交织器
螺旋交织器
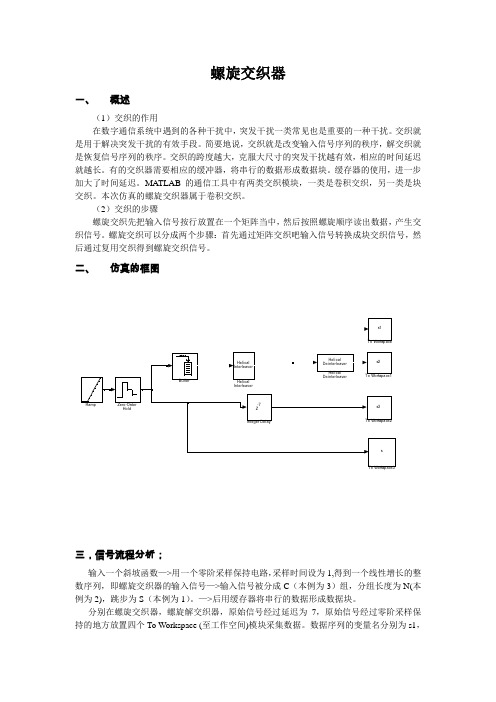
螺旋交织器一、概述(1)交织的作用在数字通信系统中遇到的各种干扰中,突发干扰一类常见也是重要的一种干扰。
交织就是用于解决突发干扰的有效手段。
简要地说,交织就是改变输入信号序列的秩序,解交织就是恢复信号序列的秩序。
交织的跨度越大,克服大尺寸的突发干扰越有效,相应的时间延迟就越长。
有的交织器需要相应的缓冲器,将串行的数据形成数据块。
缓存器的使用,进一步加大了时间延迟。
MATLAB的通信工具中有两类交织模块,一类是卷积交织,另一类是块交织。
本次仿真的螺旋交织器属于卷积交织。
(2)交织的步骤螺旋交织先把输入信号按行放置在一个矩阵当中,然后按照螺旋顺序读出数据,产生交织信号。
螺旋交织可以分成两个步骤:首先通过矩阵交织吧输入信号转换成块交织信号,然后通过复用交织得到螺旋交织信号。
二、仿真的框图三,信号流程分析;输入一个斜坡函数—>用一个零阶采样保持电路,采样时间设为1,得到一个线性增长的整数序列,即螺旋交织器的输入信号—>输入信号被分成C(本例为3)组,分组长度为N(本例为2),跳步为S(本例为1)。
—>后用缓存器将串行的数据形成数据块。
分别在螺旋交织器,螺旋解交织器,原始信号经过延迟为7,原始信号经过零阶采样保持的地方放置四个To Workspace (至工作空间)模块采集数据。
数据序列的变量名分别为s1,s2,s3,s,可以用[s1 s2 s3]’在指令窗中打开,以观察交织,解交织,与原始信号序列的关系和变化规律。
三、仿真结果;(5)结果分析。
. 螺旋交织器把长度为C*N(本例中为3*2)的输入序列分成C(本例中为3)组,每组长度为N(本例中为2).在初始状态,螺旋交织器矩阵M中的元素都等于初始值,这个值在本例中设置为1。
螺旋交织器吧每组长度为N的信号按照螺旋方式分别放置在矩阵M中,其中第一组的元素依次放在矩阵M的第一列,第i(1<=i<=C)组的元素放在第i列,以此类推。
Quartus实验报告和PN9,交织器

课程名称通信系统集成电路设计实验名称Quartus II实验二专业班级姓名学号日期 ______ 2012.12.16__________实验二:PN9序列,交织器1.实验目的a)了解伪随机序列的应用和产生原理、方法;b)掌握在FPGA上利用线性反馈移位寄存器实现伪随机码发生器的方法。
c)通过波形仿真验证此实现方法的正确性和伪随机序列的周期性。
2.实验环境a)Quartus II 9.1 (32-Bit)b)ModelSim-Altera 6.5a (Quartus II 9.1)c)WinXP操作系统3.实验要求1)PN9序列编写生成PN9的程序,用测试向量将结果写到txt文件中,用Matlab统计周期内的0和1数目。
2)分组交织器8*8 从文本中读出数据(0~255:用8bits表示)交织后写到另一个文本,交织采用分组RAM实现,分组RAM调用IP核实现(先写一个文本,然后按列写入,按行输出)。
3)汉明码(选做)将PN9 4个4个地输入到汉明码编码器中,得到(7,4)汉明码,然后按1%的比例加错。
然后进行译码,观察汉明码的纠错能力。
此部分一共包含3个模块:编码,译码和测试模块。
4.实验内容1)PN9伪随机码发生器在扩频通信、信息加密和系统测试等领域中有着广泛的应用。
伪随机序列的伪随机性表现在预先的可确定性、可重复产生与处理。
伪随机序列虽然不是真正的随机序列,但是当伪随机序列周期足够长时,它便具有随机序列的良好统计特性。
本报告给出了利用VHDL语言实现伪随机码发生器的设计,在FPGA 内利用线性反馈移位寄存器结构实现伪随机码的产生,该方法结构简单,易于实现,所产生的伪随机序列具有周期长和随机特性好的特点。
如图所示的一个n级线性移位寄存器可以用n次多项式来表征,称以此式为特征多项式的n级线性反馈移位寄存器所产生的序列,其周期p ≤2^n -1。
特征式:n级线性反馈移位寄存器(LSFR)的输出是一个周期序列。
交织与解解交织

交织与解解交织
我们知道编码的意义是通过加入冗余位信息的方法,从而在接收端能够发现和纠正由于信道影响而产生的随机错码。
那么如果信码在信道中传输时由于信道或者认为的影响而使一段连续的码元产生大量错误,由于编码长度的有限,通过编码的方法是无法达到纠错的功能的,这就需要我们通过其它方法来解决。
目前比较常用的方法是交织(In terleav e)。
交织本质上是一个将数据序列“扰乱”的过程,这里的“扰乱”实际上是按照一定的人为方式进行重新排列,交织主要由交织器完成。
它的逆过程就是解交织,将重排过的序列恢复到原来的序列顺序。
可以理解的是通过交织以后,原来可能出现的大量连续错误被分散开,成为随机错误,而随机错误我们可以通过编码来解决。
交织器/解交织器的加入将大大提高系统的纠错能力。
但是随之而来的是增加了传输延时,降低了信码的传输效率。
这是因为信号的打乱一般是通过矩阵的读入和读出采用不同的方式而实现的,这样必然带来时间上的损失,而且不同的交织方法对信号的“扰乱”程度是不同的,如果“扰乱”的程度不够的话将得不到很好的交织效果。
所以,高“扰乱”低硬件复杂度和低延时成为设计交织器的关键。
这里我们介绍两种比较常用的交织器的设计。
具有良好S距离特性QPP交织器的设计

0 引言
信道编码是提高信息传输可靠性 的有效手段 ,
19 93年 B r uC等 人 提 出 的 T ro码 方 案 以其 接 er o ub 近 Sann限 的 良好 性 能 引 起 了编 码 界 的 广 泛 关 hn o 注, 在各 个 方 面 得 到 广 泛 的应 用 。T ro码 不 仅 在 ub
性能 不差 于经 过搜 索得到 s一随机交 织器 。
第三代移动通信系统 ( G 中被各种标准采用作为 3)
高 速数据 业 务 的信 道 编 码 方 式 , 且 在 “ 4 的 而 准 G” L E( T 长期演 进 计 划 ) 也 被 列 为 备 选 的 信 道 编 码 中
方案。
1 S一距 离特 性
o r i ay S r n o i tr a e r u h r n o s a c . f d n r - d m e l v rt o g a d m e r h o a n e h
Ke od :T rocds iac rpr ;qart oyo a pr ti Q P) yw r s ub oe;Sds nepoe y udacpl mi e ao t t i n l mu tn( P
交织 的扩展 特 陛或者 说 S一距 离 特性 是 指 在交
织过 程 中相邻 的 S个 比特经 过 交 织 后 , 们 之 间 的 它
距离 至少 为 S 一般描 述 为 : ;
T ro码 编译 码 中 的交 织 器 的使 用 , 效 实 现 ub 有
随机编 译 码 的思 想 , 到 接 近 S an n理论 极 限 的 达 hno
( a g h uHag o Gu n z o ieC mmu i t n o pC . L d ,G a gh u50 6 , hn ) nc i s a o Gru o , t. u n z o 16 3 C ia
交织器

深圳大学实验报告课程名称:可编程ASIC设计实验项目名称:通信系统中数据交织器的设计学院:电子科学与技术学院专业:微电子学指导教师:刘春平报告人:郑佑民学号:2009160116 班级:微电一班实验时间:2012-05-08实验报告提交时间:2012-05-22教务部制一、实验要求完成通信系统中数据交织器的设计的设计,要求用Verilog HDL编程,在DE2平台上实现,在示波器上显示观察。
提交设计报告,包括源程序,仿真波形和实验结果及分析结论等。
二、交织器的原理交织器是通信编码中抗突发干扰的一种重要手段,要求设计一个行列交织器。
如图所示,PN码发生器模拟数据源产生串行数据,按行写入一n列m行的RAM中,写满后按列读出。
三、实现方法与代码分析1、伪随机码和时序的产生always @(posedge clk_27 )beginb<=b+1;c<=c+1;if(b==16) //交织器存/读完一次需要16个周期beginb<=0;flag<=~flag; //整个交织器操作完后标志位取反,两个交织器交换操作endif(c==4)c<=0;m[0] <= m[6]^m[5]; //以下代码为伪随机码的产生m[6:1] <= m[5:0] ;if (m==0)m <= 7'b1111111;out<=m[0]; //将伪随机码幅值给“out”end2、交织器的实现该模块定义了两个4*4的存储模块,同一时刻分别只读和写一个存储模块,处理完一个存储模块后交换读写操作。
为了验证交织器的效果,该系统将交织后的数据进行解交织,由于时序的问题,解交织后波形将于原波形形同但延迟32个时钟周期。
always@(clk_27) beginif(!flag)begin mema[b]<=m[0];if(b<4)out1<=mema1[0+4*c]; else if(b<8)out1<=mema1[1+4*c];else if(b<12)out1<=mema1[2+4*c];elseout1<=mema1[3+4*c]; endelsebeginmema1[b]<=m[0];if(b<4)out1<=mema[0+4*c];else if(b<8)out1<=mema[1+4*c];else if(b<12)out1<=mema[2+4*c];elseout1<=mema[3+4*c];endend四、实验结果实验结果如下所示,经验证,波形与理论相符,即解交织波形与原波形一致,且延迟32个时钟周期。
交织器解交织器设计

交织器/解交织器设计卷积交织: 交织深度I=12,形成相互交迭的误码保护数据包,以抵抗信道中突发的干扰。
1 卷积交织和解交织的原理交织过程可算作一个编码过程,他把经过纠错编码的数据进行一定的排列组合,提高原有纠错编码的纠突发错误的能力。
数字通信中一般采取的同步交织有2 种:(1) 块交织也叫矩阵行列转置法。
可以表述为一个二维存储器阵列( N ×B ) 。
交织过程是数据先按行写入,再按列读出;解交织过程则相反,是数据先按列写入,再按行读出。
块交织结构简单, 但数据延时时间长而且所需的存储器比较大。
(2) 卷积交织交织器的输入端的输入符号数据按顺序分别进入 B 条支路延时器,每一路延时不同的符号周期。
第一路无延时,第二路延时M个符号周期,第三路延时2M个符号周期,…,第B路延时( B - 1 )M 个符号周期。
交织器的输出端按输入端的工作节拍分别同步输出对应支路经延时的数据。
卷积交织每条支路符号数据的延时节拍为di = ( i - 1)M B , i = 1,2, …, B 。
解交织器的延时数与交织器相反。
在仔细对比块交织和卷积交织两种方法之后,考虑到缩短延时和减小器件体积,小组决定采用卷积交织的方法来设计。
然而实现卷积交织的延时方法有多种,一是采用移位寄存器法,直接利用FIFO实现每条支路的延时,这种方法实现简单,但是当B与M值较大时,需要消耗大量的寄存器(图2所示);二是利用RAM来实现移位寄存器的功能,通过控制读/写地址来实现每条支路延迟。
第一种方法,因为其设计思路和做法都相对简单,但是当需要较大的延时数时,移位寄存器变得很大,占用大量的编译时间和芯片空间,实际中并不可取,最终采用了RAM来实现移位,合理地设计读写地址按规律变化,即可实现所要的延时。
下面将阐述设计细节设计要求,交织深度B=12,M=17,即有12 条数据通路。
采用RAM 来实现输入数据的时延,按照一定的读写地址规律同时读写RAM 中。
交织器解交织器设计说明文档
交织器与解交织器的Verilog设计0 引言在数字通信中由于信道固有的噪声特性以及衰落特性,信息在有干扰信道传输时不可避免的会发生差错。
为了提高通信系统信息传输的可靠性,一般采用纠错编码技术来提高通信系统抗干扰能力。
但是当信道发生突发差错时,会造成连续的错误,超过纠错码的纠错能力。
交织技术作为一项改善通信系统性能的方式,将数据按照一定的规则打乱,把原先连续的差错分散开来,使突发性错误转化为随机性错误,能够提高通信系统抗突发差错的能力和降低译码复杂度。
VHDL作为一种硬件设计时采用的标准语言,降低设计FPGA的难度,使整个系统的设计和调试周期缩短。
本设计利用FPGA实现交织,能大大缩减电路的体积,提高电路的稳定性。
1 卷积交织和解交织的原理交织过程可算作一个编码过程,他把经过纠错编码的数据进行一定的排列组合,提高原有纠错编码的纠突发错误的能力。
数字通信中一般采取的同步交织有 2 种:(1) 块交织也叫矩阵行列转置法。
可以表述为一个二维存储器阵列 ( N × B ) 。
交织过程是数据先按行写入,再按列读出;解交织过程则相反,是数据先按列写入,再按行读出。
块交织结构简单, 但数据延时时间长而且所需的存储器比较大。
(2) 卷积交织交织器的输入端的输入符号数据按顺序分别进入 B 条支路延时器, 每一路延时不同的符号周期。
第一路无延时,第二路延时M个符号周期,第三路延时2M个符号周期,…,第B路延时( B - 1 )M 个符号周期。
交织器的输出端按输入端的工作节拍分别同步输出对应支路经延时的数据。
卷积交织每条支路符号数据的延时节拍为 di = ( i - 1)M B , i = 1, 2, …, B 。
解交织器的延时数与交织器相反。
图1 卷积交织器和解交织器原理图在仔细对比块交织和卷积交织两种方法之后,考虑到缩短延时和减小器件体积,小组决定采用卷积交织的方法来设计。
然而实现卷积交织的延时方法有多种,一是采用移位寄存器法,直接利用FIFO实现每条支路的延时,这种方法实现简单,但是当B与M值较大时,需要消耗大量的寄存器(图2所示);二是利用RAM来实现移位寄存器的功能,通过控制读/写地址来实现每条支路延迟。
随机交织器的设计与实现
随机交织器的设计与实现随机交织器设计与实现随机交织器是一种常用于数字通信系统中的技术,用于增加数据传输的可靠性。
它通过将输入数据进行随机化处理,然后进行交织,使得原始数据按照一定的规则分散在时间或频域上。
这样可以减小数据在传输过程中的连续错误,提高传输的可靠性。
本文将介绍随机交织器的设计与实现。
1. 随机交织器设计原理:随机交织器的主要原理是将输入数据通过一个伪随机数发生器(PN序列)产生的随机序列进行乱序操作,然后再通过逆序处理将乱序数据重新按照原始顺序排列,从而实现交织作用。
具体的设计步骤如下:(1) 生成随机数序列:使用伪随机数发生器生成一个伪随机数序列作为交织器的控制序列。
(2) 输入数据乱序:将输入数据分割为若干个小块,然后按照控制序列将每个小块进行乱序操作,使得输入数据在时间或频域上分散排列。
(3) 输出数据逆序:对乱序后的数据进行逆序操作,重新按照原始顺序排列。
(4) 输出交织后的数据:将逆序后的数据作为交织后的输出数据。
2. 随机交织器实现方法:随机交织器的实现可以使用硬件电路或者软件算法两种方式进行。
(1) 硬件电路实现:可以使用FPGA(Field Programmable Gate Array)等可编程逻辑器件进行硬件电路的设计与实现。
通过编写硬件描述语言,实现随机数发生器、乱序器和逆序器等功能模块,并将它们连接起来,最终实现随机交织器。
(2) 软件算法实现:可以使用编程语言(如C、Python、MATLAB等)编写程序实现随机交织器。
通过编写随机数生成算法、乱序算法和逆序算法等,以及相应的控制逻辑,最终实现随机交织器。
3. 随机交织器的应用:随机交织器广泛应用于数字通信系统中,特别是对于低信噪比环境下的信道传输非常有效。
它可以减小数据在传输过程中的连续错误,提高数据传输的可靠性。
在无线通信系统、卫星通信系统、光纤通信系统等领域都有广泛的应用。
总结:随机交织器是一种用于增加数据传输可靠性的技术。
数字基带传输系统的组成
数字基带传输系统的组成
数字基带传输系统由以下各组成部分:
1. 信源编码器:将要传输的信息进行数字化,采用数据压缩算法,减小数据量,以此提高传输效率。
常见的信源编码器包括哈夫曼编码器、游长栓编码器等。
2. 信道编码器:对数字化后的信息进行编码,以增强数据的可靠性,降低误码率。
常见的信道编码器包括卷积码、 Turbo码等。
3. 交织器:在信道编码后,还需要通过交织器实现信道编码对数据的扰乱,以避免出现连续误码。
交织器可以采用块交织、条带交织等方式。
4. 映射调制器:将数字信号转换成模拟信号,以在传输媒介上进行传输。
常见的映射调制器包括QPSK调制器,16QAM调制器等。
5. 误码纠正器:在传输过程中,使用纠错码来纠正传输中的误码,以提高传输数据的可靠性,降低误码率。
6. 解调器:将收到的信号转换为数字信号,以进行解码和解交织等操作。
7. 信道解码器:对接收到的信道编码信号进行解码,还原出原始数据。
常见的信道解码器包括卷积解码器、Turbo解码器等。
8. 信源解码器:对从信道解码器输出的数据进行解码,恢复为原始数据。
以上几个组成部分共同构成了数字基带传输系统,并且在实际的应用中,这些组成部分的配置和数量可能略有不同,但是其实质都是为了提高数字信号传输的稳定性和可靠性。
交织器的分类
交织器的分类
交织器是一种常见的纺织机械,主要用于织造各种不同的织物。
根据不同的织造方式和结构特点,交织器可以分为多种类型。
本文将从交织器的分类角度,介绍几种常见的交织器。
一、水力交织器
水力交织器是一种利用水力原理进行织造的交织器。
它的主要特点是采用水力驱动,能够实现高速织造,同时还能够节约能源和降低生产成本。
水力交织器的织造效率高,适用于生产各种不同的织物,如棉布、麻布、丝绸等。
二、气力交织器
气力交织器是一种利用气压原理进行织造的交织器。
它的主要特点是采用气压驱动,能够实现高速织造,同时还能够节约能源和降低生产成本。
气力交织器的织造效率高,适用于生产各种不同的织物,如化纤、涤纶、尼龙等。
三、电子交织器
电子交织器是一种利用电子技术进行织造的交织器。
它的主要特点是采用电子控制,能够实现高精度织造,同时还能够实现自动化生产和智能化管理。
电子交织器的织造效率高,适用于生产各种不同的织物,如高档面料、工业布料等。
四、多轴交织器
多轴交织器是一种利用多轴技术进行织造的交织器。
它的主要特点是采用多轴控制,能够实现多种不同的织造方式和织物结构,同时还能够实现高效率生产和多品种生产。
多轴交织器的织造效率高,适用于生产各种不同的织物,如复合材料、高强度织物等。
交织器是一种非常重要的纺织机械,它的分类也非常多样化。
不同类型的交织器具有不同的特点和优势,可以根据不同的生产需求进行选择和应用。
随着科技的不断发展和进步,交织器的技术水平也在不断提高,未来交织器的应用前景将会更加广阔。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《数字系统设计》课程设计题目:交织器解交织器一、实验任务卷积交织: 交织深度I=12 ,形成相互交迭的误码保护数据包,以抵抗信道中突发的干扰。
二、实验要求1. 请设计一个交织器和解交织器,完成二进制比特流的交织/ 解交织功能。
2. 设计测试基准,验证设计的功能是否正确。
三、设计卷积交织器目的在数字传输系统中,因为存在噪声,信道衰落等干扰因素,会使传输的信号发生错误,产生误码。
虽然数字信号的传输为了防止误码而会进行信道编码,增加传输码的冗余,例如增加监督位等来克服信号在信道传输过程中的错误,但这种检错纠错能力是有限的。
例如当出现突发错误,出现大片误码时,这时信道的纠错是无能为力的。
而卷积交织器可以将原来的信息码打乱,这时尽管出现大面积突发性错误,这些可以通过解交织器来进行分散,从而将大面积的错误较为平均地分散到不同的码段,利于信道纠错的实现。
四、卷积交织的原理卷积交织的原理其实是利用了延时的原理。
例如总延时是T,交织器延时t1,解交织器延时为t2,则有T=t1+t2.本次设计的交织器的交织深度为12,故交织器总共有12路,要进行卷积处理的数据分别循环的进入每一路,每一路延时不同的时间而后输出。
不难想象,如果每一路都延时相同的时间,输入序列肯定跟输出序列一模一样,但交织器因为每一路延时的时间不同,从而将序列打乱了,看上去会很乱,例如你输入1,2,3,4…….20,输出就是1,0,0,0,…..13…….25…..。
那么经过交织器处理后打乱的数据如何恢复原状呢?很简单,因为每一个数据的总延时都是T,如果一个数据A在交织器中延时了t1,那么数据A只需在解交织器中延时T-t1即可。
五、设计过程1.设计思路以上讨论的是交织器与解交织器的算法,那么在硬件电路上如何实现呢?由上讨论,交织器与解交织器都是利用了延时来实现的,而在硬件上实现延时一种很自然的想法就是利用移位寄存器来实现,延时T只需要T级的移位寄存器,在每个时钟的到来,将数据移位,例如数据‘1’经过5级的移位寄存器,经过5个时钟后,数据就经历了寄存器每个寄存单元而输出。
移位寄存器很容易理解,但用移位寄存器的方法有个不好的地方,那就是‘工程量很大’,每个时钟的到来,会有大量存在于移位寄存器中的数据移动,这会增加整个系统的功耗与效率。
为了克服移位寄存器的缺点,我们可以用ram来模仿移位寄存器的功能。
例如定义一个长度为4的ram,那么模仿移位寄存器的过程是这样的。
例如要对数据“ABCD“进行延时:第一个时钟,将A数据写入1单元,读出2单元数据。
第二个时钟,将B数据写入2单元,读出3单元数据。
第三个时钟,将C数据写入3单元,读出4单元数据。
第四个时钟,将D数据写入4单元,读出1单元数据。
这时就读出A数据了,刚好延时了四个时钟。
如此循环,“ABCD“就延时了四个时钟后输出,与4级移位功能相同,因为这种方法只是涉及了数据的读和写,所以克服了移位寄存器大量数据移位的缺点。
所以本系统使用ram来实现交织器与解交织器。
具体来说,就是将ram分成12路,第一路无延时。
第二路延时M时间,需要M+1个存储单元。
第三路延时2M时间,需要2M+1个存储单元。
第四路延时3M时间,需要3M+1个存储单元。
如此类推,第i路延时(i-1)M时间,需要(i-1)M+1;而解交织器相反,第十二路无延时。
第十一路延时M,第十路延时2M,如此类推。
下面介绍数据的流动,以交织器为例,每个时钟,数据进入不同的ram路,我们可以设置一个count_ram(1至12)进行循环计数,每个时钟count_ram就加1,数据进入第count_ram路。
确定了数据进入哪一路ram后,还要确定数据进入这路ram中的哪一个单元,故每一路ram都要一个设置一个计数器coun1-count12,来控制读写哪一个单元,利用上面讨论的ram移位法实现延时,读的地址要比写的地址靠前一位,因为数据读出的时候同时要写入数据,所以ram 要用双口ram实现。
2.设计步骤①定义相关端口,状态及信号;②每当时钟上升沿数据进入系统,根据state_count不同的值进入不同的路;③将输入数据用modelsim仿真显示。
④将程序下载到板上用数码管观察。
3.相关端口设定Clk:时钟信号输入Outdata:数码管输入Q:数码管位选Ren,wen:读写使能端Reset:置位端六、设计中出现的问题与解决:①.在交织器的设计过程过程中,也遇到了不少的困难。
在交织器的输出中,总会在输出的第二位出现一个零。
如下图,例如是应该是输出4后马上输出2的,但是仿真时却发现输出时4,0,2。
分析:后来通过分析仿真图,可以发现直接输出的第一路超前一位时钟输出了,这是因为第一路的数据没有经过ram直接输出,故会超前一个时钟。
解决:在直接输出的那一路加上一个触发器,使输出同步。
②.用定义数组的方法定义ram,发现占掉许多的资源。
解决:用quartus自有的ipcore定制ram,发现节省了许多的资源。
③.在交织器与解交织器连起来后,输出有误。
解决:因为要经过相应数量后时钟,数据才能到达解交织器的入口,所以解交织器之前要写入一些无关的ram以达到同步。
七、实验结果及分析1.交织器的仿真(输入1到256)输入数据方式:1.用文件输入 2.计数器输出做输入输出数据方式:1.用文件输出 2.直接观察波形图1).波形的方式2).用文件的方式分析:用文件输出的方式更易于观察数据的数量。
可以观察到输出的数据会越来越多。
2.解织器的仿真分析:一开始输出很大段是‘0’,因为初始化的时候ram里面存的是‘0’。
而输出完‘0’后就会输出解交织后的1到200.下载:芯片类型是四代cyclone的EP4CE22C8管脚分配:使用数码管进行显示。
具体实现在视频中已经体现。
八、设计总结通过本次课程设计,我在实践中加深了对相关知识(状态机等)的理解与应用,将所学到的知识融会贯通,从而顺利完成设计目标,达到设计要求。
最后,感谢姜小波老师在本学期数字系统设计课程中对我们耐心的指导及细心的讲解,也祝愿老师在以后能够一帆风顺,工作顺利!十、代码1.项目代码1)解交织器代码:LIBRARY IEEE; --导入库USE IEEE.std_logic_1164.ALL;use ieee.std_logic_arith.all;use ieee.std_logic_unsigned.all;ENTITY jie_jiaozhiqi ISPORT(INDATA:IN STD_LOGIC_VECTOR(7 downto 0); --数据输入OUTDATA:OUT STD_LOGIC_VECTOR(7 downto 0); --解交织数据输入CLK:IN STD_LOGIC; --时钟REN:IN STD_LOGIC; --读使能端WEN:IN STD_LOGIC; --写使能端RESET:IN STD_LOGIC --复位信号);END;ARCHITECTURE BEHA V OF jie_jiaozhiqi ISCOMPONENT ram_jiejiaozhi IS --ipcore双口ram:ram_jiejiaozhiPORT(clock : IN STD_LOGIC := '1'; --时钟data : IN STD_LOGIC_VECTOR (7 DOWNTO 0); --ram输入rdaddress : IN STD_LOGIC_VECTOR (10 DOWNTO 0); --读地址rden : IN STD_LOGIC := '1'; --读使能wraddress : IN STD_LOGIC_VECTOR (10 DOWNTO 0); --读地址wren : IN STD_LOGIC := '0'; --写使能q : OUT STD_LOGIC_VECTOR (7 DOWNTO 0) --ram输出);END COMPONENT;SIGNAL STATE_COUNT:INTEGER RANGE -1 TO 13:=-1; --每一路转换的计数信号SIGNAL RAM_OUTPUT:STD_LOGIC_VECTOR(7 downto 0); --ram输出的信号线SIGNAL RAM_INPUT:STD_LOGIC_VECTOR(7 downto 0); --ram输入的信号线SIGNAL WD_ADD:std_logic_vector(10 downto 0):="11111111110"; --读地址的信号线SIGNAL RD_ADD:std_logic_vector(10 downto 0):="11111111100"; --写地址的信号线SIGNAL INDATA_derect:STD_LOGIC_VECTOR(7 downto 0);--数据直接输出,不经过ram的信号线BEGINPROCESS(STATE_COUNT) --每一路的计数器V ARIABLE Branch_count_1:INTEGER RANGE 0 TO 18:=0;V ARIABLE Branch_count_2:INTEGER RANGE 0 TO 35:=0;V ARIABLE Branch_count_3:INTEGER RANGE 0 TO 52:=0;V ARIABLE Branch_count_4:INTEGER RANGE 0 TO 69:=0;V ARIABLE Branch_count_5:INTEGER RANGE 0 TO 86:=0;V ARIABLE Branch_count_6:INTEGER RANGE 0 TO 103:=0;V ARIABLE Branch_count_7:INTEGER RANGE 0 TO 120:=0;V ARIABLE Branch_count_8:INTEGER RANGE 0 TO 137:=0;V ARIABLE Branch_count_9:INTEGER RANGE 0 TO 154:=0;V ARIABLE Branch_count_10:INTEGER RANGE 0 TO 171:=0;V ARIABLE Branch_count_11:INTEGER RANGE 0 TO 188:=0;BEGINCASE STATE_COUNT IS--当STATE_COUNT计数到不同的值时,控制输入数据写入那一路的ram,读出那一路的ram,共有12路WHEN 12=>RD_ADD<="11111111110";WD_ADD<="11111111100";WHEN 11=>WD_ADD<=conv_std_logic_vector(Branch_count_1 mod(18),11);RD_ADD<=conv_std_logic_vector((Branch_count_1+1) mod(18),11);if Branch_count_1=18 thenBranch_count_1:=1;elseBranch_count_1:=Branch_count_1+1;end if;WHEN 10=>WD_ADD<=conv_std_logic_vector((Branch_count_2 mod(35))+18,11);RD_ADD<=conv_std_logic_vector((Branch_count_2+1) mod(35)+18,11);if Branch_count_2=35 thenBranch_count_2:=1;elseBranch_count_2:=Branch_count_2+1;WHEN 9=>WD_ADD<=conv_std_logic_vector((Branch_count_3 mod(52))+53,11); RD_ADD<=conv_std_logic_vector((Branch_count_3+1) mod(52)+53,11); if Branch_count_3=52 thenBranch_count_3:=1;elseBranch_count_3:=Branch_count_3+1;end if;WHEN 8=>WD_ADD<=conv_std_logic_vector((Branch_count_4 mod(69))+105,11); RD_ADD<=conv_std_logic_vector((Branch_count_4+1) mod(69)+105,11); if Branch_count_4=69 thenBranch_count_4:=1;elseBranch_count_4:=Branch_count_4+1;end if;WHEN 7=>WD_ADD<=conv_std_logic_vector((Branch_count_5 mod(86))+174,11); RD_ADD<=conv_std_logic_vector((Branch_count_5+1) mod(86)+174,11); if Branch_count_5=86 thenBranch_count_5:=1;elseBranch_count_5:=Branch_count_5+1;end if;WHEN 6=>WD_ADD<=conv_std_logic_vector((Branch_count_6 mod(103))+260,11); RD_ADD<=conv_std_logic_vector((Branch_count_6+1) mod(103)+260,11); if Branch_count_6=103 thenBranch_count_6:=1;elseBranch_count_6:=Branch_count_6+1;end if;WHEN 5=>WD_ADD<=conv_std_logic_vector((Branch_count_7 mod(120))+363,11); RD_ADD<=conv_std_logic_vector((Branch_count_7+1) mod(120)+363,11); if Branch_count_7=120 thenBranch_count_7:=1;elseBranch_count_7:=Branch_count_7+1;WHEN 4=>WD_ADD<=conv_std_logic_vector((Branch_count_8 mod(137))+483,11);RD_ADD<=conv_std_logic_vector((Branch_count_8+1) mod(137)+483,11);if Branch_count_8=137 thenBranch_count_8:=1;elseBranch_count_8:=Branch_count_8+1;end if;WHEN 3=>WD_ADD<=conv_std_logic_vector((Branch_count_9 mod(154))+620,11);RD_ADD<=conv_std_logic_vector((Branch_count_9+1) mod(154)+620,11);if Branch_count_9=154 thenBranch_count_9:=1;elseBranch_count_9:=Branch_count_9+1;end if;WHEN 2=>WD_ADD<=conv_std_logic_vector((Branch_count_10 mod(171))+774,11);RD_ADD<=conv_std_logic_vector((Branch_count_10+1) mod(171)+774,11);if Branch_count_10=171 thenBranch_count_10:=1;elseBranch_count_10:=Branch_count_10+1;end if;WHEN 1=>WD_ADD<=conv_std_logic_vector((Branch_count_11 mod(188))+945,11);RD_ADD<=conv_std_logic_vector((Branch_count_11+1) mod(188)+945,11);if Branch_count_11=188 thenBranch_count_11:=1;elseBranch_count_11:=Branch_count_11+1;end if;WHEN OTHERS=>--OUTDATA_reg<="00001111";RD_ADD<="11111111110";WD_ADD<="11111111100";END CASE;END PROCESS;--二路选择器,选择解交织输出的数据是从ram输出的数据还是直接输入的数据Out_choice:PROCESS(STATE_COUNT,RAM_OUTPUT,INDATA_derect)BEGINIF (STATE_COUNT=1)THENOUTDATA<=INDATA_derect;ELSEOUTDATA<=RAM_OUTPUT;END IF;END PROCESS;--特殊处理第一路,因为不能双口ram不能同时读写同一单元,故要设一支路让数据直接输入输出PROCESS(CLK,STATE_COUNT)BEGINIF (STATE_COUNT=12)THENIF RISING_EDGE(CLK)THENINDATA_derect<=INDATA;END IF;END IF;END PROCESS;--状态转换进程State_conver:process(clk,RESET)beginIF (RESET='1')THEN STATE_COUNT<=-1;ELSIF rising_EDGE(CLK) THENif STATE_COUNT=12 thenSTATE_COUNT<=1;else STATE_COUNT<=STATE_COUNT+1;end if;END IF;end process;将双口ram与解交织器相连u1 :nimei PORT MAP(clock=>CLK,data=>INDATA,rdaddress=>RD_ADD,wraddress=>WD_ADD,wren=>WEN,rden=>REN,q=>RAM_OUTPUT); --例化END BEHAV;2)、交织器代码:LIBRARY IEEE; --导入库USE IEEE.std_logic_1164.ALL;use ieee.std_logic_arith.all;use ieee.std_logic_unsigned.all;ENTITY jiaozhiqi ISPORT(INDATA:IN STD_LOGIC_VECTOR(7 downto 0); --数据输入OUTDATA:OUT STD_LOGIC_VECTOR(7 downto 0); --解交织数据输入CLK:IN STD_LOGIC; --时钟REN:IN STD_LOGIC; --读使能端WEN:IN STD_LOGIC; --写使能端RESET:IN STD_LOGIC --复位信号);END;ARCHITECTURE BEHA V OF jie_jiaozhiqi ISCOMPONENT ram_jiaozhi IS --ipcore双口ram:ram_jiejiaozhiPORT(clock : IN STD_LOGIC := '1'; --时钟data : IN STD_LOGIC_VECTOR (7 DOWNTO 0); --ram输入rdaddress : IN STD_LOGIC_VECTOR (10 DOWNTO 0); --读地址rden : IN STD_LOGIC := '1'; --读使能wraddress : IN STD_LOGIC_VECTOR (10 DOWNTO 0); --读地址wren : IN STD_LOGIC := '0'; --写使能q : OUT STD_LOGIC_VECTOR (7 DOWNTO 0) --ram输出);END COMPONENT;SIGNAL STATE_COUNT:INTEGER RANGE -1 TO 13:=1; --每一路转换的计数信号SIGNAL RAM_OUTPUT:STD_LOGIC_VECTOR(7 downto 0); --ram输出的信号线SIGNAL RAM_INPUT:STD_LOGIC_VECTOR(7 downto 0); --ram输入的信号线SIGNAL WD_ADD:std_logic_vector(10 downto 0):="11111111110"; --读地址的信号线SIGNAL RD_ADD:std_logic_vector(10 downto 0):="11111111100"; --写地址的信号线SIGNAL INDATA_derect:STD_LOGIC_VECTOR(7 downto 0);--数据直接输出,不经过ram的信号线BEGINPROCESS(STATE_COUNT) --每一路的计数器V ARIABLE Branch_count_1:INTEGER RANGE 0 TO 18:=0;V ARIABLE Branch_count_2:INTEGER RANGE 0 TO 35:=0;V ARIABLE Branch_count_3:INTEGER RANGE 0 TO 52:=0;V ARIABLE Branch_count_4:INTEGER RANGE 0 TO 69:=0;V ARIABLE Branch_count_5:INTEGER RANGE 0 TO 86:=0;V ARIABLE Branch_count_6:INTEGER RANGE 0 TO 103:=0;V ARIABLE Branch_count_7:INTEGER RANGE 0 TO 120:=0;V ARIABLE Branch_count_8:INTEGER RANGE 0 TO 137:=0;V ARIABLE Branch_count_9:INTEGER RANGE 0 TO 154:=0;V ARIABLE Branch_count_10:INTEGER RANGE 0 TO 171:=0;V ARIABLE Branch_count_11:INTEGER RANGE 0 TO 188:=0;BEGINCASE STATE_COUNT IS--当STATE_COUNT计数到不同的值时,控制输入数据写入那一路的ram,读出那一路的ram,共有12路WHEN 1=>RD_ADD<="11111111110";WD_ADD<="11111111100";WHEN 2=>WD_ADD<=conv_std_logic_vector(Branch_count_1 mod(18),11);RD_ADD<=conv_std_logic_vector((Branch_count_1+1) mod(18),11);if Branch_count_1=18 thenBranch_count_1:=1;elseBranch_count_1:=Branch_count_1+1;end if;WHEN 3=>WD_ADD<=conv_std_logic_vector((Branch_count_2 mod(35))+18,11);RD_ADD<=conv_std_logic_vector((Branch_count_2+1) mod(35)+18,11);if Branch_count_2=35 thenBranch_count_2:=1;elseBranch_count_2:=Branch_count_2+1;end if;WHEN 4=>WD_ADD<=conv_std_logic_vector((Branch_count_3 mod(52))+53,11);if Branch_count_3=52 thenBranch_count_3:=1;elseBranch_count_3:=Branch_count_3+1;end if;WHEN 5=>WD_ADD<=conv_std_logic_vector((Branch_count_4 mod(69))+105,11); RD_ADD<=conv_std_logic_vector((Branch_count_4+1) mod(69)+105,11); if Branch_count_4=69 thenBranch_count_4:=1;elseBranch_count_4:=Branch_count_4+1;end if;WHEN 6=>WD_ADD<=conv_std_logic_vector((Branch_count_5 mod(86))+174,11); RD_ADD<=conv_std_logic_vector((Branch_count_5+1) mod(86)+174,11); if Branch_count_5=86 thenBranch_count_5:=1;elseBranch_count_5:=Branch_count_5+1;end if;WHEN 7=>WD_ADD<=conv_std_logic_vector((Branch_count_6 mod(103))+260,11); RD_ADD<=conv_std_logic_vector((Branch_count_6+1) mod(103)+260,11); if Branch_count_6=103 thenBranch_count_6:=1;elseBranch_count_6:=Branch_count_6+1;end if;WHEN 8=>WD_ADD<=conv_std_logic_vector((Branch_count_7 mod(120))+363,11); RD_ADD<=conv_std_logic_vector((Branch_count_7+1) mod(120)+363,11); if Branch_count_7=120 thenBranch_count_7:=1;elseBranch_count_7:=Branch_count_7+1;end if;WHEN 9=>RD_ADD<=conv_std_logic_vector((Branch_count_8+1) mod(137)+483,11);if Branch_count_8=137 thenBranch_count_8:=1;elseBranch_count_8:=Branch_count_8+1;end if;WHEN 10=>WD_ADD<=conv_std_logic_vector((Branch_count_9 mod(154))+620,11);RD_ADD<=conv_std_logic_vector((Branch_count_9+1) mod(154)+620,11);if Branch_count_9=154 thenBranch_count_9:=1;elseBranch_count_9:=Branch_count_9+1;end if;WHEN 11=>WD_ADD<=conv_std_logic_vector((Branch_count_10 mod(171))+774,11);RD_ADD<=conv_std_logic_vector((Branch_count_10+1) mod(171)+774,11);if Branch_count_10=171 thenBranch_count_10:=1;elseBranch_count_10:=Branch_count_10+1;end if;WHEN 12=>WD_ADD<=conv_std_logic_vector((Branch_count_11 mod(188))+945,11);RD_ADD<=conv_std_logic_vector((Branch_count_11+1) mod(188)+945,11);if Branch_count_11=188 thenBranch_count_11:=1;elseBranch_count_11:=Branch_count_11+1;end if;WHEN OTHERS=>--OUTDATA_reg<="00001111";RD_ADD<="11111111110";WD_ADD<="11111111100";END CASE;END PROCESS;--二路选择器,选择交织输出的数据是从ram输出的数据还是直接输入的数据Out_choice:PROCESS(STATE_COUNT,RAM_OUTPUT,INDATA_derect)BEGINIF (STATE_COUNT=1)THENOUTDATA<=INDATA_derect;ELSEOUTDATA<=RAM_OUTPUT;END IF;END PROCESS;--特殊处理第一路,因为不能双口ram不能同时读写同一单元,故要设一支路让数据直接输入输出PROCESS(CLK,STATE_COUNT)BEGINIF (STATE_COUNT=2)THENIF RISING_EDGE(CLK)THENINDATA_derect<=INDATA;END IF;END IF;END PROCESS;--状态转换进程State_conver:process(clk,RESET)beginIF (RESET='1')THEN STATE_COUNT<=0;ELSIF rising_EDGE(CLK) THENif STATE_COUNT=12 thenSTATE_COUNT<=1;else STATE_COUNT<=STATE_COUNT+1;end if;END IF;end process;将双口ram与交织器相连u1 :nimei PORT MAP(clock=>CLK,data=>INDATA,rdaddress=>RD_ADD,wraddress=>WD_ADD,wren=>WEN,rden=>REN,q=>RAM_OUTPUT); --例化END BEHAV;3)、顶层文件:LIBRARY IEEE;USE IEEE.std_logic_1164.ALL;use ieee.std_logic_arith.all;use ieee.std_logic_unsigned.all;entity top is --顶层实体PORT(INDATA:IN STD_LOGIC_VECTOR(7 downto 0); --数据输入OUTDATA:OUT STD_LOGIC_VECTOR(7 downto 0); --数据输出CLK:IN STD_LOGIC; --时钟REN:IN STD_LOGIC; --读使能WEN:IN STD_LOGIC; --写使能RESET:IN STD_LOGIC; --置位Q:OUT BIT_VECTOR(2 DOWNTO 0) --数码管位选信号);end entity;ARCHITECTURE BEHA V OF top IScomponent jie_jiaozhiqi IS --解交织器元件PORT(INDATA:IN STD_LOGIC_VECTOR(7 downto 0);OUTDATA:OUT STD_LOGIC_VECTOR(7 downto 0);CLK:IN STD_LOGIC;REN:IN STD_LOGIC;WEN:IN STD_LOGIC;RESET:IN STD_LOGIC);END component;component SHUMAGUAN is --数码管port(CLK:IN STD_LOGIC;INDATA: IN STD_LOGIC_VECTOR(7 DOWNTO 0);OUTDATA:OUT STD_LOGIC_VECTOR(6 DOWNTO 0);Q:OUT BIT_VECTOR(2 DOWNTO 0);FENPIN_CLK_1s:OUT STD_LOGIC);END component;component jiaozhiqi IS --交织器元件PORT(INDATA:IN STD_LOGIC_VECTOR(7 downto 0);OUTDATA:OUT STD_LOGIC_VECTOR(7 downto 0);CLK:IN STD_LOGIC;REN:IN STD_LOGIC;WEN:IN STD_LOGIC;RESET:IN STD_LOGIC);END component;component count200 IS --计数器PORT(clock : IN STD_LOGIC ;q : OUT STD_LOGIC_VECTOR (7 DOWNTO 0));END component;signal jiao_jie_connect:STD_LOGIC_VECTOR(7 downto 0); --解交织器与交织器的连线signal count_out:STD_LOGIC_VECTOR(7 downto 0); --计数器输出与交织器输入连线signal shumaguan_input:STD_LOGIC_VECTOR(7 downto 0); --解交织器与数码管的连续signal fenpin:std_logic; --分频输出信号begin --连线jiaozhiqi_component:jiaozhiqiportmap(INDATA=>count_out,OUTDATA=>jiao_jie_connect,CLK=>fenpin,REN=>REN, WEN=>WEN,RESET=>RESET);jie_jiaozhiqi_component:jie_jiaozhiqiportmap(INDATA=>jiao_jie_connect,OUTDATA=>shumaguan_input,CLK=>fenpin,REN= >REN,WEN=>WEN,RESET=>RESET);counter_component:count200 port map(clock=> fenpin,q=>count_out); shumaguan_component:SHUMAGUANportmap(CLK=>CLK,INDATA=>shumaguan_input,OUTDATA=>OUTDATA,Q=>Q,FENP IN_CLK_1s=>fenpin);end behav;编译2.仿真测试代码library ieee;use ieee.std_logic_1164.all;use ieee.std_logic_arith.all;use ieee.std_logic_unsigned.all;ENTITY top_vhd_tst ISEND top_vhd_tst;ARCHITECTURE top_arch OF top_vhd_tst IS-- constants-- signalsSIGNAL CLK : STD_LOGIC;SIGNAL OUTDATA : STD_LOGIC_VECTOR(7 DOWNTO 0); --SIGNAL Q : STD_LOGIC_VECTOR(2 DOWNTO 0); SIGNAL REN : STD_LOGIC;SIGNAL RESET : STD_LOGIC;SIGNAL WEN : STD_LOGIC;COMPONENT topPORT (CLK : IN STD_LOGIC;OUTDATA : OUT STD_LOGIC_VECTOR(7 DOWNTO 0); -- Q : OUT STD_LOGIC_VECTOR(2 DOWNTO 0);REN : IN STD_LOGIC;RESET : IN STD_LOGIC;WEN : IN STD_LOGIC);END COMPONENT;BEGINi1 : topPORT MAP (-- list connections between master ports and signalsCLK => CLK,OUTDATA => OUTDATA,-- Q => Q,REN => REN,RESET => RESET,WEN => WEN);always : PROCESS --时钟BEGINCLK<='1';W AIT FOR 50 PS;CLK<='0';W AIT FOR 50 PS;-- code executes for every event on sensitivity list END PROCESS always;rst_en:process—使能与置位beginRESET<='0';WEN<='1';REN<='1';--ENABLEWAIT FOR 500 PS;RESET<='1';WAIT ;END PROCESS rst_en;inputee:process(clk)—数据输入BEGINIf RISING_EDGE(CLK)THENINDATA<=INDATA+1;END IF;END PROCESS;END top_arch;。