稀疏非负矩阵分解
非负矩阵分解算法概述之Lee&Seung的世界

非负矩阵分解算法概述(吴有光)NOTE:本文为科普文章,尽量做到通俗而不严格,比较适合理论小白补补NMF历史第一部分Lee&Seung的世界1 引言现实生活中的数据,我们总是希望有个稀疏表达,这是从压缩或数据存储的角度希望达到的效果。
从另一方面来讲,我们面对大量数据的时候,总是幻想能够发现其中的“规律”,那么在表示或处理的时候,直接操作这些提纲挈领的“规律”,会有效得多。
这个事情,让很多的科学家都伤透脑筋,不过也因此有了饭碗。
1.1第一个例子我们先来看一个简单的例子。
在人文、管理或社会学里,实证研究方法是常用的方法。
比如我们来考察大学生就业过程,对学生的选择工作类别的动机,我们常说“想吃劳保饭的同学铁了心要考公务员,喜欢轻松自由氛围的同学更趋向于外企,只想稳定的同学认为国企最好,富二代神马的最爱创业然后继承家产了”,这句话如果要严格来论证是不可能的,那么我们转而寻求“调查论证”,即通过设计问卷(问卷上设计了可能影响学生选择的因素,比如家庭情况、学业情况、性格取向、对大城市或家乡的热恋程度、以及人生观价值观等等各种我们可能会影响就业取向的因素)各种我们猜测会影响学生。
问卷上来后,我们通过统计得到如下的列表。
图1 第一个例子的统计表示例表中的各个因素我们进行了量化,比如性格因素从完全内向到热情奔放分为5个等级(可以用一些问题来直接或间接获得这个等级)。
那么剩下的问题就是回答开始的问题:(1)是不是我们设计的每个因素都有效?(显然不是,之所以设计问卷就是要来解决这个问题的)(2)是什么因素影响了学生的最终选择?或者说,从统计上来看,每个因素占多大比重?这时,用矩阵来表示可写为,其中就表示那个因素矩阵,表示最终取向,代表我们要求的系数。
我们把要求的用代替,写成矩阵形式为:(1)更进一步,如果我们不仅调查学生的去向,还想同时调查很多事情,那么就会有,这样上面的式子改写为:(2)此时问题转化为:Q1:已知,如何求解,使之满足上面的等式,其中具有初始值(就是我们设计的一堆东西)。
非负矩阵分解算法综述

E U W#iHij . i= 1 此外, BNMF 常被有盲信号 分离背景 的学者 解释为
含噪声项的产生式模型: V= WH+ E[10] , E 是 M @N 的 噪声矩阵. 不同的 BNMF 算法也常可被解释为 遵循了不 同的 E分布假设下的最大似然算法.
根据需要, 可给上述模型 中的 W和 H 施加 更多的 限制, 构成 INMF.
2 NMF 简介
定义 对一个 M 维的随机向量 v 进行了 N 次的观 测, 记这些 观测 为 vj , j = 1, 2, , , N , 取 V= [ V#1, V#2, , , V#N ] , 其中 V#j = vj, j = 1, 2, , , N, BNMF 要求发现非 负的 M @L 的基矩阵 W= [ W#1, W#2, , , W#N ] 和 L @N 的系数矩阵 H = [ H#1, H#2, , , H#N ] , 使 V U WH[1] , 这 也可 以 用 向 量 标 量 积 的 形 式 更 为 直 观 地 表 示 为 V#j
Ke y words: non2negative matrix factorization; multivariate data representation; feature extraction
1 引言
在信号处理、神经网络、模式识别、计算机视觉和图 象工程的研究中, 如何构造一个能使多维观测数据被更 好描述的变换方法始终是 一个非 常重要 的问 题. 通常, 一个好的变换方法应具备 两个基 本的特 性: ( 1) 可 使数 据的某种潜在结构变得清晰; ( 2) 能使数据的 维数得到 一定程度的约减.
主分量分析、线 性鉴别 分析、投影寻 踪、因 子分析、
冗余归约和独立分量分析是一些最常用的变换方法. 它 们因被施加的限制不同而有着本质的区别, 然而, 它们 有两个共同 的特 点: ( 1) 允 许负的 分解量 存在 ( 允 许有 减性的描述) ; ( 2) 实现线性的维数约减. 区别于它们, 一 种新 的变 换方 法 ) ) ) 非负 矩 阵分 解( Nonnegative Matrix Factor, NMF) [1]由 Lee 和 Seung 在5Nature6 上提出, 它使分 解后的所有分量均为非负值(要求纯加性的描述) , 并且 同时实现非 线性 的维 数 约减. NMF 的 心理 学和 生 理学 构造依据是对整体 的感知 由对组成 整体的 部分的 感知 构成的( 纯 加性的 ) [2~ 6], 这也 符合直 观的理 解: 整 体是 由部分组成的[1], 因此它在某种意义上抓住了智能数据 描述的本质. 此外, 这 种非负 性的限 制导致 了相应 描述 在一定程度上的稀疏性[1], 稀疏性的表述已被证明是介 于完全分布式的描 述和单 一活跃 分量 的描述 3 间 的一
【计算机应用】_非负矩阵分解_期刊发文热词逐年推荐_20140724
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
2011年 科研热词 推荐指数 非负矩阵分解 5 行列式准则 2 稀疏性 2 欠定盲分离 2 非负稀疏编码 1 非负张量分解 1 重构 1 采样 1 自动摘要 1 相关反馈 1 查询扩展 1 最小相关约束 1 数据降维 1 插值 1 掌纹识别 1 快速算法 1 径向基概率神经网络分类器 1 局部特征提取 1 多维尺度分析 1 图像检索 1 isomap 1
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13
科研热词 非负矩阵分解 人脸识别 非采样contourlet变换 矩阵分解 梯度非负矩阵分解 数字水印 推荐系统 径向基网络 图像融合 单类协同过滤 光滑性 主成分分析 wals
推荐指数 2 2 1 1 1 1 1 1 1 1 1 1 1
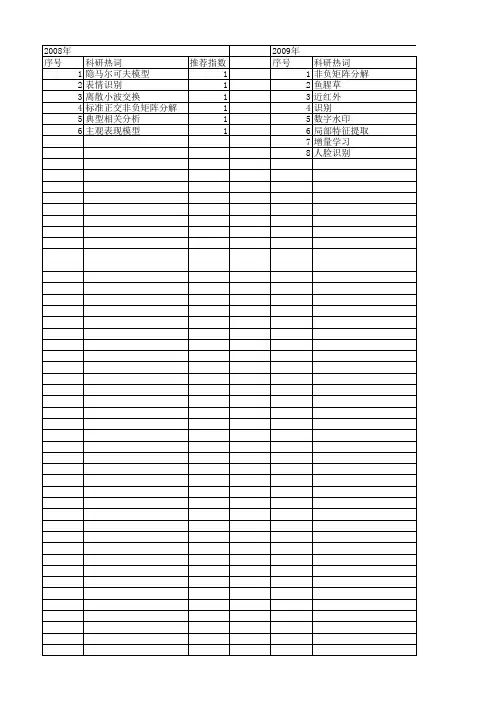
2008年 序号 1 2 3 4 5 6
科研热词 隐马尔可夫模型 表情识别 离散小波交换 标准正交非负矩阵分解 典型相关分析 主观表现模型
推荐指数 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8
科研热词 非负矩阵分解 鱼腥草 近红外 识别 数字水印 局部特征提取 增量学习 人脸识别
推荐指数 7 3 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4
2014年 科研热词 非负矩阵分解 稀疏表示 模式识别 图像特征提取 推荐指数 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
非负矩阵分解及其应用探讨

非负矩阵分解及其应用探讨作者:高燕燕来源:《硅谷》2011年第23期摘要:介绍非负矩阵分解(non-negative matrix factorization,NMF)的基本算法思想及其实现过程,并对其在一些重要领域内的应用现状进行概括归纳,最后提出NMF方法在图像处理方面存在的问题及其改进的趋势。
关键词:非负矩阵分解;特征提取;矩阵分解中图分类号:TP391 文献标识码:A 文章编号:1671-7597(2011)1210164-01随着现代计算机处理信息数据的规模越来越大,矩阵作为一种最常见的数据表示形式得到了广泛的应用。
但在实际问题当中,由于矩阵的数据量往往很大,直接处理效率低,意义不大,在实际的操作中,都需要对原始矩阵进行分解。
矩阵分解是将原始矩阵进行适当的分解,使得进一步处理变得简单些。
NMF是D.D.Lee和H.S.Seung在1999年《Nature》中首次提出的算法[1],该算法要求矩阵中所有元素均为非负的条件下对矩阵进行非负分解。
由于非负矩阵分解实现简单、分解形式和分解结果上的可解释性,以及占用存储空间上的优点,使得非负矩阵分解在实际应用中得到了广泛应用。
1 非负矩阵分解算法1)问题的描述传统NMF问题可描述如下:(1-1)即给定m个n维数据向量集合,每个列向量表示一个样本数据,m为集合中数据样本的个数。
W为基矩阵,H为编码矩阵。
选取的r值一般要求满足,从而可使W和H矩阵的秩远远小于矩阵V的秩。
这样就达到了对原始矩阵V的降维处理。
NMF算法通过“乘性”迭代规则来保证每次迭代后矩阵的元素为非负,保证了非负矩阵分解的可行性。
[2]这种算法实现容易因此得到十分广泛的应用。
2)算法的实现过程NMF算法可以理解为一个带约束的非线性规划的问题,可转化成最优化问题,利用迭代的手段可求解出W和H。
为了求出矩阵分解的结果,Lee和Seung引入了两类目标函数:①矩阵A和B之间的欧氏距离:② Kullback-Leibler散度函数:令A=V,B=WH,可得到用于NMF算法的两类目标函数基于以上两个目标函数,就可得到如下的约束优化问题:和通过合适的迭代规则对以上两个约束优化问题进行收敛得到稳定的矩阵W和H。
非负矩阵分解及其在图像压缩中的应用_张永鹏

)
+ φ(kjt)
·5 5
L C
ED
( t) kj
(4)
由此可以得到如下的加性迭代规则 :
B ik ← B ik + <ik [ ( X C T) ik - ( B CC T) ik ]
Ckj ← Ckj + φkj [ ( B T X ) kj - ( B TB C) kj ]
(5)
如果设置 <ik
X n ×m ≈ B n ×rCr ×m , 其中 B n ×r 称为基矩阵 , Cr×m 为系数矩阵 。若选择 r 比 n 小 ,即 r < n ,用系数矩阵 Cr×m 代替原数据矩 阵 X n ×m , 就可以实现对原数据矩阵的降维 , 得到数 据特征的降维矩阵 。然后对系数矩阵 C 进行压缩 , 从而减少存储空间 ,节约计算资源 。 1. 2 非负矩阵分解的算法
具体的实现技术如下 : (1) 首先把一幅图像分 8 ×8 的子块进行离散余 弦正变换 ( FDCT) 和离散余弦逆变换 ( IDCT) 。 在编码器的输入端 ,原始图像被聚分成一系列 8 ×8 的块 ,作为离散余弦正变换 ( FDCT) 的输入 。 在解码器的输出端 ,离散余弦逆变换 ( IDCT) 输出许 多 8 ×8 的数据块 ,用以重构图像 。 (2) 量化 为了达到压缩数据的目的 ,对 DCT 系数 F ( u , v) 需作量化处理 。量化处理是一个多到一的映射 , 它是造成 DCT 编解码信息损失的根源 。在 J PEG 标 准中采用线性均匀量化器 。量化定义为 , 对 64 个 DCT 变换系数 F ( u , v) 除以量化步长 Q ( u , v) 后
性以及稀疏性的特点是很有意义的 。
2 DCT 算法原理
基于结构投影非负矩阵分解的协同过滤算法

基于结构投影非负矩阵分解的协同过滤算法
非负矩阵分解(Non-negative Matrix Factorization, NMF)是一种有效的协同过滤算法,能够计算出用户评价物品的偏好,并用于推荐系统。
结构投影NMF(Structured-Projected NMF,SPNMF)是基于非负矩阵分解的一种改进算法,它能够有效解决物品评分矩阵的稀疏性、不同物品类别之间的交互效应等问题。
结构投影NMF首先将原矩阵分解成一对低阶矩阵,再对其中一个低阶矩阵进行结构投影,可以帮助物品分类并弥补稀疏性存在的问题。
结构投影NMF的基本思想是,假定一个高维度的物品描述空间有两个基本的维度,其中一个维度是针对物品内在特征的评价,另一个维度是针对物品分类结构的投影。
在结构投影非负矩阵分解中,其中一个低阶矩阵用来描述用户对物品内在特征的评价程度,另一个矩阵用来投影物品类别到较低维度的空间,从而可以补充稀疏性存在的物品评分矩阵。
结构投影NMF算法可以通过最小二乘和最小交叉熵的原理来优化,使得对于每一对用户和物品的评分值,均最接近实际值。
结构投影NMF算法在不加入复杂的搜索过程的情况下,也能够得到较为合理的高质量推荐结果。
在某些推荐任务中,用结构投影NMF算法即可获得较高精度的推荐结果,弥补物品评分矩阵的稀疏性及物品类别的多样性问题。
结构投影NMF算法的另一个优点在于它可以很好地忠实于评论者的喜好,而不会过度相信物品的普遍性,同时也可以发现具有相似分类的相关物品。
结构投影NMF算法的一个主要缺点是计算复杂度较高,在大数据集上计算时间会比较长。
因此,对大型数据集应慎重使用此算法,尽量在可接受的计算时间内获得高质量结果。
稀疏矩阵 lu分解
稀疏矩阵 lu分解稀疏矩阵LU分解稀疏矩阵LU分解是一种用于解决稀疏矩阵线性方程组的方法。
稀疏矩阵是指矩阵中绝大多数元素为零的矩阵。
在实际应用中,稀疏矩阵的出现是很常见的,比如图像处理、网络分析等领域。
LU分解是将一个矩阵分解为一个下三角矩阵L和一个上三角矩阵U的乘积的过程。
在稀疏矩阵的情况下,传统的高斯消元法可能会导致大量的计算浪费,因此稀疏矩阵LU分解成为一种更高效的方法。
稀疏矩阵LU分解的基本思想是通过选取适当的行交换和列交换来减小矩阵的非零元素个数,使得原矩阵中的非零元素位于LU分解后上三角或下三角矩阵的主对角线上。
在LU分解过程中,需要注意保持矩阵乘积不变,即A = LU。
以下是稀疏矩阵LU分解的具体步骤:1. 初始化:设置L为单位下三角矩阵,U为原矩阵A的副本。
2. 确定主元:选择A中列主元最大的行作为主元所在的行。
3. 行交换:将主元所在行与第一行交换,并更新L和U的元素。
4. 列交换:将主元所在列与第一列交换,并更新L和U的元素。
5. 更新矩阵:通过高斯消元法将第一列的非零元素置为零,并更新L和U的元素。
6. 迭代:对剩余的子矩阵重复上述步骤,直到得到完整的LU分解。
稀疏矩阵LU分解的核心优势在于减小计算量和存储空间的需求。
通过行交换和列交换,可以将稀疏矩阵的非零元素移动到主对角线上,使得后续的高斯消元过程更加高效。
此外,LU分解可以将复杂的线性方程组问题转化为更简单的求解过程,提高了解决问题的效率。
总结起来,稀疏矩阵LU分解是一种高效解决稀疏矩阵线性方程组的方法。
通过确定主元、行交换和列交换的方式,可以降低计算复杂度和存储空间的需求。
稀疏矩阵LU分解在各种应用领域中都有重要的意义,可以加快问题求解的速度和效率。
24种信号分解方法
24种信号分解方法一、傅里叶级数分解法。
这个方法可是大名鼎鼎啊!它就像是一个魔法盒子,能把周期性信号分解成一堆正弦和余弦函数的组合。
想象一下,一个复杂的周期性信号,经过傅里叶级数这么一捣鼓,就变成了好多简单的正弦、余弦波叠加在一起。
咱通过计算这些正弦、余弦波的幅度、频率和相位,就能清楚地知道原来那个复杂信号的特性啦。
比如说,在通信领域,很多信号都是周期性的,用傅里叶级数分解后,咱就能分析它包含了哪些频率成分,这对信号的调制、解调等处理那可是很有帮助的。
二、傅里叶变换分解法。
傅里叶变换和傅里叶级数有点像亲戚,但又不太一样。
它主要是针对非周期性信号的。
非周期性信号不能像周期性信号那样用级数展开,这时候傅里叶变换就派上用场啦。
它把信号从时域转换到频域,让咱能看到信号在不同频率上的分布情况。
就好比给信号拍了一张X光片,能清楚地看到它的“骨骼结构”,也就是频率成分。
在图像处理中,傅里叶变换就经常被用来分析图像的频率特性,通过对高频和低频成分的处理,可以实现图像的增强、滤波等操作。
三、离散傅里叶变换(DFT)随着数字技术的发展,离散傅里叶变换变得越来越重要啦。
因为在实际应用中,咱处理的很多信号都是离散的数字信号。
DFT就是专门用来处理离散信号的傅里叶变换方法。
它把离散的时域信号变换成离散的频域信号。
这个过程就像是把一堆离散的珠子按照一定的规律重新排列,让咱能从另一个角度去理解这些信号。
在数字音频处理中,DFT就被广泛应用,比如音频的频谱分析、均衡器的设计等,都是靠它来实现的。
四、快速傅里叶变换(FFT)FFT可是DFT的一个超级优化版本哦!DFT计算量比较大,当信号的数据量很大的时候,计算起来可就费劲啦。
而FFT就像是一个聪明的小助手,它采用了一些巧妙的算法,大大减少了计算量,让计算速度变得飞快。
这就好比是走了一条捷径,能更快地到达目的地。
FFT在很多领域都有广泛的应用,像雷达信号处理、数字通信等,只要涉及到大量数据的信号处理,基本上都离不开它。
非负矩阵分解方法在水系沉积物地球化学数据处理中应用
第34卷第2期地球科学———中国地质大学学报Vol.34 No.22009年3月Earth Science —Journal of China University of G eosciencesMar. 2009基金项目:国家自然科学基金重点项目(No.40638041);地质调查项目(No.121201063390110);地质过程与矿产资源国家重点实验室开放课题(No.GPMR200803);国家863项目(No.2006AA06Z115);地质过程与矿产资源国家重点实验室科技部专项经费资助.作者简介:张生元(1961-),男,博士,教授,主要从事矿产资源定量评价方法、科研开发和教学工作.E 2mail :zhangsh3002@非负矩阵分解方法在水系沉积物地球化学数据处理中应用张生元1,2,黄 锐2,徐德义2,成秋明21.石家庄经济学院资源与环境工程研究所,河北石家庄0500312.中国地质大学地质过程与矿产资源国家重点实验室,湖北武汉430074摘要:鉴于水系沉积物地球化学数据可以表示为非负矩阵,这使得利用非负矩阵分解(NMF )方法处理该类数据成为可能.介绍了非负矩阵分解方法的基本原理和方法,讨论了基于非负矩阵分解方法处理水系沉积物地球化学数据的可能和效果.以个旧水系沉积物地球化学数据为例,运用NMF 方法和主成分分析(PCA )方法对其进行异常分析,并对这两种方法的处理结果进行了比较,发现NMF 方法对于处理水系沉积物地球化学数据是一种有效的方法.尽管这两种方法各自有其优越性,但就本实例数据而言,NMF 方法优于PCA 方法.关键词:非负矩阵分解;主成分分析;地球化学数据.中图分类号:P628 文章编号:1000-2383(2009)02-0347-06 收稿日期:2009-01-16Application of Non 2N egative Matrix F actorization in StreamSediment G eochemical Data ProcessingZHAN G Sheng 2yuan 1,2,HUAN G Rui 2,XU De 2yi 2,CH EN G Qiu 2ming 21.I nstit ute of N at ural Resource and Envi ronment Engineering ,S hi j iaz huang Universit y of Economics ,S hi j iaz huang 050031,China2.S tate Key L aboratory of Geological Processes and Mineral Resources ,China Universit y of Geosciences ,W uhan 430074,ChinaAbstract :This paper explores the possibility of applying non 2negative matrix factorization (NMF )to process stream sediment geochemical data for mineral exploration.The brief introduction of principle of NMF is followed by detailed comparison of the results obtained by NMF and principal component analysis (PCA )applied to a dataset of 813samples with six trace elements f rom Gejiu mineral district ,Yunnan ,China.It is shown that the NMF is not only suitable for processing geochemical data which are usually of positive values but also provides superior results than that by PCA in the case study introduced in the pa 2per.The example indicates that NMF might become a usef ul method for processing other types of geochemical data.K ey w ords :non 2negative matrix factorization ;principal component analysis ;geochemical data processing. 矩阵分解是实现大规模数据处理与分析的一种有效工具.把矩阵分解为形式比较简单或具有某种特性的一些矩阵的乘积或叠加,在矩阵理论的研究与应用中都是十分重要的.在数值分析领域,利用矩阵分解可以将计算规模较大的复杂问题转化为一系列计算规模较小的简单子问题来求解;在应用统计学领域,通过矩阵分解得到原数据矩阵的低秩逼近,更易于发现数据的内在结构特征;在机器学习和模式识别方面,矩阵的低秩逼近可以大大降低数据特征的维数,节省存储和计算资源;在自适应滤波中,常常利用矩阵分解的特殊形式来减少计算的复杂性、提高滤波器的性能等.在地球化学数据处理中常用PCA 方法寻找地球化学元素的有用组合以提取地球化学元素的组合异常,为地质找矿提供依据.从数学计算的角度来看,矩阵分解结果中存在负值是允许的,但负值元素在实际问题中往往是难地球科学———中国地质大学学报第34卷以解释的.例如图像数据中的灰度值一般不能有负值,物质成分的含量也总是非负数值等.因此,研究矩阵的非负分解方法是一项很有意义的工作.早在20世纪70年代就已经有数学家针对非负矩阵做了一些相关的研究工作,但没有引起过多的关注.到20世纪90年代,科学家已进行了与非负矩阵分解类似研究,如,正矩阵分解(PM F)(J uvela et al.,1994,1996)应用于环境处理和卫星遥控(Paatero and Tapper,1994;Paatero,1997).1999年Lee和Seung两位科学家在著名杂志《Nat ure》上提出“非负矩阵分解”(non2negative matrix factoriza2 tion,NM F)的概念和算法(Lee and Seung,1999)用于寻找一组基函数表示非负矩阵的方法.这种新的矩阵分解算法要求矩阵中所有元素均为非负的.在以往的矩阵分解方法中,原始矩阵V被近似分解为低秩的V≈WH形式,这些方法的共同特点是分解因子W和H中的元素可正可负,即使原始矩阵元素是全正的,传统的算法也无法保证分解后矩阵的非负性,且正负相互抵消不利于数据特征的提取和解释.而NM F则是在初始矩阵及分解矩阵中所有元素均为非负数约束条件之下的矩阵分解方法,这种非负性条件符合许多实际问题的要求,更便于对分析结果的解释.NM F方法用于人脸表情识别比传统方法的识别效果更好,根据非负矩阵分解的特点,将其用于文本和日志分析领域,设计有针对性的分类和聚类算法,达到了较好的效果(Lee and Seung,1999;Xu et al.,2003);利用非负矩阵分解算法进行盲信号分离,证明NM F方法在分离统计独立信源、统计相关信源以及高斯分布信源上非常有效(魏乐,2004).在诸多应用中NMF能用于发现数据库中的图像特征,便于快速自动识别;能用于发现文档的语义相关度,便于信息自动索引和提取;能用于在DNA序列分析中识别基因等.NM F最成功的一类应用是在图像处理和分析领域(Guillamet et al.,2001, 2003;Feng et al.,2002).由于NM F在众多领域有较好的应用效果,本文将其引入到水系沉积物地球化学数据处理中.1 非负矩阵分解理论NM F的基本思想(Lee and Seung,1999)为任意给定一个非负的m×n矩阵V,需将其分解为左右两个非负矩阵的乘积,即要找出非负的m×r矩阵W和非负的r×n矩阵H(通常r(m+n)<m n,即r<m n/(m+n),使得W和H的总数据量比V小),从而满足:V≈WH.(1)由于分解前后的矩阵中仅包含非负元素,因此原矩阵V中的任一列向量可以解释为左矩阵W中所有r 个列向量(称为基向量)的加权和,而权重系数为右矩阵H中所对应列向量的元素.这说明W组成了一个基矩阵(基向量组),可以通过它的列向量的线性组合来近似表示V,这相当于用相对较少的基向量来表示大量的数据向量,因此只有在基向量覆盖了V中隐含的数据结构时,才能获得令人满意的近似表达效果(Donoho and Stodden,2004).非负性是对矩阵分解非常有效的约束条件,这一约束导致了对原始数据基于部分的表示,NM F算法所得到的非负基向量组W具有一定的聚类性和稀疏性,从而对原始数据的特征及结构具有较强的表达能力.这种基于基向量组合的表示形式具有很直观的语义解释,它反映了人类思维中“局部构成整体”的概念(Lee and Seung,1999).有关非负矩阵分解的算法请参阅Lee and Seung(1999,2000).2 NM F在水系沉积物地球化学数据处理中的应用化探数据,特别是水系沉积物地球化学数据是地质找矿的重要数据源之一,通过处理化探数据获取地球化学异常是化探数据处理的目标之一.化探异常包括单元素异常和多元素组合异常.传统上获取化探元素组合异常的常用方法是主成分分析(PCA)方法.PCA方法在方差极大和正交约束的条件下寻求化探元素组合,以此为基础提取化探元素组合异常.而PCA方法仅能表达数据的全局特征(Lee and Seung,1999).由于受不同地质环境的影响,化探数据在不同的研究区域内会具有不同的组合特征,表现为局部与全局特征上的差异,这些局部特征往往与成矿或矿床分布有关.NM F方法的基向量却具有表达数据局部结构特征的特点,这可能为化探数据处理提供了一种有效的途径.此外,化探数据都是非负的,也正好满足NM F方法对数据非负性的基本要求.假设有n个化探样品,每个样品分析了k个地843 第2期 张生元等:非负矩阵分解方法在水系沉积物地球化学数据处理中应用球化学元素含量,往往是含量比例如常量元素百分含量(%)或微量元素含量(pp b 或pp m ),这些含量均为非负数值,可以组成一个n ×k 阶的化探数据非负矩阵V ,每一列V i 代表一个元素,每一行代表一个样品.根据NM F 理论,可以将k 个化探元素组成的数据矩阵V 分解为以下的形式:V mn ×k ≈W mn ×r H r ×k ,(2)其中,W 为基向量矩阵(或向量组),H 为权值矩阵,r 为基向量的个数.这里要求V 、W 和H 都是非负的.由式(2)可知,数据矩阵V 的列向量可表示为左矩阵W 的列向量的线性组合,加权系数即为右矩阵H 的对应列向量中的元素.基向量组W 的每个列向量都从不同角度反映了地球化学元素组合信息.因此,非负矩阵分解的基向量可提供原始地球化学元素组合的基本信息.下面的应用实例中将会对这些基向量的意义进行研究.3 实例研究区为云南个旧锡铜多金属矿区,总面积约3108km 2,在研究区范围内共有813个1∶20万水系沉积物地球化学样采样点,等间距采样,每2km ×2km 为一个数据点,本文中用到了As 、Cd 、Cu 、Pb 、Zn 和Sn 共6种元素.有关研究区内的地质概况和物探、化探以及遥感影像特征参见成秋明等(2009).表1 r =1,2,3时NMF 权值矩阵Table 1Encodings using NMF when r =1,2,30.05810.98970.06810.02650.05990.0903r =300.016800.98370.04070.17440.494000.307900.26180.7698r =20.04230.99300.05840.04190.05280.06470.11370.02040.02280.90320.11240.3971r =10.07250.92830.06090.30260.08190.17603.1 非负矩阵分解方法应用在本例中选取As 、Cd 、Cu 、Pb 、Sn 和Zn 6个地球化学元素的813个水系沉积物样品组成813×6的非负矩阵V ,运用MA TLAB R2008a 的非负矩阵分解函数NM F 分别取r =1,2,3对V 进行非负分解.分解后的加权矩阵如表1,基向量之间的相关系数如表2.对每个基向量进行反距离插值后生成栅格图层并对其取对数,如图1所示.图1a 、1b 和1c 分别表示r =1,2,3所得到的第一个基向量的结果(为了表达方便,图中对结果取了自然对数).从这3个图的结果可以看出,它们的空间分布形态基本上一致,从表2也可以看出它们之间的相关系数分别高达0.9969,0.997和0.9999;图1d 和图1e 分别是r 为2和3时的第二个基向量取对数.从图中可以看出,两个基向量形态非常相似,它们之间的相关系数为0.9927;图1f 是r 为3时的第3个基向量取对数.可以看出,虽然当基向量的个数不同时,对应的基向量(比如第一基向量)会有所差异,但总体来说变化不大,具有相对稳定性.为了研究每个基向量与各元素之间的关系,我们计算了基向量与原始元表2 NMF 基向量和PCA 的3个主成分之间的相关系数Table 2Correlations among six basis vectors using NMF and three principal components using PCAAsCdCuPbSnZnW1W21W22W31W32W33Cd 0.642Cu 0.6920.711Pb 0.6170.8310.588Sn 0.7470.7310.7480.713Zn 0.6140.8100.6180.8420.630W10.6600.9970.7170.8680.7490.839W210.645 1.0000.7160.8270.7340.8100.997W220.6390.7950.5900.9910.7130.8830.8380.792W310.642 1.0000.7130.8290.7320.8090.997 1.0000.793W320.5920.8060.5620.9990.6930.8410.8460.8030.9930.805W330.6970.3490.5770.4760.5480.7290.3910.3530.5790.3490.479PCA10.8240.9110.8340.8860.8770.8700.9310.9130.8890.9110.8670.644PCA2-0.360.199-0.350.351-0.260.3680.2160.1910.3450.1960.380-0.14PCA30.379-0.15-0.390.0990.0380.023-0.11-0.150.139-0.150.1110.234943地球科学———中国地质大学学报第34卷图1 NMF 方法r =1,2,3时6个基向量分别取对数后的6个图层Fig.1Six basis vectors obtained using NMF when r =1,2,3a.r =1时的第一个基向量取对数;b.r =2时的第一个基向量取对数;c.r =3时的第一个基向量取对数;d.r =2时的第二个基向量取对数;e.r =3时的第二个基向量取对数;f.r =3时的第3个基向量取对数素向量之间的相关性,当r =3时,从表1可以看出,Cd 主要由第一基向量决定,Pb 主要由第二基向量表示,但Cd 与Cu 、Pb 、Sn 、Zn 的相关系数至少大于0.71,所以第一基向量间接反映了元素Cu 、Pb 、Sn和Zn 元素组合,Pb 与Sn 和Zn 的相关系数分别为0.71和0.84,间接反映了元素Sn 和Zn.而As 、Cu 、Sn 和Zn 与第三基向量关系比较大.3.2 主成分分析(PCA)方法应用为了与非负矩阵分解方法进行比较,同样选取上述6个元素的数据进行主成分分析,前3个主成分(PCA1,PCA2,PCA3)的因子载荷见图2,由于这3个主成分的因子得分包含负值,不能直接取对数,第一主成分的因子得分加0.7取对数后见图3a ,将第二、三主成分的得分分别加7后取对数如图3b 和3c.从图3和图2可以看出第一主成分的因子载荷都为正的,反映6个元素的综合效应;第二主成分因子载荷正值是As 2Cu 2Sn 组合,负值是Zn 2Pb 2Cd 组合;第三主成分因子载荷的正值是Cu 2Cd 2Pb 组合,负值是As 2Sn 2Zn 组合.53 第2期 张生元等:非负矩阵分解方法在水系沉积物地球化学数据处理中应用3.3 非负矩阵分解与主成分分析比较(1)NM F 和PCA 都是矩阵分解方法,都服从等式(1)分解模型,主要差别在于约束条件不同,NM F 模型的约束条件是W 和H 都是非负矩阵,而对于PCA 方法不要求W 和H 是非负矩阵,但W 是列正交的,H 是行正交的.(2)Lee and Seung (1999)通过对人脸图像进行分析认为,NM F 方法的基向量具有稀疏特征,H 含有较多的0元素,这一结论从本例的结果也得到了验证,特别是基向量具有大量的重复取值.这一特征说明NM F 具有较好的反映局部的特性,而PCA 方法仅能反映数据的全局特征.(3)这里只对PCA 的3个主成分和r =3时的3个基向量进行比较.从图1c 和图3a 可以看出PCA1和NM F 第一基向量都较好地反映了研究区内的多金属矿产相关的化探组合元素异常分布,二者的相关系数为0.911,具有较高的相关性;从图3b 可以看出,PCA2较好地反映了Pb 和Zn 相关异常,但对于包含Cu 2Pb 2Zn 或者Sn 2Pb 2Zn 反映较差.从图1e 看出NM F 第二个基向量对多种矿产都有较好的反映,并且其分布具有较好聚类性;从图3c 可以看出,PCA3仅对少数几个与Cu 有关的多金属矿产反映较好(负值),对大部分矿产反映较差.从图1F 看出NM F 第3个基向量对多金属矿产和Pb 矿产反映较好.就本实例而言,通过上述比较可以看出NM F 能更好地反映多金属矿产的分布特征,优于主成分分析方法.4 结论非负矩阵分解方法为水系沉积物地球化学数据处理提供了一种较好的方法;就本实例而言,非负矩阵分解方法优于传统的主成分分析方法;与主成分分析方法仅能反映数据的全局特征相比,非负矩阵分解方法能较好地反映多元素分布的局部特征.尽管本实例是针对水系沉积物地球化学数据而介绍的,但该方法对于其他数据处理同样具有参考意义,也可用于其他的地球化学数据处理,建议在其他地球化学数据处理中进行试验.R eferencesCheng ,Q.M.,Zhao ,P.D.,Chen ,J.G.,et al.,2009.Applica 2tion of singularity theory in prediction of tin and copper mineral deposits in G ejiu district ,Yunnan ,China :Weak information extraction and mixing information decom 2position.Earth Science —J ournal of China Universit y153地球科学———中国地质大学学报第34卷of Geosciences,34(2):232-242(in Chinese with Eng2 lish abstract).Donoho,D.,Stodden,V.,2004.When does non2negative ma2 trix factorization give a correct decomposition into parts?In:Thrun,S.,Saul,L.,Scholkopf,B.,eds.,Ad2 vances in neural information processing systems16.MIT Press,Cambridge,MA.Feng,T.,Li,S.,Shum,H.,et al.,2002.Local non2negative matrix factorization as a visual representation.In:Pro2 ceedings of the2nd international conference on develop2 ment and learning.IEEE,Cambridge.U.K.,178-183.DOI:10.1109/DEVL RN.2002.1011835.Guillamet,D.,Bressan,M.,Vitria,J.,2001.A weighted non2 negative matrix factorization for local representations.In:Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition V1, Kauai,HI,942-947.DOI:10.1109/CV PR.2001.990629.Guillamet,D.,Vitria,J.,Schiele,B.,2003.Introducing a weighted non2negative matrix factorization for image classification.Pattern Recognition L etters,24(14):2447-2454.J uvela,M.,Lehtinen,K.,Paatero,P.,1994.The use of posi2 tive matrix factorization in the analysis of molecular line spectra f rom the thumbprint nebula.In:Clemens,D.P., Barvainis,R.,eds.,Clouds,cores,and low mass star.A S P Conf erence S eries,65:176-180.J uvela,M.,Lehtinen,K.,Paatero,P.,1996.The use of posi2 tive matrix factorization in the analysis of molecular line spectra.Mon.N ot.R.A st ron.S oc.,280:616-626.Lee,D.O.,Seung,H.S.,1999.Learning the parts of objects by non2negative matrix factorization.N ature,401:788 -791.Lee,D.,Seung,H.,2000.Algorithms for non2negative ma2 trix factorization.In:Leen,T.,Dietterich,T.,Tresp, V.,eds.,Advances in neural information processing systems.MIT Press,Cambridge,MA,556-562. Paatero,P.,1997.Least squares formulation of robust non2 negative factor analysis.Chemomet rics and I ntelli gent L aboratory S ystems,37(1):23-35.Paatero,P.,Tapper,U.,1994.Positive matrix factorization:A non2negative factor model with optimal utilization oferror estimates of data values.Envi ronmet rics,5(2): 111-126.Wei,L.,2004.Blind sources separation based on non2nega2 tive matrix factorization.Elect ronics O ptics&Cont rol, 11(2):38-41,53(in Chinese with English abstract). Xu,W.,Liu,X.,G ong,Y.,2003.Document2clustering based on non2negative matrix factorization.In:Proceedings of SIGIR’03,J uly282August1.267-273,Toronto,CA.附中文参考文献成秋明,赵鹏大,陈建国,等,2009.奇异性理论在个旧锡铜矿产资源预测中的应用:成矿弱信息提取和复合信息分解.地球科学———中国地质大学学报,34(2):232-242.魏乐,2004.基于非负矩阵分解算法进行盲信号分离.电光与控制,11(2):38-41,53.253。
一种基于L1稀疏正则化和非负矩阵分解的盲源信号分离新算法
Ne b i d s u c e r to l o ih a e n w ln o r e s pa a i n a g r t m b s d o L1s a s e u a i a i n a d no e a i e m a r x f c o i a i n p r e r g l r z to n nn g tv t i a t r z to
21 0 0年 l 月 O
西安电子科技大学学报( 自然 科 学 版 )
J0U RNAL 0F XI I D AN UN I VER SI TY
O c . 01 t2 0
第 3 7卷
第 5 期
Vo . 7 No 5 I3 .
一
种基 于 L 稀 疏 正 则 化 和 非 负 矩q a rt rb e u d ai p o lm, a d t e rde t poe t n ag rt m t d p ie B ri iB r i tpe gh c n h n a g a in rjci lo i o h wi a a t a zl — o wen se ln t h v a
殷 海 青 , 刘 红 卫
( 西安 电子 科 技 大 学 理 学 院 , 陕西 西安 7 0 7 ) 10 1
摘 要 :针 对 线 性 混合 模 型 下 的 盲 源分 离这 一 反 问 题 , 出 了 一 种 结 合 迭 代 正 则 化 和 非 负 矩 阵 分 解 的 交 提 替 最 小化 算 法. 先 把 该 f 首 d题 转 化 为 有 界 约 束 的 二 次 规 划 , 后 采 用 了 一 种 自适 应 B B ri i 然 B( a z a l— B r i) o we 步长 的投 影 梯度 算 法 来 求 解 . 方 法不 仅 可 减 少 存 储 量 , 高 算 法 速 度 , 且 还 很 好 地 刻 画 了 n 该 提 而 信 号 的稀 疏 性 和 独 立 性. 论 分 析 和 数 值 试 验 都 验 证 了该 方 法 的有 效 性 , 混 合 的二 维 图像 能 提 高 分 离 理 对
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
稀疏非负矩阵分解
稀疏非负矩阵分解(Sparse Non-negative Matrix Factorization,SNMF)是一种常用的数据分析和模式识别方法,它广泛应用于文本挖掘、图像处理、推荐系统等领域。
本文将介绍稀疏非负矩阵分解的原理和应用,并探讨其在实际问题中的优势和局限性。
一、稀疏非负矩阵分解的原理
稀疏非负矩阵分解是一种将原始数据矩阵分解为两个非负矩阵的方法,即将一个矩阵分解为两个因子矩阵的乘积。
其中,原始数据矩阵可以表示为一个m行n列的矩阵X,而分解后的因子矩阵分别为m 行k列的矩阵U和k行n列的矩阵V。
通过对原始数据矩阵进行分解,可以得到稀疏的因子矩阵U和V,从而实现对原始数据的降维和特征提取。
稀疏非负矩阵分解的关键在于约束因子矩阵U和V的非负性和稀疏性。
非负性约束是指因子矩阵U和V的所有元素都必须大于等于零,这种约束保证了分解后的因子矩阵具有良好的物理意义和解释性。
稀疏性约束是指因子矩阵U和V的大部分元素都为零,只有少数元素非零,这种约束可以实现对原始数据的降维和特征提取,同时减少存储和计算的开销。
二、稀疏非负矩阵分解的应用
稀疏非负矩阵分解在文本挖掘、图像处理和推荐系统等领域具有广泛的应用。
在文本挖掘中,可以将文档矩阵分解为主题矩阵和词矩阵,通过对主题矩阵和词矩阵的分析,可以实现对文本的分类、聚类和关键词提取等任务。
在图像处理中,可以将图像矩阵分解为基础模式矩阵和系数矩阵,通过对基础模式矩阵和系数矩阵的分析,可以实现对图像的压缩、去噪和特征提取等任务。
在推荐系统中,可以将用户-物品评分矩阵分解为用户矩阵和物品矩阵,通过对用户矩阵和物品矩阵的分析,可以实现对用户兴趣和物品特性的建模,从而实现个性化推荐。
三、稀疏非负矩阵分解的优势
稀疏非负矩阵分解具有多个优势。
首先,稀疏非负矩阵分解可以实现对原始数据的降维和特征提取,从而减少存储和计算的开销。
其次,稀疏非负矩阵分解可以保留原始数据的稀疏性和非负性,这种特性使得分解后的因子矩阵具有良好的解释性和可解释性。
再次,稀疏非负矩阵分解可以应对大规模和高维度的数据,这种方法在处理大数据和高维数据方面具有较好的效果。
最后,稀疏非负矩阵分解可以结合其他机器学习算法,进一步提高模型的性能和准确性。
四、稀疏非负矩阵分解的局限性
稀疏非负矩阵分解也存在一些局限性。
首先,稀疏非负矩阵分解的计算复杂度较高,在处理大规模和高维度数据时,需要消耗大量的
计算资源和时间。
其次,稀疏非负矩阵分解对初始值的选择较为敏感,不同的初始值可能导致不同的分解结果。
再次,稀疏非负矩阵分解的结果可能存在误差和噪声,这种误差和噪声可能会影响到后续的数据分析和模型建立。
最后,稀疏非负矩阵分解需要根据具体问题进行调参和优化,对于非专业人士来说,可能需要一定的领域知识和经验。
稀疏非负矩阵分解是一种常用的数据分析和模式识别方法,它可以将原始数据矩阵分解为两个非负矩阵的乘积。
通过对原始数据矩阵进行分解,可以实现对原始数据的降维和特征提取。
稀疏非负矩阵分解在文本挖掘、图像处理和推荐系统等领域具有广泛的应用。
虽然稀疏非负矩阵分解具有一些优势,但也存在一些局限性。
因此,在实际应用中,需要根据具体问题和需求,选择合适的数据分析方法和模型。