两样本应变量反应曲线图分析-EmpowerStats
第二章:双变量线性回归分析
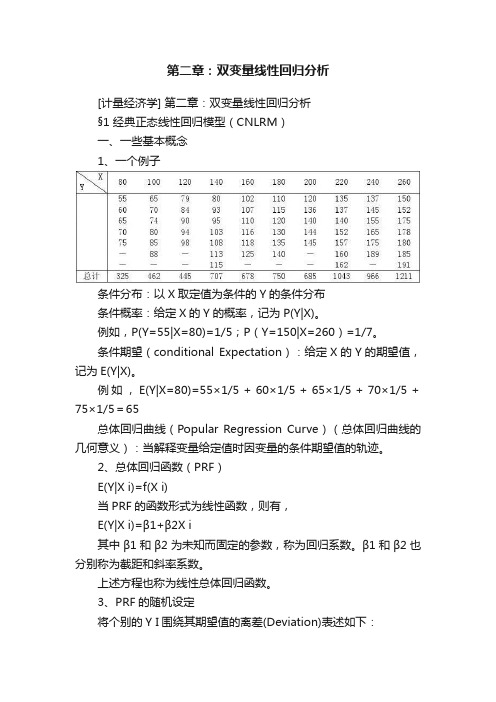
第二章:双变量线性回归分析[计量经济学] 第二章:双变量线性回归分析§1 经典正态线性回归模型(CNLRM)一、一些基本概念1、一个例子条件分布:以X取定值为条件的Y的条件分布条件概率:给定X的Y的概率,记为P(Y|X)。
例如,P(Y=55|X=80)=1/5;P(Y=150|X=260)=1/7。
条件期望(conditional Expectation):给定X的Y的期望值,记为E(Y|X)。
例如,E(Y|X=80)=55×1/5+60×1/5+65×1/5+70×1/5+75×1/5=65总体回归曲线(Popular Regression Curve)(总体回归曲线的几何意义):当解释变量给定值时因变量的条件期望值的轨迹。
2、总体回归函数(PRF)E(Y|X i)=f(X i)当PRF的函数形式为线性函数,则有,E(Y|X i)=β1+β2X i其中β1和β2为未知而固定的参数,称为回归系数。
β1和β2也分别称为截距和斜率系数。
上述方程也称为线性总体回归函数。
3、PRF的随机设定将个别的Y I围绕其期望值的离差(Deviation)表述如下:u i=Y i-E(Y|X i)或Y i=E(Y|X i)+u i其中u i是一个不可观测的可正可负的随机变量,称为随机扰动项或随机误差项。
4、“线性”的含义“线性”可作两种解释:对变量为线性,对参数为线性。
本课“线性”回归一词总是指对参数β为线性的一种回归(即参数只以它的1次方出现)。
模型对参数为线性?模型对变量为线性?是不是是LRM LRM不是NLRM NLRM注:LRM=线性回归模型;NLRM=非线性回归模型。
5、随机干扰项的意义随机扰动项是从模型中省略下来的而又集体地影响着Y 的全部变量的替代物。
显然的问题是:为什么不把这些变量明显地引进到模型中来?换句话说,为什么不构造一个含有尽可能多个变量的复回归模型呢?理由是多方面的:(1)理论的含糊性(2)数据的欠缺(3)核心变量与周边变量(4)内在随机性(5)替代变量(6)省略原则(7)错误的函数形式6、样本回归函数(SRF )(1)样本回归函数iY ?=1?β+2?βi X 其中Y ?=E(Y|X i )的估计量;1?β=1β的估计量;2β=2β的估计量。
SPSS基础教程02

第七章均数间的比较--Compare Means菜单详解7.1 Means过程7.1.1 界面说明7.1.2 结果解释7.2 One-Samples T Test过程7.2.1 界面说明7.2.2 结果解释7.3 Independent-Samples T Test过程7.3.1 界面说明7.3.2 结果解释7.4 Paired-Samples T Test过程7.4.1 界面说明7.4.2 分析实例7.4.3 结果解释7.5 One-Way ANOVA过程7.5.1 界面说明7.5.2 分析实例7.5.3 结果解释知道吗?在计算机领域中有个著名的80/20规则,也就是在奔腾及更早的CPU所采用的CISC指令集中,有80%的任务是被20%的最常用指令所完成的;换言之,另外80%的复杂指令只完成20%的不常用任务。
好了,言归正传。
现在我要非常高兴的向大家宣布:80/20规则在SPSS的使用中同样有效!仅以Analyze菜单为例,其中最常用的子菜单为:∙Discriptive Statistics∙Compare Means∙General Linear Model(第一项)∙Correlate∙Regression(前半截)只要掌握了它们的使用秘籍,你就可以理直气壮的宣称你已经可以用SPSS解决80%的统计学难题。
在以上五个菜单中,Compare Means是最简单的一个,但使用频率却几乎最高!因此,他的重要性也就不用我多说了吧。
下面让我们大家一起踏上Compare Means之旅。
该菜单集中了几个用于计量资料均数间比较的过程。
具体有:∙Means过程对准备比较的各组计算描述指标,进行预分析,也可直接比较。
∙One-Samples T Test过程进行样本均数与已知总体均数的比较。
∙Independent-Samples T Test过程进行两样本均数差别的比较,即通常所说的两组资料的t检验。
∙Paired-Samples T Test过程进行配对资料的显著性检验,即配对t检验。
EViews统计分析在计量经济学中的应用第2章 数据处理课件

2020/11/16
EViews统计分析在计量经济学中的应用第2章 数据处理
14
数据输出
• 数据输出的操作方式与数据输入的操作方式类似。 可以采用类似于数据输入中的“复制粘贴”办法来 导出数据,也可以通过工作文件工具栏中的 Proc/Export/Write Text-Lotus-Excel选项导出数据。
2020/11/16
EViews统计分析在计量经济学中的应用第2章 数据处理
15
数据生成(生成新的序列或序列组)
• 当输入一个或多个序列数据时,如1.4.1中所述 点击EViews / Quick / Empty Group建立一个数 据组(如图2-12),并命名为Y,
图2-12 建立的数据组
2020/11/16
EViews统计分析在计量经济学中的应用第2章 数据处理
16
2020/11/16
EViews统计分析在计量经济学中的应用第2章 数据处理
11
数据导入
然后在EViews中点击File / Import / Read(如 图2-9)。
图2-8 创建工作文件
图2-9 读取工作文件
2020/11/16
EViews统计分析在计量经济学中的应用第2章 数据处理
12
数据导入
值是B列第2行B2)。 • 导入外部数据文件的方式将数据导入到EViews中,
如果通过这种方式将数据导入EViews中,可以不 事先确定EViews工作文件结构。
相关性分析stata命令

相关性分析stata命令相关性分析是一种重要的统计分析方法,用于评估两个变量之间的关系以及弄清其中的联系。
为了从数据中探索出结论,可以利用STATA中的相关性分析命令,来检验两个变量之间的相关性,从而探究出结论。
STATA是一款功能强大的统计软件,研究者可以利用它进行统计分析,其中相关性分析命令尤为重要。
STATA中提供了多种方法进行相关性分析,其中最常见的是Pearson相关系数检验和Spearman等级相关分析。
《Pearson相关分析》是STATA中最常用的相关性分析命令,它可以用于计算两个变量之间的线性相关性。
该命令的语法如下:corr var1 var2 [if exp] [weight]Pearson相关分析的输出包括样本的总体相关系数、样本的概率值、样本的平方相关系数以及样本的校准相关系数等。
《Spearman等级相关分析》也是STATA中常用的相关性分析命令,它可以用于计算两个变量之间的非线性相关性。
其语法如下:corr var1 var2 [if exp] [weight] [spearman]Spearman等级相关分析的输出包括样本的总体相关系数、样本的概率值、样本的平方误差系数以及样本的等级相关系数等。
此外,还有其他一些用于相关性分析的命令,比如xtreg命令,主要用于计算因变量和多个自变量之间的关系;xtlogit命令,主要用于评估二元因变量和多个自变量之间的关系。
在进行相关性分析之前,我们需要确定两个变量之间有多大的相关性,可以采用假设检验的方法,通过对比样本的Pearson相关系数和Spearman等级相关系数,来推断判断变量之间的关系的强弱,从而作出决定。
此外,我们还需要了解变量之间的偏度和峰值。
偏度是指数据分布的非对称性,峰值是指数据分布的中位数的位置。
我们可以使用skewness和kurtosis命令来检验变量之间的偏度和峰值,一旦发现存在明显的偏度或峰值,则需要对数据进行转换和校正,以改善数据分析结果的准确性。
第三讲双变量与多变量的描述统计分析 ppt课件

二、双变量的描述统计
2.变量组合类型与描述统计的关系 一般来说,双变量的描述统计与命令取决于不同组 合类型。 由于变量的二分类区分和四分类区分具有内在一致 性,且涵括了四分类区分,我们主要以变量的二分 类区分来说明。
10
二、双变量的描述统计
3. 类型1之离散变量与离散变量组合。 描述信息:列联表与相关性分析 统计命令:table; tab Y X
【1】依据变量的二分类区分法,请从2014年 卫计委流动人口动态监测调查数据之“社会 融合与心理健康问卷”部分,有效识别出三 种变量组合类型。 【2】依据课堂所学,每种组合类型选择3-5个进行 相关分析。
19
5
一、单变量描述统计的简要回顾
1.离散型变量的简单描述统计 变量类型:定类变量与定序变量 描述信息:频数、百分比、累计百分比及分布 统计命令:tabulate;tabstat;tab1
6
一、单变量描述统计的简要回顾
2.连续型变量的简单描述统计 变量类型:定距变量与定比变量 描述信息:均值、标准差、及分布 统计命令:summarize;tabstat*,stat()
第三讲:双变量与多变量的 描述统计分析
1
1.统计软件:STATA14.0
2.数据准备:① 2014年卫计委流动人口动态监测调 查数据之“社会融合与心理健康问卷”部分;②农 民工随迁子女城市融入课题组的“外出务工调查数 据”。
2
精品资料
• 你怎么称呼老师? • 如果老师最后没有总结一节课的重点的难点,你
7
二、双变量的描述统计
1、双变量的组合类型 按照变量的四分类区分 类型1:定类变量与定类变量 类型2:定类变量与定序变量 类型3:定距变量与定距变量 类型4:定距变量与定比变量
调节变量交互作用图

做交互效应图,需要分别对X1 与 X2作中心 化处理得到x1与x2
x1=(X1-UX1) x2=(X2-UX2) 其中Y不需要作中心化处理 得到新的回归方程:
公式二: Y=β0+β1*x1+β2*x2+β3x1*x2
知识共享 3.92 4.29 4.36 4.43
低魅力领导
高魅力领导
低集体主义 高集体主义
3.92 4下面四个点输入到EXCEL里面:
低魅力领导 低集体主义 3.92 高集体主义 4.36
高魅力领导 4.29 4.43
然后点击Excel“插入”,选择“图表”,最后
选择折线图
即可,得到如下图:
利用Spss统计软件,进行线性回归,得到 β0、β1、β2、β3系数。
得到回归方程为:
Y=4.249+0.200*x1+0.240*x2-0.221x1*x2
集体主义(x2)
-0.6(-δx2) -0.6(-δx2) 0.6(δx2) 0.6(δx2)
魅力领导(x1)
-0.56(-δx1) 0.56(δx1) -0.56(-δx1) 0.56(δx1)
案例: 集体主义对魅力领导与知识共享调节作
用分析,其中魅力领导自变量,集体主义 为自变量知识共享为因变量。
利用公式二:
Y=β0+β1*x1+β2*x2+β3x1*x2 ( 体 ,魅 β主1、力义其β领)中2、导的Yβ指3为中为未心)对中化的应心值中的化,心回的化β归0知为值系识回,数共归x。2享为方,程Xx2的(1即常集X数1
医学统计学:双变量回归与相关
样本
Y
Y
总体
YX
(Y的条件均数)
根据 t 分布原理:
1 (XX)2
Yt/2,n2sYt/2,n2sY.X Y
n
(XX)2
X=12时,求Y X 的95%可信区间
s X =9.5,lXX=42, Y . X =0.1970
当X=12
时,
Y
=1.6617+0.1392 12=3.3321
SYˆ
相关分析的任务:
两变量间有无相关关系?
两变量间如有相关关系,相关的方向? 相关的程度?
相关分析时,两数值变量之间出现如下情况:当一个 变量增大,另一个也随之增大(或减少),我 们称这种现象为共变,也就是有相关关系。
若两个变量同时增加或减少,变化趋势是同 向的,则两变量之间的关系为正相关 (positive correlation);若一个变量增加时, 另一个变量减少,变化趋势是反向的,则称 为负相关(negative correlation)。 ——相关的方向
相关系数的计算
r XXYY lXY XX2YY2 lXXlYY
相关系数
相关的方向:
r>0:正相关 r<0:负相关 r=0:零相关 相关的密切程度:
样本含量n足够大时,r绝对值越接近1。相关越 密切。
0
1
0.4
0.7
低度相关 中度相关 高度相关
三、相关系数的统计推断
(一)相关系数的假设检验
(二)总体回归系数 的可信区间
总体 YX X
样本
Yˆ abX
总体
β
根据 t 分布原理估计可信区间:
bt/2,n2sb 样本
b
总体回归系数 的可信区间
第九章双变量相关与回归分析
X Y X X Y Y XY
n
二、直线回归中的统计推断
回归方程的假设检验:有方差分析和t检验方法。 总体回归系数β的可信区间 利用回归方程进行估计和预测
例题
SPSS操作分析步骤如下
1、建立数据文件
•建立两个变量: X变量:年龄,数值型 Y变量:尿肌酸含量,数值型
2、统计分析
(1)散点图的制作
graph scatter simple
通过散点图可看出两个变量间不具有直线趋势而是有曲线趋势, 可通过曲线拟合方法来刻画两变量间数量上的依存关系。
(2)曲线拟合的菜单操作
analyze
regression
Curve estimation主对话框
(
适用于两变量间关系为非直线形式,可以通过曲线拟 合方法来刻画两变量间数量上的依存关系。 毒理学动物试验中动物死亡率与给药剂量的关系、细 菌繁殖与培养时间的关系等情况。
例题
SPSS操作分析步骤如下
1、建立数据文件
•建立两个变量: X变量:住院天数,数值型 Y变量:预后指数,数值型
第六章 双变量相关与回归分析
例如:为了研究微量元素锰在胆固醇合成中的作用, 探讨大鼠肝脏中胆固醇含量和锰含量之间是否存在直 线关系?这种关系为随着锰含量的增加,胆固醇的含 量是增加还是减少呢?——直线相关问题
第一节 直线相关
直线相关:又称简单相关,是研究两个变量间线性关 系的一种常用统计方法。 直线相关分析的是两变量之间是否存在直线相关关系, 以及相关的方向和程度。直线相关系数又称Pearson相 关系数,使描述两变量线性相关关系程度和方向的统 计量。 作直线相关分析要求资料服从双变量正态分布。对于 不符合双变量正态分布的资料,不能直接计算Pearson 相关系数,可用非参数统计方法,即计算Kendall相关 系数或Spearman相关系数。
线性回归分析——双变量模型
线性回归分析双变量模型回归分析的含义回归分析是研究一个叫做因变量的变量对另一个或多个叫做解释变量的变量的统计依赖关系。
其用意在于,通过解释变量的已知值或给定值去估计或预测因变量的总体均值。
双变量回归分析:只考虑一个解释变量。
(一元回归分析,简单回归分析)复回归分析:考虑两个以上解释变量。
(多元回归分析)统计关系与确定性关系统计(依赖)关系:非确定性的关系。
在统计依赖关系中,主要处理的是随机变量,也就是有着概率分布的变量。
特别地,因变量的内在随机性是注定存在的。
例如:农作物收成对气温、降雨、阳光以及施肥的依赖关系便是统计性质的。
这些解释变量固然重要,但是并不能使我们准确地预测农作物的收成。
确定性关系:函数关系。
例如物理学中的各种定律。
)/(221r m m k F回归与因果关系❑回归分析研究因变量对于解释变量的统计依赖关系,但并不一定意味着因果关系。
一个统计关系式,不管多强和多么具有启发性,都永远不能确立因果联系。
❑因果关系的确立必须来自于统计关系以外,最终来自于这种或那种理论(先验的或是理论上的)。
回归分析与相关分析(一)❑相关分析:用相关系数测度变量之间的线性关联程度。
例如:测度统计学成绩和高等数学成绩的的相关系数。
假设测得0.90,说明两者存在较强的线性相关。
❑回归分析:感兴趣的是,如何从给定的解释变量去预测因变量的平均取值。
例如:给定一个学生的高数成绩为80分,他的统计学成绩平均来说应该是多少分。
回归分析与相关分析(二)❑在相关分析中,对称地对待任何两个变量,没有因变量和解释变量的区分。
而且,两个变量都被当作随机变量来处理。
❑在回归分析中,因变量和解释变量的处理方法是不对称的。
因变量被当作是统计的,随机的。
而解释变量被当作是(在重复抽样中)取固定的数值,是非随机的。
(把解释变量假定为非随机,主要是为了研究的便利,在高级计量经济学中,一般不需要这个假定。
)双变量回归模型(一元线性回归模型)双变量回归模型(最简单的回归模型)模型特点因变量(Y)仅依赖于唯一的一个解释变量(X)。
[经济学]第九章双变量回归与相关
病人住院天数(天) X
例9-14数据散点图
4.5 4 3.5 3 2.5 2 1.5 1 0.5 0 0 10 20 30
lnY 预 后 指 数
ˆ 4.037 0.038X ln Y ˆ 56.66 e 0.038X Y
40
50
60
70
病人住院天数(天) X
例9-14数据对Y作对数变换散点图
0
a=0 a>0 X Y a<0
2. b为回归系数,即直线的斜率。
b>0 , 直 线 从 左 下 方 走向右上方,Y 随 X 增大而增大; b<0 ,直线从左上方 走向右下方,Y 随 X 增大而减小; b=0,表示直线与 X 轴平行,X 与Y 无直 线关系。
0
Y b>0
b=0
b<0 X
0﹤R2﹤1
Y的总变异中回归关系所能解释的百分比
年龄可解释尿肌酐含量变异性的77.75% 22.25%的变异不能用年龄来解释。 越接近于1:相关的实际效果越好
五、直线回归与相关应用的注意事项
1.根据分析目的选择变量及统计方法
相关:X与Y没有主次,为双向。 回归:Y依X变化而变化,为单向。 自变量的选择: 原因、容易测量、变异小 要有实际意义。
23
例9-13 以不同剂量的标准CRF刺激离体培养 的大鼠垂体前叶细胞,监测其垂体合成分泌 肾上腺激素的量。
标准 CRF(X)刺激大鼠垂体前叶细胞分泌 ACTH(Y)测定结果 编号 1 2 3 4 5 合计 X 0.005 0.050 0.500 5.000 25.000 — Y 34.11 57.99 94.49 128.50 169.98 485.07
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
两样本应变量反应曲线图分析
将一组应变量的每个变量的取值用线连起来就形成应变量反应曲线图。这一组应变量可分两
种情况:不同时点测得的某一指标的变化,如不同时点的CD4细胞计数;同一时点测得的几个相
关的指标,如WAIS成人智力量表得出的信息记忆、相似性判断、数学推理、图形比较四项评
分。如是不同的测量指标,则要求这些指标的测量尺度相同。如WAIS成人智力量表得出的信息
记忆、相似性判断、数学推理、图形比较四项评分都是按平均水平为10的标准设计的,测量尺
度相同。如果不同的测量指标所用的测量尺度不同,可以考虑先把每个指标标准化,再做分析。
下图示两组WAIS成人智力量表得出的信息记忆、相似 性判断、数学推理、图形四项评分。
比较分析这两条线的目的与思路可归纳为三个层次的假设检验,或者说是回答3个问题:
这两条线是否平行?
H0:这两条线平行,H1:两条线不平行。如P<0.05拒绝H0,接受H1,表示不同测量指标的
两组间差距不同,或者说测量指标与组间有交互作用。
如平行,这两条线是否重叠?
H0:两条线重叠,H1:两条线不重叠。如P<0.05拒绝H0,接受H1,表示组间有差距。
如重叠,是否是一条水平线?
H0:是水平线,H1:不是水平线。如P<0.05拒绝H0,接受H1,表示指标间有差别。
图1. 同一水平(重叠)—组间无差距
图2. 不同水平(不重叠)—组间有差异
图3. 同一水平(不重叠)—组间无差异
图4. 平行—无组间交互作用
上述图中,图1、2、4平行,图2、4平行不重叠,图1重叠,但不呈水平线。
例:练习项目wais组间多元反应图比较,输入界面如下:
输出结果:
分组变量: GROUP
分层变量: NA
GROUP: 0 (1) vs. 1 (2)
每单个变量的 t 检验
N1 均数1 N2 均数2 t
自由度
P 值
INFO 28 11.892857 12 9.75 2.292335 38 0.027515
SIMIL 28 9.321429 12 6.333333 2.409823 38 0.02091
ARITH 28 11.357143 12 8.75 2.508933 38 0.016493
PICT 28 7.678571 12 5.916667 2.277562 38 0.028466
Hotelling T 平方检验
N1 N2 T 平方 F
自由度1 自由度2 P 值
28 12 11.950534 2.751768 4 35 0.043317
检验平行性
N1 N2 T 平方 F
自由度1 自由度2 P 值
28 12 1.179525 0.372482 3 36 0.773328
检验一致性
N1 N2 T 平方 F
自由度1 自由度2 P 值
28 12 10.56198 10.56198 1 38 0.00242
检验反应曲线是否呈水平性
总SS 组间SS 自由度1 组间MS 组内SS 自由度2 组内MS F P 值
1934.4 432.25 3 144.083333 1502.15 156 9.629167 14.963219 0