基于SVM的图像分类系统设计文档_成勇
基于SVM算法的分类器设计

对训练样本 的选择 、参 数的影响选择与优化 问题进行 了研 究。 实验 结果表 明 ,在应 用 支持 向量机 算 法做 数据 分类 时, 选择合适 的训 练样 本和参数有利 于提 高分 类器的准确度。
关 键 词 支持 向 量 机 ;L i b s v m 工 具 箱 ;分 类 器 中图 分 类 号 T P 3 9 1 . 4 文 献标 识 码 A 文章编 号 1 0 0 7— 7 8 2 0 ( 2 0 1 5 ) 0 4— 0 2 3一 o 4
到全 局 最优 化 , 并 在整 个 样 本 空 间 的期 望 风 险 以某 个 概 率满 足一定 上 界 。 1 . 2 原理 简介
小样 本 、 非线 性 、 高维 和局 部极 小等 问题 , 在 模 式识 别 、 回归 估计 , 分 类 等 领 域 都得 到 了 广 泛 应 用 I 2 ] 。支 持 向量 机方 法又 称 为 核 方 法 , 这 是 因为 核 的 展 开 和计 算
De s i g n o f a Cl a s s i ie f r Ba s e d o n t h e S VM Al g o r i t hm
W EI Ao
( S c h o o l o f E l e c t r o n i c E n g i n e e i r n g ,Xi d i a n Un i v e r s i t y ,X i ’ a n 7 1 0 0 7 1 ,C h i n a )
Ab s t r a c t 卟e b a s i c i d e a o f t h e S u p p o  ̄Ve c t o r Ma c h i n e ( S VM)a l g o i r t h m a n d t h e c o n c e p t o f d a t a c l a s s i f i c a t i o n
基于 SVM 分类器和 HOG 的模式识别系统的设计与实现代码大全
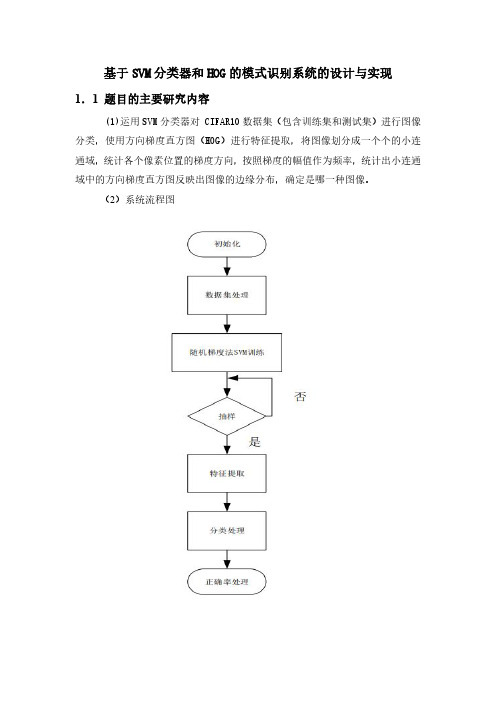
基于SVM分类器和HOG的模式识别系统的设计与实现1.1题目的主要研究内容(1)运用SVM分类器对CIFAR10数据集(包含训练集和测试集)进行图像分类,使用方向梯度直方图(HOG)进行特征提取,将图像划分成一个个的小连通域,统计各个像素位置的梯度方向,按照梯度的幅值作为频率,统计出小连通域中的方向梯度直方图反映出图像的边缘分布,确定是哪一种图像。
(2)系统流程图1.2题目研究的工作基础或实验条件(1)硬件环境:笔记本电脑一台(2)软件环境:PyCharm1.3数据集描述(1)CIFAR10数据集:包含50000张训练集图片(data_batch_1~data_batch_5各10000张),10000张测试集图片(test_batch中),每张图片分别属于10个类别中的1个。
要求在训练集上对分类器进行训练,在测试集上检验分类器的正确率。
1.4特征提取过程描述(1)提取思想:图像的内容应该通过图像的形状来得到更好的反应,而图像局部目标的表象和形状能够被梯度或边缘的方向密度分布很好地描述。
因此希望能够利用CIFAR10数据集中各个图像的边缘信息来估计反映事物的轮廓,从而作为判断图像类别的主要依据。
本质是统计图像中各个位置的梯度信息。
(2)实现方法:将图像划分成一个个的小连通域,在每个小连通域中统计各个像素位置的梯度方向,按照梯度的幅值作为频率,统计出小连通域中的方向梯度直方图。
之后由小连通域的方向梯度直方图信息逐渐合并出较大范围内的连通区域的方向梯度直方图,从而得到整张图像的方向梯度直方图信息,反映出图像的总体边缘分布。
(3)具体步骤1以CIFAR10数据集中32*32的RGB图像为例,首先将彩色图像转化为灰度图像,便于之后求解各个像素位置的梯度信息。
2对于每个像素位置,通过如下方法计算水平和方向上的(灰度值)梯度:其中代表水平方向上的梯度,代表垂直方向上的梯度,代表对应像素的灰度值。
由此可以计算出对应像素位置处的梯度幅值和梯度方向分别为:③将图像进行划分,每8*8个像素为一个单元(cell),且单元为无重叠平铺;每2*2个单元为一个块(block),且块为步长为1的有重叠平铺,如下图所示:每个红框代表一个cell每个蓝框蓝标一个block,以上示意步长为1的可重叠蓝框可能分布情况④对于②中得到的梯度幅值和梯度方向数据,首先按照cell为单位统计方向梯度直方图。
基于SVM的图像型火灾探测系统

2 0 1 3 年第0 4 期
C o m p u t e r C D S o f t w a r e a n d A p p l i c a t i o n s
…
本刊约稿
进 行 分类 ,T 为阈值 。满 足 上式 的则 为背景 像素 ,而 其他分量就被看做前景。则通过此步骤后, 移 动区域被分
割 出来 。 2 .ห้องสมุดไป่ตู้1 . 2 图像分割
利用 混 合高 斯方 法分 割之 后 ,将 移动 区域 分 割 出来 ,’ 但 是 并不是所 有 的移 动区域 都是 火焰 , 如植物 叶子 的晃 动 , 摄 像机 的 微小移 动 都会 被分 割 出来 ,但 是这 些都 是没 有意 义 的 ,所 以对 这些 较容 易分 辨 的 区域要 进行排 除,本 文 中 主要 利用 火焰像 素 的 阈值 对候选 区域 进行 排 除 。 利用 R G B 色彩 空 间 中 ,火 焰像 素 各个分 量 的范 围进 行初 步排 除 ,经 图3 B / S 架构 火 灾探 测系统 功 能 过大 量 实验数 据 发现 其 中 R 的范 围 为 ’ 1 9 0 - - , 2 5 5 ;G 的范 用 户通 过浏 览器 登 录到 视频 服务 器后 ,服 务器 端会 发 围是 1 1 3  ̄ 2 5 5 ; B 的范 围为 0 - 8 0 t 。经过 阈值排 除后 , 会 将 来 A c t i v e 控件 , 用 户成 功安装 后 , 就可直 接监 控现 场数据 , 较容易分辨的干扰物排除,为之后的 S V M 分类减少工作 并使 用其 它 功能 。如果 前 方有 火情 发生 时 ,服务 器端 会 发 量。 . 出火 警信 号 ,客 户端接 收 到之 后 ,会在 客户 端报 警提 示 , 2 . 2 火灾 判定 如果 用户 没有 点 击消警 ,则会 ~直 提 示 ,直到有 人 反应 , 经 过 阈值 排 除后 , 得 到更有 可 能性 的火 灾疑 似 图像 , 能较 好 的完成 无人值 守 时火 灾的 自动报警 任 务 。 但是还需要经过判断,本文采用 的是基于 S V M( 支持向量 3 结束语 机 )分类 方法 ,提 取疑似 火灾 图像 的面 积变化 率 、圆形 度 、 本文 设计 了一种 网络 型 的火灾 探测 系 统 ,在火 灾 识别 闪烁 频 率等 ,作 为支 持 向量机 的输 入参 数 。要 使用 好支 持 算 法 中使用 高 斯混 合模 型和 支持 向量 机 等方法 进 行 判断 , 向量机 ,核 函数 起 到很 大 的作用 ,核 函 数越适 合 ,分类 效 能较好的分割移动区域 , 经过阈值判断排除不可能区域后,
基于SVM的图像分类

基于SVM的图像分类
胡斌斌;姚明海
【期刊名称】《微计算机信息》
【年(卷),期】2010(026)001
【摘要】现有的图像检索系统多是针对底层特征的系统,而人类往往习惯于在语义级别进行相似性判别.如何跨越底层特征和高层语义之间的"鸿沟",成为基于内容检索的研究重点.本文提出一种利用SVM提取图像的高层特征,然后对图像进行语义级别的分类.实验结果表明,该方法在一定程度上跨越"语义鸿沟".
【总页数】3页(P115-116,156)
【作者】胡斌斌;姚明海
【作者单位】310014,杭州,浙江工业大学信息学院;310014,杭州,浙江工业大学信息学院
【正文语种】中文
【中图分类】TP391
【相关文献】
1.基于特征选择和SVMs的图像分类 [J], 高永岗;周明全;耿国华;刘燕武
2.基于HOG和SVM的船舶图像分类算法 [J], 吴映铮;杨柳涛
3.VTSRM:一种基于SVM-RFE和MRMR的AD MRI医学图像分类方法 [J], 周琼;陈梅;李晖;戴震宇
4.基于LBP与LSSVM的数字图像分类算法 [J], 张艮山; 田建恩; 张哲
5.基于SVM的高通量dPCR基因芯片荧光图像分类研究 [J], 刘丽;孙刘杰;王文举
因版权原因,仅展示原文概要,查看原文内容请购买。
基于SVM的遥感图像自动分类研究

纹理特征 , 然后采用人工蜂群算 法对特征进行选择和优化 , 最后采用支持 向量机对优化特征进行训练 , 建立遥感 图像 自动分 类模型 。仿真结果表明 , A B C— S V M克服了传统组合特征算法的缺陷 , 提高了遥感 图像分类 准确率 , 加快分类 速度 , 可以满
f e a t u r e s .F i n ll a y ,t h e o p t i mi z e d f e a t u r e s w e r e i n p u t t o s u p p o t r v e c t o r ma c h i n e t o l e a r n b u i l d i n g r e mo t e i ma g e a u t o ma t - i c c l a s s i i f c a t i o n mo d e 1 .T h e s i mu l a t i o n r e s u h s s h o w t h a t AB C —S VM c a n o v e r c o me t h e t r a d i t i o n l a lg a o i r t h m ,i mp r o v e
第3 O 卷 第 6 期
文章编号 : 1 0 0 6—9 3 4 8 ( 2 0 1 3 ) 0 6— 0 3 7 8— 0 4
计
算
机仿Βιβλιοθήκη 真 2 0 1 3 年6 月
基于 S V M 的遥 感 图像 自动 分 类 研 究
王养廷
( 华北科技学院计算机学院, 河北 廊坊 0 6 5 2 0 1 ) 摘 要: 遥感 图像具有信息大 、 灰度级 大等特点 , 传统简单组合特征出现特征冗余 、 维数高等缺陷 , 造成图像分类精度差。为提
基于支持向量机的图像分类算法研究

基于支持向量机的图像分类算法研究近年来,随着计算机技术和人工智能技术的不断发展,在图像处理领域中,图像分类技术显得越来越重要。
随着人们对图像识别、目标检测等方面的需求增加,如何进行高效准确的图像分类已经成为了一个热门研究课题。
本文主要围绕基于支持向量机(SVM)的图像分类算法这一研究课题展开讨论。
首先介绍SVM算法的基本原理,然后讨论SVM算法在图像分类方面的应用,最后通过实验验证SVM算法在图像分类中的有效性。
一、SVM算法基本原理SVM算法是一种机器学习算法,主要用于进行监督式学习。
其基本思想是找到一个最优超平面,把不同类别的数据分割开来,从而实现分类。
在SVM算法中,超平面可以看作是一个决策边界,用来对不同类别的数据进行分类。
SVM算法的关键在于如何选择最优超平面。
具体来说,最优超平面应该满足将两类数据间的间隔最大化。
这个间隔可以看作是一个函数,通常称为目标函数。
通过优化目标函数,可以找到最优超平面。
在实际实现中,目标函数通常被表示成二次规划问题。
SVM算法的核心就是使用核函数将数据从低维空间转换到高维空间,从而使得数据线性可分。
SVM算法的核函数通常包括线性核函数、多项式核函数、径向基函数等。
不同的核函数决定了SVM算法的性能和分类效果。
二、SVM算法在图像分类中的应用SVM算法在图像分类领域中被广泛应用。
其主要应用方式是将图像转换为特征向量,然后利用SVM算法对特征向量进行分类。
具体来说,SVM算法将一张图像作为一个样本点,将图像中各种特征作为样本点的属性,然后将这些属性用向量来表示。
这些向量被称作特征向量,由此将图像转换为了一个向量空间。
在图像分类中,提取有效的特征向量是非常关键的。
不同的图像分类问题通常需要不同的特征向量。
常见的特征向量包括颜色特征、纹理特征、形状特征等。
在实际应用中,需要根据具体问题选择合适的特征向量。
SVM算法在图像分类中的应用还包括以下两个方面。
第一,SVM算法可以实现非线性分类,这在图像分类中非常重要。
基于 CNN-SVM-GA 的图像分类系统的设计与实现代码大全
基于CNN-SVM-GA的图像分类系统的设计与实现1.1题目的主要研究内容(1)工作的主要描述使用CNN-SVM-GA遗传算法对图像进行分类。
对图像数据集进行数据预处理,并将数据集分为CIFAR-10数据集训练集和测试集;建立卷积神经网络模型,用第一步的训练集和测试集对此模型进行训练;提取训练好的模型全连接层前的所有层构成一个新的模型,此模型输出的是一个特征向量;对提取出的特征向量进行PCA特征降维,减少SVM的训练时间,形成新的训练集和测试集去训练SVM模型,用遗传算法优化支持向量机的g和c参数。
(2)系统流程图图11.2题目研究的工作基础或实验条件(1)硬件环境(MacBook Pro)(2)软件环境(pycharm,python3.9)1.3理论基础(1)卷积神经网络(CNN)卷积神经网络(CNN)是典型的前馈神经网络,由输入层,隐藏层和输出层组成。
隐藏层由卷积层,池化层和全连接层组成。
卷积模拟单个神经元对视觉刺激的反应。
它使用卷积层卷积输入数据,然后将结果传输到下一层。
卷积层由一组卷积核组成。
尽管这些内核具有较小的感知视野,但是内核延伸到输入数据的整个深度。
卷积运算可以提取输入数据的深层特征。
卷积神经网络通过卷积、池化等操作可以实现特征的自动提取,再通过全连接层实现分类。
卷积神经网络的结构:一般地,卷积神经网络由输入层、卷积层、RELU层、池化层和全连接层构成,通过梯度下降的方式训练网络模型的参数,从而实现分类。
下面将对每类层进行介绍。
卷积层。
卷积神经网络的核心功能(特征提取)由卷积层完成。
卷积层由许多可学习的卷积核(滤波器)构成,滤波器按照一定的步长对输入的张量进行遍历,当遇到某些类型的形状特征时就激活。
池化层。
池化层又可称为下采样层,通过池化操作可以减少特征图的参数量,减少运算量。
池化层对每个通道的特征图进行操作,不改变通道数,但减少每个通道的特征图的大小。
常用的池化操作有均值池化和最大池化。
基于HOG+SVM的图像分类系统的设计与实现
夺 ・ 夺 ・ 夺 ・ ÷ ・ ・ 夺 ・ 夺 ・ ( }・ ・ 夺 ・ 夺 ・ 夺 ・ ÷ ・ ・ ・ ・ 牵 ・ 夺 ・ 夺 ・ 夺 ・ 夺 ・ 夺 ・ 夺 ・ 夺 ・ ・ ・ 夺 ・ 夺 ・ 夺 - ・ ・ 夺 ・ 夺 ・ 夺 - 夺 ・ ÷ ・ 夺 ・ 夺 ・ ・ 毒 ・ 夺 ・ 夺 ・ 夺 - 夺 - ・ ÷ ・
姜 经纬 , 程传蕊
( 1 . 沈 阳航 空航 天大 学,辽宁 沈 阳 1 1 0 0 0 0 ; 2 . 漯河职业技 术学院 , 河 南 漯河 4 6 2 0 0 0 )
摘
要: 图像分 类在 工业 、 医疗、 勘测 、 驾驶等领域 都有较 高的 实用价值 , 通 过分析 图像 分 类技 术 , 采 用软件 工
作者简介 : 姜 经纬( 1 9 9 4一) , 男, 河 南漯 河人 , 在读本科生 , 主要从 事 图像识 别分类 方面的 学 习与研 究 ; 程 传蕊 ( 1 9 7 0一) , 女, 河 南漯河人 , 教授 , 主要从 事算法研 究。
第 2期
姜 经纬, 等: 基于 H O G+S V M 的图像 分类 系统的设计与 实现
Vo 1 . 1 6 No. 2 Ma r c h 2 01 7
2 0 1 7年 3月
d o i : 1 0 . 3 9 6 9 / j . i s s n . 1 6 7 1 —7 8 6 4 . 2 0 1 7 . 0 2 . 0 1 3
基于 H O G+S V M 的 图像 分 类 系统 的设 计 与 实现
基于SVM模式识别系统的设计与实现代码大全
基于SVM模式识别系统的设计与实现1.1 主要研究内容(1)现有的手写识别系统普遍采用k近邻分类器,在2000个数字中,每个数字大约有200个样本,但实际使用这个算法时,算法的执行效率并不高,因为算法需要为每个测试向量做2000次距离计算,每个距离计算包括了1024个维度浮点运算,总计要执行900次,此外需要保留所有的训练样本,还需要为测试向量准备2MB的存储空间。
因此我们要做的是在其性能不变的同时,使用更少的内存。
所以考虑使用支持向量机来代替kNN方法,对于支持向量机而言,其需要保留的样本少了很多,因为结果只是保留了支持向量的那些点,但是能获得更快更满意的效果。
(2)系统流程图step1. 收集数据(提供数字图片)step2. 处理数据(将带有数字的图片二值化)step3. 基于二值图像构造向量step4. 训练算法采用径向基核函数运行SMO算法step5. 测试算法(编写函数测试不同参数)1.2 题目研究的工作基础或实验条件(1)荣耀MagicBook笔记本(2)Linux ubuntu 18.6操作系统pycharm 2021 python31.3 数据集描述数据集为trainingDigits和testDigits,trainingDigits包含了大约2000个数字图片,每个数字图片有200个样本;testDigits包含了大约900个测试数据。
1.4 特征提取过程描述将数字图片进行二值化特征提取,为了使用SVM分类器,必须将图像格式化处理为一个向量,将把32×32的二进制图像转换为1×1024的向量,使得SVM可以处理图像信息。
得到处理后的图片如图所示:图1 二值化后的图片编写函数img2vector ,将图像转换为向量:该函数创建1x1024的NumPy 数组,然后打开给定的文件,循环读出文件的前32行,并将每行的头32个字符值存储在 NumPy 数组中,最后返回数组,代码如图2所示:图2 处理数组1.5 分类过程描述 1.5.1 寻找最大间隔寻找最大间隔,就要找到一个点到分割超平面的距离,就必须要算出点到分隔面的法线或垂线的长度。
人工智能学习笔记实验五python实现SVM分类器的设计与应用
⼈⼯智能学习笔记实验五python实现SVM分类器的设计与应⽤学习来源实验原理有关svm原理 请移步该篇通俗易懂的博客下图 或许可以简单概括svm功能与原理有关深究svm原理 请移步该篇通俗易懂的博客或者评论我获取svm学习ppt实验内容1. 数据库的选择可选取 ORL ⼈脸数据库作为实验样本,总共 40 个⼈,每⼈ 10 幅图像,图像⼤⼩为112*92 像素。
图像本⾝已经经过处理,不需要进⾏归⼀化和校准等⼯作。
实验样本分为训练样本和测试样本。
⾸先设置训练样本集,选择 40 个⼈前 5 张图⽚作为训练样本,进⾏训练。
然后设置测试样本集,将 40 个⼈后 5 张图⽚作为测试样本,进⾏选取识别。
2. 实验基本步骤⼈脸识别算法步骤概述:a) 读取训练数据集;若 flag=0,表述读取原⽂件的前五幅图作为训练数据,若 flag=1,表述读取原⽂件的后五幅图作为测试数据,数据存⼊ f_matrix 中,每⼀⾏为⼀个⽂件,每⾏为 112*92列。
参见:ReadFace.mb) 主成分分析法降维并去除数据之间的相关性;参见:fastPCA.mc) 数据规格化;参见 scaling.md) SVM 训练(选取径向基和函数)得到分类函数;参见:multiSVMtrain.me) 读取测试数据、降维、规格化;参见:multiSVM.mf) ⽤步骤 d 产⽣的分类函数进⾏分类(多分类问题,采⽤⼀对⼀投票策略,归位得票最多的⼀类);参见:main.mg) 计算正确率。
以上只是matlib做法⽽我会使⽤python做法3. 实验要求1) 分别使⽤ PCA 降维到 20,50,100,200,然后训练分类器,对⽐分类结果,画出对⽐曲线;2) 变换 SVM 的 kernel 函数,如分别使⽤径向基函数和多项式核函数训练分类器,对⽐分类结果,画出对⽐曲线;3) 使⽤交叉验证⽅法,变换训练集及测试集,分析分类结果。
实验步骤⼀、分别使⽤ PCA 降维到 20,50,100,200,然后训练分类器,对⽐分类结果,画出对⽐曲线;1.数据处理def get_data(x,y):file_path='./ORL/' #设置⽂件路径(这⾥为当前⽬录下的ORL⽂件夹)train_set = np.zeros(shape=[1,112*92]) #train_set⽤于获取的数据集train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型target=[] #标签列表for i in range(1,41): #i⽤于遍历ORL⽂件夹中的40个⽂件夹for j in range(x,y): #j⽤于遍历每个⽂件夹的对应的x到y-1的图⽚target.append(i) #读⼊标签(图⽚⽂件夹中的⼈脸是同⼀个⼈的)img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\cv2.IMREAD_GRAYSCALE) #读取图⽚,第⼆个参数表⽰以灰度图像读⼊img=img.reshape(1,img.shape[0]*img.shape[1]) #将读⼊的图⽚数据转换成⼀维img=pd.DataFrame(img) #将⼀维的图⽚数据转成DataFrame类型train_set=pd.concat([train_set,img],axis=0)#按⾏拼接DataFrame矩阵train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的⾏索引train_set.drop(labels=0,axis=0,inplace=True) #删除⾏索引为0的⾏(删除第⼀⾏)target=pd.DataFrame(target) #将标签列表转成DataFrame类型return train_set,target #返回数据集和标签2.数据标准化+PCA降维+⾃动def face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test):#2、数据标准化标准差标准化stdScaler = StandardScaler().fit(face_data_train)face_trainStd = stdScaler.transform(face_data_train)face_testStd = stdScaler.transform(face_data_test)#dimension=[3,5,10,20,50,100,200]dimension=[20,50,100,200]'''dimension=[]for i in range(1,40):dimension.append(i*5)'''accuracy=[]for i in dimension:#3、PCA降维pca = PCA(n_components=i).fit(face_trainStd)face_trainPca = pca.transform(face_trainStd)face_testPca = pca.transform(face_testStd)#4、建⽴SVM模型默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly'#svm = SVC().fit(face_trainPca,face_target_train)svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)#5、预测训练集结果face_target_pred = svm.predict(face_testPca)#6、分析预测结果true=0for i in range(0,200):if face_target_pred[i] == face_target_test[i]:true+=1accuracy.append(true/face_target_test.shape[0])print(accuracy)plt.plot(dimension,accuracy,"b-")plt.legend(['默认径向基核函数kernel=\'rbf\'','多项式核函数kernel=\'poly\''])plt.show()#draw_chart1(dimension,accuracy)3.总代码import cv2 #opencv库,⽤于读取图⽚等操作import numpy as npimport pandas as pdfrom sklearn.preprocessing import StandardScaler #标准差标准化from sklearn.svm import SVC #svm包中SVC⽤于分类from sklearn.decomposition import PCA #特征分解模块的PCA⽤于降维import matplotlib.pyplot as plt #⽤于绘制图形def get_data(x,y):file_path='./ORL/' #设置⽂件路径(这⾥为当前⽬录下的ORL⽂件夹)train_set = np.zeros(shape=[1,112*92]) #train_set⽤于获取的数据集train_set = pd.DataFrame(train_set) #将train_set转换成DataFrame类型target=[] #标签列表for i in range(1,41): #i⽤于遍历ORL⽂件夹中的40个⽂件夹for j in range(x,y): #j⽤于遍历每个⽂件夹的对应的x到y-1的图⽚target.append(i) #读⼊标签(图⽚⽂件夹中的⼈脸是同⼀个⼈的)img = cv2.imread(file_path+'s'+str(i)+'/'+str(j)+'.bmp',\cv2.IMREAD_GRAYSCALE) #读取图⽚,第⼆个参数表⽰以灰度图像读⼊img=img.reshape(1,img.shape[0]*img.shape[1]) #将读⼊的图⽚数据转换成⼀维 img=pd.DataFrame(img) #将⼀维的图⽚数据转成DataFrame类型train_set=pd.concat([train_set,img],axis=0)#按⾏拼接DataFrame矩阵train_set.index=list(range(0,train_set.shape[0])) #设置 train_set的⾏索引train_set.drop(labels=0,axis=0,inplace=True) #删除⾏索引为0的⾏(删除第⼀⾏) target=pd.DataFrame(target) #将标签列表转成DataFrame类型return train_set,target #返回数据集和标签return train_set,target #返回数据集和标签def draw_chart(dimension,accuracy):plt.rcParams['font.sans-serif']='SimHei'plt.figure(figsize=(6,6))plt.plot(dimension,accuracy,"r-")plt.xlabel('PCA降维的维度')plt.ylabel('⼈脸识别准确率')plt.title('linear不同维度差异')#plt.savefig("./tmp/采⽤默认径向基核函数kernel=\'rbf\' 先降维后标准化.png")plt.show()def draw_chart1(dimension,accuracy):plt.rcParams['font.sans-serif']='SimHei'plt.figure(figsize=(6,6))plt.plot(dimension,accuracy,"r-")plt.xlabel('PCA降维的维度')plt.ylabel('⼈脸识别准确率')plt.title('poly不同维度差异')#plt.savefig("./tmp/采⽤默认径向基核函数kernel=\'rbf\' 先降维后标准化.png")plt.show()def face_fuc(face_data_train,face_target_train,face_data_test,face_target_test): #2、数据标准化标准差标准化stdScaler = StandardScaler().fit(face_data_train)face_trainStd = stdScaler.transform(face_data_train)face_testStd = stdScaler.transform(face_data_test)#dimension=[3,5,10,20,50,100,200]dimension=[20,50,100,200]'''dimension=[]for i in range(1,40):dimension.append(i*5)'''accuracy=[]for i in dimension:#3、PCA降维pca = PCA(n_components=i).fit(face_trainStd)face_trainPca = pca.transform(face_trainStd)face_testPca = pca.transform(face_testStd)#4、建⽴SVM模型默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly' svm = SVC(kernel='linear').fit(face_trainPca,face_target_train)#svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)#5、预测训练集结果face_target_pred = svm.predict(face_testPca)#6、分析预测结果true=0for i in range(0,200):if face_target_pred[i] == face_target_test[i]:true+=1accuracy.append(true/face_target_test.shape[0])print(accuracy)draw_chart(dimension,accuracy)def face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test): #2、数据标准化标准差标准化stdScaler = StandardScaler().fit(face_data_train)face_trainStd = stdScaler.transform(face_data_train)face_testStd = stdScaler.transform(face_data_test)#dimension=[3,5,10,20,50,100,200]dimension=[20,50,100,200]'''dimension=[]for i in range(1,40):dimension.append(i*5)'''accuracy=[]for i in dimension:#3、PCA降维pca = PCA(n_components=i).fit(face_trainStd)face_trainPca = pca.transform(face_trainStd)face_testPca = pca.transform(face_testStd)#4、建⽴SVM模型默认为径向基核函数kernel='rbf' 多项式核函数kernel='poly' #svm = SVC().fit(face_trainPca,face_target_train)svm = SVC(kernel='poly').fit(face_trainPca,face_target_train)#5、预测训练集结果face_target_pred = svm.predict(face_testPca)#6、分析预测结果true=0for i in range(0,200):if face_target_pred[i] == face_target_test[i]:true+=1accuracy.append(true/face_target_test.shape[0])print(accuracy)plt.plot(dimension,accuracy,"b-")plt.legend(['默认径向基核函数kernel=\'rbf\'','多项式核函数kernel=\'poly\''])plt.show()#draw_chart1(dimension,accuracy)if __name__ == '__main__':#1、获取数据face_data_train,face_target_train=get_data(1,6) #读取前五张图⽚为训练集face_data_test,face_target_test=get_data(6,11) #读取后五张图⽚为测试集face_target_test=face_target_test.values #将DataFrame类型转成ndarrayl类型 # face_fuc(face_data_train,face_target_train,face_data_test,face_target_test) face_fuc1(face_data_train,face_target_train,face_data_test,face_target_test)4.处理结果⼆、变换 SVM 的 kernel 函数,如分别使⽤径向基函数和多项式核函数训练分类器,对⽐分类结果,画出对⽐曲线。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
. - - . 可修编- LANZHOU UNIVERSITY OF TECHNOLOGY 毕业设计
题 目 基于SVM的图象分类系统 学生 成勇 学 号 10240330 专业班级 计算机科学与技术3班 指导教师 晓旭 学 院 计算机与通信学院 辩论日期- -
. . word.zl 摘 要
支持向量机(SVM)方法是建立在统计学习理论根底之上的,克制了神经网络分类和传统统计分类方法的许多缺点,具有较高的泛化性能。但是,由于支持向量机尚处在开展阶段,很多方面尚不完善,现有成果多局限于理论分析,而应用显得较薄弱,因此研究和完善利用支持向量机进展图像分类对进一步推进支持向量机在图像分析领域的应用具有积极的推动作用。 本文通过支持向量机技术和图像特征提取技术实现了一个图像分类实验系统。文中首先引入了支持向量机概念,对支持向量机做了较全面的介绍;然后,讨论了图像特征的描述和提取方法,对图像的颜色矩特征做了详细的描述,对svm分类也做了详细的说明;最后讨论了由分类结果所表现的一些问题。测试结果说明,利用图像颜色矩特征的分类方法是可行的,并且推断出采用综合特征方法比采用单一特征方法进展分类得到的结果要更令人满意。
关键词:支持向量机 图像分类 特征提取 颜色矩
Abstract The support vector machine (SVM) method is based on statistical learning theory - -
. . word.zl foundation, overe the neural network classification and traditional statistical classification
method of faults, and has high generalization performance. But, because the support vector machine (SVM) is still in the development stage, many still not perfect, the existing results more limited to the theoretical analysis, and the use of appear more weak and therefore study and improve the use of support vector machines to image classification support vector machine to further advance in the application of image analysis play a positive role in promoting. In this paper, support vector machine (SVM) technology and image feature extraction technology implements a image classification experiment system. This paper first introduces the concept of support vector machine (SVM), the support vector machine (SVM) made a more prehensive introduction; Then, discussed the image characteristics of description and extraction method, the image color moment features described in detail, also made detailed instructions for the SVM classification; Finally discussed the classification results of some problems. Test results show that using the torque characteristics of the image color classification method is feasible, and deduce the prehensive characteristic method than using single feature method to classify the results are more satisfactory. Keywords:supportvectormachine image classification feature extractionColor Moment - -
. . word.zl 目 录
摘要I AbstractI 第一章前言1 1.1本课题的研究意义1 1.2本论文的目的、容1 1.3开发技术介绍1 1.3.1 SVM技术及其开展简史1 1.3.2 java技术简介2 第二章系统分析3 2.1 系统需求分析3 2.2 系统业务流程分析3 第三章系统总体设计4 3.1 分类系统的构造4 3.2 图像数据库4 3.3 特征提取模块4 3.4 svm分类模块4 第四章系统详细设计6 4.1 特征提取模块6 4.1.1 颜色矩6 4.2 SVM分类模块7 4.2.1 svm的算法简介7 4.2.2 svm的核函数选择8 4.2.3 svm的核函数8 4.2.4 svmtrain的用法8 4.2.5 svmpredict的用法9 第五章系统测试10 5.1 图像数据10 - -
. . word.zl 5.2 提取颜色矩特征10
5.3 svm分类11 5.4 测试结果分析12 第六章软件使用说明书14 设计总结16 参考文献17 外文翻译18 原文18 Abstract18 1 Introduction18 2 Support vector machines19 3 Co-SVM19 3.1 Two-view scheme19 3.2 Multi-view scheme20 3.3 About SVM20 4 Related works23 译文23 摘要23 1 前言23 2 支持向量机24 3 合作支持向量机25 3.1 双试图方案25 3.2 多视图方案25 3.3 SVM 简介25 4 相关作品27 致28 - -
. . word.zl 第一章 前言
1.1本课题的研究意义 随着信息社会的到来,人们越来越多的接触到大量的图像信息。每天都有大量的图像信息在不断的产生(如卫星、地质、医疗、平安等领域),这些图像信息的有效组织和快速准确的分类便成了人们亟待解决的课题。图像分类就是利用计算机对图像进展定量分析,把图像中的每个像元或区域划归为假设干类别中的一种,以代替人的视觉判读,图像分类的过程就是模式识别过程,是目视判读的延续和开展。是工业和学术界的热点问题。 本文提出了一种利用支持向量机(SupportVector Machine,简称SVM)的图像分类方法。该系统可用于各类图像的分类,给定某类图像的训练数据,可以学习分类规那么。对于给定的新图像,即能输出图像的类别。
1.2本论文的目的、容 首先应该指出的是,在某些方面,SVM同神经网络的研究方法是可以相互借鉴的。正如在对神经网络的研究一样,人们在SVM的研究方面不能抱有矛盾的梦想,一方面想使其功能强大无比,任何情况下都具有极高的泛化能力;另一方面,又要求SVM具有良好的性能,例如全局收敛且收敛速度快。这显然是不现实的,它应该是人们不断为之奋斗的目标。因此在SVM的研究方面必须有所侧重,本文在SVM的研究中偏向于它的性能和应用性,即要求保证全局最优的根底上,尽量提高收敛速度,使其在图像分析中发挥很好的作用:而对SVM的容量控制等理论问题,本文暂不过多涉及。 本文对以下问题做了研究: 1。分析SVM模型中核函数的特性,探讨核函数与SVM分类器性能的关系,为下面的研究做铺垫。 2.利用上述的分析,研究了图像的特征对SVM分类器的影响,主要利用了颜色特征和纹理特征,分别对颜色图像分类、纹理图像分类以及综合特征的图像分类进展了比拟,并在Pc机上进展大量的实验,对实验数据进展比照和分析。
1.3开发技术介绍 1.3.1SVM技术及其开展简史 SVM是支持向量机(SupportVector Machine)的简称,是在统计学习理论根底上开展起来的一种机器学习方法。早在六十年代,SVM的奠基人V.Vapink就开场了统计学习理论的研究。 1971年,V.Vapink和Chervonenkis在“The Necessary and Sufficient Conditions for the Unifoms Convergence of Averages to Expected values,一文中,提出了SVM的一个重要的