计量经济学课后思考题(答案)庞皓版
计量经济学 庞皓 第三版课后答案
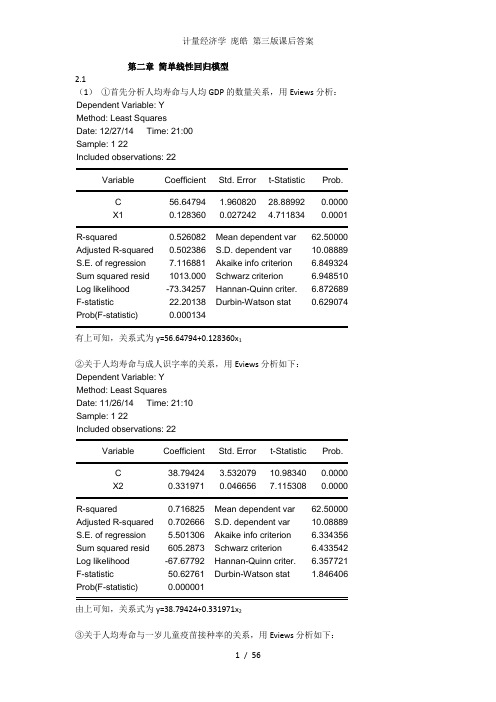
第二章简单线性回归模型2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/27/14 Time: 21:00Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000X1 0.128360 0.027242 4.711834 0.0001R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:10Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 38.79424 3.532079 10.98340 0.0000X2 0.331971 0.046656 7.115308 0.0000R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:14Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 31.79956 6.536434 4.864971 0.0001X3 0.387276 0.080260 4.825285 0.0001R-squared 0.537929 Mean dependent var 62.50000Adjusted R-squared 0.514825 S.D. dependent var 10.08889S.E. of regression 7.027364 Akaike info criterion 6.824009Sum squared resid 987.6770 Schwarz criterion 6.923194Log likelihood -73.06409 Hannan-Quinn criter. 6.847374F-statistic 23.28338 Durbin-Watson stat 0.952555Prob(F-statistic) 0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
计量经济学(庞浩)第二版课后习题答案

计量经济学(庞浩)第二版课后习题答案2.7 设销售收入X 为解释变量,销售成本Y 为被解释变量。
现已根据某百货公司某年12个月的有关资料计算出以下数据:(单位:万元) 2()425053.73tX X -=∑ 647.88X =2()262855.25t Y Y -=∑ 549.8Y =()()334229.09ttX X Y Y --=∑(1) 拟合简单线性回归方程,并对方程中回归系数的经济意义作出解释。
(2) 计算可决系数和回归估计的标准误差。
(3) 对2β进行显著水平为5%的显著性检验。
(4) 假定下年1月销售收入为800万元,利用拟合的回归方程预测其销售成本,并给出置信度为95%的预测区间。
练习题2.7参考解答: (1)建立回归模型: ii iu X Y ++=21ββ 用OLS法估计参数:222()()334229.09ˆ0.7863()425053.73i i i i i iX X Y Y x y X X x β--====-∑∑∑∑12ˆˆ549.80.7863647.8866.2872Y X ββ=-=-⨯=估计结果为: ˆ66.28720.7863iiY X =+说明该百货公司销售收入每增加1元,平均说来销售成本将增加0.7863元。
(2)计算可决系数和回归估计的标准误差 可决系数为:22222222222ˆˆˆ()0.7863425053.73262796.990.999778262855.25262855.25i i iiiiy x x R y yyββ===⨯===∑∑∑∑∑∑由 2221i ie r y=-∑∑ 可得 222(1)ii e R y =-∑∑222(1)(10.999778)262855.2558.3539ii eR y =-=-⨯=∑∑ 回归估计的标准误差:ˆ 2.4157σ===(3) 对2β进行显著水平为5%的显著性检验*222^^22ˆˆ~(2)ˆˆ()()t t n SE SE βββββ-==-^22.4157ˆ()0.0037651.9614SE β====*2^2ˆ0.7863212.51350.0037ˆ()tSE ββ===查表得 0.05α=时,0.025(122) 2.228t-=<*212.5135t=表明2β显著不为0,销售收入对销售成本有显著影响.(4) 假定下年1月销售收入为800万元,利用拟合的回归方程预测其销售成本,并给出置信度为95%的预测区间。
计量经济学庞皓第三版课后答案解析
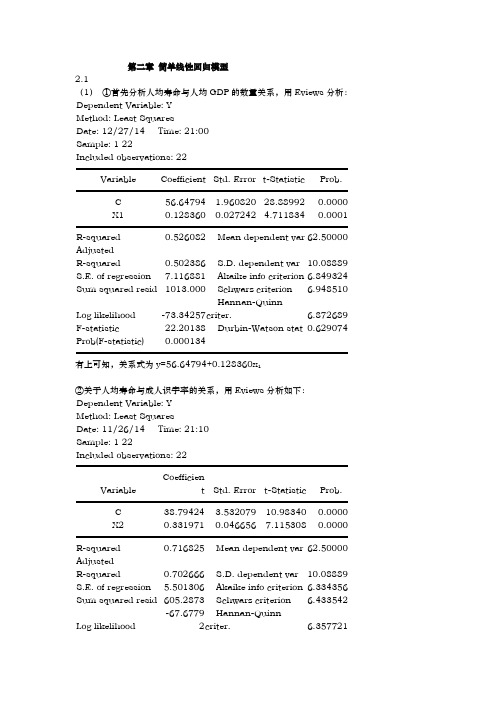
第二章 简单线性回归模型2.1(1) ①首先分析人均寿命与人均GDP 的数量关系,用Eviews 分析:Dependent Variable: YMethod: Least SquaresDate: 12/27/14 Time: 21:00Sample: 1 22Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000AdjustedR-squared 0.502386 S.D. dependent var 10.08889S.E. of regression 7.116881 Akaike info criterion 6.849324Sum squared resid 1013.000 Schwarz criterion 6.948510Log likelihood -73.34257 Hannan-Quinncriter. 6.872689F-statistic 22.20138 Durbin-Watson stat 0.629074Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x 1②关于人均寿命与成人识字率的关系,用Eviews 分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:10Sample: 1 22Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000AdjustedR-squared 0.702666 S.D. dependent var 10.08889S.E. of regression 5.501306 Akaike info criterion 6.334356Sum squared resid 605.2873 Schwarz criterion 6.433542Log likelihood -67.67792 Hannan-Quinncriter. 6.357721F-statistic 50.62761 Durbin-Watson stat 1.846406Prob(F-statistic) 0.000001 由上可知,关系式为y=38.79424+0.331971x 2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews 分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:14Sample: 1 22Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 31.79956 6.536434 4.864971 0.0001X3 0.387276 0.080260 4.825285 0.0001 R-squared 0.537929 Mean dependent var 62.50000AdjustedR-squared 0.514825 S.D. dependent var 10.08889S.E. of regression 7.027364 Akaike info criterion 6.824009Sum squared resid 987.6770 Schwarz criterion 6.923194Log likelihood -73.06409 Hannan-Quinncriter. 6.847374F-statistic 23.28338 Durbin-Watson stat 0.952555Prob(F-statistic) 0.000103 由上可知,关系式为y=31.79956+0.387276x 3(2)①关于人均寿命与人均GDP 模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
计量经济学 - 庞皓 - 第三版课后答案

计量经济学 - 庞皓 - 第三版课后答案第二章简单线性回归模型 2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析: Dependent Variable: Y Method: Least Squares Date: 12/27/14 Time: 21:00 Sample: 1 22 Included observations: 22Variable Coefficient Std. Error t-Statistic Prob. C 56.64794 1.960820 28.88992 0.0000 X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20218 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下: Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:10 Sample: 1 22 Included observations: 22Variable Coefficient Std. Error t-Statistic Prob. C 38.79424 3.532079 10.98340 0.0000 X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: Y Method: Least Squares Date: 11/26/14 Time: 21:14 Sample: 1 22 Included observations: 22Variable Coefficient Std. Error t-Statistic Prob. C 31.79956 6.536434 4.864971 0.0001 X3 0.387276 0.080260 4.825285 0.0001 R-squared 0.537929 Mean dependent var 62.50000Adjusted R-squared 0.514825 S.D. dependent var 10.08889 S.E. of regression 7.027364 Akaike info criterion 6.824009 Sum squared resid987.6770 Schwarz criterion 6.923194 Log likelihood -73.06409 Hannan-Quinn criter. 6.847374 F-statistic 23.28338 Durbin-Watson stat 0.952555 Prob(F-statistic) 0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
计量经济学第三版(庞浩)版课后答案全

第二章2.2 (1)①对于浙江省预算收入与全省生产总值的模型,用Eviews 分析结果如下: Dependent Variable: YMethod: Least SquaresDate: 12/03/14 Time: 17:00Sample (adjusted): 1 33Included observations: 33 after adjustmentsVariableCoefficient Std. Error t-Statistic Prob.??X 0.176124 0.004072 43.25639 0.0000 C-154.3063 39.08196 -3.948274 0.0004R-squared 0.983702 ????Mean dependent var 902.5148 Adjusted R-squared 0.983177 ????S.D. dependent var 1351.009 S.E. of regression 175.2325 ????Akaike info criterion 13.22880 Sum squared resid 951899.7 ????Schwarz criterion 13.31949Log likelihood -216.2751 ????Hannan-Quinn criter. 13.25931F-statistic 1871.115 ????Durbin-Watson stat 0.100021Prob(F-statistic) 0.000000②由上可知,模型的参数:斜率系数0.176124,截距为—154.3063 ③关于浙江省财政预算收入与全省生产总值的模型,检验模型的显着性: 1)可决系数为0.983702,说明所建模型整体上对样本数据拟合较好。
2)对于回归系数的t 检验:t (β2)=43.25639>t 0.025(31)=2.0395,对斜率系数的显着性检验表明,全省生产总值对财政预算总收入有显着影响。
庞皓计量经济学课后答案第七章

统计学2班第六次作业1、⑴①模型一:t t t PDI A A PCE μ++=21t tPDI E C P 008106.14269.216ˆ+-= t (-6.619723)(67.05920)996455.02=R F=4496.936 DW=1.366654美国个人消费支出受个人可支配收入影响,通过回归可知,个人可支配收入PDI 每增加一个单位,个人消费支出平均增加1.008106个单位。
②模型二:t t t t PCE B PDI B B PCE υ+++=-13211037158.0982382.02736.233ˆ-++-=t t tPCE PDI E C P T (-5.120436)(6.970817) (0.257997)996542.02=R F=2017.064 DW=1.570195美国个人消费支出PCE 不仅受当期个人可支配收入PDI 影响,还受滞后一期个人消费支出PCE t-1自身影响。
⑵从模型一得MPC=1.008106从模型二可得短期MPC=0.982382.从库伊特模型)()1(110---+++-=t t t t t Y X Y λμμλβλα可得1-t PEC 为λ的系数即037158.0=λ因为,长期MPC 即长期乘数为:∑=si iβ,根据库伊特模型)10(0<<=λλββi i ,。
当s →∞时,λβλλβλβλβλβββββ-=--==+++=++=∞∞=∞=∑∑111 (001)02210100i ii i所以长期MPC=02023.1037158.01982382.0=-=MPC2、Y :固定资产投资 X :销售额⑴ 设定模型为:t t t X Y μβα++=*,*t Y 为被解释变量的预期最佳值运用局部调整假定,模型转换为:*1*1*0*t t t t Y X Y μββα+++=- 其中:t t δμμδβδββδαα=-===**1*0*,1,,1271676.0629273.010403.15ˆ-++-=t t tY X Y T (-3.193613) (6.433031) (2.365315)987125.02=R F=690.0561 DW=1.518595t t δμμδβδββδαα=-===**1*0*,1,, ,728324.0271676.011*1=-=-=βδ7381.20728324.010403.15*-=-==δαα,864.0728324.0629273.0*0===δββ∴局部调整模型估计结果为:tt X Y 864.07381.20ˆ*+-= 经济意义:该地区销售额每增加1亿元,未来预期最佳新增固定资产投资为0.846亿元采用德宾h 检验如下0:,0:10≠=ρρH H29728.1114858.0*21121)21.5185951()ˆ(1)21(2*1=--=--=βnVar n d h 在显著性水平05.0=α下,查标准正态分布表得临界值96.1025.02==h h α,因此拒绝原假设96.129728.1025.0=<=h h ,因此接受原假设,说明自回归模型不存在一阶自相关。
庞皓计量经济学课后答案第五章
统计学2班第四次作业1、i i i i X X Y μβββ+++=33221⑴222)(i i X Var σμ= 用iX 21乘以式子的两边得: i i i i i i i i i X X X X X X X Y 2233222212μβββ+++= 令i i i X 2μυ=,此时Var(i υ)为同方差:2222222221)(1)()(σσμμυ====i ii i iii X X Var X X Var Var⑵根据最小二乘原理,使得加权的残差平方和最小,使得ii X w 221=即: ∑∑---=)ˆˆˆ(min min 33221222ii i i i i X X Y w e w βββ***12233ˆˆˆY X X βββ=--()()()()()()()***2****22232322322*2*2**2223223ˆii i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-=-∑∑∑∑∑∑∑()()()()()()()***2****23222222332*2*2**2223223ˆii i i i i i i i i i i i i i i i i W y x W x W y x W x x W x W x W x x β-=-∑∑∑∑∑∑∑其中:22232***23222,,i ii ii iiiiW XW XW Y X X Y WWW===∑∑∑∑∑∑******222333i i i i i x X X x X X y Y Y =-=-=-2、⑴模型:μββ++=X Y 21估计如下:637069.0,347522.921==ββ X Y 637069.0347522.9+=(3.638437)(0.019903) t (2.569104)(32.00881)946423.02=R F=1024.564⑵①Goldfeld-Quandt 法:首先对数据根据X 做递增排序处理。
计量经济学庞皓)第三版课后答案
第二章简单线性回归模型2.1(1)①首先分析人均寿命与人均GDP 的数量关系,用Eviews 分析:Dependent Variable: YMethod: Least SquaresDate: 12/27/14 Time: 21:00Sample: 1 22Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000X1 0.128360 0.027242 4.711834 0.0001 R-squared 0.526082 Mean dependent var 62.50000Adjusted R-squared 0.502386 S.D. dependent var 10.08889S.E. of regression 7.116881 Akaike info criterion 6.849324Sum squared resid 1013.000 Schwarz criterion 6.948510Log likelihood -73.34257 Hannan-Quinn criter. 6.872689F-statistic 22.20138 Durbin-Watson stat 0.629074Prob(F-statistic) 0.000134 有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews 分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:10Sample: 1 22Included observations: 22 Variable Coefficient Std. Error t-StatisticProb. C 38.79424 3.532079 10.98340 0.0000X2 0.331971 0.046656 7.115308 0.0000 R-squared 0.716825 Mean dependent var 62.50000Adjusted R-squared 0.702666 S.D. dependent var 10.08889S.E. of regression 5.501306 Akaike info criterion 6.334356Sum squared resid 605.2873 Schwarz criterion 6.433542Log likelihood -67.67792 Hannan-Quinn criter. 6.357721F-statistic 50.62761 Durbin-Watson stat 1.846406Prob(F-statistic) 0.000001 由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews 分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:14Sample: 1 22Included observations: 22 Variable Coefficient Std. Error t-Statistic Prob. C 31.79956 6.536434 4.864971 0.0001X3 0.387276 0.080260 4.825285 0.0001 R-squared 0.537929 Mean dependent var 62.50000Adjusted R-squared 0.514825 S.D. dependent var 10.08889S.E. of regression 7.027364 Akaike info criterion 6.824009Sum squared resid 987.6770 Schwarz criterion 6.923194Log likelihood -73.06409 Hannan-Quinn criter. 6.847374F-statistic 23.28338 Durbin-Watson stat 0.952555Prob(F-statistic) 0.000103 由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP 模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。
计量经济学第四章部分课后题(庞皓第三版)
计量经济学第四章作业思考题:4.3 多重共线性的典型表现是什么?判断是否存在多重共线性的方法有哪些?答:(1)多重共线性的典型表现:A.模型拟和较好,但偏回归系数几乎都无统计学意义;B.偏回归系数估计值不稳定,方差很大;C.偏回归系数估计值的符号可能与预期不符或与经验相悖,结果难以解释。
(2)具体的判断方法:A.解释变量之间简单相关系数矩阵法;B.方差扩大因子法;C.直观判断法;D.逐步回归的方法。
4.4 针对出现多重共线性的不同情形,能采取的补救措施有哪些?答:(1)根据经验,可以选择剔除变量,增大样本容量,变换模型形式,利用非样本先验信息,截面数据和时间序列数据并用以及变量变换等不同方法。
(2)采取逐步回归方法由由一元模型开始逐步增加解释变量个数,增加的原则是显著提高可决系数,自身显著而与其他变量之间又不产生共线性。
(3)采取岭回归方法来降低多重共线性的程度。
4.9 以下陈述是否正确?请判断并说明理由。
(1)在高度多重共线性的情形中,要评价一个或多个偏回归系数的单个显著性是不可能的。
答:正确。
(2)尽管有完全的多重共线性,OLS估计量仍然是BLUE。
答:错误。
(3)如果有某一辅助回归显示出高的R j2值,则高度共线性的存在肯定是无疑的。
答:正确。
(4)变量的两两高度相关并不表示高度多重共线性。
答:正确。
(5)如果其他条件不变,VIF越高,OLS估计量的方差越大。
答:正确。
(6)如果在多元回归中,根据通常的t检验,全部偏回归系数分别都是统计上不显著的,你就不会得到一个高的R2值。
答:错误。
(7)在Y对X2和X3的回归中,假如X3的值很少变化,这就会使Var(β3)增大,极端的情况下,如果全部X3值都相同,Var(β3) 将是无穷大。
答:正确。
(8)如果分析的目的仅仅是预测,则多重共线性是无害的。
答:错误。
练习题:4.3(1)利用eviews分析得到如下数据:Dependent Variable: LNYMethod: Least SquaresDate: 05/09/16 Time: 12:45Sample: 1985 2011Included observations: 27Variable Coefficient Std. Error t-Statistic Prob.C -3.111486 0.463010 -6.720126 0.0000LNGDP 1.338533 0.088610 15.10582 0.0000LNCPI -0.421791 0.233295 -1.807975 0.0832R-squared 0.988051 Mean dependent var 9.484710Adjusted R-squared 0.987055 S.D. dependent var 1.425517S.E. of regression 0.162189 Akaike info criterion -0.695670Sum squared resid 0.631326 Schwarz criterion -0.551689Log likelihood 12.39155 Hannan-Quinn criter. -0.652857F-statistic 992.2583 Durbin-Watson stat 0.522613Prob(F-statistic) 0.000000由上可知,模型为:lnY=1.338533lnGDP t—0.421791lnCPI t—3.111486(2)A.该模型的可决系数为0.988051,修正可决系数为0.987055,两者都很高。
计量经济学庞皓第三版课后答案解析
计量经济学庞皓第三版课后答案解析word文档,精心编排整理,均可修改你的满意,我的安心第二章简单线性回归模型字体如需要请自己调整(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/27/14 Time: 21:00Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C X1R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared residSchwarz criterionLog likelihoodHannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)有上可知,关系式为y=+②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:10Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C X2R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared resid SchwarzcriterionLog likelihoodHannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)由上可知,关系式为y=+③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:14Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C X3R-squaredMean dependent varAdjusted R-squared. dependent var. of regressionAkaike info criterionSum squared residSchwarz criterionLog likelihoodHannan-Quinn criter.F-statisticDurbin-Watson statProb(F-statistic)由上可知,关系式为y=+(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为,说明所建模型整体上对样本数据拟合较好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
资料 第一章 绪论 思考题 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 1.4在计量经济模型中被解释变量和解释变量的作用有什么不同? 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 1.5一个完整的计量经济模型应包括哪些基本要素?你能举一个例子吗? 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。
例如研究消费函数的计量经济模型:uβXαY
其中,Y为居民消费支出,X为居民家庭收入,二者是经济变量;α和β为参数;u是随机误差项。 1.6假如你是中央银行货币政策的研究者,需要你对增加货币供应量促进经济增长提出建议,你将考虑哪些因素?你认为可以怎样运用计量经济学的研究方法? 答:货币政策工具或者说影响货币供应量的因素有再贴现率、公开市场业务操作以及法定准资料
备金率。所以会考虑再贴现率、公开市场业务操作以及法定准备金率。选择这三种因素作为解释变量。货币供应量作为被解释变量。从而建立简单线性回归模型。 1.7计量经济学模型的主要应用领域有哪些? 答:计量经济模型主要可以用于经济结构分析、经济预测、政策评价和检验与发展经济理论。 1.8如果要根据历史经验预测明年中国的粮食产量,你认为应当考虑哪些因素?应当怎样设定计量经济模型? 答:影响中国的粮食产量的因素可以有农业资金投入、农业劳动力、粮食播种面积、受灾面积等。可建立如下多元模型:
uXβXβXβXβY554433221
其中,Y为中国的粮食产量,2X为农业资金投入,3X为农业劳动力,4X为粮食播种面积,5X为受灾面积。
1.9参数和变量的区别是什么?为什么对计量经济模型中的参数通常只能用样本观测值去估计? 答:经济变量反映不同时间、不同空间的表现不同,取值不同,是可以观测的因素。是模型的研究对象或影响因素。经济参数是表现经济变量相互依存程度的、决定经济结构和特征的、相对稳定的因素,通常不能直接观测。 一般来说参数是未知的,又是不可直接观测的。由于随机误差项的存在,参数也不能通过变量值去精确计算。只能通过变量样本观测值选择适当方法去估计。 1.10你能分别举出三个时间序列数据、截面数据、面板数据、虚拟变量数据的实际例子,并分别说明这些数据的来源吗? 答:时间序列数据:中国1981年至2010年国内生产总值,可从中国统计年鉴查得数据。 截面数据:中国2010年各省、区、直辖市的国内生产总值,中国统计年鉴查得数据。 面板数据:中国1981年至2010年各省、区、直辖市的国内生产总值,中国统计年鉴查得数据。 虚拟变量数据:自然灾害状态,1表示该状态发生,0表示该状态不发生。 1.11为什么对已经估计出参数的模型还要进行检验?你能举一个例子说明各种检验的必要性吗? 答:模型中的参数被估计以后,一般说来这样的模型还不能直接加以应用,还需要对其进行检验。首先,在设定模型时,对所研究经济现象规律性的认识可能并不充分,所依据的经济理论对所研究对象也许还不能作出正确的解释和说明。或者经济理论是正确的,但可能我们对问题的认识只是从某些局部出发,或者只是考察了某些特殊的样本,以局部去说明全局的变化规律,可能导致偏差。其次,我们用以估计参数的统计数据或其它信息可能并不十分可靠,或者较多地采用了经济突变时期的数据,不能真实代表所研究的经济关系,或者由于样本太小,所估计参数只是抽样的某种偶然结果。此外,我们所建立的模型、采用的方法、所用的统计数据,都有可能违反计量经济的基本假定,这也可能导出错误的结论。 1.12为什么计量经济模型可以用于政策评价?其前提条件是什么? 答:所谓政策评价,是利用计量经济模型对各种可供选择的政策方案的实施后果进行模拟运算,从而对各种政策方案作出评价。前提是,我们是把计量经济模型当作经济运行的实验室,去模拟所研究的经济体计量经济模型体系,分析整个经济体系对各种假设的政策条件的反映。在实际的政策评价时,经常把模型中的某些变量或参数视为可用政策调整的政策变量,然后分析政策变量的变动对被解释变量的影响。 资料
1.13为什么定义方程式可以用于联立方程组模型,而不宜用于建立单一方程模型? 答:定义关系是指根据定义而表达的恒等式,是由经济理论或客观存在的经济关系决定的恒等关系。国民经济中许多平衡关系都可以建立恒等关系,这样的模型称为定义方程式。在联立方程组模型中经常利用定义方程式。但是,定义方程式的恒等关系中没有随机误差项和需要估计的参数,所以一般不宜用于建立单一方程模型。
第二章 简单线性回归模型 2.1相关分析与回归分析的关系是什么? 答:相关分析与回归分析有密切的关系,它们都是对变量间相关关系的研究,二者可以相互补充。相关分析可以表明变量间相关关系的性质和程度,只有当变量间存在一定程度的相关关系时,进行回归分析才有实际的意义。同时,在进行相关分析时如果要具体确定变量间相关的具体数学形式,又要依赖于回归分析,而且相关分析中相关系数的确定也是建立在回归分析基础上的。 相关分析与回归分析的区别。从研究目的上看,相关分析是用一定的数量指标(相关系数)度量变量间相互联系的方向和程度;回归分析却是要寻求变量间联系的具体数学形式,是要根据解释变量的固定值去估计和预测被解释变量的平均值。从对变量的处理看,相关分析对称地对待相互联系的变量,不考虑二者的因果关系,也就是不区分解释变量和被解释变量,相关的变量不一定具有因果关系,均视为随机变量;回归分析是建立在变量因果关系分析的基础上,研究其中解释变量的变动对被解释变量的具体影响,回归分析中必须明确划分解释变量和被解释变量,对变量的处理是不对称的。 2.2什么是总体回归函数和样本回归函数?它们之间的区别是什么? 答:总体回归函数是将总体被解释变量的条件期望表现为解释变量的函数。样本回归函数是将被解释变量的样本条件均值表示为解释变量的函数。 总体回归函数和样本回归函数之间的区别。首先,总体回归函数虽然未知,但它是确定的;而由于从总体中每次抽样都能获得一个样本,就都可以拟合一条样本回归线,样本回归线是随抽样波动而变化的,可以有很多条。所以样本回归函数还不是总体回归函数,至多只是未知的总体回归函数的近似反映。其次,总体回归函数的参数是确定的常数;而样本回归函数的参数是随抽样而变化的随机变量。 2.3什么是随机扰动项和剩余项(残差)?它们之间的区别是什么?
答:总体回归函数中,被解释变量个别值iY与条件期望)XE(Yi的偏差是随机扰动项iu。
样本回归函数中,被解释变量个别值iY与样本条件均值iYˆ的偏差是残差项ie。残差项ie在概念上类似总体回归函数中的随机扰动项iu,可视为对随机扰动项iu的估计。 总体回归函数中的随机误差项是不可以直接观测的;而样本回归函数中的残差项是只要估计出样本回归的参数就可以计算的数值。 2.4为什么在对参数作最小二乘估计之前,要对模型提出古典假设? 答:在对参数作最小二乘估计之前,要对模型提出古典假设。因为模型中有随机扰动,估计的参数是随机变量,只有对随机扰动的分布作出假定,才能确定所估计参数的分布性质,也才可能进行假设检验和区间估计。只有具备一定的假定条件,所作出的估计才具有较好的统计性质。 2.5总体方差和参数估计方差的区别是什么?