带有双参数Volterra模型的全局结构分析_刘艺艺
ERA5资料在蓟州复杂地形下的检验与应用

海 洋 气 象 学 报
JOURNAL OF MARINE METEOROLOGY
2024 年 2 月
Vol.44 No.1
Feb.ꎬ 2024
邹双泽ꎬ白爱娟ꎬ何科ꎬ等.ERA5 资料在蓟州复杂地形下的检验与应用[ J] .海洋气象学报ꎬ2024ꎬ44(1) :118 ̄128.
can reflect the change of weather and provide reference for analyzing strong convective potential.
Keywords Jizhouꎻ Daxing sounding stationꎻ ECMWF Reanalysis v5 ( ERA5 ) ꎻ aerial explorationꎻ
发展专项( CXFZ2022J012)
第一作者简介:邹双泽ꎬ女ꎬ硕士ꎬ工程师ꎬ主要从事灾害性天气监测预警研究ꎬ317973133@ qq.comꎮ
通信作者简介:白爱娟ꎬ女ꎬ博士ꎬ教授ꎬ主要从事天气动力学研究ꎬbaiaj@ cuit.edu.cnꎮ
第1期
邹双泽等:ERA5 资料在蓟州复杂地形下的检验与应用
难ꎮ 又如河南郑州“720” 特大暴雨[4-5] ꎬ造成全市
需要验证ꎮ
暴雨[1-3] ꎬ引发的城市内涝和山区泥石流造成 78 人遇
380 人因灾死亡或失踪ꎮ 在特定天气形势和环境条
得到广泛应用[16] ꎬ但在复杂地形区资料的可靠性仍
一方面ꎬ处于复杂地形的天津蓟州短时强降水
件下产生的强对流天气是短时临近预报的重难点ꎬ高
strong convective index
辨率高的优点ꎬ能够提供对流层各高度层的温度、湿
计量经济学题目及答案

三、判断题(判断下列命题正误,并说明理由)1、简单线性回归模型与多元线性回归模型的基本假定是相同的。
2、在模型中引入解释变量的多个滞后项容易产生多重共线性。
3、D-W 检验中的D-W 值在0到4之间,数值越小说明模型随机误差项的自相关度越小,数值越大说明模型随机误差项的自相关度越大。
4、在计量经济模型中,随机扰动项与残差项无区别。
5、在经济计量分析中,模型参数一旦被估计出来,就可将估计模型直接运用于实际的计量经济分析.6、线性回归模型意味着因变量是自变量的线性函数。
7、多重共线性问题是随机扰动项违背古典假定引起的。
8、通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与样本容量大小有关.9、双变量模型中,对样本回归函数整体的显著性检验与斜率系数的显著性检验是一致的。
10、如果联立方程模型中某个结构方程包含了所有的变量, 则这个方程不可识别。
11、在实际中,一元回归没什么用,因为因变量的行为不可能仅由一个解释变量来解释.12、多重共线性问题是随机扰动项违背古典假定引起的13、在异方差性的情况下,常用的OLS 法必定高估了估计量的标准误。
14、虚拟变量只能作为解释变量。
15、随机扰动项的方差与随机扰动项方差的无偏估计没有区别.16、经典线性回归模型(CLRM )中的干扰项不服从正态分布的,OLS 估计量将有偏的。
17、虚拟变量的取值只能取0或1。
18、拟合优度检验和F 检验是没有区别的。
19、联立方程组模型不能直接用OLS 方法估计参数。
20、双变量模型中,对样本回归函数整体的显著性检验与斜率系数的显著性 检验是一致的;21、多重共线性问题是随机扰动项违背古典假定引起的。
22、在模型t t t t u X X Y +++=33221βββ的回归分析结果报告中,有23.263489=F ,000000.0=值的p F ,则表明解释变量t X 2 对t Y 的影响是显著的。
23、结构型模型中的每一个方程都称为结构式方程,结构方程中,解释变量只可以是前定变量.24、通过虚拟变量将属性因素引入计量经济模型,引入虚拟变量的个数与模型有无截距项无关。
教师薪金模型分析
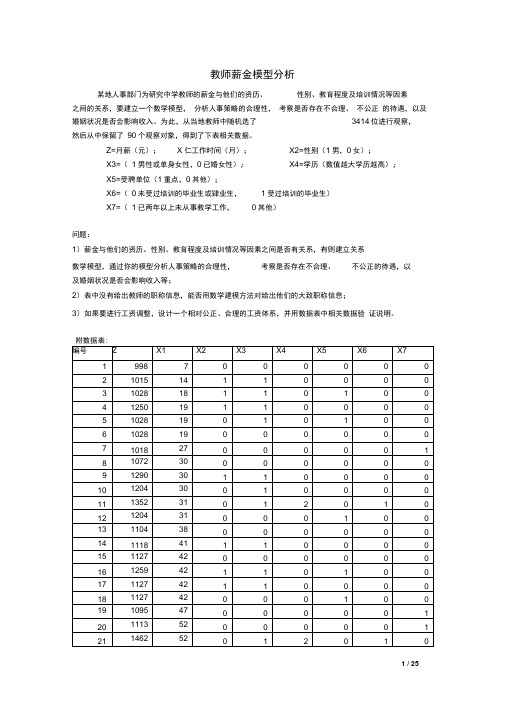
教师薪金模型分析某地人事部门为研究中学教师的薪金与他们的资历、性别、教育程度及培训情况等因素之间的关系,要建立一个数学模型,分析人事策略的合理性,考察是否存在不合理、不公正的待遇,以及婚姻状况是否会影响收入。
为此,从当地教师中随机选了3414位进行观察,然后从中保留了90个观察对象,得到了下表相关数据。
Z=月薪(元);X仁工作时间(月);X2=性别(1男,0女);X3=(1男性或单身女性,0已婚女性);X4=学历(数值越大学历越高);X5=受聘单位(1重点,0其他);X6=(0未受过培训的毕业生或肄业生,1受过培训的毕业生)X7=(1已两年以上未从事教学工作,0其他)问题:1)薪金与他们的资历、性别、教育程度及培训情况等因素之间是否有关系,有则建立关系数学模型,通过你的模型分析人事策略的合理性,考察是否存在不合理、不公正的待遇,以及婚姻状况是否会影响收入等;2)表中没有给出教师的职称信息,能否用数学建模方法对给出他们的大致职称信息;3)如果要进行工资调整,设计一个相对公正、合理的工资体系,并用数据表中相关数据验证说明。
摘要本文建立了中学教师的薪金与他们的工作时间,性别,教育程度及培训情况等之间关系的统计回归模型.针对题目要求,我们分析了各变量的特点以及各个变量之间的联系,利用EXCEL ,MATLAB 等软件,最终得到了最佳模型.首先,我们通过题目所给的数据分析,用EXCEL 软件得到散点图,我们发现X1,X2,X3,X4,X5,X6,X7 对薪金(Z )均呈线性关系.因此,我们初步得到了一般的线性回归模型如下:Z=C0+C1*X1+C2*X2+C3*X3+C4*X4+C5*X5+C6*X6+C7*X7+ &(1)利用MATLAB 软件求解,我们得到了回归系数和置信区间等一系列的数据.通过对得到的数据进行分析.我们发现模型存在缺陷,模型从整体上来看效果也不是很好.我们还可以看到有些变量的置信区间是经过零点的,因此,我们推测有些变量对薪金(Z )的影响是不显著的•同时使用EXCLE软件对每个要素与薪金的线性分析发现X1,X4,X6与薪金(Z)的相系数都在0.5以上,经过分析,我们最终涮选出对薪金(Z )影响显著的变量X1 ,X4和X6 .用残差分析法对模型进行分析•尝试将它们的平方项或开方项加入到模型中,建立新的回归模型•经多次尝试,我们最终建立了进一步改进的模型(2)如下:Z=C0+C1*X1+C2*X6+C3*SQRT(X4)*X1+C4X"2 + & (2)我们再次通过EXCEL软件回归分析得到只人2=0.87130588, F=143.8702088, P=5.45E-37 通过与模型(1)的比较,模型(2)是一个简单易用的模型,模型可靠度更高,模型更加万善•也说明教师的薪金与工作时间(x1),学历(x4),培训情况(X6)有着密切关系,与性别和婚姻状况的差异关系并不显著.全文模型的求解用图表与文字结合来说明,直观,易懂。
基于Kriging模型的自适应多阶段并行代理优化算法

第27卷第11期2021年11月计算机集成制造系统Vol.27No.11 Computer Integrated Manufacturing Systems Nov.2021DOI:10.13196/j.cims.2021.11.016基于Kriging模型的自适应多阶段并行代理优化算法乐春宇,马义中+(南京理工大学经济管理学院,江苏南京210094)摘要:为了充分利用计算资源,减少迭代次数,提出一种可以批量加点的代理优化算法。
该算法分别采用期望改进准则和WB2(Watson and Barnes)准则探索存在的最优解并开发已存在最优解的区域,利用可行性概率和多目标优化框架刻画约束边界。
在探索和开发阶段,设计了两种对应的多点填充算法,并根据新样本点和已知样本点的距离关系,设计了两个阶段的自适应切换策略。
通过3个不同类型算例和一个工程实例验证算法性能,结果表明,该算法收敛更快,其结果具有较好的精确性和稳健性。
关键词:Kriging模型;代理优化;加点准则;可行性概率;多点填充中图分类号:O212.6文献标识码:AParallel surrogate-based optimization algorithm based on Kriging model usingadaptive multi-phases strategyYUE Chunyu,MA Yizhong+(School o£Economics and Management,Nanjing University of Science and Technology,Nanjing210094,China) Abstract:To make full use of computing resources and reduce the number of iterations,a surrogate-based optimization algorithm which could add batch points was proposed.To explore the optimum solution and to exploit its area, the expected improvement and the WB2criterion were used correspondingly.The constraint boundary was characterized by using the probability of feasibility and the multi-objective optimization framework.Two corresponding multi-points infilling algorithms were designed in the exploration and exploitation phases and an adaptive switching strategy for this two phases was designed according to the distance between new sample points and known sample points.The performance of the algorithm was verified by three different types of numerical and one engineering benchmarks.The results showed that the proposed algorithm was more efficient in convergence and the solution was more precise and robust.Keywords:Kriging model;surrogate-based optimization;infill sampling criteria;probabil让y of feasibility;multipoints infill0引言现代工程优化设计中,常采用高精度仿真模型获取数据,如有限元分析和流体动力学等E,如何在优化过程中尽可能少地调用高精度仿真模型,以提高优化效率,显得尤为重要。
变系数模型的稳健变量选择与结构识别

第44卷湖北师范大学学报(自然科学版)Vol.44第1期Journal of Hubei Normal University(Natural Sciences)No.1,2024变系数模型的稳健变量选择与结构识别王照良,张素婷(河南理工大学数学与信息科学学院,河南焦作 454000)摘要:研究了稳健回归下变系数模型的变量选择和模型结构识别问题。
利用B样条基函数近似非参数系数函数,建立自适应组Lasso双惩罚函数选择变系数模型中的重要变量并且识别具有常数效应的协变量,同时估计未知的非参数系数函数。
在一定条件下,证明了所提出的惩罚估计量具有相合性和稀疏性。
通过数值模拟验证所提方法的有限样本性质。
关键词:变系数模型;稳健回归;自适应组Lasso;变量选择;稀疏性中图分类号:O212.7 文献标志码:A 文章编号:2096-3149(2024)01-0001-08doi:10.3969/j.issn.2096-3149.2024.01.0010 引言变系数模型(Varying Coefficient Models,VCM)具有如下形式: Y=X Tβ(U)+ε(1)其中Y∈ℝ为响应变量,X=(X1,…,X p)T∈ℝp是p维协变量,U∈ℝ为指标变量,β(·)= (β1(·),…,βp(·))T是ℝp上未知的p维可测函数向量,ε是随机误差,且E(ε|X,U)=0.不失一般性,假定U∈[0,1].本文方法也适用多维随机变量U,但由于“维数灾祸”,会变得不太实用。
变系数模型(1)之所以有吸引力是因为诸系数βl(U)依赖于U,这不但消减了建模偏差,而且避免了“维数灾祸”。
这个模型的另一个优点是它的可解释性。
许多学者对变系数模型进行了深入研究,得到了丰富的研究成果[1]。
有关模型(1)变量选择的研究,Wang等[2]结合组Lasso和样条基函数近似的思想研究了重要变量的选择问题。
Wang和Xia[3]提出了基于核光滑和自适应组Lasso的KLasso方法,并证明了提出方法的理论性质。
中级计量经济学课件

二、教学内容
第一讲 多元线性模型的估计、检验以及经济上的解释 1.1. 计量经济学及经济数据 1.2. 一元线性回归 1.3. 多元线性回归
3 学时
第二讲 违反高斯-马尔可夫假设的检验及处理 2.1. 高斯-马尔可夫定理 2.2. 多重共线性 2.3. 异方差 2.4. 自相关 2.5. 内生性问题:代理变量、工具变量与 2SLS
Posing a Question Literature Review Data Collection
9 deciding on the appropriate data set 9 entering and sort your data 9 inspecting, cleaning, and summarizing your data Econometric Analysis Writing an Empirical Paper 9 introduction 9 conceptual (or theoretical) framework 9 econometric models and estimation methods 9 the data 9 results 9 conclusions
两年城市犯罪数据
0bs
city
year
murders population unem
police
1
1
1986
5
350000 8.7
440
2
1
1990
8
359200 7.2
471
3
2
1986
2
64300
5.4
75
4
2
1990
1
65100
5.5
Treynor-Black和Black-Litterman模型构建分析与实际检验
作者: 张瀚予[1]
作者机构: [1]澳大利亚悉尼大学,澳大利亚悉尼2006
出版物刊名: 全国流通经济
页码: 144-148页
年卷期: 2020年 第29期
主题词: Treynor-Black;Black-Litterman;敏感性分析
摘要:对比两个著名的定量金融模型,Treynor-Black模型和Black-Litterman模型,本文通过复制这两个核心的投资组合的概念构建两个模型。
此外,还对Black-Litterman模型中的关键参数进行了敏感性分析。
研究发现这两个模型都是为了解决资产配置问题而设计的,然而在构造投资组合的最优组合时却有不同的侧重点Black-Litterman模型投资组合的表现优于Treynor-Black模型。
通过敏感性分析风险厌恶和τ的变化表明:投资者观点的变化更大的影响Black-litterman模型的绩效。
由于这些因素的变化可能会改变最终结论,研究还存在一些局限性,包括时间周期、数据不足、实验不足、再平衡的频率。