(精选)ECM误差修正模型
5.3 协整与误差修正模型 计量经济学PPT课件

• 非平稳的时间序列,它们的线性组合也可能成为 平稳的。称变量X与Y是协整的(cointegrated)。
3、协整
• 如果序列{X1t,X2t,…,Xkt}都是d阶单整,存在向量 =(1,2,…,k),使得Zt=XT ~ I(d-b), 其中,b>0,X=(X1t,X2t,…,Xkt)T,则认为序列 {X1t,X2t,…,Xkt}是(d,b)阶协整,记为Xt~CI(d,b), 为协整向量(cointegrated vector)。
5%的显著性水平下协 整的ADF检验临界值
为-3.521
注意:查什么临 界值表?
结论:中国居民总量消费的对数序 列lnY与总可支配收入的对数序列 lnX之间存在(1,1)阶协整。
注意:
这里采用由协整检 验临界值表算得的 临界值(-3.521 ),没有采用ADF 检验给出的临界值 (-1.953),是 正确的。但是,在 很多应用研究中忽 视了这一点,而直 接采用ADF检验给 出的临界值,则是 错误的,容易产生
• 均衡方程中应该包含均衡系统中的所有时间序 列,而协整方程中可以只包含其中的一部分时 间序列。
• 协整方程的随机扰动项是平稳的,而均衡方程 的随机扰动项必须是白噪声。
• 不能由协整导出均衡,只能用协整检验均衡。
五、误差修正模型 Error Correction Model, ECM
1、一般差分模型的问题
• 对于非稳定时间序列,可通过差分的方法将其 化为稳定序列,然后才可建立经典的回归分析 模型。
Yt 0 1 X t t
Yt 1X t vt vt t t1
计量经济学第五章协整与误差修正模型

根据需要对数据进行变换,如对数变换、差 分变换等,以满足模型对数据的要求。
模型参数估计方法选择
01
最小二乘法(OLS )
适用于满足经典假设的线性回归 模型,通过最小化残差平方和来 估计模型参数。
02
广义最小二乘法( GLS)
适用于存在异方差性的模型,通 过加权最小二乘法进行参数估计 ,以消除异方差性的影响。
误差修正模型定义
误差修正模型(Error Correction Model,简称ECM)是一种具有特定形式的计 量经济学模型,用于描述变量之间的长期均衡关系和短期动态调整过程。
该模型通过引入误差修正项,将变量的短期波动和长期均衡关系结合起来,从而 更准确地刻画经济现象。
误差修正项解释
误差修正项(Error Correction Term,简称ECT)是误差修正模型中的核 心部分,表示变量之间的长期均衡误差。
长期均衡
协整关系反映了时间序列之间的长期均衡,即使短期内有所偏离,长期内也会恢复到均 衡状态。
线性组合平稳
协整序列的线性组合可以消除非平稳性,得到平稳序列。
协整检验方法
EG两步法
首先通过OLS回归得到残差序列,然 后对残差序列进行单位根检验(如 ADF检验),判断其是否平稳。
Johansen检验
适用于多变量协整关系的检验,通过 构建似然比统计量来判断协整向量的 个数。
计量经济学第五章协 整与误差修正模型
汇报人:XX
目 录
• 协整理论概述 • 误差修正模型介绍 • 协整与误差修正模型关系 • 协整检验方法及应用举例 • 误差修正模型建立与评估 • 案例研究:金融市场波动性分析
01
协整理论概述
协整定义及性质
var, ecm

VaR(Value at Risk)按字面解释就是“在险价值”,其含义指:在市场正常波动下,某一金融资产或证券组合的最大可能损失。
更为确切的是指,在一定概率水平(置信度)下,某一金融资产或证券组合价值在未来特定时期内的最大可能损失。
VaR的表示公式[1]用公式表示为:P(ΔPΔt≤VaR)=a字母含义如下:P——资产价值损失小于可能损失上限的概率,即英文的Probability。
ΔP——某一金融资产在一定持有期Δt的价值损失额。
VaR——给定置信水平a下的在险价值,即可能的损失上限。
a——给定的置信水平VaR从统计的意义上讲,本身是个数字,是指面临“正常”的市场波动时“处于风险状态的价值”。
即在给定的置信水平和一定的持有期限内,预期的最大损失量(可以是绝对值,也可以是相对值)。
例如,某一投资公司持有的证券组合在未来24小时内,置信度为95%,在证券市场正常波动的情况下,VaR值为520万元,其含义是指,该公司的证券组合在一天内(24小时),由于市场价格变化而带来的最大损失超过520万元的概率为5%,平均20个交易日才可能出现一次这种情况。
或者说有95%的把握判断该投资公司在下一个交易日内的损失在520万元以内。
5%的几率反映了金融资产管理者的风险厌恶程度,可根据不同的投资者对风险的偏好程度和承受能力来确定。
VaR的计算系数由上述定义出发,要确定一个金融机构或资产组合的VaR值或建立VaR的模型,必须首先确定以下三个系数:一是持有期间的长短;二是置信区间的大小;三是观察期间。
1、持有期。
持有期△t,即确定计算在哪一段时间内的持有资产的最大损失值,也就是明确风险管理者关心资产在一天内一周内还是一个月内的风险价值。
持有期的选择应依据所持有资产的特点来确定比如对于一些流动性很强的交易头寸往往需以每日为周期计算风险收益和VaR值,如G30小组在1993年的衍生产品的实践和规则中就建议对场外OTC衍生工具以每日为周期计算其VaR,而对一些期限较长的头寸如养老基金和其他投资基金则可以以每月为周期。
面板数据、格兰杰因果关系、向量自回归和向量误差修正模型

面板数据、格兰杰因果关系、向量自回归和向量误差修正模型(2011-06-13 11:43:22)标签: 分类: 工作篇校园面板数据的计量方法1.什么是面板数据,面板数据,panel data,也称时间序列截面数据,time series and cross section data,或混合数据,pool data,。
面板数据是截面数据与时间序列综合起来的一种数据资源~是同时在时间和截面空间上取得的二维数据。
如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8,单位亿元,。
这就是截面数据~在一个时间点处切开~看各个城市的不同就是截面数据。
如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12,单位亿元,。
这就是时间序列~选一个城市~看各个样本时间点的不同就是时间序列。
如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12,上海市分别为9、10、11、12、13,天津市分别为5、6、7、8、9,重庆市分别为7、8、9、10、11,单位亿元,。
这就是面板数据。
2.面板数据的计量方法利用面板数据建立模型的好处是:,1,由于观测值的增多~可以增加估计量的抽样精度。
,2,对于固定效应模型能得到参数的一致估计量~甚至有效估计量。
,3,面板数据建模比单截面数据建模可以获得更多的动态信息。
例如1990-2000 年30 个省份的农业总产值数据。
固定在某一年份上~它是由30 个农业总产值数字组成的截面数据,固定在某一省份上~它是由11 年农业总产值数据组成的一个时间序列。
面板数据由30 个个体组成。
共有330 个观测值。
面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型。
这三类模型的差异主要表现在系数、截距以及随机误差的假设不同。
第一种是混合估计模型,Pooled Regression Model,。
协整检验和误差修正模型
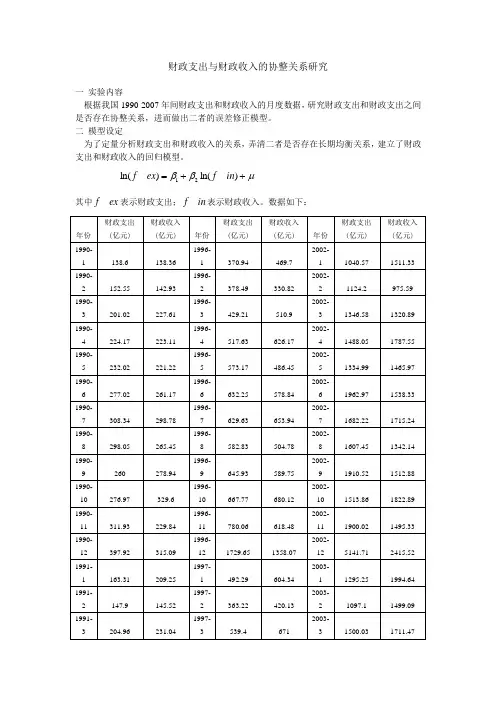
财政支出与财政收入的协整关系研究一 实验内容根据我国1990-2007年间财政支出和财政收入的月度数据,研究财政支出和财政支出之间是否存在协整关系,进而做出二者的误差修正模型。
二 模型设定为了定量分析财政支出和财政收入的关系,弄清二者是否存在长期均衡关系,建立了财政支出和财政收入的回归模型。
μββ++=)_ln()_ln(21in f ex f其中ex f _表示财政支出;in f _表示财政收入。
数据如下:数据来源:统计年鉴三、实证分析 1、数据处理由数据结构可以看出,数据存在季节波动。
首先利用X-12季节调整方法对这两个指标进行季节调整,消除季节因素,然后去对数。
2、单位根检验经济时间序列数据往往出现非平稳的情况,如果直接对数据建立回归模型,可能会出现伪回归的现象,因此在做回归之前,运用ADF 方法,对数据进行单位根检验。
对ln(ex f _)、ln(in f _)及其一阶差分进行单位根检验,具体检验结果如下所示:ln(ex f _)原值单位根检验Null Hypothesis: LNF_EX has a unit rootExogenous: ConstantLag Length: 5 (Automatic based on SIC, MAXLAG=14)t-StatisticProb.*Augmented Dickey-Fuller test statistic 0.519686 0.9871 Test critical values: 1% level -3.4614785% level -2.87512810% level -2.574090*MacKinnon (1996) one-sided p-values.f_)一阶差分单位根检验ln(exNull Hypothesis: D(LNF_EX) has a unit rootExogenous: ConstantLag Length: 4 (Automatic based on SIC, MAXLAG=14)t-Statistic Prob.* Augmented Dickey-Fuller test statistic -10.83446 0.0000 Test critical values: 1% level -3.4614785% level -2.87512810% level -2.574090*MacKinnon (1996) one-sided p-values.f_)原值单位根检验ln(inNull Hypothesis: LNF_IN has a unit rootExogenous: ConstantLag Length: 11 (Automatic based on SIC, MAXLAG=14)t-Statistic Prob.* Augmented Dickey-Fuller test statistic 0.763850 0.9932 Test critical values: 1% level -3.4624125% level -2.87553810% level -2.574309*MacKinnon (1996) one-sided p-values.f_)一阶差分单位根检验ln(inNull Hypothesis: D(LNF_IN) has a unit rootExogenous: ConstantLag Length: 10 (Automatic based on SIC, MAXLAG=14)t-Statistic Prob.*Augmented Dickey-Fuller test statistic -8.161494 0.0000Test critical values:1% level -3.462412 5% level -2.87553810% level-2.574309*MacKinnon (1996) one-sided p-values.汇总检验结果如下表所示:财政收入和财政支出的对数的原值和一阶差分的单位根检验结果指标 ADF 值P 值ln(ex f _) 0.519686 0.9871 ln(ex f _)的一阶差分-10.83446 0.0000 ln(in f _) 0.763850 0.9932 ln(in f _)的一阶差分 -8.1614940.0000从上表中的ADF 值和P 值可以看出:当显著性水平为0.05时,对ln(ex f _)和ln(in f _)的原值进行检验时,检验结果都表明不能拒绝“存在单位根”的原假设;而当对ln(ex f _)和ln(in f _)的一阶差分进行检验时,检验结果都表明拒绝“存在单位根”的原假设。
eviews试验:e-g两步法[宝典]
![eviews试验:e-g两步法[宝典]](https://uimg.taocdn.com/53b14fc03086bceb19e8b8f67c1cfad6195fe9da.webp)
E-G两步法协整检验和误差修正模型的建立实验内容:使用Eviews软件进行E-G两步法协整检验的操作,并建立误差修正模型。
分析我国居民实际可支配收入与居民实际消费之间是否存在长期均衡关系。
实验数据:我国的实际居民消费和实际可支配收入,变量均为剔除了价格因素的实际年度数据,样本区间为1978—2006年。
数据来源于各年的统计年鉴。
实验过程:1、实际居民消费CSP等于名义居民消费CS除于CPI,实际可支配收入INC 等于名义可支配收入YD除于CPI。
把上述数据导入到Eviews中,建立相应的系列。
2、对实际居民消费CSP序列和实际可支配收入INC序列进行ADF单位根检验,检验结果如下:注:△表示一阶差分,△2 表示二阶差分。
(C T K)表示检验类型,C表示常数项,T表示趋势项,K 表示滞后阶数。
﹡表示在1%的显著性水平下显著。
从ADF单位跟检验结果可知,csp和inc系列均为2阶单整系列,即csp~I(2),inc~I(2)。
因此可以对csp和inc系列进行协整关系检验。
3、建立回归方程。
点击菜单栏里的quick,选择下拉菜单的estimate equation。
在出现的对话框中依次输入:CSP、C、INC。
如下图所示:4、点击确定得到方程回归结果,如下图所示:5、在方程对象框中,单击proc,选择 make residual series,生成方程的残差系列,命名为“e”。
并对e系列进行ADF单位根检验,检验结果如下图所示:检验形式为即不包含常数项也不包含趋势项。
检验结果表明,在5%的显著性水平下,e 系列是平稳系列。
所以csp和inc 存在协整关系,也就是长期均衡关系。
6、建立误差修正模型:误差修正模型(ECM:Error Correction Model)的基本形式最早是由Davidson、Hendry、Srba和Yeo在1978年提出的,因此又称之为DHSY模型。
在建立经济模型的时候,经常会需要用数据的动态非均衡过程来逼近经济理论的长期均衡过程,最一般的模型就是自回归分布滞后模型(ADL:autoregressive distributed lag)。
基于ECM-GARCH模型对上证50股指期货套期保值的实证分析
期货价格的短期关系,并不能代表两者的长期关系。 3.2 误差修正 ECM 模型。如果有一个单位根,那么 数据是非平稳的。因此,为了排除伪回归现象的干扰, 应先对数据进行检验。
实验结果表明,现货价格与期货价格一阶差分后 得到的收益率形式通过 ADF 检验,t 统计量小于临界 值,拒绝原假设。然后利用股指期货和指数收盘价进 行最小二乘回归,再对得到的残差进行协整检验。检 验结果如图 2 所示:
其中,为方程模型的误差修正系数, 表示误差修
正项, 表示方程的截距项, 、 表示回归系数, 表示
满足独立同分布的随机误差项,
。回归系
数 也就是误差修正下模型测算出的套期保值率[3]。
2.3 ECM-GARCH 模型。上证 50 数据序列具有波动
性,我们应该考虑随时间变化的期货和现货价格的
GARCH 模型。由于 ECM 模型的残余误差有异方差,
在现货市场和期货市场对同一种类的商品同时进 行数量相等但方向相反的买卖活动,即在买进或卖出 现货的同时,在期货市场上卖出或买进同等数量的期 货[1],经过一段时间,当价格变动使现货买卖上出现 盈亏时,可由期货交易上的亏盈得到抵消或弥补。在 “现货”与“期货”之间、近期和远期之间建立一种对冲 机制,从而使价格风险降低到最低限度,这就是套期 保值的原理[2]。
最小二乘法的特点是:计算简单,易于理解,但长 期观察可以发现其残差中有异方差和自相关。 2.2 误差修正 ECM 模型。由于 OLS 模型的异方差和 自相关问题,因此减少了参数估计的有效性。同时, 两者之间的协整关系我们也不能忽略。
两 个 时 间 序 列 存 在 协 整 关 系 时,我 们 可 以 利 用 ECM 模型对序列中数据进行修正。
和 分别为第 t 天与第 t-l 天的收盘价格。股指
金融计量学,唐勇,课件.详解
6.3.1
Johansen协整检验的基本说明
6.3.1
Johansen协整检验的基本说明
6.3.1
Johansen协整检验的基本说明
6.3.1
Johansen协整检验的基本说明
6.3.1
Johansen协整检验的基本说明
6.3.1
Johansen协整检验的基本说明
6.3.1
Johansen协整检验的基本说明
6.1.2
协整检验方法
6.1.2
协整检验方法
ˆt 的最小二乘 需要注意的是,由于E-G两步法是采用协整回归的残差e ˆt 来检验平稳性的,此时的检验临界值不能再用传统的(A)DF 法估计值 e
检验的临界值,而是要采用Engle和Granger提供的临界值(见表6-1),
因此这种协整检验方法又称为扩展的Engle和Granger检验,简称AEG检验。
6.4
向量误差修正模型(VECM)
6.4
向量误差修正模型(VECM)
6.4
向量误差修正模型(VECM)
6.4
向量误差修正模型(VECM)
上述仅讨论了简单的向量误差修正模型,与VAR模型类似,我们可以 构造结构向量误差修正模型,同样也可以考虑向量误差修正模型的 Granger因果检验、脉冲响应函数和方差分解。关于VAR模型和向量误差 修正模型的更多讨论,可以参考汉密尔顿(1999)的详细讨论。
6.1.2
协整检验方法
图6-1: 两种指数2
协整检验方法
图6-2: logSZZS的ADF检验结 果
6.1.2
协整检验方法
图6-3: logSZCZ的ADF检验结 果
6.1.2
协整检验方法
平稳性检验——精选推荐
平稳性检验协整理论(Cointegration)是Granger和Engle在20世纪80年代中后期提出的,用于非平稳变量组成的关系式中长期均衡参数估计的技术。
在实际运用时,一般是首先对时间变量序列及其一阶差分序列的平稳性进行检验;其次是检验变量间协整关系,并建立修正误差模型(ECM);第三对具有协整关系的时间变量序列的因果关系进一步检验分析。
协整理论从分析时间序列的非平稳性着手,探求非平稳经济变量间蕴含的长期均衡关系。
即两经济时序数据{xt,yt}在以xt为横坐标、yt为纵坐标上,其散点图围绕在某一条直线yt=β0 β1xt的周围,直线对点(xt,yt)起着引力线的作用,当(xt,yt)偏离该直线时,引力线的作用会使它们回到直线附近,虽然不能立即到达直线上,但存在着回归这条直线的总趋势。
定义如下:若变量向量置中所有分量均为d阶单整,即Xt~I(d),且存在一个非零向量βt使得向量Zt=βXt~I(d-b),b>0,则称变量向量Xt为具有d,b阶协整关系,表示为Xt~ CI(d,b),而β为协整向量。
从经济学的观点看,协整可理解为经济时序变量间存在着一种均衡力量,使非平稳的不同变量在长期内一起运动,即如果变量之间存在长期稳定关系(协整关系),变量的增长率表现共同的增长趋势。
反之,如果这两个或以上变量不是协整的,则它们之间不存在一个长期的均衡关系。
协整理论从变量之间是否具有协整关系出发选择模型的变量,使得数据基础更加稳定,统计性质更为优良。
平稳性检验方法有:DF检验法、ADF检验法、PP检验法、霍尔工具变量法、DF-GLS变量法、KPSS检验法等等。
ADF法(Augmented-Dicky-full-er)检验变量的稳定性,即进行平稳性检验,回归方程如下:并作假设检验:H0:a2=0,H1:a2≠0,如果接受假设H0而拒绝H1,则说明序列xt存在单位根,因而是非稳定的;否则说明序列xt不存在单位根,即是稳定的。
固定资产投资经济增长误差修正模型论文
固定资产投资与经济增长的误差修正模型分析【摘要】为了研究固定资产投资对经济增长的作用方向和效果,本文以重庆市为例结合当地实际经济发展状况,运用计量经济学中的协整关系检验和格兰杰因果检验及误差修正模型,对重庆1985~2009年的国内生产总值与固定资产投资之间的相关关系进行了实证分析,得出结论与启示,固定资产投资有效地推动了重庆市经济增长,二者之间存在着长期稳定关系,但还是要警惕投资过热后的一些问题并提出了相关建议。
【关键词】gdp;固定资产投资;误差修正模型在当今经济的高速列车上,投资需求已然成为我们国家经济一直保持着平稳较快增长的重要因素。
其中投资尤以固定资产投资为主要项目,因此固定资产投资对各省的经济增长起到了主要的促进作用。
重庆作为西南地区的唯一直辖市,成为国家振兴西部经济建设的先头军,也是西部战略中的重要门户。
近年来不仅大力引进外资,同时也增加了固定资产投资的力度,增加了劳动就业,通过比较优势和后发优势逐渐缩小与东部地区之间的差异,多管齐下的促进经济的增长。
为了研究固定资产投资对重庆市经济增长的作用方向和效果,本文欲采用1985~2009年的数据进行回归分析、协整检验、误差修正模型和格兰杰因果检验等计量方法,研究重庆市固定资产对gdp的影响。
由于计算过程中的数据繁琐,所有数据处理均采用excel和eivews软件实现模型计算。
一、重庆固定资产投资与经济增长的实证分析(一)数据选取和分析本文所使用的样本取自1986-2010年重庆统计年鉴,为了剔除通货膨胀因素和消除数据产生的异方差影响,保证数据的可比性,所有数据除以当年的cpi并取对数,即lngdp、lnfai,从而增强数据的平稳性,使结论更准确真实。
同时为了大家直观了解fai对gdp 的作用以及两者的相关性,我们在样本区间对两者数据做了散点图,如图1所示。
(二)协整分析1.变量的平稳性检验。
本文采用的数据是时间序列,采用的方法是对数据进行差分检验,即adf单位根检验。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
协整与误差修正模型 在处理时间序列数据时,我们还得考虑序列的平稳性。如果一个时间序列的均值或自协方差函数随时间而改变,那么该序列就是非平稳的。对于非平稳的数据,采用传统的估计方法,可能会导致错误的推断,即伪回归。若非平稳序列经过一阶差分变为平稳序列,那么该序列就为一阶单整序列。对一组非平稳但具有同阶的序列而言,若它们的线性组合为平稳序列,则称该组合序列具有协整关系。对具有协整关系的序列,我们算出误差修正项,并将误差修正项的滞后一期看做一个解释变量,连同其他反映短期波动关系的变量一起。建立误差修正模型。 建立误差修正模型的步骤如下:首先,对单个序列进行单根检验,进行单根检验有两种:ADF(Augument Dickey-Fuller)和DF(Dickey-Fuller)检验法。若序列都是同阶单整,我们就可以对其进行协整分析。在此我们只介绍单个方程的检验方法。对于多向量的检验参见Johensen协整检验。我们可以先求出误差项,再建立误差修正模型,也可以先求出向量误差修正模型,然后算出误差修正项。补充一点的是,误差修正模型反映的是变量短期的相互关系,而误差修正项反映出变量长期的关系。下面我们给出案例分析。
案例分析 在此,我们考虑从1978年到2002年城镇居民的人均可支配收入income与人均消费水平consume的关系,数据来自于《中国统计年鉴》,如表8.1所示。根据相对收入假设理论,在一定时期,人们的当期的消费水平不仅与当期的可支配收入、而且受前期的消费水平的影响,具有一定的消费惯性,这就是消费的棘轮效应。从这个理论出发,我们可以建立如下(8.1)式的模型。同时根据生命周期假设理论,消费者的消费不仅与当期收入有关,同时也受过去各项的收入以及对将来预期收入的限制和影响。从我们下面的数据分析中,我们可以把相对收入假设理论与生命周期假设理论联系起来,推出如下的结果:当期的消费水平不仅与当期的可支配收入有关,而且还与前期的可支配收入、前两期的消费水平有关。在此先对人均可支配收入和人均消费水平取对数,同时给出如下的模型
tttlincomelconsumelconsume2110 t=1,2,…,n (8.1) 如果当期的人均消费水平与当期的人均可支配收入及前期的人均消费水平均为一阶单整序列,而它们的线性组合为平稳序列,那么我们可以求出误差修正序列,并建立误差修正模型,如下:
tecmlconsumelincomelconsumetttt4131210 t=1,2,…,n
(8.2) tecm= 12110tttlincomelconsumelconsume t=1,2,…,n
(8.3) 从(8.2)式我们可以推出如下的方程:
tlincomelincomelconsumelconsumelconsumettttt4030123222131131)()()1(
(8.4)
在(8.2)中lconsume、 lincome分别为变量对数滞后一期的值,)1(ecm为误差修正项,如(8.3)式所示。(8.2)式为含有常数项和趋势项的形式,我们省略了只含趋 势项或常数项及二项均无的形式。 表8.1
year 城镇人均可支配收入(元) 城镇居民人均消费额(元) year 城镇人均可支配收入(元) 城镇居民人均消费额(元) 1978 343.4 116.06 1991 1700.6 619.79 1979 405 134.51 1992 2026.6 659.21 1980 477.6 162.21 1993 2577.4 769.65 1981 500.4 190.81 1994 3496.2 1016.81 1982 535.3 220.23 1995 4283 1310.36 1983 564.6 248.29 1996 4838.9 1572.08 1984 652.1 273.8 1997 5160.3 1617.15 1985 739.1 317.42 1998 5425.1 1590.33 1986 900.9 356.95 1999 5854 1577.42 1987 1002.1 398.29 2000 6280 1670.13 1988 1180.2 476.66 2001 6859.6 1741.09 1989 1373.9 535.37 2002 7702.8 1834.31 1990 1510.2 584.63
分析步骤: 1、 单位根检验。 我们先介绍ADF检验。在检验过程中,若ADF检验值的绝对值大于临界值的绝对值,则认为被检验的序列为平稳序列。在此我们先以对lincome的检验为例,在主菜单中选择Quick/Series Statistics/Unit Root Test,屏幕提示用户输入待检验序列名,输入lincome,单击OK进入单位根检验定义的对话框,如图8.1。
图8.1 对话框由三部分构成。检验类型(Test Type)中默认项是ADF检验。Test for unit root In 中可选择的是对原序列、一阶差分序列或是二阶差序列做单位根检验,在此我们保持默认的level,即原序列。右上方的Include in test equation中,有三个选项,依次为含常数项,含常数项和趋势项,没有常数项且没有趋势。在右下方的空格里默认为2,但我们一般根据AIC最小来确定滞后期数,本文选定为滞后一期。检验的顺序为:先选含趋势项和常数项的检验,如果趋势项的T统计量不明显,就再选只含常 数项的,如果常数项的T统计量不明显,就选择常数项和趋势项均不包括的一项。当我们选含趋势项和常数项的检验时,会出现下面的结果,如图8.2所示。
图8.2 在检验的结果输出窗口中,左上方为ADF检验值,右上方为1%、5%和10%的显著水平下的临界值,从图8.1中可以看出ADF统计的检验值为-3.117,其绝对值小于10%的显著水平的临界值–3.2856的绝对值。同时趋势值的T统计来看,在5%的水平下显著。注意,这里的T统计量不同于我们在做最小二乘时用的T统计值。这些T统计检验的临界值在Fuller(1976)中给出.从上面的分析我们可以认为该序列为非平稳的序列,且该序列有趋势项和常数项。在下文中我们会进行一步介绍只含常数项的和常数项与趋势项均不包括的ADF检验的过程。 在上面分析的基础上,我们回到图8.1的窗口,检验lincome差分一阶的平稳性。在图8.1中的Test for unit root In中选差分一阶,同时在Include in test equation中选取含趋势项和常数项这一项,我们同样根据AIC和SC最小来选择滞后两期。此时会出现如下图8.3的结果:
图8.3 从上图中可以看出ADF的绝对值小于5%水平下的临界值的绝对值,大于10%的检验值的绝对值。但此时趋势项的T检验值不明显。所以我们回到图8.1的窗口,在Include in test equation中选取含常数项这一项。其结果如下图8.4所示,结果显示ADF的绝对值为3.4546大于5%水平下的临界值的绝对值,此时常数项的T检验值为3.34572,大于在显著水平为5%水平下的T临界值为2.61,所以常数项T检验值很明显。我们认为lincome序列差分一阶后为平稳的。值得注意的是,我们在此选择10%为临界值来判断非平稳的情况,而选择5%的临界值来判断平稳的情况,也就是,当ADF检验值的绝对值大于5%水平下的临界的绝对值。
图8.4 同时我们也可以用命令来执行单位根检验,格式如下: uroot(lags,options,h) series_name 其中,lags指式中滞后的阶数,options中可以选三个c、t和n,其中c代表含趋势项,t代表含趋势项和常数项,n代表不含趋势项也不含常数项。H表示采用pp检验, series_name即为序列名。 DF检验相当于ADF检验中的不含趋势项的常数项的情况。我们在此不再叙述。 2、协整检验。 在上面的例子中我们分析出城镇居民可支配收入为一阶单整序列,同时我们采用同样的分析方法,可知城镇居民的人均消费支出也为一阶单整。由此,可以对序列进行协整估计。 用变量lgdp对变量lm2进行普通最小二乘回归,在主窗口命令行中输入: ls lconsume c lconsume(-1) lincome 回车得到回归模型的估计结果,如图8.5所示。 图8.5 此时系统会自动生成残差,我们令残差为ecm,命令如下: ecm=resid 对残差项进行单位根检验,滞后期为1,结果如表8.2所示,从表中可以看出,残差序列为平稳序列,该协整关系成立。 表8.2 ADF Test Statistic -2.831448 1% Critical Value* -2.6756
5% Critical Value -1.9574 10% Critical Value -1.6238
3、误差修正模型。 上面的分析可以证明序列lconsume、lincome及lconsme(-1)之间存在协整关系,故可以建立ecm(误差修正模型)。先分别对序列lconsume、lincome及lconsme(-1)进行一阶差分,然后对误差修正模型进行估计。在主窗口命令行中输入: ls d(lconsume) c d(lincome) d(lconsume(-1)) ecm(-1) 此时的常数项系数不明显,我们去掉常数项后再进行回归,结果如下
图8.6所示
图8.6