spss统计软件练习题及答案
《统计分析与SPSS的应用》课后练习答案

《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习能够帮助我们更好地掌握所学知识,并将其应用到实际的数据分析中。
以下是针对部分课后练习的答案及解析。
一、选择题1、在 SPSS 中,用于描述数据集中变量分布特征的统计量是()A 均值B 标准差C 中位数D 众数答案:ABCD解析:均值、标准差、中位数和众数都是描述数据分布特征的常用统计量。
均值反映了数据的集中趋势;标准差反映了数据的离散程度;中位数是将数据排序后位于中间位置的数值;众数则是数据集中出现次数最多的数值。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 两样本相互独立D 以上都是答案:D解析:独立样本 t 检验要求样本来自正态分布总体、两样本方差相等以及两样本相互独立。
只有在这些条件满足的情况下,t 检验的结果才是可靠的。
3、以下哪种方法适用于多组数据的比较()A 单因素方差分析B 配对样本 t 检验C 相关分析D 回归分析答案:A解析:单因素方差分析用于比较三个或三个以上组别的数据是否存在显著差异。
配对样本 t 检验适用于配对数据的比较;相关分析用于研究变量之间的线性关系;回归分析用于建立变量之间的预测模型。
二、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:SPSS 中数据录入的基本步骤如下:(1)打开 SPSS 软件,选择“新建数据文件”。
(2)在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
(3)切换到数据视图,按照定义好的变量逐行录入数据。
(4)录入完成后,保存数据文件。
2、解释相关分析和回归分析的区别。
答:相关分析主要用于研究两个或多个变量之间的线性关系程度和方向,但它并不确定变量之间的因果关系。
相关分析的结果通常用相关系数来表示,如皮尔逊相关系数。
回归分析则不仅可以确定变量之间的关系,还可以建立数学模型来预测因变量的值。
spss统计分析习题答案

spss统计分析习题答案SPSS统计分析习题答案在统计学中,SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件。
它提供了一系列功能强大的工具,用于数据处理、数据可视化和统计分析。
对于学习和实践统计分析的人来说,掌握SPSS的使用是非常重要的。
在学习SPSS统计分析过程中,我们常常会遇到一些习题,用以巩固和应用所学的知识。
下面,我将提供一些SPSS统计分析习题的答案,希望能对你的学习和实践有所帮助。
习题一:假设你有一份关于某个班级学生的成绩数据,包括数学成绩、语文成绩和英语成绩。
请使用SPSS计算每个学生的总分,并计算班级的平均总分。
答案:首先,打开SPSS软件并导入数据集。
然后,依次点击"Transform"、"Compute Variable"。
在弹出的对话框中,输入一个新的变量名,比如"Total_Score",然后在"Numeric Expression"框中输入数学成绩、语文成绩和英语成绩的变量名,并使用"+"符号将它们连接起来,最后点击"OK"按钮。
这样,SPSS将会计算每个学生的总分,并将结果保存在新的变量"Total_Score"中。
接下来,点击"Analyze"、"Descriptive Statistics"、"Frequencies"。
在弹出的对话框中,将"Total_Score"变量拖动到"Variables"框中,并点击"OK"按钮。
SPSS将会计算班级的平均总分,并在输出结果中显示。
习题二:假设你有一份关于某个公司员工的工资数据,包括性别、年龄和工资水平。
SPSS统计学考试题库及答案

SPSS统计学考试题库及答案一、单选题(每题2分,共10题)1. 在SPSS中,下列哪个选项不是数据文件的保存类型?A. SAVB. CSVC. TXTD. DOCX答案:D2. 要分析数据的集中趋势,应该使用SPSS中的哪个功能?A. 描述统计B. 交叉表C. 相关分析D. 回归分析答案:A3. 在SPSS中,如何快速选择所有变量?A. 按住Ctrl键,然后点击每个变量B. 按住Shift键,然后点击每个变量C. 按住Alt键,然后点击每个变量D. 点击任何一个变量,然后使用“选择”菜单中的“选择所有变量”选项答案:D4. 在SPSS中进行方差分析时,哪个选项用于检验数据是否满足方差齐性?A. Levene's TestB. Shapiro-Wilk TestC. Kolmogorov-Smirnov TestD. Mann-Whitney U Test答案:A5. 在SPSS中,如何对数据进行分组?A. 使用“数据”菜单中的“排序案例”选项B. 使用“数据”菜单中的“拆分文件”选项C. 使用“转换”菜单中的“计算变量”选项D. 使用“分析”菜单中的“分类”选项答案:B6. 在SPSS中,要计算变量的平均值,应该使用哪个功能?A. 描述统计B. 频率C. 探索D. 描述性统计答案:A7. 在SPSS中,哪个选项用于绘制箱线图?A. 图表构建器B. 图形C. 旧对话框D. 分析8. 在SPSS中,如何对数据进行编码?A. 使用“数据”菜单中的“定义变量”选项B. 使用“数据”菜单中的“重编码变量”选项C. 使用“转换”菜单中的“计算变量”选项D. 使用“分析”菜单中的“描述统计”选项答案:B9. 在SPSS中,哪个选项用于进行因子分析?A. 描述统计B. 相关分析C. 因子分析D. 聚类分析答案:C10. 在SPSS中,如何对数据进行标准化处理?A. 使用“转换”菜单中的“标准化值”选项B. 使用“分析”菜单中的“描述统计”选项C. 使用“数据”菜单中的“定义变量”选项D. 使用“转换”菜单中的“计算变量”选项,然后使用Z分数公式答案:D二、多选题(每题3分,共5题)1. 在SPSS中,哪些选项可以用于数据的描述性统计分析?A. 描述统计B. 频率D. 交叉表答案:A, B, C2. 在SPSS中,进行假设检验时,哪些选项可以用于检验数据的正态性?A. Shapiro-Wilk TestB. Kolmogorov-Smirnov TestC. Q-Q PlotD. 箱线图答案:A, B, C3. 在SPSS中,哪些选项可以用于数据的分类分析?A. 聚类分析B. 因子分析C. 判别分析D. 多维尺度分析答案:A, C4. 在SPSS中,哪些选项可以用于数据的相关性分析?A. 皮尔逊相关系数B. 斯皮尔曼等级相关系数C. 肯德尔等级相关系数D. 偏相关分析答案:A, B, C, D5. 在SPSS中,哪些选项可以用于数据的回归分析?A. 线性回归B. 逻辑回归C. 多项式回归D. 逐步回归答案:A, B, C, D三、判断题(每题1分,共5题)1. 在SPSS中,数据文件的保存类型包括.sav、.csv和.txt。
第3章 统计软件SPSS概述练习题及答案
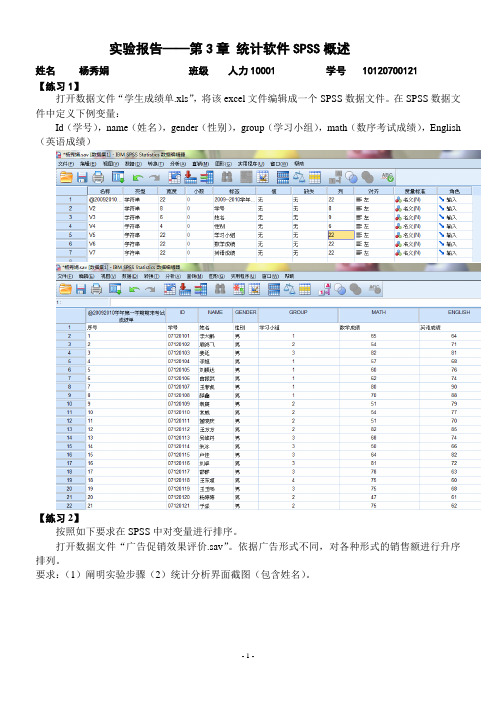
实验报告——第3章统计软件SPSS概述姓名杨秀娟班级人力10001 学号10120700121【练习1】打开数据文件“学生成绩单.xls”,将该excel文件编辑成一个SPSS数据文件。
在SPSS数据文件中定义下例变量:Id(学号),name(姓名),gender(性别),group(学习小组),math(数序考试成绩),English (英语成绩)【练习2】按照如下要求在SPSS中对变量进行排序。
打开数据文件“广告促销效果评价.sav”。
依据广告形式不同,对各种形式的销售额进行升序排列。
要求:(1)阐明实验步骤(2)统计分析界面截图(包含姓名)。
【练习3】按照如下要求在SPSS中对变量值进行重新编码。
打开数据文件“儿童身高统计.sav”。
依据如下规则,对“身高(sg)”变量重新赋值生成新变量“评价(pj)”。
若“身高(sg)<66”,其评价为“1(值标签为:低)”;若“67≤身高(sg)≤70”,其评价为“2(值标签为:中低)”;若“71≤身高(sg)≤75”,其评价为“3(值标签为:正常)”;若“76≤身高(sg)≤79”,其评价为“4(值标签为:中高)”;若“80<身高(sg)”,其评价为“5(值标签为:高)”;要求:(1)阐明实验步骤(2)统计分析界面截图(包含姓名)。
单击【转换】——【重置编码为不同变量】——选择需要重新赋值的变量——点击旧值和新值——点击范围,从最低到值/从值到最高——在新值中输入要排的新值【练习4】从大学二年级学生中抽出20人参加英语A套和B套试题的测试,数据文件为“CH3 英语测试成绩”。
求每个人回答两套测试题的成绩差值。
(计算变量)要求:(1)阐明实验步骤(2)统计分析界面截图(包含姓名)。
点击【转换】——【计算变量】【练习5】先重新编码 然后计算按照如下要求在SPSS 中计算新变量。
打开数据文件“职工基本信息.sav ”。
依据职称级别计算实发工资,计算规则:实发工资=(基本工资-失业保险)*职称级数(先编码) 计算 其中,职称级数指依据职称1~4等级分别取1.05对应1,1.03对应2,1.02对应3,1.01对应4。
spss练习题及答案

spss练习题及答案SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,被广泛应用于社会科学研究和数据分析领域。
本文将提供一些SPSS练习题和对应的答案,以帮助读者提升SPSS使用和数据分析能力。
题目1:数据导入与基本操作问题描述:使用SPSS软件,将一组身高数据导入并进行基本操作。
解答:1. 打开SPSS软件并创建一个新的数据文件。
2. 在数据编辑栏中创建一个名为"Height"的变量,并设置其数据类型为数值型。
3. 逐行输入以下身高数据:165、170、180、155、168、175、185、162。
4. 在数据编辑栏中创建一个名为"Gender"的变量,并设置其数据类型为标签型(男性、女性)。
5. 逐行输入以下性别数据:男性、女性、女性、男性、男性、女性、男性、女性。
6. 完成数据输入后,保存文件并命名为"Height_Data.sav"。
题目2:数据清理与缺失值处理问题描述:使用SPSS软件,清理一组包含缺失值的数据并进行处理。
解答:1. 打开SPSS软件,并导入包含缺失值的数据文件。
2. 在数据编辑栏中,检查数据是否存在缺失值,采用统计分析方法得到具体的缺失值情况。
3. 处理缺失值的方法之一是删除带有缺失值的行。
在数据编辑栏中选择"数据",然后点击"选择特定行",在弹出窗口中选择"删除缺少变量值",点击确定。
4. 另一种处理缺失值的方法是用合适的数据填充缺失位置。
在数据编辑栏中选择"数据",然后点击"选择特定行",在弹出窗口中选择"选中缺少变量值的行",点击确定。
然后选择"数据",再点击"修改变量",选择合适的填充方法(如平均值、中位数等),点击确定。
spss统计试题及答案

spss统计试题及答案SPSS统计试题及答案1. 单项选择题- 1.1 SPSS中,用于进行数据描述性分析的命令是()。
- A. DESCRIPTIVES- B. FREQUENCIES- C. MEANS- D. T-TEST- 答案:A- 1.2 在SPSS中,要进行方差分析,应该使用以下哪个命令?() - A. DESCRIPTIVES- B. ANOVA- C. REGRESSION- D. CROSSTABS- 答案:B2. 多项选择题- 2.1 下列哪些选项是SPSS中的数据类型?()- A. Numeric- B. String- C. Date- D. Time- 答案:A、B、C、D- 2.2 在SPSS中,进行相关性分析可以使用以下哪些命令?()- A. CORRELATIONS- B. REGRESSION- C. CROSSTABS- D. MEANS- 答案:A、B3. 简答题- 3.1 简述SPSS中如何进行数据的导入和导出。
- 答案:在SPSS中,数据的导入可以通过“文件”菜单下的“打开”选项,选择“数据”并导入不同格式的数据文件。
数据的导出则可以通过“文件”菜单下的“另存为”选项,选择导出为SPSS、Excel、CSV等格式。
- 3.2 解释在SPSS中进行回归分析的步骤。
- 答案:在SPSS中进行回归分析的步骤包括:打开数据文件,选择“分析”菜单下的“回归”选项,选择“线性”或“逻辑”回归,指定因变量和自变量,点击“确定”进行分析。
4. 计算题- 4.1 假设有一组数据:10, 15, 20, 25, 30。
计算这组数据的平均值和标准差。
- 答案:平均值 = (10+15+20+25+30)/5 = 20;标准差 =√[(10-20)²+(15-20)²+(20-20)²+(25-20)²+(30-20)²]/5 =7.071。
spss练习题及答案

spss练习题及答案SPSS练习题及答案SPSS(Statistical Package for the Social Sciences)是一款广泛应用于数据分析和统计的软件工具。
它提供了丰富的功能和强大的统计算法,帮助研究者和数据分析师快速、准确地处理和分析大量数据。
为了帮助大家更好地掌握SPSS的使用技巧,下面将给出一些SPSS练习题及答案,供大家参考。
练习题一:描述性统计分析某公司对员工的工资进行了调查,收集了100位员工的薪资数据,请根据以下数据,使用SPSS进行描述性统计分析。
薪资数据:5000,5500,6000,6500,7000,7500,8000,8500,9000,9500,10000,10500,11000,11500,12000,12500,13000,13500,14000,14500,15000,15500,16000,16500,17000,17500,18000,18500,19000,19500,20000,20500,21000,21500,22000,22500,23000,23500,24000,24500,25000,25500,26000,26500,27000,27500,28000,28500,29000,29500,30000答案:1. 打开SPSS软件,新建数据集,将薪资数据输入到数据集中。
2. 在菜单栏选择"分析",然后选择"描述统计",再选择"频数"。
3. 将薪资数据变量拖动到"变量"框中,点击"统计"按钮,在弹出的对话框中勾选"平均值"、"中位数"、"标准差"、"最小值"、"最大值"等选项,点击"确定"。
4. 点击"图表"按钮,选择"直方图",点击"确定"。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、去年某企业每天平均生产元件105个,今年改进了生产技术随机抽取15天进行测量,结果为208 112 202 108 210 106 206 204 118 112116 210 114 104 214假定生产从正态分布,能否判断今年的产量是否是去年的两倍(a=0.05)步骤:输入数据后,从菜单栏选择“分析”→“比较均值”→“单样本T检验”命令,打开“单样本T检验”对话框。
(1)将变量产量选入“检验变量”列表框。
(2)在“检验值”框中输入已知去年元件产量的平均数105。
(3)单击“确定”按钮,完成设置并执行上述操作。
单个样本统计量N 均值标准差均值的标准误元件个数15 156.27 50.005 12.911分析:样本数量为15,均值为156.27,标准差为50.005,均值的标准误差为12.911分析:显著性水平为0.001小于0.05,所以认为今年的产量不是去年的两倍。
2、一生产商想比较两种汽车轮胎A和B的磨损质量。
在比较中,选A和B型轮胎组成一对后任意安装在7辆汽车的后轮上,然后让汽车运行指定的英里数,记录下每只轮胎的磨损量。
数据如下:汽车 1 2 3 4 5 6 7轮胎A 9.6 10.8 11.3 10.7 8.2 9.0 11.2轮胎B 8.2 9.4 11.8 9.1 9.3 11.0 13.1这两种轮胎的平均磨损质量存在显著差异吗?步骤:(1)输入数据,执行“分析”→“比较均值”→“配对样本T检验”命令,打开“配对样本T检验”对话框。
(2)在“置信区间百分比”框内输入置信度95%,然后单击“继续”按钮确认,返回主对话框。
(3)单击“确定”按钮,完成设置并执行配对样本T检验。
成对样本统计量均值N 标准差均值的标准误对 1 轮胎A 10.114 7 1.1950 .4517轮胎B 10.271 7 1.7433 .6589轮胎A的均值10.114 小于轮胎B的均值10.271。
相关系数为0.457,认为轮胎之间相关性大显著性水平为0.804,大于0.01,接受原假设,认为两个轮胎的平均磨损质量之间无显著性差异。
3、某地一年级12名女大学生的身高、体重与肺活量数据如下,试建立体重与身高、肺活量间的线性回归方程。
操作步骤:(1)从菜单栏中选择“分析”→“回归”→“线性”,将“体重”选入“因变量”,将“身高”“肺活量”选入“自变量”。
(2)单击“统计量”按钮,选择“置信区间”输入95,选择“描述性”和“个案诊断”并选择“所有个案”,单击继续。
(3)单击“绘制”按钮,选用DEPENDENT和*ZPEAD,并选择“直方图”和“正态概率图”,单击继续。
(4)单击“确定”按钮,并进行线性回归分析。
体重和身高分析:体重的均值为49.41,身高的均值为160.58,肺活量的均值为2.89相关性体重身高肺活量Pearson 相关性体重 1.000 .771 .800身高.771 1.000 .640肺活量.800 .640 1.000Sig. (单侧)体重. .002 .001身高.002 . .012肺活量.001 .012 .N 体重12 12 12身高12 12 12相关性体重身高肺活量Pearson 相关性体重 1.000 .771 .800身高.771 1.000 .640肺活量.800 .640 1.000Sig. (单侧)体重. .002 .001身高.002 . .012肺活量.001 .012 .N 体重12 12 12身高12 12 12肺活量12 12 12显著性水平小于0.05,因此它们之间具有显著性差异水平描述性统计量均值标准偏差N体重49.4167 5.08935 12身高160.5833 3.77692 12肺活量 2.8942 .41745 12Anova b模型平方和df 均方 F Sig.1 回归214.6972 107.348 13.759 .002a残差70.220 9 7.802总计284.917 11Anova b模型平方和df 均方 F Sig.1 回归214.6972 107.348 13.759 .002a残差70.220 9 7.802总计284.917 11a. 预测变量: (常量), 肺活量, 身高。
b. 因变量: 体重体重与身高的线性回归方程为:体重与肺活量的线性回归方程为:案例诊断a案例数目标准残差体重预测值残差1 -.693 42.00 43.9351 -1.935112 -.537 42.00 43.4995 -1.499463 .075 46.00 45.7914 .208644 -.193 46.00 46.5401 -.540055 -.462 46.00 47.2917 -1.291726 .113 50.00 49.6837 .316277 -1.113 51.00 54.1080 -3.108038 1.219 52.00 48.5957 3.404329 -1.292 52.00 55.6084 -3.6084010 .936 52.00 49.3843 2.6157511 .342 58.00 57.0456 .9544512 1.605 56.00 51.5167 4.48334a. 因变量: 体重残差统计量a极小值极大值均值标准偏差N预测值43.4995 57.0456 49.4167 4.41790 12 标准预测值-1.339 1.727 .000 1.000 12预测值的标准误差.834 1.690 1.369 .287 12 调整的预测值44.3320 56.9053 49.4842 4.46267 12 残差-3.60840 4.48335 .00000 2.52659 12 标准残差-1.292 1.605 .000 .905 12 Student 化残差-1.506 1.715 -.011 1.031 12 已删除的残差-4.90527 5.25044 -.06750 3.30658 12 Student 化已删除的残差-1.642 1.971 .009 1.109 12 Mahal。
距离.065 3.111 1.833 1.043 12 Cook 的距离.001 .414 .104 .127 12 居中杠杆值.006 .283 .167 .095 12 a. 因变量: 体重残差统计量a极小值极大值均值标准偏差N预测值43.4995 57.0456 49.4167 4.41790 12 标准预测值-1.339 1.727 .000 1.000 12 预测值的标准误差.834 1.690 1.369 .287 12 调整的预测值44.3320 56.9053 49.4842 4.46267 12 残差-3.60840 4.48335 .00000 2.52659 12 标准残差-1.292 1.605 .000 .905 12 Student 化残差-1.506 1.715 -.011 1.031 12 已删除的残差-4.90527 5.25044 -.06750 3.30658 12 Student 化已删除的残差-1.642 1.971 .009 1.109 12 Mahal。
距离.065 3.111 1.833 1.043 12 Cook 的距离.001 .414 .104 .127 12 居中杠杆值.006 .283 .167 .095 12 a. 因变量: 体重由图可知,标准化残差呈正态分布,散点在直线上或下靠近直线,说明变量之间呈线性分布。
由图可知回归方程满足线性以及其次方程的检验4、某企业欲研究不同类型的商店对一种新产品的销售影响,选取了三类商店:副食品店、百货公司和超市。
调查时销售额如表,现分析不同商店类型对销售量有无显著影响。
(1)打开数据文件,从菜单栏选择“分析”→“比较均值”→“单因素ANOVA”命令,(2) 将“销售量”作为观测变量选入“因变量列表”框,(3)将“商店”作为控制变量选入“因子”文本框中。
控制变量有几个不同的取值,就表示控制变量有几个水平。
(4)单击“对比”按钮,然后打开对比对话框中的“度”下拉列表中选择“线性”选项,单击“继续”按钮确认。
(5)在“单因素ANOVA:两两比较”两两比较对话框中选择LSD方法进行两两比较。
单击“继续”按钮确认。
(6)在“选项”对话框中,选择“描述性”项输出描述性统计量和“均值图”输出频数图。
单击“继续”按钮确认。
(7)单击“确定”按钮完成设置,执行单因素方差分析。
ANOVA销售额平方和df 均方 F 显著性word格式-可编辑-感谢下载支持组间(组合)214.292 2 107.146 14.827 .000线性项对比195.031 1 195.031 26.989 .000偏差19.260 1 19.260 2.665 .110组内325.188 45 7.226总数539.479 47p为0.000小于0.05,拒绝原假设,认为不同商店类型对产品销售量有显著性影响。
从两两比较的结果可知,在三中类型的商店中,副食品店与百货公司、副食品店与超市之间的差异是显著的,即不同类型的商店对销售量具有显著性差异。