oracle表分区
postgresql和oracle表分区对比
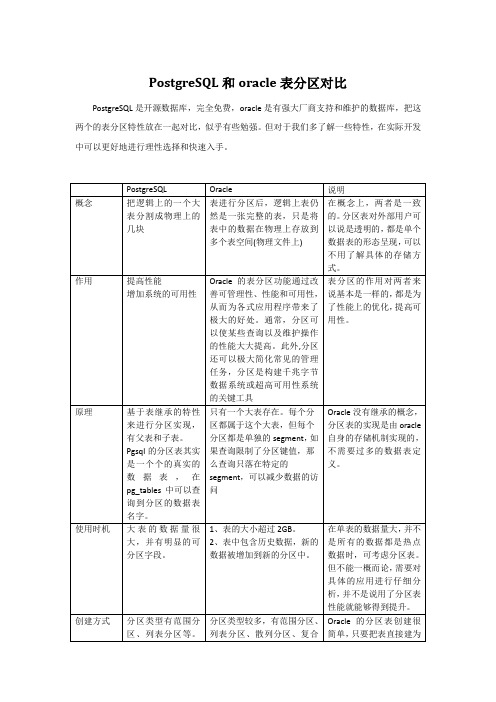
PostgreSQL和oracle表分区对比PostgreSQL是开源数据库,完全免费,oracle是有强大厂商支持和维护的数据库,把这两个的表分区特性放在一起对比,似乎有些勉强。
但对于我们多了解一些特性,在实际开发中可以更好地进行理性选择和快速入手。
总结,数据库的表分区特性优点很多,比如:1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
5、将很少用的数据可以移动到便宜的、慢一些地存储介质上。
这两种数据库的分区表都具有这些优点。
对比来说,Oracle的分区创建和管理更加方便,很多工作是由oracle的内部机制来实现的。
postgreSQL的分区表其实是一个个实际存在的数据表,分区的创建和管理都需要我们用语言来控制,增加了应用人员的工作量。
但,由于oracle自身的“侵占式”硬盘存储,对过期数据进行清除时,即便是drop分区表,也不能直接释放硬盘空间,属于“占了就占了”,这个管理起来就比较麻烦,除非对每个分区表都建立各个独立的tablespace,放在独立的物理文件上,删除过期分区表时,可以同时drop tablespace including contents。
而postgreSQL在truncate 分区表时,可以直接释放硬盘,会看到硬盘使用率下降了,这一点对硬盘资源紧张时,就非常好了。
两种数据库的分区表使用,各有利弊,但总的来说,比较偏向postgreSQL,毕竟硬盘有限。
而且,oracle收费。
Ps,在数据量很大时,任何关系型数据库都有性能上的瓶颈,不属于我们这两种数据库分区表对比的范围了。
以上,是一些使用中的总结,还请达人们指教:)。
Oracle 分区索引和全局索引

Oracle 分区索引和全局索引对于分区表而言,每个表分区对应一个分区段。
当在分区表上建立索引时,即可以建立全局索引,也可以建立分区索引。
对于合局索引,其索引数据会存放在一个索引段中;而对于分区索引,则索引数据都会被存放到几个索引分区段中。
对索引进行分区的目的与对表进行分区是一样的,都是为了更加易于管理和维护巨型对象。
在Oracle中,一共可以为分区表建立三种类型的索引,下面分别介绍它们的特点和适用情况。
1.本地分区索引本地分区索引是为分区表中的各个分区单独地建立分区,各个索引分区之间是相互独立的。
本地分区索引相对比较简单,也比较容易管理。
图10-4显示了本地分区索引和分区表之间的对应关系:分区索引分区表图10-4 本地分区索引与分区表在为分区表创建本地索引后,Oracle会自动对表的分区和索引的分区进行同步处理。
如果为分区表添加新的分区后,Oracle会自动为新分区建立新的索引。
与此相反,如果表的分区依然存在,则用户将不能删除它所对应用的索引分区。
在删除表的分区时,系统会自动删除所对应的索引分区。
例如,下面的语句为范围分区表SALES_RANGE创建本地分区索引:SQL> create index sales_local_idx2 on sales_range(customer_id) local;索引已创建。
2.全局分区索引全局分区索引是对整个分区表建立的索引,然后再由Oracle对索引进行分区。
全局分区索引的各个分区之间不是相互独立的,索引分区与分区表之间也不是简单的一对一关系。
图10-5显示了全局分区索引与分区表的对应关系。
分区索引分区表图10-5 全局分区索引与分区表例如,下面的语句为分区表SALES_LIST创建全局分区索引:SQL> create index sales_global_part_idx2 on sales_list(customer_id)3 global partition by range(customer_id)4 (5 partition part1 values less than(300) tablespace space01,6 partition part2 values less than(maxvalue) tablespace space027 );索引已创建。
Oracle分区表删除分区引发错误ORA-01502:索引或这类索引的分区处于不可用状态
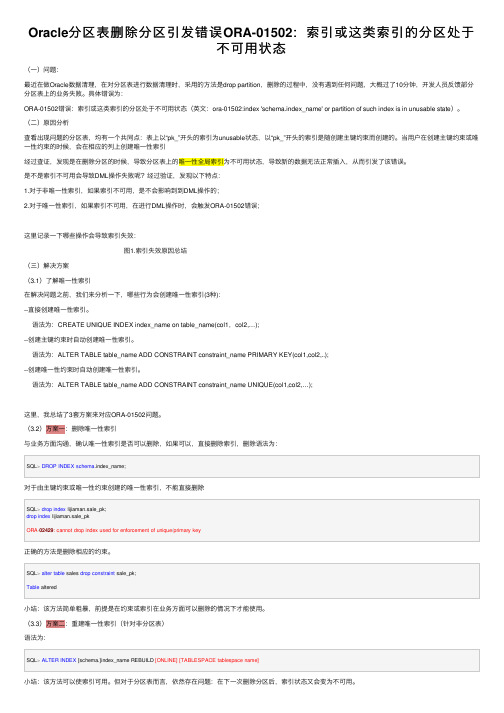
Oracle分区表删除分区引发错误ORA-01502:索引或这类索引的分区处于不可⽤状态(⼀)问题:最近在做Oracle数据清理,在对分区表进⾏数据清理时,采⽤的⽅法是drop partition,删除的过程中,没有遇到任何问题,⼤概过了10分钟,开发⼈员反馈部分分区表上的业务失败。
具体错误为:ORA-01502错误:索引或这类索引的分区处于不可⽤状态(英⽂:ora-01502:index 'schema.index_name' or partition of such index is in unusable state)。
(⼆)原因分析查看出现问题的分区表,均有⼀个共同点:表上以“pk_”开头的索引为unusable状态,以“pk_”开头的索引是随创建主键约束⽽创建的。
当⽤户在创建主键约束或唯⼀性约束的时候,会在相应的列上创建唯⼀性索引经过查证,发现是在删除分区的时候,导致分区表上的唯⼀性全局索引为不可⽤状态,导致新的数据⽆法正常插⼊,从⽽引发了该错误。
是不是索引不可⽤会导致DML操作失败呢?经过验证,发现以下特点:1.对于⾮唯⼀性索引,如果索引不可⽤,是不会影响到到DML操作的;2.对于唯⼀性索引,如果索引不可⽤,在进⾏DML操作时,会触发ORA-01502错误;这⾥记录⼀下哪些操作会导致索引失效:图1.索引失效原因总结(三)解决⽅案(3.1)了解唯⼀性索引在解决问题之前,我们来分析⼀下,哪些⾏为会创建唯⼀性索引(3种):--直接创建唯⼀性索引。
语法为:CREATE UNIQUE INDEX index_name on table_name(col1,col2,…);--创建主键约束时⾃动创建唯⼀性索引。
语法为:ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(col1,col2,..);--创建唯⼀性约束时⾃动创建唯⼀性索引。
Oracle子分区(subpartition)操作

Oracle⼦分区(subpartition)操作要重新定义⼤量分区表。
⾸先看 SQL Reference ⼤致了解了 Oracle 的分区修改操作。
Alter table 语句的alter_table_partitioning ⼦句可以分为以下⼏类:全局:modify_table_default_attrs分区:Modify, Move, Add, Coalesce, Drop, Rename, Truncate, Split, Merge, Exchange⼦分区:Set Template, Modify, Move, Drop, Rename, Truncate, Split, Merge, ExchangeMove: 将分区、⼦分区移动到新的表空间。
Coalesce: 只适⽤于 hash 分区的表。
作⽤是减少⼀个 hash 分区;⽅法是将最后⼀个分区的数据分布到前⾯的分区中,再删除此分区。
Merge: 将两个分区、⼦分区合并为⼀个新分区,并删除两个旧分区。
Merge 可以合并 List 和相邻的 Range 分区,只能合并属于同⼀分区的 List ⼦分区。
Exchange: 交换表分区。
我要做的是添加 List 分区、List ⼦分区、修改⼦分区模板。
1. 添加 List 分区:如果表使⽤ List 分区,且创建了 Default 分区,则此表上⽆法执⾏ Add 分区操作,必须 Split 此表的 Default 分区。
Alter table 语句提供了split_table_partition ⼦句。
此⼦句的功能是创建两个新分区(新建 Segment,可以指定新的物理属性),移动 partition 指定的分区的数据,满⾜ values 条件的放⼊ into 的第⼀个分区,其余的放⼊第⼆个分区,之后原分区。
Oracle 将⾃动 Split Local Index,因此需要重建索引。
下⾯的语句为表 A_CHECKBILL_MONTH 添加了⼀个分区 P_6230000,将原有 P_OTHERS 分区中 COMPANY_ID = 6230000 的数据存储到新分区 P_6230000 ,剩余数据存储到 P_OTHERS。
【Oracle】truncate分区表

no rows selected
The End!
1 row created.
SQL> insert into t_partition_range values (2,'lisi');
1 row created.
SQL> insert intoห้องสมุดไป่ตู้t_partition_range values (3,'wangwu');
1 row created.
2 partition by range(id)( 3 partition t_range_p1 values less than (10), 4 partition t_range_p2 values less than (20), 5 partition t_range_p3 values less than (30), 6 partition t_range_pmax values less than (maxvalue) 7 );
SQL> commit;
Commit complete.
SQL> select * from t_partition_range partition (t_range_p1);
ID NAME ---------- -------------------------------------------------1 zhangsan 2 lisi 3 wangwu
oracle分区表之hash分区表的使用及扩展

oracle分区表之hash分区表的使⽤及扩展Hash分区是通过对分区键运⽤Hash算法从⽽决定数据的分区归属。
使⽤Hash分区有什么优点呢?常⽤的分区表所具有的优点:如提⾼数据可⽤⾏,减少管理负担,改善语句性能等优点,hash分区同样拥有。
此外,由于Hash分区表是按分区键的hash计算结果来决定其分区的,⽽特定的分区键其hash值是固定的,也就是说Hash分区表的数据是按分区键值来聚集的,同样的分区键肯定在同⼀分区。
⽐如,在证券⾏业,我们经常查询某⼀只股票的K线,假设表的结构如下:复制代码代码如下:create table equity(id number,trade_date date,……);Equity表可能会很⼤,对equity表的查询通常都是指定id,查询某⼀交易⽇期或者某段时期内的其他信息。
这种情况下我们需要如何为equity表选择分区呢?单从表本⾝结构来看,似乎trade_date列很适合被选择⽤来作范围分区。
但如果我们这样分区的话,前⾯需求中的查询:指定某⼀id,查询其某⼀范围内的交易信息,⽐如看1年内的K线,则这种查询常常需要跨分区。
我们知道,对分区表作跨分区查询,很多时候其性能并不会太好,特别是这种查询很可能还要跨很多分区。
你也可能会说,我们再在id, trade_date列上建个索引不就⾏了,仔细想想是不是这样呢?这时候的equity表中的数据是按trade_date值来聚集的,同样trade_date值的数据常常在⼀个数据块中,这样前⾯需求中所描述的查询即使通过索引访问,最终读表时也常常是去读离散的数据块,即每⼀条记录需要对应读⼀个表数据块。
如果建成Hash分区表,则数据按hash分区键聚集,就更适合需求中描述的查询,因为同样id的记录必定在同⼀分区,同时,同样 id值的记录落在同⼀数据块的⼏率也增⼤了,从⽽“⼀定程度上”减少了IO。
上⾯对hash分区减少IO的描述加了引号,因为仅依靠Hash分区表试图实现⼤范围减少IO操作是不现实的,特别是当equity表中记录的股票数⾮常多时,同⼀股票发⽣在不同交易⽇的记录在物理上也很难聚集到相同数据块中。
Oracle分区表中索引失效
Oracle分区表中索引失效当对分区表进⾏⼀些操作时,会造成索引失效。
当有truncate/drop/exchange 操作分区时全局索引会失效。
exchange 的临时表没有索引,或者有索引,没有⽤including indexes的关键字,会导致局部的索引失效,就是某个分区失效重建局部索引只能⽤alter index local_idx rebuild partition p1这样的⽅式分区表SPLIT的时候,如果MAX区中已经有记录了,这个时候SPLIT就会导致有记录的新增分区的局部索引失效!查寻某个分区表中各个分区索引状态 USABLE/UNUSABLEselect index_name, partition_name, statusfrom user_ind_partitionswhere index_name ='indexName';--重建索引--local索引重建select b.table_name,a.INDEX_NAME,a.PARTITION_NAME,a.STATUS,'alter index '|| a.index_name ||' rebuild partition '||partition_name ||';'重建列from USER_IND_PARTITIONS a, user_part_indexes bwhere a.index_name = b.index_nameand b.TABLE_NAME IN ('PART_TAB_SPLIT')and STATUS ='UNUSABLE'ORDER BY b.table_name, a.INDEX_NAME, a.PARTITION_NAME;--全局索引重建alter index idx_part_split_col3 rebuild;在针对truncate等操作时直接更新 index 也可以搞定。
Oracle的临时表、分区表、分区索引
Oracle的临时表一、表的种类1:永久表:非私有数据,需要DML锁。
2:临时表:临时表的定义对所有会话都是可见的,处理事务或会话期存在的私有数据,不需要DML锁,对于临时表的DML语句不生成重做日志,临时表占用临时表空间,临时表的数据是自动删除的,在临时表上建的索引也是临时的。
二、临时表的种类1:事物型临时表:在事务期间数据存在,事务结束后数据被自动删除。
2:会话型临时表:在会话期间数据存在,会话结束后数据被自动删除。
三、临时表的限制1:不能分区,不能是索引组织表或簇。
2:不能指定关于临时表的外键约束。
3:不支持并行DML或并行查询。
4:不支持分布式事务处理。
5:不能指定段存储语句、嵌套表存储语句或并行语句四、建立临时表的语法1:建立关系表2:建立对象表3:并行语句Oracle的分区表一、什么是分区表Oracle可以将大表或索引分成若干个更小更方便管理的部分,每一部分称为一个分区,这样的表称为分区表。
SQL语句使用分区表比全表或全表索引能提供更好的访问和处理数据。
下图是按周所建分区表示例。
二、使用分区表的限制1:不能分割是簇一部分的表。
2:不能分割含有LONG或LONG RAW列的表。
3:索引组织表IOT不能进行范围分区。
**采用基于规则的优化器时,有会从分区表中受益!三、分区方法1:范围分区(更适合历史数据库)—Oracle8从惟一可用的分区类型按照列的列表的范围分割表;如果是索引组织表,则列的列表就必须是索引组织表主键的子集。
分区关键列的限制:列列表中的列可以是任何一种内置的数据类型,ROWID、LONG、LOB或者TIMESTAMP WITH TIME ZONE除外。
关键字MAXVALUE比任何值都高(含NULL)。
2:散列分区--Oracle8i可用的分区类型指定这个表是按哈希算法分区的,分区的数目应为2的幂。
1)单独散列分区(individual_hash_partitions)及其限制使用子名按照名字指定单个分区,分区名可以匆略。
oracle分区表压缩方法
oracle分区表压缩方法Oracle分区表压缩方法在Oracle数据库中,分区表是一种将大表拆分为多个较小、易于管理的分区的方法。
然而,随着数据的增长,分区表的存储需求也会不断增加。
为了解决这个问题,我们可以使用分区表压缩方法来减少存储空间的占用。
一、分区表压缩概述分区表压缩是指通过使用一些特定的技术和算法,对分区表中的数据进行压缩,以减少数据在磁盘上的存储空间。
这样可以节省存储成本,并提高数据的读写性能。
二、分区表压缩方法1.基于列的压缩基于列的压缩是一种以列为单位进行压缩的方法。
Oracle提供了多种列压缩技术,包括基于前缀的压缩、基于字典的压缩和基于位图的压缩等。
这些方法可以根据数据的特点选择最适合的压缩方式,以达到最佳的压缩效果。
2.基于行的压缩基于行的压缩是一种以行为单位进行压缩的方法。
Oracle提供了基于行的压缩技术,包括基于行存储的压缩和基于行组织的压缩等。
这些方法可以有效地减少数据的存储空间,并提高数据的读取性能。
3.基于分区的压缩基于分区的压缩是一种以分区为单位进行压缩的方法。
Oracle提供了分区压缩技术,可以对每个分区进行独立的压缩设置。
这样可以根据每个分区的特点选择最适合的压缩方式,以达到最佳的压缩效果。
4.基于表空间的压缩基于表空间的压缩是一种以表空间为单位进行压缩的方法。
Oracle 提供了表空间压缩技术,可以对整个表空间进行压缩设置。
这样可以统一管理表空间的压缩设置,简化管理工作,并提高压缩效果。
三、分区表压缩实践下面以一个示例来说明如何使用分区表压缩方法。
假设我们有一个分区表,包含了大量的历史数据,但这些数据很少被查询。
为了减少存储空间的占用,我们可以对该分区表进行压缩。
我们可以使用基于列的压缩方法,对一些冷数据列进行压缩。
例如,对于一些稀疏的列或者只包含有限取值的列,可以使用基于字典的压缩方法,将数据压缩为字典编码,从而减少存储空间的占用。
我们可以使用基于分区的压缩方法,对每个分区进行独立的压缩设置。
ORACLE数据库中PARTITION的用法
Oracle9i通过引入列表分区(List Partition),使得当前共有4种分区数据的方法,具体列出如下:第一种范围分区1 对表进行单列的范围分区:这使最为常用也是最简单的方法,具体例子如下:create table emp(empno number(4),ename varchar2(30),sal number)partition by range(empno)(partition e1 s less than (1000) tablespace emp1,partition e2 s less than (2000) tablespace emp2,partition e3 s less than (max) tablespace emp3);insert into emp s (100,Tom,1000);insert into emp s (500,Peter,2000);insert into emp s (1000,Scott,3000);insert into emp s (1999,Bill,4000);insert into emp s (5000,Gates,6000);commit;从emp表中选择全部的纪录如下:SQL> select * from emp;EMPNO ENAME SAL---------- ------------------------------ ----------100 Tom 1000500 Peter 20001000 Scott 30001999 Bill 40005000 Gates 6000还可以按照分区进行选择:SQL> select * from emp partition (e1);EMPNO ENAME SAL---------- ------------------------------ ----------100 Tom 1000500 Peter 2000SQL> select * from emp partition (e2)EMPNO ENAME SAL---------- ------------------------------ ----------1000 Scott 30001999 Bill 4000SQL> select * from emp partition (e3)EMPNO ENAME SAL---------- ------------------------------ ----------5000 Gates 6000使用了分区,还可以单独针对指定的分区进行truncate操作:alter table emp truncate partition e2;2 对表进行多列的范围分区:多列的范围分区主要是基于表中多个列的值的范围对数据进行分区,例如:drop table emp;create table emp(empno number(4),ename varchar2(30),sal number,day integer not null,month integer not null)partition by range(month,day)(partition e1 s less than (5,1) tablespace emp1,partition e2 s less than (10,2) tablespace emp2,partition e3 s less than (max,max) tablespace emp3);SQL> insert into emp s (100,Tom,1000,10,6);SQL> insert into emp s (200,Peter,2000,3,1);SQL> insert into emp s (300,Jane,3000,23,11);第二种Hash分区:hash分区最主要的机制是根据hash算法来计算具体某条纪录应该插入到哪个分区中(问:hash算法是干什么的?呵呵,只能去看看数据结构了)hash算法中最重要的是hash函数,Oracle中如果你要使用hash分区,只需指定分区的数量即可建议分区的数量采用2的n次方,这样可以使得各个分区间数据分布更加均匀具体例子如下:drop table emp;create table emp (empno number(4),ename varchar2(30),sal number)partition by hash (empno)partitions 8store in (emp1,emp2,emp3,emp4,emp5,emp6,emp7,emp8);怎么样?很方便吧!第三种复合分区:这是一种将前两种分区综合在一起使用的方法,例如:drop table emp;create table emp (empno number(4),ename varchar2(30),hiredate date)partition by range (hiredate)subpartition by hash (empno)subpartitions 2(partition e1 s less than (to_date(20020501,YYYYMMDD)),partition e2 s less than (to_date(20021001,YYYYMMDD)),partition e3 s less than (max));上面的例子中将雇员表先按照雇佣时间hiredate进行了范围分区,然后再把每个分区分为两个子hash分区。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
yang@ORACL> create table yangtmp ( id number, time date );
表已创建。
yang@ORACL> insert into yangtmp select rownum id ,sysdate-dbms_random.value(1,500) time
2 from dual
3 connect by level <=1e5;
已创建100000行。
yang@ORACL> select count(1) from yangtmp;
COUNT(1)
----------
100000
yang@ORACL> commit;
提交完成。
yang@ORACL> create table yang_part (
2 id number,
3 time date
4 )
5 partition by range (time) (
6 partition p2010 values less than (to_date('20110101','yyyymmdd')),
7 partition p201101 values less than (to_date('20110401','yyyymmdd')),
8 partition p201102 values less than (to_date('20110701','yyyymmdd')),
9 partition p201103 values less than (to_date('20111001','yyyymmdd')),
10 partition p201104 values less than (to_date('20120101','yyyymmdd'))
11 );
表已创建。
yang@ORACL> rename yangtmp to yang_old;
表已重命名。
yang@ORACL> rename yang_part to yang_tmp;
表已重命名。
yang@ORACL> select count(1) from yang_old;
COUNT(1)
----------
100000
yang@ORACL> select count(1) from yang_tmp;
COUNT(1)
----------
0
yang@ORACL> rename yang_tmp to yang_part;
表已重命名。
yang@ORACL> insert into yang_part select id,time from yang_old;
已创建100000行。
yang@ORACL> rename yang_part to yang_tmp;
表已重命名。
yang@ORACL> select count(1) from yang_old;
COUNT(1)
----------
100000
yang@ORACL> select count(1) from yang_tmp;
COUNT(1)
----------
100000
yang@ORACL> select count(1) from yang_tmp partition (p2010);
COUNT(1)
----------
85142
yang@ORACL> select count(1) from yang_tmp partition (p201101);
COUNT(1)
----------
14858
yang@ORACL> select count(1) from yang_tmp partition (p201102);
COUNT(1)
----------
0