中文常用分词算法
人工智能机器学习之NLP和中文分词算法

⼈⼯智能机器学习之NLP和中⽂分词算法前⾔:在⼈类社会中,语⾔扮演着重要的⾓⾊,语⾔是⼈类区别于其他动物的根本标志,没有语⾔,⼈类的思维⽆从谈起,沟通交流更是⽆源之⽔。
所谓“⾃然”乃是寓意⾃然进化形成,是为了区分⼀些⼈造语⾔,类似C++、Java等⼈为设计的语⾔。
NLP的⽬的是让计算机能够处理、理解以及运⽤⼈类语⾔,达到⼈与计算机之间的有效通讯。
01 什么是NLP1. NLP的概念NLP(Natural Language Processing,⾃然语⾔处理)是计算机科学领域以及⼈⼯智能领域的⼀个重要的研究⽅向,它研究⽤计算机来处理、理解以及运⽤⼈类语⾔(如中⽂、英⽂等),达到⼈与计算机之间进⾏有效通讯。
在⼀般情况下,⽤户可能不熟悉机器语⾔,所以⾃然语⾔处理技术可以帮助这样的⽤户使⽤⾃然语⾔和机器交流。
从建模的⾓度看,为了⽅便计算机处理,⾃然语⾔可以被定义为⼀组规则或符号的集合,我们组合集合中的符号来传递各种信息。
这些年,NLP研究取得了长⾜的进步,逐渐发展成为⼀门独⽴的学科,从⾃然语⾔的⾓度出发,NLP基本可以分为两个部分:⾃然语⾔处理以及⾃然语⾔⽣成,演化为理解和⽣成⽂本的任务,如图所⽰。
▲NLP的基本分类⾃然语⾔的理解是个综合的系统⼯程,它⼜包含了很多细分学科,有代表声⾳的⾳系学,代表构词法的词态学,代表语句结构的句法学,代表理解的语义句法学和语⽤学。
⾳系学:指代语⾔中发⾳的系统化组织。
词态学:研究单词构成以及相互之间的关系。
句法学:给定⽂本的哪部分是语法正确的。
语义学:给定⽂本的含义是什么?语⽤学:⽂本的⽬的是什么?语⾔理解涉及语⾔、语境和各种语⾔形式的学科。
⽽⾃然语⾔⽣成(Natural Language Generation,NLG)恰恰相反,从结构化数据中以读取的⽅式⾃动⽣成⽂本。
该过程主要包含三个阶段:⽂本规划:完成结构化数据中的基础内容规划语句规划:从结构化数据中组合语句来表达信息流实现:产⽣语法通顺的语句来表达⽂本2. NLP的研究任务NLP可以被应⽤于很多领域,这⾥⼤概总结出以下⼏种通⽤的应⽤:机器翻译:计算机具备将⼀种语⾔翻译成另⼀种语⾔的能⼒。
jiba中文分词原理

jiba中⽂分词原理中⽂分词就是将⼀个汉字序列分成⼀个⼀个单独的词。
现有的分词算法有三⼤类:基于字符串匹配的分词:机械分词⽅法,它是按照⼀定的策略将待分析的字符串与⼀个充分⼤的机器词典中的词条进⾏匹配,若在词典中找到某个字符串,则匹配成功。
基于理解的分词⽅法:通过让计算机模拟⼈对句⼦的理解,达到识别词的效果,特点就是在分词的同时进⾏句法,语义的分析,利⽤句法信息和语义信息来处理歧义现象。
通常包括三个部分:分词⼦系统,句法语义⼦系统,总控部分。
基于统计的分词⽅法:给出⼤量的已经分词的⽂本,利⽤统计机器学习模型学习词语切分的规律称为训练,从⽽实现对未知⽂本的切分,例如最⼤概率分词⽅法和最⼤熵分词⽅法等。
随着⼤规模语料库的建⽴,统计机器学习⽅法的研究和发展,基于统计的中⽂分词⽅法渐渐成为了主流⽅法。
jieba⽀持三种分词模式:1.精确分词,试图将句⼦最精确的切开,适合⽂本分析。
2.全模式:把句⼦中所有的可以成词的词语都扫描出来,速度⾮常快,但是不能解决歧义。
3.搜索引擎模式:在精确模式的基础上,对长词再次切分,提⾼召回率,适合⽤于搜索引擎分词。
基本原理:1.基于字典树trie树结构实现⾼效的词图扫描,⽣成句⼦中汉字所有可能成词情况所构成的有向⽆环图(DAG)jieba分词⾃带了⼀个叫做dict.txt的词典,⾥⾯有2万多条词,包含了次条出现的次数和词性,这个⼀个条原理就是把这2万多条词语,放到⼀个trie树中,⽽trie树是有名的前缀树,也就是说⼀个词语的前⾯⼏个字⼀样,就表⽰他们具有相同的前缀。
具有查找速度快的优势。
2.采⽤了动态规划查找最⼤概率路径,找出基于词频的最⼤切分组合动态规划中,先查找待分词句⼦中已经切分好的词语,对该词语查找该词语出现的频率,如果没有该词,就把词典中出现频率最⼩的那个词语的频率作为该词的频率。
对句⼦从右到左反向极端最⼤概率,因为从右往左计算,正确率要⾼于从左往右计算,因为汉语句⼦的中⼼在后⾯,就是落在右边。
tiktoken中文分词原理

tiktoken中文分词原理1.概述在自然语言处理(NL P)领域中,中文分词是一个重要的任务,它的目标是将连续的中文字符序列切分成有意义的词语。
ti kt ok en是一个开源的中文分词工具,它基于最大匹配算法和字典树的方法来实现中文分词。
本文将介绍t ik to ke n中文分词工具的原理及其运行过程。
2.最大匹配算法最大匹配算法是一种常用的中文分词算法,它基于词典中最长的词汇进行切分。
t ik to ken利用了最大匹配算法来进行分词。
具体而言,t ik to ken首先将待切分的句子按照最大切分长度划分为几个子句。
然后,它从每个子句的起始位置开始,逐渐增大切分长度,不断寻找匹配的词汇。
当找到匹配的词汇时,t ik to ke n将该词汇作为一个分词结果,并将切分位置移动到下一个子句的起始位置。
这个过程重复进行,直到所有子句都被分词为止。
最大匹配算法的一个关键问题是如何确定最大切分长度。
t ikt o ke n使用了统计信息和机器学习的方法来动态地确定最佳的最大切分长度,以提高分词的准确性。
3.字典树字典树(Tr ie)是一种树状数据结构,它能够高效地存储和查找字符串。
ti kt ok en利用了字典树来储存中文词汇信息,以支持最大匹配算法的快速匹配过程。
字典树的每个节点代表一个字符,从根节点到叶节点的路径表示一个完整的词汇。
ti kt ok e n在分词过程中通过比对待切分句子的字符与字典树节点的字符,来确定最大匹配的词汇。
4. ti ktoken的运行过程t i kt ok en的运行过程可以概括为以下几个步骤:4.1构建字典树t i kt ok en首先从一个大型的中文词汇库中提取出所有的词汇,并构建字典树。
这个字典树将作为最大匹配算法的匹配模型。
4.2切分子句t i kt ok en将待切分的句子按照标点符号或其他符号进行划分,形成若干个子句。
每个子句都将作为最大匹配算法的输入。
4.3最大匹配对于每个子句,ti kt o ke n从起始位置开始,逐渐增大最大切分长度,利用字典树进行匹配。
中文分词技术研究

分词算法一般有三类:基于字符串匹配、基于语义分析、基于统计。
复杂的分词程序会将各种算法结合起来以便提高准确率。
Lucene被很多公司用来提供站内搜索,但是Lucene本身并没有支持中文分词的组件,只是在Sandbox里面有两个组件支持中文分词:ChineseAnalyzer和CJKAnalyzer。
ChineseAnalyzer 采取一个字符一个字符切分的方法,例如"我想去北京天安门广场"用ChineseAnalyzer分词后结果为:我#想#去#北#京#天#安#门#广#场。
CJKAnalyzer 则是二元分词法,即将相邻的两个字当成一个词,同样前面那句用CJKAnalyzer 分词之后结果为:我想#想去#去北#北京#京天#天安#安门#门广#广场。
这两种分词方法都不支持中文和英文及数字混合的文本分词,例如:IBM T60HKU现在只要11000元就可以买到。
用上述两种分词方法建立索引,不管是搜索IBM还是11000都是没办法搜索到的。
另外,假如我们使用"服务器"作为关键字进行搜索时,只要文档包含"服务"和"器"就会出现在搜索结果中,但这显然是错误的。
因此,ChineseAnalyzer和CJKAnalyzer虽然能够简单实现中文的分词,但是在应用中仍然会感觉到诸多不便。
基于字符串匹配的分词算法用得很多的是正向最大匹配和逆向最大匹配。
其实这两种算法是大同小异的,只不过扫描的方向不同而已,但是逆向匹配的准确率会稍微高一些。
"我想去北京天安门广场"这句使用最大正向分词匹配分词结果:我#想去#北京#天安门广场。
这样分显然比ChineseAnalyzer和CJKAnalyzer来得准确,但是正向最大匹配是基于词典的,因此不同的词典对分词结果影响很大,比如有的词典里面会认为"北京天安门"是一个词,那么上面那句的分词结果则是:我#想去#北京天安门#广场。
一种键树结构的中文分词方法

3 】所做 的研究工 作都是改进词典 结构 ,在新 的数 据结构上 优 化 正 向最 大 匹配 算法 。研 究发 现 ,词典 的数据 结构设 计成 键
树 结构 ,每个结 点记 录字符参 与构词 的信息 ,在查 询时根 据 词 典 中信 息能快 速判断是 否 已构成 最长词 语 ,从而 不需要设
1 引 言
中文分词 正 向最 大匹 配算法是 一个 实用性 很强 的分词算 法 。该算法 只需要 一个词 典 ,依据 “ 长词 优先 ” 的原则 进行
切 分 。 文 献 【】介 绍 了 正 向最 大 匹 配 算 法 的 基 本 思 想 是 :假 1
4 ;结 点 “ ” t e=1 on =2 国 ,s t a , u t ;结 点 “ ” t e=0 c 共 ,s t a , cut ;结点 “ ” t e=0cu t ;结点 “ ” tt on =1 产 ,s t a , n =1 o 党 ,s e a
A bsr t Fo wa d m a i t ac : r r x mum ac ng ag rt m thi lo ihm swie y us d i i d l e n Chi s r e me ai n I hi p r tucur f ne e wo d s g ntto n t s pa e ,a sr t e o
摘
中文分词入门之最大匹配法
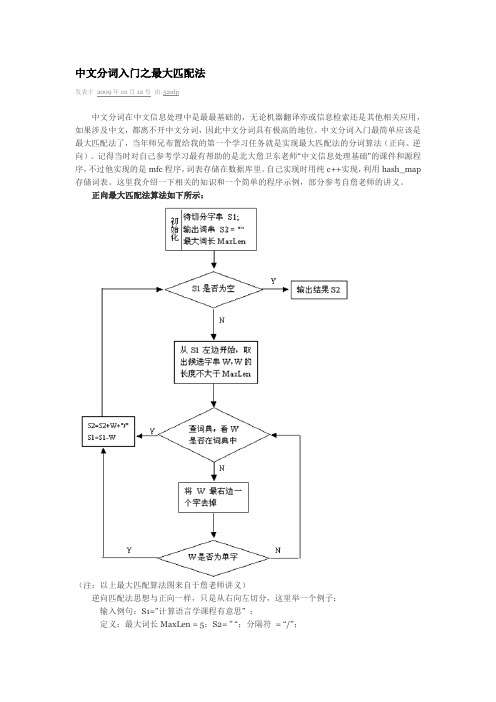
中文分词入门之最大匹配法发表于2009年01月12号由52nlp中文分词在中文信息处理中是最最基础的,无论机器翻译亦或信息检索还是其他相关应用,如果涉及中文,都离不开中文分词,因此中文分词具有极高的地位。
中文分词入门最简单应该是最大匹配法了,当年师兄布置给我的第一个学习任务就是实现最大匹配法的分词算法(正向、逆向)。
记得当时对自己参考学习最有帮助的是北大詹卫东老师“中文信息处理基础”的课件和源程序,不过他实现的是mfc程序,词表存储在数据库里。
自己实现时用纯c++实现,利用hash_map 存储词表。
这里我介绍一下相关的知识和一个简单的程序示例,部分参考自詹老师的讲义。
正向最大匹配法算法如下所示:(注:以上最大匹配算法图来自于詹老师讲义)逆向匹配法思想与正向一样,只是从右向左切分,这里举一个例子:输入例句:S1=”计算语言学课程有意思” ;定义:最大词长MaxLen = 5;S2= ” “;分隔符= “/”;假设存在词表:…,计算语言学,课程,意思,…;最大逆向匹配分词算法过程如下:(1)S2=”";S1不为空,从S1右边取出候选子串W=”课程有意思”;(2)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有意思”;(3)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有意思”;(4)查词表,W不在词表中,将W最左边一个字去掉,得到W=”意思”(5)查词表,“意思”在词表中,将W加入到S2中,S2=” 意思/”,并将W从S1中去掉,此时S1=”计算语言学课程有”;(6)S1不为空,于是从S1左边取出候选子串W=”言学课程有”;(7)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程有”;(8)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程有”;(9)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有”;(10)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有”,这W是单字,将W 加入到S2中,S2=“ /有/意思”,并将W从S1中去掉,此时S1=”计算语言学课程”;(11)S1不为空,于是从S1左边取出候选子串W=”语言学课程”;(12)查词表,W不在词表中,将W最左边一个字去掉,得到W=”言学课程”;(13)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程”;(14)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程”;(15)查词表,“意思”在词表中,将W加入到S2中,S2=“课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”计算语言学”;(16)S1不为空,于是从S1左边取出候选子串W=”计算语言学”;(17)查词表,“计算语言学”在词表中,将W加入到S2中,S2=“计算语言学/ 课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”";(18)S1为空,输出S2作为分词结果,分词过程结束。
中文bpe分词
中文bpe分词(原创实用版)目录1.中文分词的重要性2.BPE 分词方法的原理3.BPE 分词方法的优势4.BPE 分词方法的实际应用5.总结正文一、中文分词的重要性中文文本与英文文本在处理上存在很大差异,其中一个关键因素就是中文没有明确的词语边界。
英文文本通过空格可以清晰地划分单词,而中文文本则需要进行分词处理,将连续的文本切分成有意义的词汇单元。
中文分词在自然语言处理、信息检索、文本挖掘等领域具有重要意义。
二、BPE 分词方法的原理BPE(Backward Prefix-suffix)分词方法是一种基于字典的分词方法。
该方法通过遍历输入文本,动态构建一个有向无环图(DAG),并利用该图进行分词。
具体原理如下:1.构建字典:首先根据输入文本构建一个字典,存储每个字符或词语的出现频率及其前缀和后缀信息。
2.遍历输入文本:从输入文本的开始位置开始,依次将字符或词语添加到字典中,并更新它们的前缀和后缀信息。
3.动态规划:利用字典中的信息,通过动态规划算法计算每个字符或词语的分词概率。
4.切分词语:根据分词概率,从输入文本的末尾开始,向前切分出有意义的词语。
三、BPE 分词方法的优势BPE 分词方法具有以下优势:1.能够处理未登录词:BPE 分词方法可以识别字典中不存在的词语,如新词、专有名词等。
2.切分精度高:BPE 分词方法可以根据词语在文本中的上下文信息进行切分,从而获得较高的切分精度。
3.鲁棒性好:BPE 分词方法能够处理各种复杂的输入文本,如包含歧义、重复、噪音等。
四、BPE 分词方法的实际应用BPE 分词方法在许多自然语言处理任务中都有广泛应用,如文本分类、情感分析、机器翻译等。
通过 BPE 分词方法,可以有效提高这些任务的性能和准确性。
五、总结作为一种基于字典的中文分词方法,BPE 分词方法具有处理未登录词、切分精度高、鲁棒性好等优势。
中文分句模型
中文分句模型中文分句模型文档随着中文语言的发展,中文自然语言处理也得到了越来越多的应用。
其中,中文分句技术是自然语言处理中的一个重要应用。
中文分句指的是将连续的中文文本分成若干句子的过程。
在中文文本处理中,中文分句是一个非常基础的技术,其精准率和效率,直接关系到后续的处理结果。
本文将介绍中文分句的基本原理、常见算法和现有的分句模型。
一、中文分句的基本原理在英文中,一个句子通常以一些术语结尾,如period,question mark等,因此英文句子较为清晰明了。
但是,在中文中,并没有像英文一样使用标点来标记句子的结束,因此需要借助算法来实现中文分句。
中文分句技术需要考虑以下几个方面:1. 句子分隔符中文句子一般没有像英文那样的句子分隔符,如period,question mark等。
因此,我们需要在分句过程中自行定义一些句子分隔符,如句号、问号、叹号和省略号等符号。
在一些较为复杂的场景中,我们需要自定义更多的分隔符。
2. 句子结构另外,在中文中,句子结构也具有较高的复杂性。
例如,在一个较长的句子中,可能还会包含着一些小的子句,而这些子句之间也存在着一些衔接关系。
因此,在分句时还需要考虑到句子结构的复杂性。
3. 句子长度在进行中文分句的过程中,我们还需要考虑到句子的长度。
如果句子太长,那么就难以有效地处理诸如分词、命名实体识别等后续处理过程。
因此,在分句时,如果句子的长度过长,需要对其进行特殊处理。
二、常见的中文分句算法对于中文分句过程,目前已经发展出了多种算法模型,如基于规则算法模型、基于机器学习算法模型等。
下面,我们将分别介绍这些常见的分句算法模型:1. 基于规则算法模型基于规则算法模型是分句算法中最早出现的,也是最直观、最简单的算法。
该算法基于现成的语言学规则,先完成词性标注和分词工作后,利用一些指定的规则进行分句,将具有特定句末符号的句子视为一个句子。
该算法的缺点是需要手工构造规则,而且对文本的结构支持较弱,因此难以适应复杂语境。
中文分词简介
算法过程: (1) 相邻节点 v k-1 , v k 之间建立有向边 <v k-1 , v k > ,边对应的词默认为 c k ( k =1, 2, …, n) (2) 如果 w= c i c i+1 …c j (0<i<j<=n) 是一个词,则节点v i-1 , v j 之间建立有向边 <v i-1 , v j > ,边对应的词为 w
歧义切分问题
歧义字段在汉语文本中普遍存在,因此,切分歧义是中文分词研究中一个不 可避免的“拦路虎”。 (交集型切分歧义) 汉字串AJB如果满足AJ、JB同时为词(A、J、B分别为汉 字串),则称作交集型切分歧义。此时汉字串J称作交集串。 如“结合成”、“大学生”、“师大校园生活”、“部分居民生活水平”等等。 (组合型切分歧义) 汉字串AB如果满足A、B、AB同时为词,则称作多义组合 型切分歧义。 “起身”:(a)他站│起│身│来。(b)他明天│起身│去北京。 “将来”:(a)她明天│将│来│这里作报告。(b)她│将来│一定能干成大事。
中文分词的辅助原则
1. 有明显分隔符标记的应该切分之 。 2. 附着性语素和前后词合并为一个分词单位。 3. 使用频率高或共现率高的字串尽量合并为一个分词单位 。 4. 双音节加单音节的偏正式名词尽量合并为一个分词单位。 5. 双音节结构的偏正式动词应尽量合并为一个分词单位 。 6. 内部结构复杂、合并起来过于冗长的词尽量切分。
其他分词方法
▶由字构词(基于字标注)的分词方法 ▶生成式方法与判别式方法的结合 ▶全切分方法 ▶串频统计和词形匹配相结合的分词方法 ▶规则方法与统计方法相结合 ▶多重扫描法
Part 5
总结
分词技术水平
自开展中文分词方法研究以来,人们提出的各类方法不下几十种甚至上百 种,不同方法的性能各不相同,尤其在不同领域、不同主题和不同类型的汉语 文本上,性能表现出明显的差异。 总之,随着自然语言处理技术整体水平的提高,尤其近几年来新的机器学 习方法和大规模计算技术在汉语分词中的应用,分词系统的性能一直在不断提 升。特别是在一些通用的书面文本上,如新闻语料,领域内测试(训练语料和 测试语料来自同一个领域)的性能已经达到相当高的水平。但是,跨领域测试 的性能仍然很不理想。如何提升汉语自动分词系统的跨领域性能仍然是目前面 临的一个难题。 另外,随着互联网和移动通信技术的发展,越来越多的非规范文本大量涌 现,如微博、博客、手机短信等。研究人员已经关注到这些问题,并开始研究 。
分词算法java
分词算法java
在Java中,常用的分词算法包括:
1. 最大匹配算法(MM):
最大匹配算法是一种基于词典的分词算法,它将待分词的文本从左到右进行扫描,根据词典中的词语进行匹配,选择最长的匹配词作为分词结果。
该算法简单高效,但对于歧义词和未登录词处理较差。
2. 正向最大匹配算法(FMM):
正向最大匹配算法与最大匹配算法类似,但它从文本的起始位置开始匹配。
首先取待分词文本中的前n个字符作为匹配字符串(通常取词典中最长的词的长度),如果这个字符串在词典中存在,则作为分词结果,否则取待分词文本的前n-1个字符,继续匹配,直到匹配到词典中的词为止。
3. 逆向最大匹配算法(BMM):
逆向最大匹配算法与正向最大匹配算法类似,但它从文本的末尾位置向前匹配。
首先取待分词文本中的后n个字符作为匹配字符串,如果这个字符串在词典中存在,则作为分词结果,否则取待分词文本的后n-1个字符,继续匹配,直到匹配到词典中的词为止。
4. 双向最大匹配算法(BiMM):
双向最大匹配算法结合了正向最大匹配算法和逆向最大匹配算法的优点。
它
从文本的起始位置和末尾位置同时进行匹配,选择两个结果中词数较少的分词结果作为最终的分词结果。
以上是一些常见的分词算法,你可以根据自己的需求选择合适的算法进行分词处理。
同时,还可以使用一些开源的中文分词库,例如HanLP、jieba等,它们已经实现了这些算法,并提供了丰富的功能和接口供你使用。