出到结果窗口中。
3.tabulate命令:该命令可以对面板数据进行交叉分组统计,例如计算变量A在变量B的每个取值下的频数和比例。
通过对面板数据进行描述统计分析,可以初步了解数据的分布特征和变量间的关系,为后续的面板数据分析提供基础。
面板数据的回归分析除了描述统计分析,EVIEWS还提供了面板数据的回归分析功能。
通过面板数据回归分析,可以探究变量间的因果关系和影响程度。
下面介绍两个常用的回归分析命令:1.panel least squares(PLS)命令:该命令可以进行面板数据的最小二乘回归分析。
R语言-面板数据分析步骤及流程-
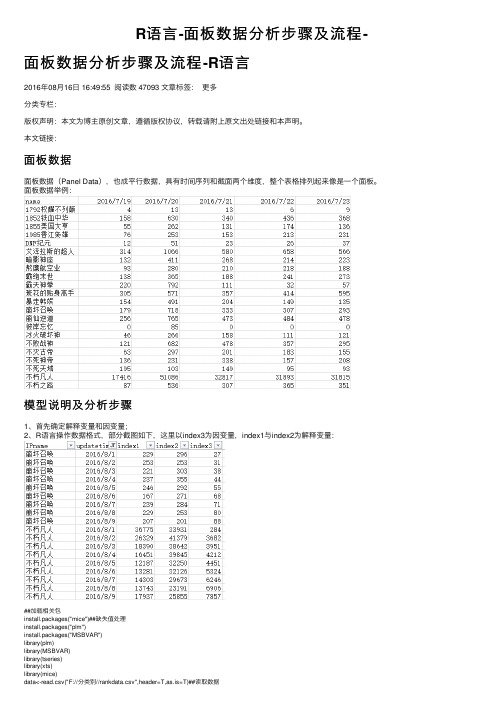
R语⾔-⾯板数据分析步骤及流程-⾯板数据分析步骤及流程-R语⾔2016年08⽉16⽇ 16:49:55 阅读数 47093 ⽂章标签:更多分类专栏:版权声明:本⽂为博主原创⽂章,遵循版权协议,转载请附上原⽂出处链接和本声明。
本⽂链接:⾯板数据⾯板数据(Panel Data),也成平⾏数据,具有时间序列和截⾯两个维度,整个表格排列起来像是⼀个⾯板。
⾯板数据举例:模型说明及分析步骤1、⾸先确定解释变量和因变量;2、R语⾔操作数据格式,部分截图如下,这⾥以index3为因变量,index1与index2为解释变量:##加载相关包install.packages("mice")##缺失值处理install.packages("plm")install.packages("MSBVAR")library(plm)library(MSBVAR)library(tseries)library(xts)library(mice)data<-read.csv("F://分类别//rankdata.csv",header=T,as.is=T)##读取数据123456789102、单位根检验:数据平稳性为避免伪回归,确保结果的有效性,需对数据进⾏平稳性判断。
何为平稳,⼀般认为时间序列提出时间趋势和不变均值(截距)后,剩余序列为⽩噪声序列即零均值、同⽅差。
常⽤的单位根检验的办法有LLC检验和不同单位根的Fisher-ADF检验,若两种检验均拒绝存在单位根的原假设则认为序列为平稳的,反之不平稳(对于⽔平序列,若⾮平稳,则对序列进⾏⼀阶差分,再进⾏后续检验,若仍存在单位根,则继续进⾏⾼阶差分,直⾄平稳,I(0)即为零阶单整,I(N)为N阶单整)。
##单位根检验tlist1<-xts(data$index1,as.Date(data$updatetime))adf.test(tlist1)tlist2<-xts(data$index2,as.Date(data$updatetime))adf.test(tlist2)123453、协整检验/模型修正单位根检验之后,变量间是同阶单整,可进⾏协整检验,协整检验是⽤来考察变量间的长期均衡关系的⽅法。
面板数据分析
面板数据分析方法或许我们已经了解许多了,但是到底有没有一个基本的步骤呢?那些步骤是必须的?这些都是我们在研究的过程中需要考虑的,而且又是很实在的问题。
面板单位根检验如何进行?协整检验呢?什么情况下要进行模型的修正?面板模型回归形式的选择?如何更有效的进行回归?诸如此类的问题我们应该如何去分析并一一解决?以下是我近期对面板数据研究后做出的一个简要总结,和大家分享一下,也希望大家都进来讨论讨论。
步骤一:面板数据分析之分析数据的平稳性(单位根检验)按照正规程序,面板数据模型在回归前需检验数据的平稳性。
李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。
这种情况称为称为虚假回归或伪回归(spurious regression)。
他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。
因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。
因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。
而检验数据平稳性最常用的办法就是单位根检验。
首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。
单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,LevinandLin(1993) 很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据分析中,并建立了对面板单位根进行检验的早期版本。
后来经过Levin et al. (2002)的改进,提出了检验面板单位根的LLC 法。
Levin et al. (2002) 指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250 之间,截面数介于10~250 之间) 的面板单位根检验。
EVIEWS面板数据分析操作教程及实例
获得S1,S2,S3后手工计算F2,F1,并查找临界值做出判定 请点:判定规则 请点 判定实例
27
模型形式检验步骤:注要手工计算
例10.5中系数 和 取何种形式可以利用模型形式设定检验方法 来确定。 (1) 首先分别计算3种形式的模型:变参数模型、变截距模 型和不变参数模型,在每个模型的回归统计量里可以得到相应 的残差平方和S1=339121.5、S2 = 444288.4 和S3 = 1570884。 (2) 按(10.2.7)式和(10.2.8)式计算F统计量,其中N=5、k=2、 T=20,得到的两个F统计量分别为: F1=((S2-S1)/8)/(S1 /85) = 3.29 F2=((S3-S1)/12)/(S1 /85) = 25.73 利用函数 @qfdist(d,k1,k2) 得到F分布的临界值,其中d 是临 界点,k1和k2是自由度。在给定5%的显著性水平下(d=0.95),得 到相应的临界值为: F2(12, 85) = 1.87 F1(8, 85) =2.049
16
表10.8 Johansen面板协整检验结果
(选择序列有确定性趋势而协整方程只有截距的情况) Fisher联合-max统计 量(p值) 128.7 (0.0000)* 65.74 (0.2266)
原假设
Fisher联合迹统计 量(p值) 133.4 (0.0000)* 65.74 (0.2266)
Kao检验 H0: = 1
除此项 外均支 持协整
Group-rho-Statistic -0.837712(0.2809) H0: = 1 Group PP-Statistic -6.990581(0.0000)* H1 :(i = )< 1 Group ADF-Statistic -7.194068(0.0000)*
面板数据回归分析步骤(一)
面板数据回归分析步骤(一)引言概述:面板数据回归分析是一种常用的经济学和统计学方法,用于研究面板数据的相关性、影响因素和趋势。
本文将详细介绍面板数据回归分析的步骤和方法,帮助读者更好地理解和应用这一方法。
正文:一、数据准备1. 收集面板数据:通过调查、观测或公共数据库来获得所需的面板数据。
2. 确定面板数据的类型:面板数据可以是平衡面板数据(每个交叉单元的观测次数相等)或非平衡面板数据(每个交叉单元的观测次数不相等)。
3. 检查数据的完整性和准确性:对面板数据进行缺失值和异常值的处理,确保数据的可靠性。
二、建立模型1. 确定因变量和自变量:根据研究目的和问题,确定面板数据中的因变量和自变量。
2. 选择适当的回归模型:根据变量的特点和关系,选择合适的面板数据回归模型,如随机效应模型、固定效应模型或混合效应模型。
3. 进行模型检验和诊断:对所选的面板数据回归模型进行统计检验,检查模型的拟合度和假设的成立情况。
三、估计回归系数1. 选择估计方法:根据面板数据的性质,选择合适的估计方法,如最小二乘法、广义最小二乘法或仪器变量法。
2. 进行回归系数估计:根据选择的估计方法,对面板数据回归模型进行回归系数估计,得到对各个自变量的系数估计值。
四、解释结果1. 解释回归系数:根据回归系数的估计结果,解释自变量对因变量的影响程度和方向。
2. 进行统计推断:对回归系数进行假设检验和置信区间估计,判断回归系数的显著性和可靠性。
五、结果分析与应用1. 分析回归结果:综合考虑回归系数的解释和统计推断结果,分析面板数据回归分析的整体效果和相关性。
2. 制定政策建议:通过分析回归结果,得出结论并提出政策建议,为决策者提供参考和借鉴。
总结:本文系统介绍了面板数据回归分析的步骤和方法,包括数据准备、模型建立、回归系数估计、结果解释和分析以及应用。
通过学习和应用面板数据回归分析,可以更好地理解和分析面板数据的相关性和趋势,从而为决策者提供有力的支持。
面板数据的常见处理
面板数据的常见处理面板数据是一种特殊的数据结构,它包含了多个个体(如个人、公司等)在多个时间周期内的观测值。
在实际的数据分析中,对面板数据的处理是非往往见的任务。
本文将详细介绍面板数据的常见处理方法,包括面板数据的描述统计、面板数据的平均值计算、面板数据的差分处理和面板数据的合并等。
1. 面板数据的描述统计描述统计是对面板数据进行初步分析的重要步骤。
常见的描述统计指标包括平均值、标准差、最小值、最大值等。
对于面板数据,我们可以通过计算每一个个体在每一个时间周期内的平均值、标准差等指标,来描述面板数据的整体特征。
此外,还可以计算面板数据的相关系数矩阵,来分析不同个体之间以及不同时间周期之间的关系。
2. 面板数据的平均值计算计算面板数据的平均值是对面板数据进行汇总的一种方法。
常见的面板数据平均值计算方法包括个体平均值和时间周期平均值。
个体平均值是指计算每一个个体在所有时间周期内观测值的平均值,而时间周期平均值是指计算每一个时间周期内所有个体观测值的平均值。
通过计算面板数据的平均值,可以得到面板数据的整体水平。
3. 面板数据的差分处理差分处理是对面板数据进行时间序列分析的一种方法。
差分处理可以用于去除面板数据中的趋势成份,使得数据更具平稳性。
常见的差分处理方法包括一阶差分和二阶差分。
一阶差分是指计算相邻时间周期内观测值的差异,二阶差分是指计算相邻时间周期内一阶差分的差异。
通过差分处理,可以得到面板数据的白噪声序列,便于后续的时间序列分析。
4. 面板数据的合并面板数据的合并是将多个面板数据集合并成一个面板数据的过程。
常见的面板数据合并方法包括纵向合并和横向合并。
纵向合并是指将多个个体在同一时间周期内的观测值合并成一个面板数据,横向合并是指将同一个体在不同时间周期内的观测值合并成一个面板数据。
通过面板数据的合并,可以得到更大样本量的面板数据,提高数据分析的准确性和可靠性。
综上所述,面板数据的常见处理包括面板数据的描述统计、面板数据的平均值计算、面板数据的差分处理和面板数据的合并等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Stata’s estimation commands with option robust also contain a cluster() option and it is this option which allows the computation of socalled Rogers or clustered standard errors.
company 1 year 1951 invest 755.9 mvalue 4833
1
1ห้องสมุดไป่ตู้
1952
1953
891.2
1304.4
4924.9
6241.7
1
2 2 2 2 3 3 3
1954
1951 1952 1953 1954 1951 1952 1953
1486.7
588.2 645.5 641 459.3 135.2 157.3 179.5
例如:共有7个州,方程可以写成:
Yit 0 1 Xit 1D1 2 D2 3D3 4 D4 5 D5 6 D6 ui
7个州的回归线斜率相同,但截距不同。
1 0 第2个州的截距是: 2 0 1 第3个州的截距是: 3 0 2 第4个州的截距是: 4 0 3
模型的估计
固定效应模型 固定效应变换(Fixed Effects Transformation) (组内变换)(Within Transformation) LSDV (Least Square Dummy Variable
固定效应变换
Yit 1 X it i it
PLS or RE xtreg fatal beertax spircons unrate perinck year2-year7,re xttest0/xttest1(AR(1))
PLS or RE
FE or RE Hausman test1 xtreg fatal beertax spircons unrate perinck year2year7, fe est store FE xtreg fatal beertax spircons unrate perinck year2year7, re hausman FE, sigmamore
y it xit ui it i 1,...n; t 1,...,T 其中u i为不可观测的个体效应 如果u i与所有解释变量不相关 ,则为随机效应模型
混合回归模型(Pooled Regression Model)
如果u i 0,即不存在个体效应,则 为混合回归模型: y it xit it i 1,...n; t 1,...,T
短面板数据分析的基本程序
方红生
浙江大学经济学院 2013年秋
参考书
计量经济学导论第四版(伍德里奇)中文版或 英文版 用Stata学计量经济学 高级计量经济学及stata应用(陈强)
内容安排
第 1讲 第 2讲 第 3讲 第 4讲 第 5讲 第 6讲 短面板数据分析 长面板数据分析(PPT 内生性与工具变量法 动态面板数据模型 双重差分模型及其应用 基于DID的权威文献做对了吗? (学生报告与讨论) 第7讲 PSMDID 第8讲 如何识别核心变量的作用机制?
Testing for Cross-sectional Dependence
xtcsd
xttest2
短面板
长面板
xtcsd is a postestimation command valid for use after running an FE or RE model. xtcsd can also perform Pesaran’s CD test for unbalanced panels.
短面板数据
面板数据(panel data)是同时在时间和截面上
取得的二维数据,也称时间序列与截面混合数
据(pooled time series and cross section data)。
是在一段时间内跟踪同一组个体的数据。既有
横截面的维度(n个个体),又有时间维度(T
个时期)。
Stata中面板数据结构
use traffic.dta des
面板数据模型
非观测效应模型(unobserved effects model) 固定效应模型(Fixed Effects Model, FE) 随机效应模型(Random Effects Model, RE) 混合回归模型(Pooled Regression Model)
RE, FE and PLS
Pooled OLS: Fixed Effects Estimator:
0
1
0,RE OLS( i 相对u i 不重要时) 1, RE FE(相对重要时)
Stata 命令
xtreg xi:xtreg ,re i.year ,re
(式1)
给定第i 个个体,将(式1)两边对时间取平均可得,
Yi 1 X i i i
(式2)
(式1) – (式2)得:
令
,则
可以用OLS方法估计β ,称为“固定效应估计量” ˆ FE (Fixed Effects Estimator),记为
ˆ FE主要使用了每个个体的组内离差信息,故 由于 也称为“组内估计量”(within estimator)。
第3步:模型选择
PLS or FE tab year, gen(year) 1. xtreg fatal beertax spircons unrate perinck year2year7,fe
这里误差项可能存在自相关、异方差和截面 相关问题,所以F检验显示的结果可能不可靠, 所以严格的话,首先要检验是否存在截面相关 问题,命令如下: xtcsd,pes xtcsd,fri xtcsd,fre
北京
北京 北京
1
1 1
2006
2007 2008
天津
天津
2
2
2000
2001
短面板:N>T;反之为长面板。
平衡面板数据(balanced panel data):如果每
个个体在相同的时间内都有观测值记录。
For any i, there are T observations.
非平衡面板数据(unbalanced panel):T may
第1个州的截距是:
Stata 命令
xi: reg xi: reg i.code i.code i.year
随机效应模型估计
GLS
The usual pooled OLS can give consistent estimators ,but as its standard errors ignore the positive serial correlation in the composite error term, they will be incorrect.
it i it
2 2 2 Corr( it , is ) /( ),t s
Solution: GLS transformation to eliminate the : serial correlation
yit yi 0 (1 ) 1 ( xit1 xi1 ) ... k ( xitk xik ) ( it i )
5593.6
2289.5 2159.4 2031.3 2115.5 1819.4 2079.7 2371.6
3
1954
189.6
2759.9
region 北京 北京 北京 北京 北京 北京
code 1 1 1 1 1 1
year 2000 2001 2002 2003 2004 2005
rgdp
inflation
But
While all these techniques of estimating the covariance matrix are robust to certain violations of the regression model assumptions, they do not consider cross-sectional correlation. However, due to social norms and psychological behavior patterns, spatial dependence can be a problematic feature of any microeconometric panel dataset even if the cross-sectional units(e.g. individuals or firms) have been randomly selected.
固定效应模型(Fixed Effects Model, FE)
y it xit ui it i 1,...n; t 1,...,T 其中u i 为不可观测的个体效应 如果u i 与某个解释变量相关, 则为固定效应模型
随机效应模型(Random Effects Model, RE)
These estimators can be based on the pooled OLS or fixed effects residuals.
Random Effects Estimator: The feasible GLS estimator that uses
in place of
PLS or FE